Inspired by this post on Pendo – Perspectives.


Inspired by this post on Pendo – Perspectives.
Every week, I watch the cybersecurity landscape bend under the pressure of AI. The pace isn’t linear—it’s compounding. What worked for IT teams last quarter often needs a rethink today, and the difference between merely coping and truly competing lies in how quickly we adapt our strategy, tooling, and operating rhythms.
Learn the ways in which AI is transforming both cybersecurity offense and defense for IT teams.
From my vantage point leading product strategy, I see three shifts that matter most right now: AI is supercharging attackers, accelerating defenders, and reshaping governance. Together, they redefine how we prioritize investments, measure risk, and align product and security roadmaps.
First, AI has leveled up the offense. Large language models can industrialize social engineering—hyper-personalized spear-phishing at scale, deepfake voice notes that spoof executives, and highly convincing support chats that trick users into bypassing controls. Code-generation tools lower the barrier to crafting polymorphic malware and automating reconnaissance. The net effect is ruthless efficiency: more credible lures, faster campaigns, and broader reach with fewer human operators. I now assume adversaries have an AI co-pilot—and plan defenses accordingly.
Second, AI is accelerating the defense. Modern detection and response stacks are moving beyond rules to behavioral analytics—correlating identity signals, endpoint telemetry, and network events to spot subtle anomalies that signature-based tools miss. Copilot-style assistants are augmenting SecOps by summarizing incidents, explaining probable root cause, and proposing next steps. The aim isn’t blind automation; it’s decision acceleration—shrinking mean time to detect and respond while reducing analyst toil. On the build side, AI-assisted code scanning and dependency analysis help teams shift security left, catching vulnerabilities earlier and turning secure defaults into muscle memory.
Third, governance is being rewritten in real time. As AI models ingest sensitive data and generate code and content, data governance and privacy-by-design move from compliance checklists to active risk management. We’re formalizing AI risk management alongside traditional AppSec: model inventories, usage policies, red-teaming prompts, and guardrails against prompt injection and data leakage. Identity remains the control plane—zero trust principles, least privilege, and continuous verification become nonnegotiable. I’ve found that aligning security, product, and IT leadership on a single policy-as-code backbone prevents drift and keeps audits predictable.
Practically, I guide teams to start with a crown-jewel inventory: What data and systems would materially impact customers, revenue, or brand if compromised? Map data flows, instrument comprehensive telemetry, and prioritize detection coverage where it matters most. Choose AI to augment before you automate—prove the loop with humans in the middle, then graduate to higher autonomy levels with clear rollback paths and audit logs.
Culturally, this is a product problem as much as a security one. We bring empowered product teams and SecOps into the same room, set measurable objectives (signal-to-noise ratio, mean time to contain, escaped defect rate), and iterate with the same cadence we use for product features. When security outcomes are treated as customer outcomes, adoption soars and friction recedes.
The takeaway: AI has tilted the field, but not inevitably against defenders. With a clear AI strategy, disciplined data governance, and pragmatic automation, IT leaders can turn reactive security into a proactive advantage—meeting attackers’ speed with speed, and outlasting them with better judgment.
Inspired by this post on Pendo – Perspectives.

Across enterprises, I’m watching AI sprint from lab experiments to business-critical workflows. That velocity is exciting—and it’s also where risk compounds. In my role partnering with CIOs and IT leadership, I’ve learned that winning with AI is as much about disciplined risk management as it is about breakthrough use cases.
Learn about the risks that AI poses to IT teams, and how they can mitigate them.
I frame the challenge as “4 AI risks for CIOs (and a guide to solve them)”: data governance and compliance, model reliability and bias, security and supply chain exposure, and operational cost/ROI drift. Below, I outline the risks I see most often and the concrete actions I take to de-risk them without slowing innovation.
Risk 1: Data governance and compliance. The fastest way to stall an AI Strategy is to overlook consent, lineage, and access controls. I establish privacy-by-design from day one: data minimization, clear retention policies, role-based access control, and auditable logs for training, inference, and feedback loops. I also insist on defensible vendor reviews (DPA, SOC2/ISO, regional data residency), PII classification, and internal model cards that document sources, sensitivities, and acceptable-use constraints. This makes IT leadership comfortable scaling from prototype to production.
Risk 2: Model reliability, hallucinations, and bias. AI that fabricates or skews output erodes trust and creates downstream risk. I operationalize quality with evaluation harnesses, golden datasets, human-in-the-loop review for high-impact actions, and red-teaming for safety. Retrieval-augmented generation with citations, content filters, and grounded prompts reduce error rates. To quantify progress, I define precision/recall targets and a minimum detectable effect (MDE) for experiments so we know when a change is truly better—not just different.
Risk 3: Security and AI supply chain. New surface area invites prompt injection, data exfiltration, and compromised dependencies. I apply zero-trust principles: strict allow/deny lists for tools and connectors, secrets isolation, egress controls, sandboxed environments for agents, and output validation before execution. Every model and plugin goes through threat modeling, dependency scanning, and vendor security reviews. For agentic AI patterns, I gate high-risk actions behind explicit approvals and granular scopes.
Risk 4: Operational cost and ROI drift. AI workloads can balloon with hidden inference costs, shadow IT, and duplicated platforms. I put governance around spend using consumption SaaS pricing guardrails, usage caps by environment, tagging by app/team, and a unified analytics platform to monitor latency, quality, and cost per transaction. This lets me reallocate budget toward the highest-impact use cases while sunsetting low-yield experiments.
Your 90-day playbook. Days 0–30: Inventory AI use cases, classify data sensitivity, choose one or two critical business workflows, and stand up core guardrails (access, audit, red-teaming). Days 31–60: Pilot with a cross-functional product trio (PM, design, engineering), define OKRs, instrument evaluations, and enable human-in-the-loop. Days 61–90: Productionize the winning flow, set usage and spend policies, enable observability dashboards, and roll out training for frontline teams with clear escalation paths.
The organizational layer matters as much as the technical one. I align stakeholders early, empower product trios to iterate quickly within boundaries, and deploy forward deployed engineers to embed with the business. This keeps trust high, reduces handoffs, and ensures that governance accelerates value rather than blocking it.
Done well, these practices turn AI risk into a competitive moat. By pairing disciplined governance with pragmatic experimentation, we capture the upside of gen ai while protecting customers, teams, and the business. That’s how I’ve helped enterprises move from scattered pilots to measurable, scalable impact—safely.
Inspired by this post on Pendo – Perspectives.

