If nobody on our team trains the Agent on how to communicate, it will sound like an LLM when it speaks to customers—because it is one. I never want a customer to feel like they’re talking to a machine that doesn’t get them. That’s why I treat conversation design as a core product capability, not an afterthought.
Conversation design is an emerging discipline in AI-first support teams built to solve this exact problem. In practice, I make someone explicitly own how the Agent communicates—tone, structure, level of detail, customer experience, and the handoff and escalation process—because that’s where trust is won or lost.
When there’s no clear owner and no explicit guidance, the Agent starts making its own choices. I’ve seen it over-explain when a short answer would do, reply in a flat tone when a customer is frustrated, or trigger a handoff too late. None of those are model problems; they’re design problems.
The cost is measurable. Customers who get awkwardly structured responses won’t trust the answer—even when it’s accurate—so they escalate to a human to hear the same thing phrased differently. Others will skip the Agent entirely. And when the Agent does hand off, a poor transition means the support rep inherits a frustrated customer. Every one of these outcomes is avoidable; conversation design exists to prevent them.
I’ve seen A/B tests where a warmer, more conversational opening message meaningfully lifted customer satisfaction—CSAT moved from 72.8% to 78.4%. A single design change, applied to the very first message, drove a measurable difference. That’s the kind of leverage I look for as a product leader.
Here’s the scope I use when I talk about conversation design—five areas that shape the customer experience end to end:
1) Tone and personality: Define the Agent’s voice, level of detail, and how formal or casual it should sound—and specify where that register adapts to the situation (for example, urgent access issues versus exploratory product questions).
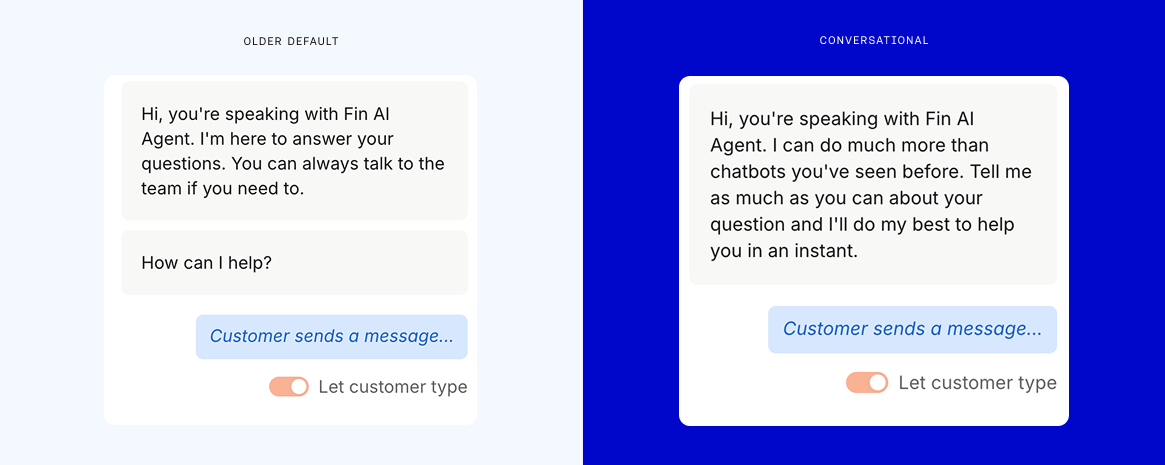
Design how your AI agent talks. Set tone, style, and product naming rules, then preview replies instantly. Clear callouts showcase brand voice consistency and flexible formatting so your bot communicates like your team.
2) Response structure: Ensure the Agent matches the level of detail to the customer’s request, keeping answers tight when the ask is simple and expanding only when complexity demands it.
3) Handoff logic: Decide when to escalate, how to communicate the transition, and what context to carry over so the human teammate can help immediately without rework.
4) Interaction flow: Map how a conversation progresses—clarifying questions, answers, resolution, or handoff—and design for smooth pivots when customers change direction.
5) Response quality: Go beyond technical correctness to ensure answers feel clear, helpful, and on-brand. Accuracy without clarity erodes trust.
To put this into practice, I start with the feel of the conversation. Before tuning individual responses, I write down one tight paragraph describing the Agent’s voice. I don’t need a full brand bible—just a north star I can use to make consistent decisions about tone. The voice stays consistent, while the register adapts to the context: a locked-out customer needs directness and speed; a feature explorer might value more context and examples.
I design the handoff with extreme care because it’s one of the highest-friction moments. Customers shouldn’t have to re-explain anything. The support rep should receive the full conversation history, the underlying context, what the Agent already tried, and why the escalation happened. Even the phrasing matters—“Let me connect you with a teammate who can help with this” feels very different from a silent handover.
The new CX Score adds context to every conversation: a donut chart surfaces drivers like policy feedback and effort, while a side panel explains why this interaction earned a 3 based on signals from an AI agent chat.
I also build a failsafe. If the Agent can’t resolve the issue cleanly, a graceful fallback still gives the customer a smooth experience. A customer might be frustrated with AI at that point, but a well-handled transition can turn that around.
Follow-ups deserve the same rigor as handoffs. If someone drops mid-conversation—with the Agent or a human—how do we reach back out to confirm they got what they needed? Most teams miss this moment; customers don’t.
Another common pitfall is over-explaining. The Agent has access to a lot of information, and left unguided, it will overshare. The fix is simple: match the answer’s depth to the question. A password reset shouldn’t take three paragraphs; a complex integration might. When there’s more to offer, the Agent should ask before expanding.
I also design for the conversation the customer is actually having—not the script I wish they’d follow. Customers change direction, stack questions, or bring up unrelated follow-ups. The Agent should pivot with them, not force them back into a rigid flow. I also consider whether flows vary by channel and whether different segments merit distinct experiences.
On the instruction side, I keep guidance short. Teams often react to edge cases by adding more rules until the LLM is parsing paragraphs before it can reply. I’ve seen it everywhere. My rule: if it’s about content or information, it belongs in the knowledge base. If it’s about tone or handling specific situations, it belongs in the Agent’s instructions. “Be direct about pricing” does more than a paragraph explaining the philosophy behind your pricing communication strategy.
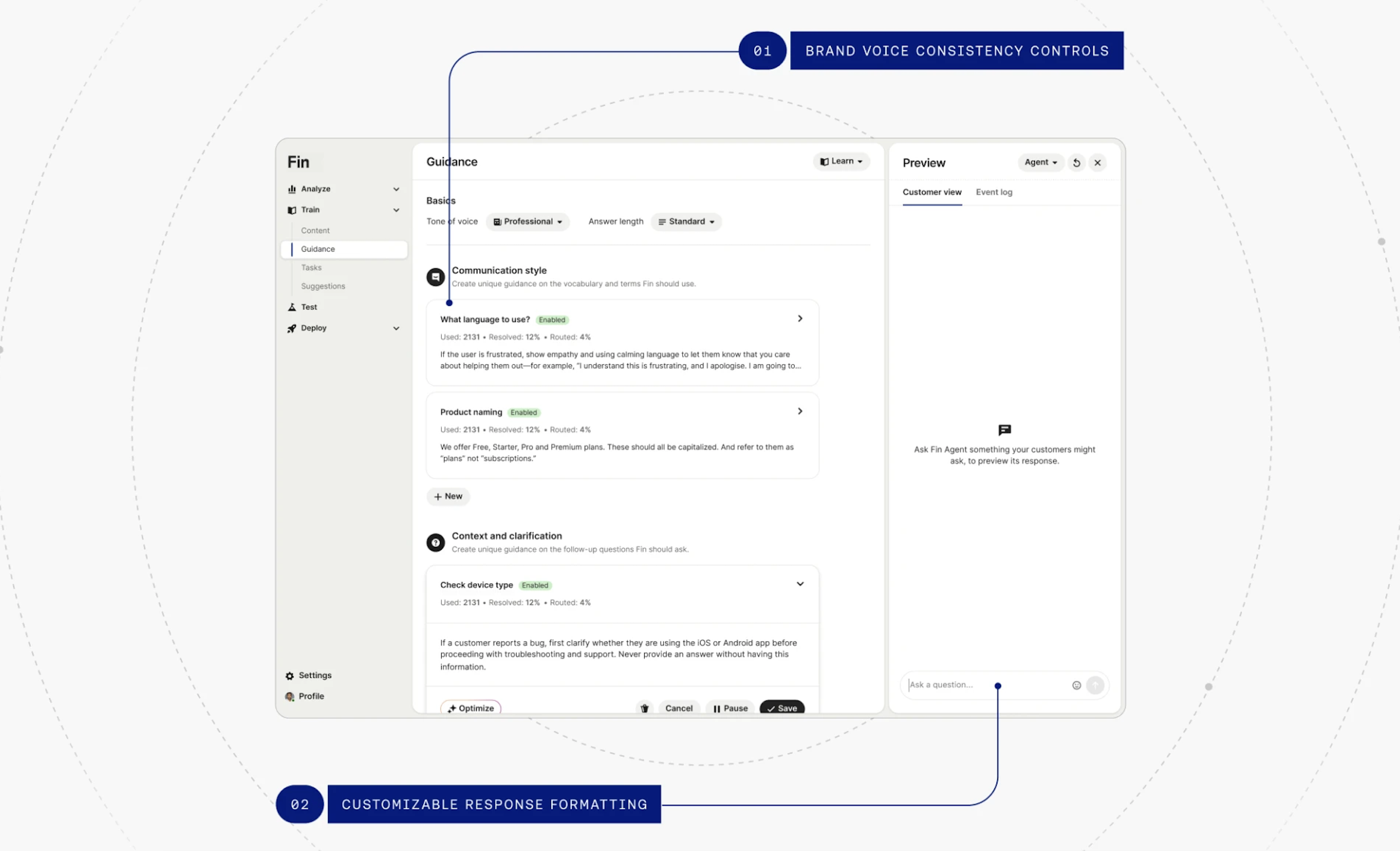
If you’re using Fin, much of this work happens in Guidance. It’s where conversation design takes shape, helping you define how the Agent should sound, how much it should say, and how it should respond in different situations.
