I just wrapped an all-out engineering sprint. That still sounds odd coming from me, because while I’ve written code on and off for years, I don’t self-identify as an engineer. I’m a product manager who used to be a designer. It’s been a long time since I wrote code for a living.
But AI has expanded what’s just now possible—for our products, and for us. It’s pushed me to do more than I imagined. In that spirit, I want to share a recent engineering story. It includes technical details, and a year ago I couldn’t have done any of it. I learned it with the help of AI, and my aim is to show what’s now within reach.
I’ve been building two services with a partner at Vistaly: AI-generated interview snapshots and AI-generated opportunity solution trees. We put out a call for alpha partners, received over 100 applicants, and selected eight design partners to start.
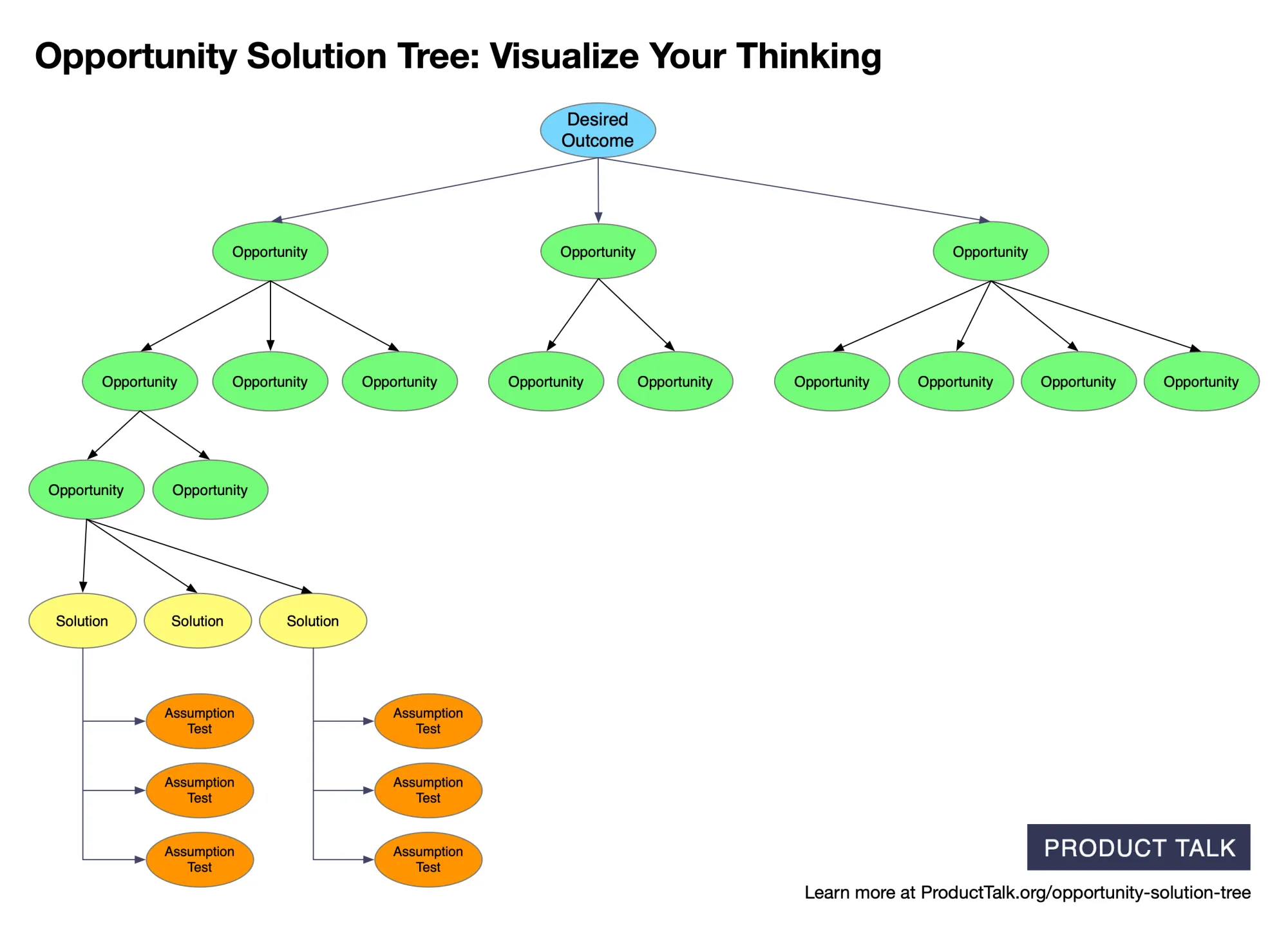
Each team uploaded three customer interviews. I identified the key moments and opportunities and then generated an opportunity solution tree from those snapshots. I provide the AI services; Vistaly is building the UI and workflows around them.
