Every week I meet marketers who are working harder than ever—more campaigns, more content, more dashboards—yet seeing less movement on metrics that matter. The surge of AI tooling has amplified activity, not necessarily impact. That’s the focus problem: we confuse motion with momentum, and our backlogs look great while our outcomes stall.
Learn how AI agents for marketing can help you prioritize impact so you can do important work, instead of just more work.
In my role leading product and growth teams, I’ve learned that AI only compounds value when it is pointed squarely at outcomes. If we don’t define what “good” looks like, agentic AI will simply scale busywork. The antidote is a disciplined operating model that connects strategy to execution and instruments agents with clear success criteria.
First, anchor your program with outcomes vs output OKRs. Choose one or two measurable business outcomes—such as qualified pipeline, conversion rate, or activation—and make everything else subordinate. This provides the compass agents need to make effective trade-offs when speed and volume tempt you to do “one more thing.”
Second, map a driver tree from the target outcome down to the controllable levers: audience segments, offers, channels, messaging, and experience friction. This traceability shows where agents can move the needle fastest—whether that’s accelerating research, sharpening positioning, or eliminating handoffs that slow experimentation.
Third, design a small, agentic AI workforce aligned to those levers. For example: a Research Agent that synthesizes market insights and past performance; a Copy Agent that generates on-brief, on-brand variants; a Distribution Agent that adapts content to each channel and schedules posts; and an Analytics Agent that runs A/B tests, summarizes results, and flags anomalies. Keep human oversight where judgment matters most—strategy, brand voice, and high-stakes decisions.
Fourth, instrument rigor from day one with Agent Analytics and eval-driven development. Define offline evals for brand consistency, factuality, safety, and response time; pair them with online experiments that quantify lift on your target outcomes. Set a minimum detectable effect (MDE) so you stop shipping changes that cannot plausibly move the metric.
Fifth, operationalize your AI workflows. Standardize prompts, inputs, and handoffs; templatize briefs and acceptance criteria; and keep a change log so improvements compound rather than reset. Use short, frequent feedback loops to prune low-impact work and double down on what demonstrably advances your objectives.
I’ve seen teams reclaim focus and momentum when they treat agents as teammates, not toys. The magic isn’t in producing more assets—it’s in consistently choosing the next best action in service of a clear outcome. When you combine outcome clarity, a driver tree, targeted agents, and tight evals, AI becomes a force multiplier for marketing impact.
If you’re feeling overwhelmed by AI’s possibilities, start small: commit to one outcome, one driver you believe is material, and one agent designed for that job. Prove lift, codify the workflow, then scale. Velocity is only valuable when it’s pointed in the right direction.
Inspired by this post on Amplitude – Best Practices.
I’ve long believed the people function is a strategic engine, not a support lane. That conviction was only reinforced in a recent deep dive with Katie Burke, now COO at Harvey after joining as Chief People Officer. Before Harvey, she spent 11 years in HR leadership at HubSpot, helping build one of tech’s most distinctive cultures. In this piece, I unpack what resonated most for me as a product leader: a marketing-minded approach to HR, deliberate hiring from hospitality, and the non-negotiable case for culture as a core business strategy.
The first principle is simple and often overlooked: HR leaders should think like marketers. Employer brand is a product; your candidate and employee journeys are funnels; and your programs deserve the same rigor we bring to product—segmentation, positioning, channels, and continuous A/B testing. When we treat onboarding, performance, and manager enablement like iterative product launches—complete with activation metrics, retention curves, and NPS—we stop guessing and start compounding results.
One line has become a north star for how I approach executive leadership: “Don’t ask for a seat at the table. Build the table.” In practice, that means codifying the operating system—decision rights, principles, cadences, and accountability—so the organization isn’t improvising strategy in every meeting. Product, People, and Finance should co-own this OS; that’s how you scale clarity faster than headcount.
Transparency is the tax we pay for alignment, and it compounds trust. After an IPO, the impulse can be to close ranks. The better move is radical transparency with context: what changed, why it matters, and how decisions get made now. On my teams, that looks like publishing decision records, sharing tradeoffs explicitly, and using written docs to reduce rumor velocity—core muscles in stakeholder management as complexity grows.
I also loved the counterintuitive hiring bet: prioritize hospitality backgrounds alongside traditional corporate pedigrees. People who’ve thrived in service environments bring customer empathy, operational resilience, and a bias for proactive care—traits that elevate everything from onboarding to incident response. In product terms, they’re culturally accretive hires with high signal on service quality and consistency.
The trickiest part of the Chief People Officer role isn’t process—it’s politics. You are the executive team’s own HR business partner, which requires coaching, candor, and conflict mediation at the highest stakes. The goal is to “Be the Michael Jordan of your exec team”—the teammate who elevates standards, makes others better, and chooses the hard right over the easy familiar.
Layoffs create a culture debt that accrues interest. Expect a “2.5-year cultural hangover after a layoff”—in many companies, an inevitable two-year layoff hangover—unless you actively repay it. That repayment plan includes narrating the why with specificity, rebuilding trust through manager enablement, and re-anchoring on performance and values. Measure leading indicators (manager effectiveness, time-to-decision, psychological safety) alongside lagging ones (regretted attrition) to track the true recovery arc.
People leaders also need to create “graceful exits.” Doing this well preserves dignity for the person, protects the team’s morale, and safeguards the company’s brand. The bar is straightforward: clear rationale, fair process, useful feedback, generous support, and alumni pathways. A graceful exit signals that even when business realities bite, respect is non-negotiable.
Expectation-setting matters. Two truths cut through the noise: “The workplace shouldn’t be Disneyland” and “Our job is not to make you happy every day.” The promise is not perpetual happiness; it’s meaningful work, fair standards, growth opportunities, and leaders who tell the truth. When we set that contract clearly, engagement becomes an outcome of purpose and progress—not perks.
On feedback, I use the protein vs. sugar rule for employee feedback. Sugar feedback is pleasant and perishable; protein feedback is specific, sometimes uncomfortable, and growth-driving. Great cultures build a taste for protein—clear role expectations, crisp examples, and written follow-ups. Mechanically, that looks like structured 1:1s, decision retros, skip-levels, and manager training that demystifies “what good looks like.”
