
I just watched one of the most significant leaps in customer service AI in years. Last week, a quiet but seismic release landed in CX: Fin introduced Apex, a vertical model purpose-built for support that raises the bar on speed, accuracy, and cost. As a product leader, this is exactly the kind of breakthrough that changes roadmaps, vendor strategies, and what customers can expect from modern service operations.
It’s a brand new model for Fin called Apex, and it’s objectively the highest performing, fastest, and cheapest model for customer service. It beats the very best models in the industry including GPT-5.4 and Opus 4.5.
In this analysis, I’ll unpack why the launch matters for the customer service agent category, what it signals for frontier labs and open‑weight ecosystems, and how leaders should rethink their AI Strategy, build vs buy decisions, and eval-driven development roadmaps.
Fin was already the highest performing and most sophisticated agent in the customer service space, consistently beating impressive competitors like Decagon and Sierra at an average win rate in the 70s. It operates at tremendous scale, now resolving almost 2M customer issues per week, a number that’s growing at an exponential clip. In its short life it’s grown to nearly $100M in recurring revenue.
As of last week, ~100% of all (English language, chat and email) customer conversations are now running on Apex. Since day 1, the Fin engine has comprised a system of models, and last year the team began replacing off‑the‑shelf models with custom ones trained on proprietary data. The core answering model had been a frontier labs offering—initially versions of GPT and more recently Sonnet 4.0. Now, that core answering model is Apex 1.0.
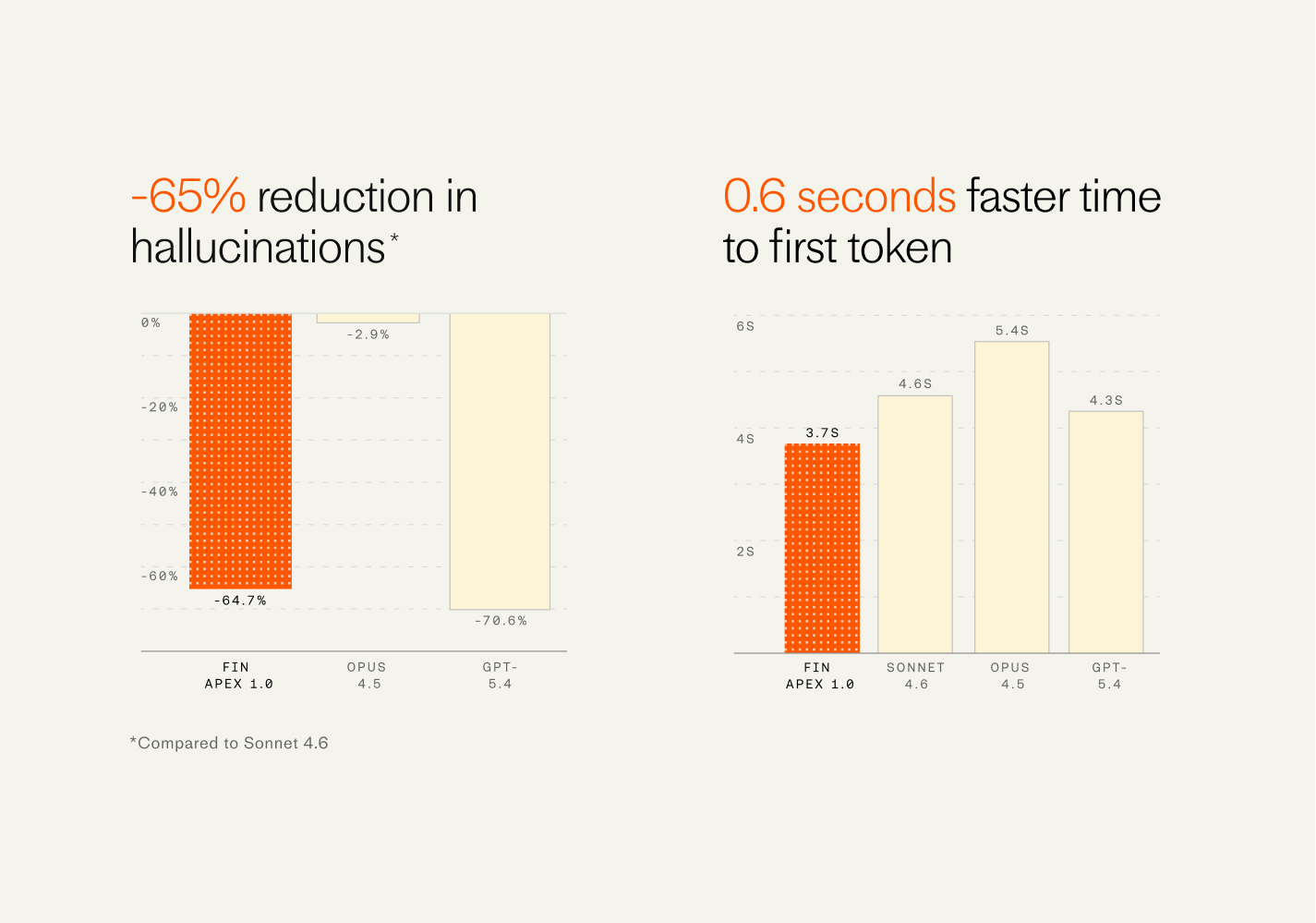
This model resolves customer issues at a materially higher rate than any other model available. One of their largest customers in the gaming space saw the resolution rate improve overnight from 68% to 75% (i.e. a reduction in unresolved conversations of 22%). The team notes they had never seen a jump this large from a single improvement since they started Fin.
