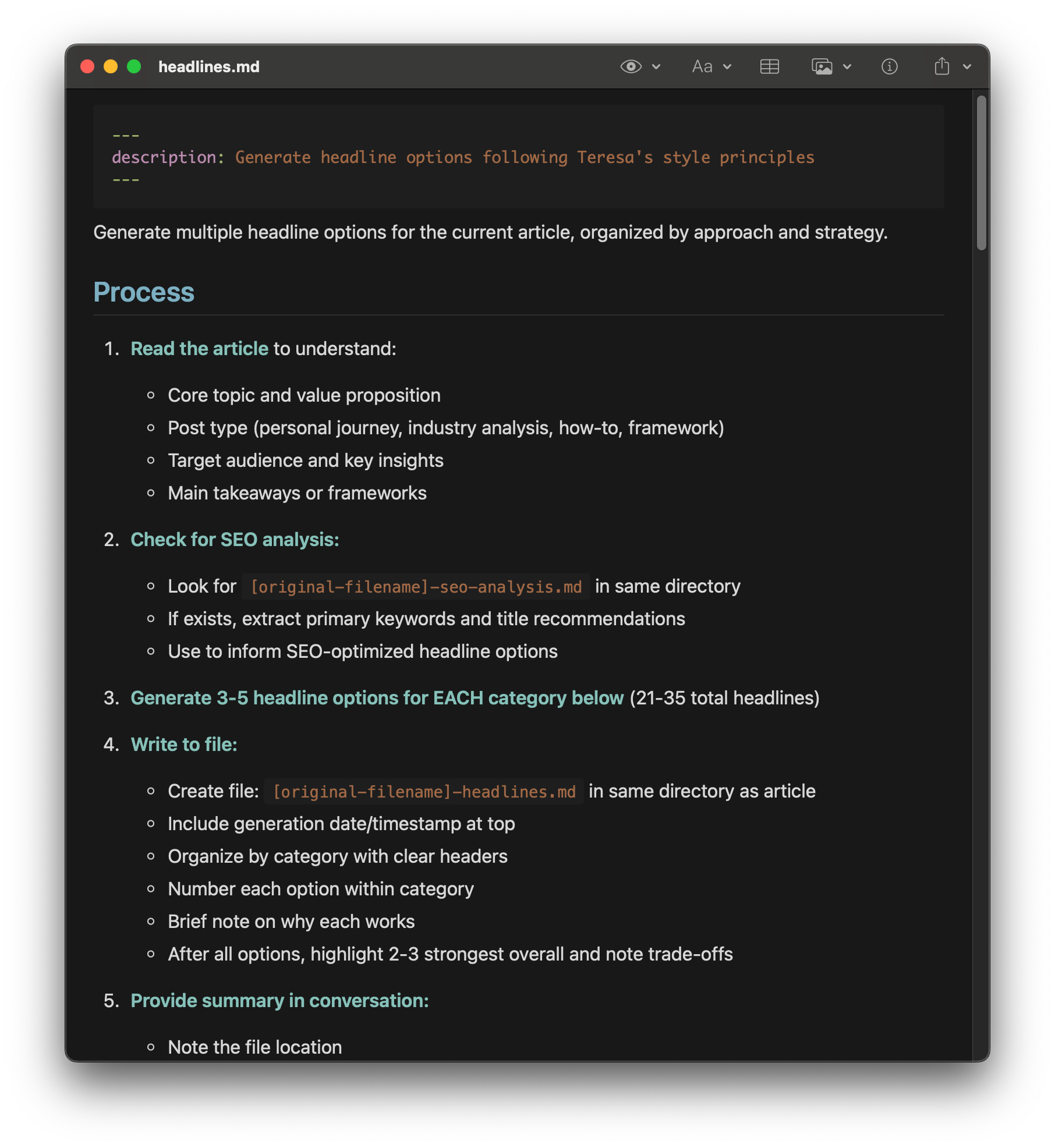
I’ve been working to remove the friction between product questions and product answers. The most impactful step so far: connecting Amplitude analytics directly into ChatGPT via OpenAI’s MCP. This turns everyday conversations into decision-grade insights—no dashboards to hunt, no SQL to write, and no analytics queue to wait on.
Connect Amplitude data directly to the tools your team uses every day. OpenAI’s MCP connector eliminates traditional barriers to product data.
In practice, this means I can ask ChatGPT natural-language questions like, “Where are users dropping in our activation funnel this week?” or “Which cohorts are driving retention lift post-onboarding?” and get grounded answers from Amplitude—fast. It’s a step-change for product-led growth because the insights live where we already think and plan.
Here’s how I apply it day to day: I’ll prompt ChatGPT to compare week-over-week activation for new SMB signups across regions, diagnose drop-offs by step, and summarize A/B testing outcomes with guardrails like minimum detectable effect considerations. When we’re shaping strategy, I’ll pull a retention analysis and cohort breakdown to inform bet sizing and roadmap tradeoffs—all without pulling the team into a BI bottleneck.
Governance remains non-negotiable. I scope the MCP tools to a least-privilege data slice, apply privacy-by-design rules to exclude PII, and log every query for auditability. Clear data governance and AI risk management policies ensure we maintain trust while accelerating discovery. Tight context window management keeps prompts focused and reduces noise.
Operationally, the setup is straightforward: define the MCP tool spec for Amplitude, map canonical events and metrics (activation, retention, conversion, and product-qualified lead stages), and test with a retrieval-first pipeline so responses reliably cite the right source of truth. We standardize metric definitions across product, growth, and customer success to avoid semantic drift.
The impact on empowered product teams is immediate. Continuous discovery becomes a daily habit rather than a quarterly ritual; questions move from “I’ll get back to you” to “Let’s check right now.” For product managers working with LLMs, this is the connective tissue that makes ChatGPT a true ChatGPT connector for analytics—an on-demand, unified analytics platform that supports faster iteration and sharper decision-making.
If you’ve been waiting to make analytics truly ambient, this is the moment. Start small with a single funnel or cohort, validate governance, and expand to your core lifecycle metrics. The payoff is a shared understanding of what’s working, what’s not, and where to focus next—delivered in the flow of work.
Inspired by this post on Amplitude – Best Practices.
My writing process used to be messy. Even in my role leading product strategy, I’d start strong and then stall because I hadn’t clarified what I truly wanted to say.
