
When people ask me about "LLM vs AI Agents: What Product Teams Must Get Right," I start with a simple truth: an LLM is a powerful prediction engine, while an AI agent is a productized workflow that plans, takes actions with tools, remembers, and closes the loop on an outcome. That difference sounds academic until you’re on the hook for reliability, cost, and customer trust.
In my role, I’ve shipped LLM copilots that delight users and piloted agents that automate complex workflows. The pattern that never fails is this: start assistive, then graduate to autonomy. Copilots accelerate people; agents own outcomes. When we respect that gradient, adoption climbs, incidents fall, and we earn the right to expand scope.
The first decision point is use-case fit. If the task benefits from human judgment, high-context nuance, or brand voice, I frame it as a copilot with strong guardrails and crisp UX. If the task is well-bounded, tool-heavy, and verify‑able, I consider an agent—but only after we can measure end‑to‑end task success with eval-driven development.
Architecture matters. I reach for a retrieval-first pipeline to keep responses grounded in authoritative data, then add tool use for actions (search, write, schedule, transact) with deterministic scaffolding to prevent thrashing. Good prompt engineering is table stakes, but context window management and a clean memory strategy (short‑term scratchpad, long‑term facts, and policy) separate demos from durable systems.
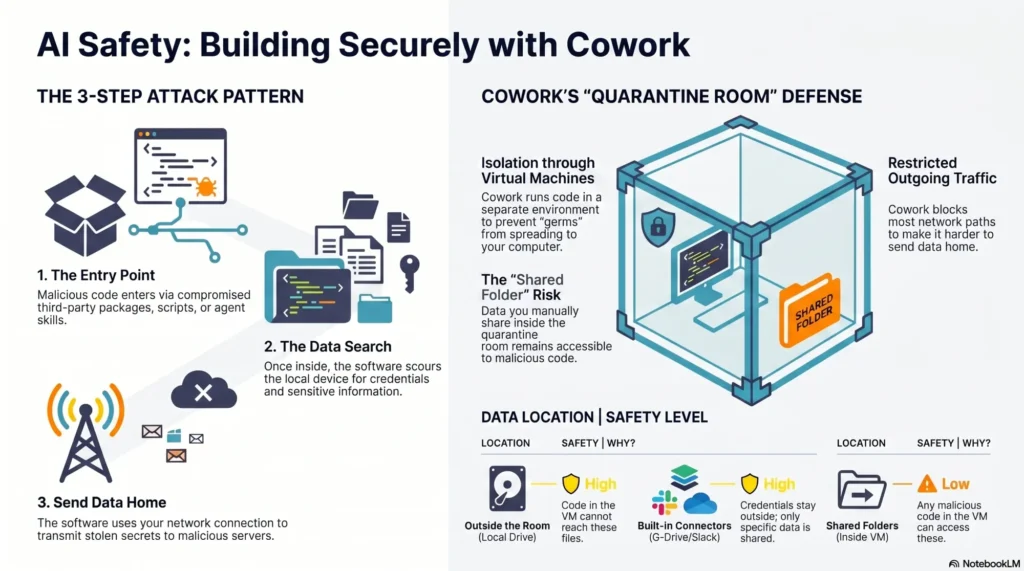
Agents amplify both value and risk. I build safety in layers: role and scope definition, tool whitelists, unit limits, human‑in‑the‑loop checkpoints at irreversible steps, and privacy-by-design data governance. We log every decision token-for-token because auditability isn’t optional once agents touch customers, money, or data.
