Your AI team is shipping, dashboards are filling up, and executives are still asking the uncomfortable question: what changed for the customer or the business?
The answer is rarely another model metric. You need an operating model that connects AI quality to customer behavior, workflow performance, commercial results, and risk. When that chain is visible, you can decide what to scale, what to repair, and what to stop.
Key takeaways
- Give every AI initiative an outcome contract that names the target behavior, business result, guardrails, and decision owner.
- Measure four linked layers: AI quality, user behavior, workflow results, and business outcomes.
- Preserve the context behind each interaction so you can compare outcomes by customer, workflow, model version, and acquisition path.
- Run one recurring evidence review where teams make explicit scale, fix, hold, or stop decisions.
- Use the first 90 days to prove a reusable learning system, not merely a functioning AI experience.
Start each initiative with an outcome contract
A feature brief tells a team what to build. An outcome contract tells it why the work exists, how evidence will be interpreted, and who can act on that evidence. It is the smallest practical unit of an outcome-led AI portfolio.
Write the contract before choosing a model or polishing a prompt. Keep it to one page and require six fields:
- Target workflow: Name the repeated job being changed, such as resolving a support request or preparing a sales follow-up.
- Target user behavior: Describe what a person should do differently. Adoption alone is weak; successful completion, accepted recommendations, or reduced rework is stronger.
- Business outcome: Connect the behavior to retention, expansion, qualified demand, service capacity, or another commercial result.
- Quality floor: Define the task-level evaluation the AI must pass before exposure expands.
- Guardrails: Name the safety, privacy, latency, reliability, and cost conditions that must remain acceptable.
- Decision rule: State what evidence will trigger a scale, fix, hold, or stop decision, and name the person accountable for making it.
A driver tree makes the logic inspectable. Start with the business result, work backward to the customer behavior that can influence it, then identify the product and AI capabilities that can change that behavior. This prevents a model improvement from being mistaken for business progress.
The contract also gives empowered teams useful boundaries. Leaders align the portfolio around outcomes and constraints; teams retain room to change prompts, retrieval methods, interaction design, or even the proposed solution. That is the practical connection between AI strategy, continuous discovery, evaluation, delivery, and value capture.
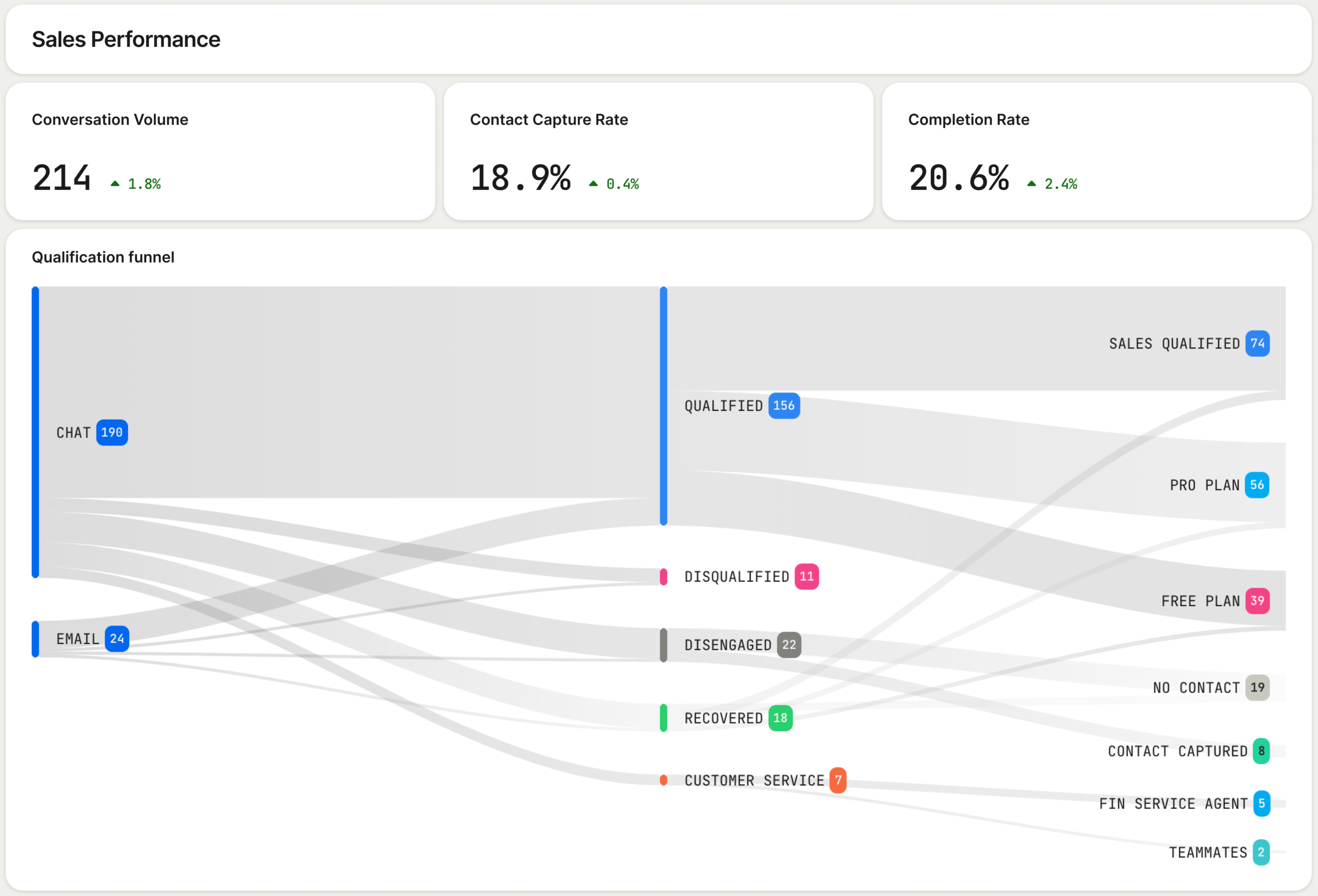
Build one scorecard across four layers
AI outcome analytics is not a single north-star metric. It is a chain of evidence. If you measure only the beginning of the chain, you learn whether the system produced an answer. If you measure only the end, you may see revenue move without knowing why.
| Measurement layer | Question it answers | Useful examples | Typical decision |
