Shipping great products is a game of making high‑quality decisions under uncertainty. In my role leading product management, I’ve seen teams stall when classic methods demand huge sample sizes before we can say anything useful. Bayesian statistics has become my go‑to approach for turning sparse data into clear, decision‑ready insights—especially when traffic is limited or experimentation windows are tight.
Understand Bayesian statistics vs. frequentist methods and learn how Bayesian approaches improve experiment insights with small sample sizes.
Here’s why I rely on it in A/B testing: frequentist methods focus on p‑values and long‑run error rates, which are tough to translate into action. With a Bayesian lens, I can express outcomes as intuitive probabilities—“Variant B has a 92% chance to outperform A”—and use credible intervals to communicate likely ranges of impact. That clarity reduces decision friction and helps the team move faster with confidence.
Bayesian methods shine when sample sizes are small and the minimum detectable effect (MDE) of a frequentist test would be impractically large. I incorporate prior knowledge—historical conversion trends, seasonality, and learnings from related experiments—to stabilize noisy early data. Done thoughtfully, priors improve estimate quality without overfitting; I always run sensitivity checks to ensure the posterior is driven by the data we’re observing, not wishful thinking.
In practice, my workflow is straightforward. I set a prior from historical performance in Amplitude analytics, run the experiment, and update the posterior daily. I track the probability of superiority, expected lift, and a credible interval that the CRO role can rally around. When the probability of a meaningful win crosses a pre‑agreed threshold, we ship. When it doesn’t, we bank the learning and move on—no prolonged debates about p‑values that few stakeholders truly understand.
This approach also strengthens product discovery. By using behavioral analytics and retention analysis as informative priors, I can evaluate early signals from narrower cohorts—new geographies, niche segments, or enterprise accounts—where traffic is scarce. The result is faster iteration in product‑led growth environments, even when a full‑funnel test would take weeks to reach frequentist significance.
Operationally, I treat Bayesian experimentation as part of a unified analytics platform strategy. The same posterior machinery that powers A/B testing can support anomaly detection during releases, quantify risk in phased rollouts, and estimate lift from in‑app guides or product tours. Because results are framed in plain language probabilities, cross‑functional teams make better, faster decisions aligned to outcomes rather than outputs.
A few guardrails keep me honest. I preregister decision rules (stop/go thresholds, guardrail metrics), run prior sensitivity analyses, and document assumptions alongside results. That discipline prevents overconfidence, improves reproducibility, and builds trust with leadership.
If your experiments are bottlenecked by low traffic or you’re tired of waiting weeks for a binary “significant/not significant,” consider a Bayesian upgrade. You’ll get earlier readouts, clearer stakeholder communication, and a repeatable path to compounding learning—without sacrificing rigor.
Inspired by this post on Amplitude – Perspectives.
“Is product management dead?” I hear this question at almost every conference hallway chat. After listening to the latest Product Builders – All Things Product Podcast with Teresa Torres & Petra Wille, I’m more convinced than ever: product management isn’t dead—it’s evolving fast, and the leaders will be those who embrace the shift.
Listen to this episode on: Spotify | Apple Podcasts
The core take resonated deeply with my day-to-day at HighLevel: product management isn’t dying—“the traditional product trio (PM, design, engineering) is collapsing into something new.” The center of gravity is shifting from swim lanes to outcomes, from rigid handoffs to fluid collaboration, and from role definitions to capabilities that actually ship value.
AI is raising the baseline across the board. That “80/20 shift: AI handles patterns, humans handle hard problems” is real on my teams. With LLMs like “GPT 5.2” and “Opus 4.5,” coding agents such as “Claude Code” and “Codex,” and tools like “Replit” and “Lovable,” we’re compressing cycle time on the repeatable 80%. The bottleneck is no longer typing code or drafting copy—it’s selecting the right problems, crafting sharp product strategy, and making confident trade-offs.
This is why the future belongs to “product builders” — people with a shared foundation across disciplines and deep expertise in one area. I look for teams that can shape, prototype, validate, and iterate in tight loops, blending continuous discovery with empowered product teams. The baseline expands, the craft deepens.
Functional expertise still matters—more than ever—because the hard parts are getting harder. We need leaders who can weigh platform scalability against time-to-value, protect privacy-by-design, apply AI risk management, and navigate data governance while sustaining product-market fit. When AI accelerates execution, judgment becomes the differentiator.
For leaders, this creates a clear mandate: “What product leaders must do to create safe AI infrastructure.” In practice, that means building guardrails early—security reviews tailored to AI workflows, QA harnesses that include eval-driven development, model performance observability, and human-in-the-loop review systems. You can’t bolt this on later without paying a tax in velocity and trust.
Hiring signals are already shifting. “How job descriptions and hiring expectations are already shifting” shows up in my reqs: we emphasize cross-functional range, fluency with AI workflows, prompt engineering literacy, and the ability to frame measurable outcomes. We still want craft depth—design systems, systems thinking in engineering, rigorous discovery—but we prize people who move seamlessly from discovery to delivery.
In the episode, I appreciated the crisp framing of why product management isn’t dying—but changing. The rise of the “product builder” foundation reframes team topology and unlocks smaller, more cross-functional squads. AI changes the baseline skill set across product teams, and ignoring it is a career risk. If you’re not learning AI tools, you’re falling behind.
My key takeaways were straightforward and actionable. Smaller, more cross-functional teams are likely. Deep expertise still matters—especially for complex trade-offs. Leaders need guardrails: security, QA, and review systems built for an AI-driven workflow. And if you work in product, design, or engineering, this episode is your signal to start upskilling now.
“The risk of ignoring AI in your craft” is not hypothetical. I encourage PMs to carve out weekly lab time for hands-on experiments with LLMs for product managers, build lightweight prototypes with Replit or Lovable, and pressure-test opportunity solution trees with data-informed discovery. Pair with your engineers on agentic AI use cases, and integrate model evals into your CI/CD pipelines.
“Mentioned in the episode” were several resources worth exploring: “Product at Heart” (June, Hamburg), “Replit,” “Lovable,” “Every,” “Petra’s Coaching Packages,” and “coding agents (Claude Code, Codex) and LLMs (GPT 5.2, Opus 4.5).” These are great jumping-off points for your own product builder toolkit.
My recommendation: queue up the episode on your commute, then pick one workflow to augment with AI before the week ends. Replace a handoff with a shared canvas. Automate a repetitive analysis. Ship a scrappy prototype. Momentum compounds.
Have thoughts on this episode? Leave a comment below. I’d love to hear how your teams are evolving your product trios, what AI workflows are sticking, and where governance has been most challenging.
PR review bots are all the rage, but they cost a premium. We built our own for cheap that work just as well, if not better. Here's how.
As a VP of Product Management, I care deeply about the velocity and quality of our software delivery. The decision to build our own pull request (PR) review agents came from a simple calculus: we needed tighter control over developer experience, CI/CD integration, and cost—without sacrificing accuracy or reliability. The result was a pragmatic system that accelerates reviews, improves code quality, and pays for itself through faster feedback loops.
