Old-school, in-person selling is having a renaissance in the AI era, and I’ve seen why up close. From leading product and go-to-market teams through hypergrowth, I keep returning to one lesson: enterprise buyers still reward the teams who show up, orchestrate change management, and own outcomes end-to-end. The tech has changed; the human dynamics haven’t.
Has the sales playbook changed in the AI era? The tools are faster and the surface area is bigger, but the core motion remains the same: “showing up” beats letting the marketplace decide. That’s why in-person enterprise rollouts still beat product-led motions, especially when the stakes include security, governance, and cross-functional adoption. You win by reducing organizational risk, not by assuming free trials will do the heavy lifting.
Great enterprise sellers collapse silos. They sell to engineers and executives in one motion, pairing deeply technical validation with crisp business narratives. In my org, that means every high-velocity pilot has a dual thread: hands-on, eval-driven proof for the builders and a value architecture for the budget owners. When those motions run in parallel, time-to-value plummets and procurement friction fades.
Selling to AI-native buyers who grew up on ChatGPT changes tempo, not fundamentals. The same seller, different tempo: 8 weeks vs. 8 business days. These buyers evaluate fast, expect clear ROI, and push for automation-first workflows. How AI-native buyers handle build vs. buy decisions comes down to build for differentiation and buy for acceleration. If you make procurement feel like product—frictionless, instrumented, and transparent—you’ll meet their bar.
Process matters, but humanity wins. Building a robust sales process that still leaves room for unscripted moments is where trust is formed. I’ll never forget the story of the rep who taught a champion’s son guitar over Zoom—an unscripted moment that cemented a partnership. The lesson: raise the floor without capping the ceiling. Equip every rep with repeatable plays, then celebrate the creative instincts that make champions out of customers.
In early GTM, why the three highest-leverage early sales hires aren’t sellers at all resonates with my experience. I prioritize a solutions engineer who can de-risk integration, a forward-deployed operator who can run the first rollout like a product manager, and a customer success lead who designs adoption paths from day zero. Together, they compress the value journey from proof to production.
Compensation design shapes your talent market. The case for outsized commission accelerators for star sellers — and the kind of person they attract is real: magnets for competitors who close complex, multi-threaded deals and thrive with ownership. But beware: why too much process narrows the kind of seller you attract. Over-script it and you filter out the very people who can navigate ambiguity with customers.
Under the hood, instrumenting the funnel from stage zero to close keeps the system honest. I track intent signals before pipeline, conversion by persona and use case, proof milestones, and time-to-value in production. The three pillars of GTM excellence for me are repeatable discovery, referenceable outcomes, and relentless enablement. And inside the leadership team, building peers who are 80% aligned, not 100% preserves healthy tension while keeping execution fast.
AI is expanding the definition of enablement—whether AI is changing what good enablement looks like isn’t a theoretical question anymore. I see world-class teams arming reps with retrieval-first knowledge bases, sandbox environments, and objection libraries that evolve weekly. Meanwhile, selling against direct and implied competitors at once is the norm: your battlecard must cover “do nothing,” internal tools, adjacent categories, and new AI entrants—while you still remember why in-person enterprise rollouts still beat product-led motions for durable adoption.
Planning horizons tighten in AI markets. How far out should a GTM leader be planning? I work a dual cadence: a rolling 6-week operating plan that’s ruthlessly tactical and a 2–3 quarter roadmap for coverage, enablement, and category storytelling. What a normal week looks like in hypergrowth blends customer time, pipeline triage, onboarding and enablement, deal engineering, and process tuning—always with one or two high-conviction bets that could bend the curve.
If you’re scaling an AI product today, pair a disciplined sales-led growth engine with the best of product-led growth: fast paths to proof, hands-on validation for builders, executive-level value mapping, and human moments that turn customers into advocates. That’s how you compress an eight-week cycle into five business days—and keep the expansion flywheel spinning.
I recently spent time with the debate behind the "product builder" trend—asking whether it’s the future of product management or just another wave of tech FOMO. The conversation featuring Teresa Torres and Petra Wille is a useful prompt, but what matters most is how we translate these ideas into healthy product practices inside our own organizations.
Here’s my take: the product builder movement is neither a mandate nor a fad—it’s a tool. The right question isn’t "should product managers code?" but whether leaning into building advances outcomes for our customers and our teams. In practice, that means letting interest and skill—not pressure—set the pace.
Petra captured it perfectly: "Just because I can do it — is it something I enjoy doing? And do I have enough experience to really get into the flow?" Those two tests—joy and depth—are underrated filters. I’ve seen PMs light up when prototyping or vibe coding a thin slice, and I’ve also seen well-meaning dabbling create hidden complexity that slows everyone down later.
Org design determines whether this works. It’s not about the tools—it’s about clarity of roles, healthy interfaces between product, design, and engineering, and explicit guardrails for where experiments stop and production begins. AI has raised the stakes: "AI can make unskilled work look polished. That’s a feature and a bug — executives see the shine, engineers inherit the mess." If you’ve ever watched a glossy demo turn into weeks of refactors, you know exactly what this looks like.
To avoid that trap, I deliberately separate the three layers where AI is changing product work: personal productivity, team process, and product strategy. Treating these as different stacks keeps expectations clean: a prompt that accelerates personal workflows isn’t the same as an AI-enhanced process that reshapes delivery, and neither automatically produces durable product advantage. Don’t conflate them.
Discovery remains stubbornly human. "Why discovery still requires talking to your customers (sorry)" is more than a friendly nudge. AI can broaden our search space and sharpen analysis, but it doesn’t replace qualitative conversations or the judgment that comes from pattern recognition across real customer contexts. Continuous discovery and disciplined customer interviews are still the most reliable compasses we have.
Where does "vibe coding" fit? It’s great for roughing out concepts, de-risking slices, and communicating intent when words or static mocks won’t cut it. Tools like Claude Code make this faster than ever, and familiar stacks like Ruby on Rails lower the bar for spinning up functional prototypes. But remember the design system trap: AI can make bad decisions look good on the surface. If you don’t control for architecture, accessibility, data contracts, and handoff quality, your team pays the integration tax later.
In well-set-up orgs, the output-oriented muscle memory gets rewired. When AI frees up time, strong teams reinvest it into better problem framing, sharper opportunity solution trees, and tighter product strategy—rather than simply chasing more output. That’s a leadership challenge, not a tooling problem, and it shows up quickly in how teams make trade-offs.
Here’s how I operationalize this with empowered product teams: we articulate clear boundaries for prototypes versus shippable code, define decision rights for when PMs or designers "build," and align on review gates that protect quality without stifling speed. We also make the three AI layers explicit in roadmapping and retros, so improvements to personal workflows don’t get mistaken for strategic advantage.
My distilled guidance echoes the episode’s throughline. The product builder trend isn’t a mandate — it’s a tool. Let enjoyment and skill guide who on your team leans into it. Organizational readiness determines whether AI empowers your team or creates chaos. Don’t conflate personal efficiency, process change, and product impact—they require different responses. Discovery fundamentals haven’t changed; AI helps you go deeper, not skip the work. And the real takeaway on product builders: not everyone has to build, but everyone can if they want to.
If you want to hear the full discussion that sparked these reflections, listen on Spotify or Apple Podcasts. Then tell me: where will you apply builder energy in your team—and where will you deliberately say no?
Resources & Links: Follow Teresa Torres: https://ProductTalk.org. Follow Petra Wille: https://Petra-Wille.com. Mentioned in this episode: Claude Code, Vibe coding, Ruby on Rails.
One more quote I loved because it centers autonomy and craft: "It’s a tool in our toolbox. We can decide who on our team has fun with it, wants to do it, wants to contribute." That’s the mindset that sustains both momentum and morale.
Inbound leads shouldn’t wait for a rep’s calendar. When we first launched The Service Agent Blueprint, support leaders finally had a clear AI path. Go-to-market and revenue teams are now facing similar uncertainty, so I’m introducing The Sales Agent Blueprint—a practical map for launching and scaling AI for sales with confidence.
For most sales teams, inbound motions require a lot of manual work. I’ve watched leads pile up in queues, waiting for availability rather than being prioritized by buyer intent. That delay costs meetings, pipeline, and momentum—and it’s exactly where a modern AI Strategy can transform your go-to-market strategy.
