Making the leap from engineer to CEO demands an almost entirely new skillset. I’ve felt that jolt firsthand: the tools that serve you as an IC or even a product leader—system design, crisp PRDs, elegant roadmaps—only get you about 20% of the way. The rest is learning to orchestrate go-to-market strategy, finance, hiring, culture, and product positioning with just enough depth to make sound, fast decisions while empowering true experts to execute.
My operating heuristic is the 80% rule. As CEO or GM, I don’t need to be the best marketer, seller, or finance leader; I need to understand 80% of each function well enough to set a compelling product strategy, ask the right questions, and catch the second-order effects. That breadth unlocks speed, quality of judgment, and the conviction to say no when the organization is tempted by what it can do rather than what it must do.
The clearest illustration comes from the journey that turned Apache Kafka—originally built at LinkedIn—into Confluent, a publicly traded enterprise software company. The technical insight was powerful, but the real lift came from translating that insight into a repeatable go-to-market engine. That required building new muscles: founder-led GTM, enterprise sales orchestration, and open source monetization without alienating the community that fueled adoption.
Early on, the product was “embarrassing” by enterprise standards—thin features, sharp edges, and a long tail of operational gaps. Shipping anyway was the point. A thin vertical slice into the market created learning loops with real customers, not hypotheticals. That uncomfortable speed became a superpower, especially when the company decided to push toward a cloud-first business in the face of widespread opposition.
The messaging challenge was just as hard as the technical one. Most marketing fails because it starts with what we built, not what customers must achieve. A simple product marketing pyramid—vision at the top, category framing and points of parity in the middle, crisp value props and proof at the base—helped explain Kafka to the world in customer language. When the narrative snaps into place, adoption accelerates. In Kafka’s case, one well-timed blog post clarified the “why now” and unlocked a step-change in community and enterprise pull.
There’s a pivotal distinction leaders underestimate: the gap between what a company can do and what it must do. I use a must-do filter before every planning cycle: What moves are non-discretionary for durable product-market fit? For Kafka and Confluent, that meant ruthless prioritization on managed cloud services, reliability, and platform scalability—even when it jeopardized short-term revenue or required retooling how engineering, sales, and support worked.
Fundraising strategy mirrored this clarity. Planning to raise before building the full product wasn’t about hype; it was about matching capital to the physics of the problem. If your category requires enterprise credibility, global infrastructure, and 24/7 SRE, you finance those table stakes early. That’s first principles decision making: instrument the constraints, then design the sequence that gets you to scale with the fewest irreversible mistakes.
In the early years, every product decision felt like a trade between polish and learning. The team essentially bludgeoned its way into a cloud-first posture—less because the initial product was ready, and more because the market’s must-do was obvious. That’s the essence of founder-led GTM: get into the field, close lighthouse customers, and use their arcs to shape the roadmap. It’s also where open source monetization matures from downloads into durable, enterprise value.
As the organization scales, excellence often erodes—the Chipotle problem. Process hardens; quality blurs; the magic decays. The antidotes are simple but hard: a few non-negotiable product quality bars, a short set of product-market fit metrics that everyone can recite, and empowered product teams who own outcomes over output. This is where organizational development matters as much as code: design clear interfaces between product, sales, and success, and you’ll keep velocity without losing standards.
Contrary to popular lore, founder optimism is overrated. Constructive realism wins. I try to model “probabilistic optimism”: assume we will win, but instrument the journey like an SRE runs an incident. Set leading indicators, rehearse failure modes, and make pre-commitments to the must-do path so you’re not swayed by the latest anecdote. It keeps the team out of a failure mindset while making room for rigorous course correction.
Giving up the right things at the right time is a CEO superpower. As complexity grows, I hand off decisions that benefit from specialization and keep only those tied to company narrative, must-do prioritization, and talent bar. CEO time management becomes a portfolio problem: ensure each week contains deep product time, frontline customer exposure, and one compounding systems fix (hiring loop, pricing rubric, or GTM enablement) that pays back for quarters.
If you’re moving from IC or PM into a GM/CEO role, here’s a practical playbook: build your product marketing pyramid; write the one-page must-do memo for the next six quarters; ship a narrow, managed cloud slice early; pick three product-market fit metrics (usage, time-to-value, retention) and publish them company-wide; and architect an enablement engine that turns field learnings into roadmap changes within one quarter. That’s how you transform technical advantage into a category-defining business.
The Kafka-to-Confluent arc reminds me that technology can open a door—but clarity of narrative, sequencing, and must-do focus determines whether you walk through it. When in doubt, bias toward shipping, talking to customers, and tightening the loop between what you learn and what you build. That’s the work of product management leadership at scale.
“Outcomes over outputs” is the right mantra—and one I’ve championed across product teams—but turning it into daily practice is where most teams stumble.
It’s simple in theory: focus on the impact of what we build, not just shipping features. In reality, it’s rarely black and white because most teams are asked to do both—hit outcomes and deliver specific outputs—at the same time.
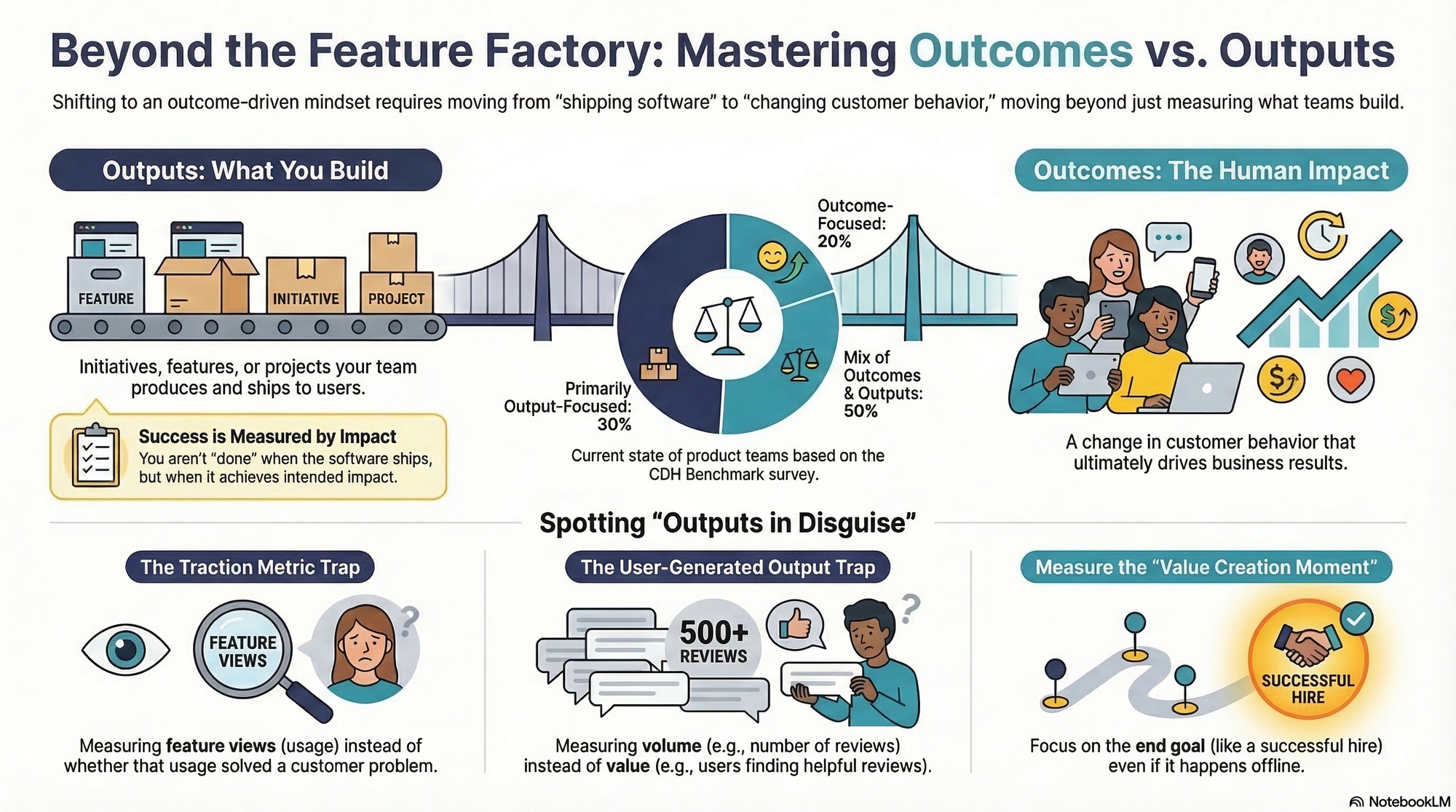
In a benchmark survey, 20% of product teams claim to be outcome-focused, nearly half describe themselves as working in a mix of outcomes and outputs, and about 30% are still primarily working with outputs. I’ve seen versions of this in my own org: we aspire to outcomes, but our rituals, roadmaps, and reporting still reward shipping.
Here’s how I draw the line clearly, coach my teams to avoid common traps, and negotiate better, more actionable outcomes that unlock genuine product discovery and business results.
Simple definitions we live by
An output is something you build or produce—a feature, a project, an initiative. It’s something your team ships.
An outcome is the impact of that output—a change in customer behavior or a business result.
Josh Seiden puts it well in his book Outcomes Over Output: “An outcome is a change in human behavior that drives business results.”
Shift from shipping to shaping results. This graphic clarifies outputs vs outcomes, revealing that value emerges between deliverables and impact—when features change customer behavior and move business results.
I distinguish business outcomes from product outcomes. Business outcomes are typically financial metrics that measure the health of the business (e.g. increase revenue or reduce costs) while product outcomes measure a customer behavior in the product or a sentiment about the product.
Here’s a simple example I’ve used with platform teams. Many B2B companies support a number of integrations. Integrations are outputs. Having integrations alone doesn’t create value. Customers using and finding value in those integrations—that’s an outcome. If those customers retain their subscriptions longer because of the integrations—that’s also an outcome.
Building something isn’t the same as creating value. That’s the core of this distinction, and it’s what separates empowered product teams from feature factories.
Why this distinction matters for empowered product teams
When we task teams with delivering outputs, they’re done when the software ships. When we task teams with delivering outcomes, they aren’t done until the software ships and has the expected impact.
That small shift changes almost everything about how a team works: what we measure (impact, not just delivery), how we know we’re done (measurable behavior change, not release notes), the autonomy we grant (told what to achieve, not what to build), and the planning artifacts we use (an opportunity solution tree beats a feature roadmap when we’re exploring the best path to an outcome).
When I assign outcomes, I’m giving the team latitude—and responsibility—to figure out the best path to success. That’s what opens the door for real product discovery and continuous discovery habits.
Shift your lens from shipping features to achieving impact. This side-by-side visual explains how outcome-driven teams measure success, grant more autonomy, define 'done' by results, and plan with an opportunity solution tree.
