
I keep meeting talented product teams who can demo impressive proof-of-concepts but can’t get durable business impact into production. The difference isn’t raw ingenuity—it’s the operating model. As I’ve scaled AI initiatives in my own organization, one sentence has proven painfully accurate: "What the top 1% of AI-native product teams are doing differently – and why most won't catch up without rebuilding the operating model."
When I say “AI operating model,” I mean the end-to-end way we set strategy, discover value, build, ship, govern, and learn—specifically adapted for AI systems. If we try to bolt AI onto a classic software cadence, we stall. If we rebuild our operating model around AI’s unique constraints and compounding advantages, we accelerate.
It starts with strategy. I anchor our portfolio to explicit outcomes, not features—tying every initiative to measurable customer and commercial impact. Driver trees and an opportunity solution tree make tradeoffs transparent, while outcomes vs output OKRs prevent us from celebrating activity over results. This is how empowered product teams earn autonomy without losing alignment on the AI Strategy.
Next is discovery. Continuous discovery reframes “can we ship a model?” into “can we change a behavior or decision with acceptable risk?” I pair customer interviews with in-product telemetry and journey mapping to qualify moments of high value and high frequency. The litmus test: can we describe the target workflow in plain language and simulate success before training models? If not, we’re not ready.
Data foundations come third. A retrieval-first pipeline is now my default, not an afterthought. We invest in data governance, privacy-by-design, and observability so we can explain where answers come from, prove consent, and debug drift. Without trustworthy data and clear lineage, every downstream AI promise is fragile—and your AI readiness is mostly theater.
Then I insist on eval-driven development. Before we optimize prompts or tune models, we define offline and online evals that represent the real task, including safety and “gotcha” cases. We treat prompt engineering, context window management, and agentic AI patterns as hypotheses that must beat a baseline under repeatable tests. This moves debate from opinions to evidence.
Shipping is where most teams quietly stall. We integrate AI into our CI/CD with feature flags, shadow modes, and progressive rollouts, building MLOps into the same platform that runs our services. I watch DORA metrics to keep delivery velocity healthy, but I also watch AI-specific signals—input distribution shifts, response variance, and time-to-mitigation—so we catch regressions before customers do. Platform scalability matters more when inference costs and latency can spike overnight.
Governance isn’t a gate at the end; it’s a runway from the start. We operationalize AI risk management with tiered reviews, model and data cards, and clear escalation paths. The goal is not to slow down, but to reduce surprise—so product managers, engineers, and legal share the same playbook for safety, fairness, and regulatory compliance.
Value capture closes the loop. We connect product metrics to commercial levers like Net Recurring Revenue (NRR) and retention analysis, then shape packaging so customers pay for outcomes, not raw compute. This is where product-led growth meets sales-led growth: we demonstrate value in-product, then arm go-to-market teams with unambiguous proof.
So why are 80% of teams stuck? Three patterns recur: technology FOMO masquerading as strategy, fragmented data that can’t support high-quality retrieval, and a lack of evals that forces decisions by vibes. Add ad hoc governance and you get pilots that impress in slides but wither under real-world variance.
How do the top 1% think differently? They rebuild the operating model first. They position discovery around workflows, not models. They invest in retrieval-first architectures early. They standardize evals. They ship with guardrails. And they treat “learning per week” as a sacred metric—because compounding insight beats sporadic heroics.
If you need a 90-day plan, here’s the sequence I use. Week 1–2: run a content audit of data sources and map the top five repeatable workflows ripe for AI leverage. Week 3–4: define success metrics and offline evals for one beachhead use case. Week 5–8: build the retrieval pipeline, implement prompt baselines, and instrument observability. Week 9–12: ship behind feature flags, run A/B testing with safety thresholds, and iterate on failure cases. By the end, you’ll have a reusable blueprint—not just a demo.
Team design matters. I staff product trios (PM, design, tech lead) with forward deployed engineers or solutions engineering partners who sit with customers. That proximity reduces spec ambiguity and accelerates learning. It also sharpens our product roadmapping and sprint planning because we plan against outcomes, not outputs.
The hardest part is emotional, not technical: letting go of familiar software rituals that don’t serve AI. Once we accept that AI demands a different operating rhythm, progress feels lighter. The top 1% don’t have secret models; they have disciplined systems. Rebuild yours, and the compounding benefits will outpace any single model upgrade.
Inspired by this post on Product School.