Agents can run sales conversations end to end – engaging buyers, qualifying leads, and routing high-intent opportunities to the right team to move prospective buyers forward quickly. Humans will still be involved, but will move their focus to the consultative conversations and higher-value work they did not have time to focus on before. In practice, this shift enables cleaner AI workflows, better conversation design, and a healthier balance between sales-led growth and product-led growth.
The questions many go-to-market and revenue leaders are facing now are where do you start? What should success look like? How do you actually test and deploy these solutions? These are the right questions—and the ones I hear most often when teams weigh build vs buy decisions, evaluation frameworks, and CRM integration nuances.
The Sales Agent Blueprint answers those questions. It’s designed to be a strategic guide for sales, revenue, and AI transformation leaders who want to deploy AI for inbound sales fast, prove value, and build momentum. If you’re aiming for eval-driven development, this will help you define success up front and operationalize it.
What’s inside is simple by design yet deep enough to take you from zero to value. The Sales Agent Blueprint is structured around two tracks that reflect how high-performing teams adopt agentic AI: first, launch for quick wins; next, scale for durable growth.
Coming soon: Sales Agent Blueprint. A sleek, blueprint-inspired teaser with the call to 'Scale it' signals tools, playbooks, and workflows to grow revenue, streamline operations, and scale teams with confidence.
Today, I’m releasing the first part of the Blueprint: “Launch it.” It’s a practical guide for getting your Agent live and seeing real results. You’ll learn how to deploy a Sales Agent that runs inbound sales conversations end to end, engaging buyers, qualifying leads, and routing high-intent opportunities to the right outcome in real time—without disrupting your current CRM integration or pipeline processes.
By the end of the “Launch it” track, you’ll be ready to execute with clarity. Here’s how I frame the essential steps, based on what consistently works in the field.
Understand what a Sales Agent is: Discover why they’re different from chatbots and how they work. Build a business case: Prove the basic economics of AI, decide whether to buy or build, and get the buy-in and budget you need to move forward.
Evaluate an Agent: Learn how to define success, choose the right evaluation criteria, and run a focused, high-impact assessment with our five-step framework.
Deploy with confidence: Build a deployment plan that gets your Agent live quickly to engage buyers at peak intent. Learn what to expect at each stage.
Introducing the Sales Agent Blueprint. This crisp, grid-based graphic spotlights step 1—Launch it—signaling day-one activation for an AI sales agent. Explore the framework and get started at fin.ai/blueprint/sales.
Continuously improve performance: After launch, your Agent becomes a system to manage. We’ll show you how to implement a repeatable process to train, test, deploy, and optimize.
The second track, “Scale it” (coming soon), focuses on the organizational and systems design work that unlocks compounding gains. Launching AI is only the beginning. To unlock its full potential, you need to rewire your inbound sales motion—redesigning the buyer journey, building AI-first systems and ownership models, and rethinking how pipeline is generated and scaled. This is where governance, measurement, and team roles evolve to support sustainable growth.
I’ll be building this Blueprint in public as I navigate the same challenges—sharing what works, what to avoid, and how to accelerate time-to-value without sacrificing quality or trust. If you’re ready to turn intent into revenue with agentic AI, this is your head start.
The Sales Agent Blueprint is live now. Explore the full guide at fin.ai/blueprint/sales and start your “Launch it” sprint today.
You need a churn score soon. Customer success wants a prioritized account list, engineering wants requirements, and finance wants to know whether it is funding a vendor contract or a permanent internal capability. A polished model can still leave all three teams waiting if nobody has decided what happens after an account is flagged.
Start with the retention decision, not the algorithm. Once you know who will act, what they will do, and how you will measure the result, the build-versus-buy choice becomes much clearer.
Decide which capability you actually need to own
Churn prediction is often discussed as if it were a single model. In practice, it is an operating loop with several layers:
Define the outcome. Specify which customers can churn, what event counts as churn, and the prediction window that gives your team enough time to intervene.
Assemble the signals. Connect product usage, account attributes, engagement, support, billing, and other permitted data to a consistent customer identity.
Estimate risk. Produce a score, category, or ranking that separates accounts requiring attention from the rest of the portfolio.
Activate the prediction. Route the result into the CRM, customer-success workflow, lifecycle message, or in-product experience where somebody can respond.
Learn from the intervention. Measure whether the action changed retention, adoption, engagement, or Net Recurring Revenue rather than assuming that a plausible score created value.
You do not necessarily need to own every layer. A vendor might provide behavioral analytics, scoring, in-app guides, and CRM integration while you retain ownership of the churn definition, intervention policy, and experiment design. Conversely, you might build a specialized risk model but continue using commercial tools to collect events and deliver treatments.
My default is to separate model ownership from outcome ownership. Your company must own the definition of success, the permitted uses of the score, and the learning loop. It only needs to own the model code when that ownership creates a strategic advantage.
Before evaluating an architecture or vendor, complete this sentence:
When a customer in [defined population] crosses [risk condition], [named owner] will take [specific action] through [named system], and I will judge the intervention using [business outcome].
If you cannot complete it, pause the model decision. You have an intervention-design problem. Buying software will automate the ambiguity, while building will make the ambiguity more expensive.
Run six decision gates before choosing a path
The right answer depends on more than whether your team can train a model. Use these gates to expose the constraint that should control the decision.
Decision gate
Evidence to inspect
What pushes you toward a path
Time to value
Decision deadline, current churn visibility, and readiness of the first intervention
Urgent activation favors buying; a longer strategic horizon makes building more viable
Data readiness
Outcome labels, identity resolution, event consistency, signal freshness, and usable history
Immature data favors a packaged baseline while you repair foundations; reliable proprietary data strengthens the case to build
Strategic differentiation
Signals or decisions competitors and general-purpose vendors cannot reproduce
A must-have retention capability favors buying; a defensible product advantage favors building
Operating talent
Named owners for data pipelines, production scoring, monitoring, governance, and intervention design
Missing ownership favors buying; durable cross-functional capacity makes building credible
Activation fit
CRM, customer-success, messaging, analytics, and in-product delivery requirements
Standard integrations favor buying; specialized actions or product-embedded scoring may require a build or hybrid approach
Risk and explainability
Privacy, access, retention, audit, explanation, and regulatory requirements
Standard controls may fit a vendor platform; domain-specific constraints can justify owning selected layers
Time to value: is speed useful, or merely urgent?
A short deadline only matters when an intervention is ready. If customer success already knows what it will do with a high-risk account, buying can put usable signals into existing workflows sooner. If the team has not agreed on an action, a fast score simply creates a faster queue of unanswered alerts.
Ask for the date on which a real user must receive the first actionable score. Then work backward through integration, workflow design, governance review, enablement, and experiment setup. This prevents a vendor demonstration or model prototype from being mistaken for operational readiness.
Data readiness: can your records support the decision?
A custom model cannot rescue an unstable churn definition or inconsistent customer identity. Inspect whether product events can be joined to the correct account, whether the churn outcome is recorded consistently, whether important segments have comparable coverage, and whether signals arrive early enough to support action.
Do not interpret weak data as an automatic reason to buy. A vendor cannot manufacture missing labels or repair every instrumentation gap. It can, however, give you a practical baseline using the signals already available while your team improves the data foundation.
Differentiation: would model ownership change your product advantage?
Build when proprietary context can materially improve the decision. That may include distinctive behavioral signals, domain-specific anomaly detection, specialized explanations, or a risk score embedded directly into your product. These are stronger reasons than a general preference to own technology.
If competitors could buy an equivalent capability and churn prediction mainly helps customer success prioritize outreach, ownership is unlikely to be the differentiator. Put product and engineering attention into the intervention, customer experience, and learning loop instead.
Talent: can you operate the system after launch?
Having someone who can train a model is not the same as having an operating team. A production capability also needs data engineering, scoring infrastructure, monitoring for drift, feature maintenance, incident ownership, governance, and a product owner who connects model changes to retention outcomes.
Put a name beside every continuing responsibility. An empty cell is not a future hiring plan; it is part of the build cost. If the same scarce people are also responsible for your core product, include the opportunity cost of redirecting them.
Activation: can the score reach the moment of action?
