
Every week, I coach product and documentation teams on a simple truth I keep pinned above my desk: "AI is reading your documentation! Learn tips from the Amplitude docs team about how to structure your documentation for both human and AI audiences." That line captures the shift we’re all living through—our docs must now serve customers, support engineers, and increasingly, LLMs powering chat, search, and in‑product help.
My AI strategy for documentation starts with intent. I map the core questions users ask at activation, onboarding, escalation, and renewal, then shape information architecture to reduce ambiguity. This helps humans find answers faster and helps LLMs retrieve the right chunks with higher precision—a win for UX writing, product-led growth, and support deflection.
Structure beats style when AI is in the loop. I rely on semantic headings (H1–H3), consistent slugs, stable anchors, and one‑topic pages that can stand alone. Short paragraphs, scannable summaries, and canonical references reduce duplication and improve retrieval quality. Treat docs-as-code with CI/CD so changes are reviewed, versioned, and shipped reliably—documentation deserves the same rigor as product releases.
Chunking matters for LLMs. I design content for context window management: one concept per section, tight procedures with numbered steps, and FAQs that mirror real queries. Glossaries define canonical terms and accepted synonyms so retrieval-first pipelines match user language without fragmenting meaning. Error messages and parameter names appear verbatim to strengthen search and grounding.
Metadata is a multiplier. I add clear titles, descriptions, last‑updated dates, product area tags, and audience labels (admin, developer, analyst) to boost SEO and machine readability. Stable IDs for components, examples, and API objects improve deep linking and evaluation. Where appropriate, I include structured examples that align with prompt engineering best practices so AI assistants can extract inputs, outputs, and constraints cleanly.
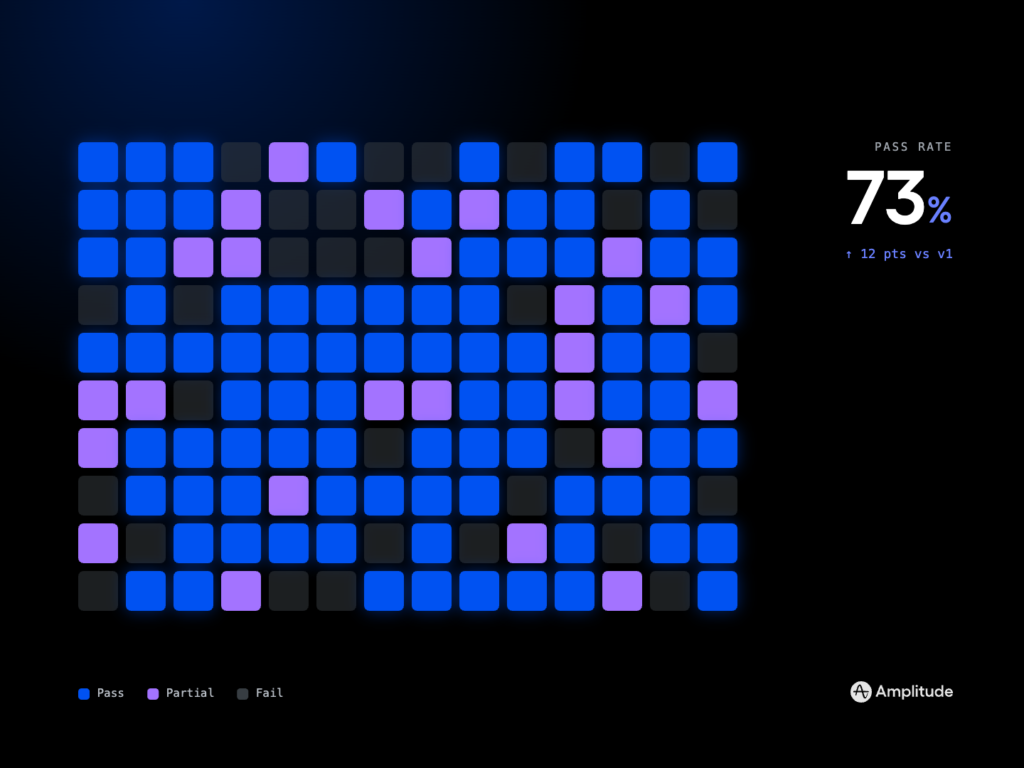
Quality is measured, not hoped for. I pair content audit checklists with analytics to see what’s searched, where users pogo‑stick, and which articles drive successful task completion. Tools like Amplitude analytics reveal gaps and dead‑ends, while lightweight evals (answer accuracy, grounding rate, latency) ensure LLMs retrieve the right doc chunks at the right time.
Consistency is a feature. I standardize terminology across UI, API, and docs, and I avoid synonym sprawl that confuses both readers and LLMs. Page intros state the job-to-be-done; conclusions link to adjacent tasks; and deprecation notes are explicit with forward paths. This coherence lowers cognitive load and improves both RAG performance and human trust.
Governance keeps it scalable. I assign owners per section, define SLAs for updates, and automate checks for broken links, orphaned pages, and outdated screenshots. Redirect rules avoid 404s, and version banners prevent LLMs from mixing deprecated guidance into current answers—small details that cumulatively protect customer experience.
If you’re just getting started, begin with three moves: clarify intents, restructure pages into atomic, linkable units, and add metadata that reflects how customers actually search. From there, tighten your retrieval-first pipeline and run regular evals. The payoff is durable: faster time to value for users, lower support load, and AI assistants that answer accurately, confidently, and consistently.
Inspired by this post on Amplitude – Perspectives.







Leave a Reply