Examples: spotting outputs disguised as outcomes
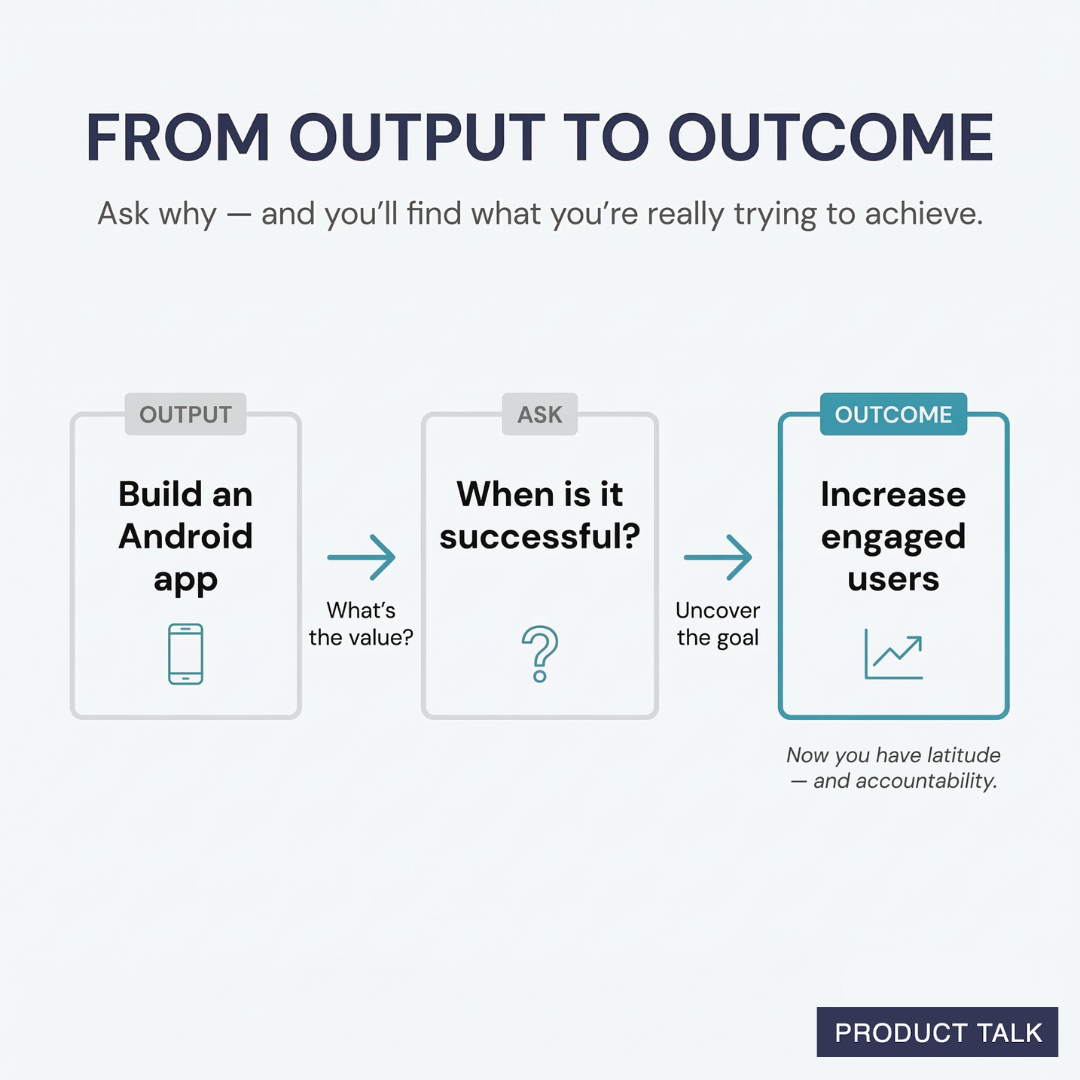
Clear-cut example: “Our outcome is to deliver an Android app.” An Android app is something we build and ship. It’s clearly an output.
To get to an outcome, I ask, “What’s the value of having an Android app?” or “How will we know the Android app is successful?”
We might answer: “Having an Android app will allow us to engage more users. We’ll know it’s successful when people engage with the app on a regular basis.”
This answer uncovers the hidden outcome: engage more people. Now we can set the right scope: increase the percentage of engaged users across any platform; increase the percentage of engaged mobile users; or increase the percentage of engaged Android users.
Any of these outcomes gives us more room to explore than a fixed output. Maybe we don’t need a native app at all. We could deliver the same engagement through a mobile web experience, notifications, or email. And we’re not done when we ship—we’re done when the right people are actually engaged.
Tricky example 1: measure the value creation moment (hires, not applicants)
Move beyond shipping features to the impact that matters. This visual maps the path from build an Android app to the real goal, increase engaged users, by asking why, defining value, and owning results.
When setting outcomes, it’s tempting to choose the easiest-to-measure metric. But a good outcome measures the customer’s value creation moment.
I worked at a company that helped new college grads find their first job. When I started working there, the primary outcome was “increase job applications.” This technically is an outcome—it measures a specific behavior in the product.
But it doesn’t measure the value creation moment. A job seeker doesn’t get value when they apply for a job. They only get value when they get the job. Similarly, employers don’t get value from any job applicant, they get value when the right job applicant applies.
Many job boards try to measure qualified applicants—instead of counting any applicant, they compare the credentials of the applicant to the job description and only count qualified applicants. This is better. But it still doesn’t measure the value creation moment. Both the job seeker and the employer get value when an open job is successfully filled. The right metric is hires.
Yes, “hires” can be hard to instrument because it happens off-platform and incentives misalign. Measure it anyway, even with proxies. The easy metric isn’t always the right outcome.
Tricky example 2: measure impact, not user-generated output (the course reviews trap)
I worked with a team that helped students choose university courses. They set their outcome as: “Increase the number of course reviews on our platform.”
Confusing activity with impact? This visual breaks down four common outcome traps—measuring at the wrong moment, mistaking outputs, chasing adoption, and relying on sentiment—so teams focus on real value.
Sounds like an outcome, right? It’s a metric. You can measure it. It’s an action users take on the site—writing a review. But it’s actually an output in disguise.
Reviews are valuable when they help a student evaluate a course. They don’t create any value if a student never sees them. More reviews aren’t always better, especially if they’re clustered where nobody looks.
A better outcome is “Increase the number of course views that include reviews.” Now we’re measuring impact on the decision moment, not just the production of content.
If you can hit your metric without helping customers, you’re tracking an output, not an outcome.
Tricky example 3: measure success, not just adoption (the traction metric trap)
“Increase the percentage of users who viewed the performance report.”
This looks like a good outcome. It measures a specific behavior in the product. It’s within the team’s control. But it’s what I call a traction metric—it measures adoption of a single feature, not value to the customer.
Why teams get trapped in shipping features: a vicious trust cycle fuels micromanagement, while performance-linked outcomes push safe targets. Break the loop and refocus on customer outcomes that truly move the needle.
Two problems arise. First, people can view the report and still not find what they need. Second, we might have perfectly happy customers who don’t need the report at all. Driving usage of an unneeded feature wastes time and erodes trust.
Measure the value creation moment, not just feature adoption.
Tricky example 4: pair sentiment with behavior
I define a product outcome as a metric that measures either 1. a specific behavior in the product or 2. a sentiment about the product. But sentiment metrics—like CSAT or NPS—can be tricky on their own.
Sentiment metrics are outcomes, but they aren’t directional. They don’t tell us where to explore or set guardrails for what to avoid. So I pair a behavior with a sentiment, for example: “Increase engagement without negatively impacting satisfaction.” I use sentiment as a counterweight.
Facebook and Instagram illustrate why this matters. Meta is exceptional at driving engagement—but to a fault. Many of us don’t like these addictive products. Pairing engagement with a satisfaction guardrail prevents “engagement at all costs.”
Why getting this right is hard (and how I counter it)
Ready to move from shipping features to creating impact? This visual playbook shares five practical moves—translate metrics, partner with teams, iterate, avoid traps, and dig deeper—to turn outputs into measurable outcomes.
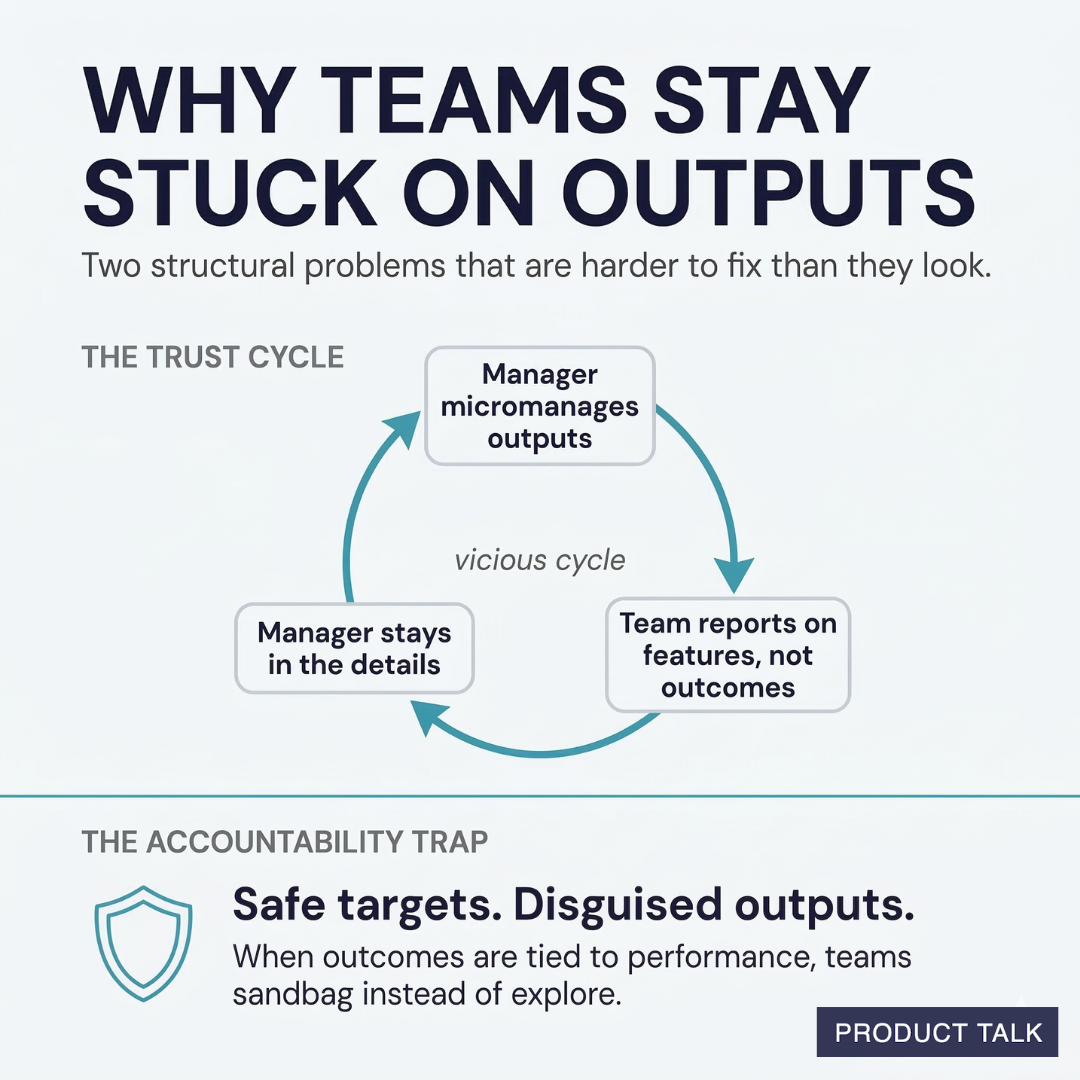
The trust cycle. Managers don’t trust that teams can reach outcomes on their own. So managers micromanage the outputs. Teams, in turn, don’t communicate their progress toward outcomes—they communicate their progress on features. This reinforces the manager’s belief that they need to stay involved in the details. It’s a vicious cycle.