Being a Chief People Officer isn’t for the faint of heart. The role must be demanding by design—on executive hiring quality, performance management courage, and values enforcement. Moments like “Berry-Gate” are reminders that small symbolic issues can balloon when feedback loops are unclear. Close the loop fast, publish the rationale, and ensure there’s a predictable path for concerns to be heard and resolved.
When hiring, beware patterns that predict friction. That’s why “frequent flyers” are a new-hire red flag. Movement can signal adaptability—but weather-vein pivots and blame-shifting often repeat. Probe for ownership, learning moments, and sustained impact; you want people who compound value, not just sample it.
Clarity on scope prevents leadership whiplash. Which company decisions fall to the Chief People Officer? Think leveling frameworks, compensation philosophy and bands, performance calibration, manager standards, ER policies, and org design guardrails—always in lockstep with Finance and the CEO. Escalate when there are values collisions or systemic risks; otherwise, push decisions to the right altitude and owner.
Scaling exposes the same few failure modes on repeat: fuzzy decision rights, a thin manager bench, brittle processes that don’t flex, and inconsistent leveling that erodes trust. The antidote is an operating model that pairs clear principles with lightweight mechanisms—documented roles, regular calibration, and reviews that audit for both outcomes and operating behaviors.
Comparing a scaled SaaS like HubSpot with an AI-native company like Harvey surfaces important differences. The former optimizes for durable systems, predictable cadences, and governance; the latter optimizes for rapid learning loops, emergent org design, and a higher tolerance for ambiguity. The art is porting the right controls at the right time without crushing velocity.
AI is already changing the people function. GenAI can draft job descriptions, summarize performance notes, classify themes from engagement surveys, and power AI workflows that resolve common HR tickets. The human-in-the-loop remains essential for judgment, context, and ethics—especially around data governance and privacy-by-design. A pragmatic AI Strategy here frees HRBPs for higher-order coaching and organizational development work.
One practice I recommend widely: share your own performance reviews. Modeling openness normalizes growth and turns feedback into a shared craft, not a secret ritual. It also builds trust when you later ask the organization to lean into sharper, protein-rich feedback.
Finally, disagreements with the CEO are inevitable—and healthy. Handle them with pre-briefs, crisp written proposals, explicit tradeoffs, and a shared decision record. Argue like scientists, not politicians; once a call is made, disagree and commit. That combination of candor and alignment is what keeps executive teams high-trust and high-velocity.
The people leader’s chair may be the most politically dangerous role in the C-suite—but it’s also one of the most leveraged. Build the table, tell the truth, design for standards and dignity, and treat culture like the product that powers everything else.
Every planning cycle, I feel the drumbeat: “Show me the AI ROI—this quarter.” The pressure is real, especially when boards and CFOs expect immediate payback. Yet when I review stalled initiatives across teams and peers, the pattern is consistent: most companies treat AI like a feature to ship, not a system to manage. That mindset almost guarantees we measure the wrong things, declare victory (or failure) too early, and miss the durable value AI can create.
Here’s the core problem I see: we leap to solution and skip the counterfactual. Without a baseline, a clear control, or a defined “what would have happened otherwise,” we’re guessing. We also fixate on lagging, financial KPIs that move slowly (revenue, cost, risk), then use outputs—not outcomes—as OKRs. If we don’t align on outcomes vs output OKRs upfront, the best team in the world can still optimize for activity over impact.
My AI Strategy starts from a simple truth: value shows up along three vectors—revenue, cost, and risk—on different timelines. In the near term, we must validate leading indicators (adoption, engagement, activation) that ladder to those vectors through a transparent driver tree. Over time, those drivers compound into the lagging KPIs finance cares about. When we make the driver tree explicit, everyone can see how model precision, response time, and workflow integration roll up to conversion lift, case deflection, time-to-resolution, or reduced exposure.
To make this rigorous, I run a five-step playbook. First, define the decision and business outcome in plain terms. Second, instrument the baseline with behavioral analytics on a unified analytics platform—tools like Amplitude analytics or Pendo help expose friction points we’ll later target. Third, create a counterfactual using A/B testing and specify a minimum detectable effect (MDE) so we know how long to run and how much traffic we need. Fourth, quantify costs (training, inference, integration, change management) and include AI risk management, privacy-by-design, and data governance up front. Fifth, lock a measurement plan that connects leading indicators to lagging ROI through the driver tree.
Most AI initiatives don’t fail on model quality—they fail on adoption. If the workflow isn’t smoother, trust isn’t earned, or value isn’t obvious, users revert. That’s why I invest early in onboarding, in-app guides, product tours, and thoughtful tooltip design to reduce the time-to-first-value. Then I watch user activation, retention analysis, and task completion to ensure the assistive experience is not just novel—it’s habit-forming.
For generative use cases, eval-driven development is non-negotiable. I maintain offline evaluations for accuracy and safety, and online evaluations for business impact. Retrieval-first pipeline health, context window management, and prompt engineering affect reliability; so do latency and grounding quality. We ship behind feature flags, measure guardrail effectiveness, and tighten feedback loops from human-in-the-loop reviews into model updates—continuously.
On the business side, I avoid “AI theater” by structuring benefits like a CFO. Revenue: increased conversion or expansion driven by better recommendations, faster sales cycles, or higher trial activation. Cost: case deflection, agent time saved, fewer escalations, and lower rework. Risk: reduced exposure via automated checks, anomaly detection, and consistent policy application. If any claim can’t be tied to measured deltas—via A/B testing or strong quasi-experiments—it doesn’t go in the deck.
Build vs buy deserves the same discipline. I map platform scalability, governance requirements, and total cost of ownership against time-to-impact. Teams often underestimate integration and maintenance drag; a pragmatic mix of bought components with thin custom layers can accelerate outcomes while keeping options open. The goal isn’t to own every layer—it’s to own the learning loop and the differentiated experience.
I also remind teams that tooling should serve the strategy, not replace it. I’ve seen concise, effective messaging that captures the point: “Increase revenue, cut costs, and reduce risk with Pendo’s Software Experience Management platform. Optimize the entire software experience to drive adoption and improve engagement.” The words are compelling because they reflect the three-vector value model and the adoption imperative. The same standard should apply to any AI initiative we propose.
