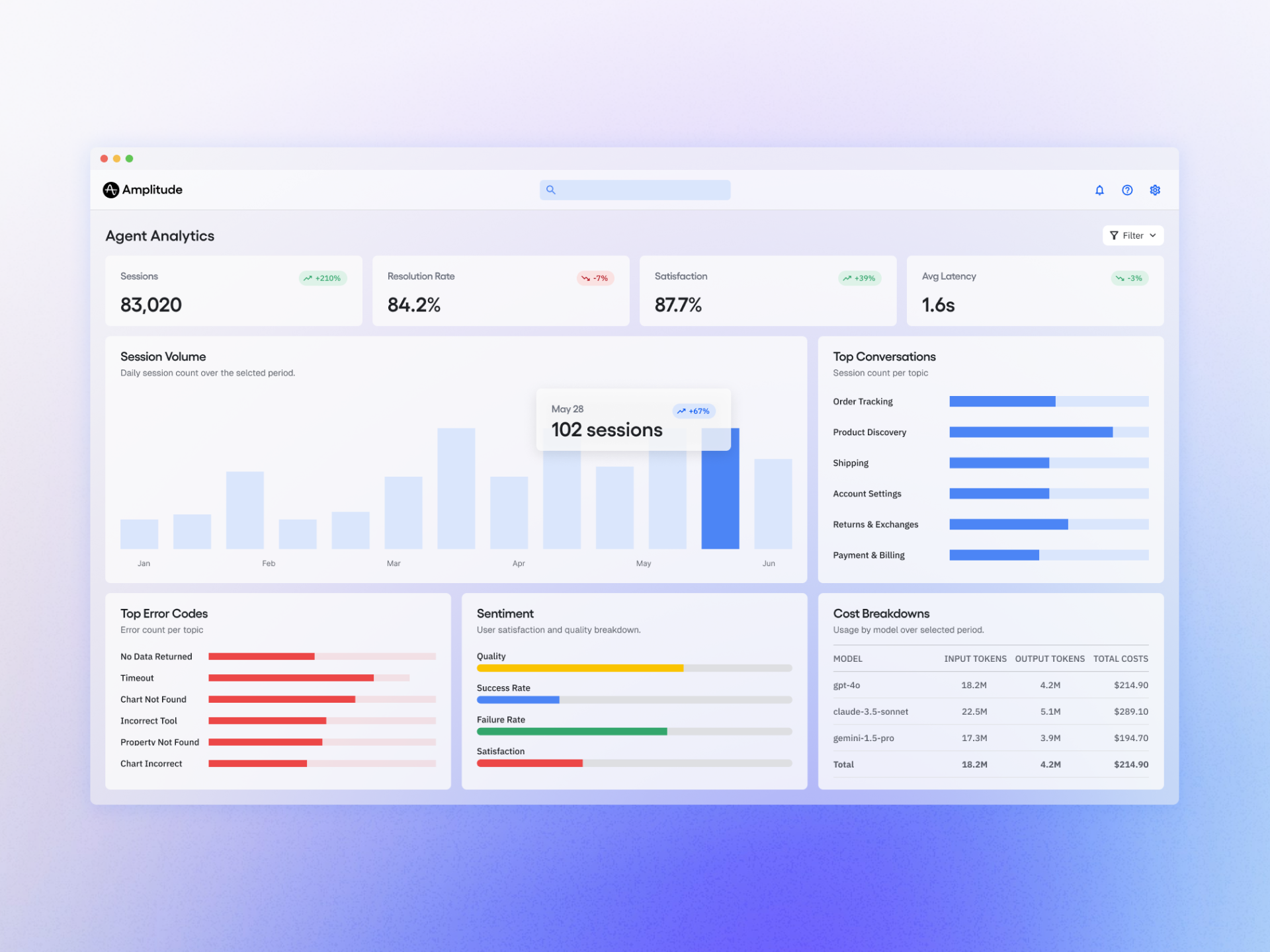
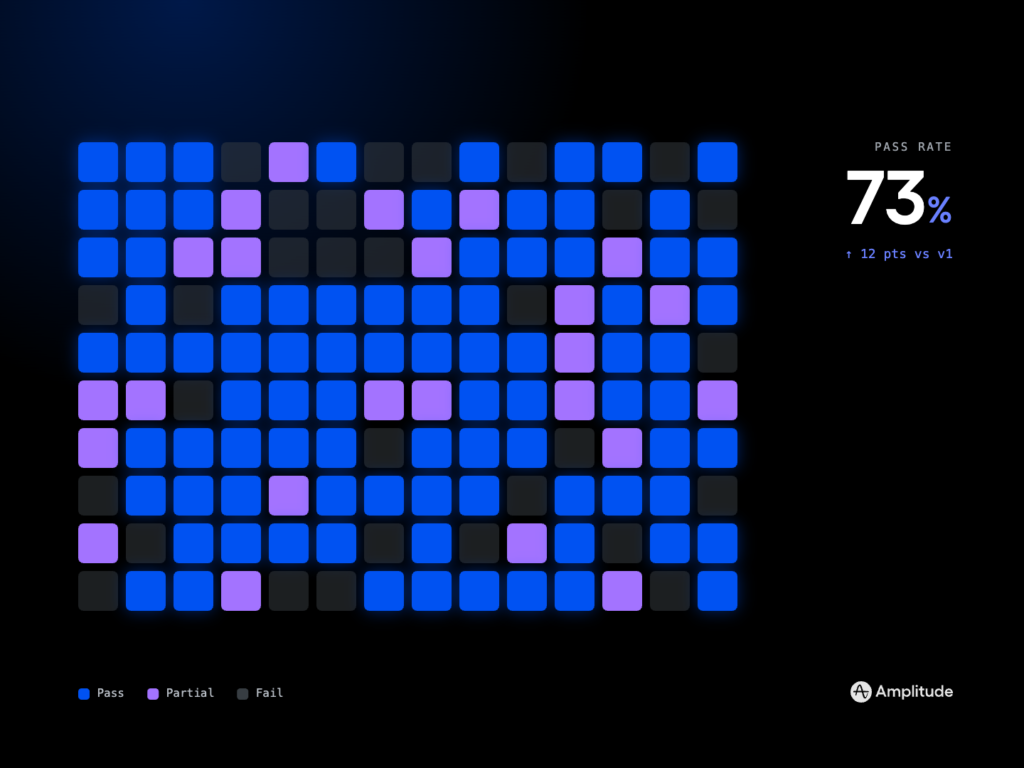
Over the past quarter, I’ve been obsessed with a simple question: how do real people actually prompt AI agents when the stakes are high and the clock is ticking? We analyzed 27K sessions with Amplitude's Global Agent using our Agent Analytics tool. Here's what we found out about how real users are prompting our agent. That single line belies months of careful instrumenting, qualitative review, and product debates—and it forever changed how I design agent experiences.
The clearest pattern I saw: users don’t craft “perfect” prompts—they co-create with the agent. Most sessions began with a broad intent, then tightened through rapid, iterative turns. The winning structure emerged as context, command, and constraints. When our agent acknowledged context first, clarified the command, and reflected constraints back, users responded with noticeably more confidence. It reinforced what great prompt engineering already teaches, but grounded in lived behavior across thousands of journeys.
Trust was the next breakthrough. People wanted transparency on capabilities, a concise first answer, and an easy path to deeper detail and sources. They frequently asked the agent to show its work, summarize trade-offs, or restate assumptions in plain language. Instrumenting observability into the agent’s reasoning artifacts—without overwhelming the user—proved foundational for building credibility session by session.
On task complexity, users fared best when the agent orchestrated a few small, verifiable steps rather than one heroic leap. Retrieval-first pipeline patterns consistently reduced confusion and rework, especially when paired with strong context window management. The more the agent proactively chunked the problem, validated intermediate outputs, and offered next-best actions, the smoother the journey—and the more reusable the prompts became.
UX nudges mattered as much as model quality. Inline examples (“Try this”), one-click refinements (“Shorter,” “Add a table,” “Cite sources”), and lightweight guardrails kept momentum high without boxing users in. When the agent made uncertainty explicit and offered safe fallbacks, abandonment dropped and users explored more ambitiously. The experience felt less like “querying a model” and more like collaborating with a capable teammate.
From a product management lens, these insights shape how I prioritize agentic AI. I’m doubling down on: scaffolded prompts that lead with context and constraints; transparent citations and assumptions; multi-step plans that the user can edit; and evaluation loops that A/B test prompt templates, tool strategies, and response formats. I’m also investing in analytics that connect session patterns to activation, speed-to-value, and retention so we can run eval-driven development, not opinion-driven debates.
If you’re building agents into a core product workflow, start by designing for iterative co-creation, not one-shot brilliance. Offer progressive disclosure, keep the first answer tight, and make verification effortless. Shape the model with retrieval-first strategies, manage your context window like a scarce resource, and treat observability as a feature, not a debug tool. Most of all, let real usage guide your roadmap—these 27K sessions reminded me that the best agent UX is learned alongside our users, not imagined in isolation.
Inspired by this post on Amplitude – Perspectives.







Leave a Reply