Before we wrote a line of code, we defined success. Our objectives were to shorten review cycles, reduce back-and-forth on style and test coverage, and surface risks earlier—measured against DORA metrics like lead time and deployment frequency. That focus aligned the team, guided our build vs buy decision, and anchored scope to the highest-impact use cases.
We started rules-first, AI-optional. The initial release enforced guardrails that are universally valuable: linting and formatting checks, required test coverage thresholds, commit message standards, ownership validation (CODEOWNERS), and basic security scans. These automated gates eliminated predictable review friction, freeing engineers to focus on logic and architecture rather than style debates.
Then we layered intelligence where it mattered. We added lightweight, explainable checks for common code smells and dependency risks, plus optional natural-language summaries that turn large diffs into concise context. Where appropriate, we introduced agentic AI workflows to triage PRs by risk, draft review comments, and suggest missing tests—always keeping humans in the loop. This hybrid approach kept costs low and outcomes high.
Integration with our CI/CD pipeline was non-negotiable. We wired GitHub/GitLab webhooks to a stateless service that queued work, executed checks in containerized workers, and posted results back as status checks and review comments. Caching, parallelization, and smart diff-scoping ensured we only computed what changed, keeping the experience snappy even on large repos.
Adoption hinged on developer experience. We made the bot’s feedback fast, specific, and actionable, with clear remediation steps and links to documentation. Feature flags allowed teams to opt into new checks gradually. ChatOps commands enabled quick overrides for emergencies, while policy-as-code kept rules visible, versioned, and auditable.
We treated this like any product: eval-driven development for accuracy, ongoing telemetry for false-positive rates, and explicit SLAs for response times. We instrumented outcomes end-to-end—tracking PR cycle time, comment-to-merge ratios, and rework—so we could prove the ROI and tune the system without guesswork.
The outcome: a reliable PR review companion that runs on a shoestring budget, integrates cleanly with our workflows, and measurably improves engineering throughput. If you’re weighing build vs buy, start small with rules that deliver immediate value, then layer intelligence where it earns its keep. With a clear product strategy, you can stand up capable PR review bots quickly—and scale them as your needs grow.
If you’re ready to try this yourself, begin with your top three friction points in code reviews, wire them into your CI/CD checks, and pilot with a single team. Iterate weekly, measure relentlessly, and let your developers be your strongest signal. You’ll be surprised how far a pragmatic, product-led approach can take you.
Inspired by this post on Amplitude – Perspectives.
In my role leading product management at HighLevel, I study the architectures and operating models behind high-velocity learning. I often reference "Amplitude's MCP server and its experimentation platform" as a benchmark for how to operationalize scale, reliability, and speed of insight across complex product ecosystems. That lens informs how I design processes, data flows, and decision loops that turn ambiguity into measurable outcomes.
Experimentation is the heartbeat of eval-driven development. In practice, that means running disciplined A/B testing, deploying targeted feature flags to de-risk rollouts, and sizing experiments with a clear minimum detectable effect (MDE) so we avoid vanity wins. When teams internalize these habits, we shift from opinion-led debates to evidence-led decisions—and that’s where product-led growth compounds.
I'm an AI enthusiast, so I think a lot about how experimentation accelerates AI roadmaps. The same rigor that validates UI changes should govern prompts, retrieval strategies, and policy settings for LLM-backed features. By treating AI behaviors as first-class experiment surfaces—and tying them to user activation, retention analysis, and value proposition metrics—we move faster without compromising safety, privacy-by-design, or customer trust.
Making this work in production demands clean instrumentation and a unified analytics platform. I look for stacks that combine Amplitude analytics with robust observability and CI/CD to ensure we can ship, measure, and iterate continuously. When platform scalability and data governance are baked in from the start, product trios can focus on product discovery rather than firefighting pipelines or reconciling metrics.
My playbook is straightforward: define decision-worthy questions, map them to crisp success metrics, run right-sized experiments with feature flags, and use consistent analytics to close the loop. Do this well, and you create a durable advantage—faster learning cycles, sharper product positioning, and a culture that lives by outcomes over output. That’s the real lesson I take from platforms that execute experimentation at scale: process and technology are table stakes; what wins is the discipline to learn relentlessly.
Inspired by this post on Amplitude – Perspectives.
I just watched one of the most significant leaps in customer service AI in years. Last week, a quiet but seismic release landed in CX: Fin introduced Apex, a vertical model purpose-built for support that raises the bar on speed, accuracy, and cost. As a product leader, this is exactly the kind of breakthrough that changes roadmaps, vendor strategies, and what customers can expect from modern service operations.
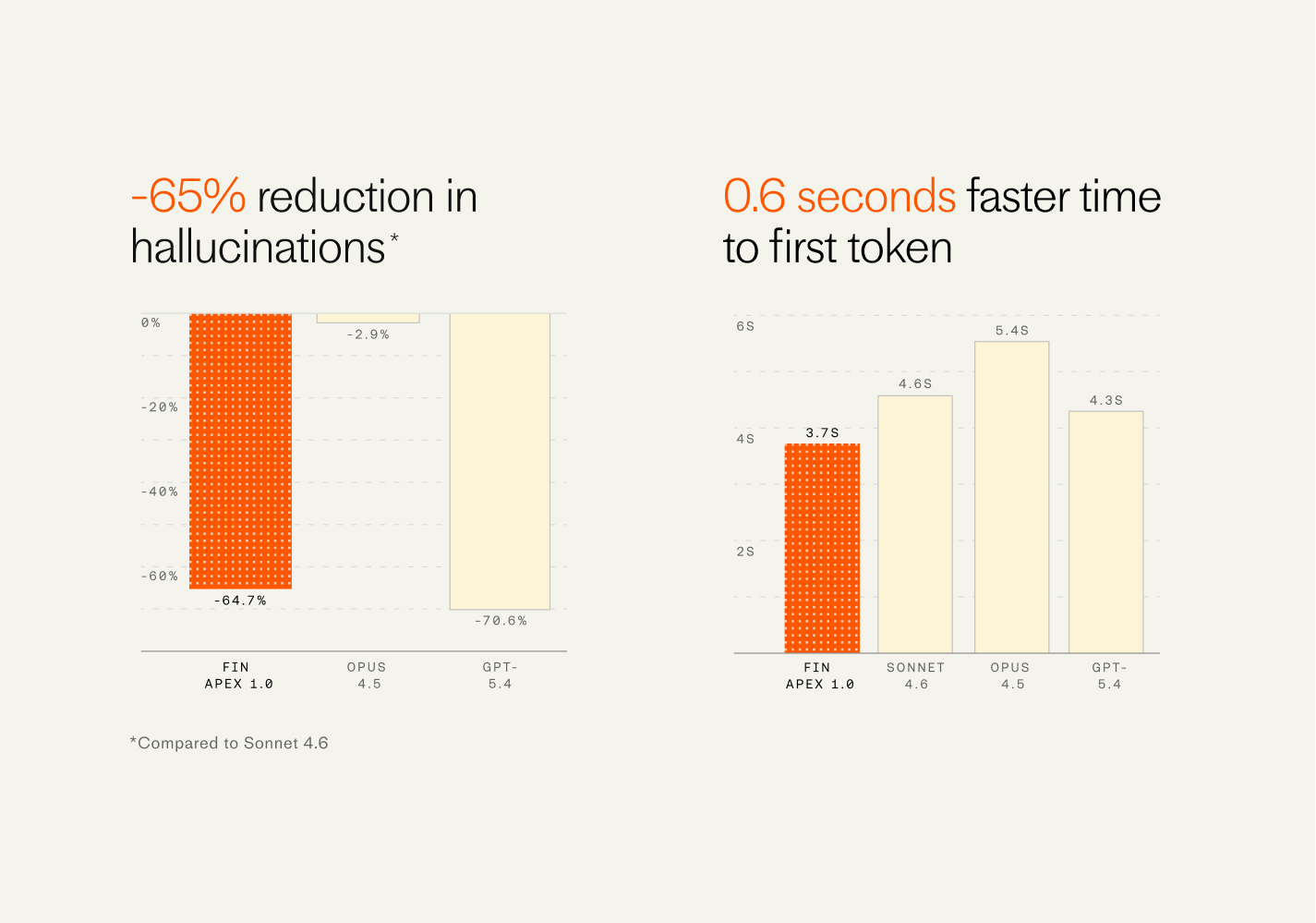
It’s a brand new model for Fin called Apex, and it’s objectively the highest performing, fastest, and cheapest model for customer service. It beats the very best models in the industry including GPT-5.4 and Opus 4.5.
