
"The best AI products improve more through context engineering than prompt tinkering." I’ve seen this play out repeatedly in high-stakes, enterprise use cases: substantive gains come from how we curate, structure, and deliver context to models—not from wordsmithing. When we started treating context as a product surface, performance climbed, hallucinations dropped, and teams shipped with more confidence.
Here are four key decisions we made to improve our AI context.
First, we moved to a retrieval-first pipeline. We unified trusted sources—CRM records, support knowledge bases, product telemetry, and governance-approved docs—behind hybrid retrieval (semantic + keyword) with strong metadata ranking. This let us constrain generations to verifiable facts, apply privacy-by-design rules at the edge, and practice disciplined context window management so every token carried its weight. Freshness policies, source-level confidence scores, and lightweight schemas kept the system precise and auditable.
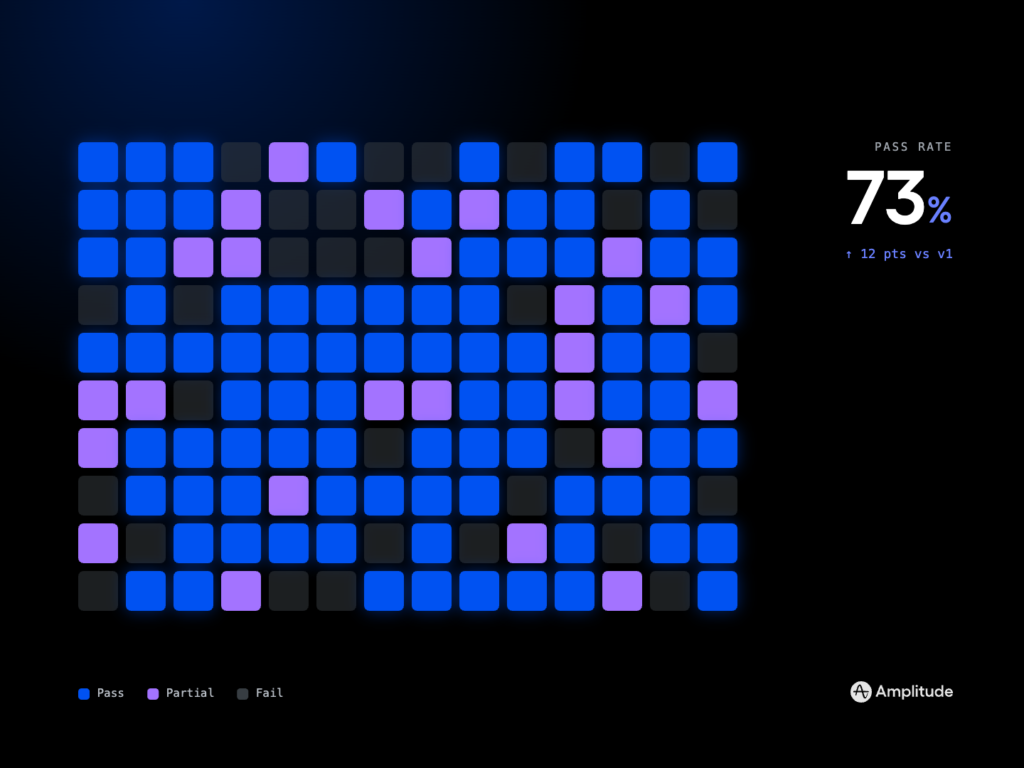
Second, we made eval-driven development non-negotiable. Every change to context assembly goes through offline evals and online A/B testing with clear acceptance thresholds (e.g., task success, groundedness, time-to-first-answer, and deflection rate). We sized tests with minimum detectable effect (MDE) and tied them to outcomes vs output OKRs so we weren’t just shipping more prompts—we were shipping measurable improvements that mattered to customers.
Third, we personalized context based on intent and role. We built AI workflows that detect user intent, segment by persona, and dynamically assemble context: recent account activity for customer success, policy-safe excerpts for finance, and fine-grained reasoning chains for product teams. For conversational and voice AI agent experiences, we combined short-term conversation memory with scoped, long-term account memory to preserve relevance without bloating the prompt. This agentic AI pattern ensured faster, safer, and more helpful responses.
Fourth, we operationalized context as a first-class platform capability. We invested in data governance (ownership, lineage, and redaction), instrumentation (Amplitude analytics for usage, retrieval hit rates, and failure modes), and CI/CD guardrails for context updates. Product trios partnered with SRE to monitor drift, while side-by-side comparisons and human-in-the-loop reviews turned frontline feedback into structured improvements. The result: a durable system that improves continuously instead of relying on one-off prompt tweaks.
Context engineering isn’t glamorous, but it compounds. By prioritizing retrieval-first design, rigorous evaluation, intent-aware assembly, and operational excellence, we transformed our AI features into dependable, enterprise-ready capabilities. If you’re serious about LLMs for product managers and sustainable AI Strategy, shift your energy from clever prompts to robust context—and watch adoption and trust follow.
Inspired by this post on Amplitude – Perspectives.







Leave a Reply