A prediction trapped in a dashboard has little retention value. Confirm that a score can create the right CRM task, customer-success play, lifecycle message, product tour, contextual tooltip, or in-app nudge. The recipient also needs enough explanation to choose an appropriate response.
Evaluate activation with a concrete scenario, not a feature checklist. Give a candidate vendor or internal team one representative account and ask it to show the full path from new behavior to updated risk, reason, assigned owner, intervention, and measured outcome. Any manual handoff in that path belongs in the decision record.
Governance: what must remain controlled and explainable?
Document which data may be used, who may see the result, how long inputs and scores are retained, what explanations users need, and how a customer could be affected by a mistaken classification. Privacy-by-design, data governance, regulatory compliance, and AI risk management apply whether the prediction is purchased or built.
Building gives you more design control, but it also transfers the burden of evidence, monitoring, and remediation to your organization. Buying transfers implementation work, not accountability. Require the same governance review for both paths.
The pattern is straightforward: buy when speed, standard coverage, and workflow activation dominate; build when proprietary signals, specialized explanations, or product differentiation dominate; blend when you need results now but have a credible reason to own selected layers later. A useful default is to buy a working baseline and build only where your context can create an outsized advantage.
Compare the full economics, not a license and a prototype
The most common cost comparison is structurally wrong: an annual software license is placed beside the effort required to train an initial model. One is closer to an operating capability; the other is an experiment. Compare both options across the same time horizon and include four cost classes: starting, running, changing, and exiting.
What belongs in the buy case
License, usage, seat, and service costs that apply to the intended customer population.
Implementation work for event collection, identity mapping, historical data, and system integrations.
Security, privacy, legal, regulatory, and procurement review.
Internal administration, score interpretation, workflow ownership, and user enablement.
Configuration or services needed for segments, reason codes, guides, alerts, and experiments.
Limits on data access, exports, custom features, scoring frequency, and downstream activation.
Migration effort if the vendor no longer fits, including preservation of historical scores and experiment records.
What belongs in the build case
Instrumentation, data quality, identity resolution, label construction, and feature pipelines.
Exploration, training, evaluation, explanation design, and production validation.
Batch or real-time scoring, storage, APIs, access control, and reliability engineering.
CRM, messaging, customer-success, analytics, and in-product integrations.
Monitoring for drift, broken inputs, coverage gaps, and unexpected segment behavior.
Retraining, feature maintenance, documentation, incident response, and ongoing product ownership.
Replacement or migration work when the architecture, churn definition, or business workflow changes.
Add cost of delay to both cases. Buying may carry a visible contract cost, but waiting for a custom capability can defer retention experiments and leave customer-success capacity poorly targeted. Building may require more internal investment, but a vendor that cannot express your signals or deliver the required intervention can delay learning in a different way.
Keep benefit assumptions separate from cost estimates. The model’s theoretical accuracy is not a financial return. Estimate value only through an intervention that can plausibly affect customer behavior, then validate that assumption with an experiment.
Your comparison should therefore show three views for each path:
Capability: which parts of the signal-to-action loop will actually work?
Economics: what will it cost to start, operate, change, and exit?
Evidence: what experiment will determine whether the capability improves retention or NRR?
If one option looks cheaper only because a row is blank, resolve the missing responsibility before approving it.
Use a hybrid path without creating two disconnected systems
A hybrid strategy is more than running a vendor score and an internal score at the same time. Done well, it sequences the work: buy the common layers needed for speed and activation, learn which proprietary signals matter, and build only the components that earn their continuing cost.
Phase one: establish a usable baseline
Choose one defined customer population, one churn outcome, and one intervention. Configure the purchased capability to produce a risk signal and a usable reason, then route both into the workflow where the named owner can act.
Record three different kinds of evidence:
Prediction evidence: coverage, signal freshness, ranking or precision, stability across relevant segments, and the usefulness of explanations.
Operational evidence: whether scores arrive in time, whether users understand them, and whether a flagged account reliably receives the intended treatment.
Business evidence: whether the intervention changes retention, adoption, engagement, or NRR.
Do not use prediction quality to claim business impact. It is possible to identify high-risk accounts accurately and still deliver an ineffective intervention. It is also possible for a broad model to create value because it reaches the right team at the right moment. These are different questions and need different measures.
Phase two: test where proprietary context adds value
Use retention analysis to identify behaviors that appear meaningfully connected to continued use or churn. Focus on information a general-purpose platform cannot represent well, such as domain-specific sequences, unusual account structures, specialized failure states, or product-specific anomalies.
Introduce one material improvement at a time. Compare the resulting decisions with the baseline: which accounts move, whether the reason becomes more actionable, and whether the intervention performs better. A more complex score is not automatically a better product.
Use A/B testing or another appropriate controlled rollout to evaluate the intervention. Set the minimum detectable effect before the test so the team agrees on the smallest change worth detecting and whether the experiment can support the decision. Where withholding an intervention is inappropriate, compare credible treatments or use a phased rollout rather than treating measurement as optional.
Phase three: build only the layer that proved distinctive
The result may not be a complete vendor replacement. You might own a proprietary feature pipeline, domain-specific anomaly detector, custom explanation layer, or specialized risk score while retaining commercial analytics and activation. That is often a cleaner boundary than recreating collection, dashboards, integrations, guides, and workflow delivery.
Before moving a custom component into production, require evidence that:
The proprietary signal changes a meaningful decision rather than merely changing a score.
The resulting intervention has a credible path to measurable retention or NRR impact.
A named team owns data quality, production reliability, drift monitoring, governance, and retraining.
The migration preserves the activation loop instead of sending users to a separate dashboard.
The added value justifies both the continuing cost and the engineering capacity displaced by the work.
Create a canonical risk contract before two systems coexist. Define the eligible population, outcome, prediction window, score meaning, reason codes, refresh expectations, owner, permitted actions, and measurement plan. Without that contract, teams will compare incompatible scores and select whichever one confirms their prior belief.
Run the custom component beside the baseline before switching interventions. Inspect coverage, stability, explanations, workflow behavior, and segment differences without changing several parts of the retention program at once. This makes the eventual migration a product decision supported by evidence, not an infrastructure milestone searching for a justification.
Key takeaways
Buy when your immediate need is dependable coverage, rapid activation, and standard integrations for customer success or product-led growth.
Build when proprietary signals, domain-specific risk scoring, specialized explainability, or product differentiation can create material value and you can fund continuing operations.
Blend when you need a working baseline now and have a testable hypothesis about where your data or context can outperform a general-purpose capability.
Do not approve any path until every score has a named recipient, a defined action, a delivery system, and a business outcome.
Compare equivalent total costs, including data work, integrations, monitoring, governance, activation, opportunity cost, and migration.
Measure the model and the intervention separately. Prediction quality can prioritize attention; only an effective action can improve retention.
Take a one-page decision memo into your next review. It should name the churn definition, first population, intervention, deadline, available signals, proprietary advantage, workflow, operating owners, governance constraints, total-cost boundary, and experiment. End the meeting with a selected path and an explicit condition for reconsidering it.
Start with the smallest path that closes the loop from behavior to action to measured outcome. Earn the right to build more by proving that your own data changes the decision and that the decision changes retention.
Internal Products Are Hard; Commercial Products Are Harder. That line captures years of hard-won lessons from leading both internal platforms and market-facing SaaS at HighLevel. I’ve seen how the two demand different muscles—even when the tech stack, talent, and timelines look the same on paper.
When I talk about internal products, I mean services and solutions that our own employees use to take care of customers—customer-enabling tools and services, agent consoles, fulfillment and billing workflows, operations dashboards, and the underlying platforms that keep them fast, compliant, and resilient. These tools don’t generate revenue directly, but they quietly determine customer experience, gross margin, and how quickly we can ship, resolve issues, and scale.
Commercial products, by contrast, add a second challenge layer. Beyond discovery, usability, and reliability, we must conquer positioning, pricing and packaging, competitive differentiation, sales enablement, procurement hurdles, and ongoing customer success motion. The surface area for failure is bigger, and the time-to-signal on product-market fit is slower and noisier.