On a crisp grid, 'Blueprint' appears as editable vector paths, underscoring a methodical plan. The image promotes the AI Agent Blueprint—a framework to launch and scale customer service automation with confidence.
Most teams won’t hire a dedicated conversation designer on day one—that’s fine. But someone still needs to own the Agent’s communication, even if it’s part of an existing role. I’ve often seen this start within support operations or knowledge management. As the Agent scales to more conversations, the responsibility becomes formal—and eventually becomes a dedicated role.
Here’s how I’d start, step by step:
1) Name an owner. Make accountability explicit; it doesn’t have to be a new hire.
2) Pick one conversation type that isn’t landing well. Look for cases where the Agent answered correctly but the customer still escalated or left negative feedback. If you’re using Fin, CX Score can help you surface these; it shows which topics and conversation types are scoring poorly and why, so you can see whether the issue is answer quality, customer effort, or something else.
3) Audit the Agent’s instructions. If they’ve grown beyond a few focused rules, trim them. Move content into the knowledge base and keep instructions focused on behavior.
4) Fix your worst handoff. Review a handful of conversations that escalated. Did the customer have to repeat themselves? Did the rep have enough context? Redesign that single transition first.
The impact of these small improvements compounds. A warmer opening can lift CSAT, trimming instructions makes responses sharper, and a better handoff prevents reps from inheriting frustrated customers. None of this requires new knowledge—just someone paying close attention to the conversation itself and designing it with intention.
I’m processing a milestone moment for SaaS, AI strategy, and product leadership. One statement captures the news with clarity: “We’re excited to share that we just signed an agreement for Salesforce to acquire Fin for ~$3.6B. The transaction is expected to close in the fourth quarter of Salesforce’s fiscal year 2027.” As a product leader, I see this as a high-conviction bet on agentic AI, Customer Agents, and CRM integration at massive scale.
The backstory matters, and it’s remarkable: “Fin started as Intercom 15 years ago. We changed our name to cap our transformation just weeks ago. We were a darling of the SaaS era and invented so many of the patterns you see in software today. Nearly four years ago, in need of a reboot, we jumped on weeks-old modern LLMs to create and define the category we know as Customer Agents today.” That arc—from SaaS pioneer to LLM-powered category creator—illustrates how bold pivots, shipped with urgency and clear product strategy, can reset the trajectory of a company and a market.
From a product management lens, this deal reinforces a few truths: category creation rewards those who move first with conviction; “reboots” succeed when they’re anchored in genuine customer value; and modern LLMs, applied through disciplined roadmapping and eval-driven development, can unlock step-change outcomes in customer support ai strategy and product-led growth. It also signals the rising centrality of agentic AI and operational AI workflows inside the CRM.
The leadership dimension is just as instructive. As the announcement framed it: “Salesforce invented modern software and SaaS. And Marc Benioff is like the final boss of tech founder CEOs. In seat for 27 years, he’s one of the last of his era. Still pushing, pivoting, placing big bets.” That ethos—placing big, principled bets while adapting the operating model—sets the tone for what sustained product management leadership looks like at scale.
Customer continuity and acceleration are clearly emphasized: “To our customers: Over the past few years we’ve been shipping intensely. Including recently our groundbreaking model, Apex, and our paradigm-defining internal agent, Operator. With the resources of Salesforce this will only accelerate. And yet little will practically change. I’ll still be CEO, Des will still be running R&D, we’ll both still be committed to continuing to lead this category. Thank you very sincerely and deeply for your belief in us.” For practitioners, the signal is strong: continued focus on shipping, sharper execution readiness, and tighter integration paths inside the Salesforce ecosystem.
Smiles, clinking glasses, and a roundtable toast in a cozy private room capture the energy of a big day—celebrating Salesforce's definitive agreement to acquire Fin and the teams joining forces for what's next.
There’s a human heartbeat here too: “While this is not the end, it is a major, pivotal, special, and emotional moment for us.” Moments like this remind me that building enduring products is equal parts craft and courage—powered by teams who commit to the long game, navigate uncertainty, and still ship relentlessly.
Strategically, I expect near-term priorities to center on secure data flow and governance, deep CRM integration, and unifying telemetry for Agent Analytics across channels. On the roadmap, I’d anticipate tighter alignment between LLM safety, retrieval-first pipelines, and enterprise-grade observability—plus thoughtful go-to-market strategy enabling sales-led growth to complement product-led growth. The real unlock comes when Customer Agents are natively orchestrated with Service, Sales, and Marketing workflows—measured with clear outcomes vs output OKRs and reinforced by robust knowledge management.
For fellow product leaders, the takeaways are actionable: define category boundaries with crisp value propositions; balance speed with governance; invest in eval-driven development and continuous discovery; and keep your product trios aligned around measurable customer outcomes. Above all, build the operating cadence—metrics, rituals, and talent—that lets you compound small wins into durable differentiation.
And I appreciate the spirit of this closing line: “And now, time to get back to work. See you at our next product launch in a few weeks. (:” That’s the mindset that turns a headline into execution: celebrate briefly, then ship the next proof point.
I build products under constant pressure to learn faster without breaking trust. Claude Code has become a pragmatic addition to my AI product toolbox because it helps me move from idea to evidence with less friction—while keeping engineering, design, and compliance in the loop.
“Claude Code for Product Managers explained: what it is, why it matters, and how it helps PMs prototype, validate, and move faster.” That line captures the essence. In practice, I use it to turn ambiguous problem statements into tangible artifacts—API stubs, SQL queries, test data, and lightweight prototypes—that sharpen conversation and accelerate decision cycles.
What is it in PM terms? A code-aware assistant that helps me prototype safely and quickly. I can generate example API calls, transform messy CSVs for retention analysis, draft instrumentation plans for Amplitude analytics, or spin up a mock service to validate an integration. Because it understands structure, it’s effective at scaffolding small utilities (e.g., a data cleaner or a CLI harness) that make discovery and validation faster.
Day to day, Claude Code reduces handoffs. If I’m exploring a new partner integration, I’ll have it produce a curl library and a Postman collection, then annotate each step with acceptance criteria and expected responses. When I’m shaping a feature, I lean on it to outline event taxonomies and feature flags so that engineering can wire telemetry without guesswork. For insights work, I’ll ask it to propose SQL for cohort, funnel, and retention analysis—always verifying against source schemas before anything touches production.
Speed is only useful when it improves signal quality. I anchor the workflow in continuous discovery: small hypotheses, thin-slice prototypes, and fast instrumentation. Claude Code helps me estimate A/B testing readiness (including minimum detectable effect), generate smoke tests for critical user paths, and structure an eval-driven development loop so we learn from every iteration. It also supports context window management by summarizing long PRDs into the few constraints a prototype must respect.
Governance matters. I apply AI readiness and AI risk management principles: never paste secrets or PII, isolate sandboxes, and log prompts as docs-as-code for auditability. I prefer a retrieval-first pipeline that feeds approved product docs, OpenAPI specs, and design tokens so generations stay grounded. When tools are integrated, I favor the Model Context Protocol (MCP) to constrain capabilities and maintain least-privilege access. Human-in-the-loop review is non-negotiable—especially for anything that might influence customer data or pricing.
The best outcomes show up in product trios. I’ll facilitate a live session with design and engineering: we co-create prompts, compare alternatives, and converge on a thin slice we can ship. That collaboration keeps us empowered, reduces interpretation drift, and turns Claude Code into an accelerant rather than a sidecar. Over time, the trio curates a reusable prompt library for PRD outlines, experiment checklists, and integration playbooks.
Getting started is straightforward: define a safe environment, assemble your authoritative corpus (requirements, specs, taxonomies), and codify a few high-value templates—API exploration, instrumentation plans, sandbox data generators, and acceptance tests. Track impact with simple, objective metrics: cycle time from hypothesis to instrumented prototype, time-to-first-signal, and the proportion of decisions made with data versus opinion.
