
AI has changed the tempo of product management, but not the timeless fundamentals. I’m living that paradox daily: the technology reshapes how we plan, build, and ship—yet the way we find real customer value hasn’t budged. Here’s how I reconcile both truths in practice.
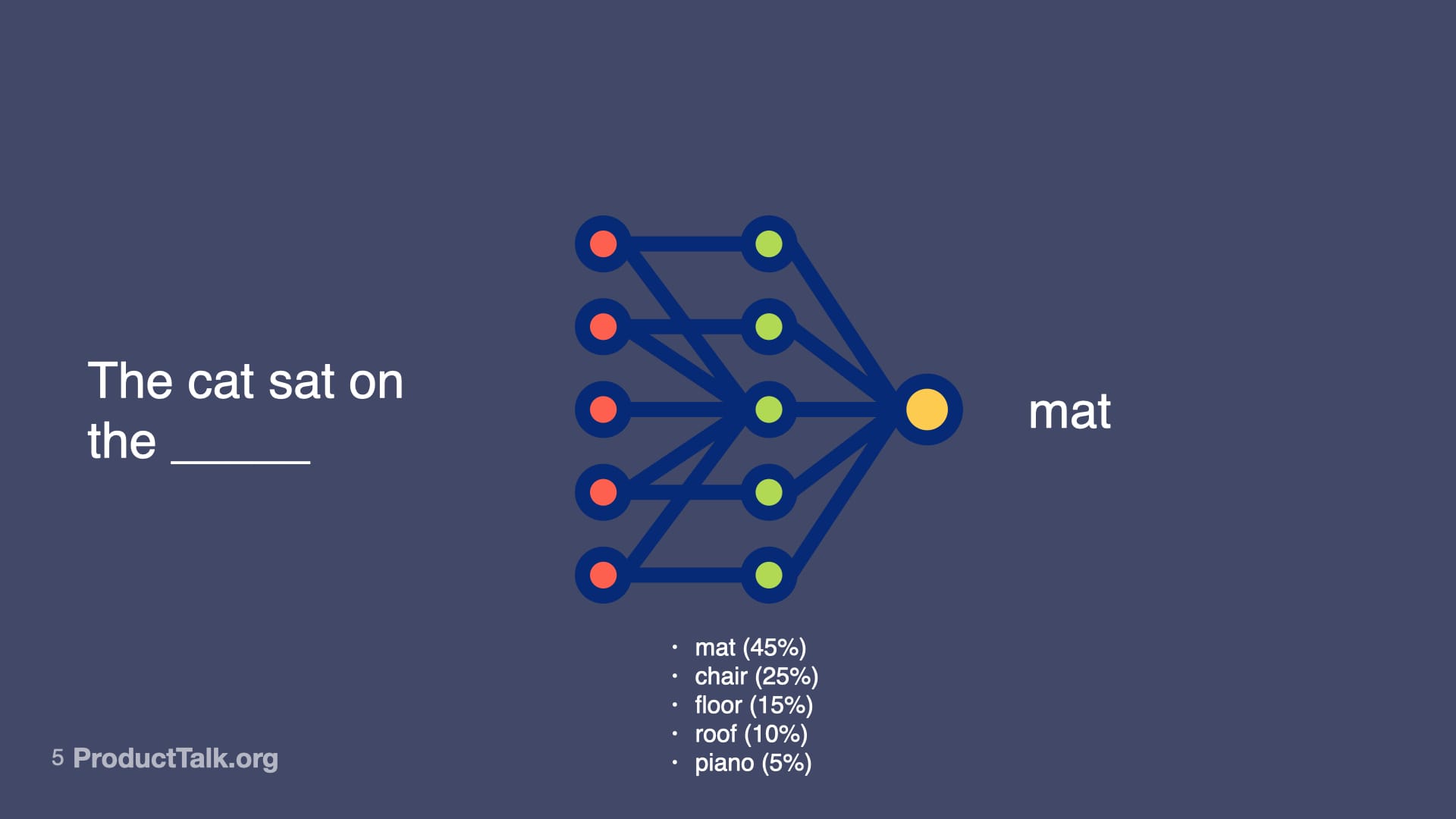
At their core, large language models predict the next token. That’s it. Consider the prompt, “The cat sat on the ____.” Mat is most likely. Chair is pretty likely. Floor, roof, piano—all possible, just less probable. When you give an LLM a prompt, it runs through a neural network—billions of parameters making calculations—to predict the most likely next word, then the next, then the next. That neural net represents not just facts, but relationships, patterns, context—and some might even argue reasoning capabilities—that all influence the probabilities of different outputs. So LLMs don’t just predict the next token. They predict the next token by drawing upon a vast amount of knowledge. LLMs are transformational.

