Every week I meet marketers who are working harder than ever—more campaigns, more content, more dashboards—yet seeing less movement on metrics that matter. The surge of AI tooling has amplified activity, not necessarily impact. That’s the focus problem: we confuse motion with momentum, and our backlogs look great while our outcomes stall.
Learn how AI agents for marketing can help you prioritize impact so you can do important work, instead of just more work.
In my role leading product and growth teams, I’ve learned that AI only compounds value when it is pointed squarely at outcomes. If we don’t define what “good” looks like, agentic AI will simply scale busywork. The antidote is a disciplined operating model that connects strategy to execution and instruments agents with clear success criteria.
First, anchor your program with outcomes vs output OKRs. Choose one or two measurable business outcomes—such as qualified pipeline, conversion rate, or activation—and make everything else subordinate. This provides the compass agents need to make effective trade-offs when speed and volume tempt you to do “one more thing.”
Second, map a driver tree from the target outcome down to the controllable levers: audience segments, offers, channels, messaging, and experience friction. This traceability shows where agents can move the needle fastest—whether that’s accelerating research, sharpening positioning, or eliminating handoffs that slow experimentation.
Third, design a small, agentic AI workforce aligned to those levers. For example: a Research Agent that synthesizes market insights and past performance; a Copy Agent that generates on-brief, on-brand variants; a Distribution Agent that adapts content to each channel and schedules posts; and an Analytics Agent that runs A/B tests, summarizes results, and flags anomalies. Keep human oversight where judgment matters most—strategy, brand voice, and high-stakes decisions.
Fourth, instrument rigor from day one with Agent Analytics and eval-driven development. Define offline evals for brand consistency, factuality, safety, and response time; pair them with online experiments that quantify lift on your target outcomes. Set a minimum detectable effect (MDE) so you stop shipping changes that cannot plausibly move the metric.
Fifth, operationalize your AI workflows. Standardize prompts, inputs, and handoffs; templatize briefs and acceptance criteria; and keep a change log so improvements compound rather than reset. Use short, frequent feedback loops to prune low-impact work and double down on what demonstrably advances your objectives.
I’ve seen teams reclaim focus and momentum when they treat agents as teammates, not toys. The magic isn’t in producing more assets—it’s in consistently choosing the next best action in service of a clear outcome. When you combine outcome clarity, a driver tree, targeted agents, and tight evals, AI becomes a force multiplier for marketing impact.
If you’re feeling overwhelmed by AI’s possibilities, start small: commit to one outcome, one driver you believe is material, and one agent designed for that job. Prove lift, codify the workflow, then scale. Velocity is only valuable when it’s pointed in the right direction.
Inspired by this post on Amplitude – Best Practices.
I’ve long believed the people function is a strategic engine, not a support lane. That conviction was only reinforced in a recent deep dive with Katie Burke, now COO at Harvey after joining as Chief People Officer. Before Harvey, she spent 11 years in HR leadership at HubSpot, helping build one of tech’s most distinctive cultures. In this piece, I unpack what resonated most for me as a product leader: a marketing-minded approach to HR, deliberate hiring from hospitality, and the non-negotiable case for culture as a core business strategy.
The first principle is simple and often overlooked: HR leaders should think like marketers. Employer brand is a product; your candidate and employee journeys are funnels; and your programs deserve the same rigor we bring to product—segmentation, positioning, channels, and continuous A/B testing. When we treat onboarding, performance, and manager enablement like iterative product launches—complete with activation metrics, retention curves, and NPS—we stop guessing and start compounding results.
One line has become a north star for how I approach executive leadership: “Don’t ask for a seat at the table. Build the table.” In practice, that means codifying the operating system—decision rights, principles, cadences, and accountability—so the organization isn’t improvising strategy in every meeting. Product, People, and Finance should co-own this OS; that’s how you scale clarity faster than headcount.
Transparency is the tax we pay for alignment, and it compounds trust. After an IPO, the impulse can be to close ranks. The better move is radical transparency with context: what changed, why it matters, and how decisions get made now. On my teams, that looks like publishing decision records, sharing tradeoffs explicitly, and using written docs to reduce rumor velocity—core muscles in stakeholder management as complexity grows.
I also loved the counterintuitive hiring bet: prioritize hospitality backgrounds alongside traditional corporate pedigrees. People who’ve thrived in service environments bring customer empathy, operational resilience, and a bias for proactive care—traits that elevate everything from onboarding to incident response. In product terms, they’re culturally accretive hires with high signal on service quality and consistency.
The trickiest part of the Chief People Officer role isn’t process—it’s politics. You are the executive team’s own HR business partner, which requires coaching, candor, and conflict mediation at the highest stakes. The goal is to “Be the Michael Jordan of your exec team”—the teammate who elevates standards, makes others better, and chooses the hard right over the easy familiar.
Layoffs create a culture debt that accrues interest. Expect a “2.5-year cultural hangover after a layoff”—in many companies, an inevitable two-year layoff hangover—unless you actively repay it. That repayment plan includes narrating the why with specificity, rebuilding trust through manager enablement, and re-anchoring on performance and values. Measure leading indicators (manager effectiveness, time-to-decision, psychological safety) alongside lagging ones (regretted attrition) to track the true recovery arc.
People leaders also need to create “graceful exits.” Doing this well preserves dignity for the person, protects the team’s morale, and safeguards the company’s brand. The bar is straightforward: clear rationale, fair process, useful feedback, generous support, and alumni pathways. A graceful exit signals that even when business realities bite, respect is non-negotiable.
Expectation-setting matters. Two truths cut through the noise: “The workplace shouldn’t be Disneyland” and “Our job is not to make you happy every day.” The promise is not perpetual happiness; it’s meaningful work, fair standards, growth opportunities, and leaders who tell the truth. When we set that contract clearly, engagement becomes an outcome of purpose and progress—not perks.
On feedback, I use the protein vs. sugar rule for employee feedback. Sugar feedback is pleasant and perishable; protein feedback is specific, sometimes uncomfortable, and growth-driving. Great cultures build a taste for protein—clear role expectations, crisp examples, and written follow-ups. Mechanically, that looks like structured 1:1s, decision retros, skip-levels, and manager training that demystifies “what good looks like.”
Being a Chief People Officer isn’t for the faint of heart. The role must be demanding by design—on executive hiring quality, performance management courage, and values enforcement. Moments like “Berry-Gate” are reminders that small symbolic issues can balloon when feedback loops are unclear. Close the loop fast, publish the rationale, and ensure there’s a predictable path for concerns to be heard and resolved.
When hiring, beware patterns that predict friction. That’s why “frequent flyers” are a new-hire red flag. Movement can signal adaptability—but weather-vein pivots and blame-shifting often repeat. Probe for ownership, learning moments, and sustained impact; you want people who compound value, not just sample it.
Clarity on scope prevents leadership whiplash. Which company decisions fall to the Chief People Officer? Think leveling frameworks, compensation philosophy and bands, performance calibration, manager standards, ER policies, and org design guardrails—always in lockstep with Finance and the CEO. Escalate when there are values collisions or systemic risks; otherwise, push decisions to the right altitude and owner.
Scaling exposes the same few failure modes on repeat: fuzzy decision rights, a thin manager bench, brittle processes that don’t flex, and inconsistent leveling that erodes trust. The antidote is an operating model that pairs clear principles with lightweight mechanisms—documented roles, regular calibration, and reviews that audit for both outcomes and operating behaviors.
Comparing a scaled SaaS like HubSpot with an AI-native company like Harvey surfaces important differences. The former optimizes for durable systems, predictable cadences, and governance; the latter optimizes for rapid learning loops, emergent org design, and a higher tolerance for ambiguity. The art is porting the right controls at the right time without crushing velocity.
AI is already changing the people function. GenAI can draft job descriptions, summarize performance notes, classify themes from engagement surveys, and power AI workflows that resolve common HR tickets. The human-in-the-loop remains essential for judgment, context, and ethics—especially around data governance and privacy-by-design. A pragmatic AI Strategy here frees HRBPs for higher-order coaching and organizational development work.
One practice I recommend widely: share your own performance reviews. Modeling openness normalizes growth and turns feedback into a shared craft, not a secret ritual. It also builds trust when you later ask the organization to lean into sharper, protein-rich feedback.
Finally, disagreements with the CEO are inevitable—and healthy. Handle them with pre-briefs, crisp written proposals, explicit tradeoffs, and a shared decision record. Argue like scientists, not politicians; once a call is made, disagree and commit. That combination of candor and alignment is what keeps executive teams high-trust and high-velocity.
The people leader’s chair may be the most politically dangerous role in the C-suite—but it’s also one of the most leveraged. Build the table, tell the truth, design for standards and dignity, and treat culture like the product that powers everything else.