Every week I meet teams eager to unleash AI-driven personalization across their products—and I share the same excitement. The promise is magnetic: experiences that feel tailor‑made, delivered at scale, and continuously optimized. Yet sustainable differentiation doesn’t come from turning every dial to eleven; it comes from clarity of intent, responsible design, and disciplined execution.
AI has us on the verge of a new age of ultra-personalized digital product experiences. But don't swing too big too early.
When I think about “how far is too far,” I anchor on user trust, explainability, and measurable value. If a personalization can’t be explained in a sentence, verified through A/B testing, or opted out of without friction, it’s a risk to both brand and product-market fit. The goal isn’t maximal personalization—it’s meaningful personalization that compounds retention and strengthens the value proposition.
I start with product discovery basics: who are the core segments, what jobs-to-be-done matter most, and where does personalization remove friction or accelerate time-to-value? That focus informs pragmatic AI Strategy. Instead of boiling the ocean, I’ll select one high-traffic, high-intent flow and define the precise outcome we want to move. Then I set outcomes vs output OKRs and instrument the path so I can track lift, variance, and trade-offs in real time.
Data governance is non-negotiable. Consent, transparency, and data minimization create the foundation for scalability. I document what signals power personalization, how long they persist, and who can access them. Strong governance isn’t a brake; it’s an enabler, letting us expand confidently without rework or reputational drag.
From there, I validate with A/B testing and clear minimum detectable effect (MDE) thresholds. Holdouts, guardrail metrics, and cohort analyses keep me honest. I’ll use Amplitude analytics to examine funnel impacts, retention analysis, and segment-level effects—especially to ensure we’re not improving conversion while harming long‑term engagement or fairness for smaller segments.
Early wins often come from onboarding and in-app guides. Personalizing the first five minutes—recommended next steps, contextual tooltips, or a tailored product tour—can deliver a step-change in activation with minimal risk. This is where product-led growth shines: relevant, timely nudges that shorten the path to the “aha” moment without feeling intrusive.
As we scale, gen ai and agentic AI open new frontiers. I’ve had success with assistants that proactively summarize account health, suggest next actions, or auto-draft content using the customer’s tone. But I always ship with transparency (“Why am I seeing this?”), controls (easy snooze or opt-out), and fallbacks (graceful degradation if signals are sparse). The human is still the hero; AI should play the role of a reliable, explainable copilot.
My implementation roadmap follows a crawl‑walk‑run arc. Crawl: rules‑based personalization in one journey; clear metrics and opt‑out. Walk: contextual recommendations using embeddings and feedback loops; continuous A/B testing. Run: agentic workflows that take multi‑step actions with approval gates and audit trails. Each phase is gated by evidence, not enthusiasm.
Finally, I treat personalization as a living system. I review dashboards weekly, continuously prune features that add complexity without durable lift, and socialize learning across product trios and empowered product teams. When personalization stays grounded in outcomes, ethics, and craftsmanship, it stops feeling “creepy” and starts feeling inevitable.
Personalization is not a stunt; it’s a capability. Build it with intention, measure with rigor, and earn the right to go deeper over time.
Inspired by this post on Amplitude – Perspectives.

When AI transformation is your mandate at enterprise scale, clarity and pragmatism matter more than hype. My approach to prepare 11,000 employees for AI—with role-specific training, modular design, and human-AI collaboration for better results—rests on three commitments: deliver outcomes tied to real workflows, meet people where they are, and make adoption safer and faster than the status quo.
I start with role-specific training because context beats generic content every time. For product managers, we focus on prompt design for discovery, prioritization signals, and faster hypothesis validation. For engineers, we emphasize code generation quality, test coverage, and secure patterns. For sales and customer success, we build repeatable workflows for research, personalization, and objection handling. Tailoring instruction to each team’s daily work drives confidence, reduces friction, and accelerates time to value.
Modular design is how we scale without sacrificing quality. I break the curriculum into atomic learning units—micro-scenarios, checklists, and in-app guides—that can be remixed into learning paths by role, seniority, and region. This enables just-in-time onboarding, easier updates as gen AI evolves, and localized relevance without reinventing the core. Product tours and embedded nudges reinforce learning in the flow of work, ensuring people practice where the value actually occurs.
Human-AI collaboration is a deliberate practice, not a slogan. We codify co-pilot patterns, checkpoints, and RACI-like ownership so humans remain accountable for outcomes while AI accelerates inputs. Agentic AI is introduced behind guardrails: clear data governance, prompt libraries with approved patterns, verifiable sources, and audit trails. The result is speed and consistency, paired with the trust that leaders and regulators expect.
Change management is where strategy becomes reality. I partner with empowered product teams to co-create playbooks, nominate champions, and sequence rollouts by readiness and impact. We keep a tight feedback loop via office hours, internal communities, and role-based enablement so adoption feels like a product we improve, not a policy we enforce. This is product management leadership applied to culture, not just software.
Measurement keeps us honest. I tie every enablement track to business outcomes—cycle time, win rates, customer satisfaction, and quality—validated through A/B testing where feasible. We monitor adoption, satisfaction, and proficiency, then iterate the content and tooling. When teams see their KPIs move, AI stops being an experiment and becomes part of how we win.
If you’re standing up your AI strategy, start small and specific, ship value fast, and scale through modularity. Role-specific training, modular design, and human-AI collaboration aren’t slogans—they’re a repeatable system for building durable capability across the organization.
Inspired by this post on Amplitude – Perspectives.

I just finished reviewing new findings on Japan’s marketing landscape, and the signal is clear: AI isn’t just a shiny tool—it’s a force multiplier for outcomes and careers. The headline that caught my attention, "Amplitude Releases New Research in Japan: Marketers are Unlocking Efficiency, Results, and Career Growth," aligns with what I’m seeing on the ground: teams that blend disciplined analytics with pragmatic AI adoption are pulling ahead.
Amplitude released a new survey of 500 Japanese marketers, which reveals how teams are benefiting from AI. Get the insights from the data
Here’s how I interpret the shift. AI accelerates the cycle from insight to action when it’s grounded in a unified analytics platform. With Amplitude analytics stitched into campaign and product signals, marketers can move beyond vanity metrics to diagnose true drivers of activation, engagement, and retention. That’s where efficiency compounds: fewer blind spots, faster iteration, and clearer attribution of what actually drives results.
On the strategy side, I’m seeing two dominant patterns. First, gen ai is speeding up creative workflows—audience research, message testing, and content generation—without sacrificing brand rigor. Second, agentic AI is emerging in operational loops: routing leads, prioritizing segments, and suggesting next-best actions based on behavioral data. The common denominator is data governance; without clean event schemas and consent-aware pipelines, AI amplifies noise instead of signal.
For product-led growth motions, this research validates what empowered product teams have practiced for years: instrument the customer journey, frame outcomes vs output OKRs, and experiment in short, learnable cycles. When marketing, product, and data join forces as true product trios, teams can run in-app guides and product tours, tune onboarding, and perform rigorous retention analysis that ties growth to product value rather than spend.
My playbook in this environment is simple but disciplined. Start with first principles decision making: define the problem, the decision, and the evidence required. Use a unified analytics platform to connect lifecycle events across acquisition, activation, and expansion. Align go-to-market strategy with product roadmapping and sprint planning, so insights move directly into experiments—not slide decks. Then close the loop with clear outcome metrics and QBRs that reward learning velocity, not activity volume.
There’s also a career arc embedded in this shift. Marketers who cultivate analytical fluency and AI literacy are becoming indispensable partners to product management leadership. They can articulate a differentiated value proposition, shape product positioning with live behavioral data, and influence board-level narratives with credible, causal evidence. That combination—story plus signal—unlocks both performance and professional growth.
My commitment going forward is to operationalize these lessons: tighter event taxonomy, sharper outcomes framing, and more systematic experimentation across channels and in-product touchpoints. With the right data foundation and a pragmatic AI strategy, we can convert curiosity into capability—and capability into repeatable growth.
Inspired by this post on Amplitude – Perspectives.

