If your company may pursue an IPO, the tempting move is to wait until the filing window is visible, then recruit executives who have done it before. That sequence solves for credentials. It does not necessarily build the decision system the business will need.
Figma took a different path. An operator who joined when the company had about 30 people and was not yet charging for its product grew into the CFO role, while the company adopted public-company habits years before its 2025 IPO. The useful lesson for you is not simply to promote insiders. It is to develop executive judgment, operating cadence, and economic instrumentation as one connected system.
Key takeaways: the playbook on one page
Expand a leader’s decision scope before expanding the title. Look for progression from doing the work, to framing the questions, to allocating resources, to improving decisions across the company.
Install public-company behaviors before the transaction demands them. Figma began operating this way three years before its IPO, using quarterly rhythms, tighter controls, a close that could withstand scrutiny, and a coherent forward-looking narrative.
Treat product, finance, and go-to-market as joint owners of the economic model. They need the same driver tree, definitions, telemetry, and assumptions before they debate pricing or investment.
Manage AI investment as a portfolio of explicit bets. Usage, customer value, cost-to-serve, decision triggers, and risks should be visible even when the underlying economics are changing quickly.
Use leadership transitions to redraw decision rights. Replacing a departing executive without reconsidering the operating model preserves yesterday’s bottlenecks.
Scale executive judgment before you scale titles
Praveer Melwani joined Figma in 2017 as its first business operations and finance hire. The company was still around 30 people and had not begun charging for the product. He became CFO in 2022 and helped lead the company through its IPO in 2025.
The important pattern is the sequence of work. Early responsibilities included building driver trees, challenging go-to-market assumptions, and establishing the mechanics of board management. Later responsibilities moved toward defining the questions the company needed to answer, directing capital, and shaping the operating cadence. The role grew because the decisions grew.
You can use that sequence as an executive-readiness ladder. It is more informative than tenure or the seniority of a candidate’s last title.
Executive mode
Work that demonstrates readiness
Failure signal to watch
Operator
Builds the model, tests assumptions, and makes the basic process reliable.
Produces accurate work but cannot explain which decision it should change.
Question-setter
Identifies the uncertainty that matters, frames options, and defines success.
Waits for the founder or another executive to determine what deserves attention.
Allocator
Connects product evidence, financial constraints, and strategic upside to resource choices.
Treats the budget as a fixed entitlement rather than a set of revisable bets.
System leader
Improves the cadence, decision rights, narrative, and judgment of the wider team.
Remains the indispensable reviewer for every important decision.
Do not promote someone merely because they are excellent in the first row. Give them work from the next row and observe what happens. Ask a strong operator to frame an ambiguous company problem, recommend where resources should move, document the trade-offs, and run the decision through the relevant functions. You are testing whether the person can create clarity beyond the boundaries of the original role.
I use a similar first-principles test when evaluating a prospective VP, especially in a function the founder does not know deeply:
Can the candidate map how the business creates and captures value?
Can they define success metrics and show where those metrics could mislead the team?
Can they explain a meaningful trade-off in plain language?
Can they describe the team and decision system they would build, rather than only the work they would personally perform?
Can they teach the executive team something useful in 30 minutes?
Run this test on your actual business context, not a generic case interview. A candidate who asks sharper questions, exposes a hidden assumption, and improves the decision has demonstrated more than someone who recites the standard playbook from a previous employer. Prior experience still matters, but learning velocity and expanding scope deserve more weight than familiarity alone.
Make IPO readiness a company cadence, not a finance workstream
Figma began behaving like a public company three years before its IPO. That is not a universal countdown for every company. The more important point is the order of operations: the habits came before the event that would test them.
Late preparation forces teams to create controls, reconcile definitions, improve forecasting, and construct a credible narrative while the stakes are already high. Early preparation turns the same work into ordinary management. It also reveals weak ownership and unreliable data while the company still has room to correct them.
Quarterly operating rhythm: Review changes in the business drivers, the assumptions behind the forecast, the resulting resource choices, and the risks that could alter the plan. A performance presentation without a decision is reporting, not an operating review.
Close and controls: Make ownership, evidence, access, and material judgments explicit. The goal is not bureaucracy for its own sake. It is to produce numbers that leaders can use without reopening the entire chain of custody every time.
Forward-looking narrative: Connect past performance to the decisions now being made. Explain what changed, why management believes it changed, what will be done next, and what evidence would invalidate that view.
Decision record: Preserve the assumptions, alternatives, owner, and follow-up trigger behind a material choice. This prevents the company from rewriting the reasoning after the outcome is known.
This discipline can accelerate decisions because product, finance, and go-to-market stop renegotiating the basic facts in every meeting. Product brings evidence about behavior and roadmap alternatives. Finance brings the model, sensitivities, and constraints. Go-to-market brings customer context, commercial implications, and execution dependencies. The executive owner makes the cross-company choice and records what would cause it to change.
A useful quarterly decision packet should answer the following questions:
Most teams ship AI agent personalities by accident—emergent quirks, brittle prompts, and uneven behavior. We refused to let that happen. From day one, we treated personality as a first-class product surface, one that should be designed, instrumented, and iterated with the same rigor as any core capability.
Learn how we designed Global Agent’s personality and fine-tuned its inquisitiveness and helpfulness using Agent Analytics.
In my role leading product at HighLevel, Inc., I framed our approach around agentic AI and conversation design: personality is not “flavor text”; it is the control system for how an agent interprets context, asks questions, and decides when to act. Our product strategy prioritized clarity, empathy, and consistency—so the agent would be curious enough to resolve ambiguity without becoming interrogatory, and helpful enough to move work forward without overstepping.
We made that intent measurable. Using behavioral analytics, we defined operational signals such as clarification-question rate, resolution-path efficiency, and escalation quality. We combined eval-driven development with targeted A/B testing to compare prompt patterns and tool strategies, ensuring each change had a clear hypothesis and measurable outcome.
To calibrate inquisitiveness, we mapped decision points where the agent should ask follow-ups versus proceed autonomously. Prompt engineering codified those thresholds, while a retrieval-first pipeline reduced unnecessary questions by improving context completeness up front. When the agent did ask, we constrained tone and cadence to keep queries concise, respectful, and progress-oriented.
To enhance helpfulness, we prioritized precise action-taking and unambiguous guidance. Context window management preserved relevant facts without diluting intent, and guardrails aligned with AI risk management principles ensured the agent stayed within policy, privacy, and compliance boundaries. The result was an assistant that resolved more tasks end-to-end, with fewer stalls and clearer handoffs when human help was warranted.
Agent Analytics became our nervous system. We instrumented every dialog turn to attribute outcomes to design choices, then used driver trees to connect micro-behaviors to macro results like time-to-resolution and customer satisfaction. This closed-loop view let us ship confidently, knowing which levers improved helpfulness, which sharpened curiosity, and which merely added noise.
Process mattered as much as tooling. Product trios ran continuous discovery with customers to surface edge cases—ambiguous intents, multi-intent turns, and sensitive scenarios—while our engineering partners operationalized experiments with clean rollback paths. We favored small, testable changes over sweeping rewrites, building momentum and trust with each iteration.
The payoff is a personality that feels consistent across use cases: curious when clarity is missing, decisive when action is obvious, and transparent when limits are reached. Users experience fewer dead ends, faster resolutions, and a brand voice that shows up the same way every time—because it was defined, measured, and improved on purpose.
If you’re building agentic AI, don’t leave personality to chance. Treat it like a product: set clear outcomes, instrument deeply with Agent Analytics, and iterate with eval-driven development and A/B testing. That’s how curiosity becomes a feature, helpfulness becomes a habit, and your agent becomes reliably, intentionally excellent.
Inspired by this post on Amplitude – Best Practices.
Your AI sales agent answers the pricing question, then recommends the wrong plan. It identifies a promising buyer, then sends the conversation to the wrong queue. If the underlying facts, decision rules, or routing policy are missing, another prompt adjustment cannot fix the problem.
You need a knowledge operating system, not a larger folder of sales collateral. The goal is to give the agent the smallest reliable path from a buyer’s question to an accurate answer, an appropriate recommendation, useful qualification, and the correct next step.
Key takeaways
Separate product facts, decision guidance, and execution policy. Each solves a different part of the sales conversation.
Turn long documents into focused, approved knowledge records with an owner, scope, effective date, and explicit boundaries.
Launch a complete sales motion for a narrow set of buyer intents before trying to document everything.
Test recommendations, qualification, routing, and escalation behavior, not just whether the agent can repeat a correct sentence.
Convert unanswered, incorrect, and disengaged conversations into a managed improvement queue.
Design for answering, recommending, qualifying, and routing
A conventional knowledge base helps someone find information. An AI sales agent has a harder job: it must interpret a buyer’s situation and decide what to do with the information it retrieves.
A language model does not inherently know your current plans, qualification criteria, commercial boundaries, or customer-specific use cases. That context is unique to your business and must be made explicit. Fluency cannot compensate for a missing policy.
I find it useful to divide sales knowledge into three layers:
Knowledge layer
What it contains
What the agent should do with it
Typical failure when it is missing
Product facts
Pricing, plan structure, capabilities, limitations, availability, and supported use cases
Give a direct, accurate answer
The agent guesses, gives a vague response, or repeats obsolete information
Decision guidance
Plan-fit logic, relevant constraints, case studies, approved comparisons, and the context behind product facts
Explain which option fits and why
The answer is technically correct but does not help the buyer decide
Execution policy
Qualification questions, required fields, routing conditions, escalation rules, and actions the agent may take
Advance the conversation within defined authority
The agent collects irrelevant details, makes an unsupported commitment, or routes the buyer incorrectly
Facts answer, “What does the product do?” Decision guidance answers, “Is this appropriate for my situation?” Execution policy answers, “What should happen next?” Audit your knowledge against all three questions.
Set a hard boundary around commercial exceptions. The agent should not infer an unlisted discount, invent a contractual commitment, or turn an internal hypothesis into a buyer-facing claim. It should state the approved terms, gather the information required by policy, and route the exception to an authorized person. A plausible but unauthorized promise can create financial and legal exposure.
Turn scattered documents into governed knowledge
Build sales-ready knowledge records
A long document can be correct and still be poor input for an agent. Pricing may be buried below an obsolete introduction. A feature table may omit the condition that changes plan fit. A battlecard may combine approved facts with a rep’s unverified notes.
Convert those documents into focused records. Each record should cover one buyer intent or one tightly related decision. Use a consistent template:
Buyer intent: The question or decision this record addresses, including common alternative phrasings.
Approved answer: The direct response the agent may give without qualification.
Decision context: Why the fact matters and when it changes the recommendation.
Constraints and exceptions: What the answer does not cover, including conditions that require clarification.
Next question or action: The appropriate follow-up, qualification step, route, or escalation.
Scope: The plans, markets, customer types, channels, or agents allowed to use the record.
Evidence location: The canonical product, pricing, or policy record from which the answer was derived.
Owner and approver: The people accountable for accuracy and authorization.
Lifecycle metadata: Effective date, review status, and whether the record replaces an earlier version.
For example, a record about plan fit should not stop after naming a plan. It should state the relevant requirement, identify the condition that changes the answer, give the agent an approved follow-up question, and define where to route a buyer whose situation falls outside the standard policy. The recommendation then becomes reproducible rather than improvised.
Keep buyer language in the record. Prospects rarely use your internal taxonomy, and the same intent may appear as a product question, an outcome question, or a comparison. Alternative phrasing helps the retrieval layer recognize that these expressions belong to the same approved answer.
Create an authority hierarchy
A centralized repository is valuable only if the agent can distinguish current authority from historical residue. Define the hierarchy before connecting more content:
Designate one canonical record for each product fact, commercial rule, or routing policy.
Make approved sales explanations point back to that record rather than becoming independent versions of the truth.
Treat scripts and examples as phrasing aids unless they are explicitly approved to carry facts.
Keep drafts, call notes, chat fragments, and retired material outside the agent’s usable knowledge until they are reviewed.
Do not let the agent reconcile conflicting records by choosing the newest upload or blending the language. When two approved items disagree, the safe behavior is to withhold the disputed claim, follow the defined escalation path, and send the conflict to its owner.
Ownership should also be specific. A knowledge owner maintains the record. A domain approver authorizes sensitive claims. An operations owner monitors how the agent uses the record in conversations. One person may hold more than one role, but every role needs a name rather than a department-shaped placeholder.
Target knowledge by audience and action
Internal knowledge is not automatically buyer-facing knowledge. A qualification score may guide routing without being disclosed. A battlecard may help frame an approved comparison without exposing internal commentary. A security question may require an authorized answer rather than the agent’s summary of a sales note.
Mark each record as buyer-answerable, decision-only, action-only, or restricted. Then expose only the appropriate material to each agent, channel, market, and sales motion. This kind of centralization and content targeting reduces duplication while keeping internal policy separate from the words a prospect sees.
