
I’ve learned that the fastest path to durable AI impact is a disciplined experimentation engine: one that moves quickly, reduces ambiguity, and earns trust with evidence. My goal isn’t just to ship models—it’s to ship measurable outcomes with repeatable rigor.
AI experimentation for product teams. Here’s how to test AI features, choose the right metrics, handle variability, and make data-driven decisions.
I start every AI initiative by framing a clear decision: what must be true for this feature to be worth building, and how will we know quickly? From there, I map driver trees that connect user value to measurable signals, so every test clarifies both impact and risk, not just accuracy.
Success criteria come next. I translate aspirations into testable thresholds, define leading and lagging indicators, and size tests with minimum detectable effect (MDE) so we don’t confuse noise for signal. This keeps us honest about sample sizes, power, and the real cost of waiting for certainty.
Before I touch production traffic, I run eval-driven development. I curate golden datasets that reflect real user complexity, codify rubrics for correctness, safety, tone, and latency, and automate scoring so improvements are reproducible—not anecdotal. This gives the team a stable baseline to iterate prompts, tools, and policies with confidence.
Model behavior is inherently stochastic, so I deliberately control variability. I document temperature, top-p, and seed strategies; I compare deterministic settings for regression checks versus sampled settings for user-facing creativity; and I test sensitivity across content lengths and edge cases. This reduces flakiness and prevents surprise regressions during CI/CD.
When it’s time to learn from real users, I favor A/B testing with thoughtful guardrails. I run holdouts, cap exposure with feature flags, and protect core experience metrics like retention and time-to-value. For ranking and retrieval changes, I’ll use interleaving or switchback tests to isolate effects from seasonality and traffic mix.
To handle LLM variability online, I aggregate outcomes over multiple prompts per cohort, use stratified bucketing to balance power users and new accounts, and track confidence intervals over time instead of snapshot p-values. This approach turns noisy model outputs into stable product signals.
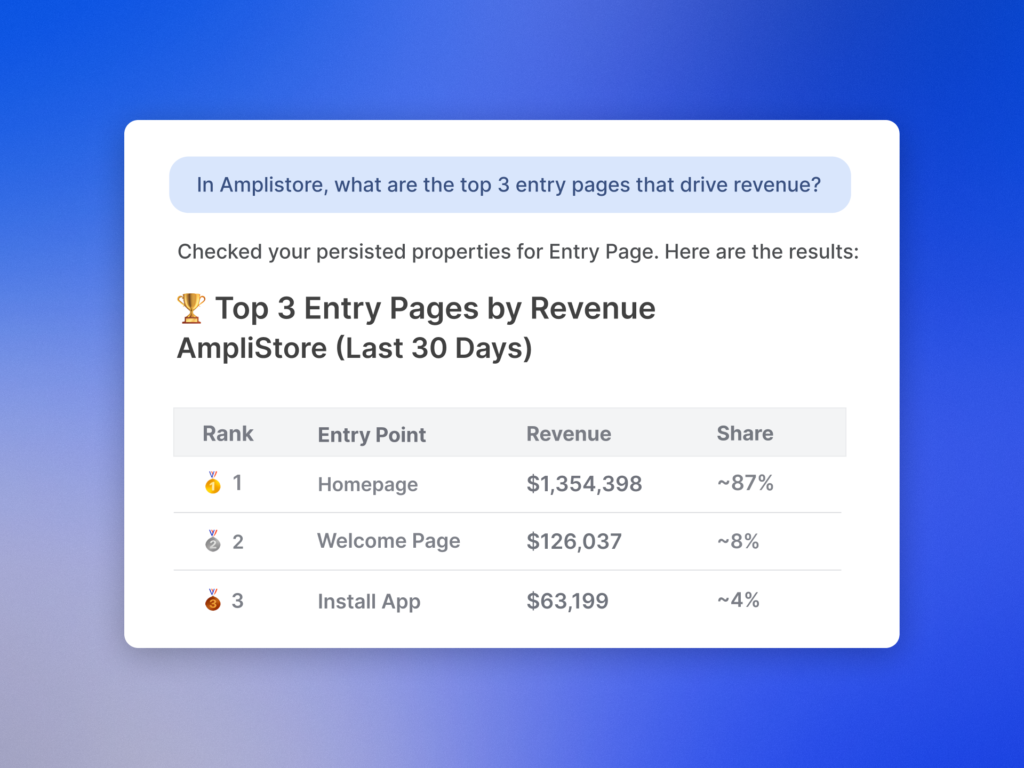
Instrumentation fuels everything. I rely on behavioral analytics to trace user intent, effort, and satisfaction across flows, and I wire up Amplitude analytics for event schemas, funnel drop-offs, and cohort comparisons. Clear event taxonomies and naming discipline make it trivial to separate model quality from UX friction.
Risk is part of the work, so I bake in AI risk management early. I include toxicity and PII checks in my offline evals, monitor safety metrics in every A/B, and set rollback criteria tied to user harm and system costs. Privacy-by-design, audit logs, and runtime safeguards aren’t afterthoughts—they’re acceptance criteria.
The operating cadence matters as much as the math. I run continuous discovery with customer interviews to keep the test queue grounded in real jobs-to-be-done, and I align product trios on hypotheses, success metrics, and stop-loss rules before launch. Weekly readouts keep decisions crisp, and post-ship learning cycles feed the next iteration.
Finally, I invest in upskilling the team. We run internal workshops on LLMs for product managers, standardize experiment templates, and maintain a living playbook so new experiments start at 80% instead of 0%. The result: faster learning loops, safer bets, and more confident shipping.
Inspired by this post on Product School.









Leave a Reply