I’m fascinated by how the most credible legal-tech platforms operationalize AI in the enterprise, where risk tolerance is near zero and trust is the product. When I evaluate solutions in this space, I look for rigor in model design, governance, and go-to-market execution—not just raw model performance.
Discover how Luminance CEO Eleanor Lightbody builds Legal-Grade™ AI for enterprise. See how their specialized, agentic AI models lawyers trust at scale.
That framing resonates with me. “Legal-Grade™” isn’t a slogan; it’s a product requirement that implies auditable decisions, explainable outputs, robust data governance, and demonstrable accuracy under real-world legal workflows. “Agentic AI” adds another layer: autonomous orchestration of tasks with explicit guardrails, role definitions, and escalation paths to humans-in-the-loop.
From a product management perspective, I start with outcomes. For legal teams, the jobs-to-be-done are concrete: contract analysis and redlining, due diligence, compliance reviews, investigations, and eDiscovery. The success criteria are equally concrete: precision and recall on domain-specific clauses, latency under load, traceability of sources, and the ability to scale across matter types, jurisdictions, and languages without degrading trust.
Building that foundation requires deliberate AI strategy. I look for domain-specialized models, retrieval-augmented generation tuned to legal corpora, evaluation harnesses with gold-standard datasets, and continuous red-teaming. Just as important are deployment choices—on-prem or VPC isolation, encryption in transit and at rest, strict PII handling, and granular access controls—to satisfy the security posture of enterprise legal and compliance teams.
Governance is where “legal-grade” is won or lost. Robust audit trails, versioned prompts and policies, model cards, clear data lineage, and event logs that support defensibility are table stakes. Human review workflows, explainability tooling, and remediation paths ensure the system remains trustworthy when edge cases arise.
On product process, I favor empowered product teams and forward-deployed engineers partnering directly with attorneys and legal ops. Co-designing workflows with subject-matter experts surfaces the right constraints early: how redlines are presented, what confidence thresholds trigger review, and where to anchor the user experience in familiar legal tools and document structures.
Competitive differentiation and product positioning hinge on clarity: what specific legal outcomes are delivered faster, safer, or more accurately than alternatives? I prioritize transparent benchmarking against baselines, proof-of-value pilots that mirror production data conditions, and pricing that aligns to measurable outcomes (e.g., time-to-first-draft, review throughput, or risk reduction) rather than abstract usage metrics.
Go-to-market strategy in enterprise legal is a discipline in itself. Expect rigorous InfoSec reviews, stakeholder alignment across legal, IT, and procurement, and the need for customer references that demonstrate “trust at scale.” Clear messaging around value proposition, safety posture, and operational readiness shortens cycles and builds confidence among risk-averse buyers.
The big takeaway for product leaders: Legal-Grade™ AI isn’t about novel models; it’s about orchestrating specialization, safeguards, and enterprise-grade delivery into a coherent system that lawyers can rely on daily. When agentic AI is harnessed with the right guardrails and domain depth, it becomes a force multiplier for legal teams—accelerating work without compromising standards.
Inspired by this post on Amplitude – Perspectives.

The AI era didn’t just speed up product development—it rewired the economics of learning. Experiments that once took weeks now take hours, and the organizations that compound learning faster are the ones outpacing competitors. In my role guiding product strategy, I’ve seen this shift firsthand: velocity is table stakes; evidence is the differentiator.
Learn why market dynamics prove that experimentation is fundamental to driving growth in the age of AI.
When AI compresses build and distribution cycles, market feedback arrives in torrents. That abundance of feedback is valuable only if we can transform it into trusted insight. I anchor every initiative with a clear hypothesis, a measurable outcome, and a pre-committed decision rule—what we’ll do if the result is positive, negative, or inconclusive. This discipline converts experimentation from a set of ad hoc activities into a repeatable growth engine.
Data quality is non-negotiable. I rely on a unified analytics platform, pairing event instrumentation with Amplitude analytics to analyze activation, retention, and long-term impact. Strong data governance prevents metric drift and ensures that our “go/no-go” calls rest on sound evidence. Retention analysis, in particular, is my north star for separating novelty spikes from durable value.
Gen AI has transformed how quickly we can explore solution space. I use gen ai for product prototyping to generate multiple UX and copy variants in minutes, then deploy in-app guides and lightweight product tours to validate which concepts resonate. This dramatically lowers the cost of curiosity: we test more, earlier, with tighter feedback loops—without compromising user experience or brand voice.
Process and culture make this sustainable. Empowered product teams—tight product trios across Product, Design, and Engineering—run weekly sprints with explicit outcomes vs output OKRs. We plan small, falsifiable bets in product roadmapping and sprint planning, stack-ranked by expected impact and learning value. The result is a team that ships with confidence, measures with rigor, and iterates without ego.
Experimentation doesn’t stop at UX. I extend the same approach to go-to-market strategy and product-led growth motions: pricing page changes, onboarding flows, paywall copy, and packaging tests all roll through the same hypothesis-measure-decide loop. We bias toward reversible decisions, emphasize speed to signal, and codify what we learn into playbooks the whole organization can reuse.
Raising the bar on experimentation means raising the bar on clarity. Every test should answer a specific question, earn its way onto the roadmap, and connect to a value proposition we can defend. In a world where AI collapses time, the advantage goes to teams that compound learning with integrity and purpose. Start small, instrument well, close the loop—and let the data guide the next bold move.
Inspired by this post on Amplitude – Perspectives.

Vibe is more than a brand voice—it’s the emotional resonance customers feel at every touchpoint, from onboarding to support. As I’ve scaled products and go-to-market motions, I’ve learned that preserving that resonance while introducing AI is both a strategic advantage and a delicate balancing act. In this three-part series, I’m sharing the approach I use to unlock AI-powered velocity without sacrificing authenticity or trust.
Learn how to get the benefits of AI-powered vibe marketing without accidentally killing the vibe for your customers in part 1 of our 3-part series.
When I say “vibe marketing,” I’m talking about the consistent, context-aware expression of your brand’s personality across channels—delivered with precision and warmth. GenAI can amplify that consistency at scale, but without the right safeguards, it risks drifting into uncanny, off-brand territory. In Part 1, I’ll center on strategy and governance—how we set up the foundation so the vibe feels intentionally human, even when AI assists the work.
Start with clarity: document your brand’s voice, tone, and emotional targets. I create a living voice and tone guide with examples of “do” and “don’t” language, aligned to specific customer moments like activation, upgrade prompts, renewal nudges, and recovery from a failed workflow. This artifact becomes the north star for prompts, training snippets, and review criteria—so AI doesn’t invent a persona you never approved.
Next, map the end-to-end journey and choose high-leverage use cases where AI can enhance relevance without increasing risk. My favorite entry points are in-app guides, lifecycle emails, contextual tooltips, and product tours—places where we can A/B test safely, measure impact on activation and retention, and iterate quickly. Keep the highest-judgment moments—pricing, security, compliance, and incident communications—squarely human-led, with AI supporting drafts and analysis, not final decisions.
Guardrails are non-negotiable. I establish prompt patterns that include brand attributes, audience, channel, goal, and constraints (length, reading level, regional spelling, accessibility). We also implement a human-in-the-loop review for net-new narratives, plus automatic checks for tone drift, sensitive topics, and jargon density. When governance is clear, teams move faster with more confidence—and customers feel the cohesion.
Measurement keeps the vibe honest. I track leading indicators like message clarity scores, reading time, and click-through alongside business outcomes such as activation rate, conversion to aha moment, support deflection, and retention analysis. Segment results by persona and lifecycle stage to catch subtle mismatches—what delights power users can overwhelm first-time builders.
Pragmatically, I use GenAI for rapid prototyping of variations. We generate multiple voice styles aligned to the guide, then test them in controlled experiments. The winner becomes the new baseline, and we codify it back into our prompt library. That tight loop—prototype, test, codify—prevents ad-hoc drift and compounds learning across product, marketing, and customer success.
Finally, empower product trios to own the vibe where it matters most: inside the product. Your PM, design, and engineering leaders should collaborate on UX writing and microcopy patterns, ensuring that AI-generated suggestions harmonize with product positioning and value proposition. This is how vibe marketing transcends campaigns and becomes a product-led growth advantage.
In Part 2, I’ll share playbooks and prompt templates for high-impact channels, including onboarding sequences, upgrade nudges, and contextual in-app experiences. In Part 3, I’ll cover instrumentation and analytics patterns so you can operationalize learning across teams.
For now, here’s the checklist I use to avoid “killing the vibe”: a codified voice and tone guide, journey-mapped use cases with risk tiers, prompt patterns with constraints, human-in-the-loop review, automated tone and compliance checks, and outcome-oriented experiments measured against activation and retention. With that foundation, AI stops being a gimmick and starts being a force multiplier for authenticity and growth.
Inspired by this post on Amplitude – Perspectives.

