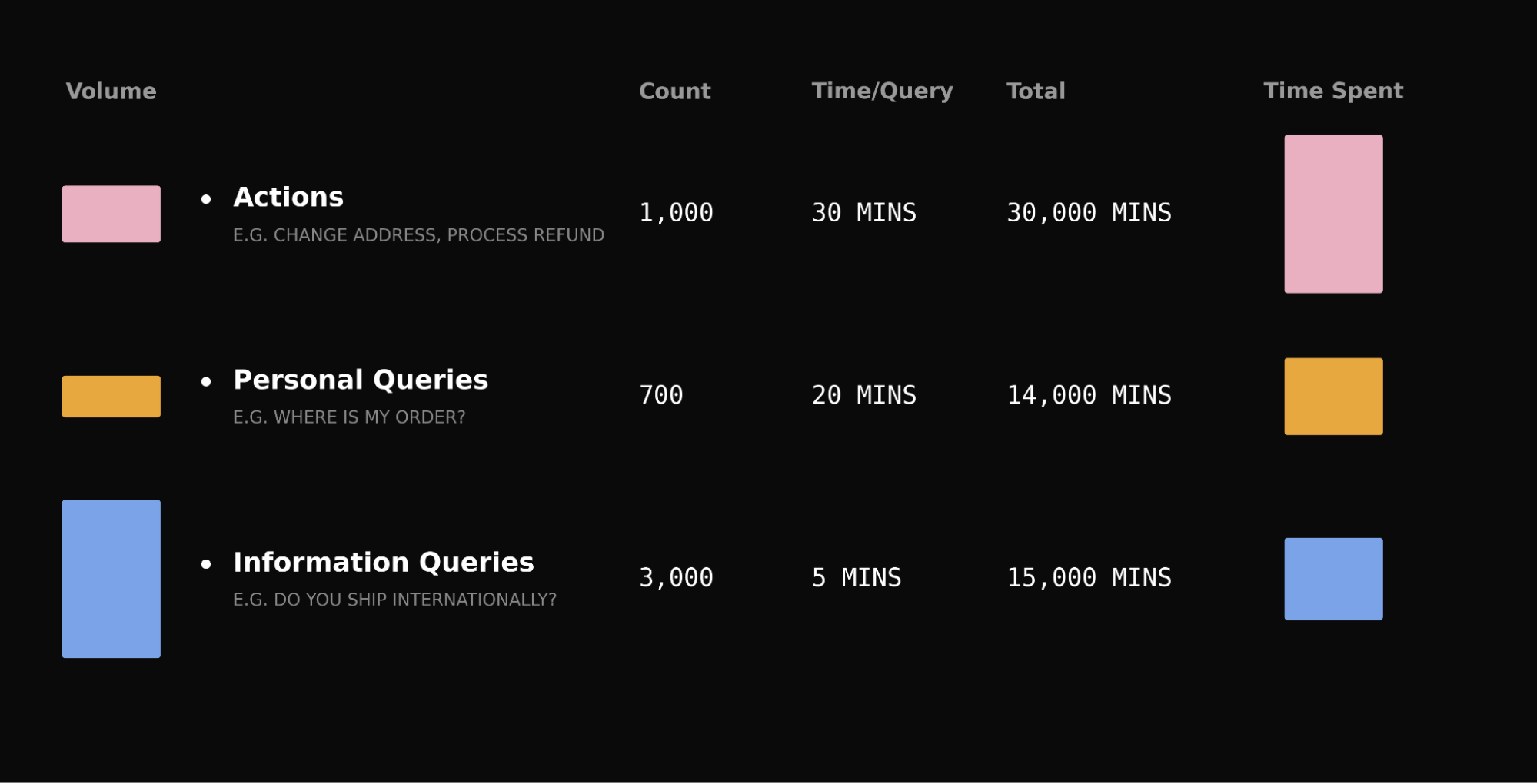
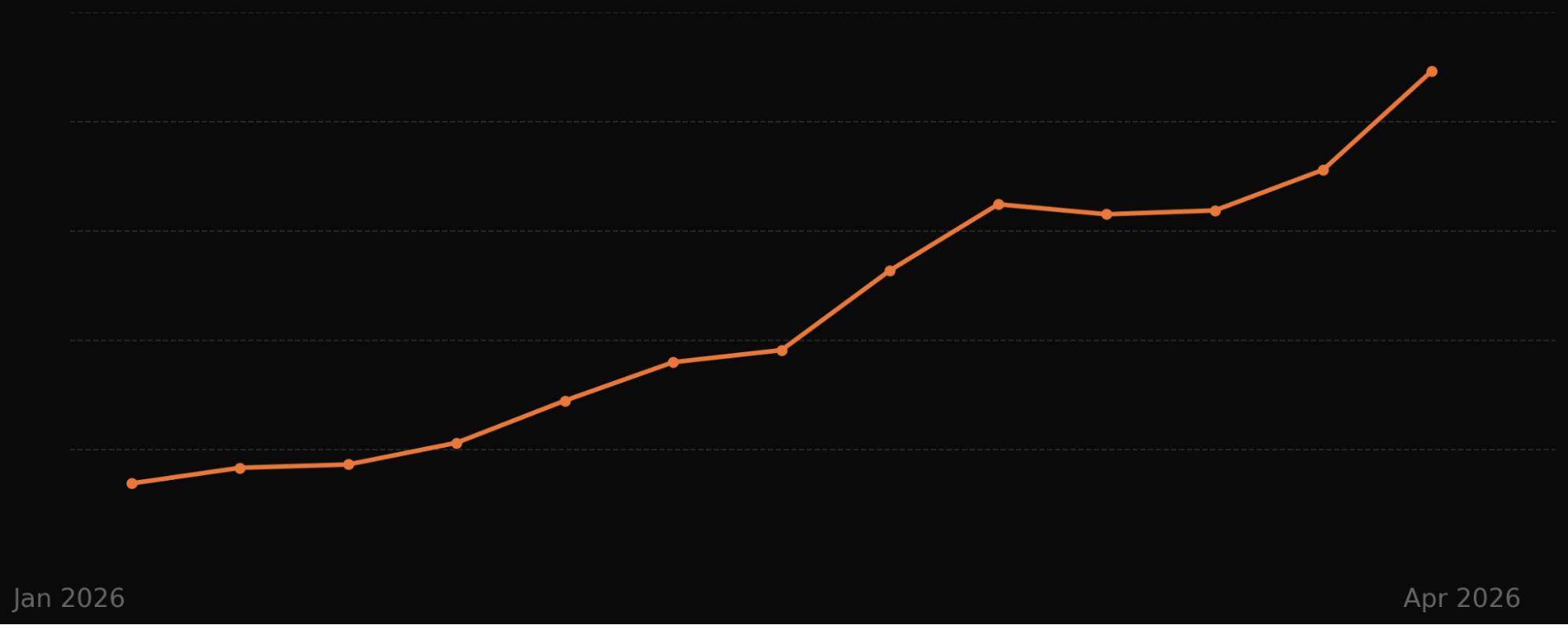
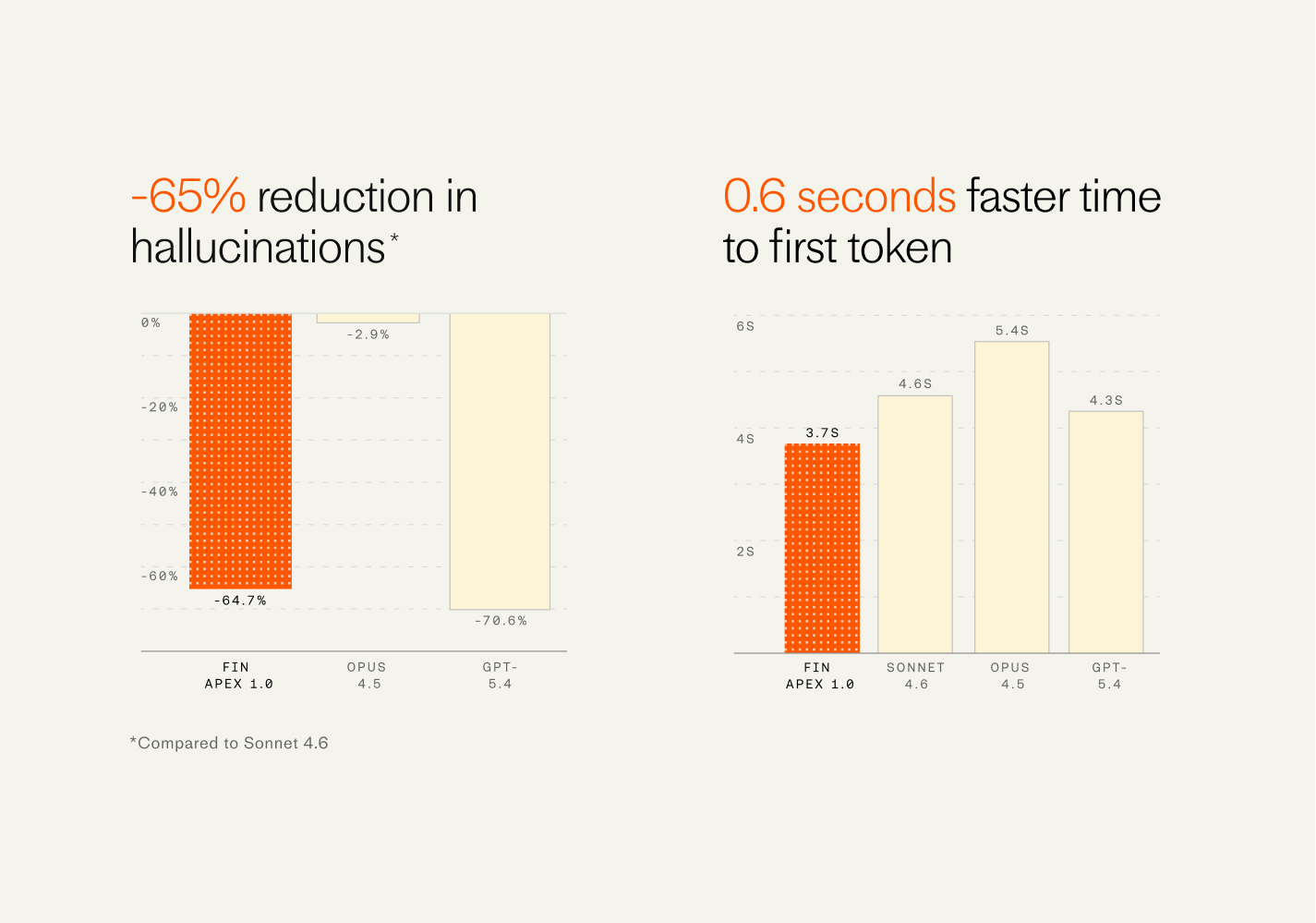
Scaling a real-world marketplace from scrappy to dominant takes a different kind of product leadership. Reflecting on Christopher Payne’s decade leading DoorDash as President and COO — growing from roughly 70 employees to the dominant food delivery platform in the US — I’m struck by how much of that success hinged on mastering an atoms-based business while still operating with software-level rigor. As a VP of Product Management, I see the same patterns in my own work: relentless clarity on inputs, a bias for builder-executives, and a cadence that keeps leaders close to product details without becoming bottlenecks.