I’d begin with a brain dump—everything swirling in my head. I’d try to shape it into an outline, lose patience, and just start writing. A few paragraphs later, I’d realize I didn’t know where I was going, stop, and return to the outline. It was a tortured loop between writing and structuring.
Now I do it differently. When I get stuck, I don’t start writing. I ask Claude for help.
Claude reviews my outline and helps me fill in gaps. It often suggests things that I don’t like. This is good. It helps me figure out the core of what I want to say. Instead of writing my way to what I think, I discuss my way to what I think.
Claude isn’t just a sounding board. I also use it to help me brainstorm headlines, explore outline alternatives, critique each section as I write, conduct supporting research, act as my thesaurus and dictionary, make SEO recommendations, and so much more. As a result, I am writing way more.
I didn’t design this workflow in one sitting. I built it iteratively, the same way I build products: by asking, "How can Claude help with this?" and evolving from there.
If you haven’t been following along, I’m deep in a series about Claude Code and how it helps me work better. Here’s what we’ve covered so far: Claude Code: What It Is, How It’s Different, and Why Non-Technical People Should Use It, Stop Repeating Yourself: Give Claude Code a Memory, How to Use Claude Code Safely: A Non-Technical Guide to Managing Risk, and How to Choose Which Tasks to Automate with AI (+50 Real Examples).
This week, I’m diving into how to design personal AI workflows. I’ll use my writing workflow to illustrate each step, and I encourage you to follow along with your own process so you end with something tangible.
Claude breaks down an AI workflow article and suggests three paywall points, weighing trade-offs to guide conversion strategy. A clear, structured example of planning content and automation steps with Claude Code.
Designing AI workflows looks a lot like designing product solutions. I lean on "discovery" habits—clarifying outcomes, mapping the journey, and testing assumptions—to make the work both reliable and repeatable.
This series is inspired by my personal usage of Claude Code. I have not received any compensation from Anthropic for writing this series. And you can trust that if that ever changes, I will disclose it. This is not only required by the FTC here in the US, but I strongly believe it is the right thing to do. You can count on me to do so.
First, I map out what I do to complete the task. Once you’ve identified the AI workflow you want to create, start by mapping exactly what you do when you do it yourself. If this feels hard, do the task a few more times and jot down each step as you go.
Here’s what I do when I write a blog post: I choose a topic; I write down everything I can think of related to that topic; I structure it into an outline; I do some research to fill in gaps; I write each section; I edit each section; I think about SEO tactics; I brainstorm headlines; I decide what images to add; and I send it to my editor.
If this looks a lot like story mapping, that’s because it is. Instead of mapping what a customer has to do to get value from a solution, I’m mapping what I do to complete a task. The benefit is the same: I can see what must happen and ask, "Where can AI help?"
From here, I focus on four moves: choose one step to automate or augment with AI; decide on the right automation (or augmentation) strategy—code vs. LLMs; prototype the first workflow with detailed instructions; and test and iterate until it meets my bar for quality and speed.
My goal is to give you enough guidance that you can follow along and end with a draft of your first AI workflow. If you apply continuous discovery to your own process, you’ll not only accelerate output—you’ll improve the clarity and quality of your thinking along the way.
I’ve spent the last few years weaving AI into core product workflows, and the pattern is clear: when we pair disciplined product thinking with pragmatic AI Strategy, growth compounds. The question I hear most isn’t if AI can help, but where to begin and how to de-risk the journey while moving fast.
AI for business growth starts with one of these six strategies. See how companies use AI to unlock revenue, cut costs, and scale smarter and faster.
1) Revenue acceleration with unified customer intelligence. I start by connecting behavioral analytics and CRM integration to a unified analytics platform, then layer a retrieval-first pipeline so large language models can surface high-intent accounts, churn signals, and next-best actions. With Amplitude analytics and A/B testing, we validate AI-driven playbooks for upsell, cross-sell, and win-back—turning insights into measurable lift rather than novelty.
2) Cost reduction through targeted automation. Not all automation yields the same outcome. I look for repetitive, high-volume processes where quality is easy to verify—customer support ai strategy with AI-assisted deflection, accounts payable automation, and security workflows like threat detection and response. Combining agentic AI with clear guardrails reduces handle time, frees teams for higher-value work, and keeps error rates within acceptable thresholds.
3) Faster time-to-market via eval-driven development. Speed without signal is noise. I lean on eval-driven development to instrument models, measure drift, and tighten CI/CD loops. We track DORA metrics like deployment frequency while using gen ai for product prototyping to compress discovery and delivery. Frameworks and tools such as Claude Code help engineers iterate safely behind feature flags so we can ship learning, not just code.
4) Personalization that drives activation and retention. Growth sticks when onboarding is contextual. I use in-app guides, product tours, and thoughtful tooltip design powered by LLMs for product managers to tailor the first-run experience. With retention analysis and outcomes vs output OKRs, we align personalization with the moments that matter—activation, habit formation, and expansion.
5) Trust-by-design to scale responsibly. AI risk management, privacy-by-design, and data governance are not afterthoughts; they are growth enablers. By defining policy, red-teaming prompts, and practicing context window management, we reduce rework, limit incident management, and maintain compliance across markets. Clear review gates make it easier to say yes to more AI use cases without compromising customer trust.
6) Voice and agent experiences that feel like product, not add-ons. When prompt engineering for voice and voice AI agent patterns are integrated into the core journey—guided onboarding, smart handoffs, proactive notifications—engagement rises. Agent Analytics turns conversations into product signals we can act on in roadmapping and sprint planning, closing the loop between user intent and product improvement.
My playbook for getting started is simple: pick one revenue and one efficiency use case, define success upfront, and ship a narrowly scoped MVP with robust analytics. Use continuous discovery with product trios to refine prompts, data sources, and experience design. Then scale what works, retire what doesn’t, and let evidence—not hype—set the roadmap.
If you’re evaluating where to apply gen ai next, these six lanes offer fast paths to impact without sacrificing governance or customer trust. The companies I’ve seen win treat AI as a capability within the product, not a separate project—and they measure it with the same rigor they use for any critical feature.
Once I’ve defined the right roles on my team, the next move is to design an operating model that makes progress a habit. My goal is simple: every interaction should strengthen the system so the AI Agent keeps improving over time.
I anchor the team on a mantra that has never failed me: “The first time you answer a question should be the last.” That single statement reframes support as a compounding system rather than a one-off activity.
The ambition is to ensure every resolution makes the next one faster and more accurate, so fewer issues repeat, quality compounds, and support scales naturally. That doesn’t happen by accident—it requires intentional design.