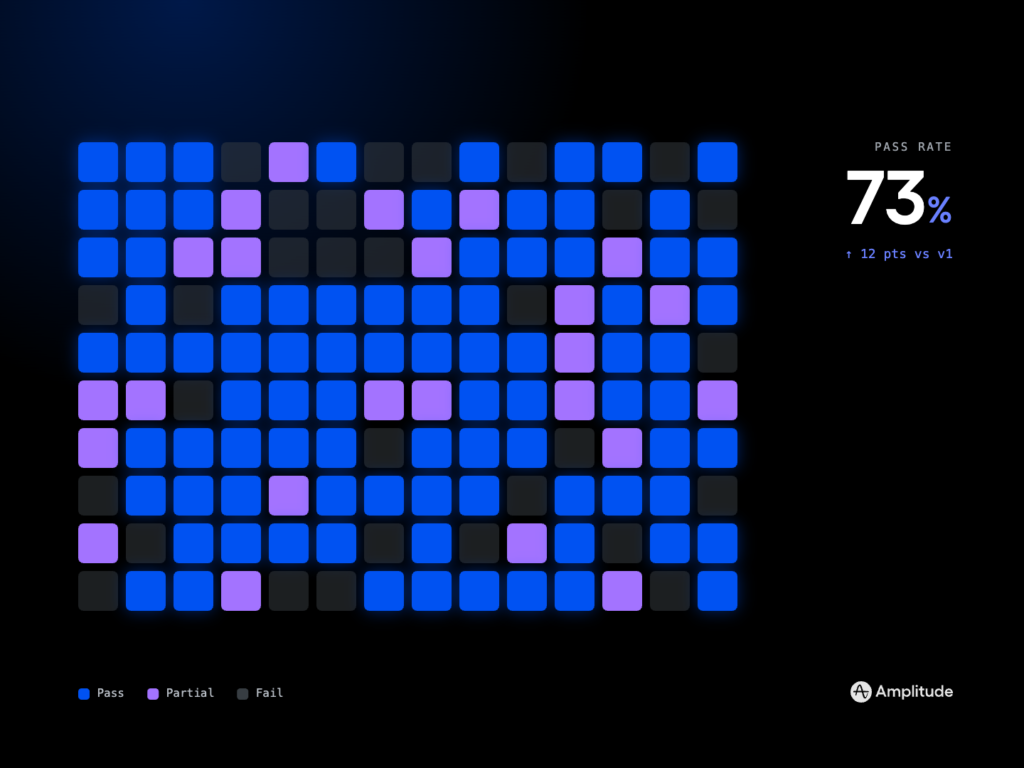
Measurement is non‑negotiable. For LLM features, I track time‑to‑first‑token, response latency, groundedness, and user satisfaction. For agents, I add Agent Analytics: task success rate, number of steps per task, tool error rate, loop detection, guardrail triggers, escalation to human, cost per successful task, and containment rate. If we can’t see it, we can’t ship it.
My delivery playbook mirrors modern software ops. We use feature flags, gated betas, and canary rollouts; we version prompts like code; we set incident management paths for model outages and tool drift; and we rehearse fallbacks so the experience degrades gracefully, not catastrophically. Dull operations build dazzling products.
On roadmapping, I thin‑slice value. We introduce a minimal viable copilot that handles a single, frequent job-to-be-done with high success. Only after continuous discovery confirms product‑market fit do we grant more autonomy, one capability at a time. Outcomes vs output OKRs keep us honest: if the customer’s job gets done faster, cheaper, and with fewer errors, we scale; if not, we fix fundamentals before adding scope.
Build vs buy is rarely binary. I tend to buy the undifferentiated heavy lifting—observability, prompt versioning, red‑teaming, and policy enforcement—while building the proprietary workflows, data modeling, and UX that encode our defensible advantage. The litmus test: if it’s part of our unique value proposition, we own it; if not, we integrate the best‑in‑class and move.
Go‑to‑market must be as rigorous as the tech. We position clearly (assistant vs agent), price to value with transparent consumption SaaS pricing, and communicate risk posture in plain language. Customers don’t buy models; they buy confidence that a job gets done reliably within their constraints.
Common failure modes repeat: shipping autonomy before instrumentation, treating prompts as magic instead of software, skipping data governance, and ignoring the human experience. The antidote is disciplined AI Strategy rooted in empowered product teams, tight feedback loops, and relentless evaluation.
If you take nothing else: choose the right paradigm for the job (copilot first, agent when proven), ground with a retrieval-first pipeline, instrument with eval-driven development and Agent Analytics, and operationalize like a mission‑critical system. Do that, and you’ll turn LLM capabilities into durable product outcomes.
Inspired by this post on Product School.







Leave a Reply