I break it by asking teams to show their work—share assumptions, research, opportunity solution trees, and evidence behind choices—and by giving feedback on the thinking, not just the solutions.
The accountability trap. When performance reviews are tied to hitting outcomes, teams play it safe. They sandbag their targets. They disguise outputs as outcomes to guarantee “success.”
I treat outcomes as learning opportunities first. When we start on a new outcome, I set a learning goal—“learn what moves the needle on this metric”—before a performance goal—“increase X by Y%.” This creates space to explore without fear.
How I get teams started with better outcomes
Translate business outcomes to product outcomes. Business outcomes like revenue, retention, and market share are lagging indicators—by the time you see them, it’s too late to act. Product outcomes measure behavior changes within the product that lead to those business results. They’re leading indicators within the team’s control.
Negotiate outcomes with your team. Outcome-setting should be a two-way conversation. Leadership brings the cross-company context. The team brings customer insight and technical realities. Neither side dictates; we co-own the target and the constraints.
Stop celebrating shipped features and start celebrating change. This visual contrasts a feature factory mindset with a true product team, urging teams to track impact, not output, and define success by outcomes.
Expect to iterate on your metrics. Your first outcome metric probably won’t be right. That’s normal. Sonja at tails.com went through four iterations—from 90-day retention to 30-day to 5-day to behavior-based metrics—before landing on something actionable. Thomas at Bluestone Analytics iterated three or four times before finding the right metric. Iteration is the work.
Watch for common mistakes. Outputs disguised as outcomes. Traction metrics masquerading as product outcomes. Sentiment metrics without direction. Business outcomes assigned directly to product teams without translating to behavior change.
Use the right artifacts. Replace feature roadmaps with an opportunity solution tree to explore multiple paths, test assumptions, and sequence bets explicitly against a clear outcome.
Align OKRs with outcomes. If your company uses OKRs, make sure the “KR”s are true product outcomes (behavior change and value creation), not a list of features to ship.
The bottom line
When we shift from an output-first mindset to an outcome-first mindset, it doesn’t mean that outputs stop mattering. Product teams will always ship features, and the ability to do so quickly and with quality still matters. This shift simply ensures those features achieve the intended impact. We aren’t done when we ship—we’re done when what we shipped has the intended impact.
Measure success by the impact of what you ship and you’ll build a product team that learns, adapts, and creates real value. Measure success by what you ship and you’ll get a feature factory.
Quick self-check: is your “outcome” really an outcome?
Ask yourself: 1) Does it measure a behavior change or a sentiment tied to value creation? 2) Could we hit it without helping customers? 3) Is it adoption of a single feature (a traction metric) or a result that customers and the business care about? 4) Do we have a counter-metric to prevent unintended harm? If you stumble on any of these, refine it before you commit.
The world can feel like it’s spinning, and as a product leader, I feel that pressure acutely—juggling customer needs, stakeholder expectations, and the relentless news cycle. I recently listened to a powerful conversation with Teresa Torres and Petra Wille about staying grounded when everything feels “bonkers,” and it offered a practical, human way to keep showing up without losing yourself.
What resonated most was the invitation to live my values through small, consistent actions. Rather than waiting for grand gestures or perfect solutions, I’m leaning into the mindset of “Something is better than nothing.” It’s the same spirit we bring to continuous improvement in product: make a change, evaluate impact, iterate.
“Create the world you want to live in” has become a daily prompt for me. I’m applying it to how I spend my attention, time, and platform—three scarce resources for any product management leader. I’m not going to do everything perfectly, but I can make better trade-offs this week than I did last week, and I can keep improving.
Practically, that looks like reconsidering which speaking invites I accept, especially when representation is skewed. If a stage is heavily male, I now ask organizers about their plan for balance before committing. I also question travel expectations for short talks when a high-quality virtual experience is possible—good for sustainability, budgets, and energy. These choices compound, just like product roadmapping and sprint planning decisions.
Petra’s “under-complexity” lens was a wake-up call. In product, oversimplified narratives—whether a single KPI, a vanity metric, or a forced binary—usually increase fear and bad decisions. The same is true in civic discourse. To counter that, I’m seeking more nuance on purpose: reading multiple sources on the same story, listening for who’s not in the room, and noticing how the same facts can carry different meanings depending on who’s telling it.
One simple habit helps: I’ll read The New York Times and The Wall Street Journal on a headline, then follow up with Tangle by Isaac Saul, which lays out “what the left says / what the right says / editor’s take,” sometimes including perspectives from affected communities. It’s a lightweight form of personal knowledge management that improves my product judgment and my citizenship.
Another idea that stuck with me is swapping media proxies for human connection. In product, we don’t ship based on secondhand opinions—we run customer interviews, co-create with users, and build empowered product teams. The same principle applies in community: talk to someone directly affected, ask real questions, and stay curious. When conversations get heated, I try to build bridges, reduce proxies, and look people in the eye.
I’m also reflecting on platform responsibility. Even a “small” platform can snowball through weak ties inside a company or community. I’m asking: When should I speak up? Where should I draw lines? And when is “staying in your lane” actually a way to avoid necessary leadership? These are the same stakeholder management questions we navigate in product strategy—assess impact, clarify intent, and act with integrity.
Local grounding matters, too. I’ve found energy and clarity in community-level action: voting, attending public protests when it feels right, mentoring, and supporting nonprofits like World Pulse. I love the framing of “don’t mess with my neighbors”—it keeps me focused on tangible care when the internet starts to feel like reality. I’ve also seen leaders use angel investing in agriculture-related efforts as a counterbalance to “internet reality,” channeling resources into durable, real-world outcomes.
If you want to experiment this week, pick one small lever you control: where you spend money, time, attention, or your platform. Add nuance by reading at least two different perspectives before reacting. Replace proxies with people by talking to someone with lived experience. Reduce polarization by asking, “what shaped that view?” before judging it. And go local—connect with neighbors or a community group and let small actions compound.
If you’d like to hear the full conversation that inspired these reflections, you can listen on Spotify or Apple Podcasts. Here are the direct links: Spotify: https://open.spotify.com/episode/1sxEFquu73ZB9fL9gGk6Om and Apple Podcasts: https://podcasts.apple.com/kh/podcast/staying-sane/id1794203808?i=1000755696295
Resources I’m exploring and recommend: World Pulse (https://www.worldpulse.org/), The New York Times (https://www.nytimes.com/), The Wall Street Journal (https://www.wsj.com/), and Tangle by Isaac Saul (https://www.readtangle.com/ and https://www.readtangle.com/author/isaac-saul/). For builders and writers, I also appreciate Ghost (https://ghost.org/) as an open-source publishing platform. If you work in or with the MENA ecosystem, take a look at MENA Product Summit ’26 (https://www.prdkt.plus/summit26). Colleagues like Jeff Merrell (https://jeffdmerrell.com/) and grassroots efforts such as No Kings Protest (https://www.nokings.org/) offer additional perspectives and ways to get involved.
If this resonates, share it with a teammate who’s been feeling the weight of the world. I’d love to hear one small, values-aligned action you’re taking this month—what “something” will you try next?
I’ve long believed a simple truth about AI in customer support: if AI is going to earn trust, pricing has to be aligned with value. That principle has guided my product decisions and the way I hold our teams accountable for measurable outcomes, not activity.
When we shared our perspective on pricing AI Agents in 2023, we made a simple argument: if AI is going to earn trust, pricing has to be aligned with value. At the time for Fin, that value was clear. You pay when the AI resolves a customer’s problem. If it doesn’t, you don’t. That’s fair, easy to understand, and grounded in results, not activity. We were the first to introduce this pricing model because we believed that pricing and value should be inherently linked.
That belief hasn’t changed, it’s grown stronger over time. What’s changed is what Fin can do. As we expanded capabilities and pushed deeper into complex workflows, it became clear that measuring value solely by end-to-end resolutions no longer captured the full picture of impact.
Resolutions were the right place to start. Historically, we measured value based on whether Fin fully resolved a conversation on its own. These are known as resolutions and they gave support teams a clear way to measure ROI, easily comparing the cost of AI versus human support. They also aligned our incentives with our customers, as our revenue was directly tied to Fin’s performance.
That clarity worked. Today, more than 7,000 teams use Fin. Our average resolution rate across customers has increased every month and now stands at 67%, even as Fin increasingly handles more complex queries. That progress came from building an Agent that could take on harder problems and still deliver.
But as Fin got more powerful, “success” stopped being binary. I saw this first-hand in customer design sessions where policy, risk, and compliance needs rightly demanded human-in-the-loop confirmation. We weren’t failing to deliver value; we were delivering it differently.
Over the last couple of years, we invested heavily to ensure Fin could handle the most complex parts of support. As Fin’s capabilities expanded, customers began pushing what Fin can do for them by deploying Fin deeper into their workflows to handle the toughest queries.
In some cases, this required Fin to work in tandem with a human agent because that’s what customer policies and oversight needs dictated. Subscription changes, transaction disputes, billing issues, and other multi-step support scenarios can often require Fin to gather context, read and write to external systems, and execute actions before handing off to a human agent for confirmation.
Fin is still doing what it was configured for – intentionally handing off after doing more of the heavy lifting, saving valuable time for support teams and overall time to serve for their customers. But our pricing metric only recognized value when the conversation ended in a full “AI resolution” (i.e. a human was never involved).
That’s why we’re evolving Fin’s pricing metric from resolutions to outcomes. This shift reflects how customers now define value: not just in full automation, but in safe, efficient progress toward the right result across complex, multi-step, and policy-constrained workflows.
An outcome represents when Fin successfully completes the action it was configured to perform, as part of a conversation. Resolutions are still one type of outcome Fin can deliver, where it handles the issue end-to-end. Another type of outcome can be a Procedure where Fin gathers context, takes action, and hands the conversation off when that’s what customers configured it to do.
Kick off your journey with the #1 Agent—an AI partner designed to turn resolutions into real outcomes. Tap “Start a free trial” to explore faster, smarter customer service and see how Fin delivers value from day one.
Increasing end-to-end AI resolutions is still a core component of scaling Agents, but they are no longer the only measure of Fin's success and utility. Especially as Fin takes on more complex work. Moving to outcomes recognizes that solving a customer problem with full automation isn’t always appropriate. It’s about getting to the right result, safely, and efficiently.
As Fin’s capabilities expand, teams should feel empowered to use it in more nuanced, collaborative work. Outcomes support that by allowing customers to design workflows that meet compliance requirements and include a human agent when necessary. From a product management standpoint, this is how we align incentives, keep risk controls intact, and still accelerate time-to-value.
Fin is becoming even more powerful at handling complex, multi-step support queries. With outcomes, we can support that growth without constantly reinventing how value is measured. And this change gives us a strong pricing foundation that can scale as Fin continues to grow and take on more roles beyond service. This aligns with our vision of Fin becoming a “Customer Agent,” capable of handling the entire customer experience.
What this means for pricing is intentionally straightforward. An outcome will be counted when Fin successfully completes an action it was configured to perform, as part of a conversation. That keeps the model predictable for finance leaders while staying transparent for operators and product teams managing AI workflows.
The pricing model stays simple and the definition of value becomes more accurate. In other words, we’re doubling down on fairness, predictability, and competitiveness—core tenets for any consumption SaaS pricing strategy tied to real business impact.