I’ve spent the past few years building in what often feels like an AI tornado—intense velocity, shifting requirements, and unforgiving expectations for security and quality. When I think about how to turn that chaos into momentum, I’m reminded of a guiding prompt: "Learn how Aparna Sinha, SVP of Vercel, builds in the AI tornado quickly and securely. Aparna shares her practical advice for builders everywhere." That mandate resonates with how I lead product teams to move decisively while protecting our customers and our brand.
In practice, building quickly and securely starts with clarity. I anchor the team on a crisp value proposition, define outcomes over output, and align product discovery with a tight feedback loop. We plan with product roadmapping and sprint planning that front-loads risk: data governance, threat modeling, and privacy-by-design are non-negotiable guardrails. This lets us unlock developer velocity without compromising trust—precisely the balance elite product management leadership aims to achieve.
On the execution side, I use lightweight gen ai experiments to accelerate insight and reduce uncertainty. For gen ai for product prototyping, we spin up narrow, testable slices that validate feasibility, usability, and safety in parallel. Two-week iteration cycles, clear exit criteria, and a secure-by-default posture keep us honest. We instrument a unified analytics view to measure real outcomes, then double down where signal is strongest and deprecate what doesn’t move the needle.
Team topology matters just as much as process. I empower product trios to own customer value end-to-end, pair forward deployed engineers with design and PM for rapid discovery, and practice developer evangelism to amplify adoption patterns early. This creates the foundation for product-led growth: a self-reinforcing loop where users teach us what to build next, and we respond with precision. Strong stakeholder management keeps go-to-market aligned so we can scale learnings into repeatable wins.
Security is everyone’s job, not a final checklist. We embed data governance and compliance considerations from day one—so speed becomes sustainable, not reckless. The outcome is a product culture that moves fast with conviction: disciplined experimentation, clear decision frameworks, and a shared commitment to quality.
If you’re building in the AI tornado, focus on three levers: sharpen outcomes (what matters), reduce uncertainty (prove it fast), and codify trust (bake in safety). Do this consistently, and your team will ship faster with fewer reversals—while compounding credibility with customers and the market.
Inspired by this post on Amplitude – Perspectives.

I’ve learned that the fastest way to stall growth is to scatter your data across a maze of dashboards and point solutions. My guiding principle is simple: Escape fragmented tools with a unified analytics platform that accelerates growth, reduces costs, and empowers smarter, real-time decision-making. When every team can trust a single source of truth, momentum compounds.
By “unified analytics,” I mean a single platform that integrates product, marketing, sales, support, and finance data with consistent definitions, shared metrics, and strong governance. The right foundation pairs real-time instrumentation and event streaming with standardized taxonomies and role-based access. This is what transforms raw data into reliable insight that product managers and executives can act on with confidence.
Growth accelerates when hypotheses move faster from discovery to delivery. A unified analytics platform tightens the experimentation loop, informs product discovery, and aligns product roadmapping and sprint planning with measurable outcomes. It anchors outcomes vs output OKRs in trustworthy metrics, so QBRs and executive reviews focus on impact, not anecdotes. The result is clearer prioritization, sharper bets, and faster compounding wins.
Costs come down just as decisively. Consolidating analytics reduces redundant SaaS, manual reporting, and bespoke pipelines that are expensive to build and maintain. With one data model, we cut duplication, improve data quality, and negotiate smarter under consumption SaaS pricing. Teams spend less time wrangling CSVs and more time shipping value.
Real-time decision-making is where unified analytics truly pays off. Proactive alerts and cohort insights surface anomalies before they become churn. LTV, funnel, and retention forecasts inform pricing and packaging moves. Layering gen ai on top of clean, unified data speeds synthesis and narrative insight, while a thoughtful customer support AI strategy connects voice-of-customer signals directly to the roadmap.
Implementation starts with clarity. Identify the highest-impact decisions you want to improve, map KPIs to events, and instrument end-to-end tracking with quality SLAs. Establish governance early, align stakeholders across data, engineering, RevOps, and finance, and empower product trios to own their metrics. With disciplined stakeholder management and empowered product teams, the platform becomes a force multiplier rather than another tool to maintain.
The payoff is strategic agility: faster learning cycles, lower operating costs, and confident calls made in the moment, not after the fact. If you’re ready to break free from fractured dashboards and lagging reports, commit to a unified analytics platform and let your data become a competitive advantage.
Inspired by this post on Amplitude – Best Practices.

