
In my role leading product, I’ve learned that the fastest path to higher-quality deliverables from large language models (LLMs) is not a clever prompt—it’s rigorous context. I call the practice AI context pulling: a repeatable way to assemble, compress, and structure the most relevant knowledge before the model ever starts generating. Done well, it turns generative AI into a dependable partner for discovery, prioritization, and execution.
AI context pulling means I proactively gather the right artifacts (customer insights, analytics, strategy, constraints), manage context windows intentionally, and shape the model’s task with clear objectives and guardrails. This reduces hallucinations, improves alignment, and creates traceability back to sources—critical for product management leadership and stakeholder trust.
Learn a new way in which product professionals can collaborate with AI to get even better results on their projects.
Here’s the simple flow I use: first, I define the intent (e.g., “synthesize discovery interviews for a positioning brief”). Next, I inventory relevant context: top customer pains from product discovery, usage patterns from Amplitude analytics, recent support trends from Intercom, and any constraints from our product strategy. Then I run a retrieval-first pipeline to select only the most pertinent slices—favoring recency, representativeness, and canonical sources.
Because context window management matters, I compress long documents into short, source-cited summaries and keep raw excerpts handy when nuance is important. My prompts follow a consistent structure: role and objective, constraints and audience, curated context, the explicit ask, preferred output format, and a brief self-check (e.g., “cite sources and flag uncertainty”). This is prompt engineering for reliability, not theatrics.
A quick example: when drafting a one-page feature brief, I attach three items—the product strategy paragraph that sets the frame, a usage cohort analysis that highlights who’s affected, and five verbatim customer quotes. I ask the LLM to propose a problem statement, success criteria, and a shortlist of solution hypotheses, each tied to a cited piece of evidence. The result is a grounded, decision-ready artifact I can share with product trios and stakeholders.
Tooling-wise, I keep it pragmatic. A lightweight retrieval-first pipeline (embeddings, metadata filters, and recency rules) ensures the LLM pulls what matters. I version prompts and contexts together so I can run quick A/B testing on output quality. And I log decisions and sources to support eval-driven development and continuous discovery.
Common pitfalls are avoidable. Too little context yields generic answers; too much overwhelms the model. Stale docs can mislead; curate aggressively. Vague asks invite fluffy prose; specify outcomes, audiences, and formats. If the task is high risk, I bias toward smaller, well-cited outputs and expand iteratively with human review in the loop.
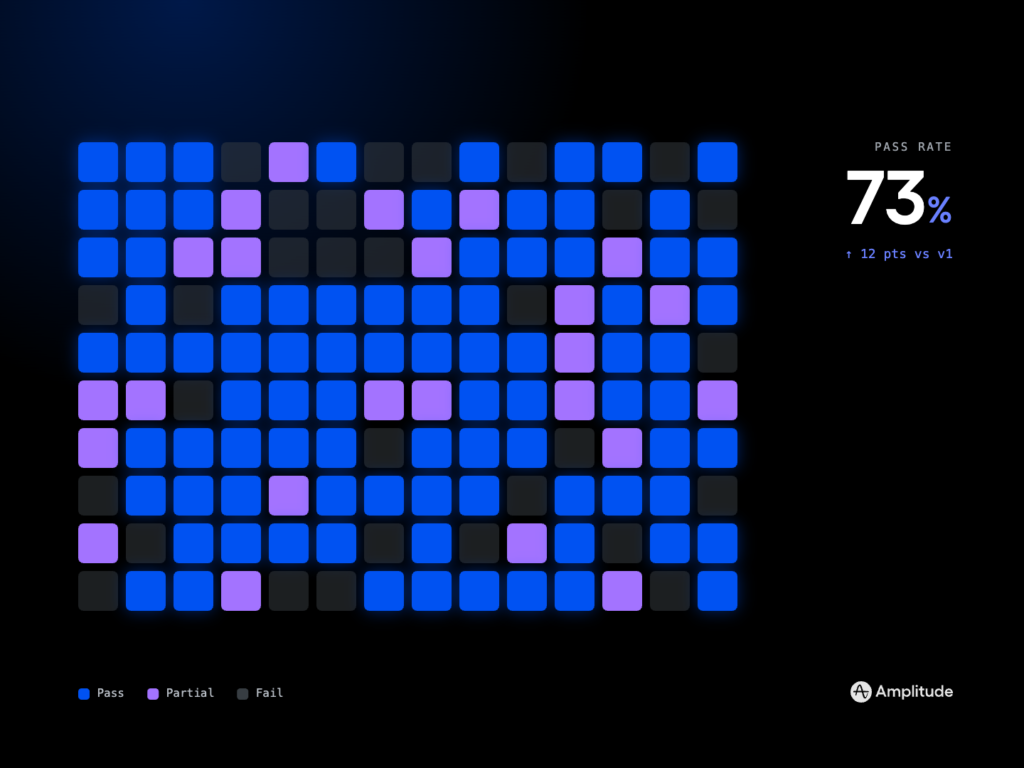
To measure impact, I track rework rate, review time, and stakeholder alignment on first pass. Over time, teams adopting AI context pulling report clearer artifacts, faster synthesis cycles, and more confident decisions—because every recommendation traces back to evidence. That’s how humans and LLMs truly collaborate better: we provide the right context, and the model amplifies our judgment.
If you’re ready to operationalize this, start by templatizing your most common product workflows—discovery synthesis, roadmap rationale, and release notes—and attach small, high-signal context packs. With a retrieval-first mindset and disciplined prompting, AI becomes an extension of your product craft, not a gamble.
Inspired by this post on Pendo – Perspectives.







Leave a Reply