Product management tools can reduce coordination work, preserve decisions, and help teams turn customer and product signals into action. Choosing them well, however, requires more than comparing feature lists.
The supplied Amplitude – Perspectives excerpt defines these tools broadly as platforms, websites, and software that make a product manager’s job easier. Because the excerpt does not include the product names, evaluations, senior-PM advice, or supporting details promised by its headline, the framework below does not attempt to reconstruct that missing list.
What belongs in a product management tool stack
A product management stack is the collection of systems used to support recurring product work. Depending on the organization, that work may include collecting customer evidence, analyzing behavior, defining priorities, documenting decisions, planning delivery, running experiments, and communicating progress.
The important distinction is between owning software and enabling a workflow. A tool creates value when it makes a necessary activity clearer, faster, more reliable, or easier to share. If it merely duplicates an existing system, it can add another place to search, update, and reconcile.
Key takeaways
Start with the product workflow and its friction points, not a catalog of vendors.
Evaluate adoption, integration, governance, and decision quality alongside features.
Give each system a clear purpose and a defined owner.
Reassess tools when the team, product, or operating model changes.
Begin with the decision the team needs to improve
A useful selection process begins by naming a specific decision or handoff that is not working. The problem might be scattered customer feedback, weak visibility into user behavior, inconsistent prioritization, unclear ownership, or roadmap updates that require repeated manual effort.
From there, the team can define what better performance looks like in general terms: less duplicate entry, a more dependable record of decisions, easier access to evidence, or clearer communication between product, design, engineering, and go-to-market groups. This keeps procurement tied to an operating need rather than enthusiasm for a new interface.
It also clarifies whether software is actually the answer. Some problems come from missing ownership, inconsistent terminology, or an undefined process. Adding a platform to that environment may formalize the confusion instead of resolving it.
Assess the full cost of fit
Functional coverage matters, but it is only one part of fit. A team should also consider how naturally a candidate tool enters existing work, which systems it must exchange information with, how permissions will be managed, and what effort will be required to maintain trustworthy data.
Adoption deserves particular attention. A sophisticated platform offers little practical value if contributors avoid it or if stakeholders cannot understand its outputs. A narrower tool that supports a well-defined workflow may outperform a broader suite that demands extensive configuration and behavior change.
The evaluation should therefore test real work rather than an idealized demonstration. Representative users can walk through a normal task, identify where information enters the system, and examine how the resulting decision reaches everyone who depends on it. That exercise reveals workflow gaps that a feature checklist may miss.
Control tool sprawl with ownership and review
Every adopted system should have a stated job, an accountable owner, and a clear relationship to the team’s source-of-truth systems. Those boundaries reduce the risk that roadmaps, customer insights, and delivery status drift into conflicting versions across multiple platforms.
Periodic review can then focus on outcomes: whether the tool is used, whether its information remains credible, whether it supports better decisions, and whether another system now covers the same need. The goal is not the largest possible stack. It is a coherent product operating environment in which each tool continues to earn its place.
Inspired by this post on Amplitude – Perspectives.
Feature management gives product teams a controlled way to decide how new capabilities reach users after the underlying code has been deployed. This separation can make releases more gradual, observable, and reversible.
Amplitude – Perspectives presents feature management as a contributor to innovative product development and introduces the topic through insights from guest Chris Condo, identified by the publication as a Forrester Principal Analyst. Because the available source is only a brief summary, the practical guidance below explains the established discipline without attributing unreported claims to Condo or the publication.
Feature management extends beyond feature flags
A feature flag is a technical mechanism that can turn behavior on or off without requiring a fresh deployment. Feature management is the broader operating practice around that mechanism: defining the intended audience, controlling exposure, observing results, assigning ownership, and deciding whether to expand, revise, or remove a feature.
The distinction matters because a flag alone does not create a sound product decision. Teams still need an explicit hypothesis, release criteria, relevant evidence, and a person accountable for the outcome. Without those elements, flags can become permanent switches that add complexity while providing little learning value.
Controlled exposure changes the release decision
A conventional launch can bundle several decisions into one moment: deploy the code, make it available to everyone, announce it, and accept the operational consequences. Feature management allows teams to separate those decisions. Code may be deployed while access remains limited, then exposure can expand as confidence grows.
Common approaches include enabling a capability for internal users, a defined customer segment, or a limited share of eligible traffic. The appropriate sequence depends on the feature’s risk, the quality of available signals, and the team’s ability to respond when something goes wrong. A narrow rollout is useful only when the organization is prepared to monitor it and act on what it learns.
Key takeaways for product teams
Define the customer problem and expected outcome before configuring a rollout.
Treat deployment, release, and promotion as related but separate decisions.
Set expansion, pause, and rollback criteria before exposing the feature.
Combine behavioral evidence with customer feedback and operational signals.
Assign an owner and a removal date for every temporary flag.
A practical operating loop
Feature management works best as a repeatable decision loop rather than a collection of launch-day controls. A lightweight process can keep product, engineering, design, data, and go-to-market participants aligned:
Frame the decision. State what the team expects to improve and which users should benefit.
Choose the exposure plan. Identify eligible users, exclusions, rollout stages, and safeguards.
Prepare observation. Confirm that product, reliability, and support signals can reveal both value and harm.
Review the evidence. Decide whether to expand access, hold the rollout, change the experience, or withdraw it.
Close the loop. Remove obsolete flags, document the decision, and carry the learning into future product work.
This process should remain proportional to the risk. A minor interface adjustment may need little ceremony, while a change affecting permissions, billing, privacy, or a critical workflow warrants stronger controls and broader review.
The discipline has costs as well as benefits
Controlled releases can reduce exposure to problems and improve learning, but they also create operational obligations. Multiple feature states increase testing demands. Targeting rules can make customer support harder when users see different experiences. Long-lived flags can complicate the codebase, and poorly designed experiments can produce misleading signals.
Governance therefore belongs inside the practice, not around it. Teams need naming conventions, access controls, auditability, flag inventories, cleanup expectations, and clear decision rights. Product leaders should also distinguish experimentation from risk control: a rollout designed to detect failures is not automatically a valid test of customer value.
The most useful next step is modest: select one meaningful upcoming release, define its exposure and decision criteria in advance, and use the resulting evidence to refine a repeatable feature-management approach.
Inspired by this post on Amplitude – Perspectives.
Continuous Discovery Habits turned five this year, and I see that milestone as a useful reminder: great product teams do not discover customer value through occasional workshops. We build the habit of discovery through repeated practice, structured reflection, and honest conversations about what we are learning.
This month, I am focusing on Chapter 8: Supercharged Ideation. For product leaders, product trios, and empowered product teams, this chapter is especially practical because it challenges one of the most persistent myths in product discovery: that traditional brainstorming is the best path to better ideas.
In my own product management work, I have seen teams move too quickly from opportunity to solution. We often identify a real customer problem, feel the pressure to show momentum, and then rally around the first plausible idea. The problem is not that the first idea is always bad. The problem is that our first idea is rarely our best idea.
This Month’s Reading
Chapters:
Chapter 8: Supercharged Ideation
Estimated reading time: ~18 minutes
This chapter introduces several ideas that matter deeply for product discovery, prioritization, and product strategy:
Why quantity of ideas leads to quality – your first idea is rarely your best idea
The four reasons traditional brainstorming doesn’t work (and what to do instead)
How to generate 15-20 ideas for a single opportunity without getting stuck
Why individuals outperform groups at ideation – and how to get the best of both
Using dot-voting to whittle ideas down to three for a compare-and-contrast decision
I find the compare-and-contrast framing particularly important. Too many product decisions are framed as whether or not decisions: should we build this, should we not build this, is this feature good, is this feature bad? A stronger product discovery process forces us to compare multiple viable paths before we commit.
Why Supercharged Ideation Matters
Supercharged ideation is not about being louder, more creative on command, or filling a whiteboard with random concepts. It is about creating enough solution diversity that the team can make a more informed choice. That distinction matters because product teams are not rewarded for having ideas; we are rewarded for solving customer problems in ways that support business outcomes.
Traditional brainstorming often feels productive because everyone is in the same room and ideas are moving quickly. But group dynamics can quietly narrow the range of thinking. Senior voices carry more weight, early suggestions anchor the conversation, and quieter team members may never share the insight that could reshape the direction.
The individual-then-share approach gives each person space to think before the group converges. I have found this especially useful with cross-functional product trios because design, engineering, and product often see different constraints and possibilities. When each discipline ideates independently first, the team gets a richer set of options.
Reflect and Discuss What You Read
When we reflect and discuss what we read, we absorb more of the material. It helps us put what we learn into practice. Don’t skip this step.
This chapter challenges how most of us think about ideation. We’ve all been taught that brainstorming is the answer, but research tells a different story. This month, I am examining my own relationship with idea generation and where I may be falling into common traps.
Individual Reflection
Think about the last time your team generated ideas for a solution. Did you generate multiple ideas for one opportunity, or did you generate one idea per opportunity? What was the outcome?
When you ideate, where do you get stuck? Is it after the first few obvious ideas? Do you struggle with wild ideas that feel unrealistic? Or do you find it hard to avoid jumping into evaluation mode too early?
Be honest: Do you have a favorite idea right now that you’re pushing for? What assumptions are you making about why it’s the best option? Are you falling in love with your idea before testing it?
That third question is the one I would push every product manager to answer honestly. Attachment to an idea can feel like conviction, but conviction without evidence can become a liability. Continuous discovery gives us a healthier path: generate multiple options, expose assumptions, and test before we over-invest.
