
AI agents are quickly moving from novelty to necessity, and the fastest way to capture value is to approach them like any other high-stakes product initiative. In this guide, I share how I plan, build, and launch production-grade agents with a product mindset—balancing ambition with risk, speed with governance, and innovation with measurable outcomes.
I start by getting crisp on the outcome. Who is the primary user, what job are they hiring the agent to do, and how will we know it’s working? I translate this into outcomes vs output OKRs, such as resolution rate, time-to-value, cost-to-serve, or qualified pipeline influenced—anchoring the roadmap before a single line of code or prompt is written.
Next, I map the agent’s scope and boundaries. I write a simple capability canvas: the tasks the agent must perform, the tools it can use, the data it can access, and the constraints it must respect. Most successful builds follow a retrieval-first pipeline: connect trusted knowledge sources, enrich with metadata, and manage a lean context window to keep responses relevant and cost-efficient. From the start, I bake in privacy-by-design, data governance, and AI risk management so compliance isn’t an afterthought.
Model selection comes after the workflow is clear. I choose an LLM for the job (latency, cost, multilingual needs, and tool-use fidelity) and pair it with the right connectors and actions—think CRM integration, ticketing, search, or internal APIs. For voice experiences, I define a voice AI agent persona, turn-taking rules, and barge-in behavior. This is where agentic AI patterns shine: structured planning, tool invocation, and verification loops create a resilient, goal-directed system.
Prompt design is product design. I write system prompts that define role, tone, constraints, data sources, and success criteria. I add few-shot examples that mirror my top use cases and edge cases, then apply prompt engineering best practices to control style, limit speculation, and encourage citations. For voice, I include prompt engineering for voice to optimize brevity, warmth, and disfluency handling without sacrificing accuracy.
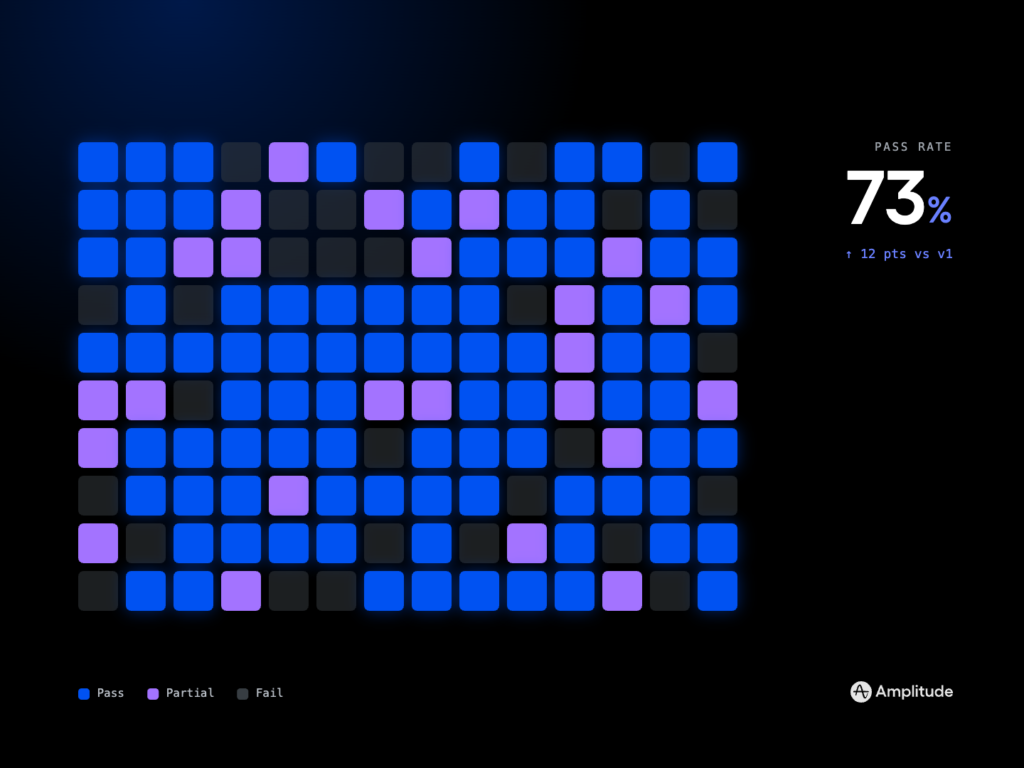
Before launch, I build an eval-driven development workflow. I curate golden datasets from real user intents, add adversarial cases, and automate evals for accuracy, safety, grounding, and tool-use success. I set a minimum detectable effect (MDE) so A/B testing can validate improvements with confidence, and I define go/no-go thresholds to prevent regression. This becomes my continuous discovery loop for the agent.