In this analysis, I’ll unpack why the launch matters for the customer service agent category, what it signals for frontier labs and open‑weight ecosystems, and how leaders should rethink their AI Strategy, build vs buy decisions, and eval-driven development roadmaps.
Fin was already the highest performing and most sophisticated agent in the customer service space, consistently beating impressive competitors like Decagon and Sierra at an average win rate in the 70s. It operates at tremendous scale, now resolving almost 2M customer issues per week, a number that’s growing at an exponential clip. In its short life it’s grown to nearly $100M in recurring revenue.
As of last week, ~100% of all (English language, chat and email) customer conversations are now running on Apex. Since day 1, the Fin engine has comprised a system of models, and last year the team began replacing off‑the‑shelf models with custom ones trained on proprietary data. The core answering model had been a frontier labs offering—initially versions of GPT and more recently Sonnet 4.0. Now, that core answering model is Apex 1.0.
This model resolves customer issues at a materially higher rate than any other model available. One of their largest customers in the gaming space saw the resolution rate improve overnight from 68% to 75% (i.e. a reduction in unresolved conversations of 22%). The team notes they had never seen a jump this large from a single improvement since they started Fin.
Just as important, it’s dramatically faster, has fewer hallucinations, and is far cheaper than other available models—exactly the attributes operations leaders weigh most when deploying agents at scale. In practice, these are the levers that unlock higher CSAT, tighter SLAs, and better unit economics.
Achieving all three simultaneously is extraordinarily hard. Credit goes to foundational research from a 60‑person AI group run by Fergal Reid, and, crucially, to domain‑specific proprietary evals drawn from billions of human and agent interactions produced by the Fin resolution engine—already hand‑tuned to be the most effective in the category. That creates a flywheel: an eval‑driven development loop that trains models to keep improving at the edge of the system’s abilities. In other words, Apex 1.0 looks like the tip of the iceberg.
Zooming out, service is one of the few categories where generative AI has already delivered commercial impact at scale (alongside coding, and arguably the legal industry). With TAMs measured in the hundreds of billions, competition is intense and well capitalized. The pattern I’ve seen repeatedly is clear: winners in these spaces must become full‑stack AI companies. As features become ~free to build, durable competitive differentiation shifts under the hood—to proprietary data, post‑training, inference efficiency, and the quality of the eval loop.
Fin Apex raises the bar for finance-ready AI, highlighting a -65% cut in hallucinations and a quicker first token at 3.7s (0.6s faster), compared with Sonnet 4.6, Opus 4.5, and GPT-5.4 in side-by-side charts.
That’s why competitors will need to release their own models. Many appear to be just starting to hire the talent to do so, which likely gives Fin at least a year of head start. For product leaders, this is a strong signal to revisit build vs buy assumptions, and to quantify when owning your post‑training pipeline and evals becomes the rational move.
Honestly, 2–3 years ago I expected AI application differentiation to live mostly in what we built around third‑party models. The AI game humbles all of us; today it’s obvious that vertical models paired with proprietary evals create compounding moats.
In a podcast interview last week, Andrej Karpathy said:
"I do think we should expect more speciation in the intelligences. The animal kingdom is extremely [diverse] in the brains that exist. And there’s lots of different niches of nature… And I think we should be able to see more speciation. And you don’t need this oracle that knows everything. You kind of speciate it. And then you put it on a specific task. And we should be seeing some of that because you should be able to have much smaller models that still have the cognitive core."
The frontier labs still have the very best models, but open‑weight models aren’t far behind—making pre‑training look increasingly like a commodity. The frontier is moving to post‑training, which is precisely what we see with Apex (and Cursor’s Composer 2), and what we should expect to dominate going forward.
Labs now face a dual reality. On one hand, horizontal general‑purpose models can over‑serve specific verticals (e.g., customer service doesn’t need an oracle that knows everything). On the other, open‑weight models are good enough that high‑quality, domain‑specific post‑training can produce superior models for special‑purpose jobs—and in the ways that matter for those jobs. In service, soft factors like judgement, pleasantness, and attentiveness matter alongside hard factors like resolution effectiveness, speed, and cost.
I’m still bullish on the labs. Many organizations remain heavy customers of Anthropic—whether as part of multi‑model systems or through deep usage of Claude Code in engineering teams (see this example of Claude Code adoption). Yet classic disruption (à la the late, great Clay Christensen) is now at their door. The way out is to disrupt themselves by building cheaper specialized models too, which likely requires acquiring the evals—or the companies with the evals—needed for each task. Expect creative data partnerships, M&A consolidation, and a wave of hyper‑specific model providers that compete head‑to‑head with the labs.
In the meantime, Fin appears to be the only vendor in its space with a custom model that’s also objectively superior to everything else out there. I’m excited to see it deployed broadly for end customers, and I’m watching closely for the next announcement that will accelerate that rollout. For product leaders, the message is clear: the age of vertical models and agentic AI is here—bring your evals, or bring your checkbook.
Making the leap from engineer to CEO demands an almost entirely new skillset. I’ve felt that jolt firsthand: the tools that serve you as an IC or even a product leader—system design, crisp PRDs, elegant roadmaps—only get you about 20% of the way. The rest is learning to orchestrate go-to-market strategy, finance, hiring, culture, and product positioning with just enough depth to make sound, fast decisions while empowering true experts to execute.
My operating heuristic is the 80% rule. As CEO or GM, I don’t need to be the best marketer, seller, or finance leader; I need to understand 80% of each function well enough to set a compelling product strategy, ask the right questions, and catch the second-order effects. That breadth unlocks speed, quality of judgment, and the conviction to say no when the organization is tempted by what it can do rather than what it must do.
The clearest illustration comes from the journey that turned Apache Kafka—originally built at LinkedIn—into Confluent, a publicly traded enterprise software company. The technical insight was powerful, but the real lift came from translating that insight into a repeatable go-to-market engine. That required building new muscles: founder-led GTM, enterprise sales orchestration, and open source monetization without alienating the community that fueled adoption.