Team Discussion
Walk through your team’s typical ideation process. Does it look more like traditional brainstorming (everyone sharing ideas out loud) or more like the individual-then-share approach the chapter recommends? What’s working and what isn’t?
Pick one opportunity from your current tree. As a team, can you generate 15-20 ideas for how to address it? If you get stuck before reaching 15, use the chapter’s techniques: look at analogous products, consider extreme users, or think about wild ideas.
Discuss: When you evaluate ideas as a team, do you tend to set up “whether or not” decisions (Is this idea good?) or “compare and contrast” decisions (Which of these ideas looks best?)? How might you shift to more compare-and-contrast decisions?
Put It Into Practice
The best way to learn supercharged ideation is to practice it with your team. These exercises help turn the concepts into a working product discovery habit rather than a theory we agree with but never operationalize.
A featured image of Teresa Torres' Continuous Discovery Habits, inviting Product Talk readers to join the July 2026 CDH Book Club and explore better product discovery practices together.
Exercise: Generate 15-20 Ideas for One Opportunity
Time: 45-60 minutes Do this: With your product trio (and consider inviting other team members for more diversity)
Choose a target opportunity from your opportunity solution tree. Set a timer and go through this process:
Individual ideation (5 minutes): Everyone generates ideas on their own. Aim for at least 7-10 ideas each. Write them down on sticky notes or in a shared doc.
Share round one (15 minutes): Take turns sharing your ideas. No evaluation yet – just share and ask clarifying questions if needed.
Individual ideation round two (5 minutes): Generate more ideas individually. The first round should have sparked new thinking. Push yourself to consider analogous products, extreme users, or wild ideas.
Share round two (15 minutes): Share your new ideas with the group.
Review and refine (10 minutes): Count your ideas. Did you reach 15-20? If not, do another quick round. Then, review the list together and remove any ideas that don’t actually address the target opportunity.
After the exercise, I would ask the team to pause before evaluating the ideas. What did we learn? Were the later ideas more creative than the earlier ones? How did hearing others’ ideas spark new thinking? Those questions help the team understand not only which ideas emerged, but how the quality of thinking changed through the process.
Exercise: Practice Dot-Voting
Time: 20 minutes Do this: With your product trio
Using the 15-20 ideas generated in the previous exercise, I would use dot-voting to narrow the field to three ideas:
Set the criteria: Remind everyone that you’re voting based on how well each idea addresses the target opportunity – not on feasibility, not on how “cool” it is.
Vote (5 minutes): Give each person three votes. You can put all three on one idea, split them across three ideas, or any combination.
Review the results (10 minutes): Which ideas got the most votes? If it’s clear that three ideas stand out, you’re done. If several ideas have similar vote counts, take a few minutes for people to advocate for their top picks, then vote again.
Check alignment (5 minutes): Once you have your top three, do a quick poll: Is everyone excited about at least one of these ideas? Does each idea have a strong advocate on the team?
Save these three ideas – you’ll use them for assumption testing in Chapter 9.
The discipline here is subtle but powerful. Dot-voting is not a popularity contest when it is used well. It is a lightweight mechanism for helping a product trio move from an overwhelming idea set to a manageable comparison set, while preserving enough variation to support real learning.
Go Deeper: Additional Reading
For teams that want to go deeper on product discovery, team creativity, and structured ideation, I would keep the following resources close. They are useful companions for product managers, designers, engineers, and leaders who want to build stronger discovery habits.
Supplementary Reading
Stop Brainstorming and Generate Better Ideas
That’s Not Brainstorming
How to Turn Bad Ideas Into Good Ideas
Product in Practice: Getting Engineers Involved in Brainstorming
Other Voices
On the Quest for Originality, Recombine the Familiar by Adam Alter
Creativity Is Not an Accident by Scott Berkun
A Data-Driven Approach to Group Creativity by Bastian Bergmann and Joe Schaeppi
Live Discussion Schedule
For teams following the July 2026 reading cadence, the live discussion schedule is:
Thursday, September 17, 2026: 9am-10am PDT and 4pm-5pm PDT
Wednesday, December 16, 2026: 9am-10am PST and 4pm-5pm PST
My Product Leadership Takeaway
My biggest takeaway from Chapter 8 is that better ideation requires both independence and collaboration. We need independent thinking to expand the solution space, and we need collaborative discussion to clarify, combine, and compare ideas. When we skip either side, the quality of our product decisions suffers.
For me, this is where continuous discovery becomes a leadership practice, not just a team ritual. Leaders have to create the conditions where teams are not punished for exploring multiple options, questioning favorite ideas, or slowing down long enough to test assumptions. That is how product discovery becomes more than a process. It becomes a product culture.
If I were applying this immediately with a product trio, I would choose one opportunity from the current opportunity solution tree, generate 15-20 ideas, dot-vote down to three, and carry those three into assumption testing. That simple sequence can turn a vague conversation about creativity into a concrete product management habit.
What makes an event truly unforgettable—and what can product teams learn from it? As I listened to an illuminating conversation about crafting experiences, I found myself reflecting on how the same principles translate directly to product strategy, continuous discovery, and the day-to-day work of product management leadership.
Listen to this episode on: Spotify | Apple Podcasts
In this episode, the conversation explores how Petra Wille and her co-organizer Arne design experiences (not just events) at Product at Heart and their Product Leadership gatherings. From a candlelit speakers' dinner in a rosemary-covered greenhouse to a disco ball that appeared for exactly 20 seconds, the details reveal how intentional design, sensory cues, and a little bit of goofy magic help people shed their corporate armor and open up to real inspiration and connection. The parallels back to product design are unmistakable—from designing for delight and awe, to the classic question of who you're choosing to serve.
In my role leading product teams, I see how these choices map directly to empowered product teams and the rigor of product discovery: you can’t please everyone, so you design deliberately for the right someone. That means curating for depth over breadth, and giving people agency through self-select paths—much like the "Hard Problems Club"—so niche audiences feel seen within a broader experience. It’s the same discipline we apply to product strategy and value proposition: clarity about the segment, the problem, and the kind of transformation we’re creating.
The programming choices here are also instructive. The team designed the Product at Heart Leadership Event across one and a half days, including a farm excursion and a leadership improv workshop. Those decisions weren’t ornamental; they were part of a deliberate journey that builds safety, curiosity, and connection—precisely the conditions that help leaders generate better ideas and have the real conversations that move work forward. In product, we build that journey through thoughtful onboarding, product tours, and progressive discovery.
I was struck by the role of sensory experience in unlocking inspiration—rosemary, zucchinis-as-instruments, and a three-meter disco ball. Too often, we conflate more features with more value; in practice, well-placed sensory or interaction details do more to create delight than another settings panel ever will. The same is true in software: microinteractions, purposeful motion, and small moments of surprise can change how people feel about your product, which changes how they use it.
What Petra calls "serendipity moments" resonated with me. Creating space for people to shed their corporate armor and make unexpected connections is as critical in community and conference networking as it is in a product’s information architecture. When we design pathways that invite contribution—opt-in tracks, intimate circles, and unstructured time—we invite the kind of learning and collaboration most teams say they want but rarely experience by accident.
The reflections on the World Domination Summit and the idea of designing for awe added a useful distinction: the difference between novelty and awe. Novelty is pleasant but fleeting; awe takes people out of the mundane and expands what feels possible. In product terms, awe is the moment a user realizes a new capability not only solves a task but changes how they think about their work. That’s the bar I want my teams aiming for in our roadmapping and journey mapping.
There’s also a pragmatic lesson in investment. The details that seem extravagant are often the ones that matter most—and not because they’re expensive, but because they’re intentional. A disco ball that appears for exactly 20 seconds signals care, timing, and narrative. In product, that’s the difference between a scattered backlog and a cohesive story: choosing the few standout moments that deliver meaning, not just motion.
For product leaders, the translation is clear: define who you serve, design for choice and delight, and invest in the details that unlock connection and insight. Whether it’s a farm excursion and leadership improv or a carefully crafted advanced-user path, the goal is the same—create conditions for real breakthroughs and lasting behavior change.
"If we can get through that armor and shut off the business reflexes, then inspiration is more likely to hit." — Petra Wille
Resources & Links
Follow Teresa Torres: https://ProductTalk.org
Follow Petra Wille: https://Petra-Wille.com
Mentioned in this episode
Strong Product People by Petra Wille
Product at Heart — Speakers Dinner Leadership (see the rosemary garden!)
Reflections on Product at Heart’s 2026 Leadership Event
Arne Kittler of Product at Heart
Product at Heart Conference — Hamburg 2026 (read about the Hard Problem Clubs)
House of Beautiful Business — an event that inspired Petra and Arne's approach to sensory experience
Petra’s recap for this year’s House of Beautiful Business in Tangier — Rituals, Rugs, and Radical Tenderness – My Experience at the House of Beautiful Business in Tangier
World Domination Summit — founded by Chris Guillebeau; "How to live a remarkable life in a conventional world"
Derek Sivers — mentioned as a spoken word contributor at experiential events
Have thoughts on this episode? I’d love to hear your perspective in the comments—what “awe moments” are you intentionally designing for your teams and your users?
Organizational change is exhausting—so I stopped trying to force it. After years of leading product teams, I’ve learned that trying to fix the people and processes around me is almost always wasted energy. If you’re eager to champion a better way of working inside a resistant organization, there’s a more sustainable path that actually drives results.
Here’s my starting point: individuals can’t change their organizations. I’m often asked to “train the PMs” or “install discovery practices,” but without executive sponsorship, organizational pain, and urgency, nothing moves. I now decline those well-intentioned requests and focus instead on creating the conditions for change.