Lately, it feels like every morning brings a new AI launch, a dazzling demo, or a must-try tool. I love the pace of innovation, but the constant stream can trigger counterproductive FOMO if I’m not intentional. As a product leader, I’ve learned to turn that anxiety into a disciplined learning system—one that keeps me curious without letting novelty hijack my focus.
That’s exactly why this conversation with Petra Wille and Teresa Torres resonated with me. They explore how to stay experimental in the AI era without chasing every shiny object. Their perspective aligns closely with my own operating cadence: start with real problems, go deep on a small set of tools, and create explicit boundaries between work, learning, and play.
Listen to this episode on: Spotify | Apple Podcasts
Here’s the mindset I apply. I don’t start with tools—I start with problems. When I encounter concrete friction in a workflow or see a credible opportunity to improve an outcome, that’s my trigger to explore a new capability. This mirrors the continuous discovery habit of prioritizing opportunities over solutions, and it’s how I avoid performing “innovation theater.”
To keep exploration healthy, I time-box my learning. I block recurring windows specifically for experiments, reading, and hands-on trials so they don’t overrun my core product work. During these blocks, I’ll set a clear question, run a tight test, and capture what I learned. No rabbit holes, no endless tinkering.
I also separate “interesting” from “actionable.” Plenty of inputs are worth awareness, but very few deserve immediate action. I bookmark the rest for later. This simple filter reduces cognitive load and keeps my backlog—from ideas to proofs of concept—well-governed.
Social media can amplify technology hype cycles, so I establish boundaries. I batch consumption, mute low-signal channels, and prioritize practitioner communities over performative threads. The goal isn’t to be first; it’s to be right for my customers, my team, and our strategy.
When choosing what to try next, I use a practical rubric. Does the tool target a real friction I’ve seen in discovery or delivery? Can it plug cleanly into our AI workflows without unsustainable glue work? Do we have a safe, compliant way to test it? Is there a plausible path from trial to compounding value? If the answer isn’t a confident yes to most of these, I wait.
Depth beats breadth. I’d rather take one promising tool into a real use case, instrument it, and measure outcomes than skim ten trending demos. That tighter loop produces sharper intuition, clearer product bets, and better partner decisions. A quick opportunity solution tree helps me connect user pain to outcomes before I let any solution onto the field.
In the episode, Petra Wille and Teresa Torres talk candidly about managing FOMO, deciding which tools to explore, and designing intentional learning systems. They discuss why starting with a problem is more valuable than starting with a tool, how social media amplifies technology FOMO, and why going deeper with fewer tools can lead to better learning. If you’ve ever felt like you’re falling behind because you haven’t tried the latest AI tool yet, this conversation will help you rethink how you approach learning and experimentation.
If you’re curious about what came up, here are some of the tools and communities mentioned: Claude Code, OpenClaw (formerly Clawdbot, Moltbot), NotebookLM, Product Talk, ElevenLabs, Lenny’s Newsletter Community, and even a nod to Bridgerton for a touch of levity.
My takeaway is simple but powerful: curiosity doesn’t require constant experimentation. The best product managers cultivate a balanced system—grounded in product discovery, energized by focused experiments, and protected by clear boundaries—so we can learn faster while staying pointed at outcomes that matter.
Discussion Question: How do you decide which new tools or technologies are worth exploring—and which ones you can safely ignore?
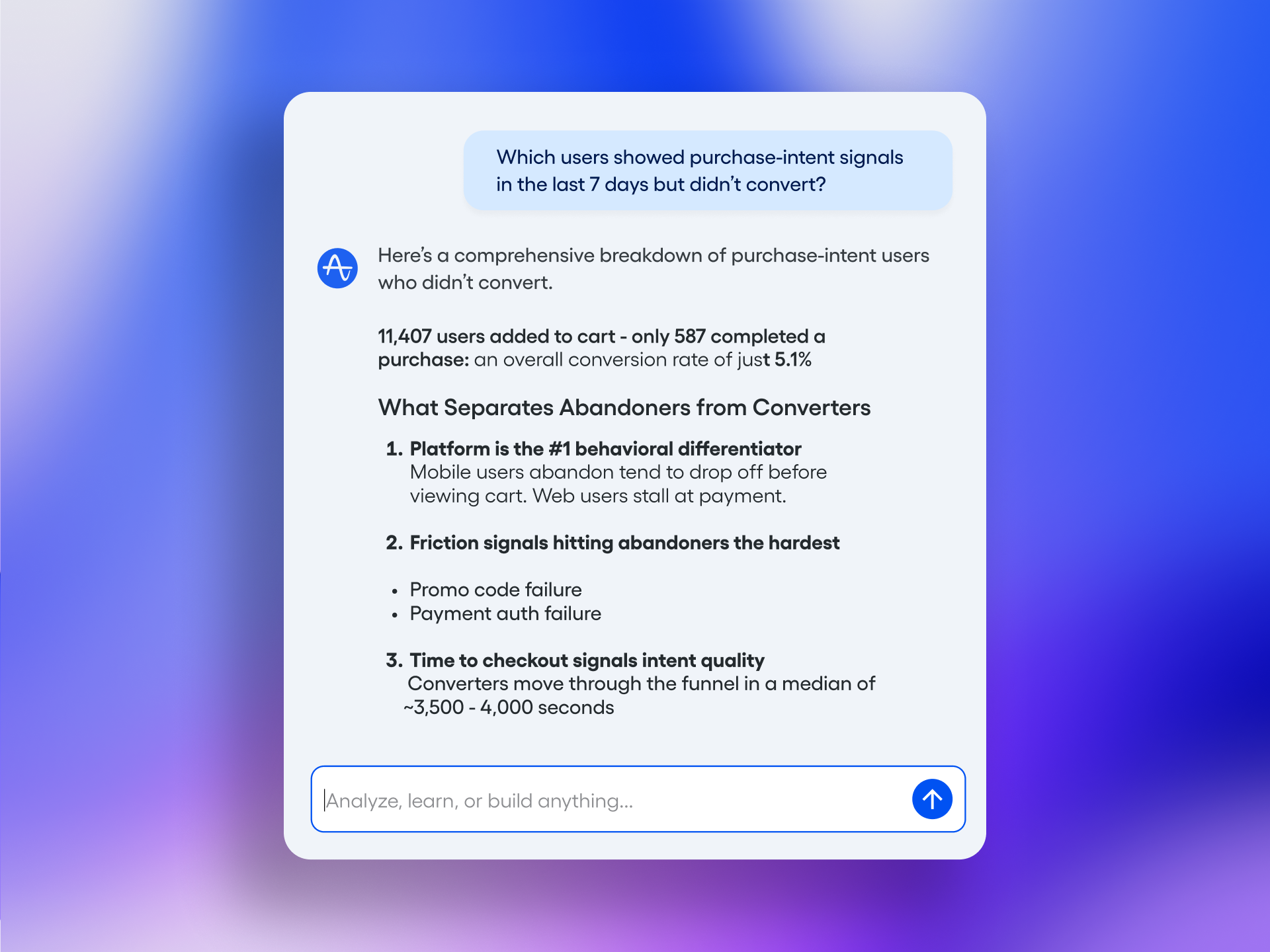
I’ve wanted my product analytics to follow me into every conversation, doc, and code review. Now they do—and it changes how quickly I can move from question to insight to decision.
Pendo is now available as an MCP (Model Context Protocol) server, easily accessible in Claude, ChatGPT, and Cursor.
Practically, this means my core product analytics, segments, and qualitative feedback can be surfaced right where I plan sprints, refine opportunity solution trees, and write specs. Fewer context switches, tighter feedback loops, and faster product decisions.
Here are five ways I put Pendo MCP to work across my day-to-day workflows—grounded in product management leadership habits and built for speed and clarity.
1) Daily triage and decision support: In ChatGPT or Claude, I quickly query product analytics to spot anomalies, usage spikes, or drop-offs by segment. Prompts like “Highlight top features by week-over-week growth and flag statistically notable anomalies” help me focus standups on what matters, tightening the loop between observability and action.
2) Continuous discovery prep: Before customer interviews, I pull recent NPS verbatims, feature adoption by persona, and journey mapping signals. In seconds, I have a concise brief that blends behavioral analytics with customer interviews, so I can ask sharper questions and validate assumptions faster—without leaving my AI workspace.
3) Evidence-based prioritization: When shaping the roadmap, I bring in retention analysis, user activation metrics, and cohort views to weigh impact vs. effort. Using Pendo MCP inside Claude or ChatGPT, I translate insights into driver trees and a clear product strategy narrative that aligns stakeholders around outcomes, not output.
4) Product-led growth and onboarding: I review onboarding funnels, identify friction in first-run experiences, and draft in-app guides and tooltip copy that meets users at the exact drop-off points. With Pendo MCP, the context for product tours and in-app guides is right where I’m writing, so iteration cycles stay tight and data-informed.
