AI agents are only as valuable as the measurable outcomes they deliver. In my role leading product strategy at HighLevel, I’ve learned that the fastest way to earn executive trust is to translate agent performance into clear revenue impact, cost savings, and risk reduction. The challenge isn’t enthusiasm for AI; it’s creating a disciplined, repeatable way to prove business value.
Here’s the three-step playbook my teams and I use to quantify the value of agentic AI, align stakeholders, and scale what works.
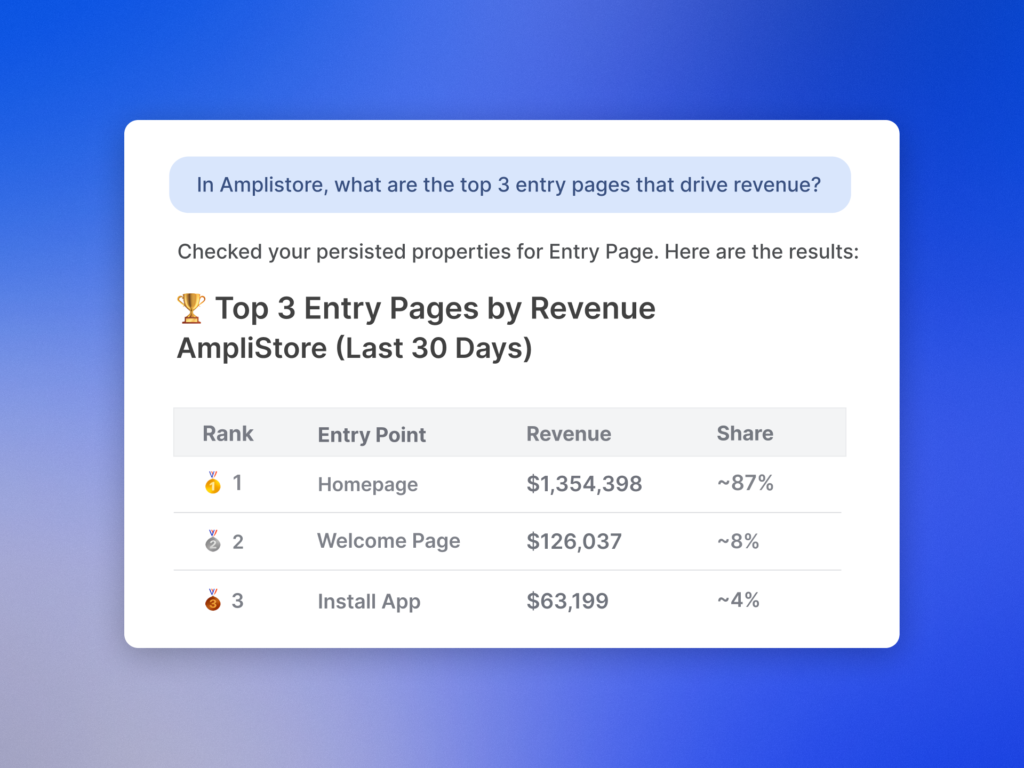
Step 1 — Define value outcomes and success criteria. Start with a driver tree that ties agent outcomes to company-level goals. For revenue, target conversion lift, average order value, and expansion (e.g., trial-to-paid, self-serve upsell). For cost, focus on containment/deflection rate, reduced handle time, and lower cost to serve. For risk, measure error rates, hallucinations, security/policy violations, and customer complaint rate. Convert these into outcomes vs output OKRs, set baselines, and pre-commit to thresholds for launch, scale, or rollback. This ensures the team is accountable to business KPIs, not vanity metrics.