And yet, AI makes silly mistakes. The kind that make you wonder how it could be so smart and so dumb at the same time. No matter how hard I tried, I could not get ChatGPT-5 to fix the closing quote on an image. And it took 12 seconds of thinking to figure out that I asked for a meeting summary but didn’t include any meeting notes. Why do LLMs make these mistakes? Well, it’s because all the LLM is doing is predicting the next token based on patterns. And sometimes those predictions are wrong. And when it’s wrong, it can be confidently wrong. So what do we do?

To build reliable AI features, I focus my team on four core skills: prompt engineering, context engineering, orchestration, and evaluation (evals). Together, they let us harness what’s powerful about generative AI while reducing unforced errors.
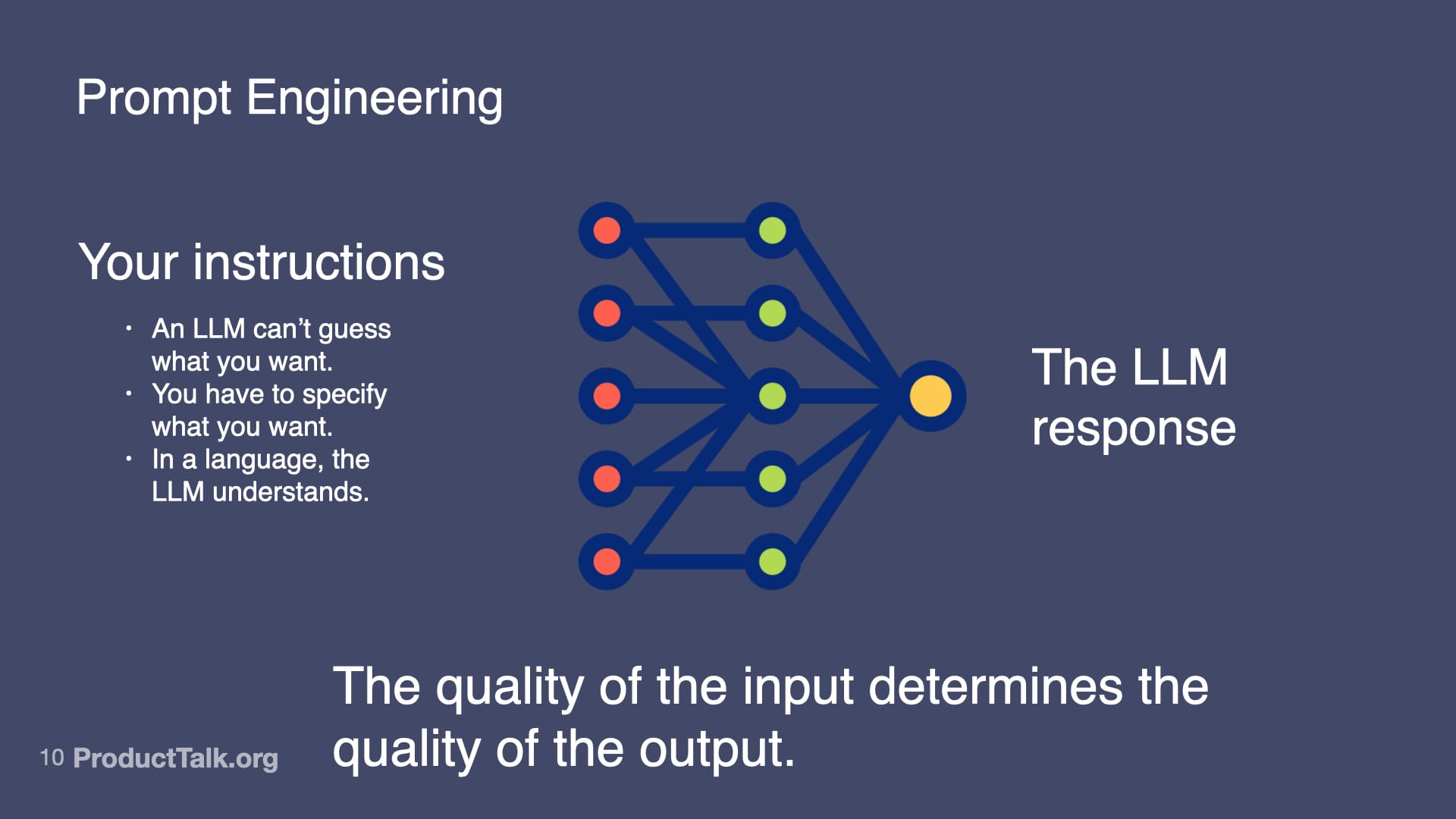
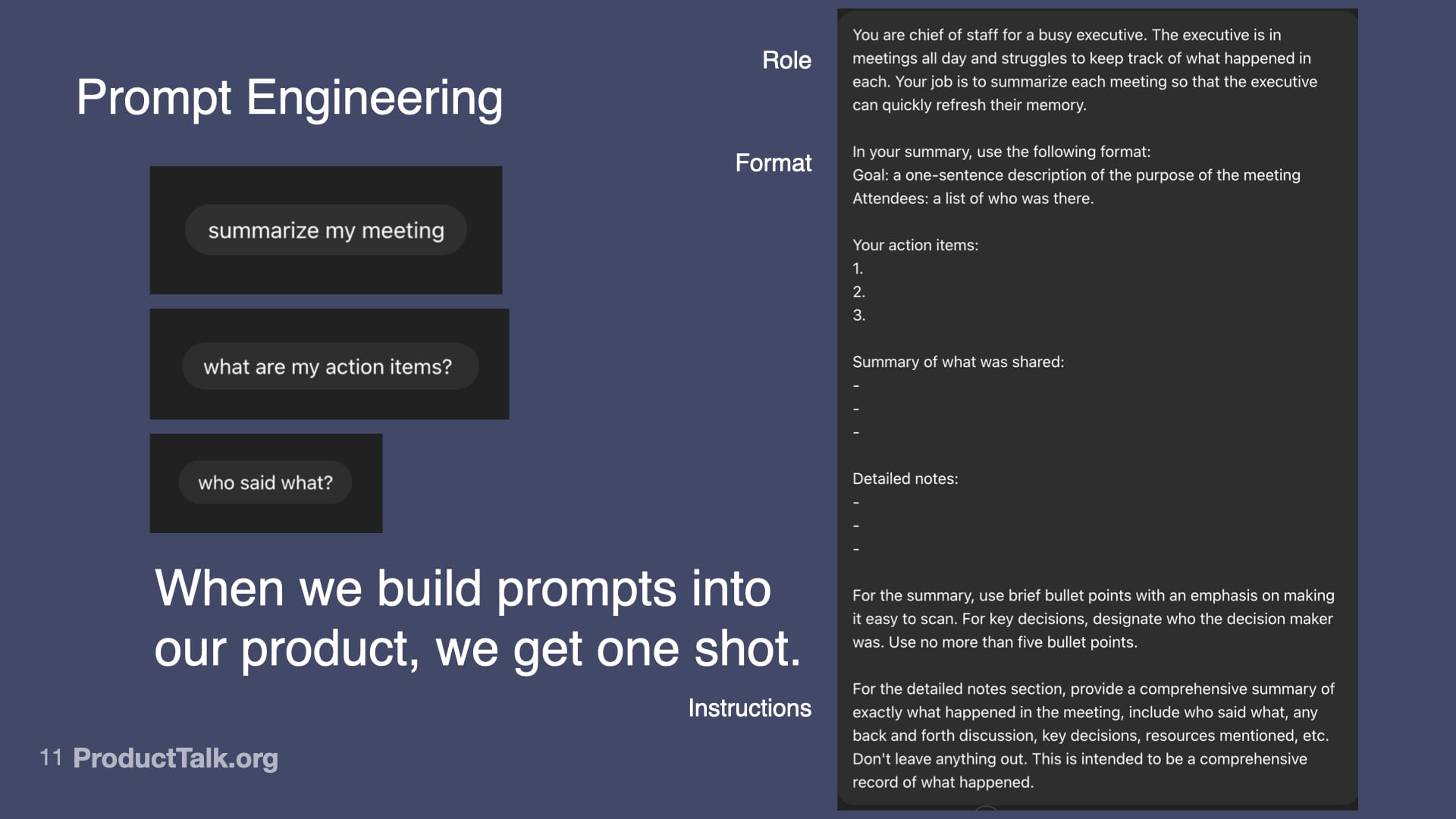
First, prompt engineering. With LLMs, the quality of the input determines the quality of the output. An LLM can’t guess what you want. You have to specify what you want in a language the LLM understands. In a chat, you can iterate with multiple turns. In a product, you get one shot. When we ship a meeting summarizer, for example, I design a production-ready prompt that assigns a role (“You are a chief of staff for a busy executive…”), specifies output format (e.g., a structured list of action items), and clarifies exactly what to include and how to structure it. This is prompt engineering. It’s like writing a really good product spec—but for an AI.