In practice, this comes down to four essentials: clear ownership of performance, guardrails that make iteration fast and safe, feedback loops that turn learning into routine upgrades, and a culture that celebrates the work of improvement—not just the outcomes. Here’s how I put that into play.
First, I start with clear ownership. Ambiguity is one of the most common reasons AI performance plateaus. When no one truly owns how the AI Agent performs, feedback gets lost, issues linger, and improvements stall.
On high-performing teams, I assign a single owner—often an AI ops lead—responsible for making the AI Agent better. They review resolution trends to spot underperformance, make targeted updates to content, configuration, and behavior, coordinate with product and engineering on systemic blockers, and set improvement priorities, targets, and timelines. The title matters less than the mandate; what matters is clear authority to drive change across teams.
Real-world example: At Dotdigital, AI performance plateaued after a strong start—resolving around 2,800 conversations per month for three consecutive months. To drive resolution rates up, the team created a dedicated support operations specialist role, filled by an experienced agent with deep product knowledge. This person will focus on refining snippets, improving content, and enhancing the AI’s resolution capabilities.
Second, I make iteration fast and safe. As the AI Agent takes on more volume and complexity, change can start to feel risky—so teams hesitate, and performance stalls. Lightweight governance fixes that by making the path from insight to action predictable.
I keep the rules simple and explicit: which changes need review (and which don’t), who the decision-makers are, how we test updates before they go live, where feedback flows so it’s seen and acted on, and when progress gets reviewed on a steady cadence. Governance isn’t bureaucracy—it’s what keeps improvement routine and safe.
Real-world example: Anthropic ran a focused “Fin hackathon” sprint to improve their AI Agent’s resolution rate. The team audited unresolved queries, identified underperforming topics, and created or updated content to close gaps. They converted frequently used macros into AI-usable snippets, monitored Fin’s performance during live support, and continuously refined content based on real interactions. This structured approach enabled rapid improvement while maintaining quality standards.
Third, I build a system that learns by default. AI performance isn’t static, but many organizations treat it like a one-time implementation. The most successful teams operationalize learning: they analyze where the AI Agent struggles and feed those insights directly into structured improvements.
The signals are straightforward: review common handoffs to humans, track unresolved queries by topic or intent, measure resolution rate trends over time, and use those inputs to prioritize fixes and content upgrades. Whether you follow a formal loop like the Fin Flywheel framework or something lighter, the goal is the same—make improvement inevitable.
Fourth, I treat content as competitive infrastructure. Your AI Agent is only as good as what it knows. As George Dilthey, Head of Support at Clay, put it: “That’s when we realized: AI doesn’t just come up with information out of nowhere, you have to feed it. We were spending all our time evaluating tools when we should’ve been focused on content.”
I operationalize knowledge like infrastructure: every topic has a clear owner, content is structured, versioned, and ingestion-ready, new products ship with source-of-truth content by default, and changes ship on a schedule—not when someone finds time. This is the backbone that differentiates teams who scale confidently from those who stall out.
In my organization, we’ve evolved our New Product Introduction (NPI) process by aligning early with R&D on a single, canonical source of truth that becomes the foundation for all downstream content—including what the AI Agent uses to resolve queries. By embedding content creation into launch readiness, not as an afterthought, we’ve consistently hit 50%+ resolution rates on new features from day one.
Finally, I make belief visible. Even the best system will stagnate if people stop believing in it. Belief can fade quietly unless you reinforce it on purpose. I keep it strong by sharing specific wins regularly, highlighting improvements with metrics, and recognizing the people behind the gains—then giving them space to lead. This isn’t just about morale; it keeps everyone aligned on the bigger play.
When you put it all together—clear ownership, safe iteration, a learning system by default, and content as infrastructure—AI performance compounds. As the AI Agent gets better, the entire support model becomes faster, more reliable, and truly scalable. That’s the foundation of a modern, AI-first support organization.
Next, I’ll take this a level deeper and share how capacity planning changes when AI handles the majority of inbound volume and your team shifts into higher-value roles. If scaling with confidence is the goal, this is where the operating model pays off.
When I assess whether an AI product is ready for prime time, I start with trust—not model accuracy. Accuracy is table stakes; trust is what earns adoption, drives retention, and unlocks durable product-led growth.
Evaluation metrics in AI products go beyond accuracy. Learn how product teams use trust-driven metrics to build reliable, growth-driving AI systems.
In practice, I organize trust-driven metrics into four layers: model quality and safety, user and business outcomes, operational reliability and cost, and governance and compliance. This layered approach keeps product trios aligned on what matters now, what must be gated in CI/CD, and what signals we’ll use to prove progress against outcomes vs output OKRs.
On model quality and safety, I care about precision, recall, F1, calibration, and abstention behavior, but also the hard-to-fake signals: hallucination rate, grounding and faithfulness, citation coverage, toxicity, bias, and fairness. For generative systems, I instrument refusal correctness (declining unsafe requests) and evidence adequacy (did the answer rely on retrieved, trustworthy sources).
User and business outcomes must be explicit. I track adoption, activation, task success rate, time to first value, win rate uplift in assisted workflows, CSAT and NPS deltas, and retention analysis by cohort exposed to AI features. For customer support scenarios, deflection rate, average handle time change, and first-contact resolution are core; for sales or ops copilots, I monitor cycle-time reduction and error-rate reduction in critical tasks.
Experimentation is non-negotiable. I design A/B testing with a clear minimum detectable effect (MDE), pre-registered guardrails for safety and quality, and sequential tests that stop early if harm outpaces benefit. Online metrics are always paired with offline evals so we can iterate quickly without exposing users to regressions.
Operationally, trust shows up as speed, stability, and cost predictability. I track latency end-to-end, time to first token, throughput, rate of 5xx and timeouts, cost per request, and caching effectiveness. We also trend safety incidents per 10,000 interactions and mean time to mitigation to keep reliability visible alongside performance.
Governance and compliance are part of the product, not an afterthought. Data governance and privacy-by-design metrics include PII exposure rate, data lineage coverage, access-control correctness, audit pass rate against internal policies, and model and prompt change traceability. This is the backbone of our AI risk management posture and accelerates regulatory compliance reviews instead of slowing them down.
The delivery engine for all of this is eval-driven development. We maintain golden datasets and scenario-based test suites that mirror real user intents, gate releases in CI/CD with minimum thresholds, and run canary rollouts to validate offline–online alignment. Every model or prompt update gets a comparable scorecard so product, engineering, and design can trade off quality, speed, and cost with shared facts.