Here’s how I decide where to invest. First, I anchor on outcomes, not output. If the business priority is net revenue retention, faster onboarding, or reduced cost-to-serve, internal products often provide the highest-leverage path. If the priority is new revenue, new market entry, or a must-have differentiator, we lean commercial. I make the trade explicit in outcomes vs output OKRs so we can defend the decision when pressure mounts.
Second, I run a clear build vs buy calculus. For internal needs, the default is buy if a mature, configurable solution exists that meets our security, data governance, and integration requirements. I only build when the workflow is core to our differentiation, the TCO of customization is lower than vendor sprawl, or we can capture unique proprietary advantage. For commercial products, I avoid embedding third-party IP in a way that caps differentiation or compresses margins as we scale.
Third, I insist on continuous discovery. Internal audiences are not a captive market—they’re discerning experts with real jobs to do. I treat them like customers, with structured customer interviews, journey mapping, and opportunity solution trees. I rely on empowered product teams and product trios to validate problems and reduce solution risk before we commit engineering time.
Fourth, I frame commercial vs internal work with capacity guardrails. In most planning cycles, I reserve explicit allocation for platform scalability and internal tooling, separate from feature bets. Without this, internal products become backlog filler, which guarantees we’ll pay the interest later in churn, SLA breaches, and slower delivery.
Execution differs too. For internal products, change management is the make-or-break. I plan enablement as a first-class deliverable: clear rollouts, in-app guides, training, and feedback loops with frontline champions. I track adoption, time-to-resolution, error rate, and satisfaction for internal users with the same rigor we apply to external users.
For commercial products, I design the discovery-to-GTM handshake early. Pricing and packaging must reflect value drivers discovered in research, not what’s easiest to meter. Sales and solutions engineering need crisp narratives, objection handling, and proof points. Customer success needs activation plans and health signals tied directly to leading indicators of retention.
Across both, I instrument the product and process. I lean on feature flags and progressive delivery to manage risk, and I protect SLOs with error budgets so teams balance reliability with iteration speed. CI/CD isn’t a badge—it’s how we earn the right to ship continuously without eroding trust.
Common pitfalls recur. Teams skip UX for employee tools because “they have to use it”—which backfires as shadow workflows and rework. Leaders underfund internal platforms, then wonder why velocity stalls. On the commercial side, teams over-index on features and under-invest in positioning and onboarding, leading to poor activation and elongated sales cycles.
What’s the payoff? When we treat internal products as products, we unlock scale: shorter handling times, fewer escalations, clearer accountability, and higher customer satisfaction. When we approach commercial products with the same discovery rigor plus smart GTM, we compress time-to-value and amplify differentiation. The craft is knowing which lever to pull when—and having the discipline to measure what matters.
My rule of thumb is simple. If the goal is operational excellence that compounds across the entire customer journey, invest in internal products with the same intensity you reserve for revenue-generating features. If the goal is market expansion or category leadership, invest in commercial products with a tight discovery-to-GTM loop. In either case, clarity of outcomes, disciplined discovery, and empowered teams win the day.
PR review bots are all the rage, but they cost a premium. We built our own for cheap that work just as well, if not better. Here's how.
As a VP of Product Management, I care deeply about the velocity and quality of our software delivery. The decision to build our own pull request (PR) review agents came from a simple calculus: we needed tighter control over developer experience, CI/CD integration, and cost—without sacrificing accuracy or reliability. The result was a pragmatic system that accelerates reviews, improves code quality, and pays for itself through faster feedback loops.
Before we wrote a line of code, we defined success. Our objectives were to shorten review cycles, reduce back-and-forth on style and test coverage, and surface risks earlier—measured against DORA metrics like lead time and deployment frequency. That focus aligned the team, guided our build vs buy decision, and anchored scope to the highest-impact use cases.
We started rules-first, AI-optional. The initial release enforced guardrails that are universally valuable: linting and formatting checks, required test coverage thresholds, commit message standards, ownership validation (CODEOWNERS), and basic security scans. These automated gates eliminated predictable review friction, freeing engineers to focus on logic and architecture rather than style debates.
Then we layered intelligence where it mattered. We added lightweight, explainable checks for common code smells and dependency risks, plus optional natural-language summaries that turn large diffs into concise context. Where appropriate, we introduced agentic AI workflows to triage PRs by risk, draft review comments, and suggest missing tests—always keeping humans in the loop. This hybrid approach kept costs low and outcomes high.
Integration with our CI/CD pipeline was non-negotiable. We wired GitHub/GitLab webhooks to a stateless service that queued work, executed checks in containerized workers, and posted results back as status checks and review comments. Caching, parallelization, and smart diff-scoping ensured we only computed what changed, keeping the experience snappy even on large repos.
Adoption hinged on developer experience. We made the bot’s feedback fast, specific, and actionable, with clear remediation steps and links to documentation. Feature flags allowed teams to opt into new checks gradually. ChatOps commands enabled quick overrides for emergencies, while policy-as-code kept rules visible, versioned, and auditable.
We treated this like any product: eval-driven development for accuracy, ongoing telemetry for false-positive rates, and explicit SLAs for response times. We instrumented outcomes end-to-end—tracking PR cycle time, comment-to-merge ratios, and rework—so we could prove the ROI and tune the system without guesswork.
The outcome: a reliable PR review companion that runs on a shoestring budget, integrates cleanly with our workflows, and measurably improves engineering throughput. If you’re weighing build vs buy, start small with rules that deliver immediate value, then layer intelligence where it earns its keep. With a clear product strategy, you can stand up capable PR review bots quickly—and scale them as your needs grow.
If you’re ready to try this yourself, begin with your top three friction points in code reviews, wire them into your CI/CD checks, and pilot with a single team. Iterate weekly, measure relentlessly, and let your developers be your strongest signal. You’ll be surprised how far a pragmatic, product-led approach can take you.
Inspired by this post on Amplitude – Perspectives.
I just watched one of the most significant leaps in customer service AI in years. Last week, a quiet but seismic release landed in CX: Fin introduced Apex, a vertical model purpose-built for support that raises the bar on speed, accuracy, and cost. As a product leader, this is exactly the kind of breakthrough that changes roadmaps, vendor strategies, and what customers can expect from modern service operations.
It’s a brand new model for Fin called Apex, and it’s objectively the highest performing, fastest, and cheapest model for customer service. It beats the very best models in the industry including GPT-5.4 and Opus 4.5.
In this analysis, I’ll unpack why the launch matters for the customer service agent category, what it signals for frontier labs and open‑weight ecosystems, and how leaders should rethink their AI Strategy, build vs buy decisions, and eval-driven development roadmaps.
Fin was already the highest performing and most sophisticated agent in the customer service space, consistently beating impressive competitors like Decagon and Sierra at an average win rate in the 70s. It operates at tremendous scale, now resolving almost 2M customer issues per week, a number that’s growing at an exponential clip. In its short life it’s grown to nearly $100M in recurring revenue.
As of last week, ~100% of all (English language, chat and email) customer conversations are now running on Apex. Since day 1, the Fin engine has comprised a system of models, and last year the team began replacing off‑the‑shelf models with custom ones trained on proprietary data. The core answering model had been a frontier labs offering—initially versions of GPT and more recently Sonnet 4.0. Now, that core answering model is Apex 1.0.