AI has changed the tempo of product management, but not the timeless fundamentals. I’m living that paradox daily: the technology reshapes how we plan, build, and ship—yet the way we find real customer value hasn’t budged. Here’s how I reconcile both truths in practice.
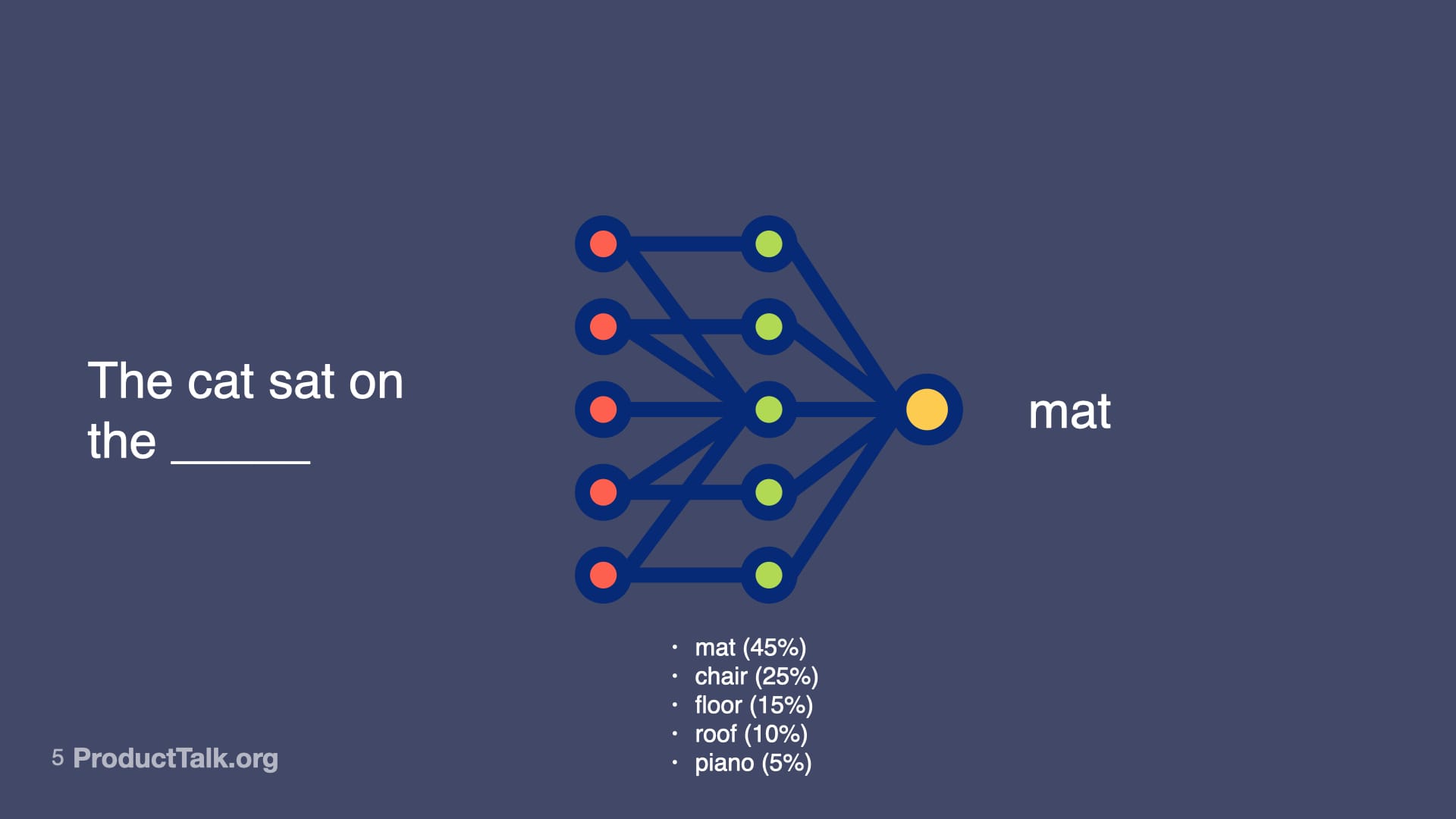
At their core, large language models predict the next token. That’s it. Consider the prompt, “The cat sat on the ____.” Mat is most likely. Chair is pretty likely. Floor, roof, piano—all possible, just less probable. When you give an LLM a prompt, it runs through a neural network—billions of parameters making calculations—to predict the most likely next word, then the next, then the next. That neural net represents not just facts, but relationships, patterns, context—and some might even argue reasoning capabilities—that all influence the probabilities of different outputs. So LLMs don’t just predict the next token. They predict the next token by drawing upon a vast amount of knowledge. LLMs are transformational.

And yet, AI makes silly mistakes. The kind that make you wonder how it could be so smart and so dumb at the same time. No matter how hard I tried, I could not get ChatGPT-5 to fix the closing quote on an image. And it took 12 seconds of thinking to figure out that I asked for a meeting summary but didn’t include any meeting notes. Why do LLMs make these mistakes? Well, it’s because all the LLM is doing is predicting the next token based on patterns. And sometimes those predictions are wrong. And when it’s wrong, it can be confidently wrong. So what do we do?