Launch the smallest complete sales motion
Trying to clean every sales document before launch creates a long project with no conversational evidence. Launching with disconnected FAQs creates a different failure: the agent answers isolated questions but cannot move the buyer forward.
The better unit of scope is a complete motion for a bounded set of intents. For each selected intent, the agent needs an answer, the relevant fit logic, the next qualification question, a route or resolution, and an escalation path.
Prioritize by demand and consequence
Start with questions that appear repeatedly, delay buyers, consume sales time, signal meaningful intent, or cause material damage when answered incorrectly. Pricing, plan differences, core capabilities, common use cases, qualification, and routing are natural candidates when they dominate your actual inbound conversations.
Two simple calculations help quantify repetitive work: team time reclaimed = average response composition time x question frequency, while buyer wait avoided = number of prospects asking x average response time. These calculations are useful for prioritizing knowledge work, but neither should be presented as revenue without downstream evidence.
Add consequence to the ranking. A frequent low-risk question may save time, but an infrequent error involving price, eligibility, security, or a contractual promise may deserve earlier treatment. Frequency tells you where the volume is. Consequence tells you where control matters.
Your initial release is ready when the selected motion has:
Approved answers for the recurring and commercially important questions in scope.
Plan-fit or use-case guidance where the buyer needs a recommendation rather than a fact.
Explicit qualification fields and follow-up questions.
Routing rules for the standard paths.
A visible no-answer and human-escalation path.
Owners and lifecycle metadata for every active record.
A representative evaluation set based on real buyer language.
Test the conversation, not the sentence
A retrieval test can show that the right paragraph was found. It cannot show that the agent asked the necessary follow-up, respected a restriction, or routed the lead correctly. Evaluate the complete interaction.
Your test set should include direct questions, paraphrases, multi-part questions, ambiguous requests, outdated assumptions, missing qualification details, requests for exceptions, and scenarios that should be escalated. For each case, check:
Is every factual claim aligned with approved knowledge?
Does the response answer the buyer’s actual question before adding detail?
Does the recommendation apply the right conditions rather than matching a keyword?
Does the agent ask only for information required by the qualification policy?
Does it avoid unsupported commitments and internal-only language?
Does the final route or escalation match the execution rule?
Record pass or fail at the behavior level and attach a reason to every failure. Do not allow a strong average score to conceal a severe pricing or policy error. High-consequence failures should block that behavior from release until the knowledge or policy is corrected.
Use a controlled launch with an obvious human path. The point is to begin collecting real conversational evidence early, not to claim autonomy before the boundaries are reliable. Fast deployment and continuous iteration work when the feedback loop is designed before traffic arrives.
Run the knowledge flywheel from real conversations
Once the agent is live, conversation failures become your most useful knowledge backlog. Do not place every poor result under a generic label such as bad answer. Classify the mechanism so the right owner can fix it.
Coverage gap: No approved record addresses the buyer’s intent.
Retrieval failure: The right knowledge exists, but the wrong record was selected or the right one was missed.
Freshness failure: The agent used information that should have been replaced or retired.
Guidance failure: The fact was correct, but the recommendation ignored relevant context.
Qualification failure: The agent skipped a required question, collected unnecessary information, or misread the answer.
Routing failure: The collected information was correct, but the next action did not follow policy.
Boundary failure: The agent disclosed restricted material or made an unauthorized claim.
Conversation failure: The content was accurate, but the response was unclear, repetitive, or poorly sequenced.
Turn each confirmed failure into a work item containing the conversation, intent, root cause, affected knowledge record, accountable owner, proposed change, and regression test. A change is not complete when the wording is edited. It is complete when the test passes, the approved version is published, and conflicting text is retired.
Track a small set of operational signals that lead to decisions:
Signal
What it tells you
What to do with it
Coverage
Which eligible buyer intents have an approved answer and action path
Add knowledge where demand and consequence justify it
Reviewed correctness
Whether sampled claims match the approved record
Repair facts, retrieval, or response generation
Knowledge conflicts
Where active records disagree or overlap ambiguously
Resolve authority and retire obsolete material
Qualification completion
Whether required information was collected for eligible conversations
Improve questions, field definitions, or sequencing
Routing compliance
Whether the next action matched the approved rule
Correct policy logic or integrations
Buyer progression
Whether the conversation reached its intended next step
Inspect guidance and friction, then validate changes against downstream outcomes
Content health
Which active records lack an owner, approval, scope, or lifecycle status
Repair governance before stale content becomes a live failure
Review these signals by intent and sales path. A global average can look acceptable while one plan, market, or routing branch fails repeatedly. Conversion can be a useful downstream outcome, but it is not proof that a knowledge change caused the result. Traffic mix, offer changes, seasonality, and human follow-up can also move it. Use controlled comparisons where practical and pair outcome data with conversation-level review.
Reserve a recurring weekly block for unanswered questions, disengaged prospects, high-consequence errors, and unresolved conflicts. Process pricing, product, and policy changes as immediate knowledge events rather than waiting for the review block. This is where knowledge management becomes an operating responsibility instead of a cleanup project.
Start with your recent inbound conversations. Choose the most repeated unanswered question, the most consequential incorrect answer, and one routing failure. Convert each into an owned knowledge record, add a regression test, and release only the behavior that passes. That small loop is the foundation of a sales agent you can trust with progressively more of the funnel.
I spent a week pointing a "Ralph Wiggum loop" at my product to see how far an agentic AI could take pragmatic, everyday improvements without human micromanagement. It was equal parts exhilarating and nerve-wracking. The short version: the loop moved fast and broke assumptions, but Amplitude analytics kept it from going off the rails—and turned chaos into controlled acceleration.
By "Ralph Wiggum loop," I mean a deliberately naive, endlessly curious cycle: try something small, ship it behind a flag, watch the data, then try again. It is the product equivalent of a fearless intern who experiments constantly. That energy is invaluable for discovery, but it absolutely demands strong guardrails and a clear definition of success.
Before I started, I framed the outcomes I cared about: user activation within the first session, reduction in time-to-value, and early retention indicators. I set baselines and a minimum detectable effect (MDE) for A/B testing so the loop could distinguish noise from signal. I also documented a driver tree of behaviors we wanted to influence and ensured every event was cleanly instrumented in Amplitude analytics to support reliable behavioral analytics.
The guardrails mattered most. I put every change behind feature flags with instant rollback. I defined "off the rails" conditions upfront, including regression thresholds for activation and retention analysis, and enabled anomaly detection to surface unexpected spikes or drops. Session replay was ready to diagnose confusion fast, and I kept a daily evaluation cadence so the loop never ran unattended for long.
Day by day, the loop proposed micro-experiments: onboarding copy variants, tooltip timing, in-app guide sequencing, and subtle changes to progressive disclosure. Each iteration shipped behind a flag to a small cohort. I watched leading indicators in real time, then zoomed out to cohort views to guard against short-term gains that might erode longer-term value. When something looked promising, we expanded exposure methodically; when something looked risky, we paused immediately.
We had a pivotal moment where the loop suggested a bolder call-to-action that spiked activation. On the surface, it looked like a win. Amplitude cohorts told a fuller story: downstream engagement softened, and anomaly detection flagged a pattern that hinted at premature conversion rather than genuine intent. A quick rollback through feature flags saved the week—and reminded me why eval-driven development should be the default for agentic AI workflows.
The most surprising part was how quickly the loop unlocked small compounding gains once the measurement scaffolding was in place. With a unified analytics platform and crisp guardrails, the system became a safe sandbox where the AI could explore aggressively while we stayed anchored to outcomes. The combination of behavioral analytics, A/B testing discipline, and daily human review turned raw speed into durable learning.
My takeaways are direct. Agentic AI can accelerate discovery, but only if you define stop conditions and wire strict feedback loops into your stack. Measurement is product strategy here—without it, you get noisy activity instead of progress. Invest in instrumentation first, treat feature flags as non-negotiable, and let anomaly detection and session replay be your early warning system. Most of all, tie every experiment to activation, engagement, or retention, not vanity metrics.
If you’re considering your own week with a "Ralph Wiggum loop," start painfully small, constrain the blast radius, and insist on decision-quality data. Do that, and you’ll turn a chaotic agent into a compounding engine for product discovery—one that moves fast, learns faster, and stays on track.
Inspired by this post on Amplitude – Perspectives.
When I consider where product development is headed, one statement captures the mandate perfectly: "Eric Carlson is a Principal AI Engineer helping to shape and build Amplitude's next generation vision of of agentic and data driven product development." That vision resonates deeply with how I lead teams—anchoring strategy in behavioral analytics while enabling agentic AI to act on insights with speed, safety, and measurable impact.
Translating that vision into execution starts with clarity of outcomes. I frame driver trees that connect customer value to leading indicators—activation, engagement depth, and retention—then instrument product telemetry with Amplitude analytics and behavioral analytics to surface the moments that matter. From there, we operationalize learning with A/B testing and feature flags, ensuring each hypothesis gets a fair, observable run and that we can safely ramp what works.
Agentic AI changes the operating model. Instead of static dashboards, we design autonomous workflows that observe signals, reason over context, and take action—grounded in a retrieval-first pipeline and governed by eval-driven development. For product managers, this demands fluency with LLMs for product managers and practical prompt engineering, plus rigorous AI Strategy around data governance, privacy-by-design, and risk scoring so agents remain trustworthy under real-world conditions.
Cross-functional cadence is everything. I partner closely with Principal AI Engineers and product trios to blend continuous discovery with execution: rapid user interviews to reveal intent, opportunity solution trees to prioritize, and outcomes vs output OKRs to align incentives. The result is a system where insights are unified, decisions are explainable, and agents improve through tight feedback loops across analytics, experimentation, and production telemetry.
If you’re building toward an agentic, data-driven future, invest in a unified analytics platform, shorten the path from signal to action, and measure learning velocity as carefully as feature delivery. With the right foundations, agentic AI becomes more than a feature—it becomes a force multiplier for product strategy, customer value, and sustainable growth.
Inspired by this post on Amplitude – Perspectives.
I just wrapped an all-out engineering sprint. That still sounds odd coming from me, because while I’ve written code on and off for years, I don’t self-identify as an engineer. I’m a product manager who used to be a designer. It’s been a long time since I wrote code for a living.
But AI has expanded what’s just now possible—for our products, and for us. It’s pushed me to do more than I imagined. In that spirit, I want to share a recent engineering story. It includes technical details, and a year ago I couldn’t have done any of it. I learned it with the help of AI, and my aim is to show what’s now within reach.
I’ve been building two services with a partner at Vistaly: AI-generated interview snapshots and AI-generated opportunity solution trees. We put out a call for alpha partners, received over 100 applicants, and selected eight design partners to start.
