“You don’t have to trust the algorithm; you can see exactly why a conversation earned the score it did.”
We recently shared how we redesigned CX Score to deliver deeper, more actionable insights across every conversation. The most common follow-up from support leaders was simpler and incredibly important: “Can I trust it?” It’s the right question—and it’s the one I use as my own bar for whether a metric is ready for the C‑suite.
CS teams are the subject matter experts on customer experience. They understand the nuance of what customers feel, the context behind every interaction, and the difference between a technically resolved issue and a genuinely satisfied customer. I’ve learned, conversation by conversation, that any metric we ship has to capture that nuance at scale—or it doesn’t deserve to be used.
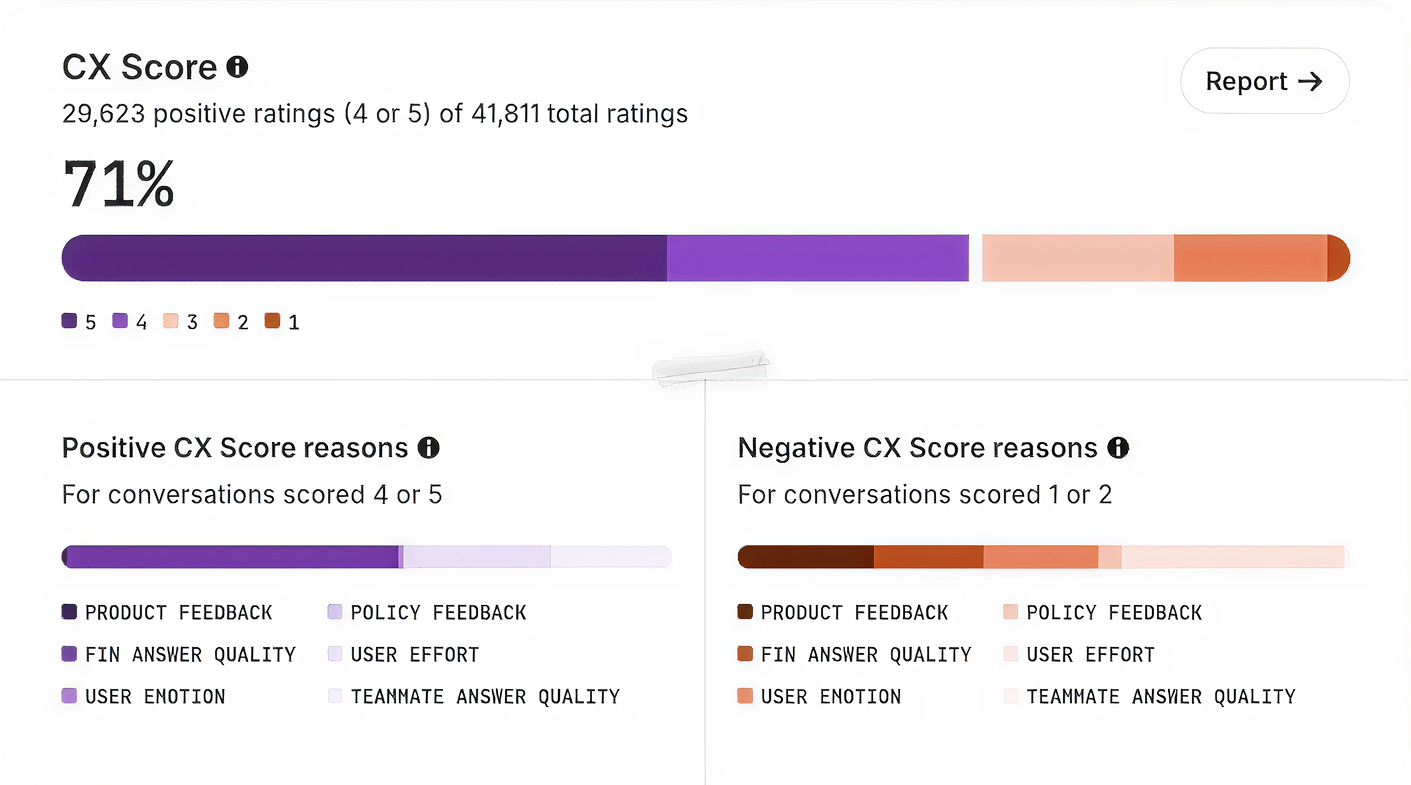
We built CX Score to give support teams a complete view of how their customers feel across every conversation. It surfaces what’s working, what’s not, and why—so leaders can communicate impact clearly and drive change across support, product, and the wider business.