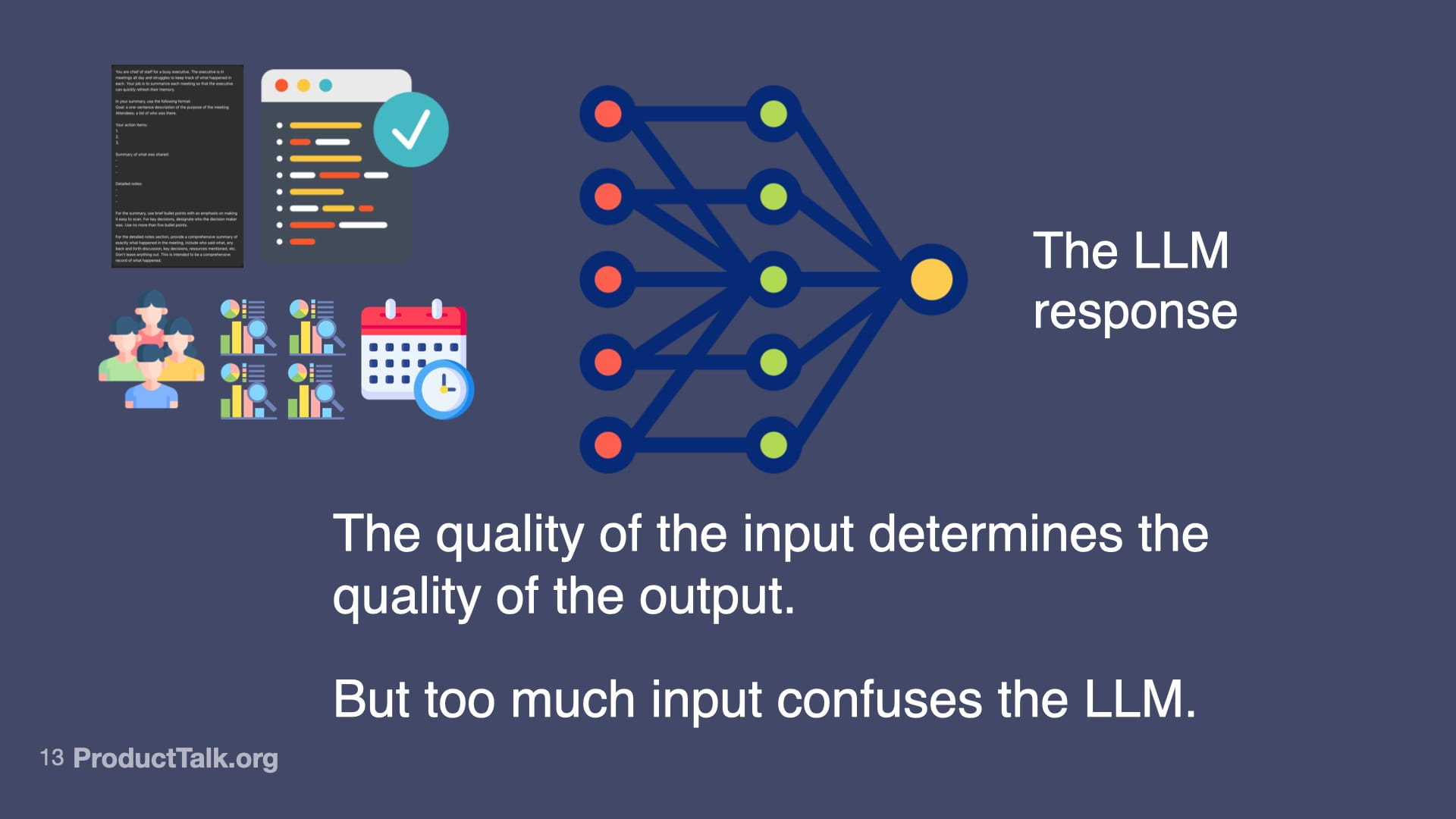
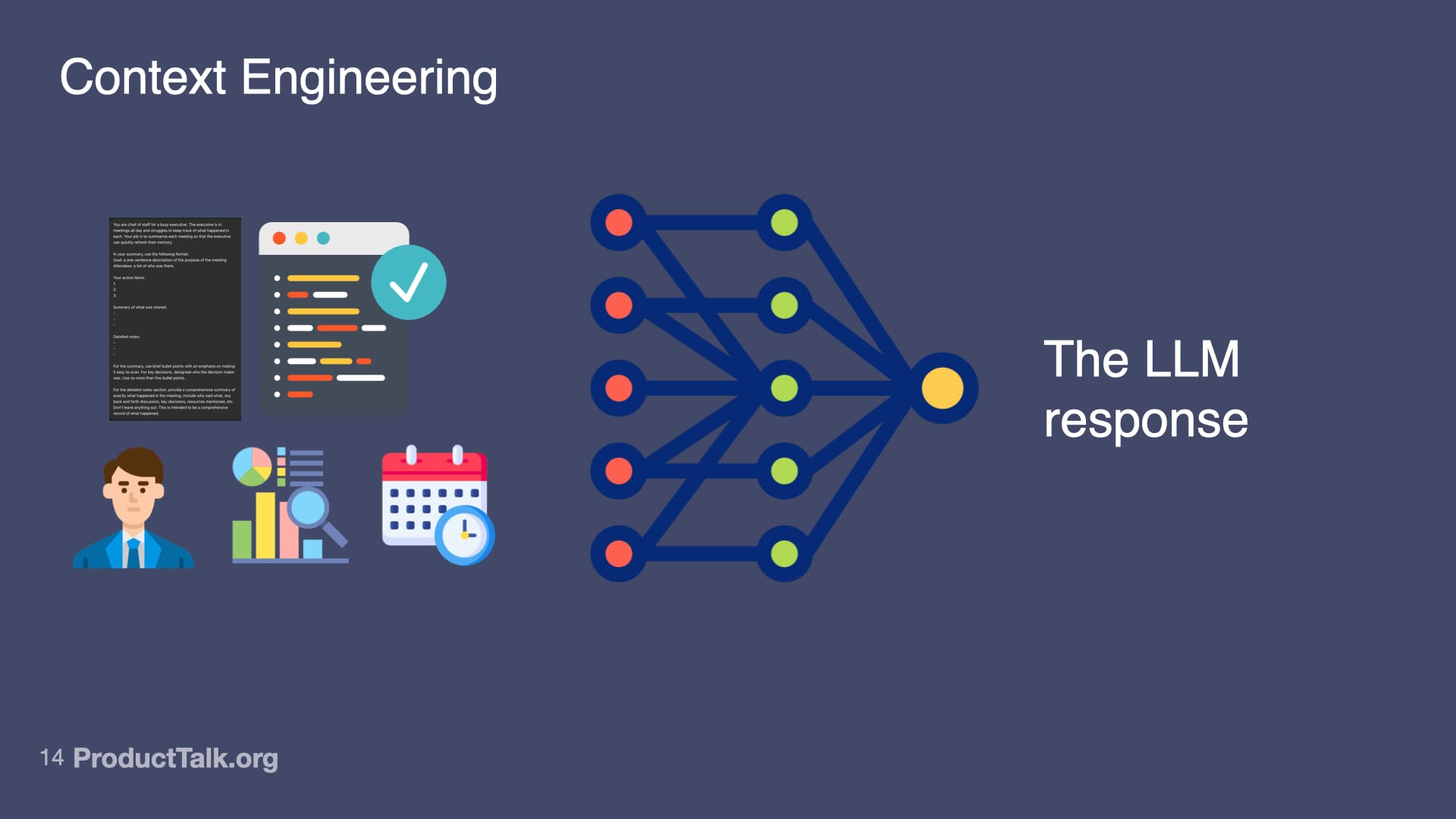
Second, context engineering. LLMs know a lot, but not everything. Imagine a takeaway reads, “Send the pipeline report to John by Friday.” When is Friday? Which John? What is the pipeline report? The model lacks today’s date, the roles of participants, and the specifics of our reporting vocabulary. If you dump every possible detail into the prompt, the model gets noisy input and the quality drops. The key is to add only the context the LLM needs to do the task at hand and nothing more. This is where techniques like RAG (Retrieval Augmented Generation) shine: retrieve just the relevant snippets—e.g., attendee roles, the precise definition of “pipeline report,” and the calendar context for “Friday”—and include only those in the prompt.