Early on, the product was “embarrassing” by enterprise standards—thin features, sharp edges, and a long tail of operational gaps. Shipping anyway was the point. A thin vertical slice into the market created learning loops with real customers, not hypotheticals. That uncomfortable speed became a superpower, especially when the company decided to push toward a cloud-first business in the face of widespread opposition.
The messaging challenge was just as hard as the technical one. Most marketing fails because it starts with what we built, not what customers must achieve. A simple product marketing pyramid—vision at the top, category framing and points of parity in the middle, crisp value props and proof at the base—helped explain Kafka to the world in customer language. When the narrative snaps into place, adoption accelerates. In Kafka’s case, one well-timed blog post clarified the “why now” and unlocked a step-change in community and enterprise pull.
There’s a pivotal distinction leaders underestimate: the gap between what a company can do and what it must do. I use a must-do filter before every planning cycle: What moves are non-discretionary for durable product-market fit? For Kafka and Confluent, that meant ruthless prioritization on managed cloud services, reliability, and platform scalability—even when it jeopardized short-term revenue or required retooling how engineering, sales, and support worked.
Fundraising strategy mirrored this clarity. Planning to raise before building the full product wasn’t about hype; it was about matching capital to the physics of the problem. If your category requires enterprise credibility, global infrastructure, and 24/7 SRE, you finance those table stakes early. That’s first principles decision making: instrument the constraints, then design the sequence that gets you to scale with the fewest irreversible mistakes.
In the early years, every product decision felt like a trade between polish and learning. The team essentially bludgeoned its way into a cloud-first posture—less because the initial product was ready, and more because the market’s must-do was obvious. That’s the essence of founder-led GTM: get into the field, close lighthouse customers, and use their arcs to shape the roadmap. It’s also where open source monetization matures from downloads into durable, enterprise value.
As the organization scales, excellence often erodes—the Chipotle problem. Process hardens; quality blurs; the magic decays. The antidotes are simple but hard: a few non-negotiable product quality bars, a short set of product-market fit metrics that everyone can recite, and empowered product teams who own outcomes over output. This is where organizational development matters as much as code: design clear interfaces between product, sales, and success, and you’ll keep velocity without losing standards.
Contrary to popular lore, founder optimism is overrated. Constructive realism wins. I try to model “probabilistic optimism”: assume we will win, but instrument the journey like an SRE runs an incident. Set leading indicators, rehearse failure modes, and make pre-commitments to the must-do path so you’re not swayed by the latest anecdote. It keeps the team out of a failure mindset while making room for rigorous course correction.
Giving up the right things at the right time is a CEO superpower. As complexity grows, I hand off decisions that benefit from specialization and keep only those tied to company narrative, must-do prioritization, and talent bar. CEO time management becomes a portfolio problem: ensure each week contains deep product time, frontline customer exposure, and one compounding systems fix (hiring loop, pricing rubric, or GTM enablement) that pays back for quarters.
If you’re moving from IC or PM into a GM/CEO role, here’s a practical playbook: build your product marketing pyramid; write the one-page must-do memo for the next six quarters; ship a narrow, managed cloud slice early; pick three product-market fit metrics (usage, time-to-value, retention) and publish them company-wide; and architect an enablement engine that turns field learnings into roadmap changes within one quarter. That’s how you transform technical advantage into a category-defining business.
The Kafka-to-Confluent arc reminds me that technology can open a door—but clarity of narrative, sequencing, and must-do focus determines whether you walk through it. When in doubt, bias toward shipping, talking to customers, and tightening the loop between what you learn and what you build. That’s the work of product management leadership at scale.
I’ve curated a focused set of product marketing insights that zero in on what actually moves the needle—turning data into decisions. You’ll find a special emphasis on Amplitude Analytics, because its behavioral analytics foundation makes it easier to translate product usage into clear messaging, sharper positioning, and measurable growth.
In my day-to-day as a product leader, I’m constantly bridging the gap between product discovery and go-to-market strategy. The best outcomes come when we connect quantitative signals to narrative: using behavioral analytics to inform the value proposition, refining product positioning with cohort trends, and driving product-led growth with activation and retention insights.
Here’s how I put this into practice. I start with user activation and retention analysis to identify the few behaviors that predict long-term value. Then I run tightly scoped A/B testing to validate messaging and in-product prompts that nudge those behaviors. When the numbers move, I translate wins into a consistent story—one that sales, success, and marketing can all rally around.
One pattern keeps repeating: clarity beats complexity. Instead of piling on more features, I focus on the minimum, verifiable set of behaviors that correlate with outcomes. That discipline makes it easier to craft a crisp value proposition, streamline go-to-market strategy, and accelerate feedback loops between product, design, and marketing.
As you explore this collection, expect practical playbooks over platitudes. You’ll see how to apply Amplitude Analytics to uncover hidden friction, validate hypotheses faster, and operationalize product-led growth motions that compound over time. My goal is to help you move from interesting dashboards to decisive actions that strengthen your roadmap and your revenue.
If you care about building empowered product teams that learn continuously, you’ll feel at home here. Dive in, borrow what works, and adapt the rest to your context—then measure it, iterate, and share the wins with your team.
Inspired by this post on Amplitude – Best Practices.
Your AI agent can resolve more conversations while customer experience quietly becomes harder to trust. A ticket marked resolved can still contain an inaccurate answer, a skipped process step, a repetitive loop, or an escalation that arrived too late.
As the product leader, you don’t have to choose between automation and judgment. You need an operating system that identifies which conversations matter, defines what good looks like, routes exceptions to the right owner, verifies fixes, and connects support quality to customer behavior.
Measure outcomes, execution quality, and coverage separately
Resolution rate is a throughput metric. It tells you how often the operation reached a terminal state, but not whether the answer was correct or the customer was treated appropriately. CSAT has a similar limitation: it captures sentiment, not conformance. Customer sentiment and adherence to your standards answer different questions, so neither should stand in for the other.
Build the dashboard around four layers. Keeping them separate prevents a good aggregate number from concealing a weak customer experience.
Whether the interaction solved the customer’s problem
Execution quality
Did the conversation meet your operating standard?
Accuracy, process adherence, clarification, escalation ease, efficiency
Whether the agent behaved correctly
Evaluation coverage
How much of the operation did you actually inspect?
Eligible, automatically evaluated, human-reviewed, and still-unreviewed conversations
How much confidence to place in the quality result
Product impact
Did better help change customer behavior?
Activation, feature adoption, retention, and journey completion by cohort
Whether the CX improvement created durable value
Read the layers together, but don’t merge them into one executive number. High sentiment with low accuracy can mean the agent sounded helpful while giving the wrong answer. A strong scorecard result with poor sentiment can expose a technically correct but difficult experience. Good conversation quality with repeated contacts may mean the product, policy, or documentation still creates the underlying problem.
The product-impact layer is especially important. A support answer may pass every conversational check without improving the journey that matters. Connect CX data to activation, adoption, and retention behavior so you can distinguish a better answer from a better customer outcome.