My readiness check is simple and ruthless. Pain — organizational pain felt by leadership, not just you. Urgency — there has to be a cost to inaction. Awareness — people need to know solutions exist. If I can’t articulate these three clearly, I narrow the scope to what my team and I can control and demonstrate.
Practically, I elevate organizational pain by making it visible and quantifiable: missed outcomes vs output OKRs, customer churn tied to unmet needs, increased operational load from legacy workflows, or cycle time and deployment friction that slow learning. I create urgency by modeling cost-of-delay and showing the trade-offs we’re already making. And I build awareness by running small, transparent experiments that show there’s a credible alternative—continuous discovery, empowered product teams, and product trios solving for outcomes, not output.
“Organizational change starts with you — but it starts with you changing you, not your organization.” I take that literally. I refine my own discovery habits, make my assumptions explicit, and raise the quality bar on evidence. Whether it’s adopting AI responsibly in our workflow or redesigning how we do customer interviews, I change me first and let the results speak.
Show your work, don’t advocate your conclusions. Instead of arguing for “the right way,” I surface the pain, share how I reached my conclusion, and let others draw their own insights. I circulate decision logs that link customer evidence to product decisions, include short snippets from interviews, and map outcomes to proposals. That transparency lowers defenses, builds stakeholder buy-in, and shifts the conversation from opinion to observable facts.
Working within constraints, not against them. Stuck in a rigid, feature-factory process? You don’t have to change quarterly planning to do great discovery. Add customer context. Frame features around outcomes. Layer in the habits without touching the formal process. I’ve embedded discovery into existing rituals: adding customer insights to PRDs, tying features to measurable outcomes, and using thin-slice experiments that fit inside current delivery cadences. Over time, those habits compound.
The ripple effect is real. Teams that do great work and show it publicly become the ones everyone wants to emulate. That’s how influence actually spreads. I make results visible—brief Looms walking through our reasoning, dashboards that track outcome movement, and internal write-ups that highlight how the work changed a customer behavior. Visibility turns quiet wins into organization-wide momentum.
If you want a place to start this week, try this: define a sharp outcome, run three quick customer interviews, share your notes and decision rationale openly, and ship one small experiment tied to that outcome. Use the data to refine your next step and repeat. In a month, you’ll have a trail of evidence, not a pitch deck—and that’s what shifts minds.
In the end, sustainable change comes from consistent practice, not fiery advocacy. Focus on outcomes, make the pain and cost-of-inaction undeniable, and keep showing your work. The organization will move when it’s ready—your job is to make “ready” happen sooner by modeling what good looks like and making it impossible to ignore.
I build products under constant pressure to learn faster without breaking trust. Claude Code has become a pragmatic addition to my AI product toolbox because it helps me move from idea to evidence with less friction—while keeping engineering, design, and compliance in the loop.
“Claude Code for Product Managers explained: what it is, why it matters, and how it helps PMs prototype, validate, and move faster.” That line captures the essence. In practice, I use it to turn ambiguous problem statements into tangible artifacts—API stubs, SQL queries, test data, and lightweight prototypes—that sharpen conversation and accelerate decision cycles.
What is it in PM terms? A code-aware assistant that helps me prototype safely and quickly. I can generate example API calls, transform messy CSVs for retention analysis, draft instrumentation plans for Amplitude analytics, or spin up a mock service to validate an integration. Because it understands structure, it’s effective at scaffolding small utilities (e.g., a data cleaner or a CLI harness) that make discovery and validation faster.
Day to day, Claude Code reduces handoffs. If I’m exploring a new partner integration, I’ll have it produce a curl library and a Postman collection, then annotate each step with acceptance criteria and expected responses. When I’m shaping a feature, I lean on it to outline event taxonomies and feature flags so that engineering can wire telemetry without guesswork. For insights work, I’ll ask it to propose SQL for cohort, funnel, and retention analysis—always verifying against source schemas before anything touches production.
Speed is only useful when it improves signal quality. I anchor the workflow in continuous discovery: small hypotheses, thin-slice prototypes, and fast instrumentation. Claude Code helps me estimate A/B testing readiness (including minimum detectable effect), generate smoke tests for critical user paths, and structure an eval-driven development loop so we learn from every iteration. It also supports context window management by summarizing long PRDs into the few constraints a prototype must respect.
Governance matters. I apply AI readiness and AI risk management principles: never paste secrets or PII, isolate sandboxes, and log prompts as docs-as-code for auditability. I prefer a retrieval-first pipeline that feeds approved product docs, OpenAPI specs, and design tokens so generations stay grounded. When tools are integrated, I favor the Model Context Protocol (MCP) to constrain capabilities and maintain least-privilege access. Human-in-the-loop review is non-negotiable—especially for anything that might influence customer data or pricing.
The best outcomes show up in product trios. I’ll facilitate a live session with design and engineering: we co-create prompts, compare alternatives, and converge on a thin slice we can ship. That collaboration keeps us empowered, reduces interpretation drift, and turns Claude Code into an accelerant rather than a sidecar. Over time, the trio curates a reusable prompt library for PRD outlines, experiment checklists, and integration playbooks.
Getting started is straightforward: define a safe environment, assemble your authoritative corpus (requirements, specs, taxonomies), and codify a few high-value templates—API exploration, instrumentation plans, sandbox data generators, and acceptance tests. Track impact with simple, objective metrics: cycle time from hypothesis to instrumented prototype, time-to-first-signal, and the proportion of decisions made with data versus opinion.
There are pitfalls. Hallucinated fields can creep into API calls, schema drift can break generated queries, and “clever” refactors may miss edge cases. I mitigate this by grounding generations in current specs, asking for unit tests alongside any code, and validating against a staging environment before anyone talks about production. Treat Claude Code as a collaborator, not an oracle.
If your mandate is to learn faster, de-risk bets, and ship with confidence, Claude Code is worth adopting. Used thoughtfully, it compresses the distance between questions and answers, elevates product discovery, and lets teams validate more ideas with fewer meetings—without compromising on governance or quality.
I’m continually evaluating how to invest in my team’s professional development in ways that create lasting capability, not just momentary enthusiasm. Recently, I revisited a compelling conversation featuring Teresa Torres and Petra Wille that zeroes in on how product teams actually learn best—especially when we’re accountable for product management leadership and sustainable practice change across empowered product teams.
Listen to this episode on: Spotify | Apple Podcasts
What's the best way to invest in your team's professional development — train everyone at once, let people self-direct, or something in between?
In my experience, the answer depends on your goals, the maturity of your product discovery habits, and how you create peer accountability. What resonated most with me was their argument that small, intentional groups are a powerful (and underused) learning model—one that aligns with how we build momentum in product discovery, product strategy, and continuous discovery routines.
Three Models of Team Learning
Train everyone at once — builds shared language, but not everyone is ready at the same time
Self-directed learning — works for highly motivated individuals, but lacks accountability
Small-group learning — the sweet spot: peer accountability, shared momentum, and just-in-time relevance
Across my teams, I’ve seen organization-wide training create useful common ground, but it rarely changes day-to-day behaviors without a follow-on mechanism for practice. Self-directed learning can inspire, yet it often fails to translate into consistent habits without peer pressure and shared goals. Small-group learning, especially within product trios or adjacent squads, consistently drives the most adoption because it blends relevance, peer accountability, and just-in-time application to real customer interviews, roadmap decisions, and stakeholder management challenges.
Why Learning Together Works
Creates natural accountability and deadlines
Helps people apply concepts to their own real work
Especially valuable for product leaders, who rarely have built-in peers to learn alongside
I’ve found small cohorts particularly effective for product leaders who need a safe space to pressure-test decisions, compare notes on org design, and align on product strategy trade-offs—without slipping into status updates. When leaders learn together, they build shared muscle memory that makes it easier to reinforce practices like continuous discovery and communities of practice across the organization.
Group/team: real work in the room, peer learning, bridges between leaders who rarely collaborate
Keep participants as close colleagues — trust and vulnerability go up when people already know each other
One-on-one coaching is invaluable for personal reflection and targeted growth. But when I need to accelerate collective behavior change—like improving discovery cadence, refining opportunity solution tree reviews, or aligning around outcome-based roadmapping—group coaching wins. Keeping participants as close colleagues increases vulnerability and candor, which in turn speeds up learning and leads to real changes in how teams plan, prioritize, and ship.
Key Takeaways
Start a book club — debriefing together beats reading alone
Train pilot teams before rolling out org-wide
Encourage duos or trios to take courses together
Match your learning format to your actual goal
Keep coaching groups tight for more honest, productive sessions
Here’s how I operationalize this: I start with a pilot team to validate the learning format and cadence, then expand to adjacent trios to build a network effect. We anchor learning to current initiatives (not abstract theory), ensure weekly touchpoints, and capture playbooks in our internal knowledge base so improvements persist beyond the cohort.
Resources & Links:
Follow Teresa Torres: https://ProductTalk.org
Follow Petra Wille: https://Petra-Wille.com
Mentioned in this episode:
Communities of Practice
Petra Wille's book Strong Product Communities – The Essential Guide to Product
Become a Better Product Leader: A 52-Week Transformation Journey – Petra's email course with quarterly live Q&A
Teresa Torres’ book Continuous Discovery Habits
Continuous Discovery Habits (CDH) Book Club
Petra’s STRONG Product People Corporate book clubs
I’m celebrating the five-year anniversary of Continuous Discovery Habits by inviting you to read it with me this June. As someone who leads product management and coaches product trios, I’ve seen how a shared discovery practice tightens alignment, speeds up learning, and drives outcomes. This month, we’ll go deep on prioritizing opportunities—not solutions—and I’ll guide you step by step so you can apply the ideas on your own team.
