
I’m excited to share that we’re opening our next R&D hub in Berlin to support significant investment in our AI customer service platform, Intercom, and market-leading AI Agent, Fin. We intend to hire 100 people in Berlin over the year ahead across engineering, AI, data science, product, and design. This move reflects our AI Strategy, our commitment to product management leadership, and our focus on building enduring product-led growth.
We believe that in a short number of years, the vast majority of customer service will be done by AI. Fin is already the world’s best Customer Service Agent. At Pioneer, our recent summit for AI customer service leaders in NYC, we talked about how Fin will become a true end-to-end Customer Agent, extending far beyond service. We showcased how companies like WHOOP, Anthropic, and Lightspeed are already pushing Fin in ways that help them grow their business.
This market opportunity is massive and expanding at unprecedented pace. Our ambition is to earn our place as one of the most successful AI businesses during this wave of AI disruption, and we want more brilliant people on our team to pursue this as aggressively as possible. If you’re motivated by Generative AI, LLMs, and building real products that scale, you’ll find both challenge and impact here.
We are already on track to be one of the fastest growing private software companies. Fin is the primary contributor to this, and is months away from passing $100m in ARR. So far, more than 7000 businesses have transformed their customer service with Fin, including German companies like electricity provider Ostrom, smart home technology provider tado°, and grocery delivery company Flink, along with global leaders like Vanta, Clay, Lovable, and Miro.
Why Berlin? We’re drawn to the city’s rare blend of deep technical talent and rich creative culture—within a vibrant, globally connected ecosystem close to our R&D hubs in Dublin and London. It’s a place where top-tier engineers and designers thrive, and where ambitious builders from around the world want to relocate and create category-defining products.
We needed a new location that would sustain the high ambition and standards held by our world-class AI teams in Dublin and London. Berlin has emerged as one of Europe’s hottest centers for AI talent, with a high density of AI-focused startups, applied research labs, and practitioners who bring exceptional literacy, optimism, and ambition. It’s the right accelerator for our AI hiring and a place to bring in brilliant minds to shape the future of our product and business.
While Intercom’s reach is global with our headquarters in San Francisco, our R&D leadership remains anchored in Dublin, where half of the executive team sits—making Berlin both geographically and strategically an ideal next location for our growth.
This isn’t our first time expanding our footprint; we previously bet on London and are delighted with how that’s been working. When we shared our Berlin news internally, the energy was palpable, with many teammates volunteering to help spin up the hub successfully—including colleagues who helped make London a big success, like Danny. That level of ownership and momentum is exactly what we aim to cultivate in Berlin.
We’re looking for people who thrive in a high-intensity, high-ambition, high-standards environment and want to help build one of the world’s best AI companies. For builders like that, the opportunity for impact, growth, and career progression is extraordinary. As with London and Dublin before it, the early Berlin cohort will have a disproportionate influence on team norms, culture, and long-term outcomes. We are in the middle of a huge disruptive wave with AI, and Fin is one of the leading examples of commercially successful AI applications. Joining Intercom is an opportunity to be part of this disruptive wave, and help us build out our vision for Fin becoming the world’s best Customer Agent.