If you’re under pressure to prove ROI, shift the conversation: lead with the driver tree, specify your counterfactual, and anchor on leading indicators you can move in weeks—not quarters. Then connect those to the lagging KPIs finance expects over time. When we manage AI like a product—grounded in evidence, experimentation, and user-centered adoption—we don’t have to force ROI. We compound it.
Lately, it feels like every morning brings a new AI launch, a dazzling demo, or a must-try tool. I love the pace of innovation, but the constant stream can trigger counterproductive FOMO if I’m not intentional. As a product leader, I’ve learned to turn that anxiety into a disciplined learning system—one that keeps me curious without letting novelty hijack my focus.
That’s exactly why this conversation with Petra Wille and Teresa Torres resonated with me. They explore how to stay experimental in the AI era without chasing every shiny object. Their perspective aligns closely with my own operating cadence: start with real problems, go deep on a small set of tools, and create explicit boundaries between work, learning, and play.
Listen to this episode on: Spotify | Apple Podcasts
Here’s the mindset I apply. I don’t start with tools—I start with problems. When I encounter concrete friction in a workflow or see a credible opportunity to improve an outcome, that’s my trigger to explore a new capability. This mirrors the continuous discovery habit of prioritizing opportunities over solutions, and it’s how I avoid performing “innovation theater.”
To keep exploration healthy, I time-box my learning. I block recurring windows specifically for experiments, reading, and hands-on trials so they don’t overrun my core product work. During these blocks, I’ll set a clear question, run a tight test, and capture what I learned. No rabbit holes, no endless tinkering.
I also separate “interesting” from “actionable.” Plenty of inputs are worth awareness, but very few deserve immediate action. I bookmark the rest for later. This simple filter reduces cognitive load and keeps my backlog—from ideas to proofs of concept—well-governed.
Social media can amplify technology hype cycles, so I establish boundaries. I batch consumption, mute low-signal channels, and prioritize practitioner communities over performative threads. The goal isn’t to be first; it’s to be right for my customers, my team, and our strategy.
When choosing what to try next, I use a practical rubric. Does the tool target a real friction I’ve seen in discovery or delivery? Can it plug cleanly into our AI workflows without unsustainable glue work? Do we have a safe, compliant way to test it? Is there a plausible path from trial to compounding value? If the answer isn’t a confident yes to most of these, I wait.
Depth beats breadth. I’d rather take one promising tool into a real use case, instrument it, and measure outcomes than skim ten trending demos. That tighter loop produces sharper intuition, clearer product bets, and better partner decisions. A quick opportunity solution tree helps me connect user pain to outcomes before I let any solution onto the field.
In the episode, Petra Wille and Teresa Torres talk candidly about managing FOMO, deciding which tools to explore, and designing intentional learning systems. They discuss why starting with a problem is more valuable than starting with a tool, how social media amplifies technology FOMO, and why going deeper with fewer tools can lead to better learning. If you’ve ever felt like you’re falling behind because you haven’t tried the latest AI tool yet, this conversation will help you rethink how you approach learning and experimentation.
If you’re curious about what came up, here are some of the tools and communities mentioned: Claude Code, OpenClaw (formerly Clawdbot, Moltbot), NotebookLM, Product Talk, ElevenLabs, Lenny’s Newsletter Community, and even a nod to Bridgerton for a touch of levity.
My takeaway is simple but powerful: curiosity doesn’t require constant experimentation. The best product managers cultivate a balanced system—grounded in product discovery, energized by focused experiments, and protected by clear boundaries—so we can learn faster while staying pointed at outcomes that matter.
Discussion Question: How do you decide which new tools or technologies are worth exploring—and which ones you can safely ignore?
“Continuous Discovery Habits” turns five this year, and I’m celebrating by reading it with our community—together, in practice, not just in theory. Each month, I’m publishing an in-depth reading guide with the chapters we’ll cover, a preview of the most important concepts, short videos you can share with your teams, individual and team discussion questions, practical exercises to apply what you read, and additional resources to go deeper.
We’ll keep the conversation active in the comments each month and meet live once a quarter to compare notes, share what’s working, and troubleshoot what’s not. If you’re joining late, no problem—start with the current month or go back to January. You can also find all of the book club articles here.
If you want to participate, grab a copy of the book (or dust off your old one), share the “Spread the Love” videos with colleagues, block time for the team exercises, and register for the community sessions. Let’s dive in together.
This chapter grounds us in why interviewing on a regular cadence is critical to the success of any product trio; how cognitive biases affect what we learn from direct questions; the difference between research questions and interview questions; how to use story-based interviewing to uncover actual customer behavior (not ideal behavior); the interview snapshot, a one-page tool for synthesizing what you learned from a single interview; how to automate the recruiting process so interviewing becomes easier than not interviewing; and why product trios should interview customers together.
Need a copy? Grab the book.
Share the Love with Friends and Colleagues
We learn best in community. To help your team rally around these practices, share these concise primers and invite them to join the book club discussion with you.
What are customer interviews? – Build a competitive advantage that compounds over time.
What should we ask in customer interviews? – Mitigating cognitive biases.
Research questions vs. interview questions – And why the difference matters.
Getting reliable feedback from customer interviews – Ask the right questions.
Who should conduct customer interviews? – My answer might surprise you.
How do you find customers to interview? – Automate the recruiting process.
The Interview Snapshot – How to synthesize a single customer interview.
Reflect and Discuss What You Read
Reflection cements learning. This month, I’m challenging you—as I challenge my own teams—to build a weekly habit of interviewing customers and to shift from direct questions (which trigger bias) to collecting specific stories about past behavior. For many teams, this is a big mindset change: from infrequent “big research projects” to lightweight, continuous conversations that fuel daily decision-making.
Individual Reflection: Think about your last customer interview or conversation. Did you rely on direct questions, or did you excavate a specific story about what happened? How might the answers have changed if you had used the other approach?
Consider your own behavior—buying jeans, going to the gym, choosing what to watch on Netflix. Where do your ideal intentions differ from what you actually do? How might that same gap show up in your customers’ answers to direct questions?
Scan your calendar from the past month. How many customer interviews did you conduct? If it’s fewer than four, what got in the way? What needs to change to make weekly interviewing sustainable?