There are pitfalls. Hallucinated fields can creep into API calls, schema drift can break generated queries, and “clever” refactors may miss edge cases. I mitigate this by grounding generations in current specs, asking for unit tests alongside any code, and validating against a staging environment before anyone talks about production. Treat Claude Code as a collaborator, not an oracle.
If your mandate is to learn faster, de-risk bets, and ship with confidence, Claude Code is worth adopting. Used thoughtfully, it compresses the distance between questions and answers, elevates product discovery, and lets teams validate more ideas with fewer meetings—without compromising on governance or quality.
What do you do when off-the-shelf moderation scores aren't good enough—and the alternative is paying human contractors to spend their days reviewing traumatizing content at scale? I’ve wrestled with that exact trade-off in enterprise environments, and it’s why I was eager to unpack how custom AI can raise the bar on trust and safety without compromising accuracy, latency, or the well-being of our teams.
In this episode of Just Now Possible, I sit down with Nikki Marinsek (Data Scientist), Brian McCaffrey (Software Engineer), and Dan Means (Machine Learning Engineer) from Musubi, an AI-native trust and safety toolkit for content platforms. Musubi builds custom-trained ML models and LLM-powered moderation tools that adapt to each platform's unique policies—from dating apps to social networks to AI inference endpoints. As a product leader, I’m drawn to their blend of eval-driven development, agentic AI, and pragmatic deployment pipelines that actually meet real-world SLAs.
We walk through their full journey—starting with a first prototype on tabular data—then discovering the system was sometimes catching issues human moderators missed. That insight became a forcing function to formalize evaluation, calibrate thresholds, and design feedback loops that help humans and models converge. Just as importantly, they built a policy optimizer that uses agentic flows so non-technical trust and safety teams can iterate on LLM moderation policies without needing a data scientist in the room.
If you’ve ever had to balance latency, accuracy, and cost at scale, you’ll appreciate how Musubi tests trade-offs across traditional ML, embedding-driven classification, and LLMs. Their approach mirrors the patterns I expect in high-throughput stacks: cache and pre-compute where possible, contain worst-case latencies, and push evaluation tooling to customers so policy changes are safe, observable, and fast to deploy.
What resonated most with me is their core product strategy: put eval tools directly in customers’ hands. When teams can benchmark AI against humans, referee disagreements using “LLM as judge,” and make policy gaps visible, trust increases and operational drift decreases. That’s the foundation for durable product strategy in sensitive domains like content moderation, fraud management, and risk scoring.
Listen to this episode on: Spotify | Apple Podcasts
Guests: Nikki Marinsek, Data Scientist, Musubi; Brian McCaffrey, Software Engineer, Musubi; Dan Means, Machine Learning Engineer, Musubi.
In this episode: Why off-the-shelf moderation scores fail and how custom-trained models fix that; How Musubi combines traditional ML with LLMs for different moderation tasks; The discovery that AI can outperform human moderators—and how to communicate that to clients; Using AI as a judge to referee disagreements between AI and human decisions; How Musubi onboards new customers with "reverse demos"; What custom model training actually means: fine-tuning, feature engineering, and reusable deployment pipelines; The policy optimizer: an agentic flow that helps customers iterate on their LLM moderation policies; Why pushing eval tools directly to customers is a core product strategy; How Musubi is building flexible orchestration workflows for non-technical trust and safety teams.
From a product management lens, a few highlights stand out. First, the disciplined separation of concerns: use traditional ML for high-precision, low-latency pattern detection and LLMs for nuanced policy interpretation. Second, invest in golden sets and policy loops early so you can quantify improvement and avoid subjective debates. Third, productize customization—create reusable deployment pipelines, parameterized policies, and self-serve evaluation—so each customer’s “custom model” still scales like a platform.
I also appreciated the onboarding tactic of "reverse demos." Rather than a canned walkthrough, the team invites customers to bring real policies and edge cases, then instruments the workflow live. That move builds credibility, accelerates discovery, and surfaces the fastest paths to value—an approach I recommend whenever you’re selling complex AI workflows to non-technical stakeholders.
If you’re navigating cost and latency trade-offs, the conversation goes deep on techniques like embedding-driven classification, fine-tuning vs. training, and when to route decisions through LLM adjudication. My takeaway: treat the router, the evaluator, and the policy as first-class products. When those elements are observable and testable, you can raise quality without exploding compute costs or creating operational bottlenecks.
Resources & Links: Musubi — AI-powered trust and safety toolkit for content platforms. Maven AI Evals Course — AI evals course.
Chapters: 00:00 Meet the Team; 01:18 Why Everyone Wears Product; 02:32 What Musubi Builds; 04:51 AI for Human Moderation; 09:59 Adversaries and Asymmetry; 11:48 Early Days and Low Latency; 13:35 First Prototype Slice; 15:33 Traditional ML Meets LLMs; 19:52 Benchmarking Against Humans; 23:09 LLM as Judge and Policy Gaps; 29:53 From Prototype to Platform; 31:15 Customer Onboarding Reverse Demos; 36:08 Custom Models Per Customer; 38:05 Fine Tuning vs Training; 39:14 Embedding Driven Classification; 40:04 Cost and Latency Tradeoffs; 43:21 Productizing Customization; 49:16 Scaling Prototypes to Production; 51:58 Golden Sets and Policy Loops; 56:17 Coaching Customers Safely; 01:02:06 Gamified Feedback Signals; 01:06:19 Agentic Toolkit Roadmap; 01:09:05 Workflow Orchestration Future; 01:12:06 Wrap Up and Thanks.
Ultimately, this is a playbook for modern trust and safety: align your models to your policies, make evals a habit not an event, and empower non-technical teams with agentic workflows and transparent metrics. That’s how we move beyond black-box scores to systems we can measure, manage, and trust.
In competitive markets, I see two options: try to win the game competitors set, or choose to play a different game. In the "Customer Agents" category, I’ve watched too many glossy, fabricated demos—especially around voice—mask the real challenges. Voice is just extremely hard. We all know the future of customer experiences will be Agent-driven voice, yet most of us haven’t actually spoken with a modern AI Agent when calling a business because the tech hasn’t been truly ready in the wild. Today, the bar moves.
What changed? There’s a live, public demo of cutting-edge voice tech you can stress test yourself—no smoke, no mirrors. I recommend taking it for a spin: https://fin.ai/voice. It’s fast, natural, and, yes, very, very good.
For context, yesterday brought Apex Flash, their newest and fastest model, built for the unique demands of low latency channels like voice. Today comes Fin Voice 2, a major upgrade to Fin Voice with over 20 new features, and the first product built on Apex Flash.
Here are the three things that stood out to me—and why they matter for customer support AI strategy and product strategy.
First — thanks to Apex Flash, Fin Voice 2 is now the fastest, most natural Agent for phone, with higher resolution rates and customer satisfaction scores than ever before. Apex Flash is trained on millions of customer experience interactions, fine tuned for customer service, and can be configured to understand all your knowledge and follow all your policies. The result is higher resolution at significantly lower latency—the best of both worlds for voice AI agent performance.
Speed and naturalness here aren’t accidental. Most voice AI products are slow because they convert speech to text, send it to a general model, get a text answer, and then convert it back to speech. Fin Voice 2 was designed to work differently, separating the real time layer that handles speech processing, and the layer that generates answers. That architecture is purpose-built for the demands of customer service on voice.