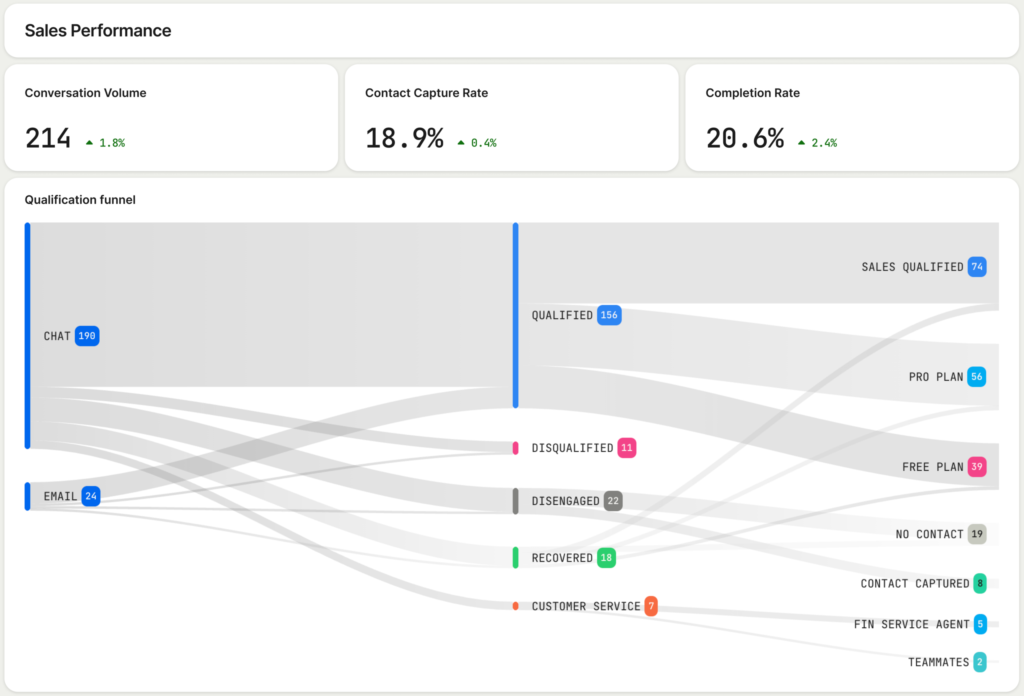
Step 2 — Instrument comprehensively and establish baselines. Instrument the full journey: prompts, responses, human-in-the-loop events, escalations, feedback, and downstream conversions. Capture both leading indicators (time-to-first-value, containment rate, self-serve completion) and lagging outcomes (NRR, churn, LTV/CAC). Use behavioral analytics, session replay, product tours, and in-app guides to contextualize what users do before and after agent interactions. Baselines matter—freeze a control period so improvements are truly incremental.
Increase revenue, cut costs, and reduce risk with Pendo’s Software Experience Management platform. Optimize the entire software experience to drive adoption and improve engagement.
Step 3 — Experiment, attribute, and risk-adjust. Treat every agent capability like a hypothesis. Run A/B tests or holdouts with a precomputed minimum detectable effect so you can ship confidently. Attribute outcomes to the agent by linking events to conversions and support deflection, and calculate ROI as (incremental revenue + cost avoided – total operating cost, including model/API, labeling, and oversight). Apply AI risk management by tracking false positives/negatives, escalation rate, and policy breaches; adjust ROI with a risk score so the “cheapest” agent isn’t inadvertently the riskiest. This is eval-driven development in practice: define success, measure, iterate.
Operationalizing the playbook requires crisp reporting. Stand up Agent Analytics dashboards in your unified analytics platform that roll up per-agent KPIs, funnel performance, cohort trends, and experiment results. Review them in QBRs and with frontline teams to connect numbers to lived customer experience. When metrics improve, amplify with product-led growth motions—targeted in-app guides and lifecycle nudges to get more users into high-value agent flows.
What does this look like in the real world? Early on, we celebrated “tickets deflected” and missed that some conversations quietly increased churn risk. After we adopted this three-step approach, we saw the full picture: a modest dip in deflection quality was offset by a larger lift in expansion revenue and a meaningful drop in time-to-resolution. The risk-adjusted ROI was unambiguous, and the CFO greenlit broader rollout.
If you’re building or scaling AI agents, anchor on outcomes, instrument ruthlessly, and insist on experimentation. With the right measurement discipline, you’ll know exactly which agents deserve more investment, which need redesign, and which should be retired. The result is a portfolio of agents that reliably drive adoption, engagement, and durable business value.
Inspired by this post on Pendo – Best Practices.







Leave a Reply