For LLM-heavy features, retrieval-first pipeline metrics are mandatory. I monitor retrieval hit rate, recall at K, mean reciprocal rank, context contamination, and citation correctness. With large prompts, context window management matters: we track context utilization, truncation rate, and the contribution of each context block to final answers to avoid silently losing critical evidence.
Finally, trust must be legible. I package these metrics into an executive scorecard that maps to business outcomes, risk appetite, and OKRs, with clear thresholds for ship, improve, or roll back. When teams can articulate trade-offs—say, a 20% latency reduction at a small cost increase, or a lower hallucination rate at the expense of higher abstention—they build credibility with stakeholders and confidence with customers.
Trust is not a single number; it’s a system of evidence. By instrumenting these layers and operationalizing AI Strategy with rigorous, transparent metrics, we can ship faster, reduce surprises, and earn the right to scale AI features across the product portfolio.
Vibe marketing can electrify a brand, but it can also derail a strategy if it outruns the fundamentals. I have seen campaigns with breathtaking creative fall flat because the message had no anchor in product truth, no measurable goals, and no operational guardrails. In this installment, I share the patterns I watch for, the diagnostics I run, and the AI tools I use to keep the vibe aligned with outcomes.
Learn how to avoid the five most common mistakes in vibe marketing to have more success with AI marketing tools.
At its best, vibe marketing translates product positioning and value proposition into an emotional signal customers immediately recognize. At its worst, it becomes mood without meaning. The difference is disciplined product management: clear go-to-market strategy, outcomes vs output OKRs, rigorous A/B testing, and a feedback loop that connects creative choices to customer behavior.
Mistake 1: Mistaking mood for strategy. Early drafts often lean on catchy lines or trending aesthetics that don’t map to customer jobs-to-be-done or competitive differentiation. When I feel that drift, I force the team to articulate the core product promise, restate the positioning, and tie each headline to a measurable outcome. If a message cannot be traced to a specific hypothesis, audience, and metric, we rewrite it before it ships.
Mistake 2: Chasing trends instead of customer truth. Vibes built on whatever is viral this week rarely compounding learnings. I push for continuous discovery with interviews, in-product surveys, and sentiment analysis, then let gen ai generate multiple narrative variants grounded in actual quotes and objections. We evaluate with A/B testing and an explicit minimum detectable effect so we don’t declare victory on noise. That keeps our experimentation eval-driven, not anecdote-driven.
Mistake 3: Measuring vanity, not meaning. Reach and likes can be directional, but I optimize for activation, time-to-value, retention analysis, and conversion lift across the funnel. I instrument journeys in a unified analytics platform with Amplitude analytics and CRM integration so we can connect vibe exposure to outcomes. If the creative lifts click-through but hurts downstream activation, it’s not working—no matter how cool it looks.
Mistake 4: One vibe for every segment and channel. Audiences experience value differently, so the same creative rarely works in ads, landing pages, and in-app guides. I use LLMs for product managers and CustomGPT workflows to adapt the message by segment and stage, then validate with product tours, in-app prompts, and targeted lifecycle emails. The goal is coherence, not uniformity: a consistent story tuned to the context where decisions happen.
Mistake 5: Unbounded AI experimentation. Without AI risk management and data governance, teams can unintentionally ship off-brand or non-compliant copy. I set privacy-by-design standards, define approval thresholds, and establish context window management so models stay on-brief and on-policy. We log generations, review outputs against brand guidelines, and use retrieval to ground messaging in approved claims.
My practical playbook is simple: define the hypothesis tied to positioning, generate creative options with gen ai, pre-qualify with qualitative feedback, run A/B tests with clear success criteria, and iterate only on variants that move a business metric. Product trios align weekly on learnings so marketing signals and product-led growth motions reinforce each other. When the vibe matches the value and the data, momentum compounds.
Vibe marketing is not the opposite of rigor; it is rigor expressed emotionally. With the right AI strategy, measurement discipline, and governance, the creative spark becomes a durable advantage—and your brand earns the right to keep the spotlight.
Inspired by this post on Amplitude – Perspectives.
I love real-world AI that ships, scales, and actually solves painful customer problems. This story checks every box. As a product leader who has brought agentic AI to production environments, I was captivated by how a small, focused team at Perk took a no-code voice AI prototype and turned it into a system that reliably makes 10,000+ calls per week to prevent failed hotel payments.
What happens when you combine a real customer problem, a no-code prototype, and a team willing to listen to every single call?
Steven Payne (Product Manager), Gabriel Stock (Senior Engineering Manager), and Philipe Steiff (Senior Software Engineer) from Perk share how they built a voice AI agent that calls hotels to verify virtual credit card payments, preventing travelers from arriving to find their rooms unpaid. This is a textbook example of linking operational pain to a high-leverage AI solution.
What started as a hackathon experiment in Make.com became a production system handling over 10,000 calls per week across multiple languages. Along the way, the team learned hard lessons about prompt engineering for voice (numbers, pronunciation, and a very "Karen-like" first version), how to break a single monolithic prompt into structured conversation stages, and why listening to actual calls beats any amount of theorizing.
From a product management perspective, this approach aligns perfectly with eval-driven development and continuous discovery. Structure the problem, instrument aggressively, ship safely, then listen—deeply—to real interactions. In my own teams, I’ve seen that nothing accelerates iteration on agentic AI like closing the loop between qualitative call reviews and quantitative evals.
They built a working prototype without writing a single line of backend code.
They structured the call into discrete stages (IVR, booking confirmation, payment) to improve reliability.
They created two eval systems: one for call success classification, another for conversational behavior.
They scaled from five calls a day to tens of thousands per week while maintaining quality.
This is a detailed look at building AI for real-time human interaction—where the stakes are high and the feedback is immediate.
Guests: Steven Payne, Product Manager, Perk; Gabriel Stock, Senior Engineering Manager, Perk; Philipe Steiff, Senior Software Engineer, Perk.
What stood out to me was how Perk's team identified an AI use case by connecting prior experimentation with a real operational problem. Why they chose Make.com for prototyping—and shipped to production without touching backend code—underscores how far no-code can take you when paired with crisp problem framing. The evolution from a single prompt to structured conversation stages (IVR handling, booking confirmation, payment request) is exactly how you harden agent behavior for production.