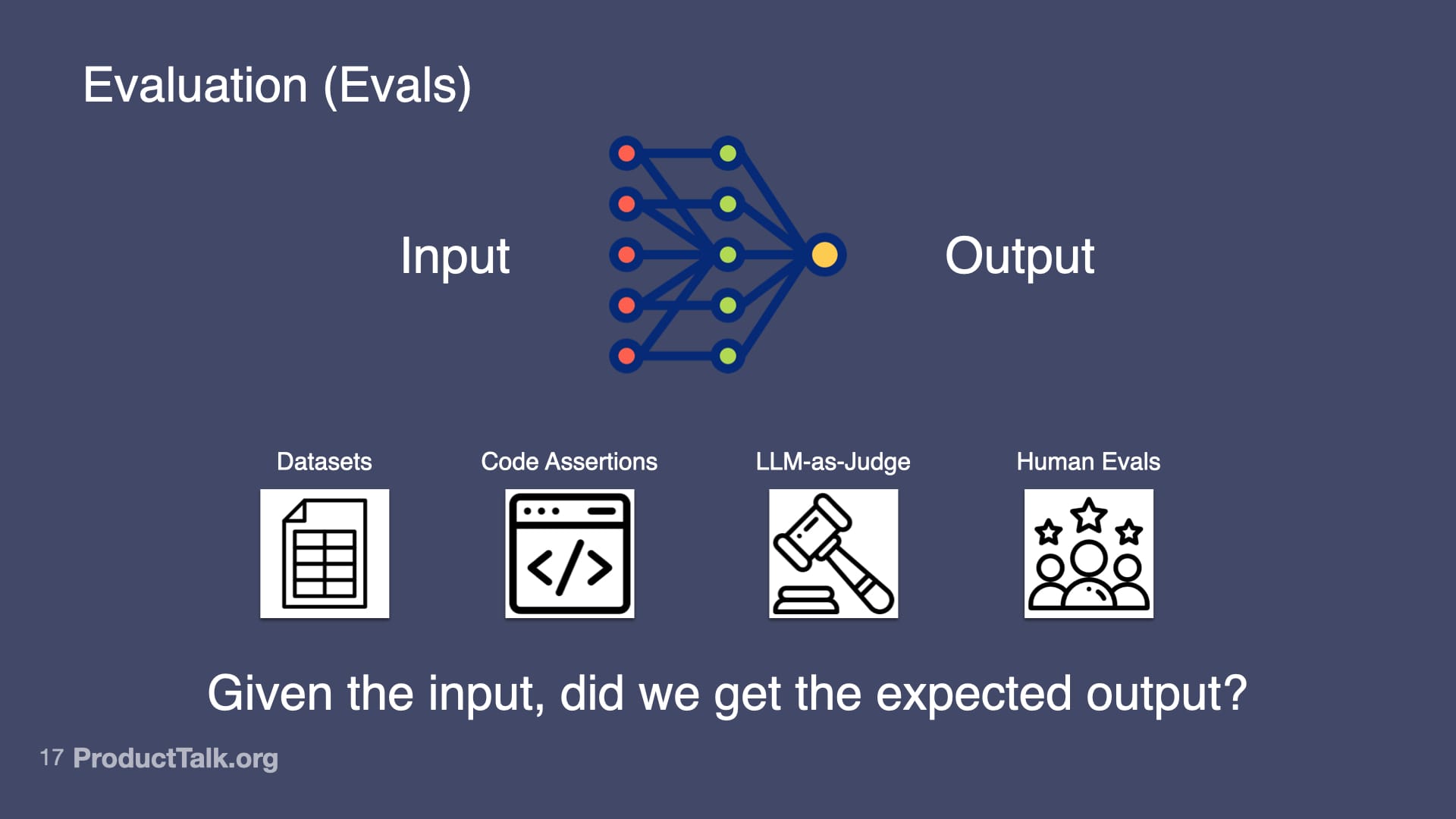
To build reliable AI features, I focus my team on four core skills: prompt engineering, context engineering, orchestration, and evaluation (evals). Together, they let us harness what’s powerful about generative AI while reducing unforced errors.
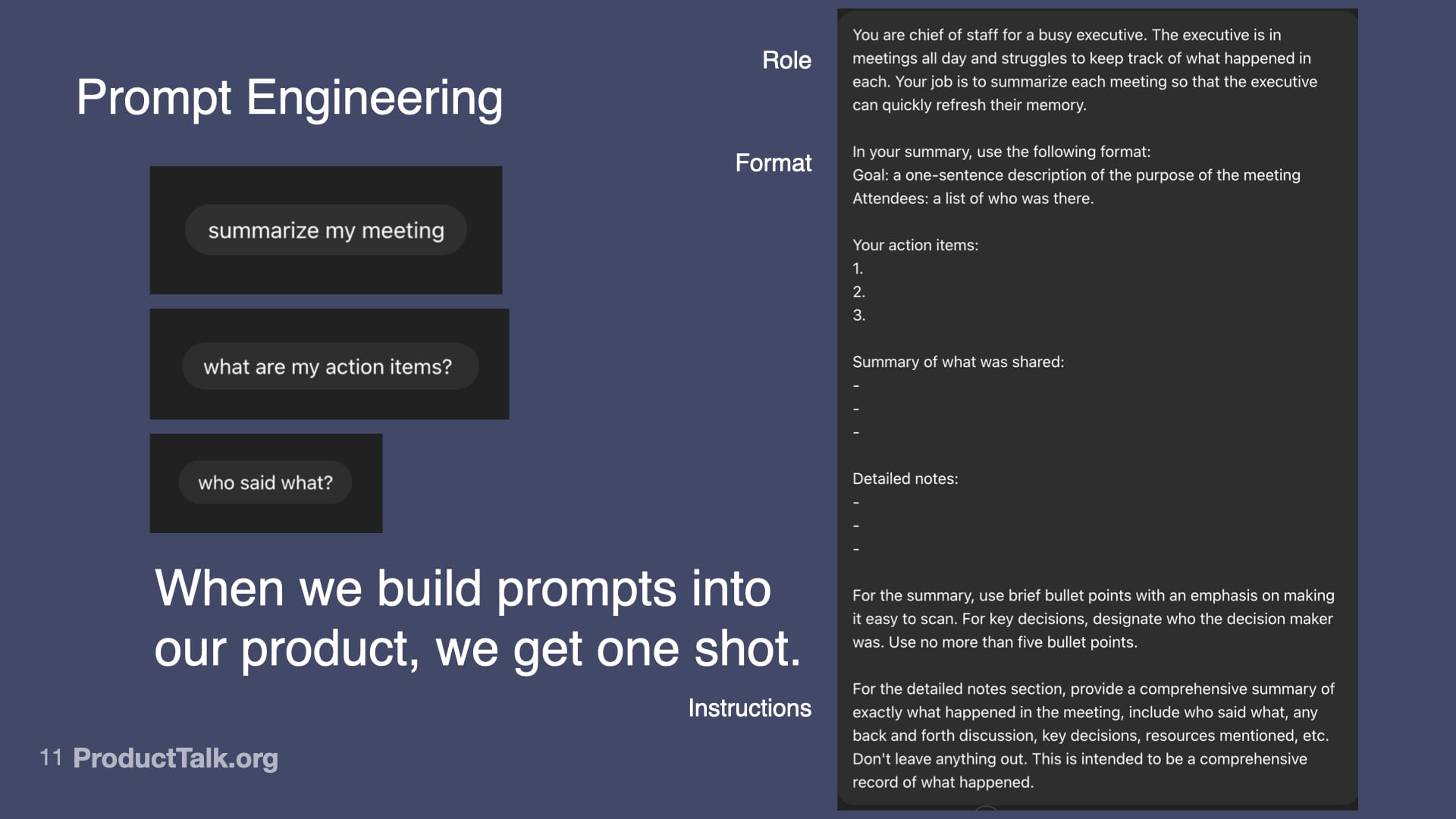
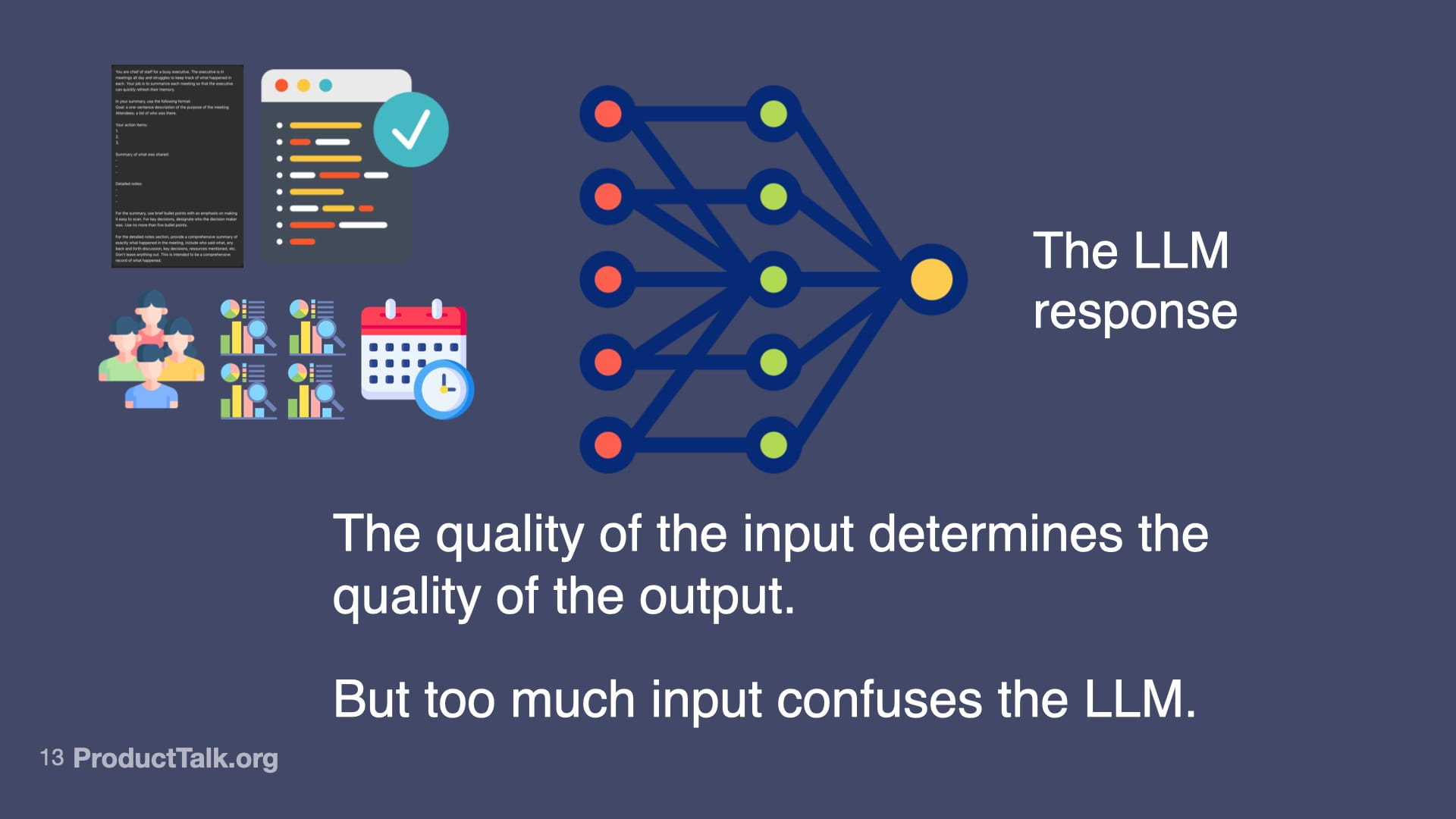
First, prompt engineering. With LLMs, the quality of the input determines the quality of the output. An LLM can’t guess what you want. You have to specify what you want in a language the LLM understands. In a chat, you can iterate with multiple turns. In a product, you get one shot. When we ship a meeting summarizer, for example, I design a production-ready prompt that assigns a role (“You are a chief of staff for a busy executive…”), specifies output format (e.g., a structured list of action items), and clarifies exactly what to include and how to structure it. This is prompt engineering. It’s like writing a really good product spec—but for an AI.
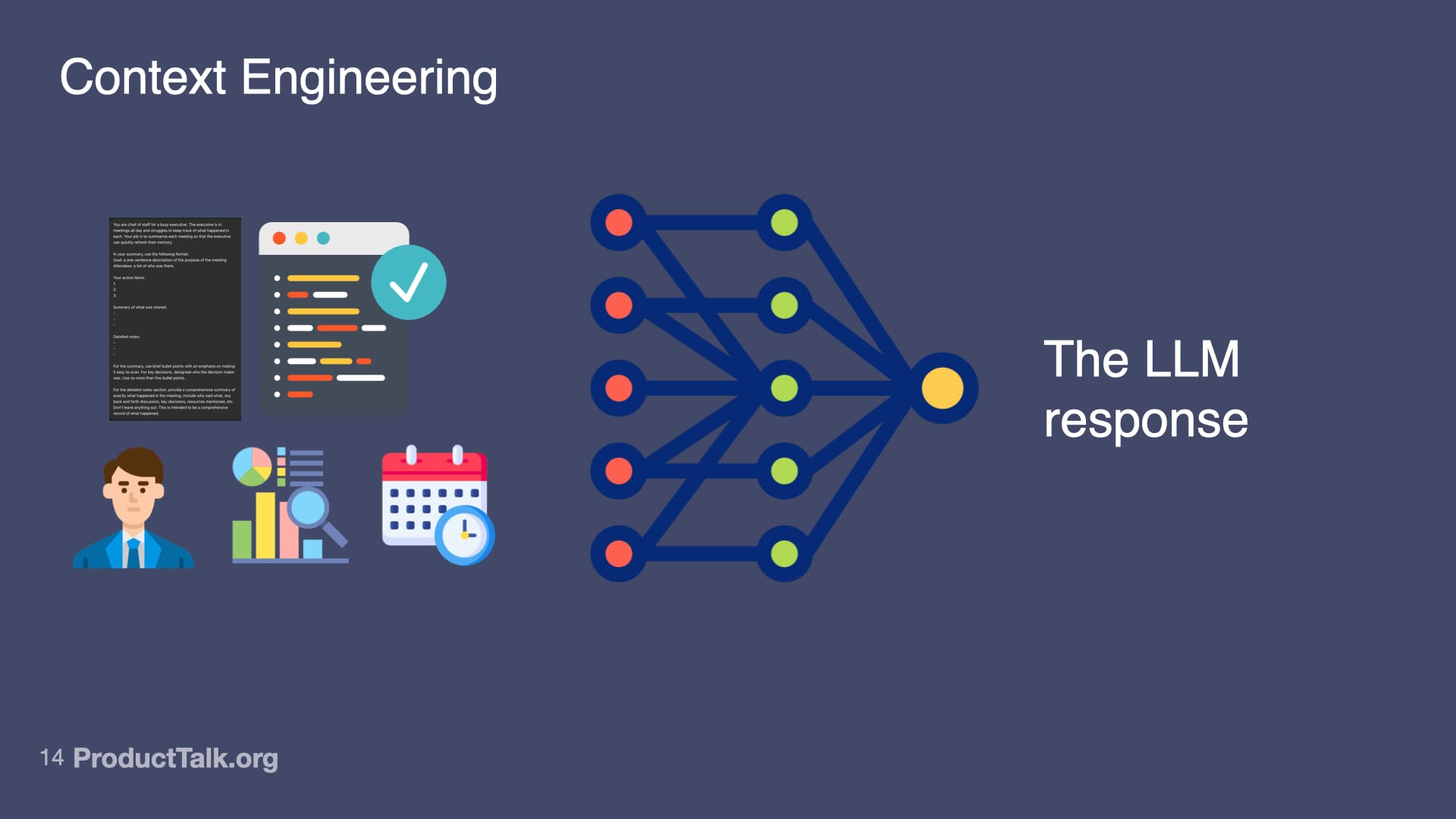
Second, context engineering. LLMs know a lot, but not everything. Imagine a takeaway reads, “Send the pipeline report to John by Friday.” When is Friday? Which John? What is the pipeline report? The model lacks today’s date, the roles of participants, and the specifics of our reporting vocabulary. If you dump every possible detail into the prompt, the model gets noisy input and the quality drops. The key is to add only the context the LLM needs to do the task at hand and nothing more. This is where techniques like RAG (Retrieval Augmented Generation) shine: retrieve just the relevant snippets—e.g., attendee roles, the precise definition of “pipeline report,” and the calendar context for “Friday”—and include only those in the prompt.