Running an atoms-based business versus a pure software company forces you to obsess over operational physics: unit economics, quality control, on-time reliability, and dense local liquidity. It’s precisely where traditional “bits” executives can stumble. What’s worked for me is a simple “plate spinning” framework for executive attention: identify the five or six plates that must never stop — customer experience, marketplace health, quality and safety, product velocity, platform reliability, and P&L — then schedule recurring deep dives to keep those plates spinning. If a plate wobbles, I drop in, fix the root cause, re-instrument the inputs, and zoom back out.
Hiring at hypergrowth speed only works when you bias toward a “builder mentality.” I look for executives who run toward fuzzy problems, write clearly, and can prove they’ve shipped value with incomplete information. Prior industry experience can be a liability when you’re reinventing the market; first-principles thinkers outlearn domain experts who try to port yesterday’s playbooks. In executive hiring, I’ve found structured work samples and narrative memos far more predictive than marathon interview loops — companies routinely spend too much time on job interviews and too little time evaluating how candidates think and execute.
Great executives never outgrow the details. Staying close doesn’t mean micromanaging — it means sampling the customer journey and instrumenting the system so you can feel where it hurts. In my own practice, I rotate through frontline touchpoints weekly: support transcripts, NPS verbatims, failed checkout sessions, and reliability dashboards. Small signals often reveal systemic issues. A single ciabatta bread moment — the kind of edge-case substitution that seems trivial — can expose broken handoffs, unclear policies, and misaligned incentives across the marketplace.
Top-down goal setting beats bottom-up when you’re aiming for category leadership. Bottom-up targets tend to regress to comfort; they calibrate to today’s constraints, not tomorrow’s possibilities. I set ambitious, top-down outcomes (not output), frame the non-negotiables, and map driver trees to clarify the input metrics that matter. Then I ask empowered product teams to pressure-test the plan, propose approaches, and own the how. This preserves ambition while unlocking creativity — a practical balance of clarity and autonomy that outcomes vs output OKRs were designed to achieve.
One-size-fits-all management is a myth. Early-stage teams need hands-on coaching and fast decisions; later-stage teams need mechanisms that scale: crisp PRDs, pre-mortems, and operating cadences that separate strategy, planning, and execution. The mark of a high-functioning executive team is not uniform style — it’s high candor, fast escalation paths, and visible commitment after debate. In tough moments, a little charisma goes a long way; in practice, that’s not theatrics, it’s steady optimism, simple language, and consistent follow-through that keeps people moving forward.
The hypergrowth skill stack for executives is surprisingly learnable: ruthless prioritization under uncertainty, narrative writing that aligns cross-functionally, structured delegation with clear “inspection points,” and a weekly rhythm that protects maker time. I leverage a cadence of business reviews (inputs > outputs), customer-scent checks, and decision logs so we can move fast without losing the thread. CEO and executive time management is the ultimate forcing function — if we can’t show where our attention maps to goals, the team won’t either.
Some of my enduring lessons echo the best of Amazon and eBay: customer obsession beats competitor obsession, input metrics beat lagging vanity metrics, and simple mechanisms beat heroics. From Jeff Bezos’s playbook I borrow the insistence on written narratives, single-threaded ownership, and clarity on what will not change. Those principles remain the backbone of platform scalability and resilient product strategy, especially when markets get noisy.
AI is about to flatten organizations. With agentic AI, retrieval-first pipelines, and AI workflows embedded into product development, managers can widen their span without losing fidelity. I see LLMs for product managers accelerating discovery, PRD drafting, and experiment analysis — while raising the bar on decision quality. The implication for leadership: fewer layers, more transparency, and even greater pressure to define sharp, top-down outcomes that teams can autonomously pursue.
If I had to compress this into a playbook, it’s this: set audacious, top-down goals; keep your “plate spinning” calendar sacred; write more than you talk; hire builders, not resume archetypes; sample the customer journey every week; and build mechanisms that make the right thing easier than the heroic thing. That’s how you scale product management leadership from dozens to thousands — in atoms, in bits, and in the messy, exhilarating space where they meet.