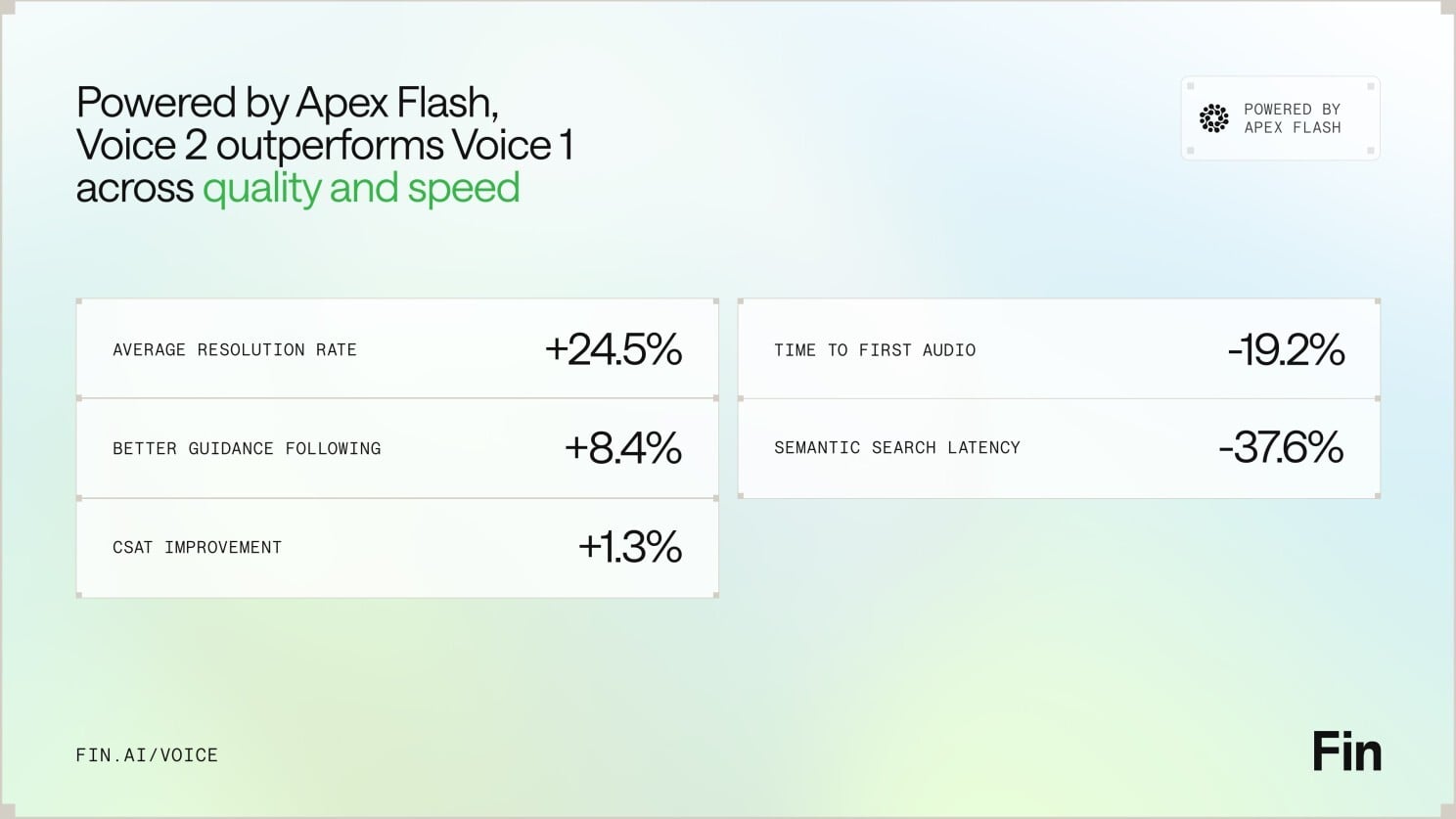
Powered by Apex Flash, Fin Voice 2 raises the bar on quality and speed—boosting resolution rates and guidance following while cutting time to first audio and semantic search latency, with a lift in CSAT too.
Second — Fin Voice 2 can handle complex queries end to end: taking actions in external systems, verifying callers’ identities, processing refunds, booking appointments, and more. Phone is a high-stakes channel, and Fin adapts to customers across emotional states, clarifies when needed, and confirms key details before taking action. Most of the time, Fin can resolve the query in full, and when it can’t, it seamlessly hands off to the human team, maintaining full customer context and history. You also get multiple improvements to call quality, plus proactive outbound calls to follow up on unresolved issues—all orchestrated by robust AI workflows.
Third — Fin Voice 2 gives you total control with industry-leading tools to configure and manage how Fin behaves. You get rich, detailed insights into call behavior and quality, the most common topics of calls, and one-click recommendations to improve. As with everything in Fin, you can fully self-serve and then manage it all with ease, without requiring professional services. Many vendors only let you set up their voice agent under supervision; with Fin, you get everything you need to iterate fast.
If you haven’t tried the demo yet, go check it out: https://fin.ai/voice. If you prefer to wait, don’t be surprised when you end up speaking with it at a favorite brand soon.
From a product management lens, this is what matters: latency is a feature customers feel; transparency builds trust in enterprise AI; and control is non-negotiable for CX leaders. The combination of a purpose-built, agentic AI architecture, measurable gains in resolution and CSAT, and true self-serve configuration signals that voice is moving from prototype theater to production reality. That’s the different game I want our industry to play.
I spend a lot of my time asking a deceptively simple question: what does excellent marketing actually look like in 2026? From the vantage point of product leadership, the answer isn’t a spreadsheet or a channel plan—it’s a feeling. Beloved tech brands earn the benefit of the doubt, create gravity around their roadmap, and make customers proud to belong. That kind of momentum is not an accident; it’s a system.
Here’s the hard truth I’ve learned building and scaling products: giving teams different goals creates dysfunction. When brand, demand gen, product marketing, and comms run on fragmented OKRs, you manufacture internal headwinds. “Marketing is one engine – not separate pieces.” One strategy, one narrative, one set of outcomes—expressed through different craft disciplines and time horizons.
That unity of purpose clarifies executive roles, too. The real difference between an SVP and a CMO is scope and narrative ownership. A great CMO architects the whole system—portfolio allocation, brand architecture, integrated go-to-market strategy, and the bar for creative taste—while refusing to get dragged into decisions they should never be making (for example, approving every headline or micromanaging channel tactics). Leaders should decide the outcomes, standards, and constraints; teams should control the craft.
On portfolio design, I run marketing like a portfolio of moonshots. You need a healthy mix: proven programs that compound, emergent bets that learn fast, and a small set of true moonshots that can change the slope of the curve. The point isn’t bravado; it’s risk-balanced exploration. If everything ships safely, you’re under-investing in differentiation. If everything is a swing for the fences, you’re not building a repeatable growth engine.
This is where taste becomes a strategic advantage. “Ubiquity is the opposite of cool.” If you want to be beloved, you cannot treat every channel, audience, and moment as equal. Early on, selective distribution, distinctive creative codes, and tight community loops create status and meaning. Later, you scale without sanding off the edges that made the product special.
Why do a few companies build a flywheel of momentum while others stall? They align story, product, and distribution. The product earns trust, the narrative creates aspiration, and the go-to-market strategy ensures the right customers experience both at the right time. Then perception cycles kick in—the Silicon Valley clock turns—and irrational optimism or skepticism can amplify signals. The antidote is compounding proof: consistent product shipping, community advocacy, and creative that makes people care.
Scaling taste across an organization is teachable. I codify brand principles, narrative guardrails, and examples of “right” versus “almost right.” I replace abstract feedback with decision rubrics—what we keep, kill, or revise and why. I run recurring creative reviews with a small cross-functional council, so judgment compounds. Taste can’t be fully automated, but it can be operationalized: shared references, a story bible, and a high bar for craft that’s explicit, not mystical.
In a post-LLM world, the fundamentals haven’t changed—but the frontier has. Generative tools supercharge iteration and research, yet the artistry never really left. You still need a point of view, a tension worth resolving, and a value proposition that’s felt, not just stated. Can taste be encoded in software? Parts of it—pattern libraries, style constraints, data-driven feedback—absolutely. But the spark that makes work unforgettable remains human: judgment, risk tolerance, and the courage to ship something that might not fit the playbook.
That’s why telling an optimistic, yet realistic story about AI matters. Over-automation drains humanity; under-automation wastes potential. The best work pairs AI Strategy with craft leadership: LLMs for rapid exploration, humans for narrative decisions and ethical judgment. Your message should show how AI expands customer agency, not just efficiency.
The brand-versus-growth debate is a false choice. The right story accelerates pipeline, and the right demand programs reinforce the brand. Look at Apple’s discipline around product truth and design codes, or Google Chrome’s “The Web Is What You Make of It (Dear Sophie)” for proof that emotion and utility can co-exist. Notion, Pinterest, Square, HubSpot, and Harley-Davidson show how community, identity, and product-led growth interlock when the company knows exactly what it stands for.
When it comes to launches, I’ve learned that announcement videos full of humans, lack humanity. Overproduced gloss often dilutes the truth customers seek: what problem does this solve, how quickly can I feel the value, and why does it matter now? Real users, real context, and a crisp arc from problem to promise will outperform most theatrics.
Practically, I architect my week to protect taste and outcomes. Early-week for strategy, portfolio reviews, and cross-functional alignment; mid-week for deep creative and product marketing work; late-week for decision clears and postmortems. I time-box “disruptive energy”—space to chase non-obvious ideas—and I guard it like any critical meeting. Without protected cycles for exploration, the urgent will always suffocate the important.
If there’s a single takeaway: playbooks are obsolete, but the fundamentals are not. The channels change; the psychology doesn’t. Run one engine. Allocate a true portfolio. Scale taste with rigor. In the AI era, make people care. That’s how beloved tech brands are built—and how they endure.
I’ve led enough multi-tool product organizations to know how quickly momentum erodes when insights and actions live in different places. When my teams bounce between Notion, Atlassian, Slack, Linear, and analytics dashboards, we pay a real tax in context switching. That’s why I’m excited about what Amplitude is enabling with Agent Connectors—bringing our daily work and our data-driven decisions into one fluid, agentic AI workflow.