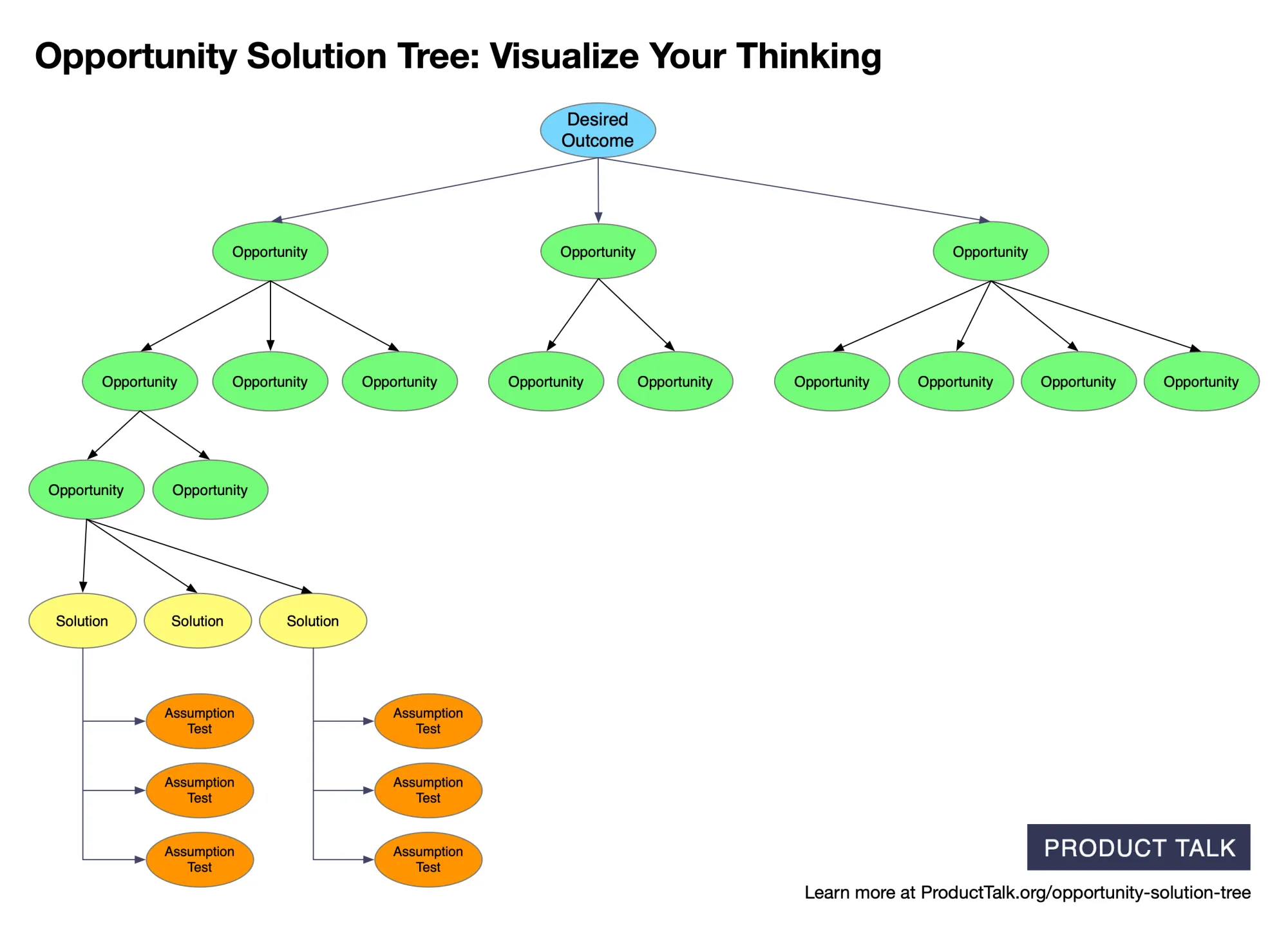
A clear, color‑coded map from desired outcome to opportunities, solutions, and assumption tests—showing how to structure discovery work and prompt AI to generate, compare, and validate product ideas.
Each team uploaded three customer interviews. I identified the key moments and opportunities and then generated an opportunity solution tree from those snapshots. I provide the AI services; Vistaly is building the UI and workflows around them.
Early feedback was strong. Teams immediately asked to upload more interviews—exactly the kind of demand signal you hope to see—so we got to work making that possible.
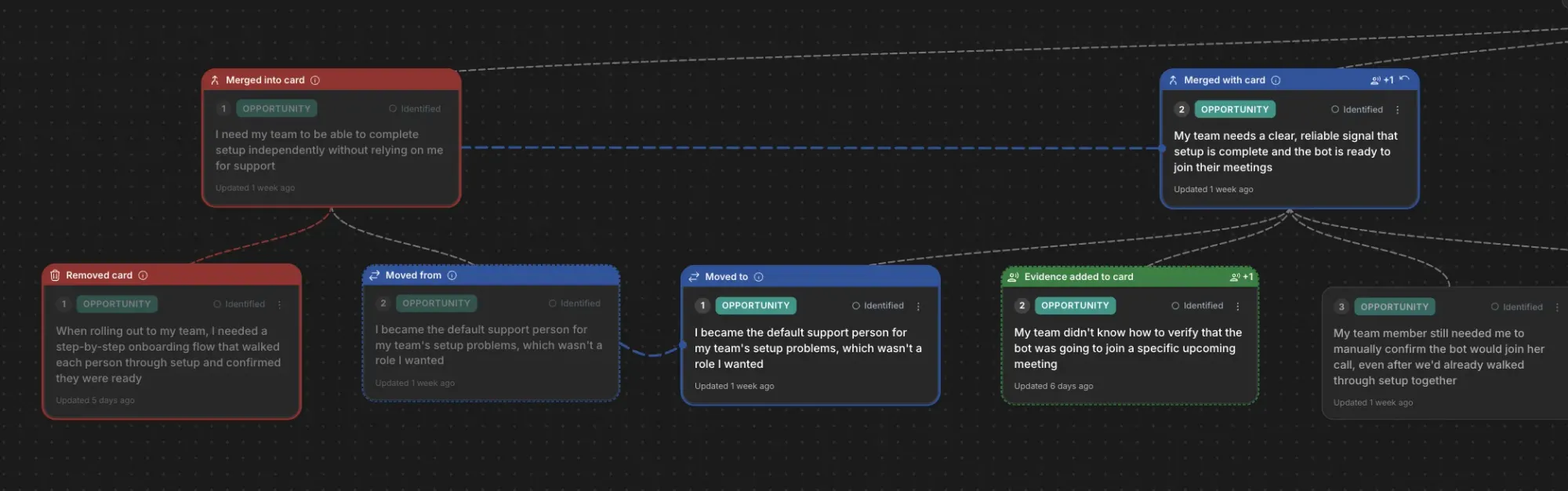
Go behind the scenes as AI turns raw feedback into a clear Opportunity Solution Tree. Linked cards reveal user needs—onboarding, support offload, and bot-readiness signals—so product teams can spot priorities and next steps at a glance.
Updating an opportunity solution tree with new interview content is far harder than generating a new tree from scratch. I initially underestimated the complexity. Our goal wasn’t to produce a tree and declare it truth. We wanted teams to engage, correct, and collaborate with the AI—scaffolding cross-interview synthesis instead of doing it for them.
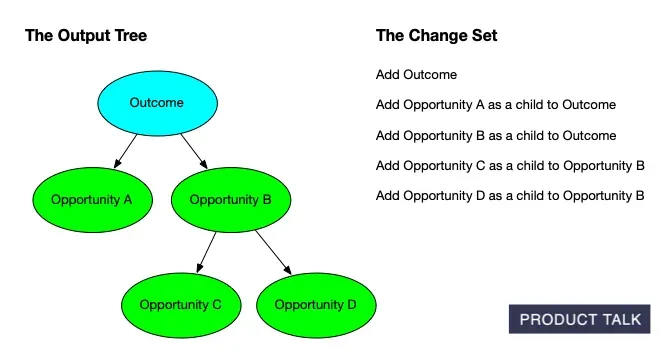
To support that, we needed a way to communicate precisely how a tree would change after new interviews were added. We took inspiration from git diff and set out to build the equivalent for opportunity solution trees—step-by-step change sets that explain each proposed modification.
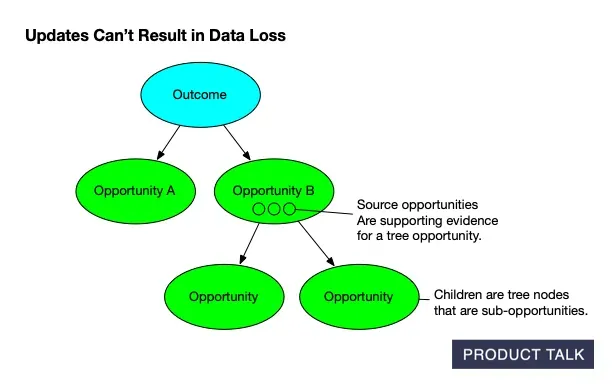
A clear visual of AI‑generated opportunity solution trees: outcomes feed opportunities that branch into sub‑opportunities, while evidence is preserved. The structure ensures updates stay traceable and never cause data loss.
That decision was right, but the lift was larger than I expected. It wasn’t enough to generate an updated tree; I also had to provide a clear, ordered walkthrough of what changed and why.
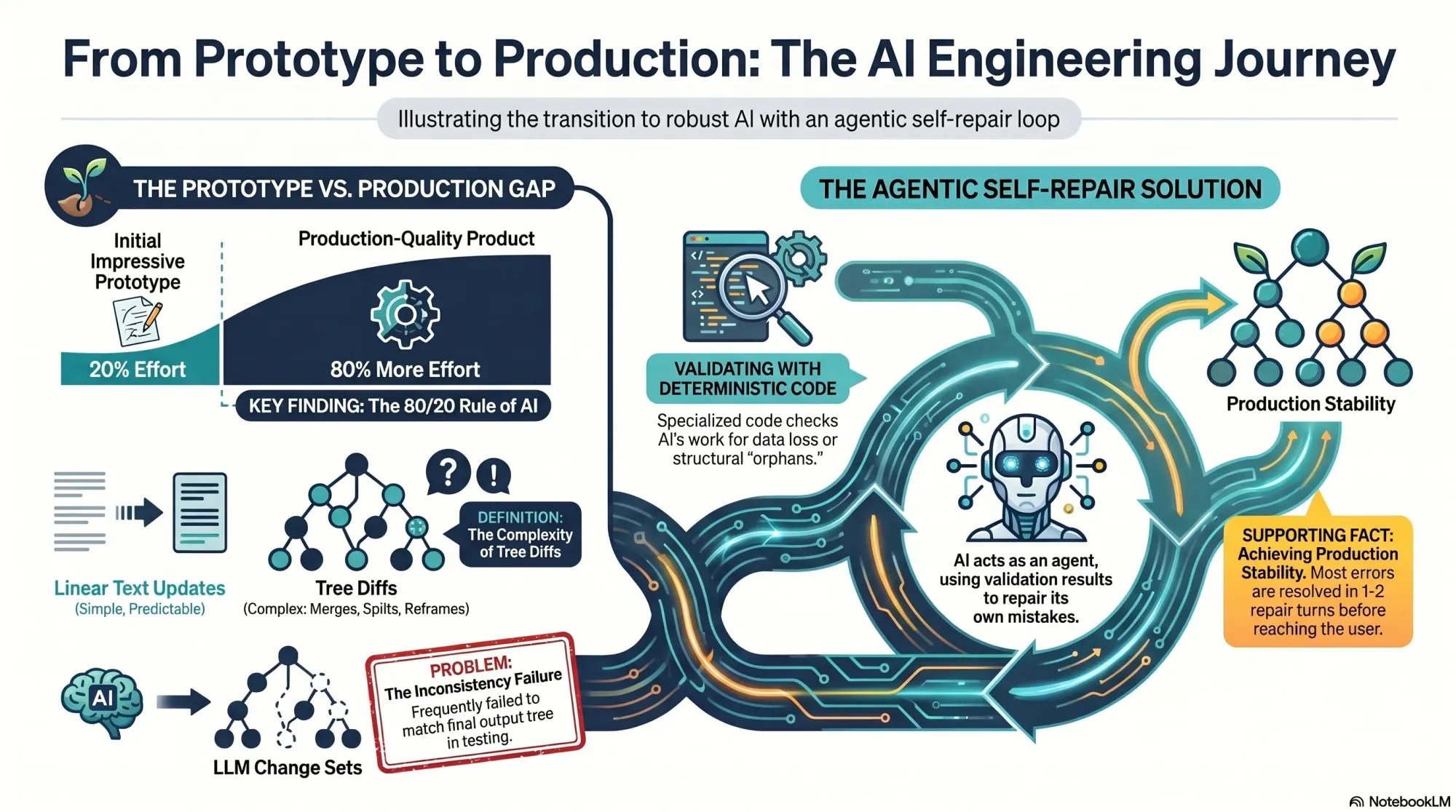
I often see the same pattern with AI: it’s easy to get to an impressive prototype, but much harder to reach a production-grade product. That was exactly my experience here. My service actually comprised two sub-services: generating a new tree from scratch and updating an existing tree with new interviews. The first worked well in alpha; the second had to be built before anyone could add a fourth interview.
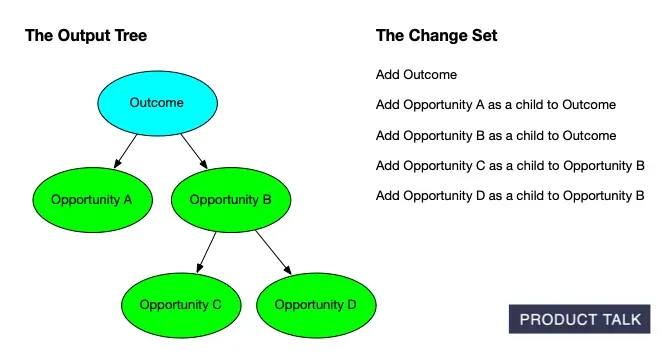
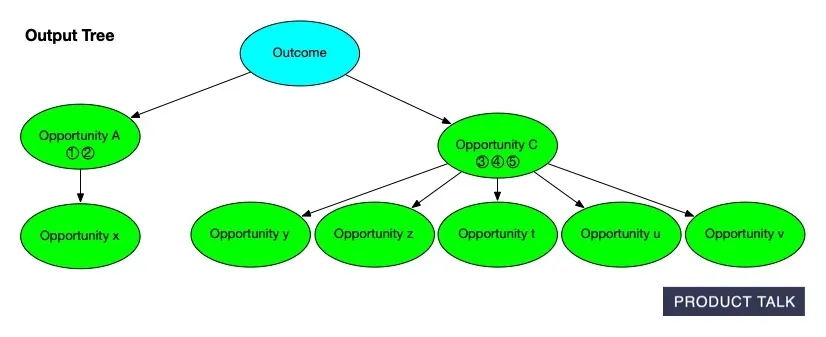
Explore how an outcome expands into an Opportunity Solution Tree: Opportunities A and B stem from the goal, with C and D nested under B, while a concise change set tracks every node added along the way.