Team Discussion: As a team, discuss your current interview cadence. If you’re not interviewing at least weekly, name the biggest obstacle—recruiting, time, or synthesis—and commit to reducing one barrier this month.
Try this together: Ask a teammate, “How does a product idea go from concept to launch at our company?” Have them write it down. Then ask for the last specific feature or improvement that launched and capture the story. Compare the two. What’s different? What does this reveal about the gap between ideal process and actual process?
If you already interview regularly, ask: Who participates? Is it just one person (like the designer or product manager), or does the whole trio join? What value might you be missing by not having all three perspectives in the room?
Put It Into Practice
Understanding the “why” is easy; building the habit is the work. The following exercises are how my teams operationalize continuous interviewing week over week.
Exercise: Conduct a Story-Based Interview (Time: 20–30 minutes. Do this with your product trio.) Schedule a conversation with a current customer. Instead of drafting a long script, identify a handful of research questions (what you need to learn) and translate them into one story-based interview question (what you’ll ask).
For example, research questions might include: What challenges do customers face when onboarding? Where do they get stuck? What are we asking them to do that they don’t understand? How can we make it easier for them to get to the activation moment? The corresponding interview question could be: Tell me about the first time you used our product.
During the interview, excavate the story with temporal prompts like “What happened first?”, “What happened next?”, and “What happened before that?” If the participant drifts into generalities (“I usually…” or “In general…”), gently bring them back to the specific instance.
After the interview, debrief as a trio. What did each of you hear? Which opportunities surfaced? What surprised you? If you want personalized, detailed feedback on your technique, consider the Interview Coach available through the Story-Based Customer Interviews course.
Exercise: Create Your First Interview Snapshot (Time: 30 minutes. Do this with your product trio immediately after the interview.) Using the interview snapshot template, capture a photo of the participant (or a visual that represents their story), quick facts about their context, a memorable quote you’ll still recall months from now, the opportunities (needs, pain points, desires) you heard, notable insights that aren’t yet opportunities, and an experience map that illustrates the story. Over time, aim to complete each snapshot in 15–20 minutes.
Go Deeper: Additional Reading
If you prefer audio, I’ve included an audio summary for paid subscribers that covers this month’s chapter plus the resources below.
Related In-Depth Guides: Customer Interviews: How to Recruit, What to Ask, and How to Synthesize What You Learn.
The Value of Continuous Interviewing: Why Product Trios Should Interview Customers Together – How interviewing together ensures research is timely, actionable, and believable.
How to Find Customers to Talk To: Customer Recruiting: Get Easy Access to Customers Week Over Week – Practical strategies for automating your recruiting process. Ask Teresa: How Do You Select Customers for Customer Interviews? – Who to interview and how to recruit them. Tools of the Trade: Finding People to Interview Before You Have Customers – Recruiting strategies for early-stage products.
What to Ask in Your Interviews: Why You Are Asking the Wrong Customer Interview Questions – Understanding the gap between ideal behavior and actual behavior. Story-Based Customer Interviews Uncover Much-Needed Context – Why collecting specific stories is more reliable than asking direct questions. Ask Teresa: What Are the Best Customer Interview Questions? – Common questions and how to improve them. Ask About the Past Rather than the Future – Why memories about recent instances are more reliable than speculation.
How to Take Notes and Synthesize What You Are Learning: How to Take Notes During Customer Research Interviews – Practical tips for capturing what you hear. The Interview Snapshot: How to Synthesize and Share What You Learned from a Single Customer Interview – A comprehensive guide to creating and using interview snapshots. Customer Interview Analysis: How AI Helps and Hurts – Learn how to use AI effectively.
Videos: All Things Product Podcast: Customer Interview Analysis – Petra and I discuss using AI to analyze customer interviews, the risks and benefits, and why your interviewing skills matter more than any AI tool.
Other Resources from Around the Web: The Top 5 Mistakes Product Teams Make With Customer Interviews by Pragmatic Live. Continuous interviewing with Kristian Collin Berge (CEO & Co-founder at UX Signals) by Afonso Franco. How to Make Time for Customer Interviews & Validation by Rich Mironov. Brave UX: An interview with Teresa Torres by Brendan Jarvis.
Related Courses: Customer Recruiting for Continuous Discovery – Get easy access to customers week over week. Story-Based Customer Interviews – Collect reliable feedback from every customer conversation.
Our Live Discussion Schedule
Our live discussion sessions are for paid subscribers. Sessions are not recorded. Invitations will go out to members two weeks before each event—add these to your calendar now: Tuesday, June 16, 2026: 9am–10am PDT. Thursday, September 17, 2026: 9am–10am PDT. Wednesday, December 16, 2026: 9am–10am PST.
Audio Summary
This summary was produced by NotebookLM. The sources supplied were the book chapters as well as all of the additional reading.
This article is part of the CDH Book Club celebrating the five-year anniversary of Continuous Discovery Habits.
Disruption is the only sustainable strategy in product. When a platform meaningfully changes how we build and operate, I pay attention—not just as a product leader, but as someone accountable for turning AI Strategy into durable competitive differentiation. That’s why the launch of the Fin API platform stands out: it’s a concrete step toward agentic AI at enterprise scale.
Today, I’m diving into what this launch includes, why it matters for product strategy, and how I’d navigate the build vs buy decision in this new landscape. My goal is to translate the announcement into actionable guidance for product teams, CX leaders, and forward-deployed engineers who are building the next generation of customer support and product-led experiences.
Fin is a customer agent platform that at present resolves over 2M customer issues a week, growing at a rapid exponential pace. It’s relied on by the best brands, large and small, in every vertical you can imagine. From Atlassian and Riot Games, to smaller hot upstarts like Mercury and Polymarket. It runs on a family of models trained by its AI group. Last week, they announced Apex, which is the world’s first specialized customer service LLM. In production tests over the last 6 months, it beat every single frontier model, including those from Anthropic and OpenAI, on resolution rate, latency, hallucination rate, and cost.
With this launch, teams can access the platform’s core capabilities and underlying models directly via API, with contracts starting at $250k per year, and usage rates that are by far the cheapest in the industry for each of the model’s subcategories. For leaders evaluating total cost of ownership, this is a meaningful data point: it shifts the economics of scaled automation from experimental to operational.