Early feedback was strong. Teams immediately asked to upload more interviews—exactly the kind of demand signal you hope to see—so we got to work making that possible.
Updating an opportunity solution tree with new interview content is far harder than generating a new tree from scratch. I initially underestimated the complexity. Our goal wasn’t to produce a tree and declare it truth. We wanted teams to engage, correct, and collaborate with the AI—scaffolding cross-interview synthesis instead of doing it for them.
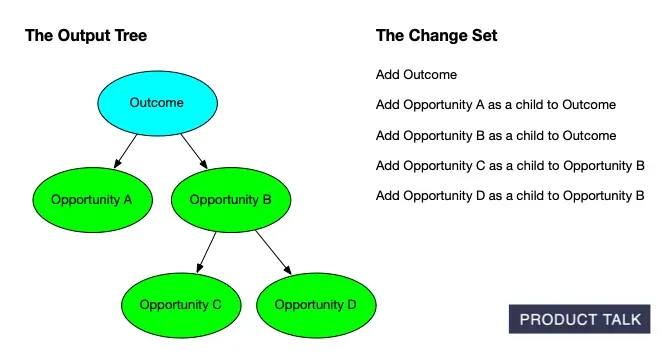
To support that, we needed a way to communicate precisely how a tree would change after new interviews were added. We took inspiration from git diff and set out to build the equivalent for opportunity solution trees—step-by-step change sets that explain each proposed modification.
That decision was right, but the lift was larger than I expected. It wasn’t enough to generate an updated tree; I also had to provide a clear, ordered walkthrough of what changed and why.
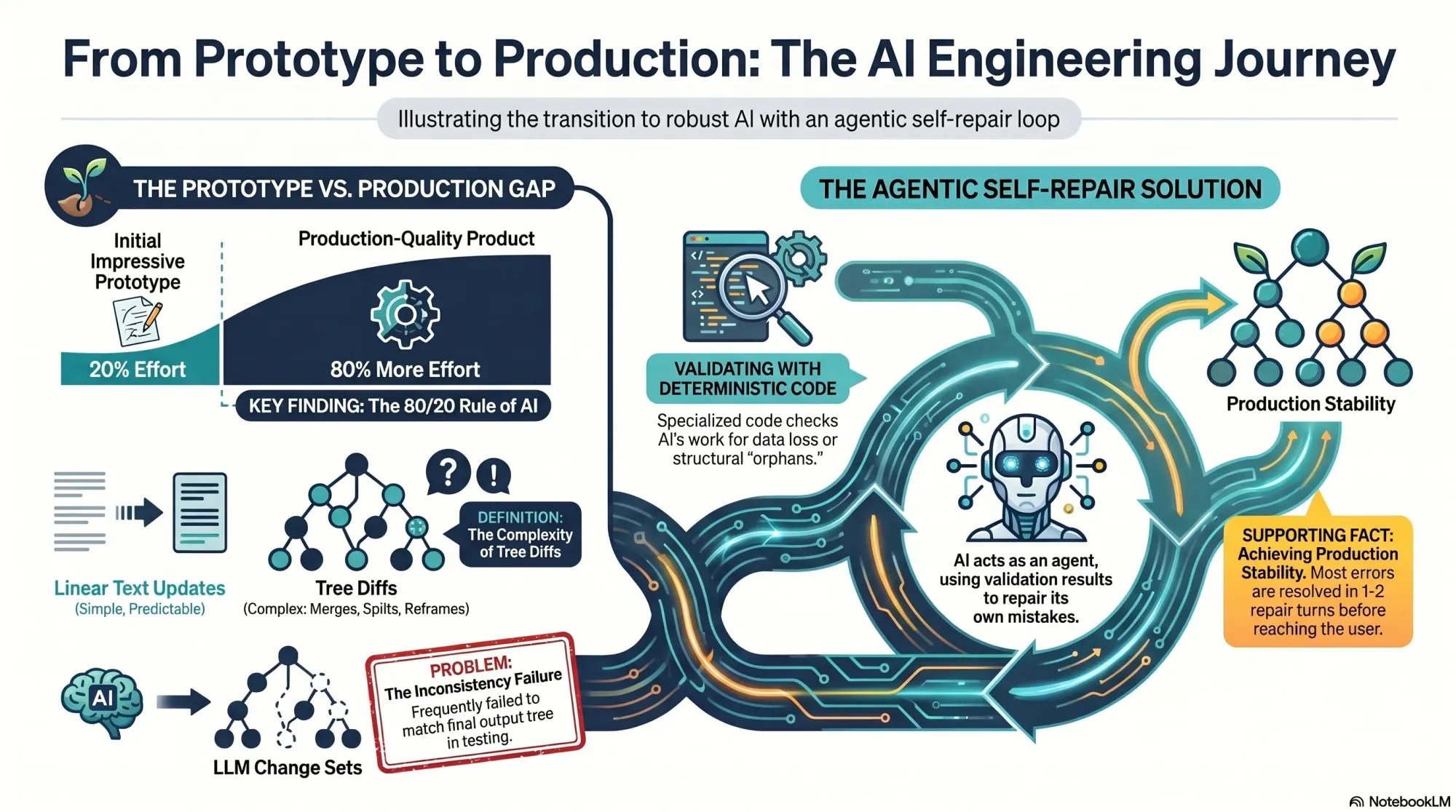
I often see the same pattern with AI: it’s easy to get to an impressive prototype, but much harder to reach a production-grade product. That was exactly my experience here. My service actually comprised two sub-services: generating a new tree from scratch and updating an existing tree with new interviews. The first worked well in alpha; the second had to be built before anyone could add a fourth interview.
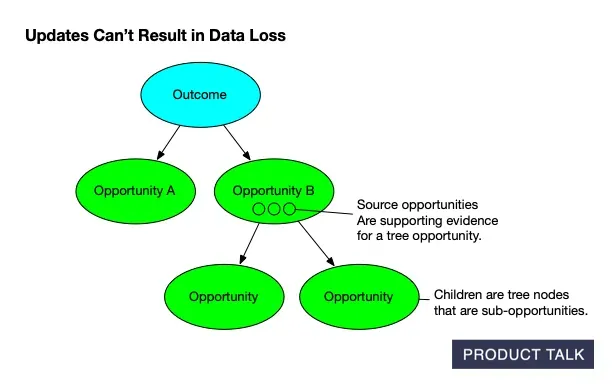
