
Every week, product and data leaders ask me the same question: can AI agents truly shoulder enterprise analytics without sacrificing trust, governance, or speed? I’ve spent the past year putting agentic AI through its paces in real product workflows, and I’ve distilled what works into a practical, task-driven evaluation approach you can adopt immediately.
Learn how to evaluate AI analytics agents with a task-based framework across analytics tasks. See how Amplitude’s Global Agent scores.
When I say “enterprise analytics,” I’m talking about far more than chatty dashboards. The bar includes consistent metric definitions, privacy-by-design, RBAC and data governance, audit trails, low-latency decision support, and repeatable outcomes across retention analysis, funnels, cohorts, A/B testing, instrumentation planning, and anomaly detection—ideally within a unified analytics platform.
My task-based framework evaluates eight capability pillars I expect from an enterprise-ready Agent Analytics solution: task coverage and depth across common product analytics workflows; data fidelity and governance (lineage, access controls, PII handling); instruction-following and reasoning transparency; evaluation rigor and reliability (repeatability, error modes, regressions); security and compliance posture; latency and cost efficiency; integration into existing product strategy workflows (e.g., CRM integration, CI/CD-linked instrumentation, experiment platforms); and human-in-the-loop controls for approvals and guardrails.
Operationally, I define canonical tasks that reflect day-to-day product management: codify a North Star metric; perform retention analysis by cohort; generate and explain a funnel with drop-off drivers; recommend an event taxonomy and tracking plan; analyze an A/B test with minimum detectable effect (MDE) considerations; and propose a driver tree that maps inputs to outcomes. Each task comes with ground-truth datasets, acceptance criteria, and edge cases to stress the agent—an eval-driven development practice I’ve found indispensable.
I then score maturity across four levels. L0: a pure chat UI that summarizes existing charts. L1: a retrieval-first pipeline that grounds responses in your analytics catalog and metric store. L2: a tool-using agent that is schema-aware, can write safe SQL, and reconciles results to canonical definitions. L3: a governance-aware autonomous workflow that executes analytics tasks end-to-end with approvals, audit logs, feature flags, and rollback plans. Most teams discover they’re between L1 and L2; reaching L3 requires serious investment in data governance and eval automation.
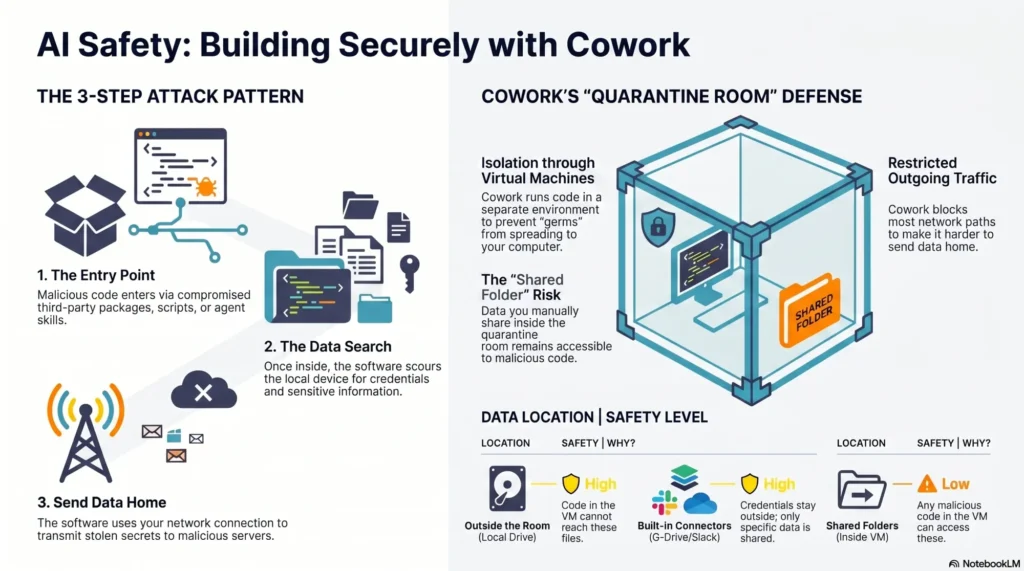
Risk management is non-negotiable. I require strict data governance and privacy-by-design controls, including scoped credentials, PII redaction, policy-aware retrieval, and comprehensive observability (query traces, prompt/response logs, lineage). Feature flags and approval gates prevent unintended metric redefinitions. Red-teaming tasks expose prompt injection, schema drift, and hallucination failure modes before they hit production stakeholders.