Here’s exactly how I approached building a trustworthy metric that support leaders can inspect, explain, and defend.
1) It’s grounded in how support teams define quality. I started with how experienced support professionals actually evaluate conversations—collecting real examples of strong, mixed, and poor interactions across industries, identifying the specific factors that shape overall experience, and writing plain-English rules for each. The result: CX Score applies the same criteria a trained support professional would use, not generic LLM assumptions.
2) It’s aligned with human judgment. We created a dataset of thousands of real customer conversations spanning multiple industries, languages, channels, and agent types. Each was manually reviewed by experienced support professionals—with two reviewers per conversation where possible and disagreement resolution to create stable consensus labels. The result: CX Score is trained and tested to behave like an expert reviewer, not a language model making broad guesses.
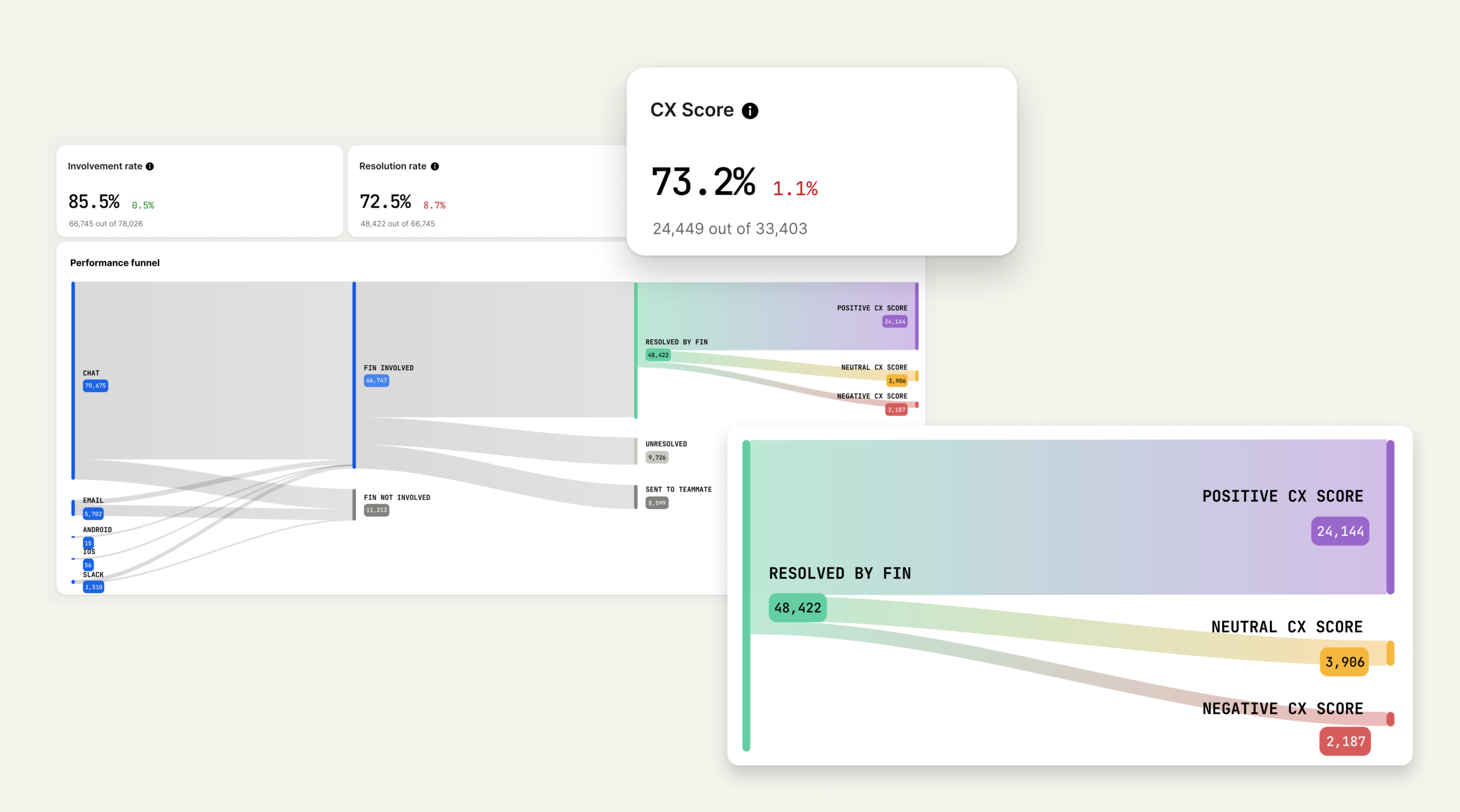
3) It’s engineered by AI specialists. CX Score isn’t a prompt attached to an LLM. It’s a production system built by Intercom’s AI Group: 37 ML scientists and 350 engineers whose full-time focus is AI for customer service. The system includes specialized handling for long transcripts, model configuration tailored for support language and subtle sentiment, prompt engineering designed to default to neutral when evidence is weak, and a multi-stage evaluation pipeline that checks for precision, consistency, and reliability. The result: A metric built by a team that understands LLM behavior in production support environments, where accuracy and consistency matter most.