|---|---|---|---|
| AI quality | Did the system perform the intended task? | Task success, groundedness, safety failures, response variance | Change prompts, context, retrieval, model, or fallback |
| User behavior | Did a person trust and use the result? | Acceptance, correction, abandonment, repeat use, human escalation | Change the interaction, explanation, or moment of assistance |
| Workflow outcome | Did the job become meaningfully better? | Successful completion, rework, cycle time, resolution quality | Expand, narrow, or redesign the workflow |
| Business and risk outcome | Did the change create durable value within constraints? | Retention, expansion, qualified leads, cost per successful outcome, incidents | Scale, repackage, hold, or stop |
Read the layers from left to right. Good AI quality with weak behavior usually points to product design, trust, or workflow placement. Strong usage with no workflow improvement may indicate novelty rather than value. Workflow gains with poor economics mean the experience works but the architecture or packaging does not.
Use the workflow attempt as the basic unit of analysis whenever possible. A generic session can contain several unrelated intentions. A workflow attempt lets you connect the user request, retrieved context, model and prompt version, response, correction, completion, and downstream result.
Persist the properties needed to reconstruct that journey. Customer segment, acquisition context, workflow type, entitlement, experiment group, model version, retrieval version, and human-handoff status often matter more than another page-view event. Carrying critical context across visits lets you trace behavior from early exploration to conversion and expansion instead of losing the causal story at signup.
Keep the event taxonomy small enough to govern. Instrument decisions and state changes, not every interface movement. For each event, document its owner, trigger, required properties, prohibited sensitive data, and validation method. A dashboard built on ambiguous events creates confidence without clarity.
Run a weekly loop from evidence to decision
Analytics creates value only when it changes a decision. Give each AI initiative a recurring evidence review attended by the product trio and the engineering, data, risk, operations, or go-to-market partners needed for that workflow.
- Check the contract. Reconfirm the target workflow, primary outcome, evaluation floor, and guardrails. If the goal has changed, update the contract before interpreting the data.
- Inspect the scorecard. Review AI quality, behavior, workflow, business, risk, and cost in that order. Look for breaks in the chain rather than averaging them into one health score.
- Segment the result. Compare the cohorts that could conceal a failure: new and experienced users, customer tiers, workflow types, channels, experiment groups, and system versions.
- Review failure cases. Sample unsuccessful attempts and classify the reason: missing context, poor retrieval, incorrect generation, confusing interaction, policy restriction, latency, or a problem outside the AI system.