On the surface, these services look similar. In reality, updates must preserve existing structure unless new evidence requires a change. You have to account for compound operations—merges, splits, deletes—while guaranteeing no data loss. Every node has source opportunities (supporting evidence from interviews) and children (tree sub-opportunities), and neither can be dropped.
In classic AI fashion, I got a reasonable version working in a few days and shipped it to our design partners. One team quickly hit our beta limits and asked to convert to a paid subscription so they could keep going. They showed a willingness to pay, converted, and started uploading aggressively.
At the 14th, 15th, and 16th uploads, the cracks appeared. We saw odd behavior in some trees. The Vistaly team noticed that the change sets—the step-by-step instructions emitted by my service—didn’t always reconstruct the final tree my service also emitted. We needed those steps to match exactly, so teams could review and accept, modify, or reject each change with confidence.
They flagged the issue the day I was flying to New Orleans for Jazz Fest. In hindsight, I’m glad I didn’t grasp the scope of what awaited me. I had roughly 80% of the work still to do to make tree updates rock solid. At least I got to enjoy the music first.
Back home, I started diagnosing. My service was a pipeline: several LLM-driven steps followed by deterministic code to compare trees and produce change sets. As I dug in, I realized that approach was flawed. Tree diffs, unlike linear document diffs, are ambiguous.