Breaking up the agent's task dramatically improved reliability. They also built two eval systems: classification for success rates and LLM-as-judge for conversational behavior. Even with automation, the team still listens to calls manually—a practice I strongly endorse for uncovering edge cases, trust issues, and UX nuances that dashboards can’t show.
The challenge of prompt engineering for voice—numbers, booking references, and text-to-speech markup—was non-trivial. Expanding to German revealed that prompts in native language improve results. And, as often happens with operations-heavy rollouts, this project uncovered other operational problems they didn't know existed—valuable signal for the roadmap.
Resources & Links: Perk. Make.com — No-code automation platform used for the prototype. Twilio — Voice/telephony provider. Eleven Labs — Text-to-speech provider (used in early experiments).
Chapters: 00:00 Introduction to the Team; 01:54 Understanding PERK's Mission; 02:59 Challenges in Travel Booking; 07:27 AI Solutions for Customer Care; 09:52 Prototyping with AI and Voice; 17:00 Implementing AI in Production; 25:51 Learning Through Trial and Error; 26:40 Prompting Challenges and Solutions; 27:58 Iterating on Prompts and Evaluations; 30:08 Scaling and Production Challenges; 32:43 Advanced Evaluation Techniques; 35:32 Real-World Applications and Success; 49:07 Future Directions and Expansion; 53:53 Conclusion and Team Reflections.
My product takeaways: Start with clear operational pain and measurable outcomes (e.g., payment verification). Use no-code to validate quickly, then progressively harden. Treat voice AI like any production system: break it into deterministic stages, add guardrails, and measure both outcome and behavior. Pair automated evals with hands-on reviews. And when going multilingual, write prompts in the native language—your accuracy will thank you.
If you’re exploring agentic AI for operations, this is the blueprint: tight scoping, Make.com for speed, Twilio for reliability, structured prompts for control, and an eval-driven loop to scale quality with confidence.
AI search is reshaping how customers discover emerging products, and I’ve seen firsthand how this shift rewards startups that speak clearly to both humans and machines. Learn how LLMs like ChatGPT and Perplexity decide which startups to recommend and what signals help a brand get discovered in AI search.
In practice, AI search behaves less like a list of blue links and more like a synthesis engine. These models look for credible, consensus-backed, well-structured sources they can cite with confidence. That means your brand’s discoverability hinges on technical clarity (schema, structure, speed), topical authority (depth, citations, expert bylines), and evidence of real-world adoption (reviews, case studies, third-party validation).
I start by mapping buyer intent across the entire journey—category exploration, problem framing, solution fit, integration needs, ROI, and competitive comparisons. Then I design a page system that answers each intent with precision: clear “About” and “Use Cases” pages, integration-specific pages, objective "X vs Y" comparisons, transparent pricing, and a living FAQ that mirrors the exact questions users ask in conversational queries.
Structure matters. I add JSON-LD schema for Organization, Product, FAQPage, HowTo, and Article where appropriate; keep canonical URLs consistent; and ensure titles, meta descriptions, and Open Graph data reinforce the same story. Clean sitemaps, a sensible robots.txt, and fast, mobile-first performance reduce friction for crawlers and increase the odds that LLMs extract accurate snippets.
Authority is earned off-site as much as on-site. I prioritize third-party signals—G2/Capterra reviews, analyst mentions, reputable press, open-source repos with README clarity, academic or industry citations, and credible partner integrations. LLMs heavily weight these external proofs when recommending solutions, especially for B2B and regulated categories.
On your site, demonstrate expertise. I include expert bylines with real credentials, cite primary sources, showcase customer outcomes with verifiable metrics, and make methodologies transparent. Shallow, keyword-stuffed posts don’t help; comprehensive, up-to-date explainers with references do.
Make your content retrieval-friendly. LLMs favor text they can segment, anchor, and quote. I structure pages with descriptive headings, short paragraphs, and linkable anchors; offer HTML-first documentation (not just PDFs); and provide copyable code or configuration steps when relevant. This also sets you up for a retrieval-first pipeline in your own product experiences.
From a product and platform angle, I expose trustworthy documentation and a clear trust center—security, compliance, data governance, and privacy-by-design content. When a user asks an LLM whether they can safely deploy your solution, these pages often get pulled into the answer.
Evaluation closes the loop. I run an eval-driven development process for content: a stable prompt set that mirrors real queries, regular tests in both Perplexity and ChatGPT, and analytics to track referrals from AI-driven sources. I iterate headlines, schema, and on-page structure, then tie changes back to engagement and pipeline using A/B testing where it’s appropriate.
Don’t neglect comparison and alternatives pages. Fair, well-cited pages that address trade-offs and points of parity build trust—and they give LLMs succinct, quotable language for recommendation contexts. Clarity beats hype every time.
Finally, keep your corpus fresh. I schedule quarterly content reviews, retire outdated claims, and highlight release notes and integration updates. Freshness signals help models favor your content when they resolve time-sensitive queries.
If you treat AI search as a product surface—one that rewards precision, provenance, and performance—you’ll dramatically increase your odds of being recommended where it matters. That’s how I operationalize AI discovery for startups: intent mapping, structured content, external authority, a retrieval-friendly corpus, and a rigorous eval loop.
Inspired by this post on Amplitude – Perspectives.
I’ve learned that the most powerful AI features rarely emerge from lone-wolf brilliance—they’re born when a community rallies around a shared objective. “Building Amplitude’s AI for insight automation felt a lot like the fable of travelers making stone soup with their community.” That spirit captures how I approach shipping AI for analytics: bring focused ingredients, invite contributions, and let rigorous evaluation transform the result into something extraordinary.
At the core is Eval-Driven Development. Rather than debating preferences, we define explicit evaluation sets, success thresholds, and guardrails, then wire them into CI/CD so every change improves reliability, quality, and relevance. For AI-driven analytics, our evals combine offline judgment tests (precision, recall, hallucination rates), user-centric measures (time-to-insight, actionability), and production health signals (failure modes, latency). When the bar rises, the product improves—continuously and measurably.
We made “stone soup” by inviting contributions from every function. Data science established gold-standard datasets and baselines. Engineering implemented retrieval, orchestration, and safe deployment paths. Product and design framed high-value use cases, in-app guides, and UX writing that clarified intent. Customer success and support piped real-world edge cases into our evals so the system improved where it mattered. Product trios kept us outcome-focused and empowered product teams moved quickly without sacrificing governance.