- Make one portfolio decision. Choose scale, fix, hold, or stop. Record the evidence, owner, next test, and condition for revisiting the decision.
Do not let offline evaluations and online analytics compete. Offline evaluations test whether a candidate change can handle representative tasks and known edge cases. Online measures show whether the released experience changes real behavior under real conditions. A candidate should clear the evaluation floor before broader exposure, then earn expansion through customer and business evidence.
When you run an experiment, agree on the hypothesis, primary outcome, guardrails, minimum detectable effect, and stopping rule before looking at results. Feature flags and progressive rollout keep the decision reversible. If the result is ambiguous, improve the test or narrow the population; do not promote the most flattering proxy.
This rhythm makes learning rate operational. The useful question is not how many experiments ran. It is how many consequential uncertainties were resolved and converted into a product, portfolio, or go-to-market decision. Testable decisions, behavioral analytics, and guarded rollouts make speed credible because the evidence can survive scrutiny.
Assign decision rights before the dashboard turns red
AI products cross boundaries that ordinary feature teams can often ignore. Product owns the customer and business outcome. Engineering owns service behavior and remediation. Data or AI teams own evaluation integrity and model observability. Risk, security, legal, and operations own constraints that cannot be traded away informally.
Write those responsibilities into the operating model. For each risk tier, specify who can approve an initial release, expand exposure, pause the system, change a model or retrieval source, accept a temporary exception, and communicate an incident. A named decision owner is more useful than a large committee with shared accountability.
Governance should begin during discovery. The team can then choose acceptable data, design consent, build traceability, create fallbacks, and define escalation paths before those choices become expensive. Model cards, data records, evaluation results, release history, and incident decisions should form one audit trail rather than separate compliance paperwork.
The same principle applies to commercial decisions. Product, finance, sales, and customer success need a shared definition of value. Measure inference and support costs against successful workflow outcomes, not raw requests or tokens. Packaging can then reflect delivered value while protecting margins and avoiding incentives for wasteful usage.
Use simple decision tests:
- Scale when the primary outcome improves, quality and safety floors hold, economics remain acceptable, and the result repeats in the intended cohorts.
- Fix when the chain reveals a local weakness, such as adequate AI quality but low acceptance, or strong adoption but excessive rework.
- Hold when the evidence is inconclusive, the measurement is unreliable, or a guardrail is close enough to its limit that broader exposure would create avoidable risk.
- Stop when only proxy metrics improve, the target workflow does not change, or the value depends on manual intervention that cannot be sustained.
Use 90 days to prove the operating system
Your first 90 days should produce more than a working use case. They should leave behind a repeatable contract, event model, evaluation set, rollout path, governance record, and decision cadence that the next team can reuse.
- Weeks 1–2: choose the workflow. Audit available content and data, map the highest-value repeatable workflows, and select one where behavior and business impact can be observed. Write the outcome contract and assign decision rights.
- Weeks 3–4: define the evidence. Build the driver tree, establish the four-layer scorecard, create representative offline evaluations, classify risk, and document the release and stop conditions.
- Weeks 5–8: build and instrument. Create the retrieval and prompt baseline, capture lineage and version context, validate events, implement observability, and test graceful fallbacks. Rehearse how the team will diagnose a failed attempt.
- Weeks 9–12: release and learn. Ship behind a feature flag, begin with limited exposure, compare behavior and outcomes, inspect failure cohorts, and make explicit scale, fix, hold, or stop decisions.
At the end, ask for three forms of proof. Can the team explain which customer behavior changed? Can it connect that behavior to a workflow and business result without hand-waving? Can another team reuse the operating artifacts without rebuilding them from scratch?
If any answer is no, keep the rollout narrow and repair the system of learning. If all three are yes, fund the next workflow using the same operating model. The goal is not a larger collection of AI features. It is an organization that can turn uncertain AI capabilities into measurable outcomes, repeatedly and responsibly.
References
- Shivam.Consulting Blog — AI Operating Model Playbook: Why 80% Stall—and How the Top 1% Accelerate with Discipline
- Shivam.Consulting Blog — Turn Clicks into Revenue: How I Connect Behavior to Conversions with Persisted Properties
- Shivam.Consulting Blog — Building AI-Era GTM and Analytics That Make Tough Calls Simple: A Product Leader’s Playbook