Each month, I’m releasing an in-depth reading guide that includes:
We’ll discuss each month’s reading in the comments, and we’ll gather quarterly on a live call to unpack real-world applications, trade wins and missteps, and keep the momentum going.
Joining late? No problem. I monitor the comments on each reading guide throughout the year. Start with the current month or go back to January—whatever works for you. Ask for help, share what’s working, and connect with other readers at any point.
If you want to participate, grab a copy of the book (or dust off your old copy), share the “Spread the Love” videos with your team, block time for the exercises, and register for the community sessions. Let’s do this.
This Month’s Reading
Chapter:
Estimated reading time: ~16 minutes
This month's chapter will introduce you to:
Need a copy? Grab the book
Share the Love with Friends and Colleagues
We learn best in community. Use these short videos to spread the key ideas across your product trios, engineering partners, and stakeholders. Invite them to read along with you so your discovery cadence—and your product strategy—advance together.
Reflect & Discuss What You Read
When we reflect and discuss what we read, we absorb more and apply it faster. This chapter challenges a deeply ingrained habit: prioritizing solutions. I’ve been in those meetings—spreadsheets full of features, heated roadmap debates, and a creeping sense that we’re optimizing outputs rather than outcomes. The shift to opportunity-first thinking changed how my teams frame bets, sequence discovery, and communicate product strategy.
Individual Reflection
Team Discussion
Put It Into Practice
This month is all about shifting from solution-first to opportunity-first thinking. These short, focused exercises will help your product trio practice opportunity prioritization and improve decision speed without sacrificing product discovery rigor.
Exercise: Map Your Roadmap to Opportunities
Time: 45 minutesDo this: With your product trio
Take your current roadmap or backlog and work backwards. For each planned feature or solution:
This exercise often reveals that you're either:
Use these insights to inform your next prioritization conversation.
Exercise: Practice Two-Way Door Thinking
Time: 30 minutesDo this: With your product trio
Choose 3-5 recent or upcoming product decisions. For each one, discuss:
The goal is to calibrate your team's decision-making speed. Two-way door decisions should be made quickly with "just enough" evidence. One-way door decisions deserve more deliberation and data.
Go Deeper: Additional Reading
If you prefer an audio summary of this month’s reading, including the book chapters and the following resources, I’ve included an audio version for members at the bottom of this post.
Related In-Depth Guides
Supplementary Reading
Related Courses
Our Live Discussion Schedule
Our live discussion sessions are for registered members. Sessions are not recorded. Invitations will go out two weeks before the scheduled event—reserve time now.
Audio Summary
Prefer to listen? Stream the audio overview here: June — Prioritizing Opportunities (audio).
Ready to put continuous discovery into action? Grab the book, share the videos with your team, schedule the exercises, and join the community sessions. Opportunity-first product strategy is a muscle we can build together.
The chapters we will be readingA preview of the most important concepts we'll be learning aboutShort videos you can share with friends and colleagues to help spread the ideasIndividual and team discussion questions to help you absorb and engage with the readingTeam exercises to help you put the ideas into practiceAdditional reading to help you go deeper on the core ideasChapter 7: Prioritizing Opportunities, Not SolutionsWhy product strategy happens in the opportunity space, not the solution spaceHow to focus on one target opportunity at a time to deliver value iterativelyUsing the tree structure to simplify prioritization decisionsThe four criteria for assessing opportunities: sizing, market factors, company factors, and customer factorsWhy treating prioritization as a messy, subjective decision leads to better outcomes than scoring formulasThe concept of two-way door decisions and how they apply to opportunity prioritizationWork on one small opportunity at a time – Reduce your batch sizeGetting started with compare and contrast decisions – Choose the right target opportunityTurn big intractable problems into smaller, more solvable problems – The power of decompositionThink about your team's current roadmap or backlog. How much of your time is spent prioritizing features versus understanding and prioritizing customer opportunities? What would change if you flipped that ratio?Reflect on the last time you made a product decision. Did you treat it as a one-way door (irreversible) or a two-way door (reversible)? How did that framing affect your decision-making process and timeline?Consider the four assessment criteria (opportunity sizing, market factors, company factors, customer factors). Which of these does your team currently emphasize most? Which do you tend to overlook or underweight?As a team, list the top 5-10 items on your current roadmap or backlog. For each one, try to identify the underlying customer opportunity it addresses. If you can't clearly articulate the opportunity, what does that tell you about how you're making decisions?The chapter argues against scoring formulas (like RICE or ICE) for prioritization, calling them "made-up math." If your team uses a scoring system, discuss: What is it really measuring? Does it help you make better decisions, or does it just make subjective decisions feel more objective?Walk through a recent prioritization decision. Did you assess options in isolation ("should we build this?") or compare and contrast them? How might your decision have been different with a compare-and-contrast approach?Identify the customer opportunity it's meant to addressWrite it as something a customer might say (e.g., "I can't find anything to watch" not "We need better search")Look for patterns: Are multiple solutions addressing the same opportunity? Are some solutions disconnected from any clear customer need?Spreading yourself thin across too many opportunitiesOver-investing in a single opportunity with multiple solutionsBuilding solutions with no clear opportunity attachedIs this a one-way door decision (hard to reverse) or a two-way door decision (easy to reverse)?If it's a two-way door, what's the smallest step we could take to learn whether we're on the right track?What would we need to see to know we made the wrong choice?If we realize we're wrong, how quickly could we course-correct?Opportunity Solution Trees: Visualize Your Discovery to Stay Aligned and Drive OutcomesCustomer Interviews: Uncover Hidden Insights from Every ConversationPrioritize Opportunities, Not Solutions7 Key Benefits of Using Opportunity Solution TreesProduct in Practice: How 2-Way Door Decisions Helped Simply Business Learn FastProduct in Practice: Getting Started with Opportunity Solution Trees at SuperAwesomeProduct Discovery Fundamentals: Learn a structured and sustainable approach to continuous discovery.Tuesday, June 16, 2026: 9am-10am PDTThursday, September 17, 2026: 9am-10am PDTWednesday, December 16, 2026: 9am-10am PST
Your discovery stack may already hold interview transcripts, support conversations, behavioral analytics, experiment results, and roadmap assumptions. Yet the decision in a product review can still depend on whoever read the most material or built the most persuasive deck.
If adding an LLM only gives you faster summaries, the workflow is not AI-native. An AI-native discovery workflow shortens the distance from evidence to a decision while making every important claim easier to inspect. AI retrieves, structures, compares, and challenges the evidence. You remain accountable for what the evidence means and what the product team does next.
Key takeaways
Begin every AI-assisted discovery run with an outcome, a metric, defined context, and a decision that someone needs to make.
Preserve raw evidence and give each observation a stable identifier before asking AI to synthesize it.
Break the workflow into bounded jobs such as retrieval, extraction, clustering, contradiction detection, and decision-brief drafting.
Evaluate citation accuracy, evidence fidelity, counterevidence, abstention, and access controls before the output enters a roadmap discussion.
Measure whether the workflow improves decision quality and product outcomes, not merely whether the model produces polished prose.
Frame the decision before you involve the model
Most weak discovery prompts fail before the model sees them. Analyze the interviews, summarize the feedback, and find insights are activities, not decisions. They give the model no principled way to distinguish useful evidence from interesting noise.
Outcome and metric: Name the user or business outcome, then define the behavior or measure that represents it. Activation, funnel conversion, and retention are not interchangeable. Include the event definition and observation window used by your analytics system.
Context and constraints: State the relevant cohort, product surface, timeframe, market, known exclusions, and data-access limits. New self-serve accounts on the web can exhibit a different pattern from established accounts or customers using another surface.
Decision and deliverable: Say what someone will do with the answer. Ask for a ranked opportunity brief, an interview plan, a set of competing explanations, or experiment candidates only when that format supports a real pending decision.
Reusable decision prompt: Help me decide [decision]. The outcome is [outcome], measured as [metric definition]. Limit the analysis to [cohort, surface, timeframe, and constraints]. Retrieve evidence from [approved repositories]. Return [deliverable]. For every material claim, include the evidence identifier, any conflicting evidence, the affected segment, and what is still unknown. If the available evidence cannot support a recommendation, say so and specify what is missing.
The last sentence matters. An AI system should be allowed to return insufficient evidence. If every run must end with a recommendation, the workflow rewards plausible completion instead of honest discovery.
Keep the outcome separate from the proposed solution. Improve activation is an outcome. Validate an onboarding checklist is already a solution choice. When you embed the solution in the prompt, AI tends to organize the available evidence around that choice instead of testing whether another opportunity matters more.
Use evidence-strength labels that a reviewer can verify rather than asking the model for an unsupported confidence percentage:
Sufficient: Direct evidence applies to the target context, and no material contradiction remains unresolved.
Mixed: Direct evidence and meaningful counterevidence both exist, or the pattern changes by segment.
Insufficient: Evidence is missing, indirect, stale for the decision, or outside the target context.
Build a traceable evidence pipeline, not a transcript pile
AI cannot make discovery evidence traceable if the underlying repository has already flattened observations, interpretations, and decisions into the same notes. Preserve those layers separately. My rule is simple: automate the movement and inspection of evidence before automating judgment.