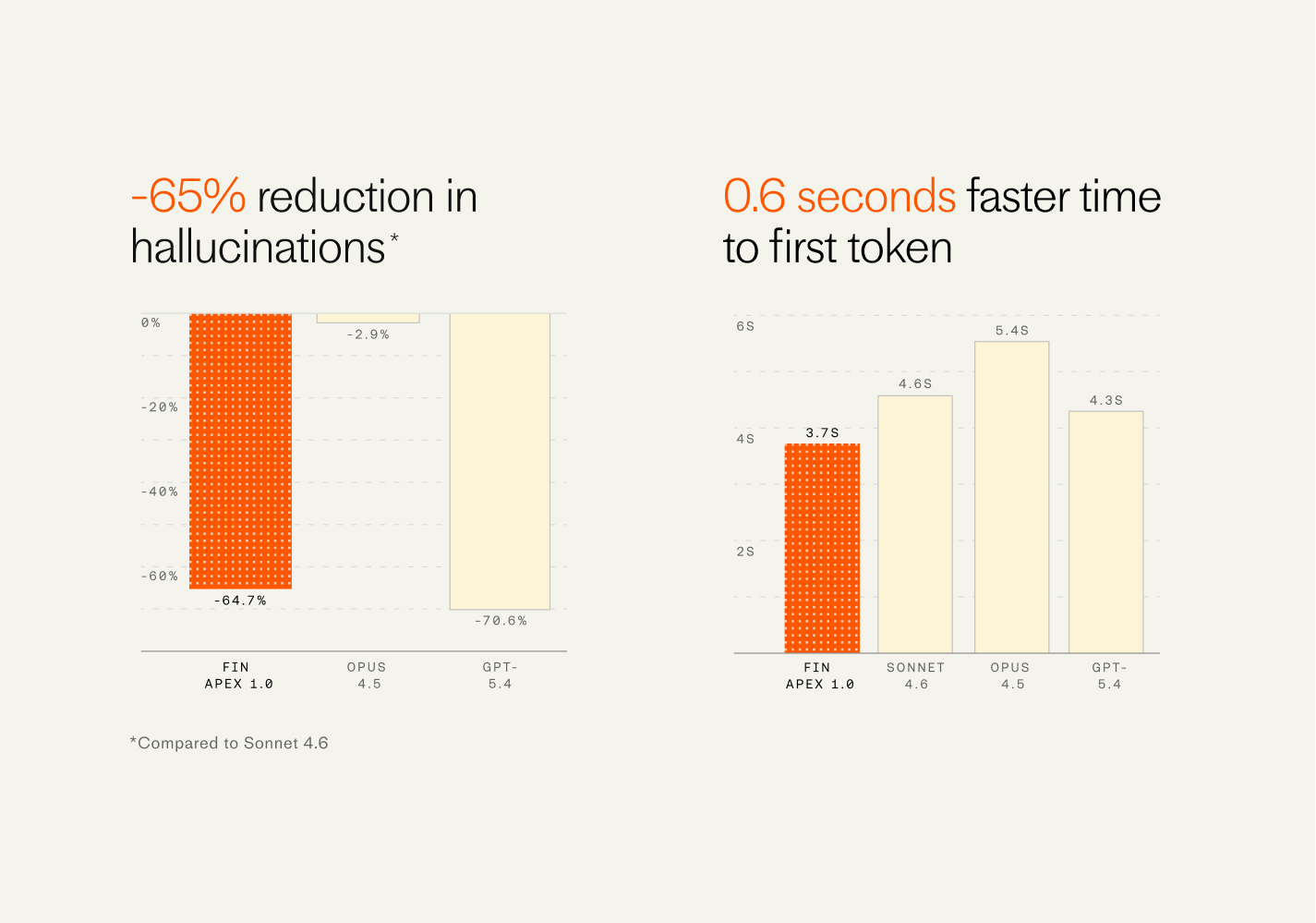
This model resolves customer issues at a materially higher rate than any other model available. One of their largest customers in the gaming space saw the resolution rate improve overnight from 68% to 75% (i.e. a reduction in unresolved conversations of 22%). The team notes they had never seen a jump this large from a single improvement since they started Fin.
Just as important, it’s dramatically faster, has fewer hallucinations, and is far cheaper than other available models—exactly the attributes operations leaders weigh most when deploying agents at scale. In practice, these are the levers that unlock higher CSAT, tighter SLAs, and better unit economics.
Achieving all three simultaneously is extraordinarily hard. Credit goes to foundational research from a 60‑person AI group run by Fergal Reid, and, crucially, to domain‑specific proprietary evals drawn from billions of human and agent interactions produced by the Fin resolution engine—already hand‑tuned to be the most effective in the category. That creates a flywheel: an eval‑driven development loop that trains models to keep improving at the edge of the system’s abilities. In other words, Apex 1.0 looks like the tip of the iceberg.
Zooming out, service is one of the few categories where generative AI has already delivered commercial impact at scale (alongside coding, and arguably the legal industry). With TAMs measured in the hundreds of billions, competition is intense and well capitalized. The pattern I’ve seen repeatedly is clear: winners in these spaces must become full‑stack AI companies. As features become ~free to build, durable competitive differentiation shifts under the hood—to proprietary data, post‑training, inference efficiency, and the quality of the eval loop.
Fin Apex raises the bar for finance-ready AI, highlighting a -65% cut in hallucinations and a quicker first token at 3.7s (0.6s faster), compared with Sonnet 4.6, Opus 4.5, and GPT-5.4 in side-by-side charts.
That’s why competitors will need to release their own models. Many appear to be just starting to hire the talent to do so, which likely gives Fin at least a year of head start. For product leaders, this is a strong signal to revisit build vs buy assumptions, and to quantify when owning your post‑training pipeline and evals becomes the rational move.
Honestly, 2–3 years ago I expected AI application differentiation to live mostly in what we built around third‑party models. The AI game humbles all of us; today it’s obvious that vertical models paired with proprietary evals create compounding moats.
In a podcast interview last week, Andrej Karpathy said:
"I do think we should expect more speciation in the intelligences. The animal kingdom is extremely [diverse] in the brains that exist. And there’s lots of different niches of nature… And I think we should be able to see more speciation. And you don’t need this oracle that knows everything. You kind of speciate it. And then you put it on a specific task. And we should be seeing some of that because you should be able to have much smaller models that still have the cognitive core."
The frontier labs still have the very best models, but open‑weight models aren’t far behind—making pre‑training look increasingly like a commodity. The frontier is moving to post‑training, which is precisely what we see with Apex (and Cursor’s Composer 2), and what we should expect to dominate going forward.
Labs now face a dual reality. On one hand, horizontal general‑purpose models can over‑serve specific verticals (e.g., customer service doesn’t need an oracle that knows everything). On the other, open‑weight models are good enough that high‑quality, domain‑specific post‑training can produce superior models for special‑purpose jobs—and in the ways that matter for those jobs. In service, soft factors like judgement, pleasantness, and attentiveness matter alongside hard factors like resolution effectiveness, speed, and cost.
I’m still bullish on the labs. Many organizations remain heavy customers of Anthropic—whether as part of multi‑model systems or through deep usage of Claude Code in engineering teams (see this example of Claude Code adoption). Yet classic disruption (à la the late, great Clay Christensen) is now at their door. The way out is to disrupt themselves by building cheaper specialized models too, which likely requires acquiring the evals—or the companies with the evals—needed for each task. Expect creative data partnerships, M&A consolidation, and a wave of hyper‑specific model providers that compete head‑to‑head with the labs.
In the meantime, Fin appears to be the only vendor in its space with a custom model that’s also objectively superior to everything else out there. I’m excited to see it deployed broadly for end customers, and I’m watching closely for the next announcement that will accelerate that rollout. For product leaders, the message is clear: the age of vertical models and agentic AI is here—bring your evals, or bring your checkbook.
Your AI roadmap is filling up, but every new use case seems to require another custom retrieval pipeline, another evaluation method, and another analytics implementation. The pilots may work. The portfolio does not yet compound.
You do not solve that problem by declaring an AI platform initiative and assembling a long infrastructure backlog. You solve it by identifying the decisions your products must support, defining the contracts every AI workflow must honor, and connecting evaluation to real product behavior. The result is a foundation that makes the next useful experiment easier to ship, safer to operate, and easier to learn from.
Make critical use cases define the platform
A platform team can spend months building abstractions that application teams neither understand nor need. The usual cause is starting with components: a model gateway, vector storage, a feature store, an evaluation tool, or a new analytics stack. Each may be useful, but none tells you what the platform must make easier.
Start with the highest-value AI decisions in your product and internal operations. A use case is specific enough when you can describe the person making the decision, the context the system requires, the action the AI is allowed to take, the unacceptable failure modes, and the outcome you expect to change.
Write a short capability brief for each critical use case:
User and moment: Who is trying to do what, and where does the AI enter the workflow?
Decision or action: Is the system recommending, drafting, classifying, retrieving, or acting autonomously?
Required context: Which behavioral events, account data, documents, permissions, and prior actions affect the answer?
Quality definition: What makes an output acceptable, and which errors matter most?
Release evidence: What must pass before the change reaches users?
Product outcome: Which user behavior or business result should move if the capability works?
Operating constraints: What must be logged, redacted, approved, monitored, or reversible?