When we first wrote about outcome-based pricing, we said that trust is the currency of AI. That’s still true. Trust is earned when customers see pricing move in lockstep with utility and risk posture, especially as gen AI and agentic AI take on higher-stakes tasks.
Pricing has to feel fair, it has to be predictable, and it has to stay competitive. Evolving from resolutions to outcomes isn’t a departure from that belief. It’s the natural maturation of how we measure value as AI moves from simple Q&A into complex procedures and human-in-the-loop collaboration.
Fin has grown more powerful because customers asked more of it. Outcomes are how we reflect that progress honestly, while staying true to the same principles that guided us from the start. This is product strategy in action: align incentives, measure what matters, and scale what works.
And as Fin continues to get stronger, we’ll keep holding ourselves to the same standard: price based on the value delivered. That’s how we build durable trust, sustainable ROI, and a better customer experience at scale.
I’m often asked how to translate early-stage experience into outsized product impact at scale. In my own practice, I study real career arcs that crystallize the habits of high-leverage product managers—especially those operating at the intersection of analytics and AI strategy.
Consider this path: Lucas is a Product Manager at Amplitude. Previously, he was employee #1 at Command AI, acquired by Amplitude in October 2024. Lucas studied computer science at Princeton.
What stands out to me is the compounding effect of being an early builder. When you are employee #1, you live close to the user problem, own outcomes end-to-end, and develop a bias toward focused, continuous discovery. That foundation creates durable instincts around product strategy, sharp prioritization, and empowered product teams—skills that transfer directly to later-stage environments where clarity and speed become competitive advantages.
Acquisition integration is where those instincts meet enterprise rigor. Folding Command AI into a unified analytics platform like Amplitude requires disciplined product roadmapping and sprint planning, precise stakeholder management, and a strong POV on where AI augments core “Amplitude analytics” versus where it creates net-new value. The north star remains unchanged: deliver measurable customer outcomes that strengthen product-led growth and reduce time-to-value.
On the AI front, I’ve seen the most successful PMs treat gen ai and LLMs for product managers as means, not ends. They anchor use cases to concrete analytics workflows—accelerating insight generation, surfacing anomaly detection, improving retention analysis, and driving user activation—while validating each step through continuous discovery and rigorous experiment design. This balance of ambition and evidence protects teams from shiny-object drift and keeps investment tethered to business impact.
Execution-wise, the playbook is straightforward but unforgiving: clarify the problem through customer interviews; define crisp outcomes vs output OKRs; map the journey end-to-end; ship in thin slices; and iterate with observability baked into every release. Along the way, keep your cross-functional partners close—solutions engineering, customer success, and GTM—so that your learning loops extend beyond the product surface and into real adoption dynamics.
If you’re building analytics or AI-powered experiences today, borrow these lessons: translate early-stage builder energy into enterprise-scale focus; make AI serve the product, not the other way around; and use Amplitude analytics to close the loop from idea to impact. That is how PMs compound credibility, accelerate careers, and, most importantly, create products customers can’t live without.
Inspired by this post on Amplitude – Best Practices.
Can an AI agent actually run a credible content audit end to end? I put that to the test. In my role leading product at a high-growth SaaS and as a hands-on content strategist, I’m constantly balancing depth with reach. During a recent office-hours discussion, someone asked me to zoom out and explain when to use Claude Code. That prompt inspired me to launch a running series—Conversations with Claude—showing exactly how I apply it to real product management and SEO problems.
I’m a heavy user and share what works for me. I receive no compensation from Anthropic for this series; if that ever changes, I’ll disclose it. With that out of the way, let’s dive into how I had Claude conduct a full content audit—and why the results exceeded my expectations.
For the first installment, I chose a fairly complex use case: a comprehensive content audit of my site. I expected this to be a slog. Instead, it was refreshingly fast and rigorous once I set Claude up with the right scaffolding.
I kicked off with a simple directive: start by asking clarifying questions, proceed step by step, and capture notes in a shared task file. I also provided deep context—specifically, the CDH Book (15 chapters + intro) and my entire blog archive in markdown—so the model could reason with my actual corpus rather than guessing from sparse prompts.
Claude began with smart clarifying questions that framed the analysis well. Scope of keywords: Should it focus strictly on concepts unique to or heavily associated with my work like "opportunity solution tree" and "continuous discovery," or also include broader product management terms such as "product outcomes," "assumption testing," and "customer interviewing"? Keyword geography: Start with US-only or include UK/global? Blog coverage assessment: What counts as "well covered"—dedicated deep dives or credible coverage within broader posts? Output format: Add findings to the task file or create a separate deliverable?
Peek inside a Notion-style page that turns content strategy into action: a content-audit task with due date and tags, plus clear steps for keyword research, blog gap analysis, and SEO improvements.
I replied: 1. both 2. us only is a good place to start 3. evaluate this based on how well we rank for the keyword, if we rank reasonably well, you might suggest content improvements to rank better, if we don't rank at all, then you might suggest a whole new article 4. add to the task file
From there, Claude read the CDH Book, extracted roughly 100 keywords, ran them through Keywords Everywhere in two batches of 50 to capture search volume, and pulled current domain rankings and traffic metrics. Within minutes, I had a high-signal view of what’s working, where we’re invisible, and how to prioritize fixes.
The good news came first: we own our branded terms—#1 for "product discovery," "opportunity solution tree," "continuous discovery," and "product trio." That brand equity is doing real work for us.
The biggest gaps were in broad topics the CDH Book covers but where there’s no targeted content. "Outcomes vs outputs" (1,300/mo) — Arguably THE central thesis of CDH, and no ranking. This is the single biggest gap. "Product roadmap" (4,400/mo) — I have a strong anti-roadmap POV but no content targeting this. "Product strategy" (1,900/mo) — Ch 7 argues strategy = opportunity selection. Strong differentiator, no ranking. "Story mapping" (5,400/mo) — I use story maps uniquely (for surfacing assumptions). Huge volume. "Stakeholder management" (2,900/mo) — Ch 13 is entirely about this. No ranking. "Pre-mortem" (4,400/mo) — I cover this as a product discovery technique. No ranking.
Inside a dark-themed writing workspace, a long-form chapter is open while a tidy folder tree catalogs pages and chapters. The scene invites readers to think like auditors—inventory content, track structure, and surface gaps with AI assistance.
The trojan horse opportunity: High-volume generic terms like story mapping, pre-mortem, and usability testing could bring in readers who don't know about CDH yet. Write about these broadly-searched topics with my specific product-discovery angle.
In just a few minutes, Claude generated an analysis of what keywords we ranked for and at what position, a ranked set of high-, medium-, and lower-volume (but strategic) keywords where we didn’t rank yet had relevant content, concrete net-new topics to close the gaps, and a list of existing articles to update to lift their SERP positions. It worked far better than I expected.
Here’s how I set it up so the model could deliver: I didn’t simply ask Claude.ai to "audit my site" and hope for the best. I supplied rich, relevant context (my book and all blog posts as markdown) so it could anchor on my language, frameworks, and mental models. I paired that with live data via APIs like Keywords Everywhere to ground recommendations in actual search volume and competitive rankings. With the right inputs, Claude Code behaved like a capable research analyst and an SEO strategist—able to reason, prioritize, and suggest high-leverage actions.
Next, I went deeper and used the findings to draft a long-form article that addresses the biggest gap—"Outcomes vs outputs"—and ties it directly to product roadmapping and sprint planning. I wove in continuous discovery practices, opportunity solution tree techniques, and product trios collaboration to make it actionable for empowered product teams. I’ll share the end-to-end workflow—including files, prompts, and the editorial QA checklist—in a follow-up.
If you’re new to Claude Code and want a practical starting point, replicate the setup above: assemble your canonical sources in markdown, define a clear evaluation rubric, and ground keyword research with reliable volume data. If you want my exact task file, clarifying-question template, and step-by-step audit rubric, tell me which content gap you’d prioritize first and why—I’ll tailor the walkthrough to the highest-interest topic.
Every update we shipped this month removed a specific constraint on what teams can do with Fin. In my world, the demo-to-production gap shows up as complexity, control, and confidence. Can the agent handle the query that actually matters? Will it sound right on a call? Can the team deploy it without filing an engineering ticket? Can managers understand what it’s doing? That’s the bar I hold us to.
This month, we delivered answers to all four. Here’s how.
Procedures and Simulations (0:51). The hardest problem in AI-powered customer service isn’t answering FAQs—it’s executing complex queries with real business logic and real consequences if anything goes wrong. Think billing refunds, multi-step flows, and actions that must be right the first time.
We made it dramatically easier to build and manage Fin for those complex queries—without pulling in an engineer. You can author in natural language, test every step in simulation, and deploy with confidence.
The workflow starts with AI drafting the procedure from your existing source material. You edit in natural language, with structured hooks to pull in live data, apply business logic, and add code for deterministic control where you need it. That’s how you handle multi-step flows with the precision that matters when things go wrong.
Simulations are the test environment. Define a test case, pass in the data Fin would receive in a real conversation, and watch it work through each step. You see what Fin is doing, why, and whether it’s meeting the criteria you set. Full transparency at every point. I’ve run these end-to-end myself, and there’s a particular confidence that comes from watching it work before it goes anywhere near a customer.
A conversational moment from the February Fin Product Updates recap: two teammates trade insights with laptops open, while a bold pull-quote drives home the promise—Fin removes complexity to start selling and supporting in under two minutes.
For a deeper look at Procedures and Simulations, head to fin.ai/procedures.
Fin Voice: three major updates. When something’s off in chat, it can take a few exchanges to notice; on a call, it’s immediate. Pronunciation, noise handling, and tone all matter because they’re the customer’s first impression.
Pronunciation rules (4:18). Fin has high out-of-the-box pronunciation accuracy, but it doesn’t know your brand—your product names, your industry terminology, the way your company uses certain words. Alihan Zinna, Staff ML Scientist, showed this with an IKEA example: without pronunciation rules, Fin mispronounced both “IKEA” and a product name; after adding rules, both were corrected and sounded natural.
New natural voices (5:48). We’ve added 11 new voices tuned to a range of brand tones so you can choose one that sounds like it truly belongs to your company—not a generic AI assistant.
Background noise reduction (6:28). People call from airports, shops, and busy offices. Fin now monitors background noise continuously and increases noise reduction when the environment demands it. No configuration needed. As Alihan put it, “This is one of those things customers really notice when it’s not working. The goal was to make it invisible. That’s what we built.”