Why this matters for analytics: AI insight automation reduces the heavy lift of exploring funnels, cohorts, anomalies, and retention patterns—accelerating activation and product-led growth. With a unified analytics platform and strong data governance, we can surface relevant patterns proactively, explain the “why” behind movements, and recommend next best actions without drowning users in noise. The result is faster decisions, cleaner handoffs between teams, and a tighter loop from observation to intervention.
Our practical playbook is simple but strict: define a clear north-star outcome; curate representative eval sets that mirror real user questions; simulate A/B testing offline before live traffic; instrument time-to-insight and adoption; and integrate evals into CI/CD so regressions never ship. We monitor DORA metrics to maintain delivery velocity while holding quality lines, and we use human-in-the-loop review to continuously refine prompts, patterns, and explanations.
We also learned what doesn’t work. General-purpose prompts seldom transfer cleanly to analytics without domain grounding and context window management. A retrieval-first pipeline improves factuality, but only if metadata and event taxonomies are consistent. And while generative UX can delight in demos, it must earn trust in production through transparent reasoning, privacy-by-design, and predictable behavior under load.
In the end, the stone soup metaphor isn’t about cute storytelling—it’s about disciplined collaboration. When a cross-functional community contributes the right ingredients and Eval-Driven Development keeps us honest, AI for insight automation becomes both credible and compounding. That’s how we turn analytics into action—and how we ship AI products that users rely on every day.
Inspired by this post on Amplitude – Best Practices.
Every week, I ask a simple question with massive implications for our AI Strategy: what do large language models actually say about our brand? As a VP of Product Management at HighLevel, I’ve learned that competitive differentiation now lives as much in AI-generated responses as it does in traditional search or social. That’s why a reliable, unified analytics platform for AI visibility is quickly becoming table stakes for product management leadership.
Discover how Amplitude AI Visibility helps you track your visibility score, uncover competitor rankings, and prove business impact—all in one platform.
Here’s why that matters. A visibility score gives me a measurable baseline—our AI share of voice—so I can see whether our product-led growth and go-to-market strategy are landing in the places where buyers increasingly look for answers. Competitor rankings reveal points of parity and opportunities to differentiate, which directly inform product positioning and our value proposition. And the ability to prove business impact closes the loop between AI exposure and outcomes that executives care about.
Operationally, I would start by benchmarking our visibility score against key competitors, then segment by core use cases to identify where our story underperforms. Those insights feed product discovery, content strategy, and enablement—tightening the narrative to better align with buyer intent. I’d translate the findings into prioritized bets for the roadmap and partner closely with marketing to amplify wins and address gaps.
For teams exploring LLMs for product managers and GenAI-driven growth, this approach creates a disciplined feedback loop: measure what AI says, experiment to improve it, and verify the impact across the funnel. It’s a pragmatic way to connect messaging, discovery, and differentiation—without guessing what the models are surfacing about your brand.
I’ve followed Amplitude analytics for years, and Amplitude AI Visibility slots naturally into a modern operating model: one platform to monitor the signals that matter, align stakeholders, and make faster, evidence-based decisions. If your mandate includes scaling product-led growth and sharpening competitive differentiation, this is a timely, actionable way to see—and shape—how AI represents you.
Inspired by this post on Amplitude – Best Practices.
I’m constantly looking for ways to collapse the distance between product questions and trustworthy answers. When behavioral data shows up in the tools I already use, my team moves faster, aligns better, and makes higher-confidence calls. That’s exactly why Amplitude MCP caught my attention—and why it’s quickly becoming essential to my AI Strategy and day-to-day Product Management practice.
Discover how Amplitude MCP brings behavioral context to AI tools like Claude and Cursor, enabling data-driven decisions in your existing workflows.
In practice, this means I can ask Claude, Cursor, or even Claude Code about activation cohorts, retention analysis, funnel drop‑offs, and feature adoption—and get responses grounded in Amplitude analytics without tab-hopping. By bringing our unified analytics platform into the flow of work, I keep momentum high and decision latency low, especially during fast-moving discovery and delivery cycles.
This approach elevates LLMs for product managers from clever assistants to reliable copilots. During continuous discovery, I can interrogate segments, compare behaviors across personas, and pressure-test hypotheses in minutes. In product-led growth environments, that behavioral context turns prioritization into a repeatable, outcomes-first ritual rather than a debate fueled by anecdotes.
Equally important, MCP helps me protect the integrity of our metrics. With consistent definitions flowing into AI tools, I reduce shadow analysis, preserve governance, and support privacy-by-design. Stakeholders—from engineers to design to GTM—see the same truths, which improves trust and accelerates alignment across the organization.
Getting started is straightforward: connect your workspace, ensure your event taxonomy is clean, and align key properties with CRM integration so segments and journeys remain attributable. I also curate an AI product toolbox of prompts for common workflows—say, exploring A/B testing outcomes or checking the minimum detectable effect (MDE) before a new experiment—so the team can move quickly without reinventing the wheel.
The payoff is immediate: fewer context switches, faster iteration loops, and sharper decisions where they matter most—inside the tools we already rely on. If you’re charting your gen ai roadmap, consider how Amplitude MCP can infuse behavioral insight into every conversation and commit. For me, it’s a pragmatic step toward an intelligent, data-informed product practice that scales.
Inspired by this post on Amplitude – Best Practices.