Why now? Because builders want options. I hear from teams daily that want to design their own agents, tune prompts and policies, and integrate with bespoke CRMs, data lakes, and product surfaces. The Fin announcement meets that demand with three clear build-paths, each mapping to a different operating model and maturity stage.
First, for the vast majority of companies, the Fin Agent Platform is the pragmatic starting point. Fin reports ~8k companies on it today. It addresses 99% of customer needs out of the box—without exhausting consulting engagements—while delivering top-tier resolution rates. If your priority is time-to-value, governance, and platform scalability, this route de-risks implementation and accelerates outcomes.
Second, for teams that need custom surfaces or channels, the Fin Agent API lets you present Fin in unique contexts. You get the Fin platform’s orchestration and controls, but you’re free to bypass the default messenger, email, voice, or any prebuilt channel and embed the agent natively in your product. I see this as the sweet spot for product-led growth motions where conversation design and UX writing are strategic levers.
Third, for companies building hyper-specific agents—think service plus in-product actions—the new API access to Apex and the broader collection of models is the obvious move. Unlike generalized models, these are purpose-trained for customer service scenarios and operational policies. If you have strong in-house solutions engineering, a retrieval-first pipeline, and eval-driven development in place, this path maximizes control without reinventing the model layer.
This also opens the door for vertical specialists. Fin-like businesses focused on deep domains can emerge quickly—Fin for dentists? Why not? Fin for car dealerships? Sure. I expect startups and modern CX providers (including players like Decagon and Sierra) to carve out niches where domain data, workflows, and compliance are the real moats. That’s where differentiated AI beats generic capability.
There’s a defensive reason to pay attention here. The software landscape is shifting fast: the moat is no longer feature parity—it’s the quality of your agents and the data flywheels powering them. Building software is simply less hard now, and I’ve watched engineering teams more than double measurable productivity as they adopt AI-assisted development. The implication is clear: the interface-and-features era is giving way to an agents-and-outcomes era.
Serious software companies must evolve from being a features company to an agents company—and build those agents on differentiated AI. More value will accrue at the model and orchestration layers, where safety, latency, cost, and resolution quality are won. That puts a premium on prompt engineering discipline, policy routing, continuous discovery of edge cases, and rigorous offline/online evals to keep hallucination rates low while maintaining speed.
How would I choose among the three build-paths? If you’re early or resource-constrained, start with the Fin Agent Platform to validate outcomes and align stakeholders. If you need branded experiences and tighter product integration, use the Fin Agent API to control surfaces without owning the heavy lifting. If you have strong ML ops and a mature customer support ai strategy, go model-level with Apex and companions, layering in your own guardrails, context window management, and test harnesses. In each case, balance velocity, control, and risk—your build vs buy decision should be grounded in clear metrics and an explicit product strategy.
Where does this lead? We’ll see more companies expose specialized model families with clearer economics and stronger governance. For now, I’m excited to see what teams build with the Fin API platform—and how they turn agentic AI into measurable improvements in resolution rate, CSAT, cost-to-serve, and ultimately, customer loyalty.
I’m continually asked how machine learning can make product analytics more actionable. Drawing from Amplitude analytics in real-world settings, I’ve distilled what matters most for product teams that want faster, smarter decisions without sacrificing rigor.
When I design experiments, I start with minimum detectable effect (MDE) to size samples correctly and avoid costly, inconclusive tests. I pair that with disciplined A/B testing hygiene—clear hypotheses, thoughtful stop rules, and guardrails for key metrics—so results translate into credible product strategy choices instead of noisy dashboards.
For growth and retention, I map behavioral analytics to activation and long-term value. Driver trees help me connect feature adoption to revenue or retention, and anomaly detection keeps me from overreacting to outliers when seasonality or data quality shift.
I segment cohorts by user intent and lifecycle stage, measure user activation with crisp event definitions, and monitor leading indicators across a unified analytics platform. This keeps cross-functional conversations grounded, accelerates product-led growth, and reduces the risk of optimizing for vanity metrics.
Operationally, that means building self-serve views that flag MDE-ready experiments, surface retention analysis by cohort, and trigger anomaly detection alerts only when the signal outpaces noise. The payoff is fewer meetings debating data quality and more time shipping value.
If you’re leveling up your analytics stack, start by tightening experimentation basics, instrumenting activation and retention with behavioral analytics, and wiring in anomaly detection as a safety net. You won’t just move faster—you’ll learn faster, and with the confidence to bet big when the data earns your trust.
Inspired by this post on Amplitude – Perspectives.
I’ve wanted my product analytics to follow me into every conversation, doc, and code review. Now they do—and it changes how quickly I can move from question to insight to decision.
Pendo is now available as an MCP (Model Context Protocol) server, easily accessible in Claude, ChatGPT, and Cursor.
Practically, this means my core product analytics, segments, and qualitative feedback can be surfaced right where I plan sprints, refine opportunity solution trees, and write specs. Fewer context switches, tighter feedback loops, and faster product decisions.
Here are five ways I put Pendo MCP to work across my day-to-day workflows—grounded in product management leadership habits and built for speed and clarity.
1) Daily triage and decision support: In ChatGPT or Claude, I quickly query product analytics to spot anomalies, usage spikes, or drop-offs by segment. Prompts like “Highlight top features by week-over-week growth and flag statistically notable anomalies” help me focus standups on what matters, tightening the loop between observability and action.
2) Continuous discovery prep: Before customer interviews, I pull recent NPS verbatims, feature adoption by persona, and journey mapping signals. In seconds, I have a concise brief that blends behavioral analytics with customer interviews, so I can ask sharper questions and validate assumptions faster—without leaving my AI workspace.
3) Evidence-based prioritization: When shaping the roadmap, I bring in retention analysis, user activation metrics, and cohort views to weigh impact vs. effort. Using Pendo MCP inside Claude or ChatGPT, I translate insights into driver trees and a clear product strategy narrative that aligns stakeholders around outcomes, not output.
4) Product-led growth and onboarding: I review onboarding funnels, identify friction in first-run experiences, and draft in-app guides and tooltip copy that meets users at the exact drop-off points. With Pendo MCP, the context for product tours and in-app guides is right where I’m writing, so iteration cycles stay tight and data-informed.