Owner: Who owns the outcome after launch, rather than merely delivering the component?
Now compare the briefs. Repeated needs are platform candidates. If several use cases require permission-aware retrieval, consistent experiment assignment, traceable prompt versions, or the same release evaluation, those capabilities deserve shared interfaces. A requirement that appears once may belong inside the application until reuse is proven.
This distinction prevents two expensive mistakes. The first is premature generalization: building a universal service before you understand the variation. The second is copy-and-paste scaling: allowing every team to create incompatible versions of a capability that is already clearly common.
Prioritize the platform backlog by friction removed from critical use cases, not by architectural elegance. A useful backlog item should complete a sentence such as: After this ships, a product team can run the standard evaluation suite on every retrieval change without building its own runner. If the item cannot name the team behavior it changes, it is probably still an implementation idea rather than a platform outcome.
Build the foundation as four enforceable contracts
A foundational AI platform is not one product or one technical layer. It is a set of contracts connecting data, evaluation, delivery, and analytics. The contracts matter more than whether every component comes from the same vendor. They let application teams move independently without giving up consistency where consistency is valuable.
1. The data and context contract
This contract defines what context an AI workflow can request and what comes back. It should cover identity, permissions, event definitions, document metadata, freshness, provenance, and retention. Retrieval should enforce access rules before context reaches the model, not rely on the model to decide what a user may see.
Keep the interface narrow. An application should be able to request approved context for a known user, account, and task without understanding every underlying data system. The response should carry enough metadata to explain where the context came from and which version was used.
A feature store belongs here when several predictive or real-time workflows need the same feature definitions at training and serving time. It should not become a mandatory platform component merely because feature stores appear on AI architecture diagrams. Add one when inconsistency is a demonstrated problem.
2. The evaluation contract
This contract defines the evidence required to change a model, prompt, retrieval configuration, tool, or policy. It should include representative test cases, expected behavior, failure labels, scoring rules, comparison baselines, and release gates.
Do not reduce evaluation to one average score. A harmless wording variation and a permission leak cannot cancel each other out. Track important failure classes separately and make critical failures blocking. Keep examples that exposed production problems so the evaluation set becomes a memory of what the system has learned.
This contract governs how a tested change reaches production and how you recover when it behaves badly. It should preserve the versions of the model, prompt, retriever, tools, policies, and relevant data configuration associated with each release.
Use controlled rollout, feature flags, rollback paths, and CI/CD gates for AI changes just as you would for other consequential product changes. Observability should connect a production trace to the exact configuration that produced it. Otherwise, a team can detect a quality drop without being able to isolate whether the model, context, prompt, tool call, or upstream data changed.
Record enough to diagnose the workflow, but do not treat raw prompts and conversations as ordinary telemetry. Apply privacy-by-design: minimize collection, redact sensitive fields where appropriate, control access, and make retention a deliberate policy. The default path should be the governed path. If secure operation requires every application team to remember a separate checklist, the platform has not removed the risk.
4. The product analytics contract
This contract maps AI interactions to product behavior. Define events for exposure, acceptance, correction, rejection, fallback, task completion, and abandonment where those states apply. Include stable identifiers that connect an interaction to its release and experiment assignment without copying sensitive content into the analytics layer.
The contract should also specify which product metric each AI capability is expected to influence. That keeps teams from declaring success because response quality improved in an offline test while users ignore the feature or fail to complete the task.
Turn analytics into the AI learning and control loop
Traditional product analytics asks what users did. AI evaluation asks how a probabilistic workflow performed. You need both views joined at the interaction level. Without that connection, model teams optimize scores, product teams optimize funnels, and neither can explain why a release helped or hurt the user.
Use four layers of measurement, and do not blend them into one health score:
Build vs. buy is a decision that never truly goes away, and with AI reshaping the economics of software, I’m revisiting this question more frequently—and with more nuance—than ever. The temptation to “just build it” is real when prototypes are cheaper, shipping feels faster, and small tools can rival big platforms. But the real decision has never been about code; it’s about value, data, and long-term responsibility.
Across product orgs at every stage, I see the same pattern: AI makes building feel easier—but it doesn’t eliminate the tradeoffs. The hard part is separating what differentiates your product from what simply supports it. That’s why I start by asking whether the capability is truly core to my value stream, and then I force myself to reason about ownership and maintenance, not just velocity.
My rule of thumb remains simple: If something isn’t core to your value stream, don’t build it. And even when it is core, vendors may still be better positioned—especially for payments, invoicing, and infrastructure. Those domains carry deep operational complexity, continuous compliance, and reliability requirements that are easy to underestimate and painful to own.
Here’s how this plays out for me. I would never build my own blogging platform. I moved from WordPress to Ghost, because publishing isn’t where I differentiate, and the long tail of upgrades, security, and performance is a drag on focus. The platform does the job, my audience gets a better experience, and my team avoids owning commodity maintenance work.
On the other hand, I did build my own task management system—despite the abundance of excellent tools like Trello, Evernote, and OmniFocus. For me, tasks, notes, and workflows are deeply personal and idiosyncratic. I wanted my system to reflect how I think, plan, and communicate, with tight integration to my daily product rituals. In this case, the underlying data became the real product—and owning and controlling that data changed the equation.
That’s the heart of the decision: When the underlying data becomes the real product, ownership matters. Task management, notes, and workflows evolve into a personalized operating system. The moment your data model represents your unique value—and your future differentiation—build vs. buy is no longer a tooling choice; it’s a strategy choice.
AI is pushing this even further. Cheaper prototyping and “vibe coding” lower the cost of building. Tools like Claude Code and platforms from OpenAI make it viable to ship smaller, targeted tools that would have been uneconomical a few years ago. That expands the frontier of what teams can build without committing to a monolithic platform—and it puts pressure on vendors to improve data portability.
Which brings me to vendor lock-in. Exports aren’t always enough. When I evaluate CRMs or course platforms, I look for more than CSV dumps. I want robust, well-documented APIs, webhook coverage, import/export parity, schema transparency, and a clear migration path. I’ve seen teams drown in brittle integrations with Salesforce or HubSpot, struggle to unwind course data from Teachable, or get stuck in signature workflows around DocuSign without a clean escape hatch. Portability is table stakes now.
I treat build vs. buy as a discovery problem. Options are assumptions to test. On the build side, I run feasibility spikes: proof-of-concept integrations, latency checks, cost-to-serve models, and a sober read on maintenance. On the buy side, I trial vendors, not their marketing. I replicate a real workflow, test the edges, validate data portability, and simulate failure modes like vendor downtime or schema changes.
A word of caution on complexity: “we can build anything” is not the same as “we should build this.” Long-lived products accumulate hidden complexity over time—security, privacy, performance, observability, SRE runbooks, QA automation, documentation, and compliance. Be honest about engineering capabilities and maintenance costs, especially when uptime and regulatory exposure are in play.
My practical checklist looks like this: Is this core to our differentiation? Do we need to own the data model? How strong is data portability (APIs, webhooks, mapping, re-import)? What’s the true total cost of ownership over three years (people, ops, security, compliance)? Are there regulatory or reliability constraints better handled by a vendor? What’s the opportunity cost of not building something more strategic? And if we buy, what’s our exit plan?
Ultimately, build vs. buy isn’t just about speed or cost—it’s about core value, data ownership, and long-term responsibility. AI lowers the barrier to building, but it doesn’t erase complexity. Treat build vs. buy decisions like any other discovery effort: test assumptions, prototype, and validate before committing. Ask not just can we build it, but should we own it?
If you’re wrestling with vendor lock-in, fielding pressure to “just build it,” or rethinking your stack in an AI-first world, this lens will help you ask better questions before you commit. And if you’re exploring targeted builds alongside platforms like Stripe, Dropbox, Obsidian, or Ghost, I’d love to hear what’s working for you and where portability remains a hurdle.
I’ve spent the last few years turning AI from an intriguing demo into an operational advantage, and the clearest wins come when we treat agents as productized workflows—not toys. In practice, that means aligning agentic AI to a sharp product strategy, instrumenting everything, and scaling what works across the organization.