Connect Notion, Atlassian, Slack, Linear, and more to Amplitude's Global Agent. Get richer analysis and take action across tools without leaving Amplitude.
Practically, this means I can treat Amplitude analytics as a unified analytics platform where analysis and execution finally meet. Instead of exporting charts or copying insights into docs, I can drive Agent Analytics directly from the same surface where I manage behavioral analytics, reducing friction and accelerating decisions. For my product strategy, that’s a meaningful shift—from “insight later” to “insight-to-action now.”
Here’s how I’d use it on a typical day: I ask the agent to synthesize signals from recent feature usage, spotlight anomalies, and then draft a concise summary for our Slack channel. In the same flow, I can prompt it to reference our Notion specs for context and queue next steps in Linear, keeping Atlassian stakeholders looped in without any extra swiveling between tabs. The value isn’t just faster execution; it’s tighter alignment across teams because the analysis and the plan live together.
From an operating model perspective, this is how I scale AI workflows responsibly. I can define clear prompts, approval paths, and ownership so the agent augments—not replaces—expert judgment. Data governance and permissions remain front and center: the agent sees what your teams are allowed to see, and we maintain auditability on critical workflow steps. The outcome is a trustworthy, repeatable system that compounds learning over time.
If you’re exploring agentic AI for product teams, start small and instrument your ROI. Pick one or two connectors (Slack and Notion are great first choices), define a measurable workflow—like pushing weekly retention insights and creating prioritized follow-ups in Linear—and iterate using continuous discovery. In my experience, the first wins appear as reduced time-to-insight, fewer meetings to align, and faster cycle time from observation to shipped change.
The big picture is simple: bring your work to your analytics, and your analytics to your work. With Agent Connectors, Amplitude’s Global Agent helps close the loop from understanding behavior to taking action—without leaving the place where your insights are born.
Inspired by this post on Amplitude – Best Practices.
You ask Amplitude Global Agent why activation fell. It returns a plausible explanation, but you still can’t tell which events it examined, whether the comparison was valid, or what your product team should do next.
The fix is to treat the prompt as an analysis specification. Define the decision, provide the relevant analytics context, constrain unsupported conclusions, and make the agent show its work. You will get an answer that is easier to verify and more useful in a product review.
Start with the decision, not a broad request for insights
Requests such as “analyze activation” leave several decisions unresolved. The agent must guess what activation means, which users belong in the analysis, which period matters, and what kind of answer you expect. Even a polished response may answer the wrong question.
Before writing the prompt, complete this sentence: “After reading the answer, we need to decide whether to…” Your ending might be “change the onboarding sequence,” “investigate a recent release,” or “prioritize one segment for discovery.” That decision gives the analysis a destination.
Then assign a role that matches the work. “You are a product analyst investigating activation performance” is more useful than “You are a helpful assistant.” Add the audience as well. An executive needs the size and business relevance of a change; a product trio also needs the affected steps, segments, and follow-up questions.
A strong opening contains three elements:
Role: the analytical perspective the agent should take.
Decision: what the team will choose or investigate after reading the result.
Success criteria: what the answer must establish before it is useful.
For example: “You are a product analyst helping the onboarding team decide whether to redesign a weak activation step. Identify the largest meaningful drop-off, show which defined segment is most affected, and separate measured findings from possible explanations.”
Give the agent a compact analytics contract
The most reliable prompt names the data the agent may use. Include the relevant event names, property names, segment definitions, filters, and timeframe. If activation has an internal definition, write it out rather than relying on the agent to infer it.
A different interpretation of activation or retention
Population
Included users or accounts and explicit exclusions
Comparisons across unlike populations
Segments
Named properties and the values to compare
Arbitrary segmentation
Timeframe
The analysis period and comparison period
Hidden or inconsistent date choices
Evidence boundary
The events, properties, definitions, and dashboards allowed
Unsupported claims presented as measured facts
Output contract
Required sections, fields, ordering, and length
A long narrative that cannot be reviewed quickly
Do not dump every available definition into the context. Include only what the question requires. More context is useful when it resolves ambiguity; irrelevant context competes for attention and makes the prompt harder for a teammate to audit.
Use a reusable prompt that exposes uncertainty
You can adapt the following structure for activation, retention, anomaly investigation, or another behavioral analysis:
Role and audience: “Act as a product analyst. Write for the product manager and analytics lead responsible for [area].”
Definitions: “For this analysis, [metric] means [explicit event or outcome definition].”
Data context: “Use these events: [names]. Use these properties: [names]. Compare these segments: [definitions]. Analyze [timeframe] against [comparison period]. Apply [filters and exclusions].”
Constraints: “Use only the supplied Amplitude analytics events, properties, and definitions. Do not treat an unmeasured explanation as a finding.”
Output: “Return the metric result, segment comparison, timeframe, evidence, interpretation, confidence or limitation, and recommended next check.”
Fallback: “If the available data cannot answer the question, state what is missing and provide the smallest follow-up query needed.”
The fallback matters. Without it, the agent has an incentive to complete the requested narrative even when the evidence is incomplete. A useful failure is specific: it identifies a missing event, undefined property, absent comparison, or ambiguous metric. Your team can fix that. A confident guess is harder to detect.
Ask for measured findings, interpretations, and recommendations as separate fields. A measured drop-off is evidence. A claim that users were confused is an interpretation unless the supplied data establishes it. A recommendation to inspect session replay or conduct customer interviews is a next step, not proof of the cause. Keeping those layers separate makes the result safer to use in prioritization.
Turn prompt quality into a small product evaluation
Do not judge a prompt by whether one response sounds intelligent. Save the prompt version, input context, and output. Then test it against a question whose answer your team already knows. This gives you a reference point for accuracy before you use the template on an ambiguous problem.
Score each version on three dimensions:
Accuracy: Did the answer use the supplied definitions, filters, segments, and timeframe correctly?
Clarity: Can a reviewer distinguish evidence, interpretation, limitations, and next steps?
Actionability: Does the result support the stated decision or name the next query required?
Change one meaningful element at a time. You might compare a broad objective with a decision-specific objective, a narrative response with a fixed output contract, or an unrestricted answer with an explicit evidence boundary. Run the same test question through each variant. Otherwise, you will not know which change improved the result.
Commit to two or three prompt iterations for one critical workflow. Review the failures, tighten the ambiguous instruction, and keep the better-performing version. Within a sprint, that process can produce a reusable template for a recurring analysis such as activation, retention, or anomaly detection.
Store winning prompts with their required inputs and known limitations. A template without those notes becomes cargo cult: teammates copy the wording but omit the definitions that made it work. Treat the prompt, context requirements, evaluation question, and scoring criteria as one asset.
Key takeaways
State the product decision before requesting analysis.
Define the metric, population, segments, filters, and timeframe explicitly.
Restrict conclusions to the analytics evidence you supplied.
Separate measured findings from interpretations and recommended actions.
Require a specific fallback when the data is insufficient.
Version and score prompts for accuracy, clarity, and actionability.
Start with the recurring Amplitude question that currently creates the most debate. Write its decision, definitions, evidence boundary, and output contract. Run two or three scored iterations, then give the winning template to another product manager. If they can obtain a defensible answer without you translating the prompt, it is ready to become part of the team’s operating system.
When teams evaluate AI Agent options for customer service, I often see the rigor aimed at the wrong subset of criteria. After leading and observing dozens of proof of concept (POC) efforts with our customers and prospects, I understand why performance—accuracy scores, resolution rates, and benchmark tests on curated datasets—soaks up most of the attention. But those indicators alone won’t guarantee success once you leave the sandbox and face real customers.
If your POC only proves that the AI “works,” you’re missing the bigger picture. Here’s what else I look for to make the best long-term decision.
How does it handle your real-world setup?
Performance is table stakes, but it has to reflect the messiness of an actual support environment. The best-performing Agents don’t just get answers right—they exhibit resilient, human-like behavior under pressure. I watch how the Agent behaves when it doesn’t know an answer: does it recover or spiral? Does it stay on track through multi-step requests, and how gracefully does it hand off to human agents? If your knowledge base depends on a retrieval-first pipeline, test cross-source retrieval and grounding—not just single-document lookups.
When I build evaluation scenarios, I put the Agent through its paces with a broad, realistic mix:
Multi-turn queries that require the Agent to carry context across a conversation, not just answer isolated questions.
Vague or fragmented inputs, like typos, grammatical errors, and incomplete questions, because that’s how customers actually write.
Edge cases and sensitive scenarios, like billing disputes, frustrated customers, and questions that sit at the boundary of what the Agent is trained on.
Different phrasings of the same question. An Agent that handles one version well but fails on a rephrasing has a knowledge problem, not a performance problem.
Queries that require pulling from multiple knowledge sources. Real issues are rarely answered by a single help article, and an Agent that can only handle single-source questions will hit a ceiling fast.
Multilingual conversations, if your customer base requires it. Performance can vary significantly across languages and it’s better to discover that in testing than in production.