5) Customer success and QBR prep: For account health and QBRs vs OKRs alignment, I generate succinct summaries of feature adoption, sentiment, and value realization—ready to paste into email, decks, or a CRM integration. This keeps sales-led and product-led growth motions unified, with a single source of truth visible in ChatGPT, Claude, or when I’m coding in Cursor.
The net effect: higher-quality decisions, faster. By bringing product analytics into my AI workflows, I reduce context switching, improve context window management, and keep my team anchored to real user behavior. Wherever I’m working—ideating in Claude, drafting in ChatGPT, or reviewing code in Cursor—my Pendo context is right there with me.
If you’re leading empowered product teams, this is a pragmatic way to operationalize continuous discovery, speed up alignment, and turn insights into outcomes. It’s a simple shift with outsized leverage.
“Is product management dead?” I hear this question at almost every conference hallway chat. After listening to the latest Product Builders – All Things Product Podcast with Teresa Torres & Petra Wille, I’m more convinced than ever: product management isn’t dead—it’s evolving fast, and the leaders will be those who embrace the shift.
Listen to this episode on: Spotify | Apple Podcasts
The core take resonated deeply with my day-to-day at HighLevel: product management isn’t dying—“the traditional product trio (PM, design, engineering) is collapsing into something new.” The center of gravity is shifting from swim lanes to outcomes, from rigid handoffs to fluid collaboration, and from role definitions to capabilities that actually ship value.
AI is raising the baseline across the board. That “80/20 shift: AI handles patterns, humans handle hard problems” is real on my teams. With LLMs like “GPT 5.2” and “Opus 4.5,” coding agents such as “Claude Code” and “Codex,” and tools like “Replit” and “Lovable,” we’re compressing cycle time on the repeatable 80%. The bottleneck is no longer typing code or drafting copy—it’s selecting the right problems, crafting sharp product strategy, and making confident trade-offs.
This is why the future belongs to “product builders” — people with a shared foundation across disciplines and deep expertise in one area. I look for teams that can shape, prototype, validate, and iterate in tight loops, blending continuous discovery with empowered product teams. The baseline expands, the craft deepens.
Functional expertise still matters—more than ever—because the hard parts are getting harder. We need leaders who can weigh platform scalability against time-to-value, protect privacy-by-design, apply AI risk management, and navigate data governance while sustaining product-market fit. When AI accelerates execution, judgment becomes the differentiator.
For leaders, this creates a clear mandate: “What product leaders must do to create safe AI infrastructure.” In practice, that means building guardrails early—security reviews tailored to AI workflows, QA harnesses that include eval-driven development, model performance observability, and human-in-the-loop review systems. You can’t bolt this on later without paying a tax in velocity and trust.
Hiring signals are already shifting. “How job descriptions and hiring expectations are already shifting” shows up in my reqs: we emphasize cross-functional range, fluency with AI workflows, prompt engineering literacy, and the ability to frame measurable outcomes. We still want craft depth—design systems, systems thinking in engineering, rigorous discovery—but we prize people who move seamlessly from discovery to delivery.
In the episode, I appreciated the crisp framing of why product management isn’t dying—but changing. The rise of the “product builder” foundation reframes team topology and unlocks smaller, more cross-functional squads. AI changes the baseline skill set across product teams, and ignoring it is a career risk. If you’re not learning AI tools, you’re falling behind.
My key takeaways were straightforward and actionable. Smaller, more cross-functional teams are likely. Deep expertise still matters—especially for complex trade-offs. Leaders need guardrails: security, QA, and review systems built for an AI-driven workflow. And if you work in product, design, or engineering, this episode is your signal to start upskilling now.
“The risk of ignoring AI in your craft” is not hypothetical. I encourage PMs to carve out weekly lab time for hands-on experiments with LLMs for product managers, build lightweight prototypes with Replit or Lovable, and pressure-test opportunity solution trees with data-informed discovery. Pair with your engineers on agentic AI use cases, and integrate model evals into your CI/CD pipelines.
“Mentioned in the episode” were several resources worth exploring: “Product at Heart” (June, Hamburg), “Replit,” “Lovable,” “Every,” “Petra’s Coaching Packages,” and “coding agents (Claude Code, Codex) and LLMs (GPT 5.2, Opus 4.5).” These are great jumping-off points for your own product builder toolkit.
My recommendation: queue up the episode on your commute, then pick one workflow to augment with AI before the week ends. Replace a handoff with a shared canvas. Automate a repetitive analysis. Ship a scrappy prototype. Momentum compounds.
Have thoughts on this episode? Leave a comment below. I’d love to hear how your teams are evolving your product trios, what AI workflows are sticking, and where governance has been most challenging.
PR review bots are all the rage, but they cost a premium. We built our own for cheap that work just as well, if not better. Here's how.
As a VP of Product Management, I care deeply about the velocity and quality of our software delivery. The decision to build our own pull request (PR) review agents came from a simple calculus: we needed tighter control over developer experience, CI/CD integration, and cost—without sacrificing accuracy or reliability. The result was a pragmatic system that accelerates reviews, improves code quality, and pays for itself through faster feedback loops.
Before we wrote a line of code, we defined success. Our objectives were to shorten review cycles, reduce back-and-forth on style and test coverage, and surface risks earlier—measured against DORA metrics like lead time and deployment frequency. That focus aligned the team, guided our build vs buy decision, and anchored scope to the highest-impact use cases.
We started rules-first, AI-optional. The initial release enforced guardrails that are universally valuable: linting and formatting checks, required test coverage thresholds, commit message standards, ownership validation (CODEOWNERS), and basic security scans. These automated gates eliminated predictable review friction, freeing engineers to focus on logic and architecture rather than style debates.
Then we layered intelligence where it mattered. We added lightweight, explainable checks for common code smells and dependency risks, plus optional natural-language summaries that turn large diffs into concise context. Where appropriate, we introduced agentic AI workflows to triage PRs by risk, draft review comments, and suggest missing tests—always keeping humans in the loop. This hybrid approach kept costs low and outcomes high.
Integration with our CI/CD pipeline was non-negotiable. We wired GitHub/GitLab webhooks to a stateless service that queued work, executed checks in containerized workers, and posted results back as status checks and review comments. Caching, parallelization, and smart diff-scoping ensured we only computed what changed, keeping the experience snappy even on large repos.
