When millions of conversations flow through a platform every day, reliability isn’t just a technical metric—it’s the foundation of customer trust. I’ve learned the hard way that green dashboards can still mask red-hot customer pain. That’s why I push teams to focus on outcomes, not just infrastructure signals.
For me, reliability starts with one essential question: “Can our customers do the job they’ve hired us to do?” That single question cuts through complexity and forces a customer-outcome lens on everything from alerting to SLAs.
That mindset leads naturally to what I call “heartbeat metrics” — vital signs that instantly tell us if systems are truly serving their purpose. Think of them as a pulse check on real customer outcomes. If the pulse weakens, customers feel it instantly. A heartbeat metric is the clearest signal you can get that a product is alive and doing its job.
I’ve seen this put into practice at scale. At Intercom, where the AI Agent Fin resolves millions of customer inquiries autonomously, their fundamental heartbeat metric is the rate of new messages and replies across Intercom. For Fin, it’s successful AI responses. If those dip, it’s hitting the ability to connect. It might be a database failover, a misconfigured fleet, or a bad code change — it doesn’t matter. What matters is that it’s hitting customers’ ability to use Intercom.
Intercom isn’t alone. Amazon tracks order volume as their heartbeat. Affirm watches checkout attempts. If those numbers fall below expected levels, they don’t wait for a support ticket—they investigate immediately, because they know their customers’ success depends on it.
Not every metric qualifies as a heartbeat. The best ones share three traits: they’re directly tied to customer value (the main job your product is hired to do), high-volume and predictable (so anomaly detection can spot small drifts quickly), and binary in spirit (a drop is a clear sign something is broken, not just “a bit slower than usual”).
When we anchor on heartbeat metrics, three benefits show up fast: we detect issues faster than user reports or support tickets, we keep teams focused on what truly matters to customers, and we create a direct tie to our SLA—a system-level answer to, “Is the promise we made being kept?”
To be clear, I still monitor the usual suspects—latency, error rates, and infrastructure health. Heartbeat metrics don’t replace those; they complement them. They’re the fastest shortcut to understanding customer impact.
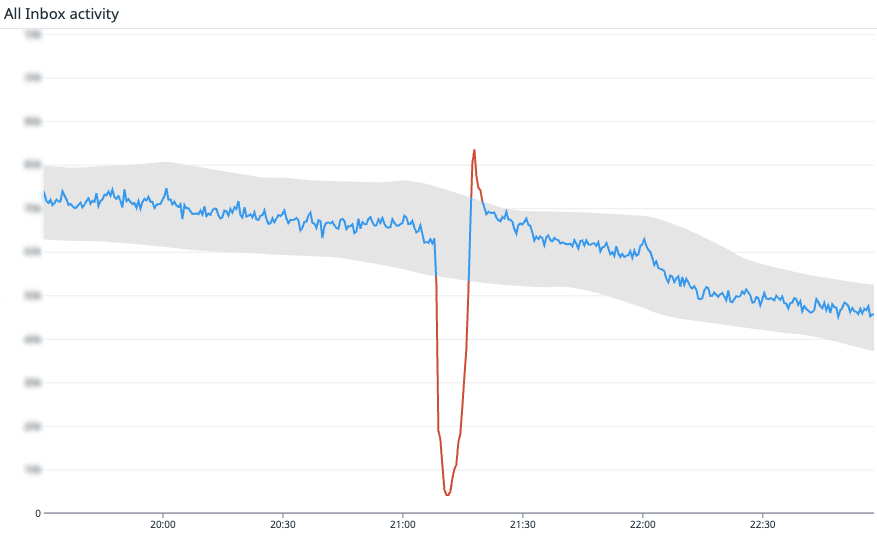
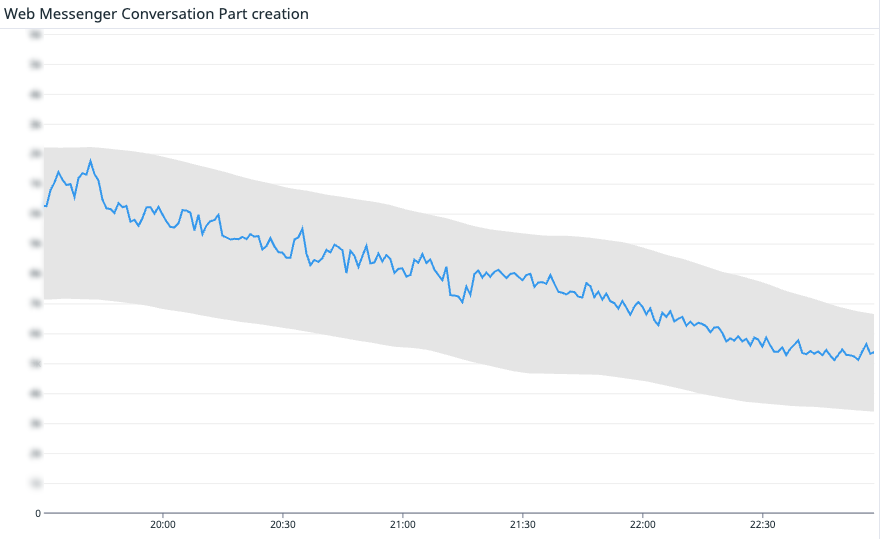
At scale, one pulse isn’t enough. Complex systems need multiple vital signs that reflect how different user groups succeed. Intercom started simple—are customers creating messages at the expected rate?—and then broke that signal down across core systems. Together, these metrics form a complete picture: Fin replies to your customers. Teammates reply in the Inbox. Teammates interact with the Inbox UI. Users on your website can message with the Web Messenger. Users on your app can message with the Mobile Messenger. If even one of them drops, it’s a major customer-impacting problem.