Just as important, it’s dramatically faster, has fewer hallucinations, and is far cheaper than other available models—exactly the attributes operations leaders weigh most when deploying agents at scale. In practice, these are the levers that unlock higher CSAT, tighter SLAs, and better unit economics.
Achieving all three simultaneously is extraordinarily hard. Credit goes to foundational research from a 60‑person AI group run by Fergal Reid, and, crucially, to domain‑specific proprietary evals drawn from billions of human and agent interactions produced by the Fin resolution engine—already hand‑tuned to be the most effective in the category. That creates a flywheel: an eval‑driven development loop that trains models to keep improving at the edge of the system’s abilities. In other words, Apex 1.0 looks like the tip of the iceberg.
Zooming out, service is one of the few categories where generative AI has already delivered commercial impact at scale (alongside coding, and arguably the legal industry). With TAMs measured in the hundreds of billions, competition is intense and well capitalized. The pattern I’ve seen repeatedly is clear: winners in these spaces must become full‑stack AI companies. As features become ~free to build, durable competitive differentiation shifts under the hood—to proprietary data, post‑training, inference efficiency, and the quality of the eval loop.
That’s why competitors will need to release their own models. Many appear to be just starting to hire the talent to do so, which likely gives Fin at least a year of head start. For product leaders, this is a strong signal to revisit build vs buy assumptions, and to quantify when owning your post‑training pipeline and evals becomes the rational move.
Honestly, 2–3 years ago I expected AI application differentiation to live mostly in what we built around third‑party models. The AI game humbles all of us; today it’s obvious that vertical models paired with proprietary evals create compounding moats.
In a podcast interview last week, Andrej Karpathy said:
"I do think we should expect more speciation in the intelligences. The animal kingdom is extremely [diverse] in the brains that exist. And there’s lots of different niches of nature… And I think we should be able to see more speciation. And you don’t need this oracle that knows everything. You kind of speciate it. And then you put it on a specific task. And we should be seeing some of that because you should be able to have much smaller models that still have the cognitive core."
The frontier labs still have the very best models, but open‑weight models aren’t far behind—making pre‑training look increasingly like a commodity. The frontier is moving to post‑training, which is precisely what we see with Apex (and Cursor’s Composer 2), and what we should expect to dominate going forward.
Labs now face a dual reality. On one hand, horizontal general‑purpose models can over‑serve specific verticals (e.g., customer service doesn’t need an oracle that knows everything). On the other, open‑weight models are good enough that high‑quality, domain‑specific post‑training can produce superior models for special‑purpose jobs—and in the ways that matter for those jobs. In service, soft factors like judgement, pleasantness, and attentiveness matter alongside hard factors like resolution effectiveness, speed, and cost.
I’m still bullish on the labs. Many organizations remain heavy customers of Anthropic—whether as part of multi‑model systems or through deep usage of Claude Code in engineering teams (see this example of Claude Code adoption). Yet classic disruption (à la the late, great Clay Christensen) is now at their door. The way out is to disrupt themselves by building cheaper specialized models too, which likely requires acquiring the evals—or the companies with the evals—needed for each task. Expect creative data partnerships, M&A consolidation, and a wave of hyper‑specific model providers that compete head‑to‑head with the labs.
In the meantime, Fin appears to be the only vendor in its space with a custom model that’s also objectively superior to everything else out there. I’m excited to see it deployed broadly for end customers, and I’m watching closely for the next announcement that will accelerate that rollout. For product leaders, the message is clear: the age of vertical models and agentic AI is here—bring your evals, or bring your checkbook.
Inspired by this post on The Intercom Blog.











Leave a Reply