4) It’s validated statistically, not qualitatively. Trust requires measurement, not vibes. We tested CX Score across standard ML metrics: Precision (when the model flags a negative experience, how often do humans agree?), recall (how many human-identified issues does it catch?), and F1 score (the balance between both). We set an explicit bar: F1 above 0.8, representing high agreement with human judgment. We reran these evaluations through every revision, checking for regressions or biases, and I focused especially on negative experiences, because a false negative hides a real problem. The result: CX Score meets a measurable standard before it ships—not a gut check, a statistical requirement.
5) It was battle-tested with real customers. Lab accuracy isn’t enough. Customer environments are messy: Varied ticket types, mixed languages, unpredictable edge cases. Before release, we ran a multi-phase field test—shadow-scoring conversations with both old and new models, validating sensible behavior across agent type and conversation length, then rolling out to a controlled customer group who confirmed the scores felt right, reasons were clear, and insights were actionable. The result: CX Score shipped because real teams told us it made sense in practice, not because it passed internal tests.
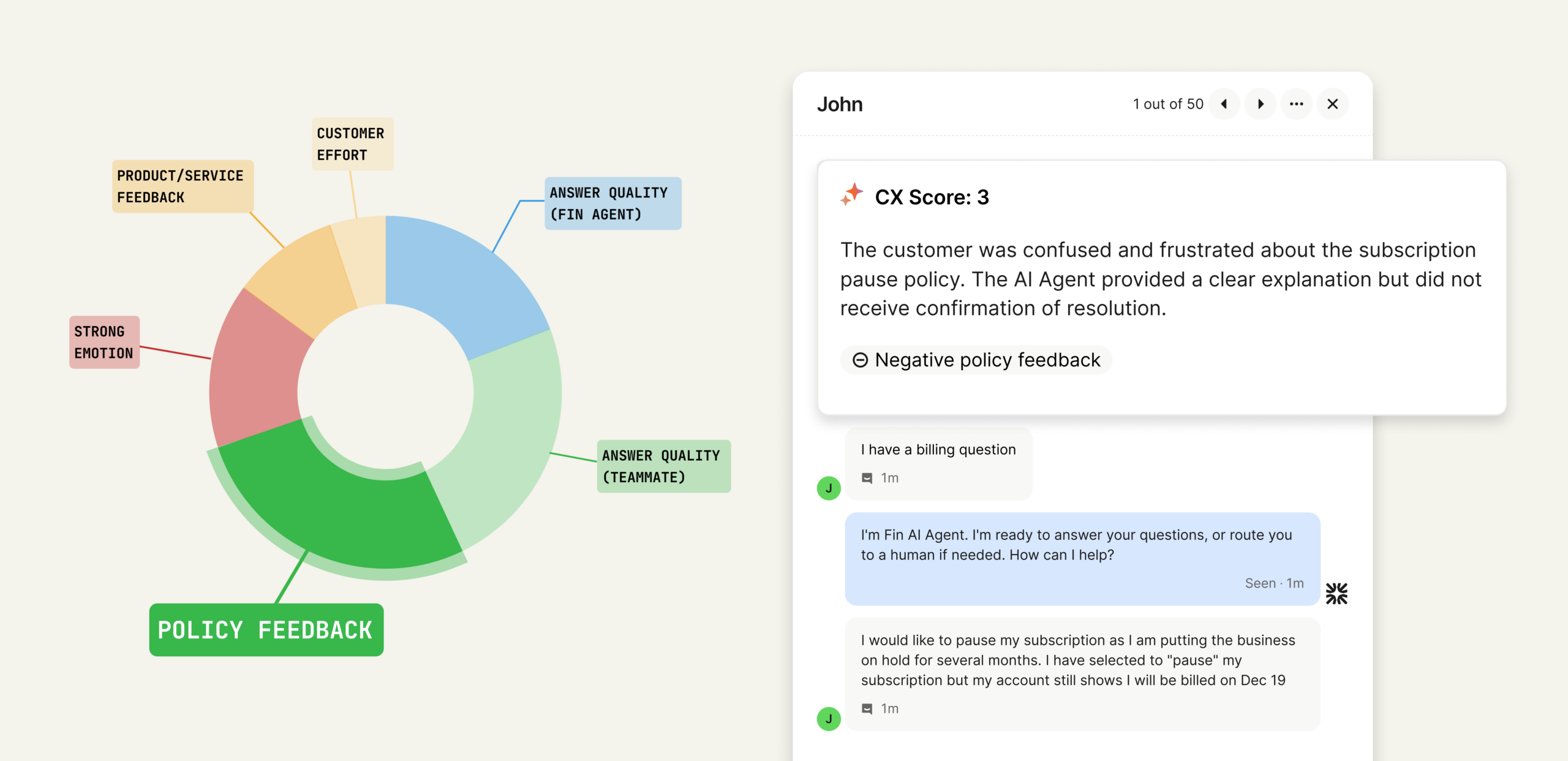
