
We open-sourced our AI Skills library. Here's what we built, why we built it, and how to use it. I’m sharing the approach we’ve used to move faster with more confidence across product discovery, prototyping, and production—while keeping governance, safety, and measurement front and center.
What we built is a modular, open-source library of “skills” for agentic AI and LLM-powered workflows—things like retrieval and grounding, summarization, classification, tool-use, data enrichment, safety guardrails, and evaluation harnesses. Each skill follows consistent interfaces and conventions so teams can compose them like building blocks, swap implementations without breaking flows, and standardize best practices across products.
Why we built it is simple: we kept rebuilding the same core capabilities across experiments and teams. Standardizing these skills accelerates time-to-value, reduces integration risk, and helps product trios collaborate with a common language. It also lets us scale what works—prompt patterns, eval datasets, telemetry—so every new initiative starts on third base instead of at bat.
How to use it in practice: start by running a quick-start example to see a baseline skill chain in action. Then compose your own flow by selecting skills (for example, retrieval + summarization + tool call), configure them with environment variables and guardrails, and wire in evaluation datasets. From there, instrument the pipeline with metrics so you can compare variants and promote the best-performing chain to your main app or API.
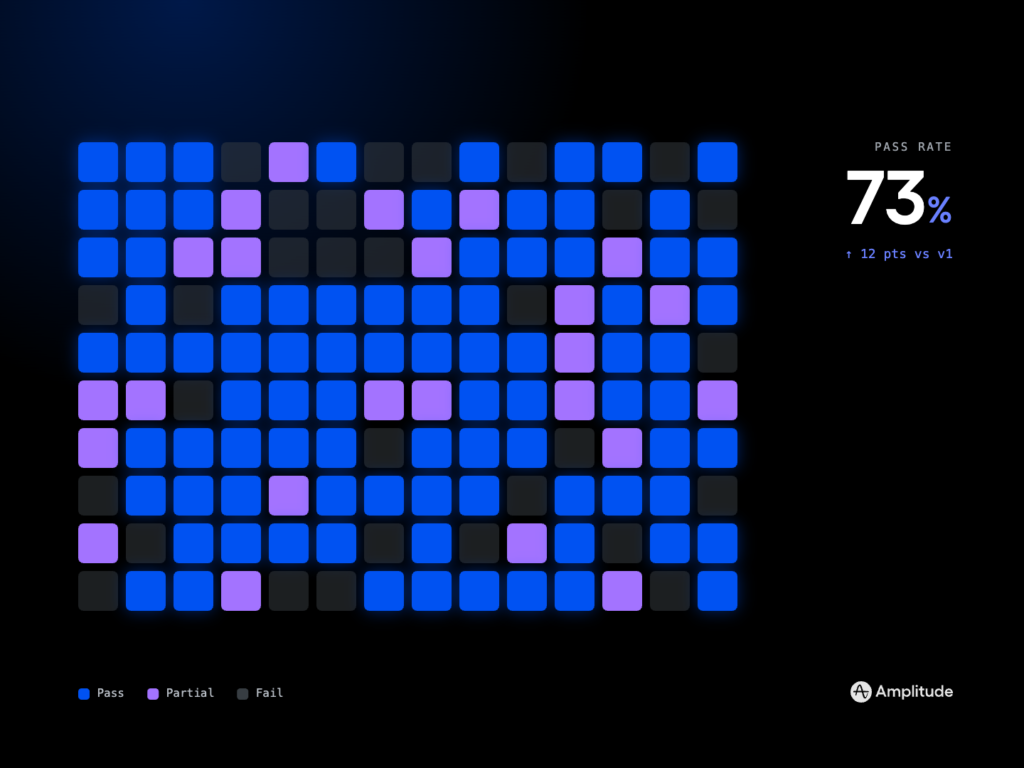
In a typical stack, the library dovetails with analytics and experimentation: ship skill variants behind feature flags, measure impact with A/B testing, and observe runtime behavior with logs and traces. CI/CD hooks let you run evals pre-merge, and production dashboards keep an eye on latency, cost, and outcome quality. This creates a virtuous loop where ideas move from prototype to production with clear evidence.
Common use cases include customer support summarization and triage, lead scoring and enrichment, anomaly detection in product telemetry, and automated content workflows. Because the skills are composable, you can try multiple retrieval-first strategies, swap prompt templates, or add tools (search, RAG, calculators, connectors) without rewriting everything from scratch.
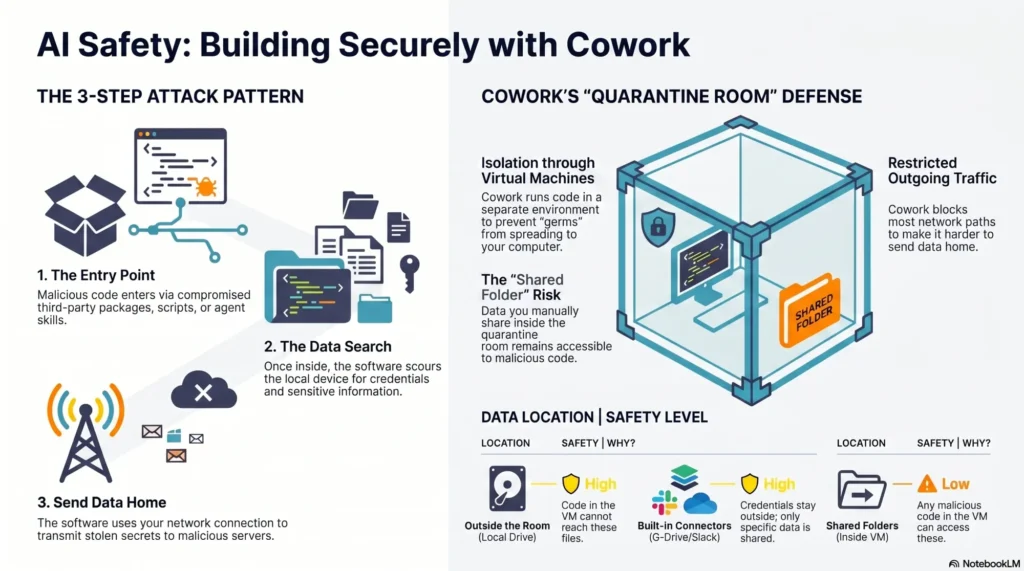
Governance and safety are built in. Guardrails handle PII redaction, content policy checks, and rate limiting; configs make it easy to enforce privacy-by-design; and evaluation harnesses encourage an eval-driven development culture. The result is faster iteration without sacrificing data governance or reliability.
If you want to contribute, add a new skill, improve prompts, share eval datasets, or open an issue with a scenario you want supported. The roadmap focuses on richer retrieval adapters, better test fixtures, and deeper observability so teams can debug and optimize complex chains with confidence.
I’m excited to see how you’ll use the library to accelerate your roadmap. Clone it, run a quick start, and compose your first workflow today—then measure, iterate, and scale what works. I’ll keep sharing patterns, learnings, and updates as we grow the skills catalog and sharpen the tooling.
Inspired by this post on Amplitude – Perspectives.







Leave a Reply