Learn how companies like Replit are consolidating workflows, creating one-person departments, and building systems for scale with Amplitude
When I talk about agentic AI, I’m focused on outcomes: fewer handoffs, faster cycle times, and measurable uplift in activation, retention, and NPS. The most successful rollouts start with a specific job-to-be-done, translate it into clear AI workflows, and then iterate with a tight feedback loop between data, design, and engineering.
My implementation playbook is simple and disciplined. First, choose a high-friction workflow and define success upfront. Second, make the build vs buy call on the foundation model, orchestration layer, and connectors. Third, establish AI risk management and safeguards early—before scale amplifies errors. Finally, run small, eval-driven releases and promote what performs.
Instrumentation is where the leverage compounds. With Amplitude analytics as a unified analytics platform, I design purposeful events (agent intent, tool calls, resolution state, human handoff), map funnels from user input to agent outcome, and cohort users by context to pinpoint lift. This gives me an honest read on where agents help, where they hinder, and what to tune next.
The “one-person departments” concept isn’t about doing more with less at all costs; it’s about assembling a tight loop of product management leadership, data, and automation so one operator can own a business outcome end-to-end. An agent handles the repeatable work, while the human focuses on judgment, edge cases, and continuous improvement that compounds.
As we scale, I look for platform scalability patterns: shared tools and policies, reusable prompt libraries, standardized evaluation suites, and consistent governance. That structure keeps agent performance predictable while preserving speed, and it aligns beautifully with product-led growth when agents are embedded directly in the product experience.
If you’re starting now, begin with a single, valuable workflow. Instrument it thoroughly with Amplitude analytics, make decisions from the data you see—not the demos you remember—and expand only after you’ve proven uplift. Iteration beats ambition here: agentic AI rewards teams who measure relentlessly and scale only what truly works.
Inspired by this post on Amplitude – Perspectives.
You have an AI capability on the roadmap. A vendor can demonstrate something credible almost immediately, while engineering believes an internal version would fit the product better. Both claims may be true, and neither one answers the decision in front of you.
The useful question is not simply whether to build or buy. You need to decide which parts of the capability create strategic advantage, what you must learn before committing further, which obligations you are prepared to own, and how you will leave if the economics or technology changes.
Draw the capability boundary before comparing options
Most weak build-versus-buy debates begin with a label that is too broad. AI assistant, support automation, recommendation engine, and enterprise search each describe an experience, not a single technical capability. Comparing a vendor’s finished product with an imagined internal system at that level guarantees an uneven evaluation.
Break the experience into layers before discussing ownership. An AI product might contain data connectors, ingestion, domain retrieval, ranking, generation, orchestration, evaluation, observability, policy guardrails, workflow logic, a user interface, and a human handoff. You can make a different decision for each layer.
Classify every layer by its strategic role:
Differentiation: The layer materially affects why customers choose, retain, or expand with your product. It may encode a proprietary workflow, use unique data, or create a feedback loop competitors cannot easily reproduce.
Parity: Customers expect the capability, but it is not a meaningful reason to choose you. Reliable billing infrastructure, standard integrations, and generic analytics plumbing often belong here.
Control: The layer may not be visible to customers, but it determines whether you can satisfy security, regulatory, reliability, cost, or product-policy obligations. Control can justify ownership even when the layer itself is not differentiating.
If this layer became substantially better, would it change the product’s value proposition or merely close a feature gap?
Does operating it create proprietary data, evaluation evidence, workflow knowledge, or customer insight that compounds over time?
Would dependence on a vendor’s roadmap prevent you from making an important product promise?
Could a close competitor buy the same capability and achieve roughly the same result?
Do privacy, residency, auditability, reliability, or recovery requirements force you to retain direct control?
Can your team support the layer after launch, including incidents, upgrades, security work, and user adoption?
A retrieval-augmented generation system shows why this decomposition matters. The right answer may be to build the parts that encode domain knowledge while buying fast-moving infrastructure around them.
Layer
Strategic question
Plausible initial posture
Domain retrieval and ranking
Does relevance depend on proprietary content, metadata, permissions, or customer context?
Build when this is central to answer quality and differentiation.
Orchestration and observability
Would owning the runtime create customer value, or only infrastructure work?
Buy when a platform provides adequate reliability, APIs, and portability.
Prompts, policies, guardrails, and evaluation cases
Do these artifacts encode product behavior, risk tolerance, and domain expertise?
Own the specifications and evidence even if a vendor executes them.
User workflow and human handoff
Is the workflow part of the product’s distinctive experience?
Build the differentiated interaction; integrate commodity components behind it.
The point is not that every retrieval system should use this split. The point is to stop forcing one ownership decision across layers with different strategic value. A composed architecture can give you speed at the edges and control at the center.
Compare time to value and total ownership cost separately
Buying and building usually produce different cost curves. Buying can reduce the initial implementation burden and provide proven operations. Building concentrates cost and complexity near the beginning but may create a better fit and more favorable economics at scale. Neither profile is automatically cheaper.
Evaluate the decision across two horizons. The first is time to activated value: how long it takes before the intended users complete the intended workflow successfully. The second is total cost of ownership over the period in which the capability must operate, evolve, and eventually migrate.
Do not treat a signed contract, completed deployment, or merged pull request as time to value. Procurement, security review, data preparation, integration, enablement, in-product guidance, and user activation sit between acquisition and an actual outcome. A fast purchase with weak adoption is not a fast result.
A useful cost model is:
Total ownership cost = acquisition or development + integration + operations + change + risk exposure + exit.
Apply the same formula to both choices. Teams often present the vendor’s full commercial cost against only the internal development estimate, or compare a subscription price with an imagined build that excludes maintenance. Both comparisons are misleading.
Cost area
Evidence needed for a buy option
Evidence needed for a build option
Acquisition or development
Subscription, per-seat or consumption charges, implementation fees, support tier, and expected price changes with growth.
Product, design, engineering, data, security, and platform capacity required to reach usable scope.
Integration
Connector work, identity and permission mapping, data transformation, API constraints, testing, and CI/CD maintenance.
Interfaces with existing systems, migration of current workflows, data contracts, and platform dependencies.
Operations
Internal administration, vendor management, incident coordination, usage monitoring, and workarounds for roadmap gaps.
On-call ownership, observability, model and dependency updates, incident response, capacity management, and reliability work.
Change
Configuration limits, professional services, retraining, contract changes, and waiting for vendor roadmap delivery.
Continuing product development, evaluation maintenance, documentation, enablement, and the opportunity cost of displaced roadmap work.
Risk exposure
Vendor outages, security posture, data handling, roadmap dependence, quota changes, and concentration risk.
Internal security gaps, insufficient operational maturity, key-person dependency, and failure to meet compliance obligations.
Exit
Data export, contract termination, migration assistance, replacement integration, and reconstruction of non-portable artifacts.
Decommissioning, data migration, user transition, and replacement of internally coupled components.
Run an expected case and a stress case for both options. For a vendor, stress usage, API consumption, support requirements, and the cost of additional environments or features. For an internal system, stress incident load, model or infrastructure changes, evaluation maintenance, and continued product demands. The purpose is not to produce a perfectly precise forecast. It is to expose which assumptions can overturn the decision.
Record those assumptions in the decision memo. If vendor consumption cost must stay within an agreed envelope, state that envelope internally and assign someone to monitor it. If the build case depends on reuse across several product surfaces, name those surfaces and verify that their teams actually intend to adopt the component. An unowned assumption is not a forecast; it is hidden risk.
Turn the debate into an evidence-based decision
A scorecard is useful only when it forces explicit trade-offs. It should not turn judgment into decorative arithmetic. Establish hard gates first, agree on the relative importance of the remaining criteria before vendor demonstrations or internal prototypes create attachment, and then evaluate both options against the same outcome.
How directly does the capability support the value proposition or defensibility?
Product strategy, roadmap commitments, customer workflow evidence, proprietary data advantages, and the importance of controlling behavior.
Build becomes more attractive as the capability determines why customers choose or stay.
Urgency and time to value
What is the cost of waiting, and when can users reach a meaningful outcome?
Procurement and security timelines, integration dependencies, build scope, launch readiness, enablement needs, and adoption path.
Buy becomes more attractive when delay is costly and the purchased path can reach activated value materially sooner.
Security and regulatory risk
Can either option verifiably meet non-negotiable obligations within the launch window?