5) Customer success and QBR prep: For account health and QBRs vs OKRs alignment, I generate succinct summaries of feature adoption, sentiment, and value realization—ready to paste into email, decks, or a CRM integration. This keeps sales-led and product-led growth motions unified, with a single source of truth visible in ChatGPT, Claude, or when I’m coding in Cursor.
The net effect: higher-quality decisions, faster. By bringing product analytics into my AI workflows, I reduce context switching, improve context window management, and keep my team anchored to real user behavior. Wherever I’m working—ideating in Claude, drafting in ChatGPT, or reviewing code in Cursor—my Pendo context is right there with me.
If you’re leading empowered product teams, this is a pragmatic way to operationalize continuous discovery, speed up alignment, and turn insights into outcomes. It’s a simple shift with outsized leverage.
“Is product management dead?” I hear this question at almost every conference hallway chat. After listening to the latest Product Builders – All Things Product Podcast with Teresa Torres & Petra Wille, I’m more convinced than ever: product management isn’t dead—it’s evolving fast, and the leaders will be those who embrace the shift.
Listen to this episode on: Spotify | Apple Podcasts
The core take resonated deeply with my day-to-day at HighLevel: product management isn’t dying—“the traditional product trio (PM, design, engineering) is collapsing into something new.” The center of gravity is shifting from swim lanes to outcomes, from rigid handoffs to fluid collaboration, and from role definitions to capabilities that actually ship value.
AI is raising the baseline across the board. That “80/20 shift: AI handles patterns, humans handle hard problems” is real on my teams. With LLMs like “GPT 5.2” and “Opus 4.5,” coding agents such as “Claude Code” and “Codex,” and tools like “Replit” and “Lovable,” we’re compressing cycle time on the repeatable 80%. The bottleneck is no longer typing code or drafting copy—it’s selecting the right problems, crafting sharp product strategy, and making confident trade-offs.
This is why the future belongs to “product builders” — people with a shared foundation across disciplines and deep expertise in one area. I look for teams that can shape, prototype, validate, and iterate in tight loops, blending continuous discovery with empowered product teams. The baseline expands, the craft deepens.
Functional expertise still matters—more than ever—because the hard parts are getting harder. We need leaders who can weigh platform scalability against time-to-value, protect privacy-by-design, apply AI risk management, and navigate data governance while sustaining product-market fit. When AI accelerates execution, judgment becomes the differentiator.
For leaders, this creates a clear mandate: “What product leaders must do to create safe AI infrastructure.” In practice, that means building guardrails early—security reviews tailored to AI workflows, QA harnesses that include eval-driven development, model performance observability, and human-in-the-loop review systems. You can’t bolt this on later without paying a tax in velocity and trust.
Hiring signals are already shifting. “How job descriptions and hiring expectations are already shifting” shows up in my reqs: we emphasize cross-functional range, fluency with AI workflows, prompt engineering literacy, and the ability to frame measurable outcomes. We still want craft depth—design systems, systems thinking in engineering, rigorous discovery—but we prize people who move seamlessly from discovery to delivery.
In the episode, I appreciated the crisp framing of why product management isn’t dying—but changing. The rise of the “product builder” foundation reframes team topology and unlocks smaller, more cross-functional squads. AI changes the baseline skill set across product teams, and ignoring it is a career risk. If you’re not learning AI tools, you’re falling behind.
My key takeaways were straightforward and actionable. Smaller, more cross-functional teams are likely. Deep expertise still matters—especially for complex trade-offs. Leaders need guardrails: security, QA, and review systems built for an AI-driven workflow. And if you work in product, design, or engineering, this episode is your signal to start upskilling now.
“The risk of ignoring AI in your craft” is not hypothetical. I encourage PMs to carve out weekly lab time for hands-on experiments with LLMs for product managers, build lightweight prototypes with Replit or Lovable, and pressure-test opportunity solution trees with data-informed discovery. Pair with your engineers on agentic AI use cases, and integrate model evals into your CI/CD pipelines.
“Mentioned in the episode” were several resources worth exploring: “Product at Heart” (June, Hamburg), “Replit,” “Lovable,” “Every,” “Petra’s Coaching Packages,” and “coding agents (Claude Code, Codex) and LLMs (GPT 5.2, Opus 4.5).” These are great jumping-off points for your own product builder toolkit.
My recommendation: queue up the episode on your commute, then pick one workflow to augment with AI before the week ends. Replace a handoff with a shared canvas. Automate a repetitive analysis. Ship a scrappy prototype. Momentum compounds.
Have thoughts on this episode? Leave a comment below. I’d love to hear how your teams are evolving your product trios, what AI workflows are sticking, and where governance has been most challenging.
PR review bots are all the rage, but they cost a premium. We built our own for cheap that work just as well, if not better. Here's how.
As a VP of Product Management, I care deeply about the velocity and quality of our software delivery. The decision to build our own pull request (PR) review agents came from a simple calculus: we needed tighter control over developer experience, CI/CD integration, and cost—without sacrificing accuracy or reliability. The result was a pragmatic system that accelerates reviews, improves code quality, and pays for itself through faster feedback loops.
Before we wrote a line of code, we defined success. Our objectives were to shorten review cycles, reduce back-and-forth on style and test coverage, and surface risks earlier—measured against DORA metrics like lead time and deployment frequency. That focus aligned the team, guided our build vs buy decision, and anchored scope to the highest-impact use cases.
We started rules-first, AI-optional. The initial release enforced guardrails that are universally valuable: linting and formatting checks, required test coverage thresholds, commit message standards, ownership validation (CODEOWNERS), and basic security scans. These automated gates eliminated predictable review friction, freeing engineers to focus on logic and architecture rather than style debates.
Then we layered intelligence where it mattered. We added lightweight, explainable checks for common code smells and dependency risks, plus optional natural-language summaries that turn large diffs into concise context. Where appropriate, we introduced agentic AI workflows to triage PRs by risk, draft review comments, and suggest missing tests—always keeping humans in the loop. This hybrid approach kept costs low and outcomes high.
Integration with our CI/CD pipeline was non-negotiable. We wired GitHub/GitLab webhooks to a stateless service that queued work, executed checks in containerized workers, and posted results back as status checks and review comments. Caching, parallelization, and smart diff-scoping ensured we only computed what changed, keeping the experience snappy even on large repos.
Adoption hinged on developer experience. We made the bot’s feedback fast, specific, and actionable, with clear remediation steps and links to documentation. Feature flags allowed teams to opt into new checks gradually. ChatOps commands enabled quick overrides for emergencies, while policy-as-code kept rules visible, versioned, and auditable.
We treated this like any product: eval-driven development for accuracy, ongoing telemetry for false-positive rates, and explicit SLAs for response times. We instrumented outcomes end-to-end—tracking PR cycle time, comment-to-merge ratios, and rework—so we could prove the ROI and tune the system without guesswork.
The outcome: a reliable PR review companion that runs on a shoestring budget, integrates cleanly with our workflows, and measurably improves engineering throughput. If you’re weighing build vs buy, start small with rules that deliver immediate value, then layer intelligence where it earns its keep. With a clear product strategy, you can stand up capable PR review bots quickly—and scale them as your needs grow.
If you’re ready to try this yourself, begin with your top three friction points in code reviews, wire them into your CI/CD checks, and pilot with a single team. Iterate weekly, measure relentlessly, and let your developers be your strongest signal. You’ll be surprised how far a pragmatic, product-led approach can take you.
Inspired by this post on Amplitude – Perspectives.
In my role leading product teams at HighLevel, I’m often asked to explain what’s really happening behind the scenes of today’s AI products. The short answer is that modern systems are built on "Agentic Architecture: How Modern AI Systems Actually Work"—not just a single model, but a coordinated loop of planning, tool use, memory, and evaluation. Once you see that pattern, the design decisions snap into focus and the roadmap becomes far easier to prioritize.
At its core, agentic AI treats the model as a reasoning engine embedded within an AI workflow. The agent interprets intent, plans steps, calls the right tools and APIs, grounds itself in trusted data, and then evaluates outcomes before deciding to continue or stop. This loop creates reliability, reduces hallucinations, and enables the system to operate in real-world, multi-step scenarios.
Here’s the practical lifecycle I rely on. A user provides intent (a goal or request). We run a retrieval-first pipeline to ground the model in accurate, current data. Prompt engineering structures the task and primes the agent with constraints and success criteria while managing context window management. The agent generates a plan, executes steps by calling tools or services, evaluates intermediate results, reflects or revises as needed, and only then returns a final answer with clear citations or evidence.
For more complex work, I orchestrate multiple specialized agents—commonly a planner, a solver, and a critic—coordinated by a lightweight controller. This multi-agent pattern reduces single-agent blind spots, encourages self-checking, and mirrors how empowered product teams collaborate. Whether it’s conversation design for support flows or a voice AI agent driving hands-free tasks, orchestration is the difference between a clever demo and a dependable product.