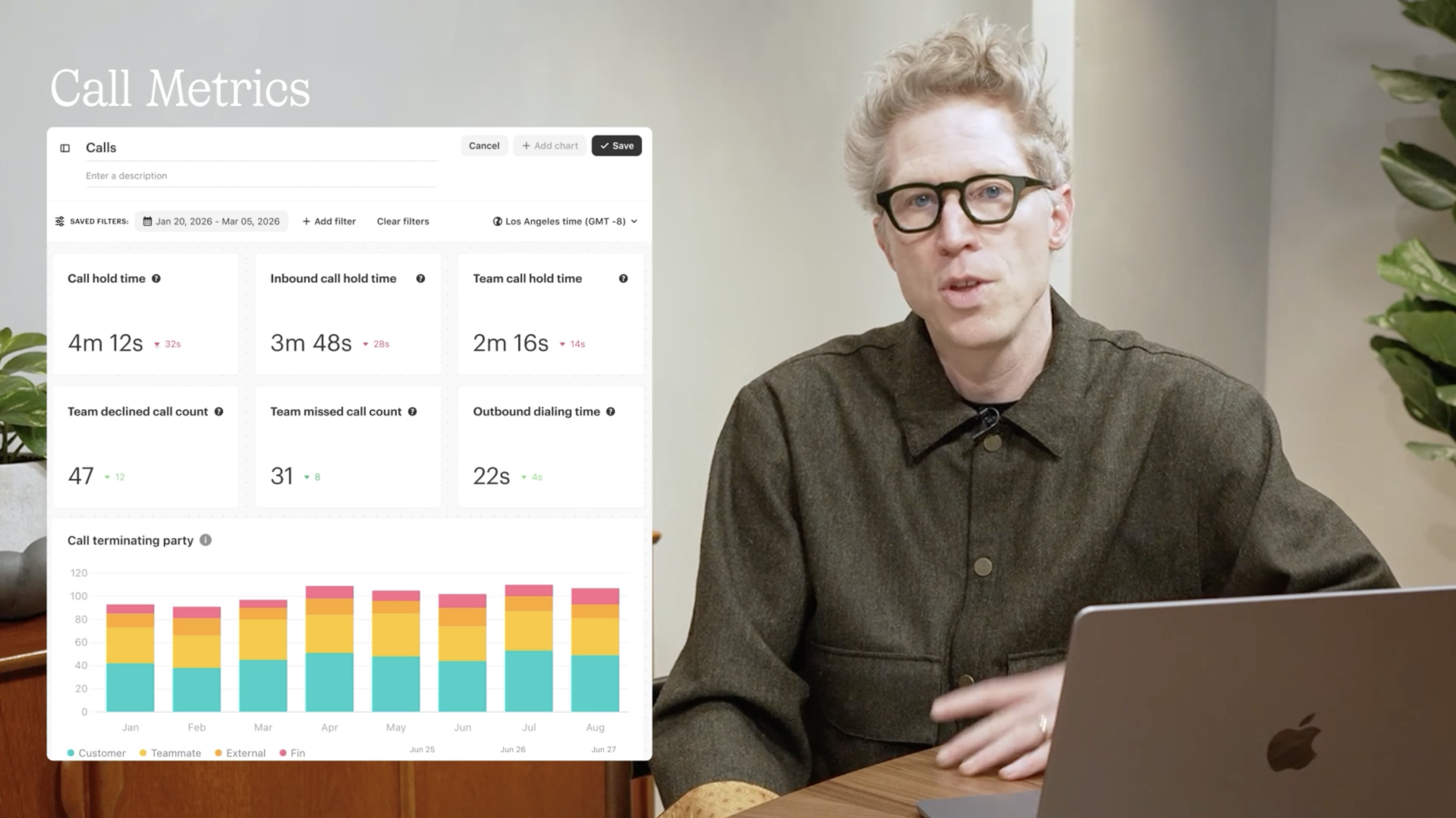
Catch up on February’s Fin Product Updates with a walkthrough of the Call Metrics dashboard—saved filters, hold‑time tiles, missed and declined call counts, and a monthly breakdown that helps support teams act faster.
Shopify setup experience (8:21). Fin began as a Service Agent and is quickly becoming a Customer Agent—working across the whole lifecycle to support, sell, and guide, even before a customer has an issue. The revamped Shopify setup is a clear step forward.
Shopify catalogs are complex—thousands of products, variants, and dynamic inventory—and connecting all of that to an agent has historically been painful. We removed the friction.
Setup now takes three steps: first, connect your store. Second, install the Messenger directly in Shopify—no code, just a few clicks. Third, deploy Fin. Total time: under two minutes. We timed it live.
What that unlocks is real. In the demo, a first-time snowboarder asked for recommendations. Fin searched the catalog, reasoned about attributes that matter to a beginner (there’s no “beginner” tag in the catalog), personalized suggestions by height and weight, and added a board to the cart.
Even better, one customer updated their website copy to promote a sale. Fin immediately picked up the new context and began recommending sale items, nudging shoppers to add more to the cart to access a discount—no extra configuration required. It read the situation and acted.
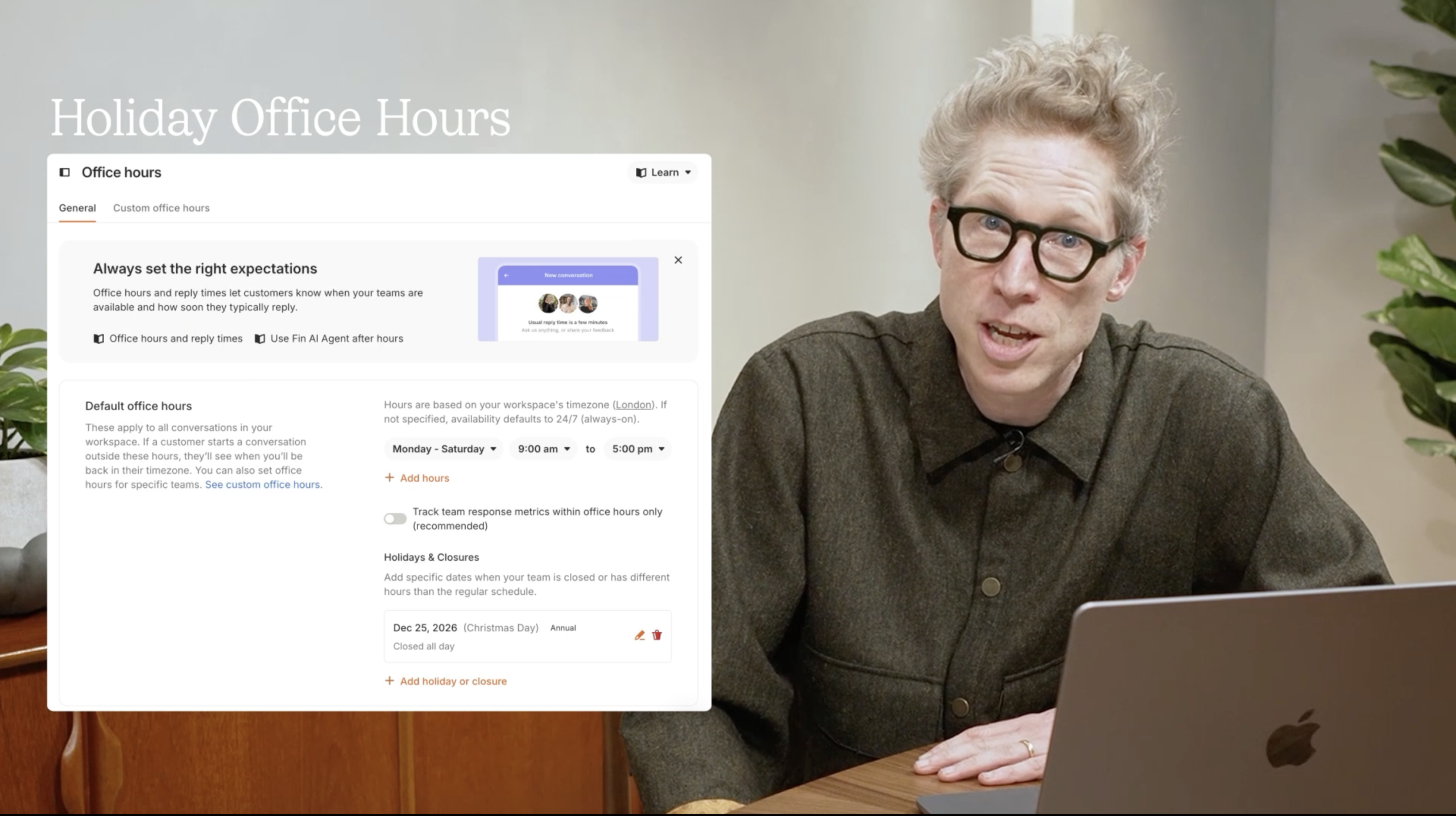
See how the latest Fin update streamlines support scheduling. A product expert walks through Holiday Office Hours, showing how to set default hours, track response metrics, and add closures so teams stay consistent.
Three steps, and you have a real-time shopping assistant that knows your store and sells on your behalf.
Helpdesk improvements (12:31). Fin works with any helpdesk, but many teams consolidate to take advantage of our native Intercom helpdesk integration. We’ve shipped 19 helpdesk improvements in 2026 so far; two from this month stand out.
11 new call metrics. Hold time, outbound dial time, missed and declined calls, call terminating party, and more. These give leaders the visibility to analyze workload distribution and call handling quality in detail.
Holiday office hours. Teams no longer need to manually update office hours for every public holiday. This was the most upvoted request in our community, and we shipped it.
Across the board, we removed the constraints that hold teams back: the complexity ceiling in automation, the quality ceiling in voice, the setup barrier in Shopify, and the operational overhead in the helpdesk.
We closed out the month with a Star Wars–style crawl of 22 additional updates. All features mentioned here are live and available now. Explore more at fin.ai/updates. More to come—see you next month.
There’s a moment in every product leader’s career when the bravest decision isn’t to build—it’s to stop. That’s why the “Kill Your Darlings” theme resonated so strongly with me. In this episode of All Things Product, Teresa Torres and Petra Wille dig into the courage and craft it takes to sunset products that look successful on the surface yet quietly block your path to meaningful growth. As someone accountable for portfolio outcomes, I’ve learned that disciplined endings are often the catalyst for exceptional beginnings.
Listen to this episode on: Spotify | Apple Podcasts
The heart of the conversation is that uncomfortable middle ground between obvious failure and runaway success: products that are profitable, loved by customers, but fundamentally flatlining. Teresa shares candid stories from her own business, including a decision to cut 40% of revenue on purpose. I’ve been there—choosing to retire a “working… kind of” product to free up discovery capacity felt risky in the moment, but it created the focus we needed for durable growth.
Here’s the trap: some traction can be more dangerous than no traction at all. Early fans are not the same as durable product–market fit, and “stable but not growing” can lull leaders into maintaining instead of learning. Every hour of design, engineering, and go-to-market attention that props up a flatlining product is an hour not invested in the next breakthrough—an opportunity cost that rarely shows up on a dashboard, yet compounds month after month.
From a portfolio perspective, this is continuous discovery in action. If we want empowered product teams to tackle meaningful outcomes, we have to protect their capacity from zombie work. That means setting clear thresholds for when we double down, shift strategies, or sunset—before attachment and inertia take over. When I’ve institutionalized this discipline, our throughput of high-quality bets increased, and our confidence in what not to do became a strategic advantage.
Organization design can make sunsetting harder than it needs to be. Dedicated, long-lived teams are fantastic for compounding capability, but they also create emotional and structural ties to specific products. Petra’s point lands: leaders need explicit sunsetting conversations and a portfolio decision-making cadence that sits one level above teams. In my org, we treat sunsetting as a strategic reallocation—not a verdict on a team’s talent—so people are celebrated for learning, not punished for outcomes outside their control.
Killing profitable products can be the right strategic move when the growth ceiling is clear and the opportunity cost is high. I’ve chosen to “burn the ships (on purpose)” more than once—retiring add-ons that generated reliable revenue but diluted our value proposition and spread discovery thin. Yes, it stings in the quarter you do it. But it’s astonishing how quickly focus restores momentum when you create intentional space for what’s next.