Adoption hinged on developer experience. We made the bot’s feedback fast, specific, and actionable, with clear remediation steps and links to documentation. Feature flags allowed teams to opt into new checks gradually. ChatOps commands enabled quick overrides for emergencies, while policy-as-code kept rules visible, versioned, and auditable.
We treated this like any product: eval-driven development for accuracy, ongoing telemetry for false-positive rates, and explicit SLAs for response times. We instrumented outcomes end-to-end—tracking PR cycle time, comment-to-merge ratios, and rework—so we could prove the ROI and tune the system without guesswork.
The outcome: a reliable PR review companion that runs on a shoestring budget, integrates cleanly with our workflows, and measurably improves engineering throughput. If you’re weighing build vs buy, start small with rules that deliver immediate value, then layer intelligence where it earns its keep. With a clear product strategy, you can stand up capable PR review bots quickly—and scale them as your needs grow.
If you’re ready to try this yourself, begin with your top three friction points in code reviews, wire them into your CI/CD checks, and pilot with a single team. Iterate weekly, measure relentlessly, and let your developers be your strongest signal. You’ll be surprised how far a pragmatic, product-led approach can take you.
Inspired by this post on Amplitude – Perspectives.
In my role leading product management at HighLevel, I study the architectures and operating models behind high-velocity learning. I often reference "Amplitude's MCP server and its experimentation platform" as a benchmark for how to operationalize scale, reliability, and speed of insight across complex product ecosystems. That lens informs how I design processes, data flows, and decision loops that turn ambiguity into measurable outcomes.
Experimentation is the heartbeat of eval-driven development. In practice, that means running disciplined A/B testing, deploying targeted feature flags to de-risk rollouts, and sizing experiments with a clear minimum detectable effect (MDE) so we avoid vanity wins. When teams internalize these habits, we shift from opinion-led debates to evidence-led decisions—and that’s where product-led growth compounds.
I'm an AI enthusiast, so I think a lot about how experimentation accelerates AI roadmaps. The same rigor that validates UI changes should govern prompts, retrieval strategies, and policy settings for LLM-backed features. By treating AI behaviors as first-class experiment surfaces—and tying them to user activation, retention analysis, and value proposition metrics—we move faster without compromising safety, privacy-by-design, or customer trust.
Making this work in production demands clean instrumentation and a unified analytics platform. I look for stacks that combine Amplitude analytics with robust observability and CI/CD to ensure we can ship, measure, and iterate continuously. When platform scalability and data governance are baked in from the start, product trios can focus on product discovery rather than firefighting pipelines or reconciling metrics.
My playbook is straightforward: define decision-worthy questions, map them to crisp success metrics, run right-sized experiments with feature flags, and use consistent analytics to close the loop. Do this well, and you create a durable advantage—faster learning cycles, sharper product positioning, and a culture that lives by outcomes over output. That’s the real lesson I take from platforms that execute experimentation at scale: process and technology are table stakes; what wins is the discipline to learn relentlessly.
Inspired by this post on Amplitude – Perspectives.
I just watched one of the most significant leaps in customer service AI in years. Last week, a quiet but seismic release landed in CX: Fin introduced Apex, a vertical model purpose-built for support that raises the bar on speed, accuracy, and cost. As a product leader, this is exactly the kind of breakthrough that changes roadmaps, vendor strategies, and what customers can expect from modern service operations.
It’s a brand new model for Fin called Apex, and it’s objectively the highest performing, fastest, and cheapest model for customer service. It beats the very best models in the industry including GPT-5.4 and Opus 4.5.
In this analysis, I’ll unpack why the launch matters for the customer service agent category, what it signals for frontier labs and open‑weight ecosystems, and how leaders should rethink their AI Strategy, build vs buy decisions, and eval-driven development roadmaps.
Fin was already the highest performing and most sophisticated agent in the customer service space, consistently beating impressive competitors like Decagon and Sierra at an average win rate in the 70s. It operates at tremendous scale, now resolving almost 2M customer issues per week, a number that’s growing at an exponential clip. In its short life it’s grown to nearly $100M in recurring revenue.
As of last week, ~100% of all (English language, chat and email) customer conversations are now running on Apex. Since day 1, the Fin engine has comprised a system of models, and last year the team began replacing off‑the‑shelf models with custom ones trained on proprietary data. The core answering model had been a frontier labs offering—initially versions of GPT and more recently Sonnet 4.0. Now, that core answering model is Apex 1.0.
This model resolves customer issues at a materially higher rate than any other model available. One of their largest customers in the gaming space saw the resolution rate improve overnight from 68% to 75% (i.e. a reduction in unresolved conversations of 22%). The team notes they had never seen a jump this large from a single improvement since they started Fin.
Just as important, it’s dramatically faster, has fewer hallucinations, and is far cheaper than other available models—exactly the attributes operations leaders weigh most when deploying agents at scale. In practice, these are the levers that unlock higher CSAT, tighter SLAs, and better unit economics.
Achieving all three simultaneously is extraordinarily hard. Credit goes to foundational research from a 60‑person AI group run by Fergal Reid, and, crucially, to domain‑specific proprietary evals drawn from billions of human and agent interactions produced by the Fin resolution engine—already hand‑tuned to be the most effective in the category. That creates a flywheel: an eval‑driven development loop that trains models to keep improving at the edge of the system’s abilities. In other words, Apex 1.0 looks like the tip of the iceberg.
Zooming out, service is one of the few categories where generative AI has already delivered commercial impact at scale (alongside coding, and arguably the legal industry). With TAMs measured in the hundreds of billions, competition is intense and well capitalized. The pattern I’ve seen repeatedly is clear: winners in these spaces must become full‑stack AI companies. As features become ~free to build, durable competitive differentiation shifts under the hood—to proprietary data, post‑training, inference efficiency, and the quality of the eval loop.