Memory is the second pillar. Short-term working context sits in the prompt, while long-term memory lives in vector stores or databases to track past interactions, preferences, and outcomes. Retrieval augments the model with the right facts at the right time, and tight context window management ensures the agent stays focused on signal, not noise. The result is faster responses, lower costs, and far better accuracy.
Reliability is earned through eval-driven development and robust AI risk management. I define offline and online evaluations, guardrails, and human-in-the-loop checkpoints before scaling traffic. These evaluations become living, automated tests that protect against regressions as prompts, models, and tools evolve. The payoff is real: fewer escalations, higher trust, and measurable improvements to quality over time.
From a product strategy perspective, I resist over-engineering. Start with a simple retrieval-first pipeline and a single agent; prove value; then layer in multi-agent orchestration only where it moves key metrics. Instrument everything—latency, cost, grounding coverage, and outcome quality—and build Agent Analytics dashboards so teams can diagnose issues and iterate with confidence.
If you’re looking for a practical playbook, here’s mine: clarify the user intent and success criteria; design the tools the agent can call; ground with authoritative data; write prompts that constrain scope and define termination conditions; add reflection and automated evaluations; and ship behind feature flags for safe, staged rollout. Each step compounds reliability without killing velocity.
The diagram and the video above bring these patterns to life. If you watch closely, you’ll see the same loop—plan, retrieve, act, evaluate—show up in every effective implementation, regardless of domain. That repetition isn’t accidental; it’s the backbone of agentic architecture and a blueprint you can adapt to your own stack.
Ultimately, what matters is outcomes. When we build around agentic AI, we create systems that are explainable to stakeholders, maintainable by engineers, and genuinely helpful to customers. That’s how we move past hype to durable impact—shipping AI products that plan, learn, and execute at scale.
Leading the Support function for a company that builds a leading Agent and AI-forward customer service platform has been, for me, unique, exciting, and yes—daunting. It’s where product ambition meets operational reality, and where every decision I make is immediately tested by customers who expect excellence.
It’s unique because we use the same technology as our customers. We live in the product every day, which puts us in a privileged position to be the voice of the customer across the organization. That tight feedback loop has shaped how I prioritize, what I build next, and how I measure success.
It’s exciting because we get to try all of the new features and capabilities of Fin and the Intercom helpdesk. With a relentless focus on AI innovation, I’ve had access to remarkable tools that help us deliver an incredible customer experience—and I’ve seen firsthand how the right workflows and guardrails turn those tools into outcomes.
And it’s daunting because expectations for our own Customer Support (CS) team are sky high. If we can’t deliver incredible support using our own technology, we undermine its value proposition. That imperative has kept me honest, focused, and fast.
In our new research, “The 2026 Customer Service Transformation Report,” we’ve been sharing how forward-looking teams use AI to transform their support models. If you’d like to get straight to the report, download it here.
When Intercom changed its focus in late 2022 to prioritize the customer service use case, we undertook a critical review of the support experience we were delivering and committed to driving meaningful change under an AI-first framework. That was a turning point: I aligned product strategy and operations around a single north star—automate with quality, and elevate humans to higher-value work.
Three years on, Fin now resolves over 81% of all our customer support volume, delivering immediate and high-quality resolutions. We have absorbed a 300%+ increase in customer demand since 2022 without proportional headcount growth. Without Fin, we would have needed at least 100 additional CS team members to meet that demand and our improved service levels – a net saving to Intercom of between $7.5M–$9M annually.
Throughout this work, we drew on research from the 2026 Customer Service Transformation Report and applied the lessons directly to our own org design, knowledge management, and AI workflows. What follows is our story of transformation and how we achieved a mature deployment of Fin.
The problems we set out to solve
Back in 2022, our challenges looked familiar to any modern support organization, and I knew we needed a step-change—not incremental tweaks.
We faced increased support demand from new and existing customers: Intercom was launching major features and changes at speed, driving up overall customer conversation volume and requiring additional headcount for the CS team. I could see we were scaling people faster than processes—unsustainable without automation.
Our support policy (as defined by our service level objectives) was not based on a high bar: In most cases, we were only committed to “business hours” coverage for the majority of our customers, impacting first response times. Even with SLOs that were not considered best in class, we were struggling to meet our commitments. I wanted 24/7 coverage and faster first responses without sacrificing quality.
We wanted to do more: As we pivoted our strategy, we wanted to open new routes to our support team, such as providing support to website visitors with technical questions and to trial customers. That meant meeting customers earlier in their journey with accurate, on-brand responses—at scale.
What we did
We made a very conscious decision to become our own best reference customer. As Intercom embraced the opportunity that generative AI presented to transform customer service, we intentionally moved to an AI-first strategy for our Customer Support team. I set a simple operating principle: ship value quickly, measure relentlessly, and let evidence guide the next bet.
We started with the highest-volume, informational queries and saw our resolution rates climb quickly. With that foundation in place, we pushed Fin further, training it on deeper documentation and internal procedures, and eventually giving it the ability to take actions on behalf of customers. As Fin took on more complex work, our results started to compound—and trust in the system grew across the organization.
Early adoption and building trust. When “AI Assist” features came to the Intercom Inbox, the CS team got early exposure to AI and were empowered to provide feedback directly to our product teams. This built awareness and trust across the team about what we were trying to achieve with AI, and helped shape the product roadmap. We were also the first beta customer for Fin, rolling it out to a subset of customers to watch sentiment and outcomes closely. With no adverse reaction and an initial resolution rate of over 25%, we deployed Fin to most customer segments within weeks. I’ll never forget the first week we put Fin in front of real customers—the silence of issues that never reached humans was the loudest signal of success.
Knowledge management as a product. We recognized quickly that time spent tuning our help center and knowledge assets for Fin would pay dividends. We transitioned our Help Center Manager into a “Knowledge Manager,” with a dedicated remit to optimize content for Fin. We embedded knowledge creation into our “New Product Introduction” (NPI) process, targeting that Fin would resolve at least 50% of customer issues at every new product and feature launch. Over time, we added new sources, including “Developer Documents,” enabling Fin to handle increasingly complex issues. We built a culture of continuous improvement—allocating “out of the inbox” time so every teammate could close content gaps and raise the bar.
Conversation design end-to-end. To ensure a consistent, high-quality customer experience, we created a new “Conversation Designer” role that owns the journey across automation and human handoffs. Using Intercom’s Workflows, we introduced “skills-based routing” so that when a customer asks for a human, the conversation reaches someone with the right expertise quickly. This is now handled by Fin directly using a feature called “Attributes.” The result: a seamless, on-brand experience regardless of channel or escalation path.
Leaders are racing ahead with real AI in support. Explore the 2026 Customer Service Transformation Report to see where deployment is stalling, benchmark your team, and get practical steps to scale automation that delights.
Organization changes that unlocked leverage. As we scaled Fin, we stood up a dedicated AI Support team under a senior CS leader to continuously optimize automation and define our AI adoption strategy across the journey. We restructured human roles into “Technical Support Specialist” and “Technical Support Engineer” to better align with the complexity of incoming work. We also expanded Support Operations to focus on optimization—using AI to uplevel Enablement, Workforce Management, QA, Process Management, and Data Insights. Just as important, we reset expectations about the balance between time spent supporting customers directly versus improving AI. That mindset shift created compounding returns.
Pushing Fin further with new capabilities. As capabilities matured, we were early adopters and saw measurable wins:
Fin Guidance: Multiple Guidance rules provide additional controls and a more personalized, targeted experience for customers.
Fin Tasks and Procedures: Enables Fin to carry out activities such as updating customers on incident status and deep troubleshooting for technical issues.
Insights: AI-driven dashboards provide deep insight into Fin’s performance and surface recommendations for further optimization. Insights also provides a Customer Experience (CX) Score for every customer interaction, enabling more targeted improvement efforts and opening up new ways to close the loop with customers who have had a poor experience.
What we achieved
What started as a focused effort to improve our customer support experience became the strongest proof point for what’s possible when you fully embrace AI. Fin now resolves over 81% of all our customer support volume and has allowed us to absorb a 300%+ increase in demand without proportional headcount growth. Over 90% of our customers now benefit from improved first response performance, 24/7 coverage, and outbound phone support.
What the numbers don’t fully capture is the shift in how our team operates. With volume absorbed by Fin, our CS teammates now deliver consultative support—guiding next best actions, deepening product adoption, and contributing directly to retention and expansion. Customers that receive these engagements adopt Fin at a much deeper level and achieve greater support success. What was once a reactive, volume-driven team is now a function that generates significant revenue.