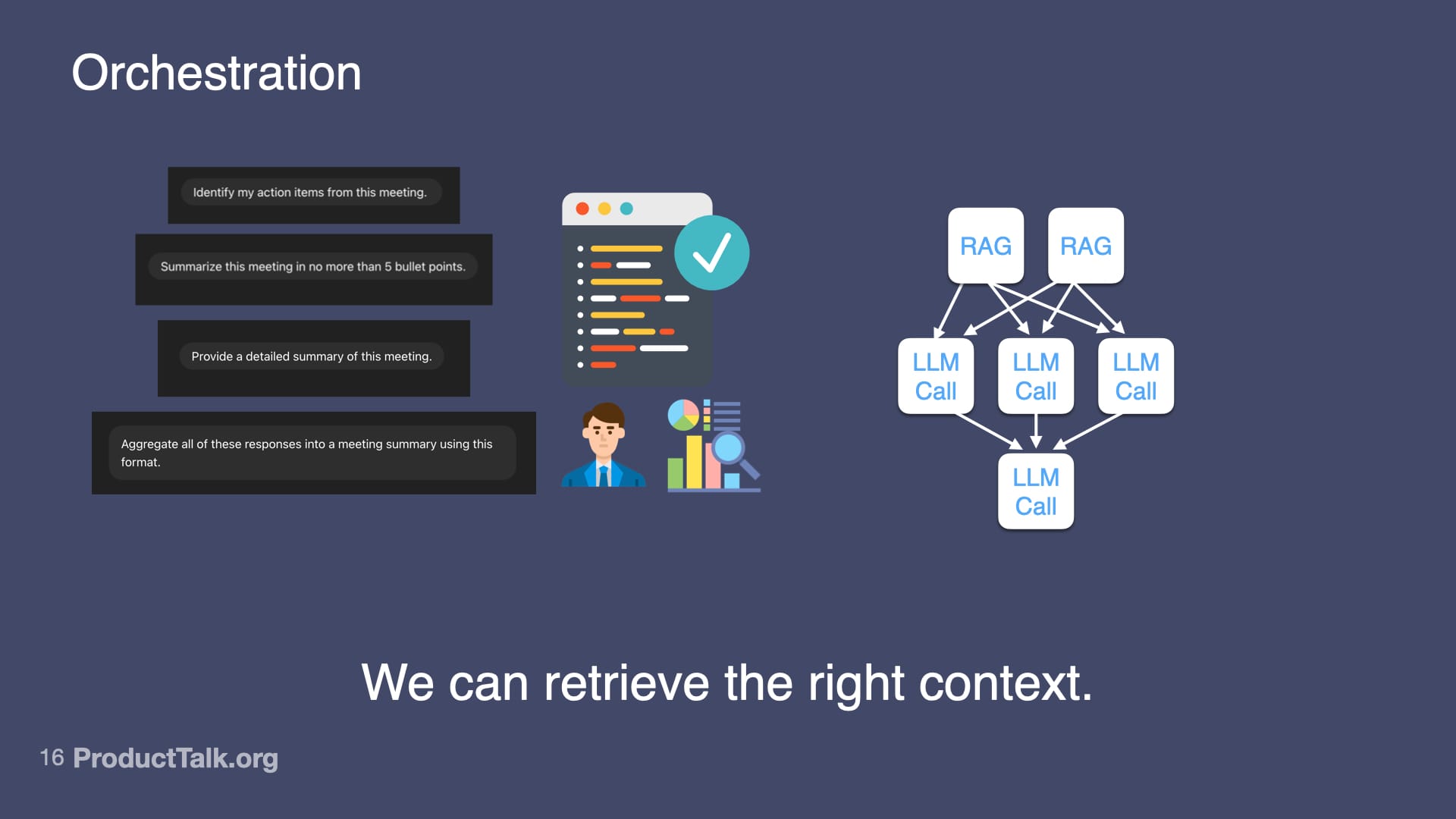
Third, orchestration. LLMs are better at simpler tasks. If you try to do everything in one prompt—identify action items, summarize the meeting, categorize by urgency, match to owners, check for clarity—the quality goes down. But if you break it into steps, each focused on one thing, the quality goes up. I design a workflow of multiple LLM calls that work together. For example: First call: identify action items from the transcript. Second call: categorize by urgency using lightweight project context. Third call: match to owners with a minimal team directory. Fourth call: generate calendar events via an API. Each step is simple. But together, they create something sophisticated.
Fourth, evaluation (evals). Otherwise known as: Is my AI product any good? At the heart of evals is this question: Given the input, did we get the expected output? I use several approaches. Datasets: I collect 20–100 real examples, define expected outputs, run the prompt, and measure the success rate. Code assertions: I enforce rules the output must follow (for example, “Every action item must have a task, owner, and deadline”) and fail the test when they’re violated. LLM-as-Judge: I use a model to verify factuality (e.g., “Is each item in this summary in the meeting transcript? Yes or no.”). Human evals: I track whether users need to edit the output and by how much. Start simple; get more sophisticated as the stakes rise.