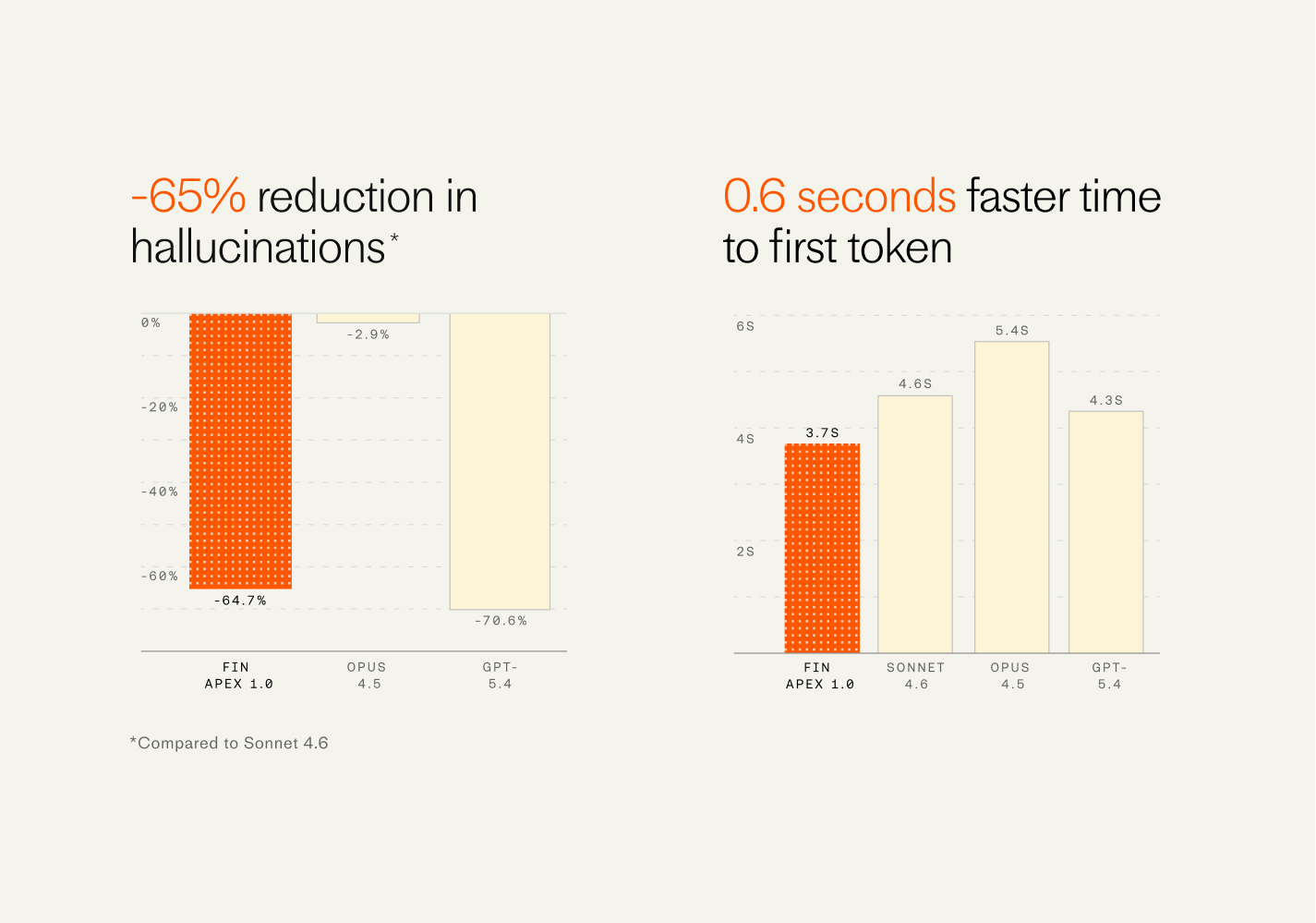
Fin Apex raises the bar for finance-ready AI, highlighting a -65% cut in hallucinations and a quicker first token at 3.7s (0.6s faster), compared with Sonnet 4.6, Opus 4.5, and GPT-5.4 in side-by-side charts.
That’s why competitors will need to release their own models. Many appear to be just starting to hire the talent to do so, which likely gives Fin at least a year of head start. For product leaders, this is a strong signal to revisit build vs buy assumptions, and to quantify when owning your post‑training pipeline and evals becomes the rational move.
Honestly, 2–3 years ago I expected AI application differentiation to live mostly in what we built around third‑party models. The AI game humbles all of us; today it’s obvious that vertical models paired with proprietary evals create compounding moats.
In a podcast interview last week, Andrej Karpathy said:
"I do think we should expect more speciation in the intelligences. The animal kingdom is extremely [diverse] in the brains that exist. And there’s lots of different niches of nature… And I think we should be able to see more speciation. And you don’t need this oracle that knows everything. You kind of speciate it. And then you put it on a specific task. And we should be seeing some of that because you should be able to have much smaller models that still have the cognitive core."
The frontier labs still have the very best models, but open‑weight models aren’t far behind—making pre‑training look increasingly like a commodity. The frontier is moving to post‑training, which is precisely what we see with Apex (and Cursor’s Composer 2), and what we should expect to dominate going forward.
Labs now face a dual reality. On one hand, horizontal general‑purpose models can over‑serve specific verticals (e.g., customer service doesn’t need an oracle that knows everything). On the other, open‑weight models are good enough that high‑quality, domain‑specific post‑training can produce superior models for special‑purpose jobs—and in the ways that matter for those jobs. In service, soft factors like judgement, pleasantness, and attentiveness matter alongside hard factors like resolution effectiveness, speed, and cost.
I’m still bullish on the labs. Many organizations remain heavy customers of Anthropic—whether as part of multi‑model systems or through deep usage of Claude Code in engineering teams (see this example of Claude Code adoption). Yet classic disruption (à la the late, great Clay Christensen) is now at their door. The way out is to disrupt themselves by building cheaper specialized models too, which likely requires acquiring the evals—or the companies with the evals—needed for each task. Expect creative data partnerships, M&A consolidation, and a wave of hyper‑specific model providers that compete head‑to‑head with the labs.
In the meantime, Fin appears to be the only vendor in its space with a custom model that’s also objectively superior to everything else out there. I’m excited to see it deployed broadly for end customers, and I’m watching closely for the next announcement that will accelerate that rollout. For product leaders, the message is clear: the age of vertical models and agentic AI is here—bring your evals, or bring your checkbook.