What’s next
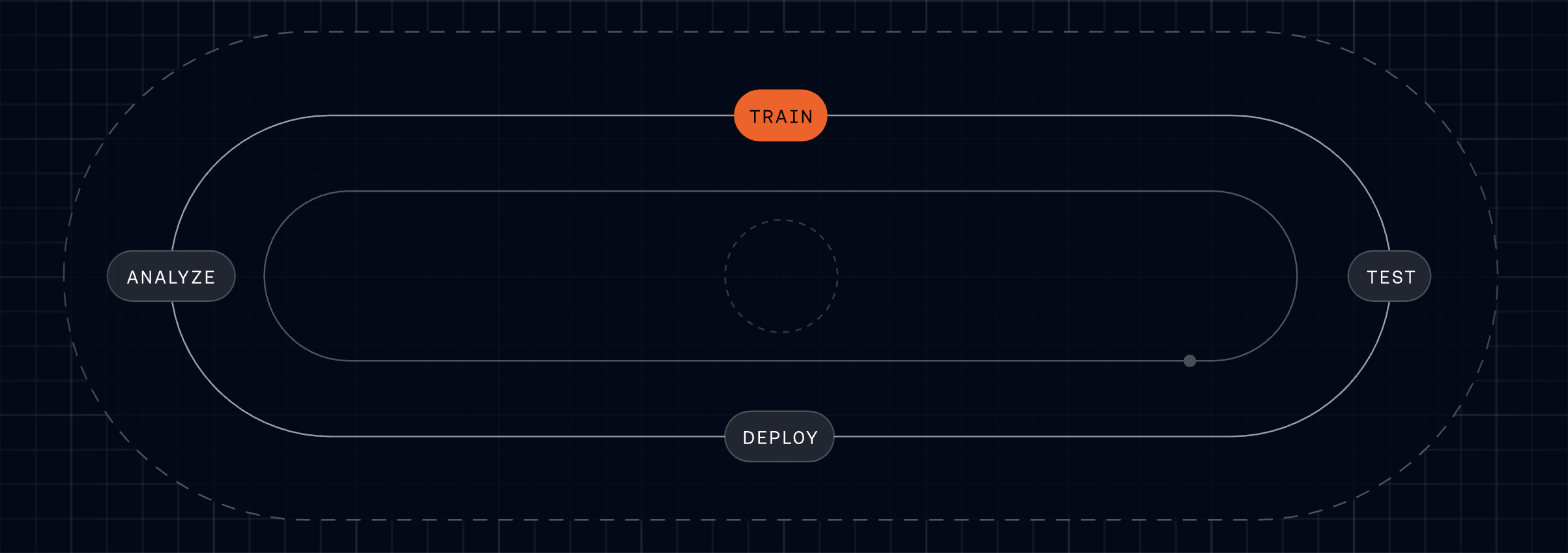
Customer expectations are always rising, so we’re building on our progress by embracing the Fin Flywheel—an actionable framework for ongoing improvement and optimization. This keeps us honest about the discipline required to sustain AI performance at scale.
Train: Teach Fin to resolve even the most complex queries with Procedures, knowledge, and policies.
Test: Run fully simulated customer conversations from start to finish to see exactly how Fin will behave before going live.
Deploy: Set Fin live across every channel – voice, email, chat, and social – for consistent support wherever customers reach out.
Analyze: Use AI-powered Insights to analyze and improve Fin’s performance and deliver better customer experiences.
We are also investing in our support teammates so they can adjust to the new world of AI—taking on more complex work and being valued for the subject matter expertise, consultative engagement, and empathy they bring to the role. That human layer is where differentiation shines.
We will continue to develop and share best practices for deploying an Agent, based on our own experience with Fin and the lessons learned from our most forward-looking customers. These are captured and continually evolving in The Agent Blueprint.
Transformation takes commitment
The most successful teams aren’t bolting AI onto old processes; they’re rebuilding support around it—investing in knowledge and people alongside technology, and treating AI as a continuous discipline rather than a one-time deployment. That’s the real change required. For support teams willing to make it, there’s a rare opportunity to redefine what customer service can deliver—higher CSAT, faster resolution, and durable ROI.
I’ve long believed a simple truth about AI in customer support: if AI is going to earn trust, pricing has to be aligned with value. That principle has guided my product decisions and the way I hold our teams accountable for measurable outcomes, not activity.
When we shared our perspective on pricing AI Agents in 2023, we made a simple argument: if AI is going to earn trust, pricing has to be aligned with value. At the time for Fin, that value was clear. You pay when the AI resolves a customer’s problem. If it doesn’t, you don’t. That’s fair, easy to understand, and grounded in results, not activity. We were the first to introduce this pricing model because we believed that pricing and value should be inherently linked.
That belief hasn’t changed, it’s grown stronger over time. What’s changed is what Fin can do. As we expanded capabilities and pushed deeper into complex workflows, it became clear that measuring value solely by end-to-end resolutions no longer captured the full picture of impact.
Resolutions were the right place to start. Historically, we measured value based on whether Fin fully resolved a conversation on its own. These are known as resolutions and they gave support teams a clear way to measure ROI, easily comparing the cost of AI versus human support. They also aligned our incentives with our customers, as our revenue was directly tied to Fin’s performance.
That clarity worked. Today, more than 7,000 teams use Fin. Our average resolution rate across customers has increased every month and now stands at 67%, even as Fin increasingly handles more complex queries. That progress came from building an Agent that could take on harder problems and still deliver.
But as Fin got more powerful, “success” stopped being binary. I saw this first-hand in customer design sessions where policy, risk, and compliance needs rightly demanded human-in-the-loop confirmation. We weren’t failing to deliver value; we were delivering it differently.
Over the last couple of years, we invested heavily to ensure Fin could handle the most complex parts of support. As Fin’s capabilities expanded, customers began pushing what Fin can do for them by deploying Fin deeper into their workflows to handle the toughest queries.
In some cases, this required Fin to work in tandem with a human agent because that’s what customer policies and oversight needs dictated. Subscription changes, transaction disputes, billing issues, and other multi-step support scenarios can often require Fin to gather context, read and write to external systems, and execute actions before handing off to a human agent for confirmation.
Fin is still doing what it was configured for – intentionally handing off after doing more of the heavy lifting, saving valuable time for support teams and overall time to serve for their customers. But our pricing metric only recognized value when the conversation ended in a full “AI resolution” (i.e. a human was never involved).
That’s why we’re evolving Fin’s pricing metric from resolutions to outcomes. This shift reflects how customers now define value: not just in full automation, but in safe, efficient progress toward the right result across complex, multi-step, and policy-constrained workflows.
An outcome represents when Fin successfully completes the action it was configured to perform, as part of a conversation. Resolutions are still one type of outcome Fin can deliver, where it handles the issue end-to-end. Another type of outcome can be a Procedure where Fin gathers context, takes action, and hands the conversation off when that’s what customers configured it to do.
Kick off your journey with the #1 Agent—an AI partner designed to turn resolutions into real outcomes. Tap “Start a free trial” to explore faster, smarter customer service and see how Fin delivers value from day one.
Increasing end-to-end AI resolutions is still a core component of scaling Agents, but they are no longer the only measure of Fin's success and utility. Especially as Fin takes on more complex work. Moving to outcomes recognizes that solving a customer problem with full automation isn’t always appropriate. It’s about getting to the right result, safely, and efficiently.
As Fin’s capabilities expand, teams should feel empowered to use it in more nuanced, collaborative work. Outcomes support that by allowing customers to design workflows that meet compliance requirements and include a human agent when necessary. From a product management standpoint, this is how we align incentives, keep risk controls intact, and still accelerate time-to-value.
Fin is becoming even more powerful at handling complex, multi-step support queries. With outcomes, we can support that growth without constantly reinventing how value is measured. And this change gives us a strong pricing foundation that can scale as Fin continues to grow and take on more roles beyond service. This aligns with our vision of Fin becoming a “Customer Agent,” capable of handling the entire customer experience.
What this means for pricing is intentionally straightforward. An outcome will be counted when Fin successfully completes an action it was configured to perform, as part of a conversation. That keeps the model predictable for finance leaders while staying transparent for operators and product teams managing AI workflows.
The pricing model stays simple and the definition of value becomes more accurate. In other words, we’re doubling down on fairness, predictability, and competitiveness—core tenets for any consumption SaaS pricing strategy tied to real business impact.
When we first wrote about outcome-based pricing, we said that trust is the currency of AI. That’s still true. Trust is earned when customers see pricing move in lockstep with utility and risk posture, especially as gen AI and agentic AI take on higher-stakes tasks.
Pricing has to feel fair, it has to be predictable, and it has to stay competitive. Evolving from resolutions to outcomes isn’t a departure from that belief. It’s the natural maturation of how we measure value as AI moves from simple Q&A into complex procedures and human-in-the-loop collaboration.
Fin has grown more powerful because customers asked more of it. Outcomes are how we reflect that progress honestly, while staying true to the same principles that guided us from the start. This is product strategy in action: align incentives, measure what matters, and scale what works.
And as Fin continues to get stronger, we’ll keep holding ourselves to the same standard: price based on the value delivered. That’s how we build durable trust, sustainable ROI, and a better customer experience at scale.
