
Too often I watch teams ping a global agent with vague AMAs and then wonder why they get generic summaries instead of decisive guidance. When I lead product reviews, I push the team to treat AI like a partner in decision-making, not a trivia engine. That simple mindset shift transforms how quickly we move from questions to confident action.
AI isn’t built for AMA (ask me anything). Get recommendations for outcome-based questions for the best results with Amplitude AI.
In practice, outcome-based prompting means I don’t ask an agent to “analyze the data.” I ask it to help me reach a specific product decision, grounded in behavioral analytics and connected to our outcomes vs output OKRs. To make that concrete, I always frame my prompts around three things.
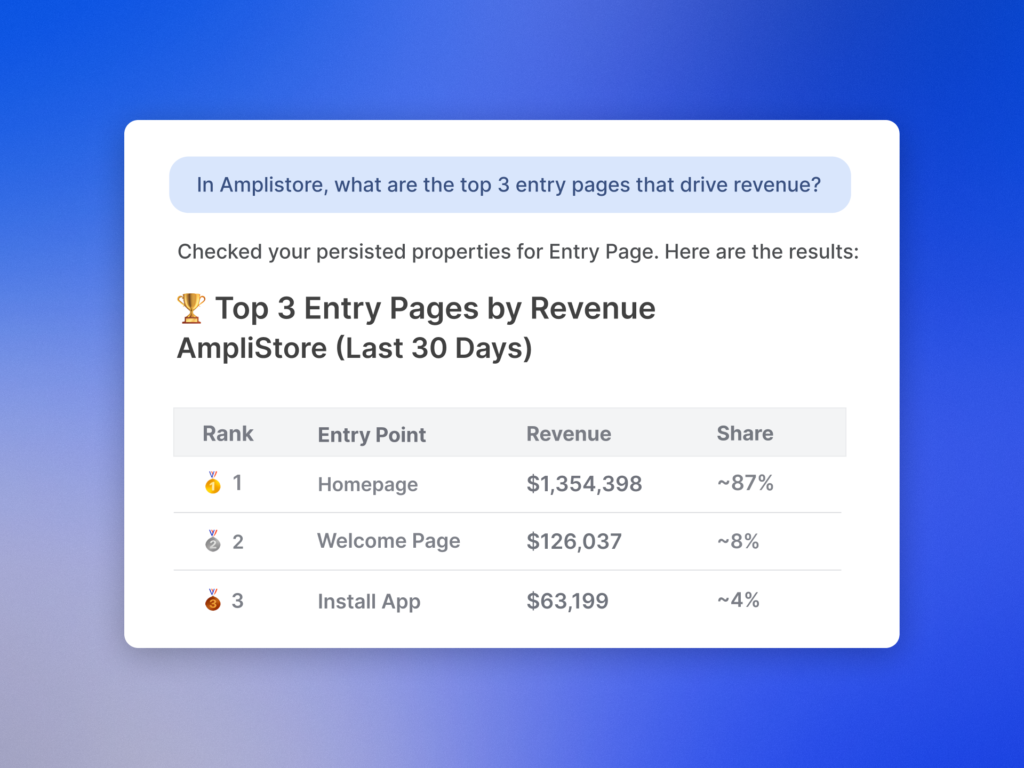
First, I state the outcome and metric. I name the business goal and the exact measure in Amplitude analytics that will validate success—activation rate, funnel conversion from A to B, or 8-week retention. I’ll reference the relevant events, segments, or driver trees so the agent has a crisp target. This is where product strategy meets measurement discipline.
Second, I define the context and constraints. I specify the user cohort, the timeframe, and the surface area I care about—new self-serve signups in the last 30 days, first-session behavior on web only, or EU traffic where data governance rules apply. On a unified analytics platform, this context lets an agentic AI narrow its search to the highest-signal slices of behavioral analytics rather than pattern-matching across noise.
Third, I declare the decision and deliverable. I tell the agent exactly what I will do next and the format I need to act: a ranked list of levers for an A/B testing plan, a recommended prompt engineering template for in-app guides, or a one-page brief I can hand to the growth team. Clear decisions lead to clear outputs; vague intents lead to vague answers.
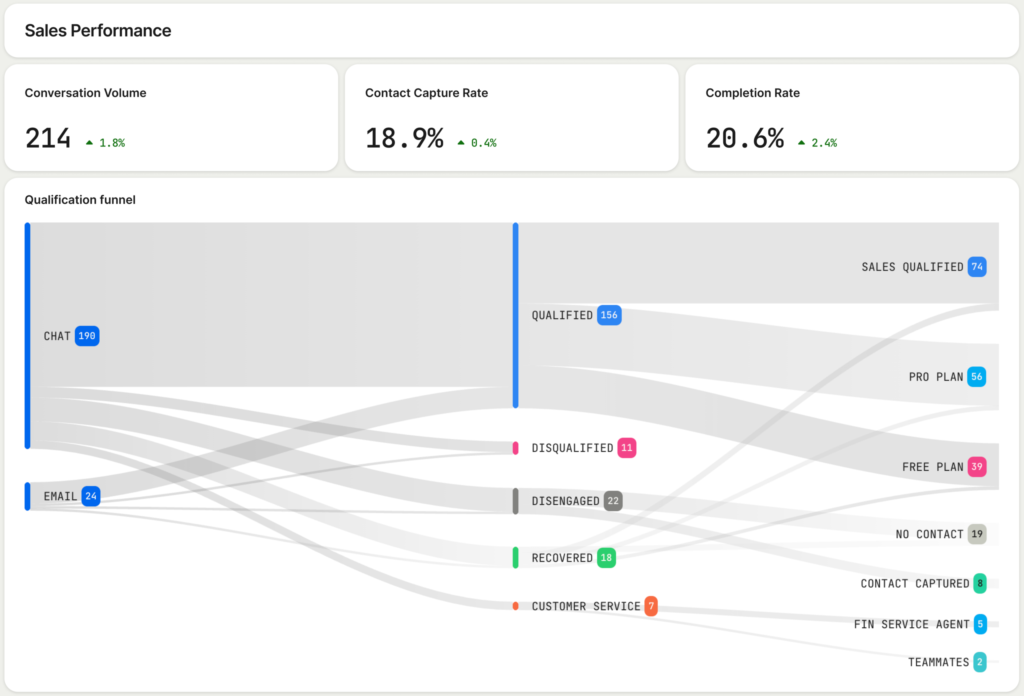
Operationally, I turn these three elements into reusable prompt templates, and I track their performance with Agent Analytics. I review traces to see which inputs drive the best recommendations, and I refine prompts the same way I iterate on product copy. For LLMs for product managers, this is the craft: small, testable improvements that compound into outsized impact.
Here’s a quick example. When I needed to lift user activation, I asked for a prioritized set of friction points blocking first-value within 24 hours for new self-serve accounts, based on last month’s data. I defined activation as completing event X within Y hours, asked the agent to analyze top drop-offs in the funnel, and requested an action plan with two experiment ideas and success thresholds. The response mapped behaviors to interventions, connected to retention analysis, and gave me a prompt engineering snippet for the onboarding nudge we shipped the same week.
If your AI workflow still starts with “What does the data say?”, you’ll keep getting broad narratives. Start with outcomes, sharpen the context, and specify the decision you will make. That’s how Amplitude analytics, paired with agentic AI, stops being interesting and starts being indispensable.
Inspired by this post on Amplitude – Perspectives.







Leave a Reply