
I remember the exact moment our product crossed the threshold from scripted automation to truly agentic AI. The excitement was real—so was the pit in my stomach when our dashboards went dark. Our trusted analytics and observability stack, which had served us flawlessly for traditional software, suddenly couldn’t explain what the agent was doing, why it made certain choices, or how to reproduce outcomes across runs.
"The moment our product became a AI agent, our entire observability stack became irrelevant—not something you want as an analytics company. Here's what we did."
Why does this happen? Agentic AI doesn’t behave like conventional apps. Instead of deterministic flows and neatly tagged events, we face non-deterministic trajectories, tool-use chains, evolving prompts, context window dynamics, and policy guardrails that influence outcomes in real time. Clicks and pageviews give way to tokens, tool calls, and conversation turns. Without purpose-built observability, you can’t do credible product discovery, measure behavioral analytics, or run eval-driven development with confidence.
That’s why we built Agent Analytics. We needed a unified lens to trace every step of an AI workflow—from user intent to model prompts, function calls, retrievals, tool outputs, and final responses—while capturing latency, cost, guardrail hits, fallbacks, and outcome tags. We instrumented runs end-to-end, added experiment support for prompt engineering and policy variants, and wired in evaluations so we could turn subjective quality into objective signals the team could act on.
The impact on product management was immediate. We shortened iteration cycles by making failure states obvious and reproducible, turned ambiguous feedback into structured data, and gave engineers and designers a shared source of truth for conversation design and AI workflows. With visibility into containment, escalation, autonomy ratio, and step-level success, we could ship confidently, rollback safely, and align roadmap bets to measurable outcomes—not anecdotes.
Building this capability demanded more than logging. We invested in data governance and privacy-by-design to mask sensitive content while preserving semantic context, and we separated human-identifiable data from model telemetry. We treated prompts and policies like code—versioned, diffable, and safely rolled out behind feature flags and CI/CD—so we could experiment without risking regressions in production.
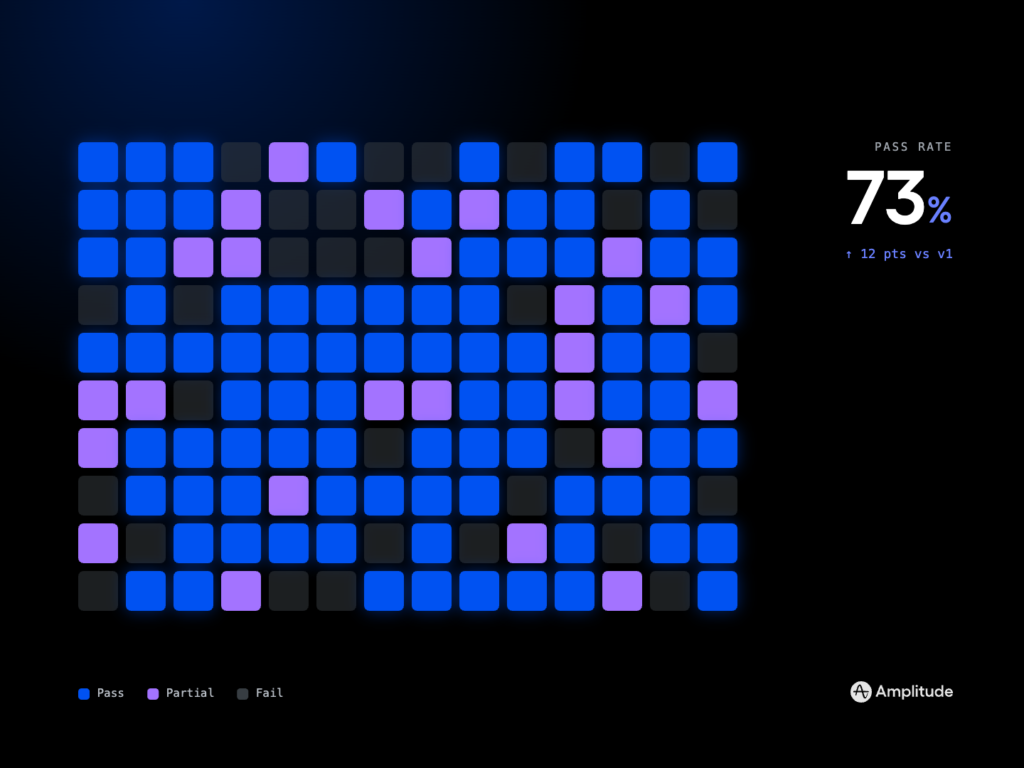
What should every team measure? Start with outcome quality (task success, resolution, containment), reliability (tool success rate, guardrail triggers, fallbacks), performance (time-to-first-token, total latency, step-level latency), and efficiency (tokens and cost per successful task). Add groundedness checks for retrieval steps, regression evals for core journeys, and post-release anomaly detection to catch drift before users do. These metrics become your operating system for agent performance and your compass for product strategy.
If you’re building or scaling AI agents, you need Agent Analytics before you hit your first incident. It’s the difference between guessing and knowing—between reactive firefighting and proactive iteration. With the right observability, your team can move faster, manage risk intelligently, and translate agent behavior into business outcomes that compound over time.
Inspired by this post on Amplitude – Best Practices.







Leave a Reply