Here’s the hard truth: you can master all four skills and still ship the wrong thing. Why? Because you chose the wrong problem to solve. Who needs yet another meeting summarizer? The ease of building with generative AI tempts us to jump straight to solutions. Resist it.

Discovery matters more than ever. Before writing your first prompt, be explicit about the impact you want and set a clear outcome. Talk to your customers and ensure you understand their needs; choose the right opportunity before you chase a cool solution. Explore multiple options and use assumption testing to converge on what will actually move the needle.
Prototype, test, and build iteratively. With AI products, it’s easy to get to a great demo and hard to get to a production-grade experience. I validated feasibility before I wrote a line of production code by experimenting directly in a model’s UI, pasting real transcripts, and shaping the system instructions and output format. Only after I had a repeatable prompt and useful feedback did I worry about deployment.
From there, I tested deployment paths with the smallest viable investment. I tried a custom chat in Replit and embedded it. It wasn’t the right interaction model for targeted feedback. I switched to a submission flow using a homework-style pattern: students upload their transcript, the system processes it, they get detailed feedback. Done. That worked—until automation reliability lagged. I wired it up in Zapier, then rebuilt it on AWS Step Function for robust retries and better error handling when scale introduced edge cases.

Each iteration tested a different assumption. Iteration 1 (Claude): Can AI even do this? What makes good feedback? Iteration 2 (Replit chat): How should people interact with it? Iteration 3 (Zapier): Can I integrate this into the existing workflow with minimal engineering? Iteration 4 (Step Functions): How do I make it reliable at scale when things inevitably go wrong? I didn’t know the answers up front; I learned by building, shipping, and observing.
Ethical data practices are non-negotiable. Improving AI products requires inspecting traces—the user input, system prompts, tool calls, and LLM responses. For a coaching flow, that includes the uploaded transcript, the system prompts that define evaluation criteria, and the AI’s feedback. To fix issues, I look at traces where things went wrong—but only with explicit user permission. Too many AI products collect everything by default and review traces without clear consent. Don’t do this.
In my products, users must explicitly grant permission for me to review their data. The consent is clear and specific. If they say no, I don’t see their data. Full stop. That forces me to rely on synthetic data for many tests and to engineer privacy into the architecture from day one rather than bolt it on later. It’s the right thing to do, and increasingly, it’s required.

Everything changes—and nothing changes. Yes, there are new skills you should master: prompt engineering to get the right output the first time; context engineering to give the LLM exactly what it needs; orchestration to decompose complex tasks into simpler steps; and evals to systematically measure quality. And the fundamentals still rule: solve the right customer problems with strong discovery; prototype and iterate to de-risk; and uphold ethical data practices as a design constraint, not an afterthought. The teams that win with AI will master both the new technical craft and the timeless product fundamentals.
If this resonates, pick one active workflow, apply the four AI skills end-to-end, and run a short discovery and eval cycle against a clear outcome. Then ship. You’ll learn faster than any slide deck could ever teach you.
Inspired by this post on Product Talk.