Layer
What it contains
Control that matters
Raw evidence
Interview recordings or transcripts, support records, session evidence, and analytics query results
Keep the original record intact, access-controlled, and addressable by a stable locator
Evidence units
Atomic observations with metadata
Separate exact customer language, observed behavior, and analyst interpretation
Opportunities
Candidate needs, frictions, or desired outcomes
Attach supporting evidence, counterevidence, affected segments, and unresolved questions
Decisions
Choices made, rejected alternatives, assumptions, and rationale
Name the decision owner and preserve the evidence available at the time
Learning
Experiment results and later customer or behavioral evidence
Update the opportunity without erasing the earlier reasoning
Each evidence unit should carry enough metadata to survive outside its original document:
A stable evidence identifier.
The collection date and an exact locator such as a transcript timestamp or saved analytics query.
The relevant user segment, product surface, and journey stage.
The raw observation, kept separate from the interpretation proposed by a person or model.
The access, retention, and sensitivity classification.
The opportunity, assumption, or outcome to which the evidence may relate.
This structure prevents a common failure: a model paraphrases an interview, a later summary compresses that paraphrase, and the roadmap eventually treats the compressed interpretation as a customer fact. A reviewer should always be able to move from a claim to the evidence unit and then to the original record.
Apply data-governance rules before ingestion. If customer conversations contain personal, confidential, or contract-restricted information, do not copy them into an AI system until its access, retention, redaction, and model-training terms match your commitments. A more convenient synthesis workflow is not worth an unauthorized disclosure.
Retrieve the smallest useful context
Once the evidence corpus no longer fits sensibly into a prompt, use a retrieval-first pipeline with modular prompts and observable traces. Retrieval-augmented generation should select evidence relevant to the decision contract, rather than asking a general agent to reason over everything the company knows.
RAG is a grounding mechanism, not a truth guarantee. A fluent answer does not prove that the retriever found the decisive interview, the correct event definition, or the evidence that contradicts the dominant pattern. Configure retrieval to look for both support and contradiction, preserve evidence identifiers, respect access controls, and return no result when the available context does not meet the task.
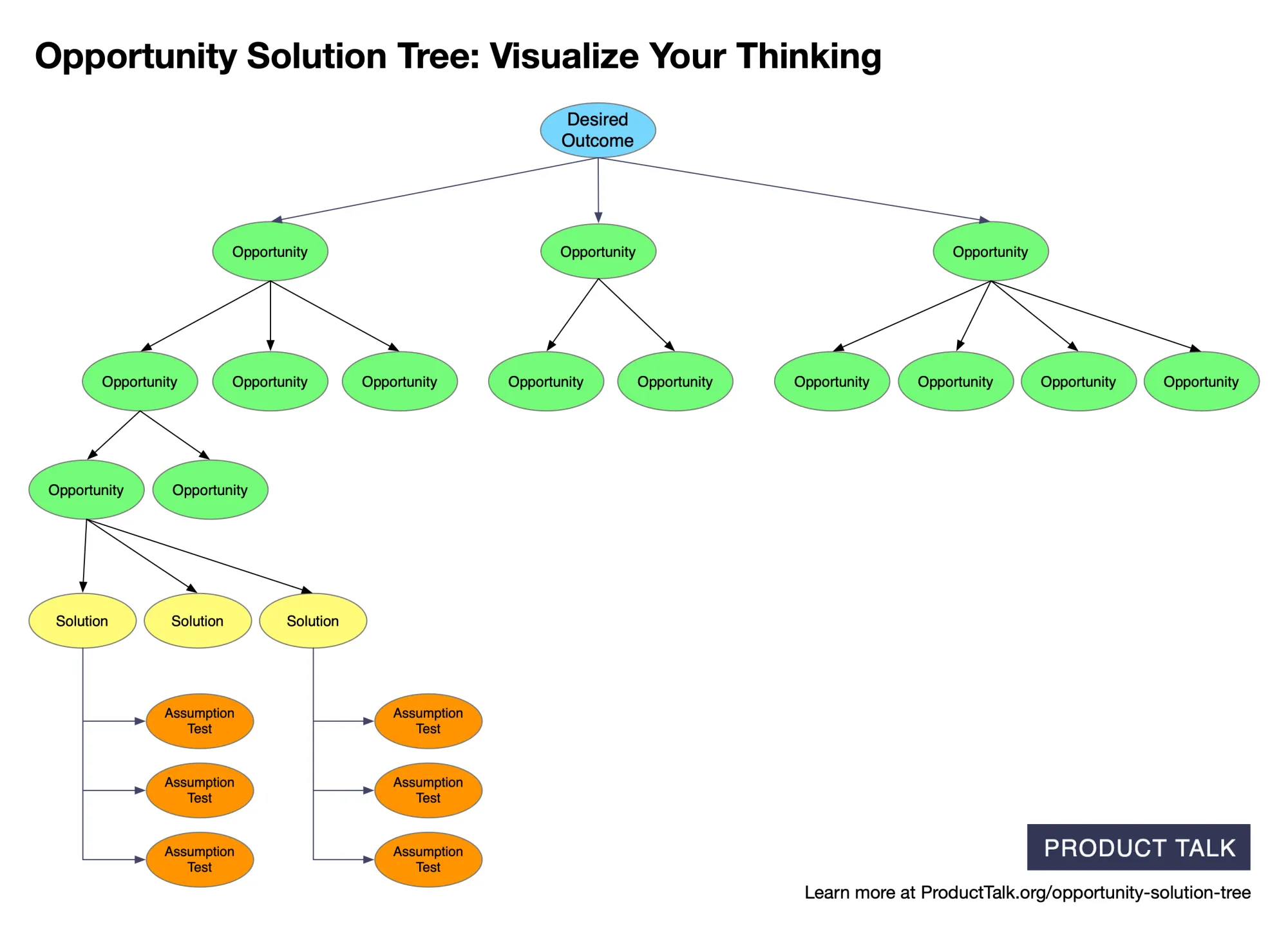
An opportunity solution tree can provide the shared view above this pipeline: the desired outcome connects to opportunities, solution candidates, and tests. Treat the tree as a navigable representation of current thinking. Every important node should still resolve to evidence and assumptions beneath it.
Give AI a chain of bounded jobs
A single agent asked to interview customers, interpret feedback, size opportunities, choose a solution, and write a roadmap has too many ways to hide a weak inference. Break the work into stages with explicit inputs and review gates:
Prepare: Give AI the outcome, assumptions, and learning gaps. Let it draft non-leading interview questions. A human checks whether the guide is testing an assumption or merely inviting agreement.
Convert: Extract atomic observations from approved records. Require exact locators and label customer language, observed behavior, and interpretation separately.
Synthesize: Cluster candidate opportunities without erasing segment differences. Request supporting evidence, counterevidence, and unrepresented cohorts for every cluster.
Connect: Use behavioral analytics to examine whether the observed pattern appears in the target cohort. Interviews can expose mechanisms and unmet needs; they should not be treated as a substitute for measuring prevalence.
Challenge: Ask for rival explanations, evidence that would reverse the conclusion, and assumptions that remain untested. This stage should consume the evidence record, not just the previous summary.
Draft: Produce a decision brief containing the pending decision, options, evidence, contradictions, unknowns, and proposed next test. A named human accepts, revises, or rejects it.
Learn: Attach experiment and outcome evidence to the same opportunity record. Preserve what the team believed before the test so later reviewers can inspect how the decision changed.
Pass structured artifacts between stages. If each stage receives only prose copied from the previous chat, unsupported claims can become progressively harder to distinguish from evidence.
Buy workflow plumbing; own the decision logic
You do not need to build every repository, connector, permission system, visualization, and observability screen. Licensing purpose-built opportunity-tree infrastructure can be the sensible choice when your differentiated work is the learning system rather than the canvas or collaboration layer.
Keep ownership of the parts that encode how your company makes product decisions: the decision contract, evidence schema, opportunity taxonomy, prompt modules, evaluation cases, escalation rules, and approval gates. Before choosing a platform, ask:
Can you export the raw evidence, metadata, opportunity structure, prompts, and run traces?
Can access rules follow the evidence through retrieval and generation?
Can the system connect to your approved analytics and customer-evidence repositories without repeated manual copying?
Can you evaluate a prompt or retrieval change against representative past cases?
Can a reviewer inspect why a claim appeared and what evidence was omitted?
Would building this capability improve the customer outcome, or merely recreate commodity workflow infrastructure?
Evaluate the workflow before it shapes the roadmap
Start evals before AI-generated conclusions become routine inputs to product reviews. The evaluation set should represent the cases the workflow will actually encounter: a clear pattern, conflicting evidence, insufficient evidence, cohort-specific behavior, stale material, duplicated records, and content the requesting user is not allowed to retrieve.
For synthesis and decision-support tasks, evaluate behavior that a reviewer can observe:
Citation validity: Every material claim points to a real, accessible evidence identifier.
Evidence fidelity: Quotations and behavioral facts remain faithful to the underlying record; interpretations are labeled as interpretations.
Retrieval coverage: The output includes the evidence required to assess the target opportunity, not merely the easiest matching passages.
Contradiction handling: Material counterevidence and segment differences are visible rather than buried.
Abstention: The system returns insufficient evidence when the decision cannot be supported.
Decision fit: The deliverable answers the stated decision instead of drifting into a generic summary or unrelated recommendation.
A strict release gate is useful here. Fail the output if it invents an evidence identifier, turns an interpretation into a quotation, ignores a material contradiction, or exposes restricted content. Those are not cosmetic defects that a polished paragraph can offset.
Treat the prompt, retrieval configuration, model choice, taxonomy, and evaluation set as versioned artifacts. This is the practical value of eval-driven development and early observability: when behavior changes, you can identify the change that caused it and rerun representative cases before wider use.