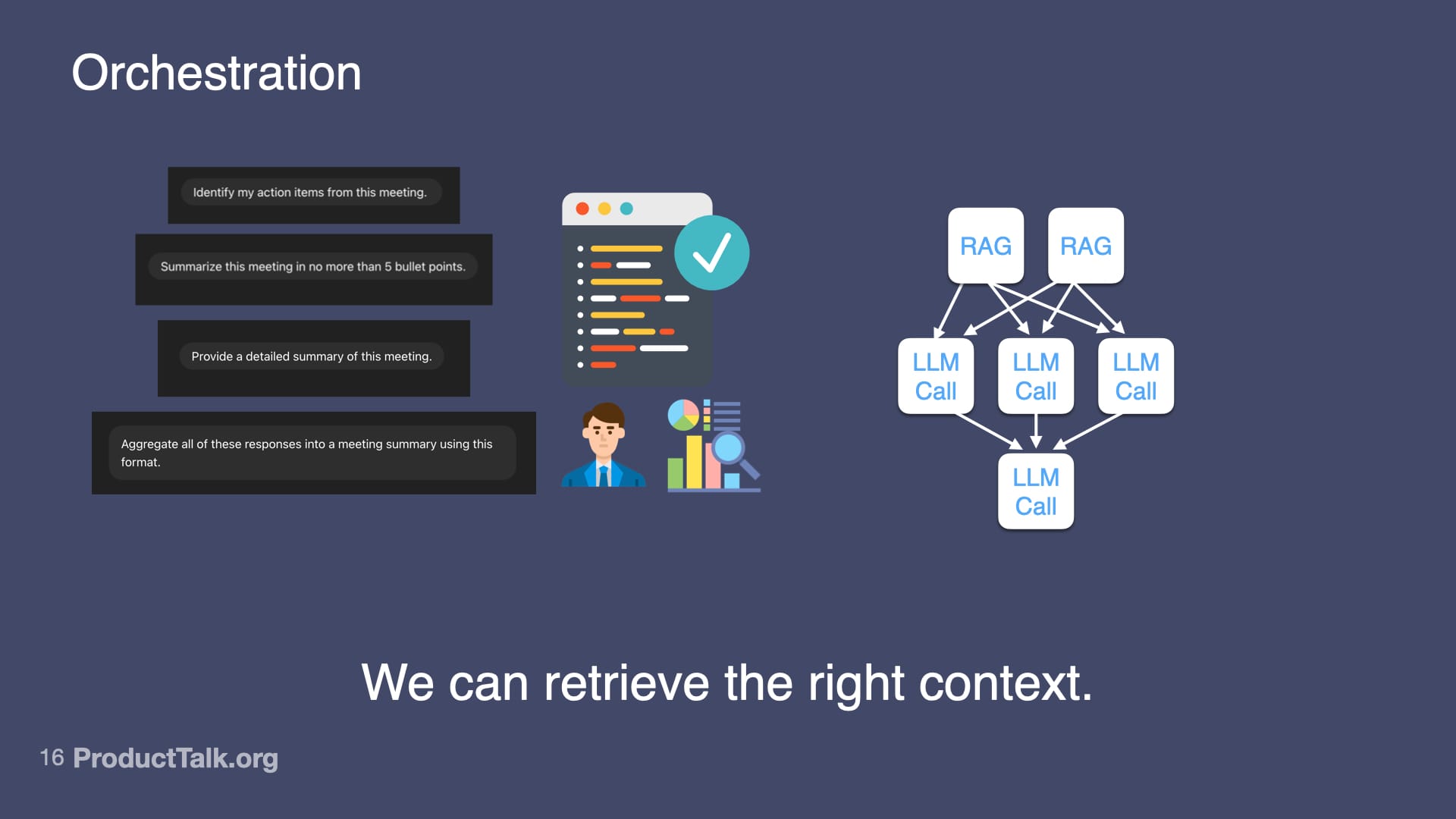
Third, orchestration. LLMs are better at simpler tasks. If you try to do everything in one prompt—identify action items, summarize the meeting, categorize by urgency, match to owners, check for clarity—the quality goes down. But if you break it into steps, each focused on one thing, the quality goes up. I design a workflow of multiple LLM calls that work together. For example: First call: identify action items from the transcript. Second call: categorize by urgency using lightweight project context. Third call: match to owners with a minimal team directory. Fourth call: generate calendar events via an API. Each step is simple. But together, they create something sophisticated.