On the surface, these services look similar. In reality, updates must preserve existing structure unless new evidence requires a change. You have to account for compound operations—merges, splits, deletes—while guaranteeing no data loss. Every node has source opportunities (supporting evidence from interviews) and children (tree sub-opportunities), and neither can be dropped.
In classic AI fashion, I got a reasonable version working in a few days and shipped it to our design partners. One team quickly hit our beta limits and asked to convert to a paid subscription so they could keep going. They showed a willingness to pay, converted, and started uploading aggressively.
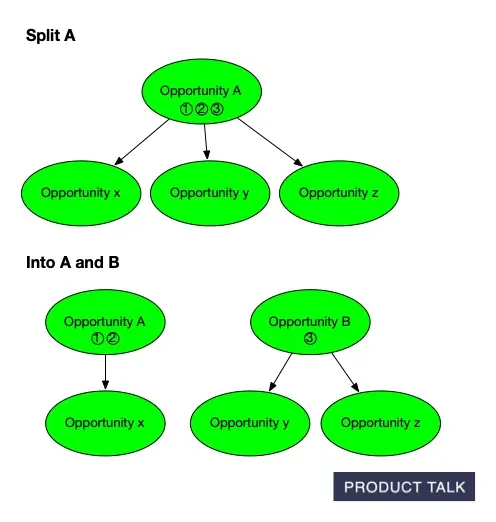
Watch an Opportunity Solution Tree evolve: the original parent A with x, y, z branches is split into A and B, shifting evidence while preserving links—mirroring how AI refines scope and structure in discovery.
At the 14th, 15th, and 16th uploads, the cracks appeared. We saw odd behavior in some trees. The Vistaly team noticed that the change sets—the step-by-step instructions emitted by my service—didn’t always reconstruct the final tree my service also emitted. We needed those steps to match exactly, so teams could review and accept, modify, or reject each change with confidence.
They flagged the issue the day I was flying to New Orleans for Jazz Fest. In hindsight, I’m glad I didn’t grasp the scope of what awaited me. I had roughly 80% of the work still to do to make tree updates rock solid. At least I got to enjoy the music first.
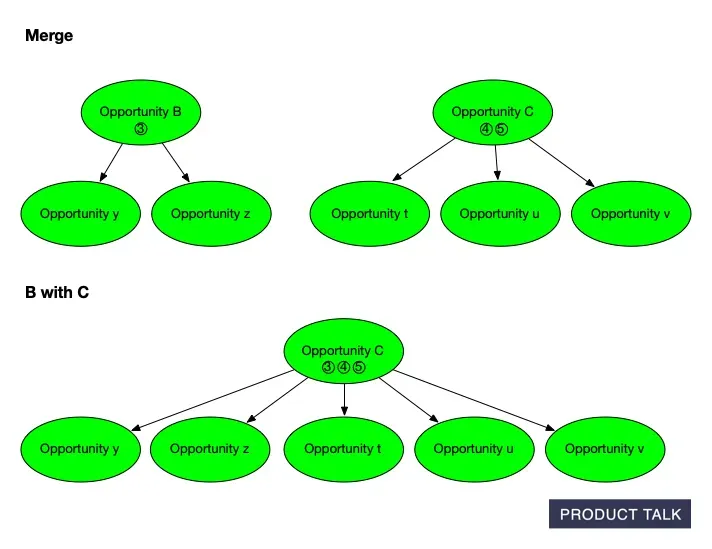
From fragments to focus: this diagram shows how Opportunities B and C are merged into a single Opportunity Solution Tree, removing duplicates and unifying context so AI can rank and explore five related opportunities with clarity.
Back home, I started diagnosing. My service was a pipeline: several LLM-driven steps followed by deterministic code to compare trees and produce change sets. As I dug in, I realized that approach was flawed. Tree diffs, unlike linear document diffs, are ambiguous.
In a document, if I add a sentence, the diff shows an addition. If I delete a paragraph and rewrite it, the diff shows a removal and an addition. Simple. But trees are different. Suppose I split opportunity A into A and B, and later merge B with C. The split can disappear from the final diff.
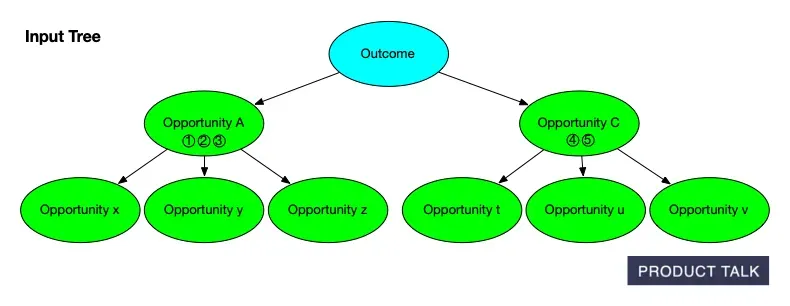
Peek inside our process: a simple opportunity solution tree maps an outcome to prioritized opportunities A and C with downstream options x-z and t-v. A clear snapshot of how AI organizes product discovery.
When the model splits an opportunity, it must distribute A’s source opportunities and children between A and B. For instance, if A has source opportunities 1, 2, 3 and children x, y, z, after the split A might keep 1, 2, and x, while B takes 3, y, and z.
Now suppose the model merges B into C. If C originally had source opportunities 4 and 5 and children t, u, v, then after the merge C now has source opportunities 3, 4, 5 and children t, u, v, y, z. When you compare the original and final trees, it looks like A somehow donated some evidence and children directly to C. The split and merge that explain why are invisible to a naive diff.
See how an AI-generated Opportunity Solution Tree unfolds: one Outcome flows to Opportunities A and C, then into options x–v. Clean colors and arrows reveal the hierarchy from goal to opportunities at a glance.
That was the core insight: we didn’t just need to show what changed—we needed to show why it changed. I had to reconstruct each move step-by-step. That meant getting the model to show its work, which opened a new can of worms.
I refactored my prompts so the model produced both the final output and the exact change set it used to get there. The action language was explicit: add, delete, reframe, merge, split, and so on. Crucially, I asked the model to describe its moves in user-meaningful terms—“split A into A and B, then merge B into C”—not as opaque reassignments of sources and children.
Watch an opportunity solution tree take shape: start with the outcome, add opportunities A and B, then extend B to C and D. The paired change set makes every edit transparent—ideal for AI-assisted product discovery.
For each LLM step, the model now emitted its recommendation and the corresponding change set. This helped, but it wasn’t perfect. After extensive testing and error analysis, two classes of errors emerged: (1) the model attempted an invalid move, and (2) the change set didn’t actually generate the recommendation.
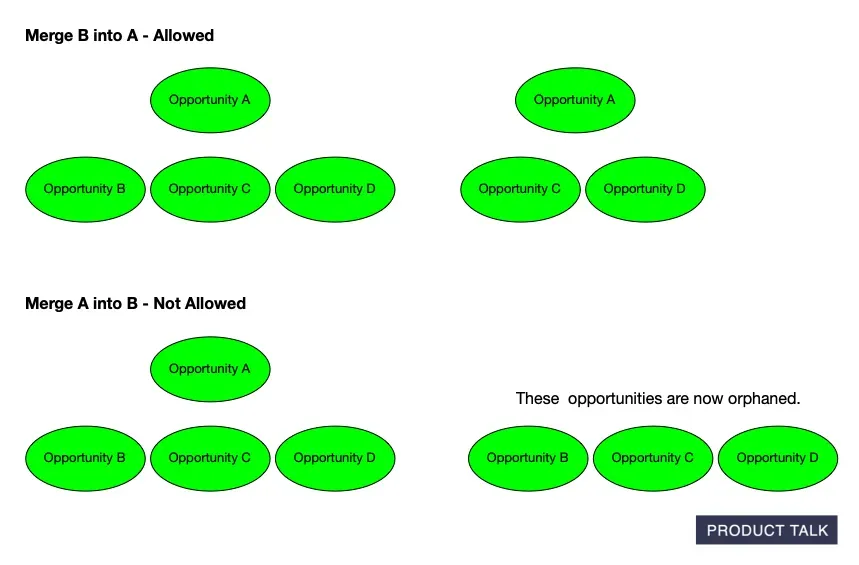
Category 1 felt like designing a game while the model played it creatively. For example, what happens when the model tries to merge a parent with a child? If opportunity A has children B, C, and D and the model merges A with B, the merge is directional. If the instruction is “keep A, delete B,” that works—the parent absorbs the child. But if the instruction is “keep B, delete A,” then C and D become orphans. These puzzles were solvable and even fun.
Visual explainer from Product Talk on AI-generated Opportunity Solution Trees. It contrasts an allowed merge (B into A) with a not-allowed merge (A into B) that leaves child opportunities orphaned, guiding safe hierarchy edits.
Category 2 was harder. Despite prompt iterations, I could only push the discrepancy rate down to about 1 in 40 instances. With 10–20 LLM calls per run, that meant roughly half of all runs still failed. Not acceptable for production. I hit a wall. A paying customer was waiting, and more design partners were queued up.
Next, I tried to correct the model’s mistakes with deterministic code. I had promised that my change sets would generate the output tree, so I wrote verifiers: detect conflicts (e.g., delete a node, then try to use it later), guard against data loss, prevent orphaned nodes, and more. Detection was straightforward; correction was not. Fixing issues required guessing the model’s intent. If the sequence said “delete A, then merge A with B,” should I remove A entirely or salvage A’s sources and children by merging into B? There were dozens of such cases with no unambiguous answer.
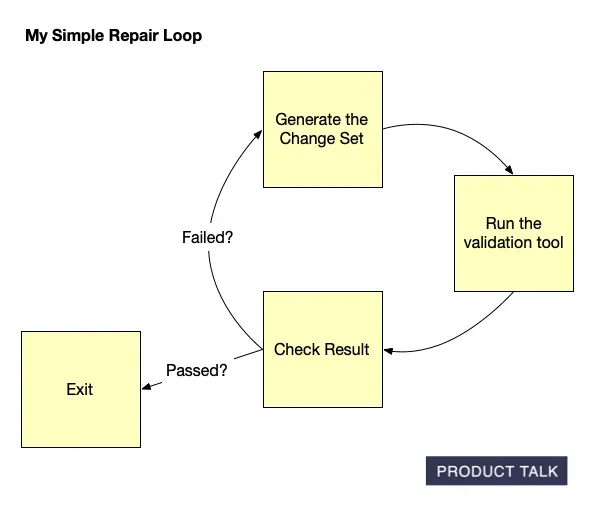
A step-by-step loop shows how changes are validated: generate a change set, run a validation tool, review the result, then repeat on failure and exit on pass—mirroring iterative work behind AI-built Opportunity Solution Trees.
After 11 straight days of deep work—including weekends—I was exhausted. I dislike hustle culture; this isn’t how I design my life. But I was stuck, and then I had an insight.
On a walk with my husband (also an engineer), I realized I could have the LLM repair its own mistakes. My data contract with Vistaly requires that the change set must generate the output tree. I had already built robust validation code. I knew exactly when a change set failed—and why. No amount of prompt tuning alone was fixing it. So I turned the validator into a tool for the model and created a simple agentic loop.
The loop works like this: the model proposes a change set, calls the validation tool, and gets back a pass/fail plus specific feedback. If it fails, the model uses those instructions to repair the change set and calls the tool again. Iterate until success or a max number of turns.
I prototyped in Node.js with a single model call, a verifier pass, and a repair attempt. At first, the loop didn’t converge—it just accumulated compute. I experimented with how to communicate errors, how much context to include, and how to sequence feedback. Eventually, it clicked: the model began fixing its own mistakes and typically returned a valid change set in one or two repairs. It was, in practice, eval-driven development applied to LLM outputs.
I had already built an agent loop utility for another AI workflow, so I productionized quickly: model call, optional tool invocation, tool result returned to the model, repeat until the validator signals success or the loop times out. I integrated the new loop into the pipeline and shipped the revamped service to Vistaly on Monday at noon. They’re integrating now, and it will be in the hands of our design partners shortly. I’m relieved—and ready for a day off.
Reflecting on the last two weeks, a few things stand out. First, I shed limiting beliefs about being an engineer. To make this reliable, I had to solve legitimately hard problems, and that feels good.