Practically speaking, I make sunsetting easier and less traumatic by operationalizing it: Regular portfolio reviews focused on outcomes and opportunity cost; a visible “sunsetting” column so everyone sees what’s on the table; the Horizon (H1 / H2 / H3) model to balance core, adjacent, and transformational bets; and making portfolio decisions one level above teams to avoid local optimizations. Add explicit exit criteria and success metrics for endings, the same way we set entry criteria for new bets.
Another theme I appreciated is designing for the right customers. Teresa highlights intentionally limiting access and pricing to work with customers who show agency and commitment. I’ve applied the same principle: when we’re clear about who we serve and who we don’t, our product–market signal sharpens, churn narratives simplify, and roadmaps get crisper. Focus is a growth strategy.
If you’re leading a product portfolio, running discovery, or wrestling with a product that “works… kind of,” this conversation is permission to act. Product–market fit isn’t binary, and mediocre success can be the most dangerous place to stay. Sunsetting is a portfolio decision, not a team failure; teams shouldn’t be punished for reaching the end of a product’s natural lifecycle. If experimentation isn’t in your DNA, killing products will always feel traumatic—so make space for it intentionally, not passively.
Key moments and themes worth bookmarking: 00:00 – Why “kill your darlings” matters; 04:30 – The dangerous middle ground; 09:30 – The opportunity cost of “okay” products; 14:30 – Sunsetting in product organizations; 19:00 – Real examples of killing revenue streams; 28:00 – Designing for the right customers; 33:30 – Burn the ships (on purpose); 38:00 – Making sunsetting easier with Regular portfolio reviews, a visible “sunsetting” column, the Horizon (H1 / H2 / H3) model, and making portfolio decisions one level above teams; 46:00 – Normalizing product lifecycles.
Resources & Links:
Follow Teresa Torres: https://ProductTalk.org
Follow Petra Wille: https://Petra-Wille.com
Mentioned in this episode:
Ways to Work with Petra Wille
Product at Heart
CDH Membership by Teresa Torres
Product Talk by Teresa
Product Talk Academy by Teresa
Enduring Ideas: The three horizons of growth
Join the Conversation:
Have thoughts on this episode? Leave a comment below.
Full Transcript
Full transcripts are only available for paid subscribers.
Building a great end-to-end customer experience with AI means going beyond support, and I’ve seen firsthand how transformative that shift can be when we treat every interaction as part of one cohesive journey.
Every customer touchpoint, from the first sales conversation through to post-sales support and success, is an opportunity to get it right. Other teams are now turning to AI to transform how they show up for customers, and support, which led the way, has already written the blueprint. In my role, I focus on making that blueprint actionable across the entire lifecycle.
In The 2026 Customer Service Transformation Report, it’s clear most businesses are thinking about what’s next, with more than half planning to scale AI to other departments. Interestingly, they often cite their early success with AI in support as motivation for the move. This makes support teams uniquely positioned to help lead the transition, a strategic role unimaginable just two years ago.
In this piece, I share how teams are introducing AI to other parts of the business, how to think about this expansion effort, and the new opportunities it creates for support leaders who want to drive a unified customer experience.
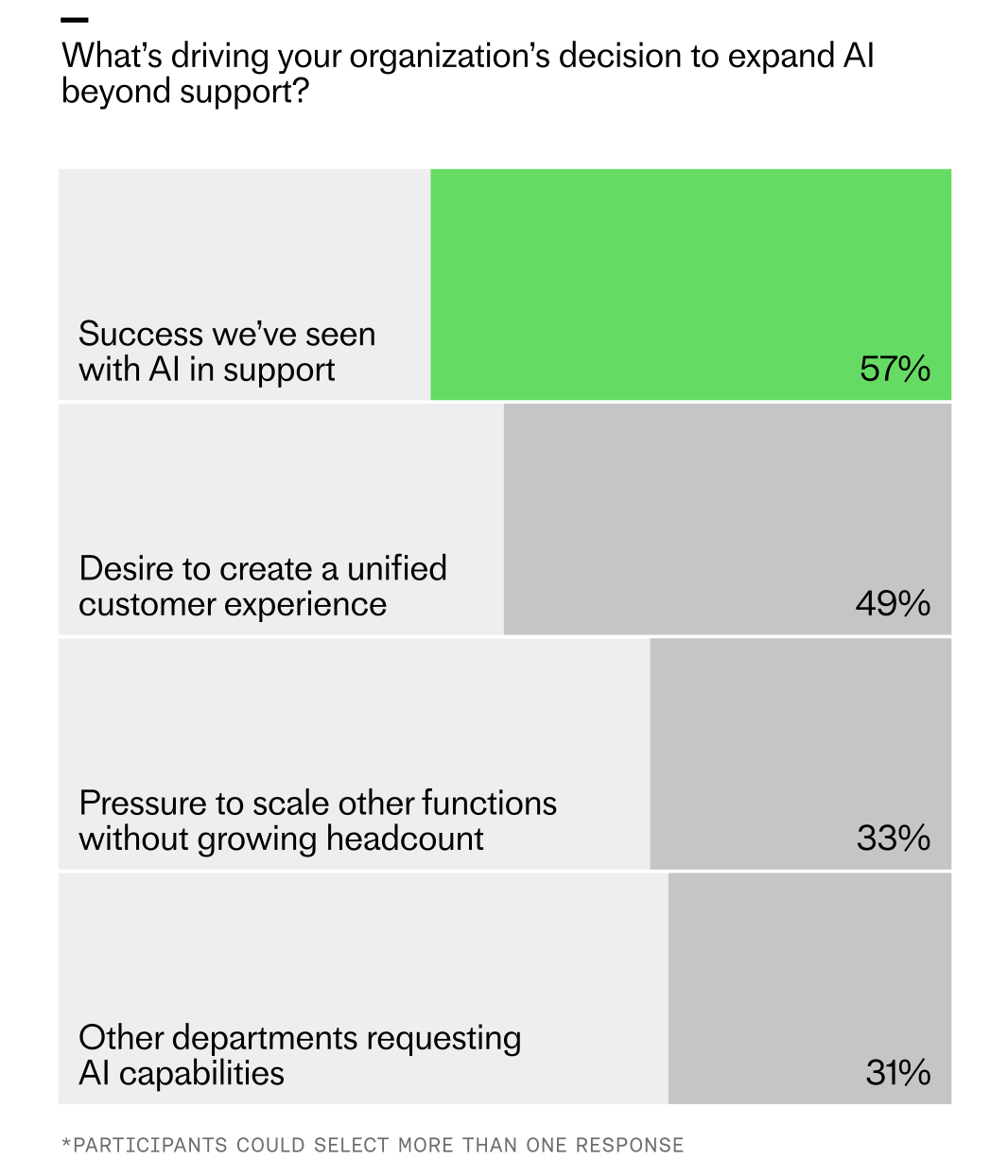
Support was the first proving ground for AI, and our research suggests that businesses are now planning to expand its use to other areas based on the results it’s yielded so far. Fifty-two percent of respondents said that their organizations are actively planning to scale AI to other departments in 2026.
What will this look like? Leading companies are already finding out.
Wins in support are setting the pace for company-wide AI. Survey results rank the drivers: proven success in support (57%), the push for a unified customer experience (49%), scaling other functions without more headcount (33%), and cross-department demand (31%).
My favorite example is WHOOP, the fitness wearables company. They offer a premium product which makes their sales conversations more consultative than transactional. Customers want to know “Which membership is right for me?” or “How often do I need to charge my WHOOP?” According to Emily Shirley, Business Manager for Growth Product at WHOOP, if someone chatted with the inside sales team, they were twice as likely to convert, but they didn’t have enough reps to respond to incoming queries fast enough. Customers could wait more than 10 hours for a reply.
With a big product launch on the line and an anticipated spike in prospective customer conversations, their three-person team needed help. So they deployed Fin to the "Join" page, the final step before purchase.
With Fin resolving 84% of inbound questions, the sales team was able to focus on high-value leads. Together, they drove a 130% increase in attributable sales. The team is now exploring ways to expand Fin beyond FAQs, focusing on personalised conversation flows, multi-product recommendations, and richer data capture. As Emily says: “There are so many parts of the buyer journey where this applies. We’ve only scratched the surface.”
It’s clear there’s a desire to push AI to other parts of the customer lifecycle, but there is a risk hidden in this expansion. If sales, customer success, and other departments all launch their own Agent, each operating in isolation, you can end up fragmenting the very thing our research says teams want to create. The second-most cited reason for pushing AI beyond support: desire for a unified customer experience.
Without shared context, each handoff becomes a source of friction where customers could receive inconsistent answers or be asked to repeat information. I’ve watched even well-intentioned AI rollouts struggle here—great local wins, but an overall journey that feels disjointed.
A translucent UI visual maps a support-led AI blueprint that scales across the business—from SDR and sales to custom assistants—anchored by layers for goals, memory and user context, business knowledge, and interoperability.
The opportunity (and the challenge) is to keep the customer at the center. Instead of department-specific Agents that operate independently, we must strive for cohesion. That means shared memory, consistent governance, and connected AI workflows that respect the customer’s history and intent across channels.
This is the future I’m building toward: solutions like Fin becoming a “Customer Agent,” capable of handling the entire customer experience. This will mean Fin can function in many roles, supported by a memory that grows with the customer over time and deep knowledge of the business, creating a seamless experience for every interaction. In practice, that’s agentic AI designed to collaborate across teams, systems, and journeys—without losing context.
Pushing AI into new parts of the business requires someone to own the process. And for many organizations, that’s the support team. Nearly a third of respondents (32%) confirmed their customer service teams are leading their business' AI transformation strategy.
This presents a real opportunity for support teams to shape the future of customer experience. Instead of each function reinventing the wheel, support can act as a center of excellence, defining shared standards, guardrails, and operating practices that drive performance.
“You already manage the most complex, high-volume customer interactions; you have rich data on customer needs and behavior; and you know how Agents perform in the real world. Those insights will be invaluable as AI scales across your business.”
Leaders are racing ahead with real AI in support. Explore the 2026 Customer Service Transformation Report to see where deployment is stalling, benchmark your team, and get practical steps to scale automation that delights.
In my organization, when we extended AI from support into sales, we deliberately brought our conversation design expertise, Agent Analytics, and governance models along with it. One team owns the orchestration, memory strategy, and CRM integration so a customer can start with a sales question and end up with a support one—without ever feeling a seam. That continuity is where journey mapping meets product strategy and turns into measurable outcomes.
As Agents like Fin expand their capabilities and move into new areas, I expect many customer service leaders will see their roles expand to include AI implementation across the customer journey. It’s a natural progression for product management leadership in support: owning the experience, the data, and the operating model.
Achieving perfect customer experience is AI’s biggest promise. But in order to get there, teams need to be smart about the solutions they deploy. A unified Customer Agent capable of handling the entire journey end-to-end will have a significant advantage, delivering consistent, context-aware experiences across every interaction.
The Customer Agent future is being built right now, and it’s starting with the team pioneering AI transformation from the very beginning: support. For leaders in these organizations, this is a rare opportunity to shape how customer relationships will be built and maintained in the AI era.
If you’d like to dig deeper into the data and benchmarks guiding these decisions, download The 2026 Customer Service Transformation Report.
"What if an AI could spot the moment two product teams start pulling in opposite directions — before it derails a quarter?" That question hooked me, because I’ve lived through the costly fallout of subtle misalignments that only surface at the end of a sprint—or worse, during quarterly business reviews.