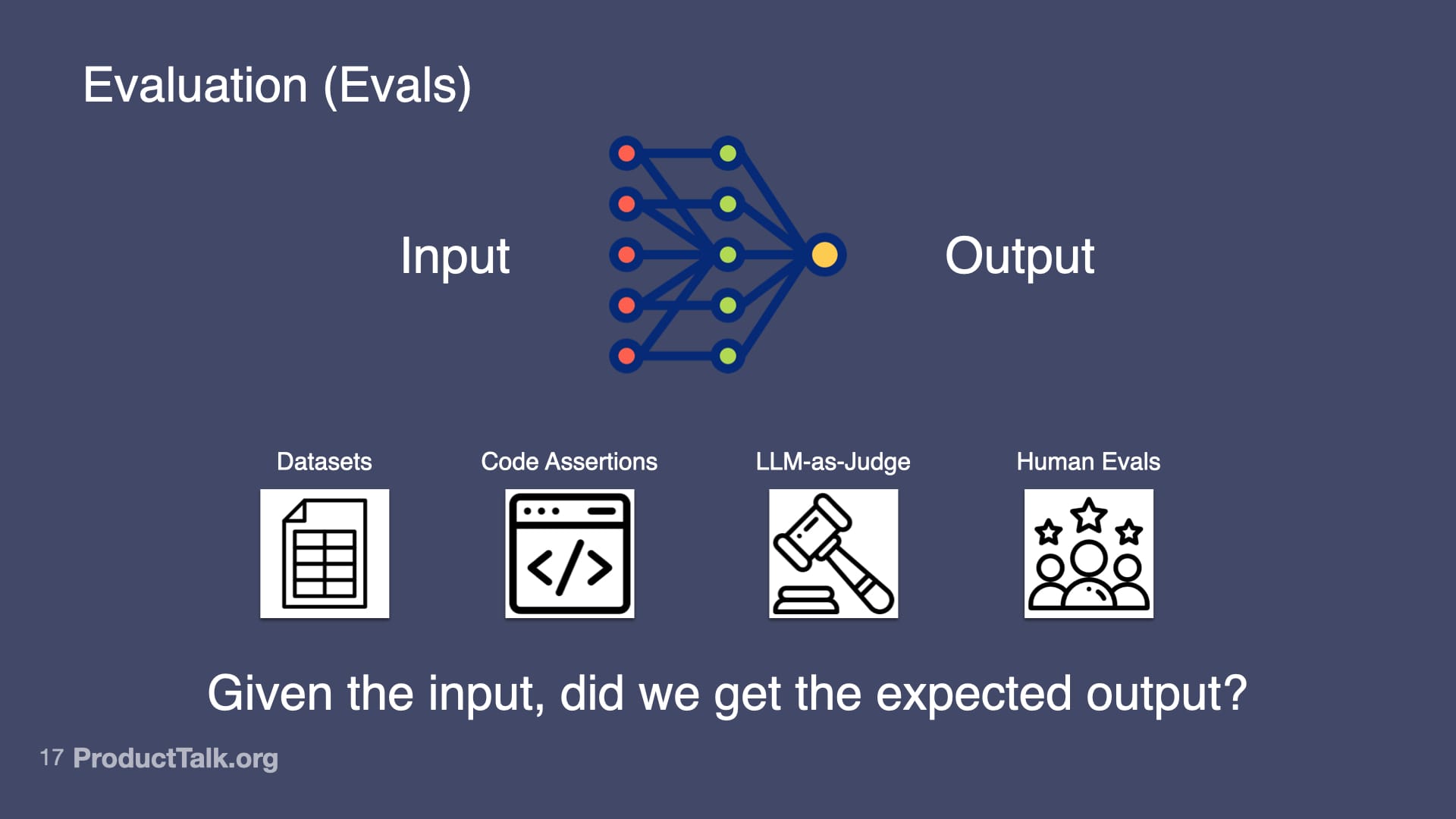
Fourth, evaluation (evals). Otherwise known as: Is my AI product any good? At the heart of evals is this question: Given the input, did we get the expected output? I use several approaches. Datasets: I collect 20–100 real examples, define expected outputs, run the prompt, and measure the success rate. Code assertions: I enforce rules the output must follow (for example, “Every action item must have a task, owner, and deadline”) and fail the test when they’re violated. LLM-as-Judge: I use a model to verify factuality (e.g., “Is each item in this summary in the meeting transcript? Yes or no.”). Human evals: I track whether users need to edit the output and by how much. Start simple; get more sophisticated as the stakes rise.