The importance of explainability. One of the most critical choices I made was ensuring CX Score isn’t a black box. Every score comes with clear reasons, concrete excerpts, and a short explanation of what influenced the rating. This turns the metric into something you can inspect, audit, and explain to executives. You don’t have to trust the algorithm. You can see exactly why a conversation earned the score it did.
A metric that evolves with your business. Customer expectations shift. Products change. AI improves. A trustworthy metric can’t be static. CX Score evolves with the same commitments that shaped its redesign: Evaluate the real signals that shape customer experience, keep the logic simple and interpretable, and ensure leaders can make clear decisions from it. It’s built to be a durable source of truth across every conversation.
The takeaway. In a world where products look the same and AI can generate any interaction, customer experience is one of the few differentiators that actually matters. Support leaders have built that expertise conversation by conversation. What they’ve lacked is a measurement system that could validate it at scale—one that’s reliable enough to report to the C-suite, explainable enough to defend in strategy meetings, and rigorous enough to drive real decisions. That’s what CX Score is designed to be: A metric that reflects the reality support leaders see every day, backed by the technical rigor to make it credible everywhere else.
Want to see CX Score in your workspace? Ask your admin to enable it for your team, and start using explainable AI insights to improve customer experience and coach with confidence.
Inspired by this post on The Intercom Blog.











Leave a Reply