Can an AI agent actually run a credible content audit end to end? I put that to the test. In my role leading product at a high-growth SaaS and as a hands-on content strategist, I’m constantly balancing depth with reach. During a recent office-hours discussion, someone asked me to zoom out and explain when to use Claude Code. That prompt inspired me to launch a running series—Conversations with Claude—showing exactly how I apply it to real product management and SEO problems.
I’m a heavy user and share what works for me. I receive no compensation from Anthropic for this series; if that ever changes, I’ll disclose it. With that out of the way, let’s dive into how I had Claude conduct a full content audit—and why the results exceeded my expectations.
For the first installment, I chose a fairly complex use case: a comprehensive content audit of my site. I expected this to be a slog. Instead, it was refreshingly fast and rigorous once I set Claude up with the right scaffolding.
I kicked off with a simple directive: start by asking clarifying questions, proceed step by step, and capture notes in a shared task file. I also provided deep context—specifically, the CDH Book (15 chapters + intro) and my entire blog archive in markdown—so the model could reason with my actual corpus rather than guessing from sparse prompts.
Claude began with smart clarifying questions that framed the analysis well. Scope of keywords: Should it focus strictly on concepts unique to or heavily associated with my work like "opportunity solution tree" and "continuous discovery," or also include broader product management terms such as "product outcomes," "assumption testing," and "customer interviewing"? Keyword geography: Start with US-only or include UK/global? Blog coverage assessment: What counts as "well covered"—dedicated deep dives or credible coverage within broader posts? Output format: Add findings to the task file or create a separate deliverable?
Peek inside a Notion-style page that turns content strategy into action: a content-audit task with due date and tags, plus clear steps for keyword research, blog gap analysis, and SEO improvements.
I replied: 1. both 2. us only is a good place to start 3. evaluate this based on how well we rank for the keyword, if we rank reasonably well, you might suggest content improvements to rank better, if we don't rank at all, then you might suggest a whole new article 4. add to the task file
From there, Claude read the CDH Book, extracted roughly 100 keywords, ran them through Keywords Everywhere in two batches of 50 to capture search volume, and pulled current domain rankings and traffic metrics. Within minutes, I had a high-signal view of what’s working, where we’re invisible, and how to prioritize fixes.
The good news came first: we own our branded terms—#1 for "product discovery," "opportunity solution tree," "continuous discovery," and "product trio." That brand equity is doing real work for us.
The biggest gaps were in broad topics the CDH Book covers but where there’s no targeted content. "Outcomes vs outputs" (1,300/mo) — Arguably THE central thesis of CDH, and no ranking. This is the single biggest gap. "Product roadmap" (4,400/mo) — I have a strong anti-roadmap POV but no content targeting this. "Product strategy" (1,900/mo) — Ch 7 argues strategy = opportunity selection. Strong differentiator, no ranking. "Story mapping" (5,400/mo) — I use story maps uniquely (for surfacing assumptions). Huge volume. "Stakeholder management" (2,900/mo) — Ch 13 is entirely about this. No ranking. "Pre-mortem" (4,400/mo) — I cover this as a product discovery technique. No ranking.
Inside a dark-themed writing workspace, a long-form chapter is open while a tidy folder tree catalogs pages and chapters. The scene invites readers to think like auditors—inventory content, track structure, and surface gaps with AI assistance.
The trojan horse opportunity: High-volume generic terms like story mapping, pre-mortem, and usability testing could bring in readers who don't know about CDH yet. Write about these broadly-searched topics with my specific product-discovery angle.
In just a few minutes, Claude generated an analysis of what keywords we ranked for and at what position, a ranked set of high-, medium-, and lower-volume (but strategic) keywords where we didn’t rank yet had relevant content, concrete net-new topics to close the gaps, and a list of existing articles to update to lift their SERP positions. It worked far better than I expected.
Here’s how I set it up so the model could deliver: I didn’t simply ask Claude.ai to "audit my site" and hope for the best. I supplied rich, relevant context (my book and all blog posts as markdown) so it could anchor on my language, frameworks, and mental models. I paired that with live data via APIs like Keywords Everywhere to ground recommendations in actual search volume and competitive rankings. With the right inputs, Claude Code behaved like a capable research analyst and an SEO strategist—able to reason, prioritize, and suggest high-leverage actions.
Next, I went deeper and used the findings to draft a long-form article that addresses the biggest gap—"Outcomes vs outputs"—and ties it directly to product roadmapping and sprint planning. I wove in continuous discovery practices, opportunity solution tree techniques, and product trios collaboration to make it actionable for empowered product teams. I’ll share the end-to-end workflow—including files, prompts, and the editorial QA checklist—in a follow-up.
If you’re new to Claude Code and want a practical starting point, replicate the setup above: assemble your canonical sources in markdown, define a clear evaluation rubric, and ground keyword research with reliable volume data. If you want my exact task file, clarifying-question template, and step-by-step audit rubric, tell me which content gap you’d prioritize first and why—I’ll tailor the walkthrough to the highest-interest topic.
Every update we shipped this month removed a specific constraint on what teams can do with Fin. In my world, the demo-to-production gap shows up as complexity, control, and confidence. Can the agent handle the query that actually matters? Will it sound right on a call? Can the team deploy it without filing an engineering ticket? Can managers understand what it’s doing? That’s the bar I hold us to.
This month, we delivered answers to all four. Here’s how.
Procedures and Simulations (0:51). The hardest problem in AI-powered customer service isn’t answering FAQs—it’s executing complex queries with real business logic and real consequences if anything goes wrong. Think billing refunds, multi-step flows, and actions that must be right the first time.
We made it dramatically easier to build and manage Fin for those complex queries—without pulling in an engineer. You can author in natural language, test every step in simulation, and deploy with confidence.
The workflow starts with AI drafting the procedure from your existing source material. You edit in natural language, with structured hooks to pull in live data, apply business logic, and add code for deterministic control where you need it. That’s how you handle multi-step flows with the precision that matters when things go wrong.
Simulations are the test environment. Define a test case, pass in the data Fin would receive in a real conversation, and watch it work through each step. You see what Fin is doing, why, and whether it’s meeting the criteria you set. Full transparency at every point. I’ve run these end-to-end myself, and there’s a particular confidence that comes from watching it work before it goes anywhere near a customer.
A conversational moment from the February Fin Product Updates recap: two teammates trade insights with laptops open, while a bold pull-quote drives home the promise—Fin removes complexity to start selling and supporting in under two minutes.
For a deeper look at Procedures and Simulations, head to fin.ai/procedures.
Fin Voice: three major updates. When something’s off in chat, it can take a few exchanges to notice; on a call, it’s immediate. Pronunciation, noise handling, and tone all matter because they’re the customer’s first impression.
Pronunciation rules (4:18). Fin has high out-of-the-box pronunciation accuracy, but it doesn’t know your brand—your product names, your industry terminology, the way your company uses certain words. Alihan Zinna, Staff ML Scientist, showed this with an IKEA example: without pronunciation rules, Fin mispronounced both “IKEA” and a product name; after adding rules, both were corrected and sounded natural.
New natural voices (5:48). We’ve added 11 new voices tuned to a range of brand tones so you can choose one that sounds like it truly belongs to your company—not a generic AI assistant.
Background noise reduction (6:28). People call from airports, shops, and busy offices. Fin now monitors background noise continuously and increases noise reduction when the environment demands it. No configuration needed. As Alihan put it, “This is one of those things customers really notice when it’s not working. The goal was to make it invisible. That’s what we built.”