Data-flow diagrams, privacy controls, residency, retention, audit logs, access controls, certifications, threat response, model lineage, and red-team practices.
An option that fails a mandatory obligation should be removed, regardless of its aggregate score.
Integration complexity
How much continuing work is hidden behind the initial connection?
Sandbox tests, API behavior, quotas, identity mapping, data contracts, failure modes, deployment workflow, and ownership of connectors.
Build gains ground when vendor constraints create persistent product or operational work; buy gains ground when internal integration and support exceed the apparent build scope.
AI leverage and portability
Which prompts, data, evaluations, embeddings, policies, and feedback become valuable, and can they move?
Export tests, API abstraction, model-routing options, ownership terms, deletion process, evaluation access, and migration design.
Build or a hybrid architecture gains ground when the vendor captures an asset central to future differentiation.
Security, regulatory compliance, and minimum reliability are gates, not preferences. A high score elsewhere cannot compensate for an option that cannot lawfully handle the data, meet a required recovery posture, or provide necessary audit evidence. The same logic applies to internal capacity: if no team can own production incidents, an attractive prototype is not a viable build option.
Use a product trio of product, design, and engineering to set the scorecard’s priorities. Bring security, data, finance, procurement, and operations into the criteria they own. This prevents a late-stage veto from appearing as a surprise when it was actually a missing requirement.
Then run comparable discovery work. Give the vendor a production-like workflow in a sandbox. Give the internal option a thin vertical slice that touches the real data and integration boundary. Test the same cases for outcome quality, failure handling, permissions, auditability, operator effort, integration behavior, and unit economics. A polished vendor demonstration and a rough internal prototype reveal different things; common acceptance cases make the evidence comparable.
Keep confidence separate from the decision direction. A criterion can favor building while resting on weak evidence. Mark it as an assumption and define the cheapest test that would resolve it. This is more useful than adding precision to a score whose inputs remain speculative.
The final memo should fit the decision, not the politics around it. Include the capability boundary, strategic classification of each layer, intended user outcome, hard gates, scorecard, cost assumptions, evidence quality, operational owner, exit path, and re-evaluation triggers. Anyone reading it later should be able to tell why the decision was reasonable at the time and which changed condition would justify revisiting it.
Run an AI-specific risk and portability pass
AI changes more than development speed. It introduces movable models, probabilistic behavior, data-dependent quality, metered usage, and artifacts that can become strategically valuable. A normal software procurement checklist will miss several of these dependencies.
Data route: Document what enters the system, which service receives it, where it is stored, how long it is retained, whether it can be used for training, how deletion works, and whether residency requirements apply. Include prompts, retrieved context, generated output, user feedback, and operational logs.
Model and quality governance: Require a way to identify the model, configuration, prompt, retrieval state, and policy version associated with important behavior. Decide who maintains evaluation cases, reviews regressions, investigates failures, and approves consequential changes.
Security and privacy: Verify role-based access, audit logs, PII handling, privacy-by-design controls, threat detection and response, and the vendor’s red-team and incident practices. For an internal build, require equally concrete evidence rather than assuming control equals safety.
Portability: Establish ownership and export mechanisms for source data, metadata, prompts, policies, evaluation sets, feedback, transcripts, and relevant logs. Treat a contractual right to export and a technically usable export as separate requirements.
Unit economics: Map every metered event in the actual workflow. Per-seat pricing, consumption charges, model usage, and orchestration can behave differently as adoption and workflow complexity grow. Test the economic model against expected and stressed usage.
Operational responsibility: Specify who diagnoses a failure that crosses your application, the vendor platform, a model provider, and a data source. Shared architecture does not remove accountability; it makes the handoffs more important.
Portability deserves an actual exit test. Ask the vendor to produce a representative export before the contract is final. Confirm its format, completeness, permission model, and usefulness in another environment. An export button is not evidence that you can reconstruct the product behavior that matters.
Prompts require the same caution. Access to prompt text is necessary, but equivalent behavior may still depend on a model, tool interface, retrieval implementation, or vendor-specific orchestration. Preserve the intent, policies, evaluation cases, and expected outcomes around a prompt, not just the string itself.
Embeddings can also create false confidence about portability. Preserve the original content, chunking inputs, metadata, permission relationships, and evaluation set so embeddings can be regenerated if the model or retrieval system changes. The derived vectors alone are not a complete migration asset.
For vendors, negotiate transparent API quotas, usable sandbox environments, data-export terms, growth price protections, and clear ownership of AI artifacts. Pressure-test the roadmap against your deployment cadence and ask how incidents, breaking changes, and model transitions are communicated. For an internal build, apply the same rigor to service levels, incident response, observability, model lineage, retention, and ongoing staffing.
Buying does not outsource your responsibility for the product’s behavior. Building does not prove that the behavior is controlled. Choose the implementation that can produce the evidence your risk level demands within the launch window.
Make a staged commitment with explicit re-evaluation triggers
A build-versus-buy decision does not need to be permanent to be disciplined. When uncertainty is high and speed matters, a bounded purchase can be a learning instrument. When differentiation or control is already clear, a minimum lovable internal slice can establish the core while purchased components accelerate everything around it.
For a buy-to-learn path, use this sequence:
Name the uncertainty. Decide whether you are testing demand, workflow fit, quality, integration feasibility, adoption, operational burden, or economics. Do not call a general implementation a pilot.
Bound the commitment. Limit initial scope, data exposure, coupling, and custom vendor work to what the learning objective requires. Preserve an adapter or interface where replacement would otherwise become expensive.
Instrument the outcome. Track whether intended users activate, return, complete the workflow, accept the output, escalate to a human, and create operational work. Monitor consumption and connector reliability alongside product use.
Review against prewritten triggers. Deepen the vendor integration if adoption is durable, economics remain acceptable, and integration pain is manageable. Move toward building if unique requirements emerge, strategic artifacts accumulate, vendor constraints block the roadmap, or costs reach the agreed inflection point. Stop if the user outcome does not materialize.
This approach works because a purchased solution can validate value before a deeper build commitment. The learning is reusable only if you retain the data model, evaluation evidence, workflow understanding, and user-behavior insight rather than burying them inside vendor-specific configuration.
For a build-to-differentiate path, keep the first scope narrow. Build the smallest end-to-end experience that proves the differentiating hypothesis. Buy mature infrastructure around it where doing so does not surrender the key data, policy, or product behavior. Isolate components behind explicit interfaces so a model, orchestration service, retrieval system, or observability layer can change without rewriting the entire experience.
Set re-evaluation triggers before launch, while nobody is defending a sunk decision:
Product trigger: Usage fails to become durable, or customers reveal a need that the current option cannot support.
Financial trigger: Consumption pricing, operating cost, or internal staffing moves outside the approved economic envelope.
Technical trigger: Integration maintenance, API limits, reliability, or roadmap mismatch begins delaying important releases.
Risk trigger: Data handling, retention, auditability, model governance, or regulatory obligations can no longer be met.
Strategic trigger: A previously generic layer begins creating proprietary data, workflow advantage, or meaningful differentiation.
Capacity trigger: The internal team can no longer sustain the operational burden, or gains the maturity needed to own a capability previously bought.
Assign an owner and a review event to each trigger. Without ownership, continuous re-evaluation becomes a good intention that loses to roadmap pressure. The decision memo should remain a living control surface for product, engineering, finance, security, and procurement, not an artifact filed after approval.
Do not neglect activation. Whether you build or buy, budget for workflow changes, onboarding, in-app guidance, support preparation, and measurement. Deployment creates availability. Repeated successful use creates value.
Key takeaways
Decompose an AI experience into layers before deciding who should own it.
Build differentiated or control-critical layers; buy parity where a vendor can accelerate activated value.
Compare both choices across time to value and total ownership cost using the same scope and service expectations.
Apply non-negotiable gates before a weighted scorecard, then test both options against common acceptance cases.
Own the data, policies, evaluation evidence, and migration path that protect your future leverage.
Use staged commitments and prewritten triggers so changing the decision becomes responsible management, not an admission of failure.
The next time this question reaches your roadmap review, do not ask for a permanent verdict on build or buy. Ask for a capability map, comparable evidence, an operational owner, a tested exit path, and the conditions that would change the answer. That gives you a decision you can defend now without mortgaging your ability to adapt later.