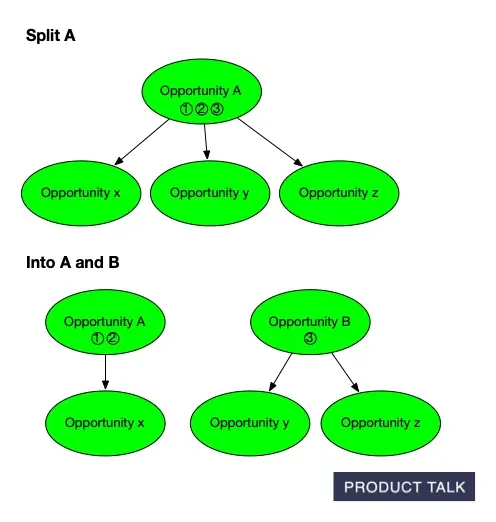
In a document, if I add a sentence, the diff shows an addition. If I delete a paragraph and rewrite it, the diff shows a removal and an addition. Simple. But trees are different. Suppose I split opportunity A into A and B, and later merge B with C. The split can disappear from the final diff.
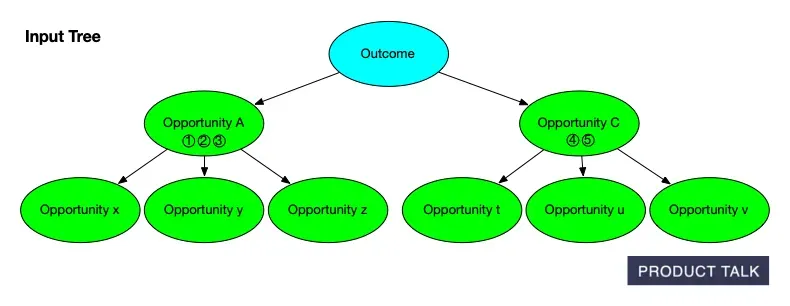
When the model splits an opportunity, it must distribute A’s source opportunities and children between A and B. For instance, if A has source opportunities 1, 2, 3 and children x, y, z, after the split A might keep 1, 2, and x, while B takes 3, y, and z.
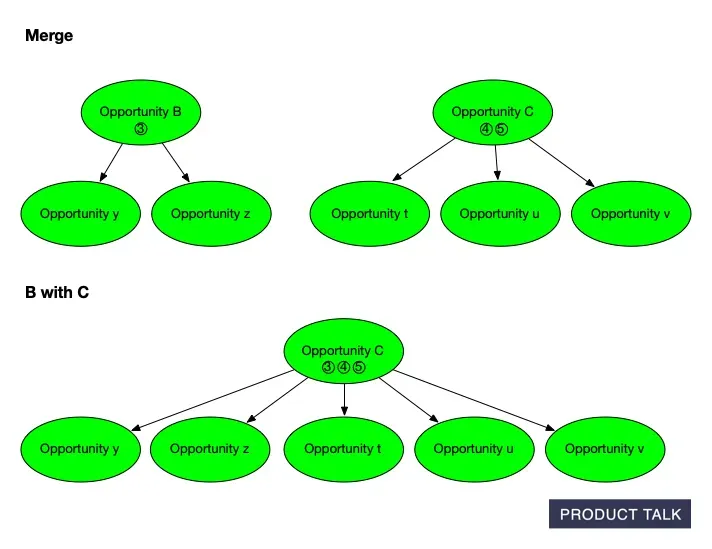
Now suppose the model merges B into C. If C originally had source opportunities 4 and 5 and children t, u, v, then after the merge C now has source opportunities 3, 4, 5 and children t, u, v, y, z. When you compare the original and final trees, it looks like A somehow donated some evidence and children directly to C. The split and merge that explain why are invisible to a naive diff.
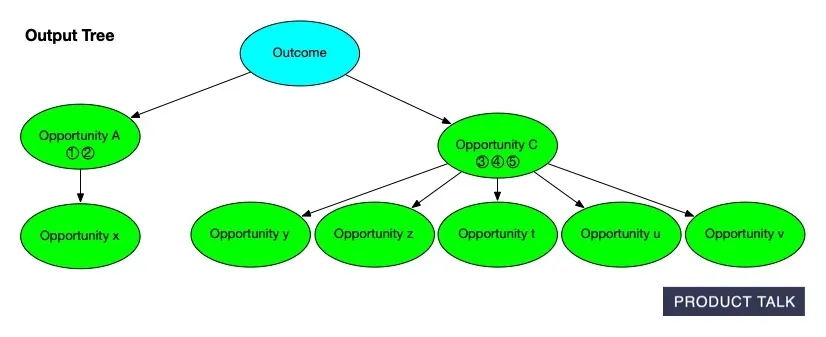
That was the core insight: we didn’t just need to show what changed—we needed to show why it changed. I had to reconstruct each move step-by-step. That meant getting the model to show its work, which opened a new can of worms.