For each production run, retain the decision contract, evidence identifiers retrieved, prompt and retrieval versions, generated output, reviewer edits, final decision, and later outcome. That trace lets you distinguish a retrieval failure from a synthesis failure, a weak decision contract, or a reasonable decision invalidated by new evidence.
Model-quality checks are only one layer. Also baseline and monitor the discovery workflow itself:
Time from a framed question to a reviewable decision brief.
The share of material claims with inspectable evidence.
Reviewer corrections to quotations, segments, event definitions, and interpretations.
Decisions reopened because relevant evidence was missing or misread.
Movement in the outcome and metric named in the original decision contract.
Do not set improvement targets until you have a baseline for the existing process. A system can make synthesis faster while increasing correction work or encouraging premature decisions. The end-to-end measure tells you whether the saved time is real.
Turn the workflow into a product operating system
AI-native discovery changes the product team’s operating model only when ownership remains explicit. The product manager or product trio owns the outcome, assumptions, and decision. Research and design judgment protects interview quality and interpretive nuance. Data and engineering ownership protects event definitions, retrieval reliability, instrumentation, and access controls. AI produces candidate artifacts. The decision owner approves the action.
Review by exception instead of rereading every generated sentence. Inspect claims marked mixed or insufficient, new opportunity clusters, segment differences, material contradictions, changed event definitions, and outputs that differ from earlier runs. This focuses human attention where judgment is most valuable without treating the model as an authority.
Roll out the workflow through one recurring, reversible discovery decision:
Choose a decision for which customer evidence and behavioral data already exist, such as prioritizing an onboarding friction or investigating a repeated support issue.
Baseline the current path from question to decision, including reviewer corrections and missing-evidence failures.
Create the decision contract, evidence schema, and access rules before connecting an agent.
Build the evaluation set from previous clear, contradictory, insufficient, segment-specific, and restricted cases.
Run the AI workflow in shadow mode beside the existing process. Compare claims, omissions, reviewer effort, and the resulting decision without allowing the generated output to act automatically.
Promote bounded jobs only after they pass their gates. Evidence extraction may be ready before opportunity ranking, and opportunity ranking may be ready before solution recommendations.
Expand to another workflow only when the traces are stable, reviewers understand escalation paths, and the first use case is improving the decision process rather than merely generating more material.
At your next discovery review, do not ask what AI found. Bring one decision contract, require every consequential claim to resolve to evidence, and make the unresolved assumption visible. That is a small enough change to start immediately and a strong enough foundation for everything you automate later.
I’m excited to share two opportunities this season to uplevel your craft, connect with peers, and leave with practical, repeatable techniques you can apply immediately to your product work.
We will be doing another round of Claude Code: Show and Tell on May 26th at 9am PDT. These community-driven sessions are hands-on and fast-paced—we swap proven workflows, compare prompts, and pressure-test approaches together. You’ll see how product teams are operationalizing AI workflows in real contexts and walk away with ideas you can adapt for your own roadmap and experimentation pipeline. Invites will go out to Supporting Members and CDH Members tomorrow. If you'd like to join us, keep an eye on your inbox for the invite.
I love these Show & Tell sessions because they translate tacit knowledge into clear, reusable playbooks. Whether you’re refining evaluation loops for LLMs, streamlining discovery synthesis, or standardizing prompts for consistency, the shared rigor and camaraderie make it a high-signal hour for any product leader invested in AI workflows.
I also want to share that I'll be teaching our June 4th – July 9th cohort of Product Discovery Fundamentals. This is the last time I'll be teaching this cohort in its current format. If you've been thinking of enrolling in this program, and want to take it with me, this is your last chance. Register here.
Across this cohort, we’ll practice continuous discovery habits—framing opportunities, tightening assumptions, running lean experiments, and aligning product trios on evidence-backed decisions. If you want a rigorous, repeatable system for turning customer insight into confident prioritization and compelling product strategy, I’d be thrilled to have you in the room.
When I consider where product development is headed, one statement captures the mandate perfectly: "Eric Carlson is a Principal AI Engineer helping to shape and build Amplitude's next generation vision of of agentic and data driven product development." That vision resonates deeply with how I lead teams—anchoring strategy in behavioral analytics while enabling agentic AI to act on insights with speed, safety, and measurable impact.
Translating that vision into execution starts with clarity of outcomes. I frame driver trees that connect customer value to leading indicators—activation, engagement depth, and retention—then instrument product telemetry with Amplitude analytics and behavioral analytics to surface the moments that matter. From there, we operationalize learning with A/B testing and feature flags, ensuring each hypothesis gets a fair, observable run and that we can safely ramp what works.
Agentic AI changes the operating model. Instead of static dashboards, we design autonomous workflows that observe signals, reason over context, and take action—grounded in a retrieval-first pipeline and governed by eval-driven development. For product managers, this demands fluency with LLMs for product managers and practical prompt engineering, plus rigorous AI Strategy around data governance, privacy-by-design, and risk scoring so agents remain trustworthy under real-world conditions.
Cross-functional cadence is everything. I partner closely with Principal AI Engineers and product trios to blend continuous discovery with execution: rapid user interviews to reveal intent, opportunity solution trees to prioritize, and outcomes vs output OKRs to align incentives. The result is a system where insights are unified, decisions are explainable, and agents improve through tight feedback loops across analytics, experimentation, and production telemetry.
If you’re building toward an agentic, data-driven future, invest in a unified analytics platform, shorten the path from signal to action, and measure learning velocity as carefully as feature delivery. With the right foundations, agentic AI becomes more than a feature—it becomes a force multiplier for product strategy, customer value, and sustainable growth.
Inspired by this post on Amplitude – Perspectives.
I just wrapped an all-out engineering sprint. That still sounds odd coming from me, because while I’ve written code on and off for years, I don’t self-identify as an engineer. I’m a product manager who used to be a designer. It’s been a long time since I wrote code for a living.
But AI has expanded what’s just now possible—for our products, and for us. It’s pushed me to do more than I imagined. In that spirit, I want to share a recent engineering story. It includes technical details, and a year ago I couldn’t have done any of it. I learned it with the help of AI, and my aim is to show what’s now within reach.
I’ve been building two services with a partner at Vistaly: AI-generated interview snapshots and AI-generated opportunity solution trees. We put out a call for alpha partners, received over 100 applicants, and selected eight design partners to start.
A clear, color‑coded map from desired outcome to opportunities, solutions, and assumption tests—showing how to structure discovery work and prompt AI to generate, compare, and validate product ideas.
Each team uploaded three customer interviews. I identified the key moments and opportunities and then generated an opportunity solution tree from those snapshots. I provide the AI services; Vistaly is building the UI and workflows around them.
Early feedback was strong. Teams immediately asked to upload more interviews—exactly the kind of demand signal you hope to see—so we got to work making that possible.
Go behind the scenes as AI turns raw feedback into a clear Opportunity Solution Tree. Linked cards reveal user needs—onboarding, support offload, and bot-readiness signals—so product teams can spot priorities and next steps at a glance.
Updating an opportunity solution tree with new interview content is far harder than generating a new tree from scratch. I initially underestimated the complexity. Our goal wasn’t to produce a tree and declare it truth. We wanted teams to engage, correct, and collaborate with the AI—scaffolding cross-interview synthesis instead of doing it for them.
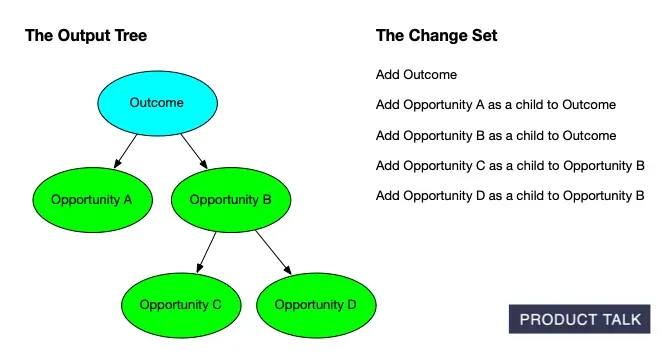
To support that, we needed a way to communicate precisely how a tree would change after new interviews were added. We took inspiration from git diff and set out to build the equivalent for opportunity solution trees—step-by-step change sets that explain each proposed modification.
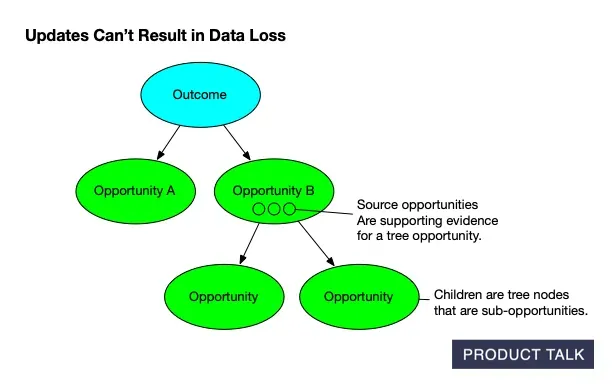
A clear visual of AI‑generated opportunity solution trees: outcomes feed opportunities that branch into sub‑opportunities, while evidence is preserved. The structure ensures updates stay traceable and never cause data loss.
That decision was right, but the lift was larger than I expected. It wasn’t enough to generate an updated tree; I also had to provide a clear, ordered walkthrough of what changed and why.