Speed matters when the heartbeat alarm fires. After months of reliable signal, automation becomes a force multiplier—paired with human oversight. Here’s what happens when a heartbeat metric drops: If we have just deployed new code to production, we automatically roll it back. Rolling back recent changes is a safe, and fast operation. We automatically create an incident in incident.io and page in engineering and an incident commander. If this alarm fires, it’s likely we will need our full incident response including status page updates. The system automatically suggests initial actions to first responders. For example, we use incident.io’s Investigations feature to get a head start on suggesting root causes.
This kind of automation pays off. On April 24th, a server issue slowed the Inbox, impacting teammates’ ability to use the Inbox. Heartbeat metrics caught it fast, and the issue was resolved in 10 minutes. End-user messaging was unaffected. This counted as downtime toward the SLA, with a full root cause analysis shared publicly here. That level of transparency keeps trust intact even when incidents happen.

Where heartbeat metrics truly shine is in how they define and enforce accountability. They don’t just monitor; they inform SLAs in a way customers understand. Two independent SLAs matter most in this model: Core Platform SLA: If your team can’t reply in the Inbox or customers can’t message via the Messenger, that’s downtime. Fin SLA: If Fin cannot generate text answers, we record downtime.
Measurement matters. Many status pages stay green as long as an HTTP probe returns 200 OK, even when users are stuck. Heartbeat metrics close that gap by checking real customer outcomes, not just server responses. I also favor anomaly detection—tracking expected patterns over time and flagging when something looks off—and tooling that lets us drop to a per-customer level when we need to understand individual impact.
If you don’t have a heartbeat metric yet, start simple. Pinpoint your product’s must-do job—the one thing customers must accomplish to succeed. Choose a metric with volume so you can detect drifts quickly, not just total failures. Make it binary in spirit so a drop clearly signals breakage. Hook it to your alerts so it’s loud and reaches the right responders. Use it to align teams on what to do when the heartbeat falters. And stick to it, 24/7—reliability isn’t a 9-to-5 job.
For monitoring, I like practical guardrails. Here’s a Datadog monitor pattern I recommend for an Inbox-style heartbeat (Terraform syntax, simplified for clarity): keep a tight baseline window, alert on negative deviations beyond statistically expected ranges, auto-page responders, and attach standard operating procedures for immediate rollback and incident initiation. It’s simple, auditable, and fast.
Modern systems grow more complex every quarter. The question that matters stays refreshingly simple: “Can our customers do what they came here to do?” Build a reliability heartbeat that answers that question in real time, and you’ll keep your teams honest, aligned, and fast. Define yours—it might become your most valuable signal.
Inspired by this post on The Intercom Blog.











Leave a Reply