A simple driver tree makes that connection explicit. Start with the business result, trace it to the customer behavior that produces it, identify the journey friction blocking that behavior, and then define the AI behavior that should remove the friction. If you can’t trace a proposed quality criterion through that chain, it may be a preference rather than a requirement.
Design monitoring as a portfolio, not a random sample
A stable benchmark cohort. Evaluate a repeatable sample on a consistent schedule. Preserve the same eligibility rules and segmentation so changes in pass rate represent changes in performance rather than changes in the sample.
Risk-targeted monitors. Select conversations with signals that deserve deliberate review. Examples include a customer showing signs of financial vulnerability, an agent repeating essentially the same answer, a required escalation that did not happen, or a sensitive process being handled without its required checks.
Change-specific monitors. Create cohorts for a new model, prompt, workflow, tool, policy, or knowledge release. Version every relevant component so a quality change can be traced to the production change that preceded it.
Journey monitors. Group conversations by customer intent and journey stage, not just channel or queue. This exposes recurring friction in onboarding, adoption, billing, account management, and other product journeys that an operation-wide average will flatten.
Instrument every eligible conversation, but don’t assume every conversation needs human review. Automated evaluation is appropriate for high-volume, clearly defined criteria. Human judgment belongs on critical failures, ambiguous cases, disputed scores, new scenarios, and calibration cohorts. The scalable design is broad automated visibility with concentrated human attention.
Each monitor should report more than a pass rate:
Coverage rate: completed evaluations divided by eligible conversations. Never present pass rate without this denominator.
Pass rate: completed evaluations that met the scorecard standard divided by all completed evaluations.
Critical failure rate: completed evaluations that failed at least one critical criterion divided by all completed evaluations.
Unreviewed queue: qualifying conversations that have not received their required review. Break this out by risk and age rather than showing only a total.
Evaluator overturn rate: dual-reviewed cases in which a human changed the automated judgment. A rising rate can signal an ambiguous rubric, a weak evaluator, or a new conversation pattern.
Failure recurrence: previously addressed failure modes that appear again after a fix. This distinguishes completed work from effective work.
Segment these measures by AI versus human handling, journey, intent, customer segment, channel, and deployed version. One shared quality system can compare AI and human conversations against the same customer outcomes, while still assigning different operational responsibilities. Unified review across automated and human conversations also makes handoff failures visible; otherwise, each side can look healthy while the transition between them breaks.
Be deliberate about the data attached to monitoring. Store the fields needed for segmentation, diagnosis, and audit, and restrict access to sensitive conversation content. A monitoring program creates risk if it spreads personal or regulated data into dashboards that were designed only for aggregate analytics.
Turn scorecards into executable product requirements
I treat a scorecard as an executable product requirement. Each criterion should be observable in the conversation, interpretable by two independent reviewers, and connected to a specific action when it fails. Vague criteria such as helpful, natural, or on-brand produce arguments rather than reliable signals.
Build each criterion with the following fields:
Intent: the customer or business outcome the criterion protects.
Pass condition: the observable behavior that must be present.
Failure condition: the observable behavior that makes the conversation fail.
Evidence rule: the part of the transcript, tool trace, policy, or approved knowledge that supports the judgment.
Applicability: when the criterion is required and when it is not applicable.
Severity: whether failure contributes to a weighted score or overrides the entire evaluation.
Reviewer: automated evaluation, human evaluation, or both.
Remediation owner: the person or function expected to act on failure.
A practical CX scorecard usually needs criteria such as:
Accuracy: the answer is supported by approved knowledge, customer context, and tool results. Unsupported claims fail even if the customer accepts them.
Resolution and next step: the agent answers the request, clearly states what remains, or routes the customer to the correct next action.
Process adherence: required verification, disclosure, permission, and workflow steps are completed in the correct context.
Clarification: the agent asks for missing information when intent or account context is too ambiguous to answer safely.
Escalation: the agent recognizes defined handoff conditions, escalates without unnecessary resistance, and transfers the context the next agent needs.
Conversation efficiency: the agent avoids repetition, irrelevant steps, and loops while preserving the information necessary for a correct outcome.
Communication quality: the response is clear, appropriately direct, and consistent with the brand’s communication standard.
Weights help express relative importance, but a weighted average must not wash away a consequential failure. Mark accuracy, safety, security, required process steps, or other non-negotiable controls as critical where appropriate. A polite answer that gives a harmful instruction should not pass because it accumulated enough points elsewhere.
For legal, financial, safety, account-security, or regulated decisions, follow the applicable organizational policy and require human review or escalation where that policy demands it. An aggregate quality score is not authorization for an AI agent to make a decision outside its approved scope.
Automated evaluators also need calibration. They are measurement components, not ground truth. Build an adjudicated set of clear passes, clear failures, difficult edge cases, and not-applicable examples. Have human reviewers score the same cases independently, compare their reasoning with the automated result, and rewrite any criterion that allows materially different interpretations. Repeat calibration after changes to the model, evaluator, prompt, tools, knowledge, policy, or conversation mix.
Keep the evidence behind every automated judgment. A score without the relevant transcript excerpt or trace is difficult to challenge and nearly impossible to improve. Reviewers should be able to see what failed, why it failed, and which requirement governed the decision.
Make every failure end in a product decision
Quality monitoring creates value only when it changes the system. The review queue should represent work, not a museum of bad conversations. A useful workflow moves each case through explicit states such as Not reviewed, Reviewed, Needs a fix, and Fix complete.
Require the following information before a failed case leaves review:
The customer intent and journey stage.
The failed criterion and supporting evidence.
The failure class, not merely the visible symptom.
The owner responsible for the correction.
The proposed change and the signal expected to improve.
The regression case, deployment version, and monitor that will verify the correction.
A consistent failure taxonomy keeps teams from treating every bad answer as a prompt problem:
Knowledge failure: the approved information is missing, stale, contradictory, or too difficult to interpret.
Retrieval or context failure: the right information exists, but the system did not retrieve, rank, or apply it.
Policy or workflow failure: the operating rule is wrong, incomplete, or impossible for the agent to execute.
Model behavior failure: the system ignored instructions, made an unsupported inference, or produced an otherwise defective response despite receiving adequate context.
Conversation-design failure: the interaction collected the wrong information, asked an unclear question, or sequenced the exchange poorly.
Tool or handoff failure: an integration, action, routing rule, or transfer prevented the correct outcome.
Product-friction failure: the support interaction is a recurring symptom of something the product itself should make clearer or eliminate.
This taxonomy changes prioritization. If the same onboarding question keeps passing through support, improving the answer may reduce handling friction but preserve the underlying product problem. Journey mapping, behavioral analytics, and in-product guidance can reveal whether the better fix belongs in the interface, workflow, documentation, or agent.
Close each failure through a controlled loop:
Reproduce it. Confirm the failure and preserve the relevant inputs, context, versions, and tool behavior.
Diagnose it. Assign a cause from the shared taxonomy and identify the owner with authority to change that component.
Correct it. Update the product, knowledge, retrieval logic, prompt, workflow, policy, integration, or escalation rule that caused the defect.
Test it. Run the original failure and nearby cases that should remain unchanged. Add the sanitized case to the regression set where appropriate.