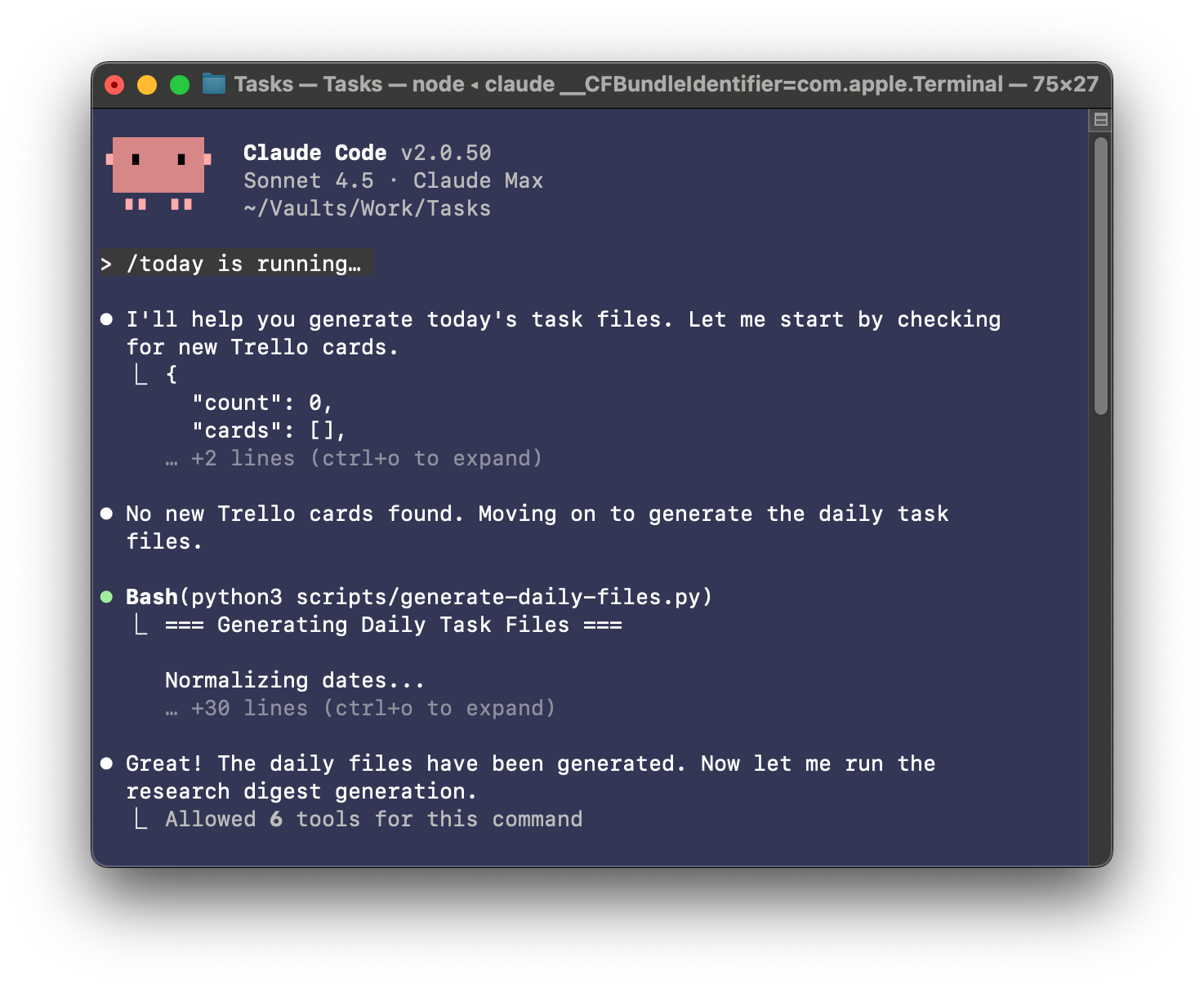
Most mornings start the same way for me: coffee in hand, I sit down, open Claude Code, and type /today. In a few seconds, Claude pulls fresh tasks from my Trello board, compiles a clean today.md with what matters most, and assembles a research digest of the latest academic work across my focus areas.
Scanning that today.md has become my daily ritual. My workload typically spans writing, coding, and administration. I now make a habit of asking Claude, "What's on my to-do list that you can help with?" That simple question keeps me honest about where AI can accelerate my day.
I’m experimenting with a workflow where Claude enriches every task based on what it can take on or accelerate. It’s still early, so we iterate together for a few minutes each morning to tighten the loop and improve the prompts and outputs.
Next up is my research digest. I skim, download the PDFs that look promising, and move on. Tomorrow, Claude will deliver detailed summaries of every paper I saved—so I stay current without burning hours on search and sorting.
For the first few hours, I protect deep work. Today, that means writing this article. My to-do list and draft live side-by-side in Obsidian, so I click directly from the task into the outline, pick up my running conversation with Claude, and get right back into flow. I pair-write: we outline, I draft, and then I ask, "I wrote the intro. What do you think?"
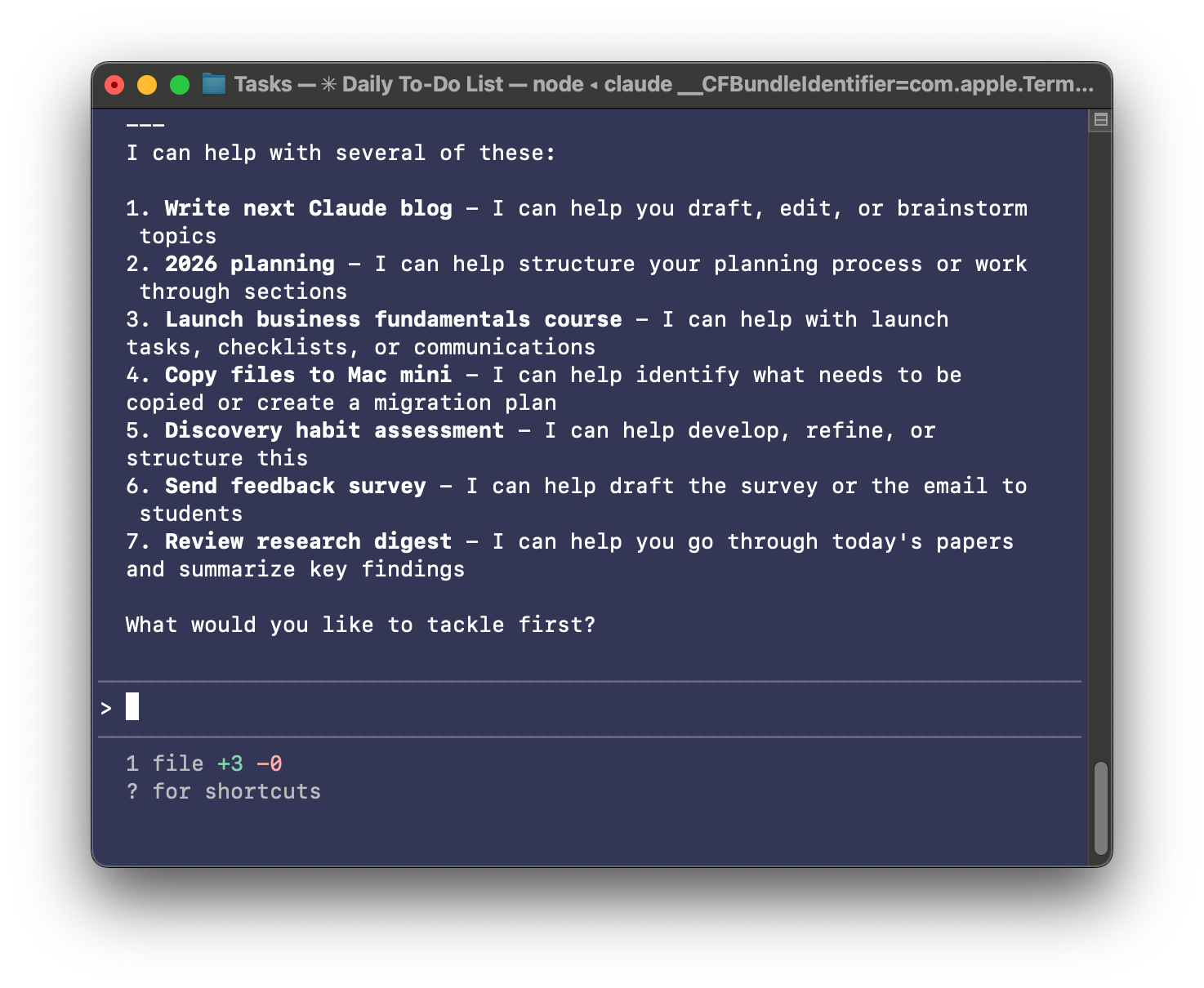
A terminal-based AI helper suggests concrete ways to lighten your workload—draft a blog, plan 2026, launch a course, migrate files, craft a survey, and digest research—so you can pick the next task fast.