This preparation is worth the effort. Any Agent can look impressive in a demo; what matters is how it holds up as part of your team, serving your customers in production.
What does it feel like to interact with the Agent?
Two AI Agents can post the same quantitative scores—resolution rates, containment rate, and more—and still deliver very different customer experiences. Resolution rate tells me whether the Agent finishes conversations; it says nothing about how customers felt during them. I deliberately assess the experience, not just the outcome, because conversation design shapes trust and brand perception.
Here’s what I look for to ensure the AI Agent is enjoyable to interact with:
Is the tone natural and on-brand, or does it feel robotic and generic?
Does it build trust early in the conversation, or does it create friction that makes customers want to immediately request a human?
When it doesn’t know the answer, does it handle that gracefully?
When it hands off to a human, is that transition seamless, or does the customer feel abandoned?
As George Dilthey at Clay put it when evaluating their AI setup: “Keep what’s important to your business up front and center. For us, that was transparency and control over the customer experience.”
That framing is exactly right. The Agent represents your brand in every conversation. Customers don’t experience “accuracy,” they experience conversations. An Agent that’s technically accurate but tonally off-brand will erode customer trust over time.
I make the experience dimension explicit in my POCs. I have people on my team—and when possible, a small cohort of real customers—interact with the Agent under realistic conditions. Then I ask how it felt, not just whether it worked.
Can you keep improving it after launch?
This is the dimension most teams don’t evaluate at all, and it’s possibly the most important one. Choosing an Agent that works today and ensures you can continuously improve the customer experience over time requires more than a functional demo. You’re buying a system that must get better every week, not just during the first sprint.
The feedback loop
Can your team easily review conversations and identify where the Agent is underperforming? Can you pinpoint specific gaps (missing knowledge, incorrect tone, poor handoff decisions) and act on them quickly? The faster the loop between “something isn’t working” and “we’ve fixed it,” the more value compounds over time. In practice, that means instrumenting conversations, leveraging Agent Analytics, tagging misroutes and tone slips, and running targeted evals on known failure modes.
The speed of iteration
When you identify a gap, how quickly can you address it? This is partly a question of tooling (how easy is it to update knowledge, refine guidance, adjust behavior?) and partly a question of team capability. The teams getting the most out of AI are the ones that have changed how they operate and made continuous improvement a part of their everyday work. They’ve committed to going all-in for the long term, not just the first few weeks when launching their AI Agent. We treat this as eval-driven development: automate evaluations that mirror real tickets, tighten prompt engineering and retrieval settings, and ship small fixes daily.
The vendor partnership
The vendor behind the Agent matters just as much as the solution itself. You’re choosing a partner for transformation that will help you evolve how your business delivers customer experience. Ask:
How does customer feedback influence the product roadmap, and can they show you examples?
If you have feedback on limitations or weaknesses, do they engage transparently or get defensive?
What kind of support will you get post-launch?
Are they shaping where AI customer experience is going, or reacting to what others are building?
How a vendor responds to those questions tells you more about the long-term relationship than any benchmark result.
What a good POC proves
If your POC only proves “the AI works,” you haven’t done enough. A strong proof of concept tests performance in realistic conditions, evaluates the experience from the customer’s perspective, and validates the system that will support continuous improvement after launch. Done well, it sets you up for long-term operational success and builds organizational AI readiness—not just a flashy demo.
I’m getting sharper, more specific questions about scale from enterprise customers every quarter, and that’s exactly how it should be. Teams want to know how our platform behaves during their highest-volume moments — the Black Friday sales, the sporting events, the production incidents — and they want confidence their growth won’t outpace the systems they depend on.
We welcome those questions. They’re the right ones to ask of any critical component of your business.
Today, our systems handle serious scale. At daily peak, we see over 150,000 customer requests per second coming into the platform, with more than 70,000 asynchronous requests per second flowing through the background systems. During our busiest days of the week, we handle over five million conversations and more than 100 million comments being added across the platform.
We also design for individual customer spikes, not just aggregate platform traffic. We can handle a single customer workspace spiking with hundreds of comments per second, or around 100 new conversations per second. Sustained over a full day, that would map to millions of conversations from a single customer.
While those numbers matter, they age quickly. Every growing software company can publish a bigger number every year, month, week. What ultimately matters is whether the architecture has clear scaling levers, whether we understand the pressure points in the system, and whether we can add capacity before customers need it.
Every system has limits. Competence is knowing where they are, measuring them, and moving them before customers reach them.
Here’s how we do that in practice.
We build on boring foundations because at the edges, we try hard not to be clever. We use AWS for the infrastructure primitives AWS is very good at running. We do not want our engineers spending their best energy recreating S3, load balancers, queues, or commodity infrastructure patterns. We want that energy spent on the parts of the system that are specific to our customers and our product.
“That is a deliberate trade-off. It gives us fewer systems to understand, deeper expertise in the ones we do run, and more leverage when we need to scale.”
This extends a principle I’ve embraced for years: run less software. The point isn’t to minimize the stack for its own sake; it’s to compound expertise. When many teams build on the same small set of technologies, our tooling, observability, and operational practice all improve together. Boring technology choices aren’t a lack of ambition — they reserve our ambition for the nuanced scaling challenges that matter.
The source of truth is the hard part. You can scale stateless web traffic by adding machines, add queue consumers, and add cache. Those are real problems — just not the hardest ones. The source-of-truth database is where the most important data lives, where the hardest correctness guarantees exist, and where maintenance windows often come from. It has to be correct, fast, resilient to failover, capable of large migrations, and able to keep serving traffic while we improve it. As customers grow, it cannot require a full re-architecture every time the next ceiling appears.
That is why we moved to Vitess, managed by PlanetScale. The goals were clear: improve availability, reduce operational complexity, make large table migrations safer, simplify MySQL scaling, and eliminate customer downtime from routine database maintenance and failovers. When we first laid out this direction, the largest part of the migration was still ahead of us. We completed that migration in 2025, and the benefits are now part of how we operate the platform day to day.
Today, our highest-scale source-of-truth data is spread across 128 shards. The database layer handles around two million requests per second, with more than ten million cache reads per second in front of it. For the largest customers, we can isolate and scale database capacity independently, including dedicating a shard to a single customer when needed.
We have not come close to needing that, which is significant. The goal of architecture like this is not to run every system at the edge of its capacity, but rather to have room to move before customers need it. Vitess gives us native sharding, query routing, online schema change capabilities, connection pooling, and resharding primitives built for this kind of workload. Instead of application code carrying all of the sharding complexity, the database layer can do more of the work. That reduces cognitive load for engineers and removes whole classes of operational risk.
Ultimately, this gives us practical scaling options instead of hard architectural rewrites, and lets us do routine database improvement without planned customer-impacting maintenance windows.
Search is not a hidden bottleneck for us. Search underpins core product surfaces across the platform — from vector search in our AI features to realtime reporting — and if it’s slow or unhealthy, customers feel it. Scaling isn’t just adding more machines; often the better approach is making the product do less unnecessary work. Today, our Elasticsearch clusters support a much higher-throughput product than in the past, with more than 650TB of storage, more than 1.7 trillion documents, and peaks above 40,000 requests per second. We’re serving a larger product surface more efficiently, not just running a bigger cluster.
More importantly, when an index gets too large or traffic distribution turns unhealthy, we don’t want a high-risk, manual migration. We reshape Elasticsearch indexes online by partitioning by customer ID, dual-writing to old and new indexes, backfilling, validating, gradually moving customers with feature flags, and deleting the old index only when we’re confident. We’ve used this pattern for years to make large search migrations safer and more incremental — a core playbook in our platform scalability and SRE practices.
Fairness is non-negotiable in a multi-tenant system. A single customer’s high-volume moment should not quietly become everyone else’s latency problem. We design for this at multiple layers. For asynchronous work, we use overflow queues and queueing strategies that prevent one high-volume workload from consuming shared capacity in a way that hurts quieter tenants. AWS SQS fair queues are one example of a primitive we use extensively. They’re designed for exactly this class of problem. When one tenant creates a backlog in a shared queue, fair queues help reduce the dwell-time impact on other tenants.
We also build application-level guardrails so customer isolation doesn’t depend on every engineer remembering every rule in every code path. In a large multi-tenant Rails application, the safe path must be built into the system. The focus is primarily about correctness and customer data separation, but the broader operating principle is the same: important customer boundaries should be enforced by infrastructure and application frameworks.
The same thinking applies to scale. We want customer-specific load to be visible, attributable, and controlled. When a customer spike happens, we should be able to understand it as that customer’s workload, protect the rest of the platform, and add capacity where it’s actually needed.
Fin adds a new dimension to scaling. Our AI Agent Fin introduces a new set of infrastructure challenges. To provide reliable AI-powered support at scale, we need to operate across multiple model providers, route across them based on capacity and latency, and protect customer-facing workloads from lower-priority work. The details differ from traditional SaaS infrastructure, but the principle is the same: understand the bottlenecks, build clear scaling levers, and monitor the customer outcome. AI providers are not commodity storage systems, and we do not design as if they are.