Where do agents shine today? Rapid exploration, SQL generation from schema context, summarizing experimentation results, and turning natural-language questions into actionable charts. Where do they struggle? Ambiguous metric semantics, under-specified experiment designs, and edge-case-heavy analyses where ground truth depends on organizational nuance. The cure is disciplined product management: codify definitions, maintain a living analytics taxonomy, and continuously harden your eval suite.
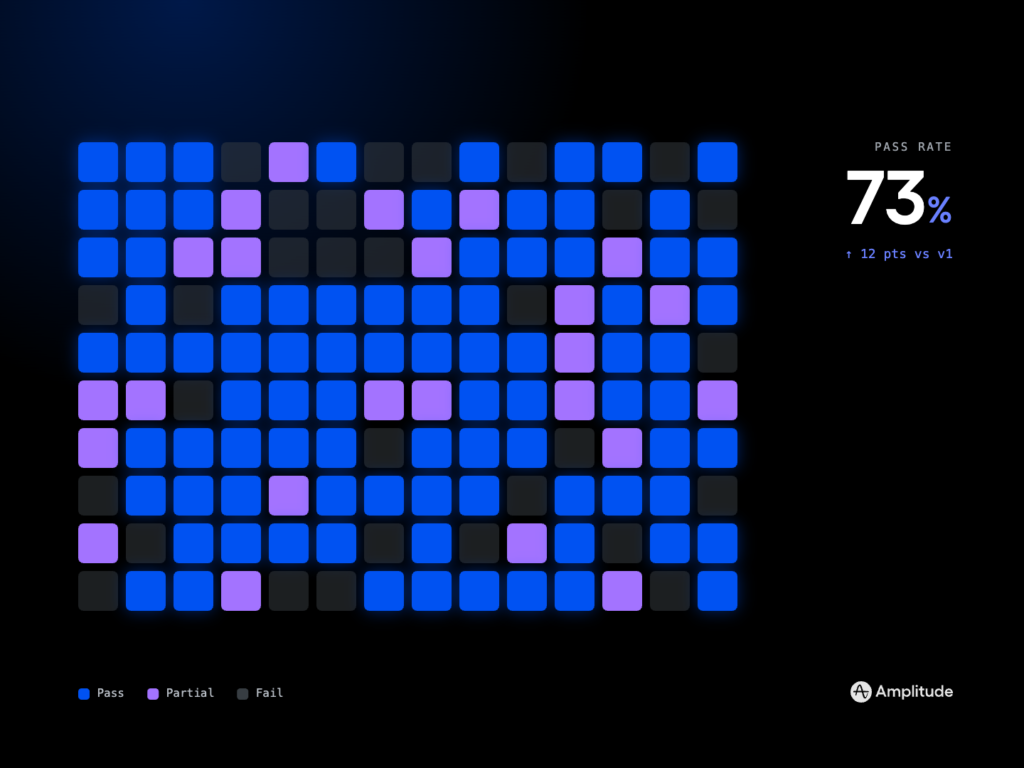
In the context of product analytics stacks, Amplitude analytics is a common anchor for product teams, and many are evaluating “Amplitude’s Global Agent” to accelerate insight generation. In my framework, I look for how well it grounds to canonical metrics, handles retention and funnel tasks, explains trade-offs, and respects governance boundaries—before I consider expanded autonomy. I share the full task matrix and scoring rubric so you can replicate the assessment in your environment.
If you’re getting started, pick your top ten high-frequency analytics tasks and define crisp success metrics for each (accuracy, explainability, latency, and reusability). Build a small eval harness with golden datasets, assertions, and regression tests. Favor a retrieval-first pipeline tied to your taxonomy and metric store, add human-in-the-loop approvals for sensitive actions, then pilot with a cross-functional tiger team. Measure time-to-insight, analyst hours saved, and stakeholder trust—then iterate.
Enterprise analytics isn’t a single feature; it’s a system of definitions, workflows, and governance. With a task-based, eval-driven approach, agentic AI can become a reliable partner—not just a novel interface. If you’re evaluating options, apply this framework first, then expand scope as reliability and trust climb.
Inspired by this post on Amplitude – Best Practices.







Leave a Reply