Second, this was genuinely fun. Designing the action set and watching the model push those boundaries was like working through elegant puzzles. Models are incredibly creative, and harnessing that creativity with the right constraints is deeply satisfying.
Third, I learned when I can and can’t trust Claude to write code for me. Since Opus 4.6 came out, I gave Claude a much longer leash. After the past two weeks, Claude is back on a short leash. I found a lot of gaps in my implementation in areas where I simply trusted that Claude got it right, when in fact it didn’t. If you don’t have the right infrastructure—planning, testing, code review—this can be disastrous. I’ll be investing more here and sharing what I learn.
Finally, if this work had been spread over two months, it would have been thoroughly enjoyable. I’m discovering how much I like being an AI engineer. It feels like a new chapter where I can combine opportunity solution trees with modern AI engineering—and deliver real value to product teams doing continuous discovery.
I’m excited to share more of what we’re building with Vistaly and to onboard more design partners soon. If you’re interested, get on the waiting list. And if you’ve been hesitant to stretch beyond your current skill set, I hope this story nudges you to take the first small step toward what’s just now possible.
You can get an AI model to produce a roadmap in minutes. That is precisely the problem. A polished roadmap can hide weak evidence, unresolved trade-offs, and a strategy that never made a real choice.
The useful question is not whether AI can do product management work. It is where AI should accelerate the path from evidence to decision, where human judgment must remain explicit, and how you will know the resulting strategy is working. The operating system below gives you that separation.
Key takeaways
Give AI a defined role in the decision process. It can extract, organize, challenge, and draft; the product leader still owns choices, trade-offs, and commitments.
Build a strategy chain from customer problem to business result before asking AI for initiatives. Otherwise, the model will fill strategic gaps with plausible language.
Ground every workflow in canonical product context, and require every important claim to point back to evidence.
Use AI to shorten discovery synthesis, not to turn a limited set of interviews or support conversations into false market certainty.
Carry the same strategic hypothesis through the roadmap, experiment, launch, and learning review. Changing the success definition between those stages makes measurement meaningless.
Start with decision architecture, not a better prompt
Most weak AI-assisted strategy work begins with an underspecified request: analyze this feedback, prioritize these ideas, or build a roadmap. The model responds by making silent assumptions about the customer, the business objective, and the meaning of priority. Its output may read well while answering a question nobody deliberately chose.
Write a decision brief before opening the model. This is not a conventional product requirements document. It is a compact contract defining the decision AI is helping you make.
Decision: State the choice in one sentence. For example, decide which onboarding opportunity deserves discovery capacity in the next planning cycle.
Target customer and context: Name the segment, job, and situation. Feedback from an administrator configuring an account should not be blended with feedback from an end user completing a daily task.
Desired outcome: Identify the customer behavior you want to change and the business result it is expected to influence.
Evidence in scope: List the interviews, behavioral data, support conversations, journey maps, and prior experiments the model may use.
Constraints: Include privacy requirements, technical dependencies, commercial commitments, capacity limits, and non-goals.
Decision owner: Name the person accountable for accepting the trade-off. An AI-generated recommendation does not distribute accountability.
Build a strategy chain the model can inspect
Your strategy should form a traceable chain:
Choose the customer and job that matter.
Define the value proposition, including what must match the market and what should be meaningfully different.
Name the customer outcome and business outcome.
Break that outcome into drivers the product can influence.
Select an opportunity supported by evidence.
Form a testable product bet.
Decide what evidence would justify continuing, changing, or stopping.
Keep outputs and outcomes separate. Shipping an AI onboarding assistant is an output. Changing a defined activation behavior for a defined customer segment is an outcome. The model can help rewrite output-oriented objectives, but it cannot choose a credible target without baseline data, business context, and an accountable owner.
Force a distinction between fact, inference, and assumption
Require the model to label every material statement as one of three things:
Observed: Directly supported by a supplied interview, event, support conversation, or experiment.
Inferred: A reasonable interpretation that combines observations but is not explicitly stated by the customer or proven by the data.
Assumed: Necessary for the recommendation to work but not yet supported by the supplied evidence.
This simple classification prevents an attractive narrative from laundering assumptions into facts. It also improves discovery planning: the most consequential assumption with the weakest evidence becomes a candidate for the next test.
A useful instruction is: Use only the supplied material. For every recommendation, show the observations that support it, the inference connecting those observations to the recommendation, the assumptions that remain, and the evidence that could disprove it. If support is missing, say that it is missing.
Build a controlled workflow from context to decision record
AI assistance becomes reliable when it is a workflow rather than a chat session. A chat encourages improvisation: context changes, instructions disappear, and nobody can reconstruct why an answer looked different the next time. A workflow gives each pass a defined input, output, and approval gate.
Ground the model in canonical product context
Start with a retrieval-first set of canonical documents. At minimum, that context should include the current vision, product strategy, target segments, value proposition, OKRs, metric definitions, analytics dashboards, relevant discovery evidence, decision history, and definition-of-done checks.
Canonical does not mean comprehensive. More context can make conflicts harder to notice. Give each item an owner, a freshness indicator, and an authority level. If an old positioning document conflicts with the approved strategy, the workflow should identify the conflict rather than silently averaging the two.
Include exclusions as well. Tell the model which documents are historical, which metrics are deprecated, which segments are out of scope, and which proposals have already been rejected. Without those boundaries, previously abandoned ideas can return as apparently new recommendations.
Separate extraction, synthesis, challenge, and approval
Extract: Pull observations, customer language, events, metrics, decisions, and unresolved questions from the supplied material. Preserve links to the original evidence.
Synthesize: Group related observations and propose opportunity statements. Keep contradictory evidence visible.
Challenge: Look for alternative explanations, missing segments, weak causal claims, metric gaming, dependencies, and reasons the recommendation could fail.
Decide: Have the accountable product leader and relevant partners accept, modify, or reject the recommendation. Record the trade-off explicitly.
Publish: Store the decision, evidence, owner, expected outcome, guardrails, and next review trigger in the system the team already uses.
Do not combine these passes into one request for a final answer. Extraction should not quietly prioritize. Synthesis should not hide inconvenient evidence. A challenge pass should test a proposed direction without changing the original evidence set. The human approval gate should be visible, not implied by the fact that somebody copied the output into a roadmap.
Raw interviews, support threads, CRM records, and analytics exports can contain personal or confidential data. Do not paste them into an unapproved model. Minimize the data, remove identifiers that are not needed for the decision, use the governed environment approved by your organization, and retain only what the workflow requires. Privacy-by-design belongs at intake because redacting an output does not undo an inappropriate disclosure in the input.
For recurring workflows, add acceptance criteria and evaluation cases. A discovery synthesis evaluation might check whether every theme retains evidence links, whether contradictions survive summarization, and whether unsupported market-size claims are rejected. A strategy evaluation might check whether every initiative maps to an outcome driver and whether an output has been mislabeled as an objective. Re-run those checks when the model, prompt, context set, or output schema changes.
Use AI in discovery without laundering uncertainty
Discovery generates exactly the kind of material language models handle well: interview transcripts, support conversations, journey notes, behavioral patterns, and open-ended hypotheses. AI can reduce the time between collecting this material and discussing it. It cannot make a biased sample representative or turn a correlation into a cause.
Run synthesis as part of a weekly learning cadence that combines customer evidence with journey and behavioral analysis. Waiting for a large quarterly research readout increases the distance between observation and decision. Treating every new conversation as a roadmap mandate creates the opposite problem. A regular review gives the team a stable point at which evidence can accumulate, conflict, and change an existing belief.
A cluster is a lead, not a finding
Theme clustering is useful for navigation. It is not proof of importance. A frequent topic in support data may reflect product friction, a noisy customer segment, a documentation gap, or a recent incident. The model sees only the supplied dataset, not the market outside it.
Require each proposed opportunity to include:
The affected segment and the context in which the problem occurs.
The job the customer is trying to complete.
Links to supporting observations, including direct customer language where it preserves important nuance.
The observed count within the supplied dataset, clearly distinguished from prevalence in the customer base or market.
Behavioral evidence that supports or challenges the qualitative pattern.
The outcome driver the opportunity could influence.
Contradictory evidence and plausible alternative explanations.
The unanswered question that creates the greatest decision risk.
The next piece of evidence that would materially change the decision.
Then place the opportunity in an opportunity solution tree. Keep the opportunity separate from candidate solutions. If the branch says customers need an AI assistant, it has already collapsed a customer problem into a preferred implementation. Rewrite it in terms of the customer’s obstacle or desired progress, then generate multiple ways to address it.
At the weekly review, ask four practical questions: What did the team observe? Which belief changed? Which important assumption remains weakly supported? What evidence should be collected next? AI can prepare the evidence packet and show deltas from the prior review. The product trio should decide what the evidence means and whether it changes the opportunity being pursued.
Connect roadmap, experiment, launch, and learning
A strategy loses integrity when each delivery stage invents its own explanation. The roadmap promises one outcome, the experiment measures another, the launch emphasizes a feature, and the retrospective celebrates shipping. AI can help maintain the thread, but only if the same hypothesis and metric definitions travel with the work.
Decision layer
Useful AI assistance
Required human judgment
Artifact to preserve
Strategy
Check the chain from customer value to business result and expose unsupported jumps
Choose the segment, differentiation, outcome, and trade-offs
Strategy brief and driver tree
Discovery
Extract observations, cluster themes, retain contradictions, and draft opportunities
Interpret evidence and choose the next uncertainty to reduce
Evidence-linked opportunity record
Roadmap
Map candidate initiatives to drivers, surface dependencies, and prepare option comparisons
Allocate capacity and accept opportunity cost
Prioritization decision record
Experiment
Draft hypotheses, instrumentation, guardrails, edge cases, and analysis checks
Approve the test design, statistical assumptions, and decision rule
Experiment brief
Launch
Adapt release notes, in-product guidance, support material, and segment messaging
Approve claims, rollout risk, positioning, and readiness
Launch plan and approved message set
Learning
Summarize funnels, cohorts, retention patterns, qualitative feedback, and anomalies
Decide whether to continue, revise, expand, or stop
Learning review and updated decision
Make the roadmap show its reasoning
Ask AI to produce roadmap options, not a single supposedly objective ranking. Each option should show the outcome driver it targets, evidence strength, important dependencies, unresolved risk, stakeholder impact, and the work displaced by choosing it. A priority score can organize inputs, but it cannot resolve a strategic disagreement about which customer or outcome matters most.
Every roadmap item should answer: Why this customer problem, why now, what behavior should change, which business result should follow, and what observation would make the team reconsider? If the answer is merely that customers requested it or a competitor has it, the strategy is incomplete.
Make experiments decision-ready before they run
An AI-drafted experiment brief should contain a falsifiable hypothesis, eligible population, primary metric, guardrail metrics, instrumentation plan, exposure logic, expected mechanism, known confounders, and decision rule. For A/B testing, define the minimum detectable effect before interpreting results. The value must be tied to a practically meaningful change and checked against baseline behavior and available traffic; a model cannot infer those constraints from a feature description.
Instrumentation deserves its own review. Specify the event, properties, eligibility conditions, trigger, and expected sequence in the funnel. Use behavioral analytics to check that exposure and activation are measured consistently across variants. Feature flags can separate deployment from release, support a controlled ramp, and limit exposure while the team checks behavior.
For an AI-powered product experience, add eval-driven checks alongside product metrics. Define the behavior the model should exhibit, edge cases it must handle, unacceptable outputs, privacy constraints, and regression cases. Product success cannot compensate for a model behavior that violates an explicit safety or trust requirement.
Keep launch language tied to the original value proposition
AI can adapt UX copy, product tours, tooltips, release notes, in-app guides, and support macros for different segments. Give every channel the same approved value proposition, capability boundaries, terminology, and claims. Otherwise, speed creates message drift: the release note promises an outcome the interface does not support, while the support macro describes a different workflow again.
After release, bring the original decision brief into the learning review. Examine the target cohort, funnel behavior, activation, retention, qualitative feedback, and guardrails. Do not ask only whether the feature was adopted. Ask whether the intended customer behavior changed, whether the assumed mechanism appears credible, and whether the business outcome remains a reasonable consequence.
Scale the workflow only when another person can audit it
Before expanding AI assistance across the product organization, hand one completed decision package to a colleague who was not part of the workflow. They should be able to identify the governing strategy, trace each important claim to evidence, see which assumptions remain open, understand the trade-off, and find the metric that will trigger the next decision.
If they cannot, do not solve the problem with a longer prompt. Repair the missing artifact, unclear ownership, broken evidence link, or inconsistent metric definition. That is where strategic reliability lives.