Instrumentation is non-negotiable. I wire up Agent Analytics to track task success, containment/deflection rate, handoff quality, cost per task, and user satisfaction. I supplement with a unified analytics platform and session replays to observe failure patterns. These signals feed prioritization and help me decide when to expand scope versus harden reliability.
For delivery, I rely on CI/CD with feature flags to gate risky capabilities, plus canary releases for new tools and prompts. I monitor DORA metrics to maintain deployment frequency without trading off quality. When incidents happen, I treat them like production issues: incident management playbooks, rollbacks, and clear postmortems.
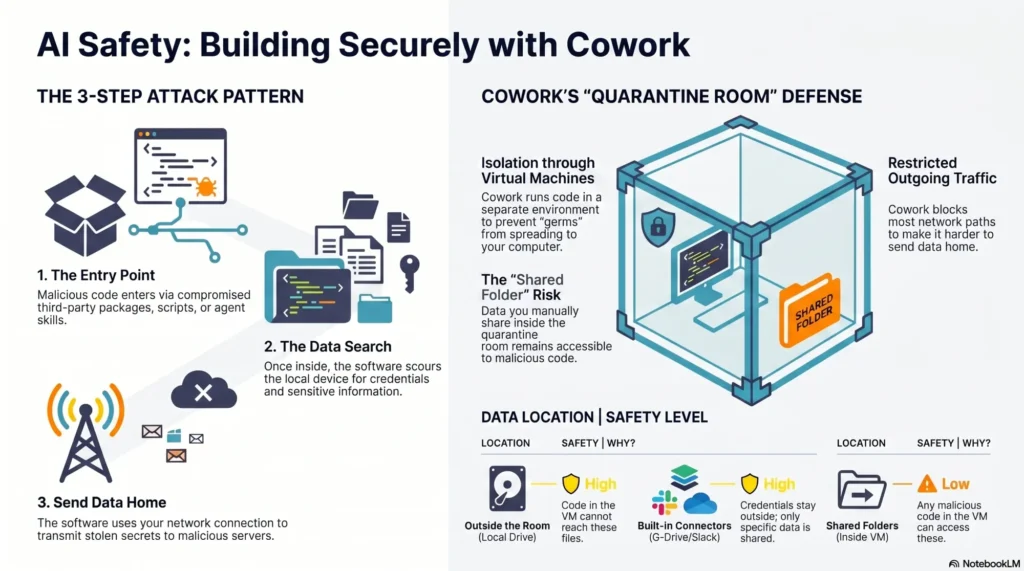
Trust is earned through safety and transparency. I enforce least-privilege access, structured logging, and red-teaming for jailbreaks, prompt injection, and data exfiltration. Threat detection and response plus clear user disclosures keep the experience responsible and compliant with regulatory requirements.
GTM is product-led. I use in-app guides, product tours, and onboarding checklists to drive user activation and early wins. I define success moments, turn them into habit loops, and run retention analysis to find where users stall. This tight loop of messaging, measurement, and iteration accelerates product-market fit.
Common high-ROI use cases I prioritize include customer support ai strategy (automated resolution and augmented agent assist), sales and success workflows (lead qualification, QBR prep), and internal knowledge copilots (policy, process, engineering runbooks). Each starts narrow, ships fast, and scales with proven evidence from analytics and experiments.
If you’re skimming, here’s the blueprint: clarify outcomes, design AI workflows with a retrieval-first pipeline, select the right LLM and tools, engineer robust prompts, institutionalize evals and A/B testing, instrument Agent Analytics, ship with CI/CD and feature flags, and iterate with discipline. In the walkthrough video above, I go deeper on templates, prompts, and experiments you can use to build your first agent with confidence.
Inspired by this post on Product School.







Leave a Reply