Deploy it with versioning. Preserve enough release context to compare behavior before and after the change.
Verify it in production. Watch the targeted monitor, baseline quality, and associated customer behavior. Close the case only when the expected signal improves without creating a new failure elsewhere.
Bring this loop into a regular operating review. Inspect coverage first, then critical failures, the largest changes by segment and version, queue health, recurring causes, completed fixes, and downstream customer behavior. The meeting should end with product decisions: roll back a change, revise knowledge, alter a workflow, strengthen an escalation, change the interface, expand monitoring, or explicitly accept a known limitation.
Assign ownership before volume grows. CX and support leaders can define service standards; product leaders can connect recurring friction to roadmap decisions; AI and engineering owners can maintain instrumentation, evaluators, and regression tests; analytics can connect interactions to behavioral outcomes; and security, legal, or compliance owners can approve critical controls in their domains. Your organization may divide the roles differently, but every critical criterion and failure class needs a named decision owner.
Key takeaways
Resolution rate measures throughput, not whether an AI interaction was accurate, compliant, or useful.
Track customer sentiment, execution quality, evaluation coverage, and product impact as separate layers.
Combine a stable benchmark cohort with risk-targeted, change-specific, and journey-based monitoring.
Show pass rate with coverage and critical failure rate. A strong score over thin or biased coverage is weak evidence.
Write scorecard criteria as executable requirements with pass conditions, failure evidence, severity, reviewer type, and remediation ownership.
Use automated evaluation for breadth and human judgment for calibration, ambiguity, disputes, and consequential failures.
Don’t close a quality issue when a document or prompt changes. Close it after the deployed fix passes regression checks and improves the intended production signal.
Route recurring conversation failures into product discovery. Sometimes the best CX fix is removing the reason customers need to ask.
Start with one journey that combines meaningful volume with meaningful consequence. Give it an eligibility rule, a scorecard, explicit coverage, a review queue, a failure taxonomy, named owners, regression cases, and a downstream product outcome. Run that chain until failures reliably produce verified changes, then extend the same control loop to the next journey. Scalable quality comes from repeating a dependable operating system, not from adding another dashboard.
Your healthcare AI prototype works in a demo. Clinicians see potential. Then privacy, security, compliance, and legal reviewers ask questions the roadmap cannot answer: Which data crosses the model boundary? What happens when the output is wrong? Who can stop it? What evidence justifies exposing it to patients or providers?
The answer is not a longer policy document. You need a delivery system in which the use case, data boundaries, acceptable behavior, evidence, and rollback path are inspectable before anyone depends on the product. That system lets you move faster because each review produces a decision instead of another round of open-ended concerns.
Key takeaways
Start with the decision or action the AI will influence, not the model you want to deploy.
Keep identifiers in clinical systems by default and send only the behavioral or operational signals a downstream system genuinely needs.
Put success metrics, unacceptable behavior, human review, and stop conditions in the same release contract.
Move from synthetic or de-identified sandbox testing to a tightly controlled pilot, then scale only when the agreed evidence supports it.
Monitor model behavior, workflow performance, segment outcomes, data quality, and incidents as one production system.
Define the clinical boundary before choosing the AI approach
A vague use case such as improving patient engagement is almost impossible to evaluate responsibly. It does not identify a user, a decision, an action, or a credible failure. The first useful artifact is a use-case card that makes those boundaries explicit.
Complete these fields before discussing vendors, models, or architecture:
User and job: Name the person using the capability and the task that person is trying to complete.
Input: List the information required to perform the task. Separate essential inputs from data that is merely available.
Output: Define what the system produces: a summary, draft, recommendation, prediction, classification, or action.
Action authority: State whether the AI informs a person, proposes an action for approval, or executes an action itself.
Unacceptable outcome: Describe the failure that must not reach the user, patient, provider, or downstream system.
Human checkpoint: Identify who reviews the output, what that person can see, and how the person can reject or correct it.
Success measure: Name the workflow outcome that should improve, such as task completion, time-to-first-value, or sustained adoption.
Accountable owner: Name the person who can approve the use case, pause it, and accept or reject residual risk.
The action-authority field is especially important. A system that drafts text for a qualified person to review has a different failure surface from one that sends the text automatically. A recommendation that a clinician can inspect is different from an action that changes a care workflow without an intervening decision. If the team cannot describe that distinction, it is too early to approve a production design.
I use a simple product-risk ladder during intake:
The AI summarizes or drafts, and its output has no effect until a qualified person reviews it.
The AI recommends a next step, but a person must make and record the decision.
The AI executes a reversible administrative action within a tightly bounded workflow.
The AI influences a care pathway, patient communication, or another consequential decision.
The AI executes a consequential or difficult-to-reverse action without prior human approval.
This ladder is a product-triage device, not a legal or clinical classification. Your qualified clinical, privacy, security, compliance, and legal owners still need to determine the obligations that apply. Its purpose is to prevent a low-risk drafting assistant and a high-consequence decision system from passing through the same generic review.
Once the boundary is clear, choose the least complex mechanism that can deliver the outcome. Conventional automation may be enough for deterministic rules. Retrieval may be appropriate when the primary job is finding and grounding information. An agentic workflow introduces additional action authority and therefore needs stronger controls. Selecting among conventional automation, a retrieval-first pipeline, and agentic AI should follow the use case, its failure modes, and its lifecycle requirements.
Apply the same discipline to build-versus-buy decisions. Do not reduce the choice to feature coverage or procurement cost. Evaluate who can control data handling, model and prompt versions, evaluation, incident response, observability, and future changes. A vendor can supply technology, but it cannot own your product decision or your duty to operate the resulting workflow responsibly.
Make the data boundary reviewable, not merely promised
Privacy-by-design becomes real when a reviewer can trace each field from its origin to every place it is processed, logged, measured, retained, and deleted. A sentence saying the product is secure is not a data-control mechanism.
Start with a data-flow map that covers the entire operating path:
The clinical or operational system where the data originates.
Any transformation, minimization, masking, or de-identification step.
The application, retrieval layer, model, or external service that processes it.
Prompt, response, diagnostic, and application logs.
Behavioral analytics and product dashboards.
Human-review, support, escalation, and incident queues.
Long-term storage, retention, deletion, and backup paths.
For every step, record the purpose, permitted fields, prohibited fields, access roles, retention rule, downstream recipients, and owner. If a field has no necessary purpose, remove it before debating how to secure it. Data minimization reduces both the risk surface and the number of controls the team has to maintain.
Do not assume data is de-identified merely because a visible name or patient identifier has been removed. Combinations of fields, free text, prompts, model responses, URLs, error messages, and support attachments can still disclose sensitive information. Have the designated privacy and legal owners determine whether the transformation meets the applicable requirements. If they cannot verify it, keep the data inside the approved clinical boundary or use synthetic data for development.
Behavioral instrumentation needs its own contract. For each event, define:
The event name and the exact behavior it represents.
The allowed properties and the business purpose of each property.
Explicitly prohibited identifiers, clinical text, and other sensitive payloads.
The application and workflow versions that generate the event.
The owner who approves schema changes.
Validation rules that reject or quarantine malformed events.
The metric definitions and dashboards that consume the event.
