
Scaling AI Visibility pushed me to rethink what “reliable” really means for AI infrastructure. As my team expanded usage across more datasets, models, and workflows, we uncovered unexpected sources of report failure and built the guardrails, observability, and processes that now anchor our stability strategy.
In practice, the surprising failure modes were rarely the loud ones. We saw report failure triggered by small schema drift from non-deterministic LLM outputs, silent permission changes in upstream data sources, token-limit truncation that broke downstream parsing, third-party API rate limits that surfaced only under bursty load, and clock skew that confused idempotent writes. Individually these issues looked minor; together they created reliability debt.
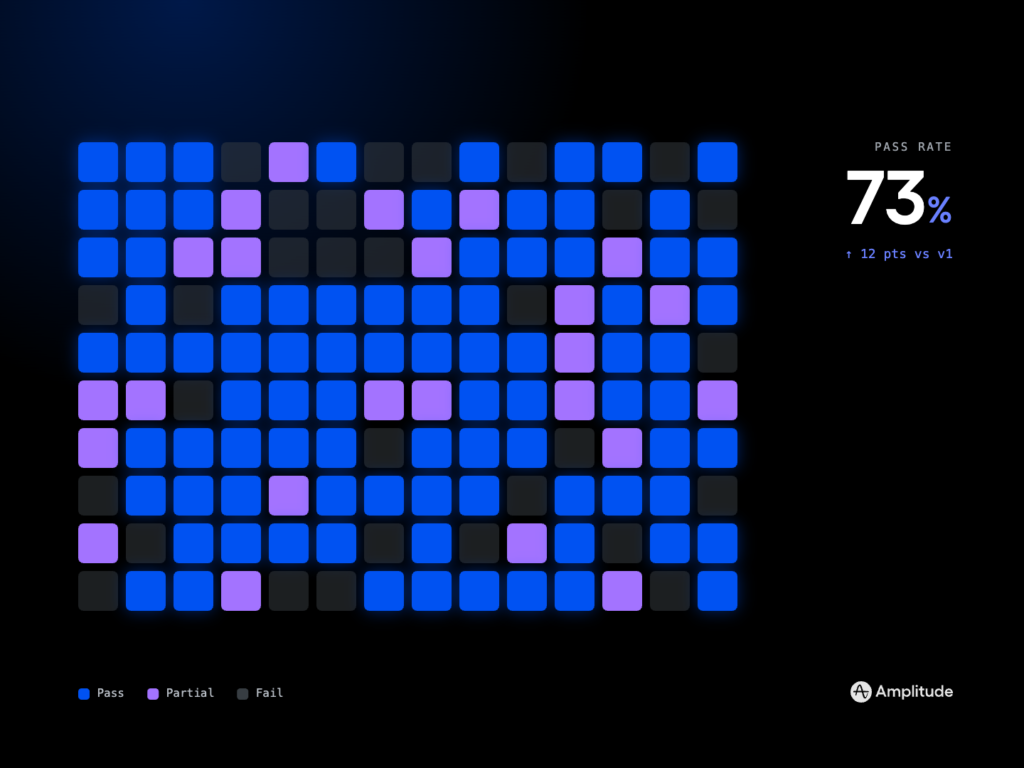
Our first move was deep observability. We instrumented the end-to-end pipeline with structured logs, distributed tracing, and high-signal metrics mapped to SLOs and error budgets. That visibility let us separate symptom from cause, quantify impact by segment, and prioritize fixes that moved business outcomes, not just vanity thresholds. It also gave product managers and SREs a shared, real-time view to make tradeoffs explicit.
Next, we hardened the runtime with resilience patterns: circuit breakers on flaky dependencies, timeouts tuned to p95 behavior, retries with jittered backoff, idempotent processing for at-least-once delivery, and backpressure-aware queues. We enforced schema contracts at ingestion with JSON validation and added feature flags to decouple deploys from releases, so we could roll forward or back within minutes when signals degraded.
On the product side, we adopted eval-driven development for model and prompt changes, shifting risky modifications behind canaries and staged rollouts. CI/CD gates required evaluation baselines to hold or improve before promotion. We tracked DORA metrics to keep deployment frequency high without sacrificing change failure rate, and we used P95 latency and budget burn as the forcing functions for prioritization.
Culture mattered as much as code. We formalized incident management with clear ownership, lightweight runbooks, and blameless reviews that produced crisp, automatable actions. We partnered early with SRE on SLO design, integrated privacy-by-design and PII scanning into the pipeline, and treated AI risk management as an ongoing product constraint rather than a checkbox.
The net effect: fewer flaky reports, faster recovery when things do break, and far more confidence to ship improvements to AI Visibility at pace. If you’re scaling similar capabilities, start with observability, make resilience patterns non-negotiable, and let SLOs guide your product roadmap. Reliability is not a phase—it’s the product.
Inspired by this post on Amplitude – Best Practices.







Leave a Reply