Here’s the hard truth: you can master all four skills and still ship the wrong thing. Why? Because you chose the wrong problem to solve. Who needs yet another meeting summarizer? The ease of building with generative AI tempts us to jump straight to solutions. Resist it.

Discovery matters more than ever. Before writing your first prompt, be explicit about the impact you want and set a clear outcome. Talk to your customers and ensure you understand their needs; choose the right opportunity before you chase a cool solution. Explore multiple options and use assumption testing to converge on what will actually move the needle.
Prototype, test, and build iteratively. With AI products, it’s easy to get to a great demo and hard to get to a production-grade experience. I validated feasibility before I wrote a line of production code by experimenting directly in a model’s UI, pasting real transcripts, and shaping the system instructions and output format. Only after I had a repeatable prompt and useful feedback did I worry about deployment.
From there, I tested deployment paths with the smallest viable investment. I tried a custom chat in Replit and embedded it. It wasn’t the right interaction model for targeted feedback. I switched to a submission flow using a homework-style pattern: students upload their transcript, the system processes it, they get detailed feedback. Done. That worked—until automation reliability lagged. I wired it up in Zapier, then rebuilt it on AWS Step Function for robust retries and better error handling when scale introduced edge cases.

Each iteration tested a different assumption. Iteration 1 (Claude): Can AI even do this? What makes good feedback? Iteration 2 (Replit chat): How should people interact with it? Iteration 3 (Zapier): Can I integrate this into the existing workflow with minimal engineering? Iteration 4 (Step Functions): How do I make it reliable at scale when things inevitably go wrong? I didn’t know the answers up front; I learned by building, shipping, and observing.
Ethical data practices are non-negotiable. Improving AI products requires inspecting traces—the user input, system prompts, tool calls, and LLM responses. For a coaching flow, that includes the uploaded transcript, the system prompts that define evaluation criteria, and the AI’s feedback. To fix issues, I look at traces where things went wrong—but only with explicit user permission. Too many AI products collect everything by default and review traces without clear consent. Don’t do this.
In my products, users must explicitly grant permission for me to review their data. The consent is clear and specific. If they say no, I don’t see their data. Full stop. That forces me to rely on synthetic data for many tests and to engineer privacy into the architecture from day one rather than bolt it on later. It’s the right thing to do, and increasingly, it’s required.

Everything changes—and nothing changes. Yes, there are new skills you should master: prompt engineering to get the right output the first time; context engineering to give the LLM exactly what it needs; orchestration to decompose complex tasks into simpler steps; and evals to systematically measure quality. And the fundamentals still rule: solve the right customer problems with strong discovery; prototype and iterate to de-risk; and uphold ethical data practices as a design constraint, not an afterthought. The teams that win with AI will master both the new technical craft and the timeless product fundamentals.
If this resonates, pick one active workflow, apply the four AI skills end-to-end, and run a short discovery and eval cycle against a clear outcome. Then ship. You’ll learn faster than any slide deck could ever teach you.
Inspired by this post on Product Talk.











Leave a Reply