I recently dug into an episode of Just Now Possible featuring Matthias and Charlotte Kleverud, co-founders of Momental. Their vision for "GitHub for product management" hits a nerve in the best possible way: find "merge conflicts" in strategy, not code, and do it early enough to save execution time, trust, and outcomes.
Here’s the core: Momental ingests documents, meeting transcripts, and voice recordings across an organization, then uses AI agents to map them into a structured context layer—a set of interconnected trees covering goals, decisions, learnings, and who's doing what. When it finds a conflict—say, one team betting on retention while another is prioritizing conversion—it surfaces the misalignment for humans to resolve, just like a merge conflict in code. That framing is both familiar (for anyone who’s shipped software) and powerful (for anyone who’s scaled product strategy across multiple teams).
Their journey tracks with what many of us have learned the hard way. "Starting in 2022 with DaVinci 002 and learning that the market wasn't ready for AI-assisted product thinking" pushed them toward experiments with agent teams. "The origin story: building a team of AI agents in 2024, only to discover agents hit the same alignment problems as humans" is exactly the kind of meta-lesson I’d expect when you scale autonomy without shared context. The breakthrough was an "OODA-loop-driven document processing agent" that continuously curates a living knowledge graph rather than relying on static prompts or brittle pipelines.
One model that stood out was "The product chain: signals → learnings → decisions → principles, and how AI maps it." That is the backbone of healthy product thinking. When this chain is explicit and inspectable, you can trace why a team chose Path A over Path B—and detect when new signals should invalidate old decisions. I’ve seen this accelerate continuous discovery and improve executive decision hygiene.
I also appreciated the organizational modeling: "Three trees that model an organization: the product tree (OKRs to epics), the wisdom tree (decisions and their reasoning), and the people/time tree." This maps cleanly to how we run quarterly planning at scale—tying outcomes to work, preserving rationale, and grounding ownership and timelines. With that structure, "How conflicts are detected, auto-resolved, or escalated to humans with merge options" becomes a pragmatic workflow, not a theoretical AI demo.
On the technical front, they’re blunt about limits: "Why traditional chunking and RAG breaks down at scale and what Momental does instead." Anyone who’s tried to stitch strategy from ad hoc notes knows that naive retrieval won’t cut it. You need durable context boundaries, rich metadata, and graph-aware reasoning. Which brings me to one of my non-negotiables: "Why metadata—who said it, when, and in what context—is critical to preventing hallucinations." In my world, we treat provenance like test coverage—you can’t ship without it.
Process-wise, the product philosophy resonated: "How a document processing agent uses OODA-loop thinking to extract and connect context across documents" reinforces the need for short feedback cycles, explicit hypotheses, and continuous refactoring of knowledge. Pair that with "The self-improving agent: collecting user feedback weekly and rewriting its own prompts" and you’ve got a blueprint for eval-driven development that keeps the system honest over time.
Their UI choices also mirror a pattern I’ve adopted: "Moving from chat-first to UI-first to proactive agents as an AI product design pattern." Chat can feel magical, but alignment work benefits from concrete artifacts—trees, timelines, driver trees, and opportunity solution trees—so people can reason together. Then, let proactive agents watch for drift and nudge teams before the cost of change spikes.
Two broader themes are worth calling out. First, "Specialized tools win" when the problem is deep, cross-functional context like product strategy. General-purpose chatbots struggle here; domain-specific models with strong information architecture have the edge. Second, product culture matters: "Discovery Versus Vibe Coding" is not just a catchy contrast—it’s a reminder that disciplined discovery beats intuition theater when stakes are high.
As for the roadmap, I’m encouraged by their "Design partner strategy and what's next for Momental's public launch." Early design partners are where you validate signal quality, precision of conflict detection, and the ergonomics of human-in-the-loop resolution. I’m especially curious how this intersects with LLMs for product managers, outcomes vs output OKRs, and product roadmapping and sprint planning in large portfolios.
Finally, a nod to the broader ecosystem. The conversation touched on "Claude Code" and a shift "Beyond documents and vectors" that many of us are living through—toward retrieval-first pipelines that respect context windows, stronger governance, and measurable improvements in decision quality. If you care about AI Strategy for empowered product teams, this is a space to watch—and to pilot.
Bottom line: If you’ve ever wished you could prevent strategy drift before it shows up in your dashboards, this "GitHub for product management" approach is worth your attention. Make the chain of signals, learnings, decisions, and principles explicit. Keep humans in the loop for the hard calls. And let proactive, agentic AI do what it does best: flag misalignments early, so your teams can move fast together.
I’m seeing the same pattern in product orgs everywhere—inside HighLevel and across my network: everyone is racing to add AI to the roadmap, and every stakeholder has a strong opinion about what to build next. Delivery has never been faster, which makes it dangerously easy to confuse speed with progress.
When we chase features without grounding in continuous discovery, we drift back into a feature factory. We ship more, but we ship the wrong things faster. The antidote is simple and hard at the same time: recommit to product discovery, validate with assumption testing, and let the evidence steer our AI Strategy—not the hype.
Of course, that only works if we can bring our stakeholders along. In the AI moment, it’s deceptively easy to get to a slick prototype and painfully hard to harden it for production. Early demos make almost any idea look promising. That’s precisely why stakeholder management must evolve from pitching solutions to showing our work.
In practice, stakeholder management is about alignment with the people who influence our product decisions—executives, sales, marketing, customer success, engineering leadership, and sometimes legal or finance. Some have veto power; others have input. Knowing who can block versus who can shape is crucial for where we spend our time. Even in empowered product trios, the best discovery can derail if we reveal only conclusions at the end.
I’ve tried every mapping framework—power-interest grids, RACI matrices—and they help. But the real challenge isn’t identifying stakeholders. It’s figuring out how to bring them along so that our product roadmapping and sprint planning decisions stick.
Identify who shapes your product decisions. This visual groups stakeholders into three tiers—those with veto power, key influencers, and audiences to inform—so teams can align, communicate, and reduce delivery risk.
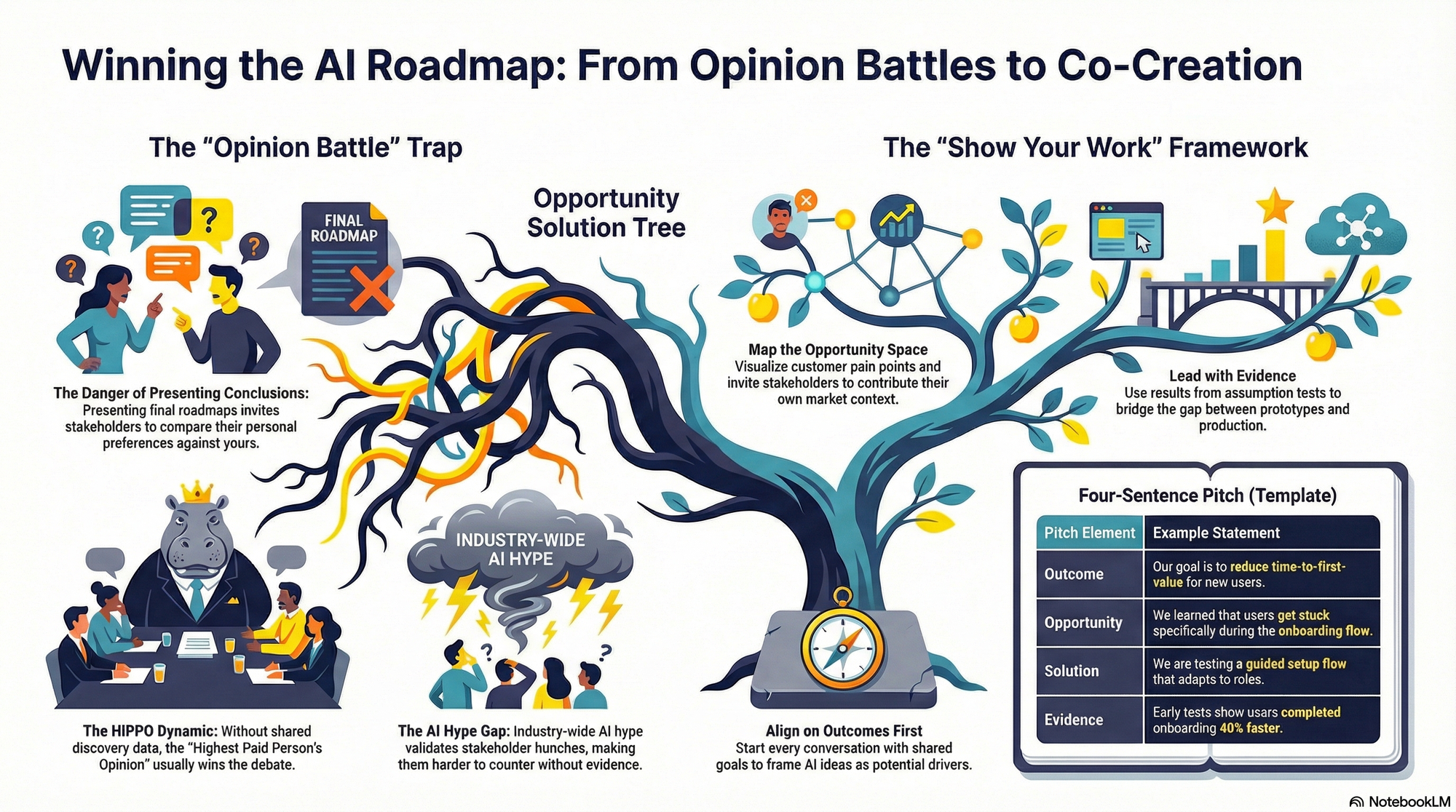
Here’s the most common trap I see (and have fallen into): focusing stakeholder reviews on the roadmap, release plan, or prioritized backlog. That invites an opinion battle. And stakeholders have their own conclusions—usually shaped by the last customer call, a board meeting, or a market headline.
This is how the HiPPO dynamic gets created. HiPPO stands for the “Highest Paid Person’s Opinion,” and the saying goes, “The HiPPO always wins.” When we present conclusions without the journey, we set ourselves up to lose. In the gen ai rush, the chorus of “everyone is doing AI” makes that opinion even harder to counter.
So I don’t try to win opinion battles. I bring new information—fresh customer interviews, clear opportunity mapping, and results from assumption tests. The gap between what the market hypes and what customers actually need is often enormous. Our edge is evidence.
The strategy that consistently works for me is simple: show your work. If you’re practicing continuous discovery, your opportunity solution tree isn’t just a thinking tool—it’s your strongest stakeholder management asset. It helps you build confidence in your decisions, and it can help your stakeholders build the same confidence.
Avoid the stakeholder trap of selling conclusions. This visual shows how anchoring on solutions invites HiPPO battles—and how to shift the conversation by sharing discovery evidence, insights, and data.
Step 1 — Start with the outcome. I open every conversation by restating the shared goal and asking whether anything has changed. Anchoring on outcomes vs output OKRs reframes hot-button solution debates (like “we need an AI feature”) back to what will move the needle on the outcome we agreed to pursue.
Step 2 — Share the opportunity space. I show how we mapped customer needs, pain points, and desires. Then I ask, “What did we miss?” Stakeholders often surface opportunities we haven’t seen yet—signals from the field, market shifts, or partner feedback. I capture their input and commit to validating it in upcoming customer interviews.
Step 3 — Walk through prioritization. Using the tree’s structure, I explain why we prioritized one branch over another. Then I ask where they might have chosen differently. This turns debate into collaboration and lets me leverage their expertise without ceding the discovery framework.