This is governed analytics in operational form. Curated events, certified metric definitions, role-based access, lineage, and change control create a shared, auditable view for product, data, security, and compliance. They also prevent a quieter product failure: two teams using the same metric name for different behaviors and making incompatible release decisions.
Apply comparable scrutiny to an external provider. Ask what data the provider processes, where it is stored, whether inputs or outputs can be used for training, what is logged, how long each artifact is retained, how deletion works, who can access it, which subprocessors receive it, how tenants are separated, and what happens during an outage or security incident. Route the answers to the people responsible for contractual, security, privacy, and regulatory assessment. Product should own the use-case decision, not silently treat vendor approval as proof that every use is approved.
Convert responsible AI into a release contract
Responsible AI fails as a delivery practice when responsibility is expressed only as principles. A team needs observable release criteria: the behavior it expects, the behavior it prohibits, the evidence it will collect, and the condition that stops the launch.
Put those criteria in one release contract shared by product, engineering, data science, clinical leadership, security, privacy, and compliance. The exact metric thresholds will vary by use case, so the accountable owners must set them before the pilot produces results. A threshold chosen after seeing the data is an explanation, not a gate.
Release layer
Define before the pilot
Evidence to collect
Do not proceed when
Product value
The user task and expected workflow improvement
Task completion, time-to-value, adoption, abandonment, and sustained use
The feature creates activity without improving the intended task
Model behavior
Expected responses, prohibited responses, escalation behavior, and task-specific pass criteria
Versioned offline evaluations, human review, guardrail results, and regression comparisons
A critical safety case fails or behavior cannot be reproduced
Data quality
Required inputs, permitted schemas, freshness expectations, and lineage
Schema validation, missing-data checks, source versions, and anomaly monitoring
Inputs are stale, malformed, untraceable, or outside the approved boundary
Human control
Review point, override, correction, escalation, and rollback path
Correction behavior, overrides, escalations, and successful rollback tests
The responsible person cannot inspect, reject, or stop the output
Operational health
Acceptable latency, cost, availability, error behavior, and incident ownership
Production telemetry, alerts, version history, and incident records
Failure is silent, alerts lack an owner, or recovery depends on an untested path
Segment outcomes
The patient, provider, workflow, and operating segments that require separate review
Outcome and error variance across approved segments
Material variance is unexplained or a consequential segment lacks adequate evidence
Model quality is only one layer. A strong offline result can still produce a poor product if the workflow is slow, users cannot correct the output, input data is unreliable, or the intervention fails to improve the intended task. Connect the layers with a driver tree:
Model behavior: What must the system produce or avoid?
Workflow behavior: What will the user do differently if the output is useful and trusted?
User outcome: Which task becomes more complete, efficient, or reliable?
Organizational or care outcome: What meaningful result should eventually change?
Treat each arrow as a hypothesis, not an assumed causal relationship. For example, a more relevant recommendation might reduce corrections, and fewer corrections might improve task completion. Instrument both transitions. If relevance improves but completion does not, the team has learned that the bottleneck is elsewhere.
Your offline evaluation set should include representative routine inputs, ambiguous inputs, edge cases, and the sensitive scenarios most closely connected to the unacceptable outcomes on the use-case card. For each case, store the expected behavior, reviewer rubric, model version, prompt version, retrieval configuration, policy or rule version, and result. This makes regression testing possible when any part of the system changes.
Use A/B testing only where exposure is ethically and operationally appropriate, failure is reversible, and the relevant reviewers have approved the experiment. Do not use an experiment to discover whether an unbounded high-consequence behavior is safe. Establish safety through evaluation and controlled review first. For an approved experiment, predefine the minimum detectable effect that would make the release risk worthwhile, along with guardrail metrics and stop conditions.
Use evidence gates from sandbox to controlled scale
A responsible rollout is not one approval followed by unrestricted production access. It is a sequence of gates. Each gate expands exposure only after the previous stage produces the required evidence.
Gate 1: Sandbox validation
Start with synthetic or appropriately de-identified data. The sandbox should reproduce the workflow closely enough to test prompts, retrieval, interface behavior, event instrumentation, alerts, and rollback without exposing a patient or provider to an unproven capability.
Use the sandbox to answer concrete questions:
Does each approved input produce a traceable output?
Do ambiguous, incomplete, or malformed inputs fail safely?
Are prohibited data fields rejected before they reach logs or analytics?
Do critical evaluation cases pass on the exact release configuration?
Can a reviewer see the context needed to accept, edit, or reject an output?
Do alerts reach a named owner?
Can the feature be disabled without disrupting the underlying workflow?
Are latency and cost compatible with the intended operating model?
A polished demonstration is not the exit criterion. The exit criterion is a reproducible evidence packet containing the use-case card, data-flow map, event contracts, evaluation results, open risks, mitigations, configuration versions, approvals, and tested rollback procedure.
Gate 2: Controlled production pilot
A pilot is an instrumented risk test, not a smaller marketing launch. Define its boundaries before enabling the feature:
Which users and roles are eligible.
Which workflows and data types are permitted.
Which outputs and actions are enabled.
Where human review is mandatory.
Which feature flag or access control contains exposure.
Which metrics and segments will be reviewed.
Which events trigger an alert, pause, rollback, or incident process.
Who makes the decision to continue, modify, or stop.
Write the success and stop criteria before the first participant enters the pilot. Otherwise, adoption pressure can turn a temporary exception into a permanent operating state. A pre-agreed stop condition gives the incident owner authority to act without waiting for a fresh executive debate while a consequential failure continues.
The pilot should test the entire sociotechnical workflow. Measure whether people understand the AI’s role, inspect the output, use the correction path, escalate uncertain cases, and complete the intended task. A model can appear accurate while users over-trust it, ignore it, or spend more time verifying it than the workflow saves.
Gate 3: Controlled expansion
Scale only when the evidence satisfies the release contract and the remaining risks have named owners. Expand one meaningful dimension at a time where practical: the eligible cohort, supported workflow, data scope, or action authority. Opening all four simultaneously makes it difficult to identify which change caused a new failure.
Outcome and safety health: Guardrail failures, prohibited behavior, incidents, rollback events, and outcome variance across relevant segments.
Every alert needs an owner, response path, and severity interpretation. Every material incident needs a record of the affected configuration, inputs, outputs, user impact, containment action, root cause, and prevention work. If the team cannot reconstruct which version produced a harmful or noncompliant output, observability is incomplete.
Treat a material model, prompt, retrieval, policy, or data-schema change as a product release even when the interface does not change. Run the relevant regression suite, compare the new configuration with the approved baseline, update the risk record, and preserve the decision. Change control is what prevents a previously reviewed system from becoming a different system under the same feature name.
Keep customer success, support, solutions engineering, and operational users in the feedback loop. Structured corrections and escalations can reveal workflow failures that aggregate accuracy metrics hide. Route those signals into evaluation cases, product discovery, and prioritization instead of treating them as isolated support tickets.
Your next step does not need to be a company-wide governance rewrite. Pick one healthcare AI use case and complete four artifacts: the use-case card, data-flow map, release contract, and gated rollout plan. If you cannot name the unacceptable outcome, the person who can stop the system, or the evidence required to resume it, the use case is not ready for production. Once those answers exist, responsibility becomes part of delivery rather than a negotiation at the end of it.