I refactored my prompts so the model produced both the final output and the exact change set it used to get there. The action language was explicit: add, delete, reframe, merge, split, and so on. Crucially, I asked the model to describe its moves in user-meaningful terms—“split A into A and B, then merge B into C”—not as opaque reassignments of sources and children.
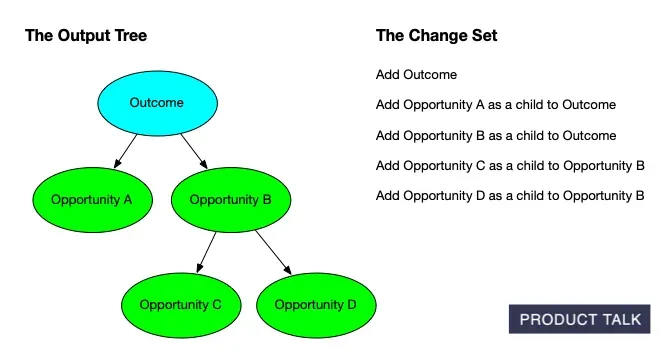
For each LLM step, the model now emitted its recommendation and the corresponding change set. This helped, but it wasn’t perfect. After extensive testing and error analysis, two classes of errors emerged: (1) the model attempted an invalid move, and (2) the change set didn’t actually generate the recommendation.
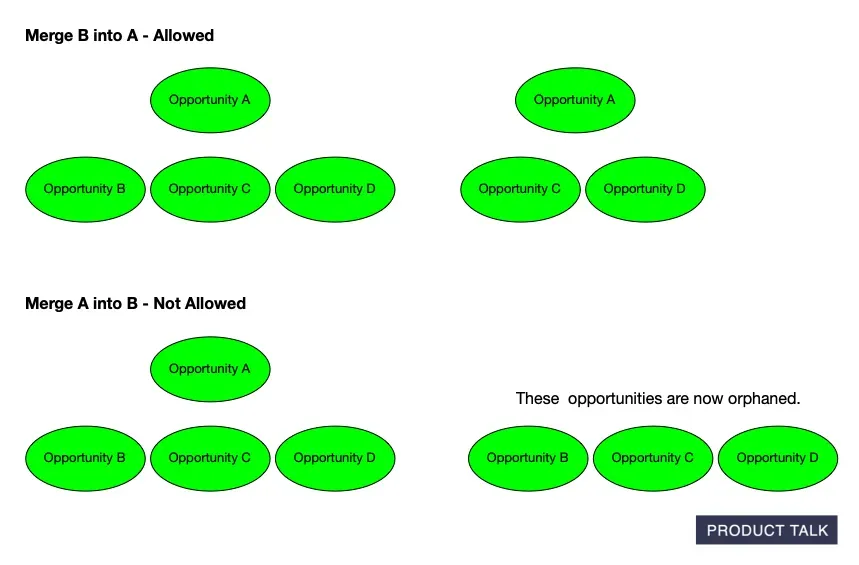
Category 1 felt like designing a game while the model played it creatively. For example, what happens when the model tries to merge a parent with a child? If opportunity A has children B, C, and D and the model merges A with B, the merge is directional. If the instruction is “keep A, delete B,” that works—the parent absorbs the child. But if the instruction is “keep B, delete A,” then C and D become orphans. These puzzles were solvable and even fun.
Category 2 was harder. Despite prompt iterations, I could only push the discrepancy rate down to about 1 in 40 instances. With 10–20 LLM calls per run, that meant roughly half of all runs still failed. Not acceptable for production. I hit a wall. A paying customer was waiting, and more design partners were queued up.