Start with one decision entering your next weekly discovery review. Build its evidence set, label observations and assumptions, run separate synthesis and challenge passes, and publish the human decision with its reversal signal. Once that chain survives review, reuse the workflow. The goal is not more AI-generated product work. It is a shorter, more inspectable path from customer evidence to a measurable strategic choice.
If you are deciding whether an AI product should become your company name, you probably do not have a naming problem. You have a portfolio commitment problem. The rename will make your bet visible, but it will also force you to explain what existing customers still own, what will keep improving, and what now defines the company’s future.
The most important word in this rebrand is not Fin. It is “remains.” Intercom remains a product, a customer commitment, and a place where the company can keep creating value. Fin becomes the corporate identity and the clearest expression of the next growth thesis.
Changing the company name while retaining the established product name is not an incomplete rebrand. It is deliberate brand architecture. The two names answer different customer questions:
The company brand answers: What future is this organization building toward?
The product brand answers: What can I buy, operate, renew, and rely on today?
The category brand answers: What new capability should I understand, budget for, and compare with alternatives?
Those answers do not always belong under one name. Forcing them together can make the new strategy sound smaller than it is or make the established product appear to be on its way out. Keeping Intercom as the platform avoids turning corporate ambition into accidental product deprecation.
Before approving a similar rename, write a transition contract. This is not a legal document. It is a short internal statement that every product, sales, marketing, support, recruiting, finance, and communications leader can use without improvising. It should answer:
Exactly which entity is being renamed?
Which products keep their current names?
What changes for an existing customer because of the rename?
What explicitly does not change?
Where will investment increase, continue, or decline?
How should someone describe the relationship between the company and each product?
If the answers vary by executive, your organization is not ready to communicate the rename. Customers will encounter every inconsistency as a separate strategic story.
A new category needs a clean place in the buyer’s mind
Established brands are efficient because buyers use them as shorthand. The same shorthand becomes restrictive when a company wants to define a substantially different category. People do not continuously reassess every vendor from first principles. They attach new information to what they already believe.
That is why a legacy name can create friction even when it has strong awareness and customer trust. The problem is not that buyers dislike the old brand. The problem is that they already know where to file it. Every pitch for the new category begins with a correction: the company you associate with one product is now asking you to understand it as something else.
You should look for the same underlying evidence before elevating a product brand:
Prospects ask for the new product or category by name instead of treating it as another feature of the established platform.
The product has a distinct job, competitive set, buying conversation, and roadmap.
Your largest resource-allocation decisions increasingly revolve around the new category.
The existing company name repeatedly requires explanation before buyers understand the new proposition.
The legacy product can remain a coherent, investable business under its own name.
Leadership is willing to keep prioritizing the category when it competes with comfortable, near-term work elsewhere in the portfolio.
Wait if the new product still depends almost entirely on legacy demand, if “AI” is the only thing making it sound like a new category, or if leaders cannot explain the future of the existing portfolio. A corporate rename should settle a strategic truth that is already visible in the product and resource decisions. It cannot manufacture that truth.
Test the strategy before you test the name
Name preference is the least important question at the start. A memorable name cannot rescue an unstable thesis, and a room full of favorable reactions cannot prove that the proposed architecture makes sense. Test the decisions the name is meant to encode.
Strategic permanence
Ask whether the new identity can survive normal product evolution. A company named after a feature will eventually outgrow its name. A company named for a durable category, customer outcome, or long-term platform has more room to expand.
Pressure-test the choice against plausible roadmap changes. If the current interface changes, the underlying models improve, or the product expands into adjacent workflows, does the name still represent the company? If one disappointing planning cycle would make leadership retreat to the old story, the corporate rename is premature.
Customer comprehension
Do not ask customers whether the new brand “makes sense.” That question invites politeness. Show them the proposed naming hierarchy without an explanation and ask them to describe:
What the company does.
What they can buy.
What happened to the existing product.
Which name they expect to see in the application, documentation, support experience, and commercial relationship.
Whether the new offering feels like a feature, a product, a platform, or a category.
The vocabulary in their answers matters more than a preference score. If customers merge the company and product into one ambiguous object, the hierarchy needs work. If established customers assume their product is being replaced, the continuity story is too weak. If prospects still describe the company only through the old category, the new position has not yet become legible.
Portfolio durability
Every product affected by the rename needs a stated fate: promoted, retained, integrated, or retired. Silence creates its own answer, and customers usually interpret it as declining commitment.
The Intercom-to-Fin architecture avoids that ambiguity. The corporate brand follows the AI growth engine, while the established platform receives a rebuilt product and continued investment. You can apply the same discipline by requiring a roadmap, owner, customer promise, and success measure for every brand that survives the transition.
Operating commitment
A company name is a resource-allocation claim. Check whether hiring plans, executive attention, roadmap capacity, sales enablement, partner priorities, and operating metrics already support the future implied by the name.
This is where weak rebrands reveal themselves. The homepage changes, but planning continues to favor the old center of gravity. Sales compensation rewards the previous motion. Product teams keep describing the AI offer as an add-on. Recruiting language promises one future while internal goals fund another. If those contradictions remain, the market will believe the operating behavior rather than the new identity.
Turn the rebrand into an operating model
A corporate rename touches more than brand assets. It changes the nouns people use to make product, commercial, and technical decisions. Treat it as a cross-functional migration with a defined architecture, owners, dependencies, and observable failure modes.
Before launch, remove internal ambiguity
Start with an inventory of named objects. Separate the corporate brand, legal entity, product names, application name, AI agent, domains, documentation, status pages, integrations, partner listings, support channels, and customer-facing team names. They may not all change together, and some should not change at all.
Create a controlled vocabulary for each object. Record the approved name, a plain-language definition, the transition phrase, phrases to avoid, and the person responsible for exceptions. Then apply it to roadmap documents, release notes, sales materials, onboarding, job descriptions, support macros, analytics labels, and executive reporting. This prevents each function from inventing a slightly different portfolio.
Keep the public brand change separate from legal and payment instructions. A new display name does not automatically mean that the contracting entity, tax information, or bank details changed. Telling customers to update those records without confirmation can create payment failures, procurement delays, and fraud risk. Legal and finance owners should identify any real operational changes and communicate them through established, verifiable channels.
Build the customer FAQ from actual consequences, not brand language. Cover logins, existing contracts, invoices, data handling, support access, integrations, domains, saved links, product roadmaps, and administrative work. For every item, say whether action is required. “No action required” is useful only when you have verified it across the relevant systems.
At launch, separate ambition from continuity
Lead with the scope of the change. Say which name belongs to the company, which belongs to the existing product, and how the new category fits. Then explain why the corporate identity is changing. Follow that with a precise account of what existing customers should expect.
Do not rely on “nothing changes” as reassurance. It is usually too broad to be credible, especially when a new product strategy and increased investment are central to the story. Name the stable elements instead: the product that remains, the workflows that continue, the commitments that persist, and any interfaces or commercial records that stay the same.
Use the same architecture everywhere a customer can encounter the company. A clear launch page cannot compensate for an application header, help center, invoice, partner marketplace entry, or sales deck that implies a different relationship. Transitional wording can help connect the names, but it should have an exit condition rather than becoming permanent clutter.
After launch, measure the translation tax
Launch reach tells you that people saw the rename. It does not tell you that they understood it. Establish a pre-launch baseline where possible, then monitor evidence of confusion:
Support conversations asking whether the existing product is being discontinued or replaced.
Sales calls in which representatives must repeatedly correct the company-product relationship.
Documentation searches that mix old and new names in ways your information architecture does not handle.
Broken redirects, failed bookmarks, authentication problems, or integration errors caused by changed domains or labels.
Procurement and accounts-payable questions about the company name, contracting entity, or invoice sender.
Prospect descriptions of the category after encountering the new positioning.
Retention, adoption, and expansion for the established product, tracked separately from awareness of the new corporate brand.
Review the language in those interactions, not just their volume. The words customers use will show whether the new mental model has formed. Retire transition copy only when support, sales, search, and customer interviews indicate that people can move between the names without assistance.
Key takeaways for your own portfolio decision
The Fin corporate name expresses the future growth bet; retaining Intercom protects a valuable product identity and signals continued commitment.
A corporate rename is a brand-architecture and resource-allocation decision, not a cosmetic marketing project.
Elevate a product name only when the category, roadmap, buying conversation, and operating priorities already support it.
Tell customers exactly what is renamed, what remains, what changes, and whether they need to act.
Validate comprehension with unscripted customer explanations, not name-preference questions.
Measure confusion across support, sales, documentation, procurement, integrations, and product health after launch.
If this decision is in front of you, bring a one-page transition contract to your next portfolio review. Ask product, sales, support, legal, finance, and recruiting to describe the company and its products using the same nouns. If they cannot, keep working on the architecture. If they can, and your resource allocation already matches the story, the rename can do its real job: make the strategy easier for the market to understand.
I recently spent time with the debate behind the "product builder" trend—asking whether it’s the future of product management or just another wave of tech FOMO. The conversation featuring Teresa Torres and Petra Wille is a useful prompt, but what matters most is how we translate these ideas into healthy product practices inside our own organizations.
Here’s my take: the product builder movement is neither a mandate nor a fad—it’s a tool. The right question isn’t "should product managers code?" but whether leaning into building advances outcomes for our customers and our teams. In practice, that means letting interest and skill—not pressure—set the pace.
Petra captured it perfectly: "Just because I can do it — is it something I enjoy doing? And do I have enough experience to really get into the flow?" Those two tests—joy and depth—are underrated filters. I’ve seen PMs light up when prototyping or vibe coding a thin slice, and I’ve also seen well-meaning dabbling create hidden complexity that slows everyone down later.
Org design determines whether this works. It’s not about the tools—it’s about clarity of roles, healthy interfaces between product, design, and engineering, and explicit guardrails for where experiments stop and production begins. AI has raised the stakes: "AI can make unskilled work look polished. That’s a feature and a bug — executives see the shine, engineers inherit the mess." If you’ve ever watched a glossy demo turn into weeks of refactors, you know exactly what this looks like.
To avoid that trap, I deliberately separate the three layers where AI is changing product work: personal productivity, team process, and product strategy. Treating these as different stacks keeps expectations clean: a prompt that accelerates personal workflows isn’t the same as an AI-enhanced process that reshapes delivery, and neither automatically produces durable product advantage. Don’t conflate them.
Discovery remains stubbornly human. "Why discovery still requires talking to your customers (sorry)" is more than a friendly nudge. AI can broaden our search space and sharpen analysis, but it doesn’t replace qualitative conversations or the judgment that comes from pattern recognition across real customer contexts. Continuous discovery and disciplined customer interviews are still the most reliable compasses we have.
Where does "vibe coding" fit? It’s great for roughing out concepts, de-risking slices, and communicating intent when words or static mocks won’t cut it. Tools like Claude Code make this faster than ever, and familiar stacks like Ruby on Rails lower the bar for spinning up functional prototypes. But remember the design system trap: AI can make bad decisions look good on the surface. If you don’t control for architecture, accessibility, data contracts, and handoff quality, your team pays the integration tax later.
In well-set-up orgs, the output-oriented muscle memory gets rewired. When AI frees up time, strong teams reinvest it into better problem framing, sharper opportunity solution trees, and tighter product strategy—rather than simply chasing more output. That’s a leadership challenge, not a tooling problem, and it shows up quickly in how teams make trade-offs.
Here’s how I operationalize this with empowered product teams: we articulate clear boundaries for prototypes versus shippable code, define decision rights for when PMs or designers "build," and align on review gates that protect quality without stifling speed. We also make the three AI layers explicit in roadmapping and retros, so improvements to personal workflows don’t get mistaken for strategic advantage.
My distilled guidance echoes the episode’s throughline. The product builder trend isn’t a mandate — it’s a tool. Let enjoyment and skill guide who on your team leans into it. Organizational readiness determines whether AI empowers your team or creates chaos. Don’t conflate personal efficiency, process change, and product impact—they require different responses. Discovery fundamentals haven’t changed; AI helps you go deeper, not skip the work. And the real takeaway on product builders: not everyone has to build, but everyone can if they want to.
If you want to hear the full discussion that sparked these reflections, listen on Spotify or Apple Podcasts. Then tell me: where will you apply builder energy in your team—and where will you deliberately say no?
Resources & Links: Follow Teresa Torres: https://ProductTalk.org. Follow Petra Wille: https://Petra-Wille.com. Mentioned in this episode: Claude Code, Vibe coding, Ruby on Rails.
One more quote I loved because it centers autonomy and craft: "It’s a tool in our toolbox. We can decide who on our team has fun with it, wants to do it, wants to contribute." That’s the mindset that sustains both momentum and morale.
Your cloud-cost agent can identify the line item that moved and still fail to change a single decision. The gap appears after the diagnosis: the recommendation arrives without the product, pricing, ownership, and risk context needed to act.