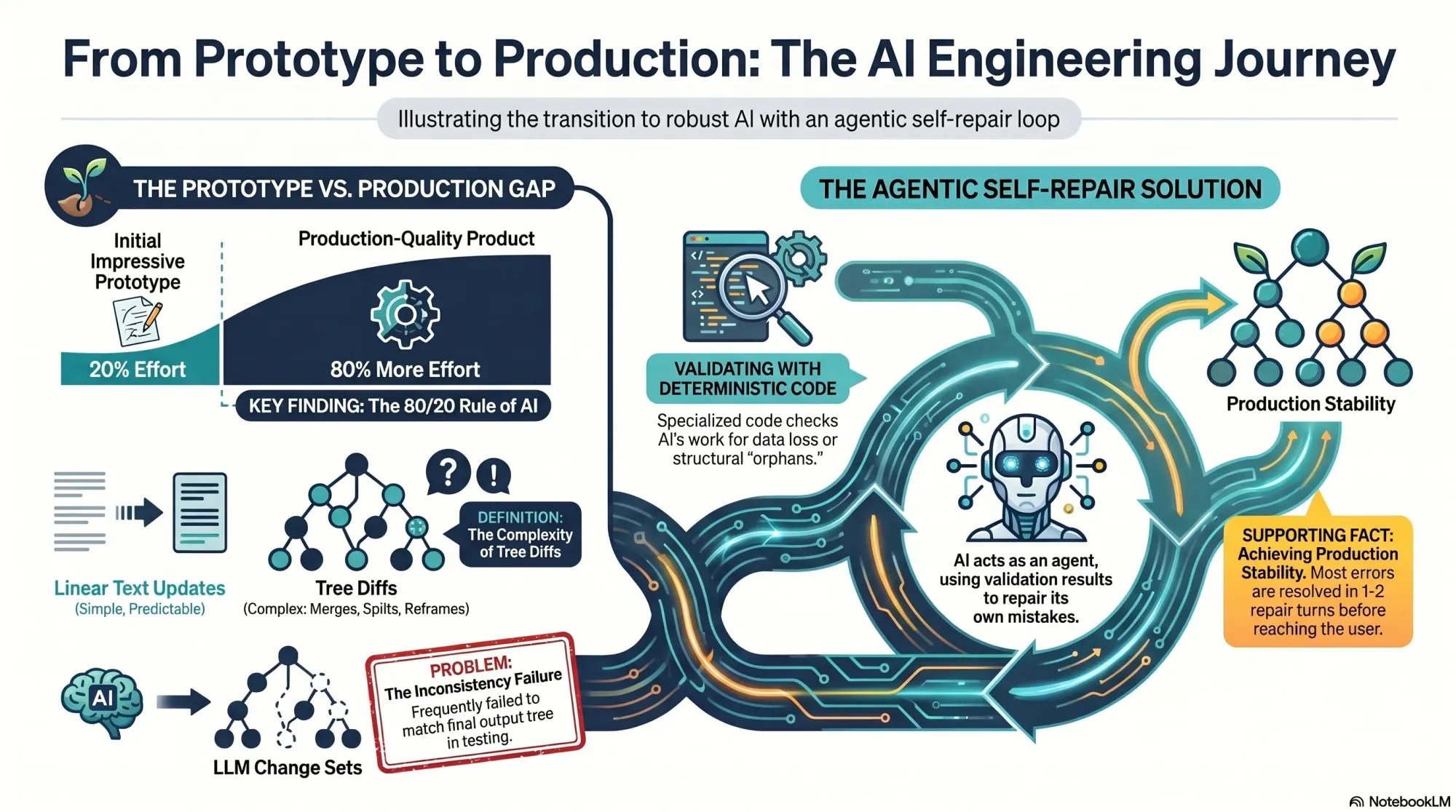
I often see the same pattern with AI: it’s easy to get to an impressive prototype, but much harder to reach a production-grade product. That was exactly my experience here. My service actually comprised two sub-services: generating a new tree from scratch and updating an existing tree with new interviews. The first worked well in alpha; the second had to be built before anyone could add a fourth interview.
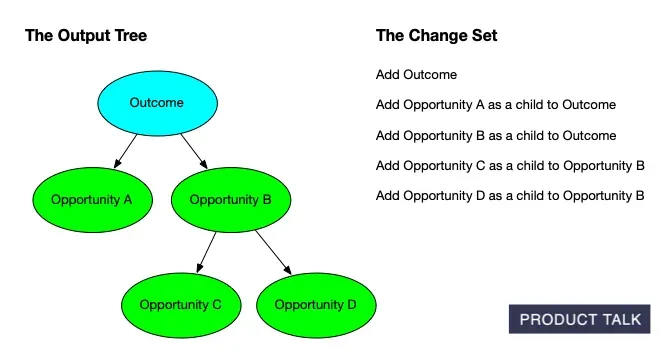
Explore how an outcome expands into an Opportunity Solution Tree: Opportunities A and B stem from the goal, with C and D nested under B, while a concise change set tracks every node added along the way.
On the surface, these services look similar. In reality, updates must preserve existing structure unless new evidence requires a change. You have to account for compound operations—merges, splits, deletes—while guaranteeing no data loss. Every node has source opportunities (supporting evidence from interviews) and children (tree sub-opportunities), and neither can be dropped.
In classic AI fashion, I got a reasonable version working in a few days and shipped it to our design partners. One team quickly hit our beta limits and asked to convert to a paid subscription so they could keep going. They showed a willingness to pay, converted, and started uploading aggressively.
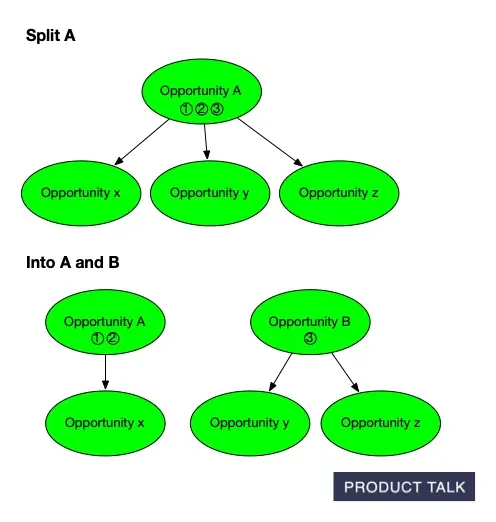
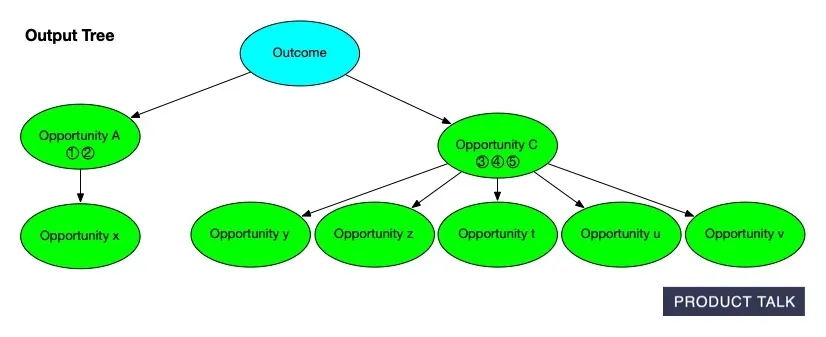
Watch an Opportunity Solution Tree evolve: the original parent A with x, y, z branches is split into A and B, shifting evidence while preserving links—mirroring how AI refines scope and structure in discovery.
At the 14th, 15th, and 16th uploads, the cracks appeared. We saw odd behavior in some trees. The Vistaly team noticed that the change sets—the step-by-step instructions emitted by my service—didn’t always reconstruct the final tree my service also emitted. We needed those steps to match exactly, so teams could review and accept, modify, or reject each change with confidence.
They flagged the issue the day I was flying to New Orleans for Jazz Fest. In hindsight, I’m glad I didn’t grasp the scope of what awaited me. I had roughly 80% of the work still to do to make tree updates rock solid. At least I got to enjoy the music first.
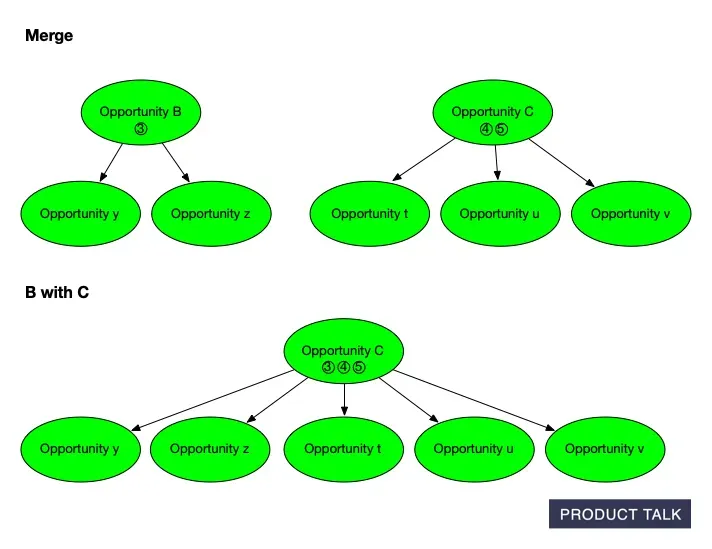
From fragments to focus: this diagram shows how Opportunities B and C are merged into a single Opportunity Solution Tree, removing duplicates and unifying context so AI can rank and explore five related opportunities with clarity.
Back home, I started diagnosing. My service was a pipeline: several LLM-driven steps followed by deterministic code to compare trees and produce change sets. As I dug in, I realized that approach was flawed. Tree diffs, unlike linear document diffs, are ambiguous.