Next, I tried to correct the model’s mistakes with deterministic code. I had promised that my change sets would generate the output tree, so I wrote verifiers: detect conflicts (e.g., delete a node, then try to use it later), guard against data loss, prevent orphaned nodes, and more. Detection was straightforward; correction was not. Fixing issues required guessing the model’s intent. If the sequence said “delete A, then merge A with B,” should I remove A entirely or salvage A’s sources and children by merging into B? There were dozens of such cases with no unambiguous answer.
After 11 straight days of deep work—including weekends—I was exhausted. I dislike hustle culture; this isn’t how I design my life. But I was stuck, and then I had an insight.
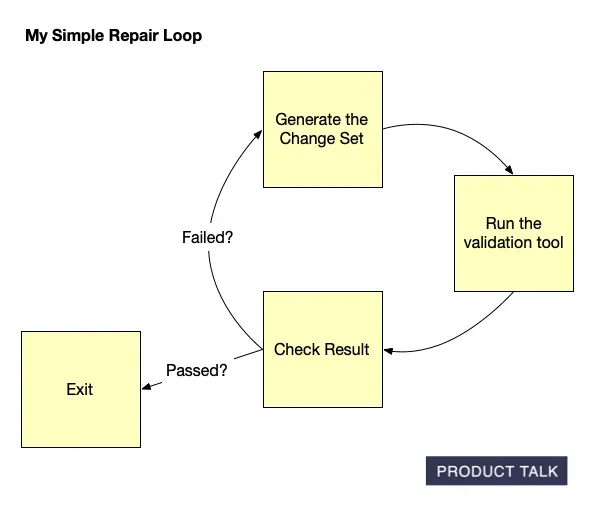
On a walk with my husband (also an engineer), I realized I could have the LLM repair its own mistakes. My data contract with Vistaly requires that the change set must generate the output tree. I had already built robust validation code. I knew exactly when a change set failed—and why. No amount of prompt tuning alone was fixing it. So I turned the validator into a tool for the model and created a simple agentic loop.
The loop works like this: the model proposes a change set, calls the validation tool, and gets back a pass/fail plus specific feedback. If it fails, the model uses those instructions to repair the change set and calls the tool again. Iterate until success or a max number of turns.
I prototyped in Node.js with a single model call, a verifier pass, and a repair attempt. At first, the loop didn’t converge—it just accumulated compute. I experimented with how to communicate errors, how much context to include, and how to sequence feedback. Eventually, it clicked: the model began fixing its own mistakes and typically returned a valid change set in one or two repairs. It was, in practice, eval-driven development applied to LLM outputs.
I had already built an agent loop utility for another AI workflow, so I productionized quickly: model call, optional tool invocation, tool result returned to the model, repeat until the validator signals success or the loop times out. I integrated the new loop into the pipeline and shipped the revamped service to Vistaly on Monday at noon. They’re integrating now, and it will be in the hands of our design partners shortly. I’m relieved—and ready for a day off.
Reflecting on the last two weeks, a few things stand out. First, I shed limiting beliefs about being an engineer. To make this reliable, I had to solve legitimately hard problems, and that feels good.
Second, this was genuinely fun. Designing the action set and watching the model push those boundaries was like working through elegant puzzles. Models are incredibly creative, and harnessing that creativity with the right constraints is deeply satisfying.
Third, I learned when I can and can’t trust Claude to write code for me. Since Opus 4.6 came out, I gave Claude a much longer leash. After the past two weeks, Claude is back on a short leash. I found a lot of gaps in my implementation in areas where I simply trusted that Claude got it right, when in fact it didn’t. If you don’t have the right infrastructure—planning, testing, code review—this can be disastrous. I’ll be investing more here and sharing what I learn.
Finally, if this work had been spread over two months, it would have been thoroughly enjoyable. I’m discovering how much I like being an AI engineer. It feels like a new chapter where I can combine opportunity solution trees with modern AI engineering—and deliver real value to product teams doing continuous discovery.
I’m excited to share more of what we’re building with Vistaly and to onboard more design partners soon. If you’re interested, get on the waiting list. And if you’ve been hesitant to stretch beyond your current skill set, I hope this story nudges you to take the first small step toward what’s just now possible.
Inspired by this post on Product Talk.











Leave a Reply