I’ve watched too many AI agent deployments celebrate velocity while overlooking the one thing that determines long-term success: whether real users are actually getting value. Dashboards tend to spotlight model upgrades, prompt tweaks, and launch counts, yet they rarely quantify task completion, trust, or time-to-value. That blind spot isn’t technical—it’s human.
Enterprises are spending 93% of their AI budget building agents and almost none know if those agents are actually working for users. Pendo Agent Analytics closes the gap.
In my product reviews, I look for evidence that agentic AI is improving outcomes across the customer journey, not just the demo path. Without behavioral analytics and observability, teams optimize for throughput instead of resolution, for novelty instead of reliability. This is where eval-driven development, A/B testing, and rigorous cohort analysis become non-negotiable: they translate agent performance into user impact we can measure and improve.
Here’s the pattern that works for me: define user-centric success metrics first, then let the AI follow. I prioritize signals like successful task completion, low-friction activation, reduced escalations, and sentiment lift—tied directly to product-led growth indicators such as retention and expansion. When these metrics move in the right direction, I know the agent is creating compounding value, not just answering faster.
Practically, I operationalize this with an analytics spine that captures end-to-end agent interactions: intents, prompts, responses, clarifying turns, handoffs, and final outcomes. I segment by persona, journey stage, and account tier to uncover where agents delight and where they degrade trust. With this foundation, I can run controlled experiments, spot anomalies early, and connect improvements in agent behavior to improvements in business performance.
Pendo Agent Analytics closes the loop by making these user outcomes visible and actionable. Instead of guessing whether an agent helped or hindered, I can analyze where users stall, which prompts or skills drive completion, and how interventions like in-app guides or product tours change behavior. That visibility lets me tune models and experiences in days, not quarters—and gives stakeholders confidence that our AI investments are paying off for customers.
If you’re scaling agents today, start small but instrument deeply: map top user intents, define offline and online evals, A/B test prompts and policies, monitor regressions, and tie every improvement to activation, adoption, and retention. The result is a durable feedback loop that keeps agents aligned with user value as your surface area grows.
AI agents are not a destination—they’re a capability. When we anchor that capability to clear user outcomes and measure it with the right analytics, we stop flying blind and start compounding advantage. That’s how we turn promising demos into dependable products.
What happens when an AI starts giving advice in your voice—advice you’d never actually give? I’ve been thinking a lot about that question, and this conversation hit home for me as a product leader navigating the fast-evolving reality of AI “clones.”
Listen to this episode on: https://open.spotify.com/episode/7DNDIlIimwbbMOytArewRp?ref=producttalk.org | https://podcasts.apple.com/kh/podcast/bad-advice/id1794203808?i=1000756914818&ref=producttalk.org. Prefer video? Watch on YouTube: https://www.youtube.com/embed/RF4BwaeMMlg?feature=oembed
The episode examines AI “clones” built from podcast transcripts and public content—where the experimentation feels exciting, where it crosses ethical lines, and what happens when mediocre AI outputs get attributed to real people. The tension is real: when a bot confidently answers in your style but misses the nuance, “it’s not me” becomes more than a disclaimer—it’s a reputational defense.
We dig into the messy parts: IP ownership of open-sourced transcripts, the role of pirated books in LLM training sets, rising inference costs, and the uncomfortable economic question: if anyone can prompt “act like Teresa,” how do creators make a living? In my own decision-making, I look for clear consent, guardrails that prevent impersonation, and transparent UX that never confuses a synthetic perspective with a human expert.
This isn’t anti-AI. It’s a nuanced conversation about quality, consent, and remembering there are real humans behind the ideas.
Here’s how I translate the key takeaways into practice. Using AI for perspective is fine—equating it to the real person isn’t. Free-feeling AI outputs still rely on someone’s work. Expertise is more than past content—it’s context, judgment, and evolution. If someone’s work influences you, find a way to support them. These principles help teams benefit from gen ai without eroding trust or the creator ecosystem.
“Technically possible” doesn’t mean “ethically okay.” My AI Strategy playbook includes privacy-by-design, clear data governance on training materials, and a bright line between inspiration and impersonation. When we ship AI features, we label synthetic outputs, avoid mimicking living experts without permission, and create paths to compensate or promote the humans whose thinking underpins the experience.
I’ve also tested the “act like X” pattern to stress-test product quality. Even when outputs sound plausible, they rarely capture the expert’s mental models, trade-offs, or the evolution of their thinking—especially in complex product discovery work. That gap is the difference between average AI text and expert product management leadership.
If you listen, consider a few reflection prompts: Have you ever used AI to “act like” someone you admire? Could you tell whether the output matched that person’s actual thinking? How do you decide what’s ethically okay when using public content in LLMs? And how can we support creators while still embracing new tools?
Have thoughts on this episode or practices that have worked in your org? Share them below—I’m keen to learn how other teams are balancing innovation with integrity.
For years, I’ve watched product, growth, and data teams burn cycles stitching together manual dashboards and reports, then slogging through replay review just to validate a hunch. That overhead slows discovery and delays decisions. The promise here is different: "Discover how Amplitude AI Agents help product, growth, and data teams turn questions into action without manual dashboards, reports, or replay review." As someone obsessed with decision velocity and evidence-based product strategy, that shift is exactly what I’ve been waiting for.
In practice, I think about "Amplitude AI Agents" as always-on data analysts embedded in our workflow. Instead of queuing requests or context-switching into tooling, I can ask targeted questions, get synthesized insights, and move directly to action. This is a powerful example of agentic AI meeting behavioral analytics in a unified analytics platform—removing friction between inquiry and impact while keeping teams focused on outcomes, not artifacts.
What changes for my day-to-day? I can interrogate customer behavior in real time, pressure-test hypotheses from discovery interviews, and quickly understand whether activation, retention, or monetization is the current constraint. If I’m probing a driver tree for activation or a retention analysis for a specific cohort, I can get to a decision faster—without waiting on someone to build a bespoke dashboard. That means more cycles spent shaping product strategy and fewer sunk into report wrangling.
This matters beyond speed. When product, growth, and data leaders anchor discussions in the same source of truth, we shorten the distance from signal to decision. That alignment is the backbone of product-led growth and continuous discovery: shared context, faster feedback loops, and clearer trade-offs. It also reduces the long tail of analytics debt—those one-off reports and stale views that quietly accumulate across teams.
Of course, adopting any AI workflow in analytics demands governance. I hold these systems to the same bar I set for my teams: clarity of assumptions, consistent metric definitions, and auditable reasoning. Pairing "Amplitude analytics" with strong data governance, CI/CD for analytics definitions, and lightweight evals helps ensure the recommendations we act on are reliable, reproducible, and explainable. AI should accelerate our judgment, not replace it.
The strategic shift is simple and profound: move from building dashboards to making decisions. With always-on analysis, we can spend less time instrumenting analytics theater and more time delivering customer value. That is how we translate insights into impact—and why I’m excited to operationalize this capability across our product trios and go-to-market partners.
Inspired by this post on Amplitude – Best Practices.