If you are taking an internal FinOps capability into the customer experience, design for a closed decision loop. The goal is not autonomous cost cutting. It is a governed system that connects spend to customer value, recommends the next move, and proves whether the move worked.
Design a decision loop, not another cost dashboard
Start by naming the decision your product will improve. A broad promise such as optimize cloud spend gives the agent no useful boundary. A better contract is: detect a material change in workload cost, identify the most plausible driver, propose one permitted response, route it to the right owner, and verify the effect.
Agentic does not mean unrestricted. It means the agent can select the next permitted step based on context. Deterministic services should still perform calculations, enforce policies, check permissions, and execute infrastructure changes. Use the model where interpretation is valuable: reconciling signals, building a driver narrative, identifying missing context, explaining tradeoffs, and routing a decision.
That distinction matters in FinOps. A model should not improvise a billing calculation, invent a price, or bypass a commitment policy. If a calculation has one correct result, compute it in code and give the result to the agent as evidence.
Learning layer: Post-action telemetry, realized outcomes, agent evaluations, customer feedback, and recurring patterns that belong in the product roadmap.
A retrieval-first pipeline that combines billing, usage, observability, product, and go-to-market context is more useful than a large prompt containing a monthly cost export. Retrieve the records needed for the current decision and preserve their lineage. Every recommendation should reveal which records were used, when they were updated, which pricing assumptions applied, and what the agent could not retrieve.
Customer-facing retrieval adds another non-negotiable boundary: tenant isolation must be enforced before context reaches the model. Do not rely on a prompt to prevent cross-customer disclosure. Access control belongs in the retrieval and service layers, with the resulting access decision recorded in the audit trail.
Start with one anomaly and one reversible response
Your first release does not need to optimize every cloud service. A practical thin slice is anomaly detection plus one high-leverage remediation path. For example, the agent might detect a change in non-production workload cost, connect it to a schedule change, prepare a schedule correction, request approval from the workload owner, and monitor the next usage window.
Choose a first action that is bounded and reversible. A scheduling correction is easier to inspect and undo than a long-term financial commitment or a production capacity change. The purpose of the thin slice is to prove the whole operating loop, not merely the anomaly model.
Make every recommendation safe enough to act on
A recommendation without an execution envelope is an opinion. It may be correct, but the recipient still has to reconstruct the evidence, find the owner, assess the downside, and decide how to validate it. That is where apparently intelligent systems create more work than they remove.
Use a recommendation contract
Treat every agent recommendation as a structured product object. At minimum, require these fields:
Decision: The exact choice the recipient is being asked to make.
Scope: The account, workload, service, environment, and time window affected.
Owner: The person or role accountable for the workload and the person authorized to approve the action.
Evidence: Links to the billing, usage, observability, deployment, and product records that support the diagnosis, including their freshness.
Driver path: The causal chain the agent believes explains the change, plus material alternative explanations it considered.
Proposed action: The change, its expected mechanism, and any assumptions behind an estimated effect. If the effect cannot be estimated reliably, say that it is unknown.
Confidence and unknowns: Evaluation-backed confidence evidence, missing context, and conditions that would invalidate the recommendation.
Verification plan: The telemetry, observation window, success condition, and stop condition used after the action.
The expiration field is easy to overlook. Cloud state changes quickly enough that an old recommendation can remain plausible after its evidence has gone stale. Expire the recommendation when its pricing, topology, deployment, or usage assumptions are no longer current. Force a fresh retrieval before execution.
Grant autonomy by action class
Do not give an agent one global autonomy setting. Earn autonomy independently for each action class:
Observe: Detect and organize a possible anomaly.
Explain: Build a driver tree and expose supporting evidence without proposing a change.
Recommend: Propose an action while a human retains approval and execution.
Prepare: Generate a change plan or dry run, but require an authorized owner to apply it.
Execute within policy: Apply a reversible, bounded action only when the policy engine, permissions, evidence freshness, and rollback checks all pass.
Purchasing a cloud commitment or altering production resources can create real financial or availability exposure. Keep finance and service owners in the approval path until confidence evidence and post-action telemetry demonstrate reliable performance for that specific intervention. Good results on anomaly explanations do not establish that the same agent is safe to execute infrastructure changes.
Governance should be visible in the product, not left in a policy document. Show the approver which data was accessed, which rules passed, who changed the recommendation, what action ran, and what happened afterward. Privacy-by-design, data controls, and transparent decision logs are part of the user experience when the system influences money and production infrastructure.
Evaluate the decision loop, not the prose
A polished explanation is not evidence of a useful agent. Build evaluations around the failure modes that can block or distort a decision:
Did the recommendation use the correct customer, workload, environment, price, and time window?
Can each material claim be traced to an underlying record?
Does the driver path match known cases, including cases with several plausible causes?
Does the agent abstain when ownership, telemetry, or pricing context is missing?
Did approval routing and policy enforcement behave correctly?
Can the recipient perform the proposed action without reconstructing missing steps?
Did post-action telemetry confirm the expected direction of change without creating an unacceptable operational tradeoff?
Put retrieval changes, prompts, policies, and tools through the same delivery discipline as application code. Eval-driven development, CI/CD, and a weekly shipping cadence make regressions visible before a persuasive but poorly grounded recommendation reaches an operator or customer.
Embed the capability with customers before scaling it
The first customer version should not be a general-purpose cost chatbot. It should be a narrow, product-assisted engineering motion in which a Forward Deployed Engineer, or FDE, helps the customer connect product usage, cloud architecture, and cost-to-value.
Choose a small pod and customers that can teach you
A sensible starting shape is one FDE pod focused on two or three high-potential customers. High potential should not mean merely the largest cloud bill. Select customers where the team can access the necessary evidence, an accountable sponsor can authorize changes, the problem is likely to recur, and the customer agrees to clear data and governance boundaries.
Evidence readiness: Billing, metering, observability, pricing, and deployment context can be joined without weeks of manual reconciliation.
Decision access: An engineering, product, or finance owner can approve an intervention and explain the operational constraints.
Learning value: The problem represents a pattern that may apply beyond one account.
Measurability: The customer and FDE can agree on a cost-to-value measure before making a change.
Governance fit: Data access, retention, tenant isolation, approvals, and audit expectations are explicit.
If any of these conditions is absent, the engagement may still be commercially important, but it is a weak environment for deciding whether the agentic product works. Separate account urgency from product-learning quality.
Run a customer optimization loop that produces reusable knowledge
Define the value unit. Agree on what an active workload or valuable unit of product usage means. Total spend alone cannot distinguish efficient growth from contraction.
Establish the baseline. Record current cost per active workload, time-to-first-value, relevant deployment behavior, and the constraints the customer will not trade away.
Build the driver tree. Connect the spend change to services, environments, releases, product behavior, and customer usage. Surface gaps instead of filling them with assumptions.
Select one intervention. Prefer the smallest action that can test the diagnosis. Document the expected mechanism, approver, risk, and rollback before execution.
Verify the outcome. Compare post-action telemetry with the agreed baseline. Record savings, unit-economics movement, performance effects, adoption effects, and unintended consequences separately.
Codify the pattern. Capture the inputs, decision rule, action, exceptions, safeguards, and evidence required to repeat the intervention.
Send a weekly learning packet to product. Include successful patterns, failed diagnoses, missing platform capabilities, customer language, and recommendations that still depend on FDE judgment.
Customer-embedded optimization creates an obvious trust question for a consumption business: does the vendor want the customer to spend less or consume more? The clean answer is to optimize cost-to-value rather than either number in isolation.
A customer’s total cloud cost can rise while cost per active workload improves because valuable usage is growing. Total cost can also fall because the customer is using less of the product, which is not an optimization success. Label the outcome precisely: lower total spend, lower unit cost, avoided waste, shifted commitment, higher useful consumption, or reduced operational risk. Do not collapse these different effects into a generic savings claim.
The FDE is also a trust boundary. The role should explain the recommendation, expose assumptions, and represent the customer’s constraints. It should not become a human interface for repetitive exports and one-off queries that the platform ought to handle.
Turn field work into a roadmap, not permanent custom service
A strong FDE can make a weak product look successful by solving every gap manually. That is useful for an individual customer and dangerous for product strategy. You need an explicit test for moving work from the field into an agent workflow or native platform capability.
Apply a productization test to every recurring intervention
Can the same signal be retrieved reliably across the intended customer segment?
Can the decision logic be expressed without undocumented customer-specific knowledge?
Can the action be bounded by a stable policy, approval path, and rollback procedure?
Can the outcome be measured with telemetry that exists before and after the change?
Do the likely exceptions fit a review workflow, or do they fundamentally change the decision?
If the signal, decision, action, and measurement are repeatable, make the pattern a native feature or automated playbook. If the evidence is repeatable but judgment varies, keep an agentic workflow with human review. If the action carries high financial or availability risk, keep the FDE and accountable owner in the loop. If the pattern is a one-off, document it but resist turning it into product scope.
Use a scorecard that reveals where the loop is breaking
Dimension
Measure
Decision it informs
Insight speed
Time-to-insight from a material spend change
Is the system finding the issue early enough to change an engineering decision?
Action quality
Recommendations with evidence, an owner, a permitted action, and a verification plan
Is the agent producing executable decisions or polished commentary?
Economics
Realized savings per recommendation and cost per active workload
Did the intervention improve spend or unit economics for the intended value unit?
Reliability
Post-action effects, abstentions, rollbacks, and policy failures by action class
Which interventions have earned more autonomy, and which need tighter controls?
Customer outcome
Time-to-first-value and NRR movement on FDE-supported accounts
Is the motion improving adoption and durable account value? NRR is directional evidence, not proof of causation.
Product leverage
Recurring field patterns converted into features, guardrails, or in-product guidance
Is customer work compounding into a scalable product?
Recommendation volume, prompt length, and agent activity are operating diagnostics, not business outcomes. A quiet system that changes a few high-value decisions can be more useful than an active system that produces hundreds of unactioned findings.
Make build versus buy a component decision
Do not treat the choice as one monolithic platform decision. Separate commodity capabilities from the context and workflow that create differentiation. Evaluate billing ingestion, normalization, anomaly detection, the context model, pricing logic, recommendation policy, approval routing, execution, and agent analytics independently.
Does the capability require knowledge of your architecture, pricing model, feature flags, customer usage, or deployment behavior?
Can an external component preserve evidence lineage, tenant isolation, and decision logs at the level your customers require?
Is the capability a generic input to the product, or is it where your product makes a differentiated decision?
Can your team evaluate and operate the component continuously, including regressions after model, prompt, policy, or data changes?
Will the component reduce time-to-value without trapping critical customer and pricing context in an opaque workflow?
Give the core product to a product trio spanning product management, engineering, and FinOps. Bring FDE, customer success, SRE, finance, and security into discovery and evaluation where their decisions are affected. Field requests should enter the roadmap with evidence of recurrence, strategic importance, or platform leverage rather than becoming an informal side door to custom development.
Key takeaways
Define the product as observe, explain, propose, authorize, execute, and verify. Diagnosis alone is not an agentic outcome.
Retrieve billing, usage, observability, pricing, product, and ownership context for each decision, with lineage and tenant boundaries enforced outside the prompt.
Represent every recommendation as a governed contract containing evidence, owner, action, risk, approval, rollback, expiration, and verification.
Grant autonomy by action class. Keep humans in the loop for commitments and production changes until that intervention has reliable post-action evidence.
Start customer delivery with one FDE pod and two or three customers that offer evidence access, decision access, measurable value, and reusable learning.
Measure time-to-insight, realized outcomes, unit economics, reliability, customer value, and productized patterns instead of counting recommendations.
This week, choose one recurring cost anomaly and map the complete path from underlying records to a verified action. Name the owner, approval rule, rollback, and success telemetry before improving the prompt. Do not add a second workflow until the first can explain what changed, why the action was allowed, and whether it improved customer cost-to-value.
You are days from releasing a feature. Engineering needs a rollout decision. Go-to-market teams need a clear promise. Support needs to know what could go wrong. Leadership wants to know whether the release changed customer behavior. Dropping an AI bot into the launch channel will not resolve those tensions. If the metrics, authority, and escalation rules are vague, the bot will only answer ambiguity faster.
The useful model is a closed loop: define the behavior you want to change, instrument exposure and value, operate the rollout from one shared channel, let agents handle repeatable retrieval and synthesis, and reserve consequential decisions for accountable people. Done well, AI reduces the coordination tax around a launch while making the growth decision more disciplined.
Define the growth decision before you automate the launch
A feature being available is an output. A customer reaching value is an outcome. Your launch plan has to connect the two before anyone writes an agent prompt or schedules a readout.
A durable growth plan translates the product North Star into activation and retention signals, then defines the minimum detectable effect before experimentation. The North Star provides direction, but it is often too distant to diagnose a new feature. A launch needs an earlier behavioral signal that can tell you whether eligible users encountered the feature, understood it, and reached its intended value.