That is why we have invested in Fin-specific reliability systems. Fin now fully resolves over two million conversations per week. At that scale, high availability cannot depend on a single model, a single provider, a single region, or a single pool of capacity. Our LLM routing layer supports cross-vendor failover, cross-model failover, latency-based routing, capacity isolation, and load testing. We also maintain buffer capacity with major providers, with headroom to handle 2x to 3x normal Fin traffic at any point. For enterprise customers, this matters because AI support volume can spike just like human support volume — and the AI layer must absorb that spike without relying on one fragile upstream path.
When customers depend on Fin to absorb a spike in support demand, the AI layer needs the same operational discipline as the rest of the platform.
Performance tests help, but production traffic is reality. Real customers use products in ways no synthetic test will perfectly predict: launches, incidents, seasonal patterns, gaming events, sudden changes in end-user behavior. Those moments give us data that no lab can fully reproduce. Often, a large customer event barely moves the platform-wide graphs because our customer base is broad enough that one industry’s peak aligns with another’s quiet period. Black Friday and Cyber Monday are good examples. Many ecommerce customers are at their busiest, while many B2B SaaS customers are quieter. At the aggregate platform level, the change can be much less dramatic than people expect.
“That does not mean those events are unimportant. It means we need to look at both levels: the health of the overall platform and the experience of the individual customer having the spike.”
Sometimes, these events teach us something specific. In one case, a very large customer used the Messenger in a way that exercised the full Messenger lifecycle even though the visible user experience did not require it. Under normal traffic, this was fine. During a major customer-side incident, their users refreshed aggressively, generating a much larger burst of Messenger traffic than the integration actually needed. The platform stayed available, but the event exposed unnecessary work in that integration path. We built a lighter-weight integration path that served the customer’s actual use case with far less work per request, making future spikes easier to absorb.
We treat large customer events this way even when there’s no broad customer impact. They’re opportunities to understand real scaling properties and make the next event safer — a habit that anchors our incident management, observability, and FinOps practices.
Scale is also an operating model. The infrastructure matters, but it’s not enough. You can have the right database architecture and still hurt customers if you detect issues late, recover slowly, communicate poorly, or fail to learn from incidents.
“That is why our operating model starts with customer outcomes. If the customer cannot do the job they came to do, the system is unhealthy. It does not matter how many dashboards are green.”
Heartbeat metrics tell us whether customers can do the core jobs they hire us to do. They cut through infrastructure noise and answer the question that matters most during an incident: are customers able to use the product successfully?
This shapes how we ship. Today, we average around 250 ships to production per workday, with an average merge-to-production time under 10 minutes. That isn’t a vanity metric — it’s part of the safety model. Smaller changes are easier to understand, easier to observe, and easier to roll back. Feature flags let us separate deployment from release. Automatic rollback and heartbeat-driven detection help us recover quickly when a change hurts customers. These are the very DORA metrics we hold ourselves to in order to balance CI/CD speed with stability.
“Fast shipping is not the opposite of reliability. Done properly, it is one of the ways you stay in control of change.”
The bar is high. Engineers are expected to understand the impact of their changes, watch them go live, and act quickly if something looks wrong. Resuming service is not the end of an incident. We expect teams to understand the root cause, fix the contributing systems, and prevent recurrence. That’s how scale stays safe over time.
Scheduled maintenance should be extraordinary. Historically, database maintenance was a main reason for maintenance windows: upgrading a database, changing instance sizes, performing failovers, or moving large tables could require customer-impacting downtime. With the move to Vitess and PlanetScale, we changed what routine database improvement looks like. We can upgrade, scale, and improve critical database infrastructure without turning that work into planned customer-impacting downtime — and we do this in practice, not just as a goal.
This matters because customers rely on our platform for live operations. If their support team, Messenger, Help Desk, or AI Agent is unavailable, the impact is immediate. Scheduled maintenance cannot be treated as a casual operational convenience.
“Our posture is simple: routine infrastructure improvement should not require planned customer-impacting downtime.”
Scheduled maintenance should be exceptional, non-routine, clearly communicated, and minimized in frequency, duration, and customer impact. That’s the practical benefit of the architecture work: better scaling is not only about handling more traffic, but also reducing the operational moments that might inconvenience customers.
What this means for customers is simple: be skeptical of vague scale claims. The question isn’t whether a vendor says they can scale — it’s whether they can explain how, where the limits are, what they measure, how they recover, and what they’ve changed after learning from production. We understand the scaling properties of our systems, have clear levers to add capacity at the right layers, design for customer isolation and fairness, monitor customer outcomes directly, and use real production events to make the next one safer. Scale is never finished. Every large customer event, traffic spike, migration, and incident teaches us something about the real behavior of the system — and we use that data to keep improving. That’s what you should expect from a platform you depend on during your busiest moments.
Your discovery stack may already hold interview transcripts, support conversations, behavioral analytics, experiment results, and roadmap assumptions. Yet the decision in a product review can still depend on whoever read the most material or built the most persuasive deck.
If adding an LLM only gives you faster summaries, the workflow is not AI-native. An AI-native discovery workflow shortens the distance from evidence to a decision while making every important claim easier to inspect. AI retrieves, structures, compares, and challenges the evidence. You remain accountable for what the evidence means and what the product team does next.
Key takeaways
Begin every AI-assisted discovery run with an outcome, a metric, defined context, and a decision that someone needs to make.
Preserve raw evidence and give each observation a stable identifier before asking AI to synthesize it.
Break the workflow into bounded jobs such as retrieval, extraction, clustering, contradiction detection, and decision-brief drafting.
Evaluate citation accuracy, evidence fidelity, counterevidence, abstention, and access controls before the output enters a roadmap discussion.
Measure whether the workflow improves decision quality and product outcomes, not merely whether the model produces polished prose.
Frame the decision before you involve the model
Most weak discovery prompts fail before the model sees them. Analyze the interviews, summarize the feedback, and find insights are activities, not decisions. They give the model no principled way to distinguish useful evidence from interesting noise.
Outcome and metric: Name the user or business outcome, then define the behavior or measure that represents it. Activation, funnel conversion, and retention are not interchangeable. Include the event definition and observation window used by your analytics system.
Context and constraints: State the relevant cohort, product surface, timeframe, market, known exclusions, and data-access limits. New self-serve accounts on the web can exhibit a different pattern from established accounts or customers using another surface.
Decision and deliverable: Say what someone will do with the answer. Ask for a ranked opportunity brief, an interview plan, a set of competing explanations, or experiment candidates only when that format supports a real pending decision.
Reusable decision prompt: Help me decide [decision]. The outcome is [outcome], measured as [metric definition]. Limit the analysis to [cohort, surface, timeframe, and constraints]. Retrieve evidence from [approved repositories]. Return [deliverable]. For every material claim, include the evidence identifier, any conflicting evidence, the affected segment, and what is still unknown. If the available evidence cannot support a recommendation, say so and specify what is missing.
The last sentence matters. An AI system should be allowed to return insufficient evidence. If every run must end with a recommendation, the workflow rewards plausible completion instead of honest discovery.
Keep the outcome separate from the proposed solution. Improve activation is an outcome. Validate an onboarding checklist is already a solution choice. When you embed the solution in the prompt, AI tends to organize the available evidence around that choice instead of testing whether another opportunity matters more.
Use evidence-strength labels that a reviewer can verify rather than asking the model for an unsupported confidence percentage:
Sufficient: Direct evidence applies to the target context, and no material contradiction remains unresolved.
Mixed: Direct evidence and meaningful counterevidence both exist, or the pattern changes by segment.
Insufficient: Evidence is missing, indirect, stale for the decision, or outside the target context.
Build a traceable evidence pipeline, not a transcript pile
AI cannot make discovery evidence traceable if the underlying repository has already flattened observations, interpretations, and decisions into the same notes. Preserve those layers separately. My rule is simple: automate the movement and inspection of evidence before automating judgment.
Layer
What it contains
Control that matters
Raw evidence
Interview recordings or transcripts, support records, session evidence, and analytics query results
Keep the original record intact, access-controlled, and addressable by a stable locator
Evidence units
Atomic observations with metadata
Separate exact customer language, observed behavior, and analyst interpretation
Opportunities
Candidate needs, frictions, or desired outcomes
Attach supporting evidence, counterevidence, affected segments, and unresolved questions
Decisions
Choices made, rejected alternatives, assumptions, and rationale
Name the decision owner and preserve the evidence available at the time
Learning
Experiment results and later customer or behavioral evidence
Update the opportunity without erasing the earlier reasoning
Each evidence unit should carry enough metadata to survive outside its original document:
A stable evidence identifier.
The collection date and an exact locator such as a transcript timestamp or saved analytics query.
The relevant user segment, product surface, and journey stage.