Claude gives pointed feedback—what’s working, what needs tightening—and we iterate. This is genuinely how I work now. I pair with Claude on almost everything I do. It didn’t happen overnight; over the past five months, I’ve built a personal AI-enhanced operating system that has fundamentally improved how I operate: more output, faster cycles, and frankly, more joy in the work.
Because it’s made such a difference, I’m sharing the playbook. If you’re new to Claude Code or want to get more from it, start here:
Claude Code: What It Is, How It's Different, and Why Non-Technical People Should Use It
Stop Repeating Yourself: Give Claude Code a Memory
How to Use Claude Code Safely: A Non-Technical Guide to Managing Risk
In recent office hours, one question came up again and again: Where do I start—what should I automate and what should I have AI augment? Today, I’ll walk through how I decide, share my own workflows, and show how I prioritize what to build next. Next week, we’ll get into how to design and build personal workflows.
This series was inspired by my personal usage of Claude Code. I have not received any compensation from Anthropic for writing this series. And you can trust that if that ever changes, I will disclose it. This is not only required by the FTC here in the US, but I strongly believe it is the right thing to do. You can count on me to do so.
Understanding what AI workflows can do for you
Peek inside a dark-themed writing workspace where a markdown editor displays an article on choosing tasks to automate with AI. The sidebar organizes notes, while the draft outlines pulling Trello tasks, making today.md, and using Claude.
I started with ChatGPT in the browser not long after it launched and quickly began asking, “Can ChatGPT help with this?” As my use cases grew (and my patience for copy-paste vanished), I moved to Claude Code. The philosophy never changed: continuously push the envelope of what LLMs can do today while managing risk.
My default stance is to attempt everything with AI, then decide what becomes a reusable workflow versus a one-off assist. A workflow, to me, is a sequence of steps where some are automated by AI, others are AI-augmented, and some still require me.
Across my setup, clear patterns emerged. I use AI to: (1) do more of what I’m already good at, (2) eliminate friction in frequent tasks, and (3) remove what drains me. The goal is simple: multiply impact without sacrificing quality.
Take writing. I now average about 35,000 words per month—up from roughly 8,000. I’m writing more often and in more depth. I draw more from academic research and include more stories—both my own and those from others. Claude gives me detailed feedback on everything I write, which helps me maintain momentum. It’s remarkable how often a simple nudge—“Ready to write the next section?”—keeps me in the zone. I also spend more time with Claude on structure before drafting, so I discard far less.
Go behind the scenes of creating an AI automation guide: a split-screen workspace pairs the article draft with detailed reviewer notes, revealing a practical, iterative process of outlining, fact-checking, and refining before publication.
Podcast production is another domain where AI shines. I produce two weekly shows: I love connecting with Petra Wille on All Things Product, and talking with product teams building AI-powered products on Just Now Possible. I use Descript to edit, and I rely on Claude Code shortcuts (slash commands) to draft episode titles, descriptions, show notes, chapters, and social posts. I still own the editorial bar—no “AI slop”—but I let AI handle the heavy lifting so I can focus on shaping the final story.
Then there are tasks I fully automate. I love reading across creativity, collaboration, AI efficacy, and more. I do not love searching for relevant papers. So I don’t. Every morning, my automated research workflow finds the newest, most relevant articles and populates my digest. All I do is review.
Choosing your first AI workflows
Classic delegation advice still applies: build awareness of where your time goes; identify what you can delegate; invest your time in the work you’re uniquely equipped to do. That’s a great start for AI workflow strategy, but don’t ignore what you love doing and want to do more of. Augmentation often generates the highest returns—AI helps me go deeper, faster, without diluting my craft.
Peek inside an AI-powered curation flow: a markdown workspace compiles a 'Filtered Research Digest' with criteria, paper counts, and summaries, demonstrating how automation turns raw literature into actionable insights.
To uncover opportunities, I simply ask, over and over: Can AI help with this? As you go about your work today, keep asking yourself: How can AI help with this?
Evaluating if a task is a good candidate for an AI workflow
Through trial and error, I now run new tasks through a quick filter:
• Is this a one-time task or do I do it often?
A clean, workshop-style slide asks the pivotal question: "How can AI help with this?" Use it to spark automation ideas, map steps, and decide where generative AI can accelerate research, drafting, analysis, and repetitive work.
• Do I enjoy doing this task or would I give it to someone else if I could?
• How complex is the task?
• Can I articulate how I would do the task step-by-step?
• Does completing the task require my human judgment?
• Can I define what "done successfully" looks like?
• How much risk is there if the task is not done well?
This checklist takes minutes and pays off quickly. The answers tell me whether to automate, augment, or keep a task human-only for now—and they guide how much process and guardrailing to build around each workflow.
From here, I’ll walk through how to answer these questions in practice, how the answers map to different levels of automation or augmentation, and how I prioritize which workflows to invest in. I’ll also share 41 of my own AI workflows (noting which are automated versus augmented) plus 9 discovery-related workflows currently in development so you can steal shamelessly and ship your first one today.
The rest of this article requires a paid subscription. This publication is reader-supported. If you’ve benefited from my writing, please subscribe today.