Step 4 — Go deep on the target opportunity. Before we talk solutions, I make the customer’s problem vivid and real. Interview snapshots help stakeholders empathize and see what matters most. Once the opportunity is crisp, solution discussions become dramatically more objective.
Show your work, not just your conclusions. This infographic guides product teams through seven steps to build stakeholder confidence—align on outcomes, map opportunities, prioritize, test assumptions, and repeat.
Step 5 — Share solutions and invite theirs. I present our solution set and explicitly ask for additional ideas. If their suggestions diversify our set, we include them. Solution ideas are cheap; the opportunity is what matters. This is where product trios can benefit from leadership’s pattern recognition and industry context.
Step 6 — Share your assumption tests and results. I walk through our story maps, high-risk assumptions, and what we’ve learned so far. I invite stakeholders to add assumptions—this is where their knowledge shines. If we have data, we share it; if we’re pre-data, we share the plan to get it and ask for feedback.
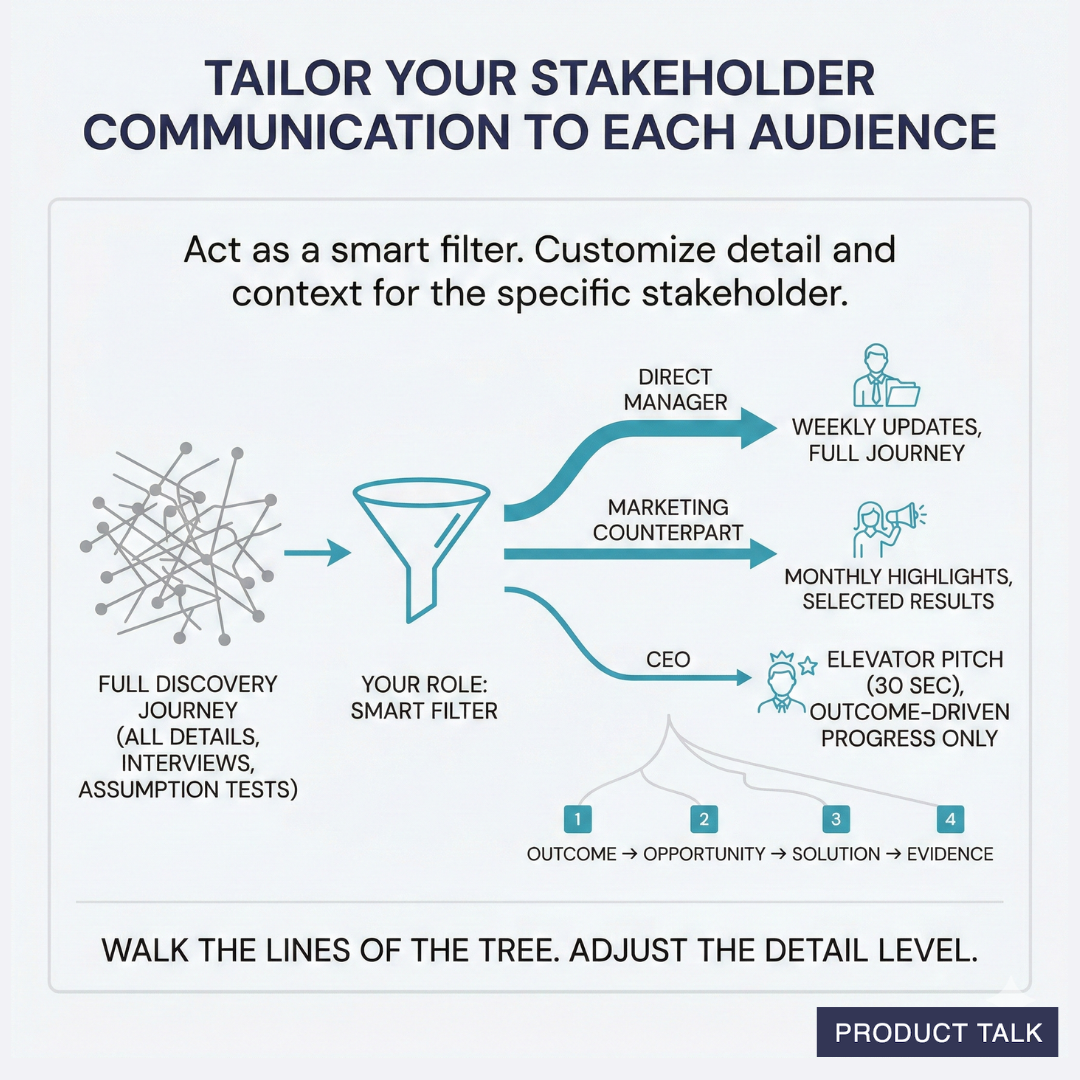
Step 7 — Repeat. I don’t batch this into a big reveal. I keep a steady cadence and tailor depth to each audience: weekly for my manager, monthly highlights for marketing, and concise updates for executives. Continuous discovery pairs with continuous stakeholder management.
Showing your work doesn’t mean drowning people in detail. It means tailoring the signal to the audience. My rule of thumb is outcome, opportunity, solution, evidence—walk the lines of the tree at the right altitude for each stakeholder.
Show your work the right way for each stakeholder. Use a smart filter to turn discovery noise into clear signals—weekly journeys for your manager, focused monthly highlights for marketing, and a 30-second CEO pitch.
In a 30-second update with a CEO, it might sound like this:
“Our goal is to reduce time-to-first-value for new users. We’ve been interviewing customers and learned that onboarding is where most people get stuck—specifically, they don’t know which features to try first. We explored a few approaches and tested them. The most promising one is a guided setup flow that adapts based on the user’s role. In early tests, new users completed onboarding 40% faster.”
That pattern works across channels—Slack updates, monthly reviews, or quarterly planning. The format flexes, the structure doesn’t: outcome, opportunity, solution, evidence.
As you adopt this approach, watch for four anti-patterns that quietly erode trust.
Avoid the traps that erode stakeholder trust. This infographic guides product teams to show their work, welcome ideas, provide frequent updates, and prioritize results over ideology to build alignment and credibility.
Anti-pattern 1 — Telling instead of showing. The curse of knowledge makes our conclusions feel obvious to us and opaque to others. The fix: slow down, start at the top of the tree, walk the decisions, and let stakeholders reach the conclusion with you.
Anti-pattern 2 — Shooting down stakeholder ideas. As you build a library of validated assumptions, it’s easy to spot flaws in a suggestion and say “no” too quickly. Instead, place their idea within your discovery framework. If it maps to a different opportunity, say, “That idea has promise—we’ll consider it when we address that opportunity.” If it rests on risky assumptions, story map the idea together, list the assumptions, and share what you’ve already learned. People accept the evidence they help generate.
Anti-pattern 3 — Saving everything for a big reveal. Infrequent, comprehensive updates invite opinion battles because stakeholders have formed their own conclusions in the dark. Short, frequent updates build alignment as the work unfolds.
Anti-pattern 4 — Fighting the ideological war. Sometimes a more senior stakeholder will overrule you. Don’t turn it into a debate about how product decisions “should” be made. Focus on the decision at hand, do the best work within constraints, and let results—not ideology—prove the value of discovery over time.
Shift from selling to showing. This co-creation guide invites stakeholders into discovery, taps their expertise, and turns relationships from obstacles into partnerships for smarter product decisions.
Here’s the mindset shift that changes everything: stakeholder management is a co-creation opportunity. When we show our work with artifacts like an opportunity solution tree, experience maps, and interview snapshots, we’re not just communicating—we’re inviting collaboration. We’re leveraging stakeholders’ expertise, context, and connections to make better product decisions.
When stakeholders have walked the path with us, they don’t need to be sold on the destination. They become allies. Engagement stops being a status ritual and starts being real partnership—the kind that moves outcomes and builds durable trust.
Try this in your next review: don’t start with your roadmap. Start at the top of the tree. Reaffirm the outcome. Share the opportunity space. Explain your prioritization. Show what you’re learning. Invite contribution. You might be surprised how quickly alignment—and confidence—follow when you stop selling conclusions and start showing your work.
Ever feel like your product team is “lost in the woods”? I’ve certainly been there—when strategy gets fuzzy, outcomes drift, or constraints aren’t clear. What helped me reframe the chaos was borrowing “lost person” patterns from search-and-rescue and mapping them to product strategy, product discovery, and team behaviors. The result is a practical playbook for product management leadership that keeps empowered product teams moving toward outcomes—not just outputs.
Listen to this episode on: Spotify | Apple Podcasts
Here are the five patterns I see most often—and how I turn each one into forward motion: settle in place (freeze), chase shortcuts, follow the first visible path, use your own navigation (intuition/taste), and retrace your steps. Each of these has a smart, minimal move that helps teams reorient fast without abandoning continuous discovery or product strategy discipline.
Settle in place (freeze). Sometimes the smartest move is to stop. When my team lacks context or authority, I pause delivery work and escalate instead of improvising fixes. This prevents thrash, protects focus, and creates the air cover we need to realign outcomes vs output OKRs.
Chase shortcuts. Shortcuts can be brilliant—or overconfident. I’ve learned to pressure-test whether the “road” is where we think it is before we commit. That means lightweight experiments, clear exit criteria, and the humility to pivot. Think about big bets like Spotify podcasts: compelling vision, but you still have to validate assumptions step by step.
Follow the first visible path. The obvious option isn’t always the best one. My job as a product leader is to make multiple paths visible before we choose. I lean on opportunity solution trees and KPI trees (or driver trees) to surface alternatives, align stakeholders, and keep empowered product teams focused on customer impact and product-market fit—not just the loudest idea.
Use your own navigation (intuition/taste). Judgment matters, especially for product trios making fast calls—but it’s not a replacement for evidence. When my “compass” conflicts with what we observe, I anchor back to customer interviews, rapid tests, and discovery loops. Intuition should guide where we look, while data validates how we proceed.
Retrace your steps. When we’re drifting, I go back to what used to work: principles, quality practices, and discovery habits as feedback loops. Returning to fundamentals—clear problem statements, crisp value propositions, and disciplined outcomes—rebuilds momentum fast.
Team prompt to try: If your team is “lost” right now, which pattern are you defaulting to—and what’s the smallest move you can make this week to get oriented (escalate, test a shortcut, map options, validate intuition with evidence, or retrace to a principle)? I use this question in weekly reviews to keep us grounded in continuous discovery and product strategy.
Resources & Links:
Follow Teresa Torres: https://ProductTalk.org
Follow Petra Wille: https://Petra-Wille.com
Mentioned in the episode:
Lost Person Behavior: A Search and Rescue Guide on Where to Look – for Land, Air and Water
Robert J. Koester
Examples referenced: Xerox, Nokia, Kodak, Volkswagen emissions scandal, Spotify podcasts, large-org tooling contexts like Oracle and SAP
Opportunity Solution Trees: Visualize Your Discovery to Stay Aligned and Drive Outcomes
KPI Trees: How to Bridge the Gap Between Customer Behavior, Product Metrics, and Company Goals
Let's Read Continuous Discovery Habits Together (January 2026) for Continuous Discovery Habits (and the idea of habits as feedback loops)
Shifting from Outputs to Outcomes: Why It Matters and How to Get Started
I’d love to hear how your team navigates these patterns. Which small move will you try this week? Leave a comment below and let’s compare notes on product discovery, stakeholder management, and product roadmapping that actually drives outcomes.