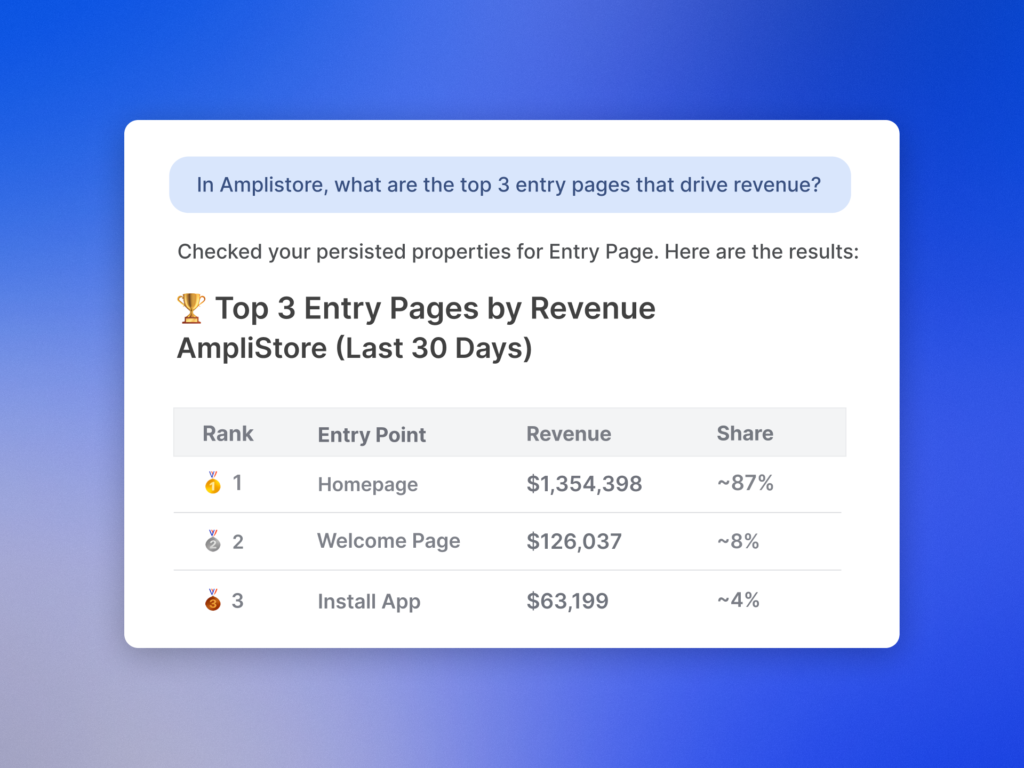




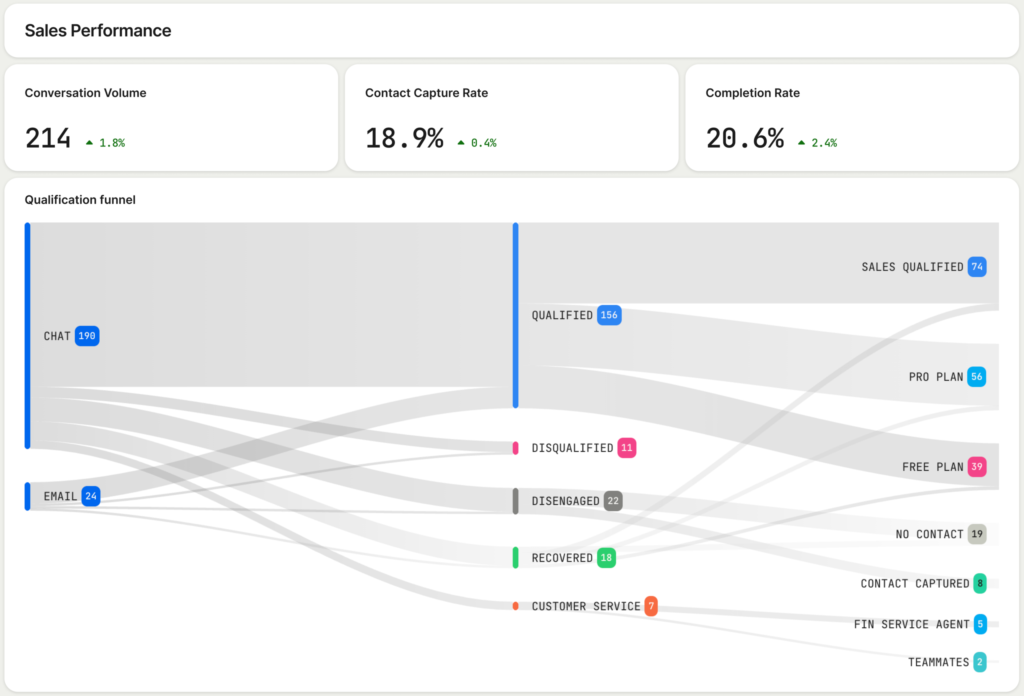

Leave a Reply