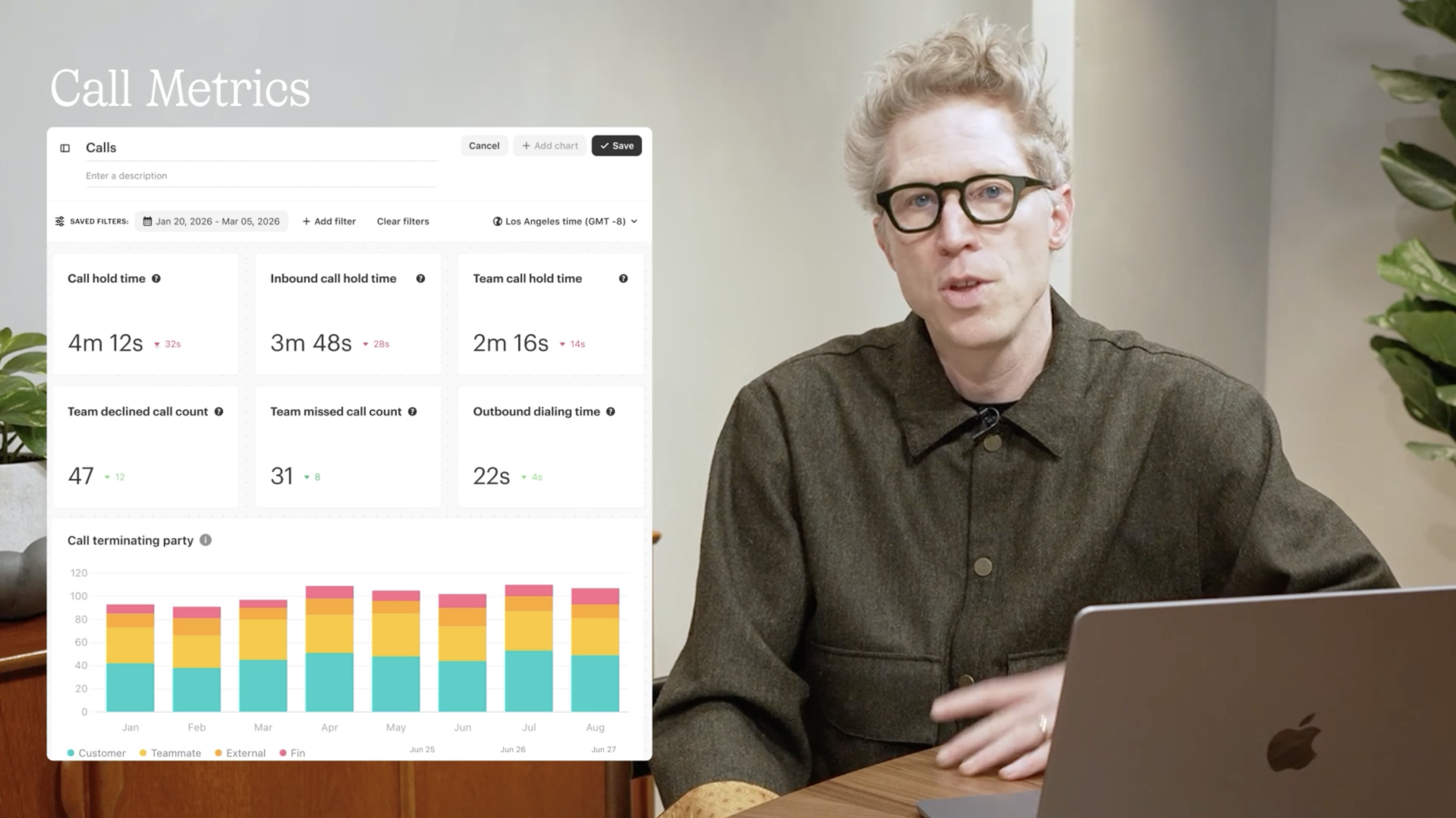
Catch up on February’s Fin Product Updates with a walkthrough of the Call Metrics dashboard—saved filters, hold‑time tiles, missed and declined call counts, and a monthly breakdown that helps support teams act faster.
Shopify setup experience (8:21). Fin began as a Service Agent and is quickly becoming a Customer Agent—working across the whole lifecycle to support, sell, and guide, even before a customer has an issue. The revamped Shopify setup is a clear step forward.
Shopify catalogs are complex—thousands of products, variants, and dynamic inventory—and connecting all of that to an agent has historically been painful. We removed the friction.
Setup now takes three steps: first, connect your store. Second, install the Messenger directly in Shopify—no code, just a few clicks. Third, deploy Fin. Total time: under two minutes. We timed it live.
What that unlocks is real. In the demo, a first-time snowboarder asked for recommendations. Fin searched the catalog, reasoned about attributes that matter to a beginner (there’s no “beginner” tag in the catalog), personalized suggestions by height and weight, and added a board to the cart.
Even better, one customer updated their website copy to promote a sale. Fin immediately picked up the new context and began recommending sale items, nudging shoppers to add more to the cart to access a discount—no extra configuration required. It read the situation and acted.
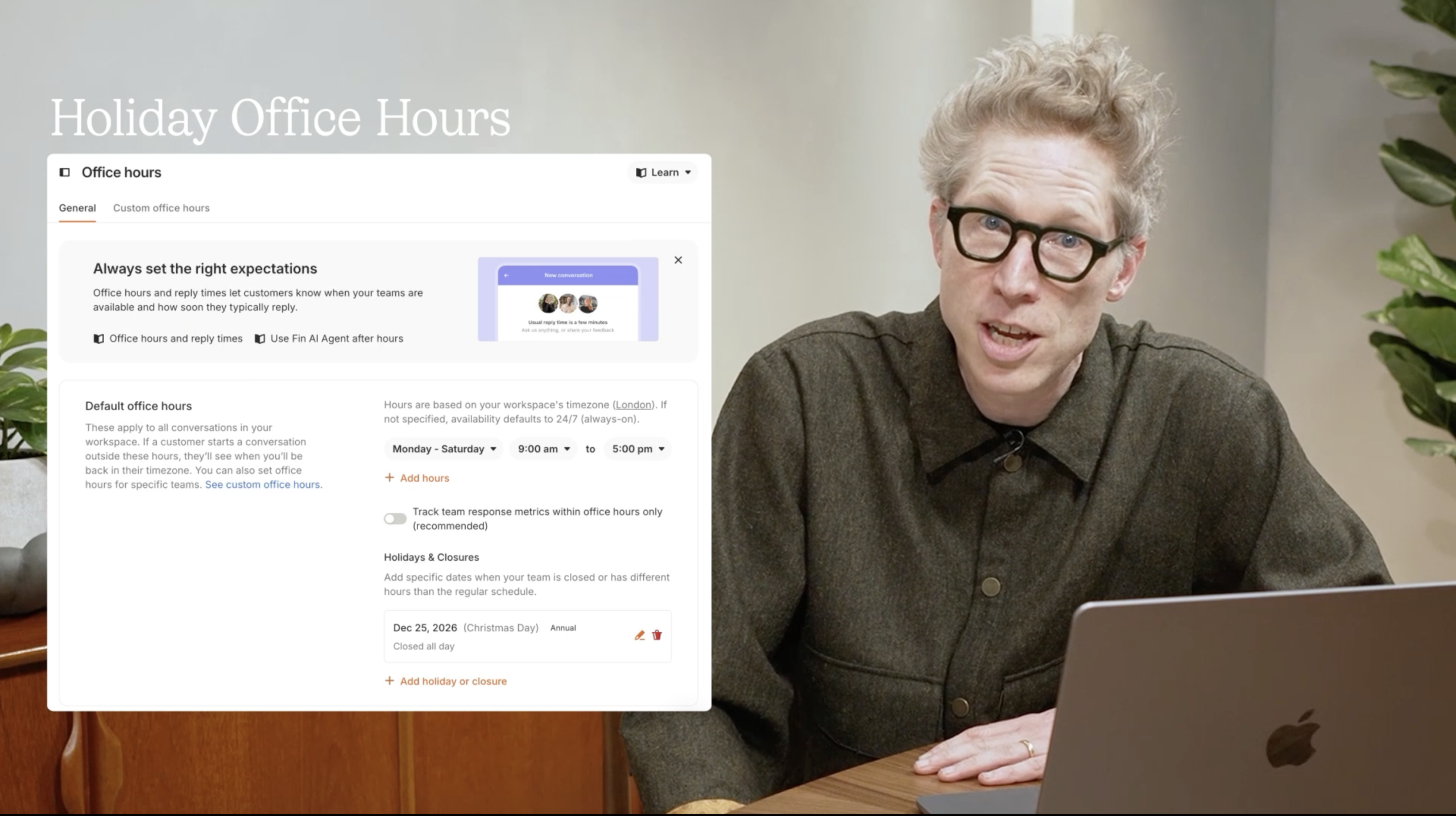
See how the latest Fin update streamlines support scheduling. A product expert walks through Holiday Office Hours, showing how to set default hours, track response metrics, and add closures so teams stay consistent.
Three steps, and you have a real-time shopping assistant that knows your store and sells on your behalf.
Helpdesk improvements (12:31). Fin works with any helpdesk, but many teams consolidate to take advantage of our native Intercom helpdesk integration. We’ve shipped 19 helpdesk improvements in 2026 so far; two from this month stand out.
11 new call metrics. Hold time, outbound dial time, missed and declined calls, call terminating party, and more. These give leaders the visibility to analyze workload distribution and call handling quality in detail.
Holiday office hours. Teams no longer need to manually update office hours for every public holiday. This was the most upvoted request in our community, and we shipped it.
Across the board, we removed the constraints that hold teams back: the complexity ceiling in automation, the quality ceiling in voice, the setup barrier in Shopify, and the operational overhead in the helpdesk.
We closed out the month with a Star Wars–style crawl of 22 additional updates. All features mentioned here are live and available now. Explore more at fin.ai/updates. More to come—see you next month.
Building a great end-to-end customer experience with AI means going beyond support, and I’ve seen firsthand how transformative that shift can be when we treat every interaction as part of one cohesive journey.