In a document, if I add a sentence, the diff shows an addition. If I delete a paragraph and rewrite it, the diff shows a removal and an addition. Simple. But trees are different. Suppose I split opportunity A into A and B, and later merge B with C. The split can disappear from the final diff.
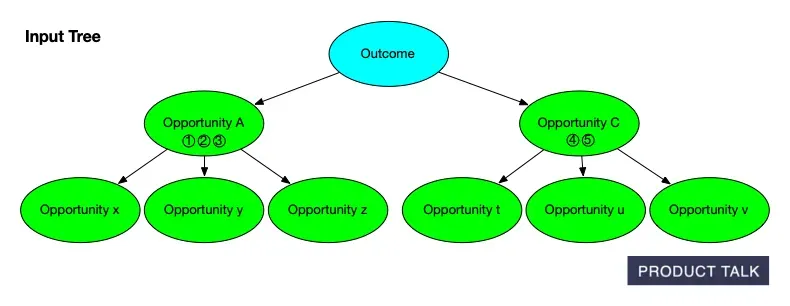
Peek inside our process: a simple opportunity solution tree maps an outcome to prioritized opportunities A and C with downstream options x-z and t-v. A clear snapshot of how AI organizes product discovery.
When the model splits an opportunity, it must distribute A’s source opportunities and children between A and B. For instance, if A has source opportunities 1, 2, 3 and children x, y, z, after the split A might keep 1, 2, and x, while B takes 3, y, and z.
Now suppose the model merges B into C. If C originally had source opportunities 4 and 5 and children t, u, v, then after the merge C now has source opportunities 3, 4, 5 and children t, u, v, y, z. When you compare the original and final trees, it looks like A somehow donated some evidence and children directly to C. The split and merge that explain why are invisible to a naive diff.
See how an AI-generated Opportunity Solution Tree unfolds: one Outcome flows to Opportunities A and C, then into options x–v. Clean colors and arrows reveal the hierarchy from goal to opportunities at a glance.
That was the core insight: we didn’t just need to show what changed—we needed to show why it changed. I had to reconstruct each move step-by-step. That meant getting the model to show its work, which opened a new can of worms.
I refactored my prompts so the model produced both the final output and the exact change set it used to get there. The action language was explicit: add, delete, reframe, merge, split, and so on. Crucially, I asked the model to describe its moves in user-meaningful terms—“split A into A and B, then merge B into C”—not as opaque reassignments of sources and children.
Watch an opportunity solution tree take shape: start with the outcome, add opportunities A and B, then extend B to C and D. The paired change set makes every edit transparent—ideal for AI-assisted product discovery.
For each LLM step, the model now emitted its recommendation and the corresponding change set. This helped, but it wasn’t perfect. After extensive testing and error analysis, two classes of errors emerged: (1) the model attempted an invalid move, and (2) the change set didn’t actually generate the recommendation.
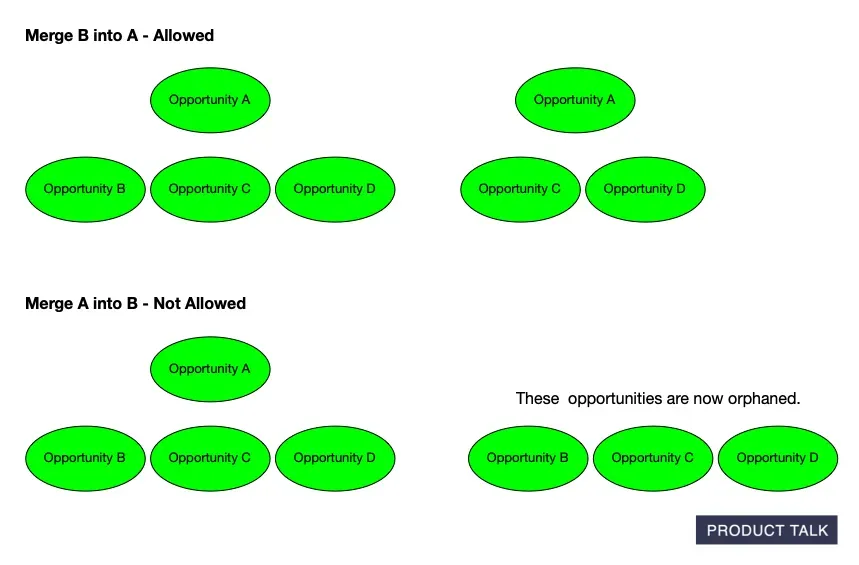
Category 1 felt like designing a game while the model played it creatively. For example, what happens when the model tries to merge a parent with a child? If opportunity A has children B, C, and D and the model merges A with B, the merge is directional. If the instruction is “keep A, delete B,” that works—the parent absorbs the child. But if the instruction is “keep B, delete A,” then C and D become orphans. These puzzles were solvable and even fun.
Visual explainer from Product Talk on AI-generated Opportunity Solution Trees. It contrasts an allowed merge (B into A) with a not-allowed merge (A into B) that leaves child opportunities orphaned, guiding safe hierarchy edits.
Category 2 was harder. Despite prompt iterations, I could only push the discrepancy rate down to about 1 in 40 instances. With 10–20 LLM calls per run, that meant roughly half of all runs still failed. Not acceptable for production. I hit a wall. A paying customer was waiting, and more design partners were queued up.
Next, I tried to correct the model’s mistakes with deterministic code. I had promised that my change sets would generate the output tree, so I wrote verifiers: detect conflicts (e.g., delete a node, then try to use it later), guard against data loss, prevent orphaned nodes, and more. Detection was straightforward; correction was not. Fixing issues required guessing the model’s intent. If the sequence said “delete A, then merge A with B,” should I remove A entirely or salvage A’s sources and children by merging into B? There were dozens of such cases with no unambiguous answer.
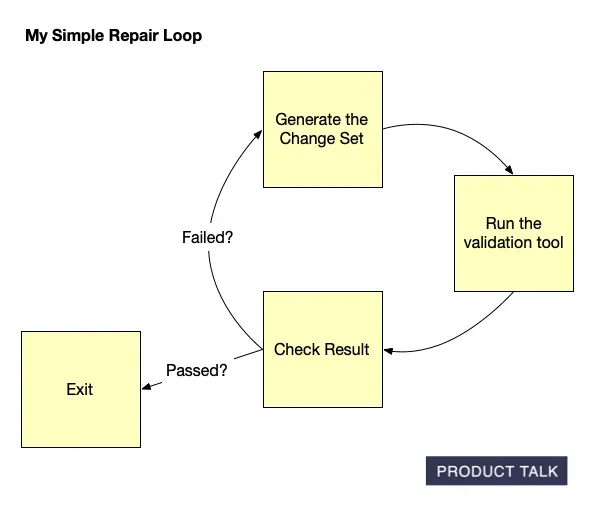
A step-by-step loop shows how changes are validated: generate a change set, run a validation tool, review the result, then repeat on failure and exit on pass—mirroring iterative work behind AI-built Opportunity Solution Trees.
After 11 straight days of deep work—including weekends—I was exhausted. I dislike hustle culture; this isn’t how I design my life. But I was stuck, and then I had an insight.
On a walk with my husband (also an engineer), I realized I could have the LLM repair its own mistakes. My data contract with Vistaly requires that the change set must generate the output tree. I had already built robust validation code. I knew exactly when a change set failed—and why. No amount of prompt tuning alone was fixing it. So I turned the validator into a tool for the model and created a simple agentic loop.
The loop works like this: the model proposes a change set, calls the validation tool, and gets back a pass/fail plus specific feedback. If it fails, the model uses those instructions to repair the change set and calls the tool again. Iterate until success or a max number of turns.
I prototyped in Node.js with a single model call, a verifier pass, and a repair attempt. At first, the loop didn’t converge—it just accumulated compute. I experimented with how to communicate errors, how much context to include, and how to sequence feedback. Eventually, it clicked: the model began fixing its own mistakes and typically returned a valid change set in one or two repairs. It was, in practice, eval-driven development applied to LLM outputs.
I had already built an agent loop utility for another AI workflow, so I productionized quickly: model call, optional tool invocation, tool result returned to the model, repeat until the validator signals success or the loop times out. I integrated the new loop into the pipeline and shipped the revamped service to Vistaly on Monday at noon. They’re integrating now, and it will be in the hands of our design partners shortly. I’m relieved—and ready for a day off.
Reflecting on the last two weeks, a few things stand out. First, I shed limiting beliefs about being an engineer. To make this reliable, I had to solve legitimately hard problems, and that feels good.
Second, this was genuinely fun. Designing the action set and watching the model push those boundaries was like working through elegant puzzles. Models are incredibly creative, and harnessing that creativity with the right constraints is deeply satisfying.
Third, I learned when I can and can’t trust Claude to write code for me. Since Opus 4.6 came out, I gave Claude a much longer leash. After the past two weeks, Claude is back on a short leash. I found a lot of gaps in my implementation in areas where I simply trusted that Claude got it right, when in fact it didn’t. If you don’t have the right infrastructure—planning, testing, code review—this can be disastrous. I’ll be investing more here and sharing what I learn.
Finally, if this work had been spread over two months, it would have been thoroughly enjoyable. I’m discovering how much I like being an AI engineer. It feels like a new chapter where I can combine opportunity solution trees with modern AI engineering—and deliver real value to product teams doing continuous discovery.
I’m excited to share more of what we’re building with Vistaly and to onboard more design partners soon. If you’re interested, get on the waiting list. And if you’ve been hesitant to stretch beyond your current skill set, I hope this story nudges you to take the first small step toward what’s just now possible.