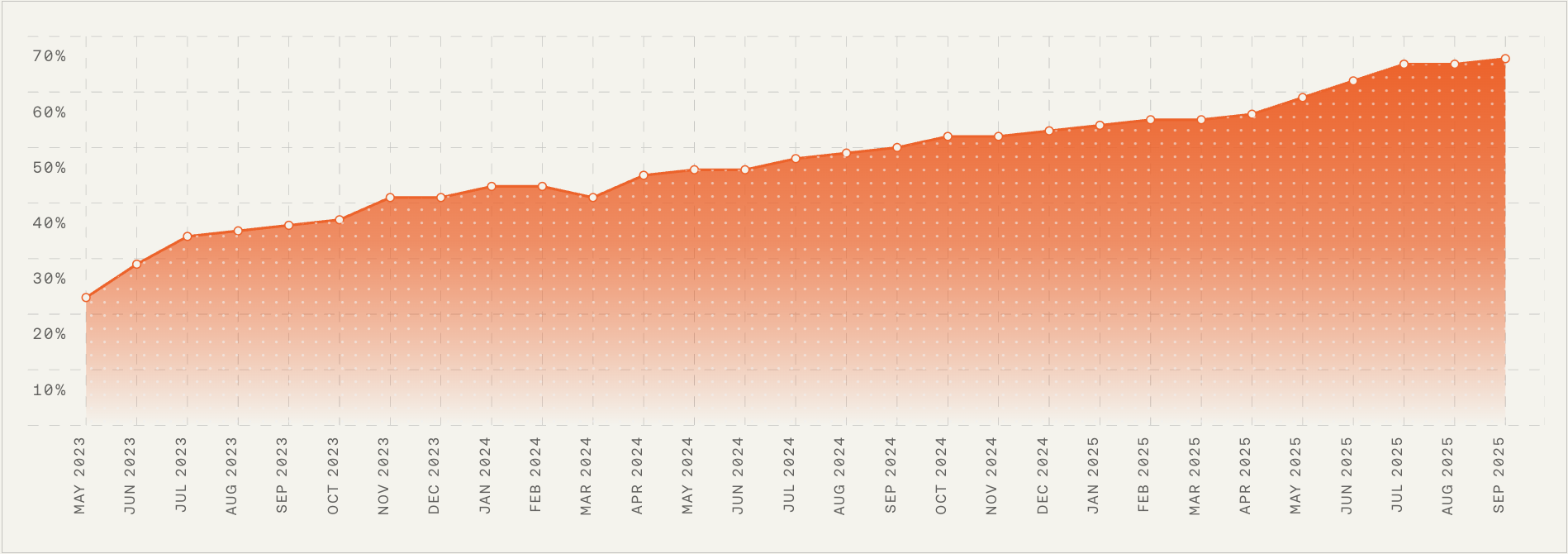
There are plenty of AI companies to join, but our technology and culture set us apart. Any AI product is only as good as the AI layer powering it. Ours is industry-leading, built by a highly talented, ambitious, and technical team of over 40 machine learning scientists, engineers, and designers in Europe who continuously optimize Fin’s performance through cutting-edge research, experimentation, and innovation. Fin’s average resolution rate increases 1% every month. That kind of steady, compounding improvement is exactly what great customer support AI strategy looks like in practice.
We also build in public and share our progress and learnings with the AI community at large. Recently, our Chief AI Officer Fergal Reid and SVP of Engineering Jordan Neill joined leaders from Cognition, Harvey, and Perplexity in San Francisco to share real lessons, challenges, and breakthroughs from building frontier AI products. Our AI team regularly publishes their insights on the AI research blog; from optimizing inference speed and availability, to building our own proprietary models that outperform general purpose models for CX.
Our AI group and the broader R&D org they operate within work at extraordinary scale and speed. We recognize that moving fast can’t be taken for granted—you must fight for it—and we’re doing just that, embracing the capabilities AI tooling brings us to achieve 2x the throughput. One example of this mindset in practice is us “Betting on the future of frontend at Intercom,” making a technology choice that optimizes for our teams’ ability to build high-quality product, fast.
Our design and product teams are world-class and forward-thinking; they’re embracing AI to evolve how they work, as shared in our 3-point framework for AI-driven design and recently presented by Emmet Connolly, our SVP of Design, at this year’s Hatch conference in Berlin. As a product leader, I’m grateful to work alongside brilliant product and design thinkers—it gives me confidence that we’re solving the right problems, solving them well, and driving real impact.
We plan to open our Berlin office space in December or January. To get the office started, we’re hiring Senior Product Engineers, Machine Learning Scientists, Product Managers, Senior Product Designers, Engineering Managers, and Data Scientists immediately. If your craft sits at the intersection of LLMs for product managers, agentic AI, and empowered product teams, you’ll be right at home.
You can learn more about our open roles, company, culture, and locations on our careers site, or feel free to reach out to me, Jordan, Fergal, or Brian directly on LinkedIn if you have any questions.
Some of our engineering team will also be at LeadDev Berlin on November 3rd—come say hi if you’re attending.
I’m looking forward to continuing to build Intercom as one of our generation’s best AI companies—and I’m excited for our expansion into Berlin to be a major contribution to that success.
Inspired by this post on The Intercom Blog.