Every customer touchpoint, from the first sales conversation through to post-sales support and success, is an opportunity to get it right. Other teams are now turning to AI to transform how they show up for customers, and support, which led the way, has already written the blueprint. In my role, I focus on making that blueprint actionable across the entire lifecycle.
In The 2026 Customer Service Transformation Report, it’s clear most businesses are thinking about what’s next, with more than half planning to scale AI to other departments. Interestingly, they often cite their early success with AI in support as motivation for the move. This makes support teams uniquely positioned to help lead the transition, a strategic role unimaginable just two years ago.
In this piece, I share how teams are introducing AI to other parts of the business, how to think about this expansion effort, and the new opportunities it creates for support leaders who want to drive a unified customer experience.
Support was the first proving ground for AI, and our research suggests that businesses are now planning to expand its use to other areas based on the results it’s yielded so far. Fifty-two percent of respondents said that their organizations are actively planning to scale AI to other departments in 2026.
What will this look like? Leading companies are already finding out.
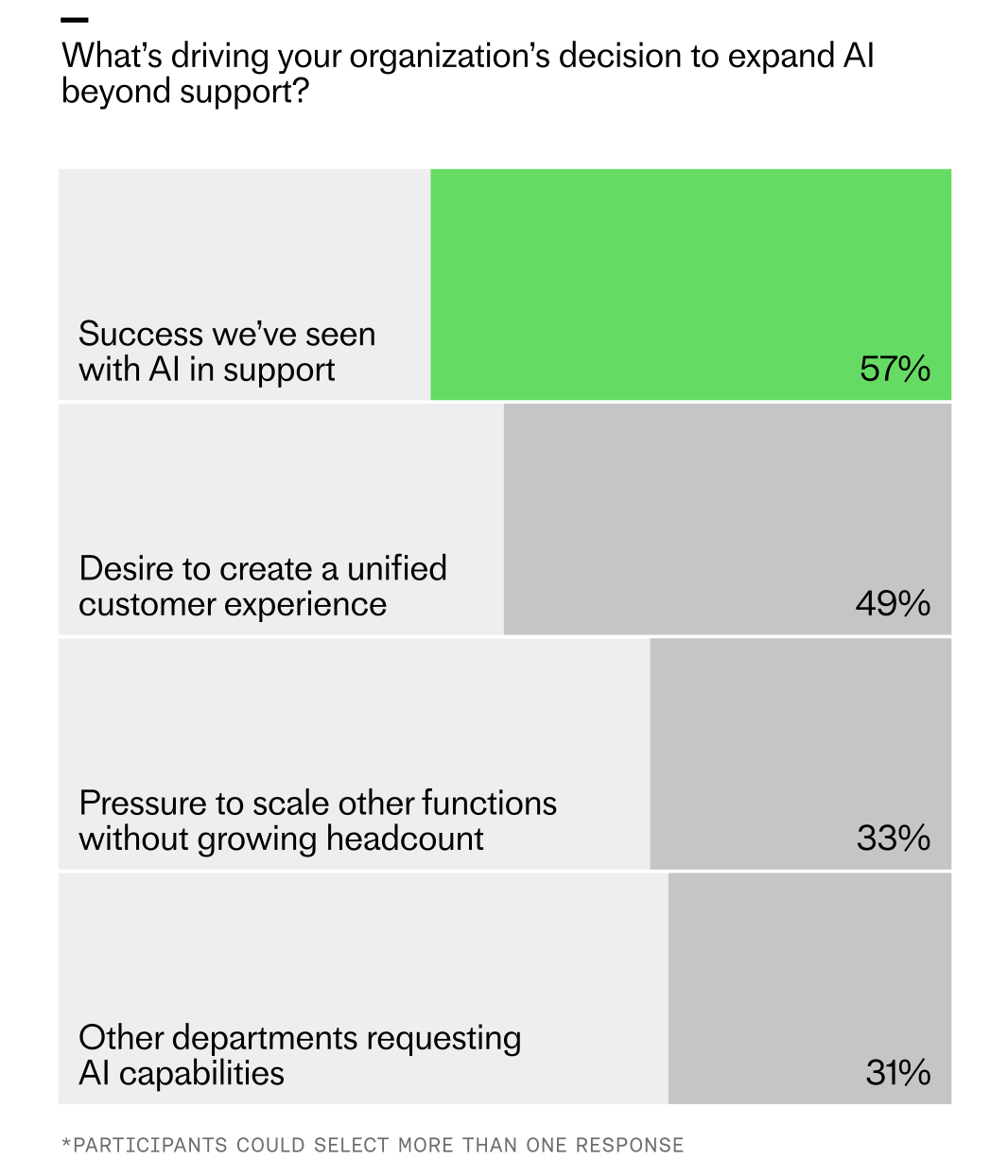
Wins in support are setting the pace for company-wide AI. Survey results rank the drivers: proven success in support (57%), the push for a unified customer experience (49%), scaling other functions without more headcount (33%), and cross-department demand (31%).
My favorite example is WHOOP, the fitness wearables company. They offer a premium product which makes their sales conversations more consultative than transactional. Customers want to know “Which membership is right for me?” or “How often do I need to charge my WHOOP?” According to Emily Shirley, Business Manager for Growth Product at WHOOP, if someone chatted with the inside sales team, they were twice as likely to convert, but they didn’t have enough reps to respond to incoming queries fast enough. Customers could wait more than 10 hours for a reply.
With a big product launch on the line and an anticipated spike in prospective customer conversations, their three-person team needed help. So they deployed Fin to the "Join" page, the final step before purchase.
With Fin resolving 84% of inbound questions, the sales team was able to focus on high-value leads. Together, they drove a 130% increase in attributable sales. The team is now exploring ways to expand Fin beyond FAQs, focusing on personalised conversation flows, multi-product recommendations, and richer data capture. As Emily says: “There are so many parts of the buyer journey where this applies. We’ve only scratched the surface.”
It’s clear there’s a desire to push AI to other parts of the customer lifecycle, but there is a risk hidden in this expansion. If sales, customer success, and other departments all launch their own Agent, each operating in isolation, you can end up fragmenting the very thing our research says teams want to create. The second-most cited reason for pushing AI beyond support: desire for a unified customer experience.
Without shared context, each handoff becomes a source of friction where customers could receive inconsistent answers or be asked to repeat information. I’ve watched even well-intentioned AI rollouts struggle here—great local wins, but an overall journey that feels disjointed.
A translucent UI visual maps a support-led AI blueprint that scales across the business—from SDR and sales to custom assistants—anchored by layers for goals, memory and user context, business knowledge, and interoperability.
The opportunity (and the challenge) is to keep the customer at the center. Instead of department-specific Agents that operate independently, we must strive for cohesion. That means shared memory, consistent governance, and connected AI workflows that respect the customer’s history and intent across channels.
This is the future I’m building toward: solutions like Fin becoming a “Customer Agent,” capable of handling the entire customer experience. This will mean Fin can function in many roles, supported by a memory that grows with the customer over time and deep knowledge of the business, creating a seamless experience for every interaction. In practice, that’s agentic AI designed to collaborate across teams, systems, and journeys—without losing context.
Pushing AI into new parts of the business requires someone to own the process. And for many organizations, that’s the support team. Nearly a third of respondents (32%) confirmed their customer service teams are leading their business' AI transformation strategy.
This presents a real opportunity for support teams to shape the future of customer experience. Instead of each function reinventing the wheel, support can act as a center of excellence, defining shared standards, guardrails, and operating practices that drive performance.
“You already manage the most complex, high-volume customer interactions; you have rich data on customer needs and behavior; and you know how Agents perform in the real world. Those insights will be invaluable as AI scales across your business.”
Leaders are racing ahead with real AI in support. Explore the 2026 Customer Service Transformation Report to see where deployment is stalling, benchmark your team, and get practical steps to scale automation that delights.
In my organization, when we extended AI from support into sales, we deliberately brought our conversation design expertise, Agent Analytics, and governance models along with it. One team owns the orchestration, memory strategy, and CRM integration so a customer can start with a sales question and end up with a support one—without ever feeling a seam. That continuity is where journey mapping meets product strategy and turns into measurable outcomes.
As Agents like Fin expand their capabilities and move into new areas, I expect many customer service leaders will see their roles expand to include AI implementation across the customer journey. It’s a natural progression for product management leadership in support: owning the experience, the data, and the operating model.
Achieving perfect customer experience is AI’s biggest promise. But in order to get there, teams need to be smart about the solutions they deploy. A unified Customer Agent capable of handling the entire journey end-to-end will have a significant advantage, delivering consistent, context-aware experiences across every interaction.
The Customer Agent future is being built right now, and it’s starting with the team pioneering AI transformation from the very beginning: support. For leaders in these organizations, this is a rare opportunity to shape how customer relationships will be built and maintained in the AI era.
If you’d like to dig deeper into the data and benchmarks guiding these decisions, download The 2026 Customer Service Transformation Report.