The raw observation, kept separate from the interpretation proposed by a person or model.
The access, retention, and sensitivity classification.
The opportunity, assumption, or outcome to which the evidence may relate.
This structure prevents a common failure: a model paraphrases an interview, a later summary compresses that paraphrase, and the roadmap eventually treats the compressed interpretation as a customer fact. A reviewer should always be able to move from a claim to the evidence unit and then to the original record.
Apply data-governance rules before ingestion. If customer conversations contain personal, confidential, or contract-restricted information, do not copy them into an AI system until its access, retention, redaction, and model-training terms match your commitments. A more convenient synthesis workflow is not worth an unauthorized disclosure.
Retrieve the smallest useful context
Once the evidence corpus no longer fits sensibly into a prompt, use a retrieval-first pipeline with modular prompts and observable traces. Retrieval-augmented generation should select evidence relevant to the decision contract, rather than asking a general agent to reason over everything the company knows.
RAG is a grounding mechanism, not a truth guarantee. A fluent answer does not prove that the retriever found the decisive interview, the correct event definition, or the evidence that contradicts the dominant pattern. Configure retrieval to look for both support and contradiction, preserve evidence identifiers, respect access controls, and return no result when the available context does not meet the task.
An opportunity solution tree can provide the shared view above this pipeline: the desired outcome connects to opportunities, solution candidates, and tests. Treat the tree as a navigable representation of current thinking. Every important node should still resolve to evidence and assumptions beneath it.
Give AI a chain of bounded jobs
A single agent asked to interview customers, interpret feedback, size opportunities, choose a solution, and write a roadmap has too many ways to hide a weak inference. Break the work into stages with explicit inputs and review gates:
Prepare: Give AI the outcome, assumptions, and learning gaps. Let it draft non-leading interview questions. A human checks whether the guide is testing an assumption or merely inviting agreement.
Convert: Extract atomic observations from approved records. Require exact locators and label customer language, observed behavior, and interpretation separately.
Synthesize: Cluster candidate opportunities without erasing segment differences. Request supporting evidence, counterevidence, and unrepresented cohorts for every cluster.
Connect: Use behavioral analytics to examine whether the observed pattern appears in the target cohort. Interviews can expose mechanisms and unmet needs; they should not be treated as a substitute for measuring prevalence.
Challenge: Ask for rival explanations, evidence that would reverse the conclusion, and assumptions that remain untested. This stage should consume the evidence record, not just the previous summary.
Draft: Produce a decision brief containing the pending decision, options, evidence, contradictions, unknowns, and proposed next test. A named human accepts, revises, or rejects it.
Learn: Attach experiment and outcome evidence to the same opportunity record. Preserve what the team believed before the test so later reviewers can inspect how the decision changed.
Pass structured artifacts between stages. If each stage receives only prose copied from the previous chat, unsupported claims can become progressively harder to distinguish from evidence.
Buy workflow plumbing; own the decision logic
You do not need to build every repository, connector, permission system, visualization, and observability screen. Licensing purpose-built opportunity-tree infrastructure can be the sensible choice when your differentiated work is the learning system rather than the canvas or collaboration layer.
Keep ownership of the parts that encode how your company makes product decisions: the decision contract, evidence schema, opportunity taxonomy, prompt modules, evaluation cases, escalation rules, and approval gates. Before choosing a platform, ask:
Can you export the raw evidence, metadata, opportunity structure, prompts, and run traces?
Can access rules follow the evidence through retrieval and generation?
Can the system connect to your approved analytics and customer-evidence repositories without repeated manual copying?
Can you evaluate a prompt or retrieval change against representative past cases?
Can a reviewer inspect why a claim appeared and what evidence was omitted?
Would building this capability improve the customer outcome, or merely recreate commodity workflow infrastructure?
Evaluate the workflow before it shapes the roadmap
Start evals before AI-generated conclusions become routine inputs to product reviews. The evaluation set should represent the cases the workflow will actually encounter: a clear pattern, conflicting evidence, insufficient evidence, cohort-specific behavior, stale material, duplicated records, and content the requesting user is not allowed to retrieve.
For synthesis and decision-support tasks, evaluate behavior that a reviewer can observe:
Citation validity: Every material claim points to a real, accessible evidence identifier.
Evidence fidelity: Quotations and behavioral facts remain faithful to the underlying record; interpretations are labeled as interpretations.
Retrieval coverage: The output includes the evidence required to assess the target opportunity, not merely the easiest matching passages.
Contradiction handling: Material counterevidence and segment differences are visible rather than buried.
Abstention: The system returns insufficient evidence when the decision cannot be supported.
Decision fit: The deliverable answers the stated decision instead of drifting into a generic summary or unrelated recommendation.
A strict release gate is useful here. Fail the output if it invents an evidence identifier, turns an interpretation into a quotation, ignores a material contradiction, or exposes restricted content. Those are not cosmetic defects that a polished paragraph can offset.
Treat the prompt, retrieval configuration, model choice, taxonomy, and evaluation set as versioned artifacts. This is the practical value of eval-driven development and early observability: when behavior changes, you can identify the change that caused it and rerun representative cases before wider use.
For each production run, retain the decision contract, evidence identifiers retrieved, prompt and retrieval versions, generated output, reviewer edits, final decision, and later outcome. That trace lets you distinguish a retrieval failure from a synthesis failure, a weak decision contract, or a reasonable decision invalidated by new evidence.
Model-quality checks are only one layer. Also baseline and monitor the discovery workflow itself:
Time from a framed question to a reviewable decision brief.
The share of material claims with inspectable evidence.
Reviewer corrections to quotations, segments, event definitions, and interpretations.
Decisions reopened because relevant evidence was missing or misread.
Movement in the outcome and metric named in the original decision contract.
Do not set improvement targets until you have a baseline for the existing process. A system can make synthesis faster while increasing correction work or encouraging premature decisions. The end-to-end measure tells you whether the saved time is real.
Turn the workflow into a product operating system
AI-native discovery changes the product team’s operating model only when ownership remains explicit. The product manager or product trio owns the outcome, assumptions, and decision. Research and design judgment protects interview quality and interpretive nuance. Data and engineering ownership protects event definitions, retrieval reliability, instrumentation, and access controls. AI produces candidate artifacts. The decision owner approves the action.
Review by exception instead of rereading every generated sentence. Inspect claims marked mixed or insufficient, new opportunity clusters, segment differences, material contradictions, changed event definitions, and outputs that differ from earlier runs. This focuses human attention where judgment is most valuable without treating the model as an authority.
Roll out the workflow through one recurring, reversible discovery decision:
Choose a decision for which customer evidence and behavioral data already exist, such as prioritizing an onboarding friction or investigating a repeated support issue.
Baseline the current path from question to decision, including reviewer corrections and missing-evidence failures.
Create the decision contract, evidence schema, and access rules before connecting an agent.
Build the evaluation set from previous clear, contradictory, insufficient, segment-specific, and restricted cases.
Run the AI workflow in shadow mode beside the existing process. Compare claims, omissions, reviewer effort, and the resulting decision without allowing the generated output to act automatically.
Promote bounded jobs only after they pass their gates. Evidence extraction may be ready before opportunity ranking, and opportunity ranking may be ready before solution recommendations.
Expand to another workflow only when the traces are stable, reviewers understand escalation paths, and the first use case is improving the decision process rather than merely generating more material.
At your next discovery review, do not ask what AI found. Bring one decision contract, require every consequential claim to resolve to evidence, and make the unresolved assumption visible. That is a small enough change to start immediately and a strong enough foundation for everything you automate later.
I’m excited to share two opportunities this season to uplevel your craft, connect with peers, and leave with practical, repeatable techniques you can apply immediately to your product work.
We will be doing another round of Claude Code: Show and Tell on May 26th at 9am PDT. These community-driven sessions are hands-on and fast-paced—we swap proven workflows, compare prompts, and pressure-test approaches together. You’ll see how product teams are operationalizing AI workflows in real contexts and walk away with ideas you can adapt for your own roadmap and experimentation pipeline. Invites will go out to Supporting Members and CDH Members tomorrow. If you'd like to join us, keep an eye on your inbox for the invite.
I love these Show & Tell sessions because they translate tacit knowledge into clear, reusable playbooks. Whether you’re refining evaluation loops for LLMs, streamlining discovery synthesis, or standardizing prompts for consistency, the shared rigor and camaraderie make it a high-signal hour for any product leader invested in AI workflows.
I also want to share that I'll be teaching our June 4th – July 9th cohort of Product Discovery Fundamentals. This is the last time I'll be teaching this cohort in its current format. If you've been thinking of enrolling in this program, and want to take it with me, this is your last chance. Register here.
Across this cohort, we’ll practice continuous discovery habits—framing opportunities, tightening assumptions, running lean experiments, and aligning product trios on evidence-backed decisions. If you want a rigorous, repeatable system for turning customer insight into confident prioritization and compelling product strategy, I’d be thrilled to have you in the room.