Write a short launch contract with these fields:
Target user and moment: Name the user or account segment, the situation that makes the feature relevant, and any eligibility rules. A feature intended for a new administrator solving an initial setup problem should not be evaluated across every user in the product.
Behavioral hypothesis: State the current behavior, the desired behavior, and why the feature should cause the change. If the causal link cannot be written plainly, the team is not ready to interpret the launch data.
Measurement chain: Instrument eligibility, actual exposure, meaningful engagement, the activation action, and the downstream value event. If you record engagement but not exposure, low adoption could mean either that users ignored the feature or that they never saw it.
Primary signal: Choose the behavior closest to customer value that can mature within the launch window. Do not promote every available metric to equal status. That turns a decision into a search for whichever chart looks most favorable.
Guardrails: Name the operational and customer signals that can stop a rollout, such as degraded performance, errors, support burden, privacy concerns, or a harmful shift in another important behavior. Define the actual acceptable bounds in your internal contract before launch; do not negotiate them after a concerning result appears.
Minimum detectable effect: Decide what change would be large enough to matter to the product and business. This keeps the team from celebrating meaningless movement or waiting indefinitely for certainty that the planned test cannot provide.
Decision rule and authority: Specify what evidence permits a ramp, what requires a hold, what triggers investigation, and who can pause or roll back the feature. An agent may assemble the evidence, but it should not invent the rule during the incident.
The contract should also distinguish a growth signal from a health signal. Activation, conversion, or repeated use may tell you whether the feature is producing value. Latency, error rates, complaints, and anomalous segment behavior tell you whether it is safe to continue. A healthy system with an immature growth signal may justify holding the rollout. Broken instrumentation or a material guardrail breach calls for a different response.
This distinction prevents a common category error: treating an inconclusive experiment as a failed feature, or treating early adoption as proof of durable value. The launch decision should always answer the same question: given trustworthy exposure data, the primary signal, and the guardrails, should you ramp, hold, investigate, or roll back?
Pin the launch contract: Include the hypothesis, eligible population, event definitions, primary signal, guardrails, rollout stages, owners, and links to live dashboards. A screenshot becomes stale; a governed dashboard remains inspectable.
Create stable work lanes: Use separate parent threads for metrics, incidents, enablement, and customer feedback. This gives each agent and human responder a predictable place to work without fragmenting the overall launch record.
Publish response expectations: State which questions the agent can answer immediately, which require a human owner, and how urgent operational issues are escalated. The agent should never make an urgent request look handled merely because it produced a fluent reply.
Keep a decision ledger: For every ramp, hold, pause, or rollback, record the timestamp, evidence considered, decision, rationale, approver, and next review point. This matters later when a stakeholder asks why exposure changed or when the team compares the result with the original hypothesis.
Require channel-visible handoffs: If a question moves to a data, engineering, or privacy owner, the agent should post the handoff and preserve the relevant query, definitions, filters, and context. Do not let direct messages become a shadow operating system.
Give every automated data answer a consistent shape:
The direct answer, including the population and time window.
The metric definition and denominator.
The relevant cohort, segment, environment, and experiment variant.
A link to the approved underlying data or dashboard.
An as-of timestamp so readers know how fresh the result is.
Any missing data, definition conflict, or limitation that changes interpretation.
The named human owner when judgment or investigation is required.
An activation rate without its denominator, an environment, or a timestamp is not decision-grade evidence. A polished answer should not receive more trust than the data lineage beneath it. Make uncertainty visible instead of prompting the agent to conceal it behind a confident summary.
Give agents narrow jobs and humans explicit authority
The safest launch architecture separates three jobs: retrieving data, operating rollout controls, and interpreting evidence. Combining them in one broadly empowered agent creates unnecessary risk. It also makes failures harder to diagnose because you cannot tell whether the problem came from a bad query, a bad recommendation, or an unauthorized action.
Use a data agent for retrieval and first-pass synthesis
Connect the data agent only to approved sources and metric definitions. It can answer repeatable questions such as activation by cohort, conversion by segment, latency by region, exposure by variant, or the movement of a named guardrail. It should provide citations and timestamps, then route questions requiring nuance to an owner while keeping the context in the thread.
Write the escalation boundary into its operating instructions. Escalate when metric definitions conflict, required data is unavailable, a query touches restricted information, the request asks for a causal conclusion that descriptive data cannot establish, or the answer would materially change rollout. The best response in those cases is not a guess. It is a precise statement of what is missing and who must resolve it.
Keep the feature-flag agent read-only by default
A flag agent can safely expose status by environment, current rollout allocation, and change history. That alone removes many repetitive questions. Write access is different: an incorrect production change can expose an unready experience, expand an incident, or remove access unexpectedly.
When you permit flag mutations, require an explicit sequence:
The requester names the feature, environment, target population, requested action, and reason.
The agent shows the current flag state and summarizes the evidence relevant to the request.
The authorized approver confirms the exact change. Approval cannot be inferred from an emoji, an ambiguous reply, or the agent’s own recommendation.
The integration performs only the approved action through constrained permissions.
The agent posts the resulting state, timestamp, requester, approver, rationale, and change-history link.
Do not give the agent a broad production credential merely because the chat interface is convenient. Restrict its access by environment and role, preserve an audit trail, and keep a manual rollback path available to the responsible engineer.
Use a readout agent to maintain the launch narrative
Scheduled summaries prevent the team from rebuilding the same analysis for every stakeholder. A useful default is to publish readouts at T+1 hour, T+24 hours, and T+7 days, while adapting the questions to the product’s actual usage cycle:
T+1 hour: Confirm that exposure is occurring as intended. Check instrumentation, operational performance, obvious anomalies, and incident status. This checkpoint is primarily about measurement and safety, not declaring growth success.
T+24 hours: Review adoption and activation by the planned cohorts, early conversion movement where applicable, support themes, and any uneven behavior across important segments.
T+7 days: Evaluate experiment results that have had time to mature, retention or repeated-value signals when the product cycle makes them observable, significant outliers, and the follow-up work needed to harden or revise the experience.
These checkpoints are operating cadences, not guarantees of statistical maturity. A feature used on a longer cycle may not produce a meaningful retention signal by the final checkpoint. The readout should say that plainly instead of treating missing maturity as neutral evidence.
Every readout should end with a decision or an explicit statement that no decision is yet warranted. It should also name the evidence still needed, the owner, and the next review point. A summary that lists charts but does not clarify the decision state creates more reading without reducing uncertainty.
Make the accountability map visible
Product owns the behavioral hypothesis, the primary growth signal, and the recommendation to ramp, hold, or change direction.
Engineering owns operational health, flag implementation, incident response, and safe rollback execution.
Data owns metric definitions, instrumentation validity, experiment design, and interpretation limits.
Support and go-to-market owners contribute customer feedback, readiness concerns, enablement status, and communication needs.
Agents retrieve, summarize, route, and perform narrowly preauthorized steps. They do not approve their own consequential recommendations.
The governance layer is part of the product, not a final compliance check. Apply role-based access, protect personally identifiable information, require source citations, and retain transparent logs. Then monitor response accuracy, deflection, and time-to-answer through Agent Analytics. Deflection alone is a poor success metric: a confidently wrong response may reduce human questions while increasing decision risk. Review incorrect answers, unnecessary escalations, missed escalations, and stale data as carefully as response speed.
Run the rollout as a sequence of evidence gates
A feature flag is not merely a switch. It lets you separate deployment from exposure and turn a large release decision into a sequence of smaller, inspectable decisions. The appropriate rollout stages depend on the feature’s operational, privacy, and customer risk, so define them in advance rather than copying a universal percentage.
Use this operating sequence:
Preflight the measurement: Verify eligibility, exposure, activation, value, and guardrail events in the intended environment. Confirm that dashboards use the launch contract’s definitions and that the agent can retrieve the same governed numbers.
Release to the defined cohort: Use the flag to control who can receive the experience. Confirm actual exposure before interpreting engagement. Eligibility and exposure are different facts.
Inspect evidence at the scheduled gates: Start with instrumentation and safety, then move to activation, conversion, retention, and other downstream value signals as they become observable. Review the preselected segments before exploring unexpected cuts of the data.
Choose a named decision state: Ramp, hold, investigate, pause, or roll back. Record the evidence and rationale. Avoid vague states such as looking good, because they do not tell engineering what to do or stakeholders what has been decided.
Feed the learning back into the journey: Update onboarding, in-product guidance, targeting, positioning, or the feature itself based on the observed friction. A winning test becomes a growth mechanism only when the trigger, experience, and value-producing behavior can be repeated reliably.
Use a clear decision ladder:
Ramp when measurement is trustworthy, guardrails remain inside the pre-agreed bounds, the evidence meets the decision rule, and customer-facing teams are ready for broader exposure.
Hold when the system is healthy but the outcome has not matured enough to support a decision. State what evidence is pending and when it can reasonably be reviewed.
Investigate when an anomaly, segment divergence, definition conflict, or instrumentation gap makes the aggregate result unreliable.
Pause when continued exposure could obscure an incident, contaminate the test, or expand a customer problem while the team diagnoses it.
Roll back when a material operational, privacy, safety, or customer guardrail crosses the boundary defined in the launch contract. Do not wait for the primary growth metric to mature before acting on a serious downside.
Logging only the final conversion makes those questions impossible to separate. A delivery problem, poor recommendation, confusing interaction, and weak value proposition can all produce the same downstream result. Preserve the path from eligibility through value, including the experience variant the user received. If targeting or adaptive behavior changes during the test, log the change and account for it in the interpretation.
Do not confuse high initial use with a durable growth loop. Novelty can produce engagement without retained value. Look for the sequence that matters to your product: activation, repeated value, and then the relevant expansion, collaboration, or retention behavior. If the product has no natural invitation or sharing mechanic, do not force a viral story onto it. Build the loop around the behavior customers already have a reason to repeat.
Key takeaways
Start with a launch contract that names the user, behavioral hypothesis, measurement chain, primary signal, guardrails, minimum detectable effect, decision rules, and accountable owners.
Use one launch channel as the shared operational record, but separate metrics, incidents, enablement, and feedback into stable threads.
Split agent responsibilities across data retrieval, flag operations, and scheduled readouts. Keep consequential actions approval-gated and auditable.
Treat T+1 hour, T+24 hours, and T+7 days as decision checkpoints, not automatic declarations of success.
Use feature flags to move through evidence gates. Ramp, hold, investigate, pause, or roll back according to rules written before the data arrives.
Measure AI-powered experiences from eligibility through delivery, engagement, value, and guardrails so you can diagnose why growth did or did not move.
For your next launch, begin with a narrow operating slice: a completed launch contract, a structured channel, a data agent limited to approved queries, read-only flag visibility, and scheduled readouts. Review every wrong answer, escalation, and decision after the rollout. Expand the agent’s authority only when the evidence shows that the control system is trustworthy.
Data has always been my compass for building products that customers love and businesses depend on. Few sentences distill that imperative as crisply as the one below—and it continues to inform how I prioritize, experiment, and scale outcomes across the roadmap.
Krista is a digital analytics leader, product strategist, and industry evangelist. She helps businesses use data to drive growth, retention, and monetization.
That mandate mirrors how I run product: leverage behavioral analytics to uncover patterns, translate those insights into hypotheses, and validate them through rigorous A/B testing. I start by instrumenting the user journey end to end, then use cohort analysis, funnel diagnostics, and retention analysis to pinpoint where activation, engagement, or monetization is stalling. From there, I map driver trees to connect inputs (feature adoption, time-to-value, onboarding friction) to outputs (retention, conversion, revenue), so every experiment has a clear line of sight to business impact.
On experimentation, I hold the bar high: define the minimum detectable effect (MDE) up front, ensure clean experiment design, and size samples to reduce noise. I combine Amplitude analytics with qualitative signals from continuous discovery to prioritize tests that move the needle, not just the vanity metrics. When a variant wins, I don’t stop at the lift—I track downstream effects on user activation, long-term retention, and monetization, ensuring we’re compounding gains rather than optimizing in silos.
For product-led growth, I focus on the moments that matter most: first-value, aha, and habit formation. Journey mapping helps me identify the shortest, clearest path to value, while targeted in-app experiences and contextual nudges accelerate activation without adding friction. Every iteration feeds a learning loop—measure, learn, and ship—so we can pursue step-change outcomes, not incremental tweaks.
Ultimately, the craft is in translating analytics into action. When teams can trace a feature idea to a specific behavioral pattern, test it with a well-powered A/B experiment, and observe durable improvements in retention and revenue, momentum takes care of itself. That’s how I operationalize data to deliver growth, retention, and monetization at scale.
Inspired by this post on Amplitude – Best Practices.