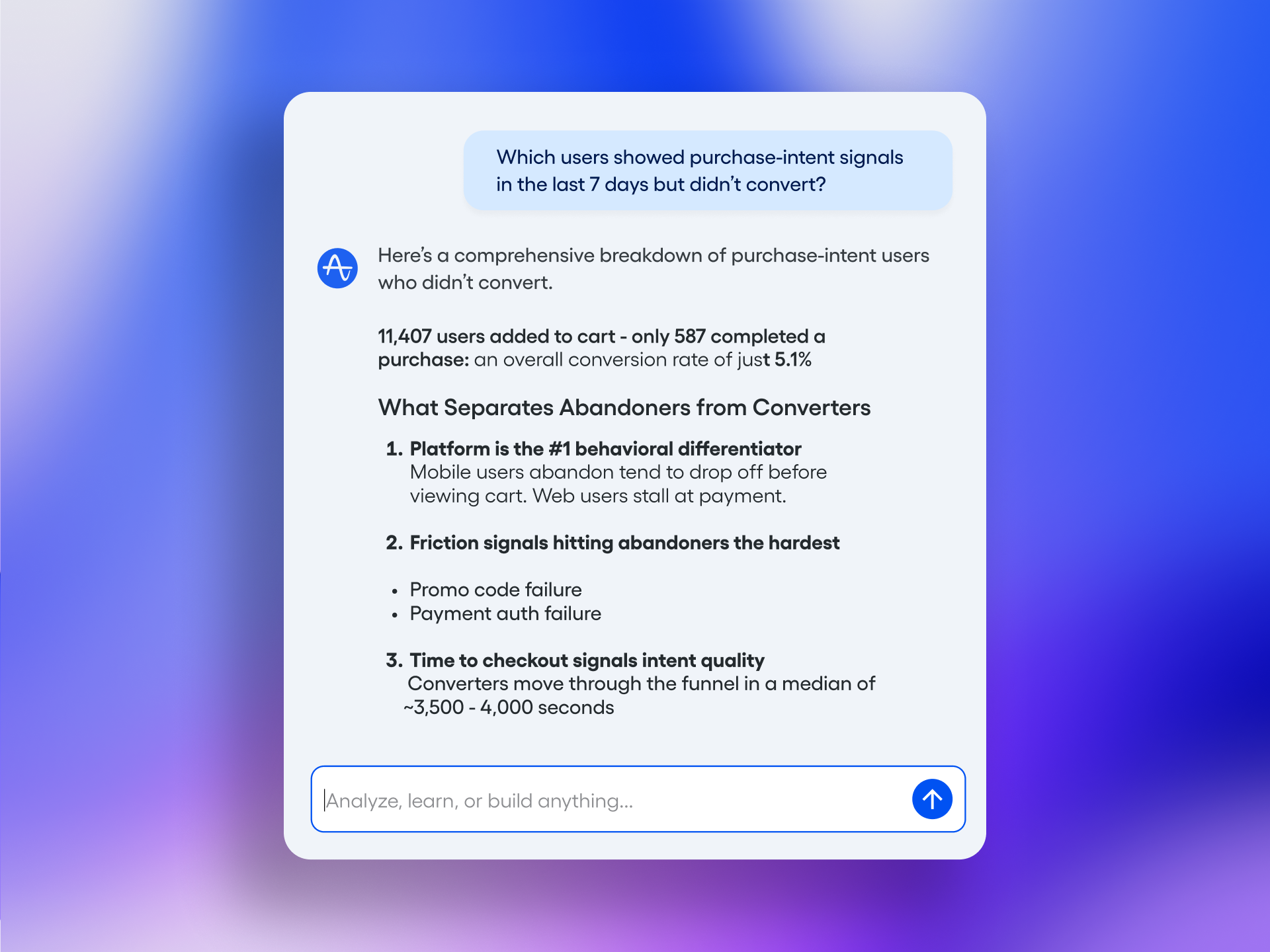
You have an AI demo that looks impressive. It answers the happy-path prompt, the latency seems acceptable, and stakeholders can already imagine the launch. The uncomfortable question is whether any of that proves the product is worth building.
It does not. A useful validation process has to reduce several different risks: whether customers care, whether the workflow helps them, whether the AI performs reliably, whether the economics work, and whether failures remain tolerable. Test those risks in that order and you can make a defensible investment decision without turning production traffic into your debugging environment.
Define the decision before you design the AI
The first artifact for an AI initiative should not be a model shortlist or a prototype. It should be a decision contract that states what must become true for the initiative to deserve more investment.
A practical decision statement has this shape: For a defined user in a defined situation, the proposed capability will improve an observable outcome relative to the current alternative, without breaching named guardrails. If the agreed threshold is met, you will advance. If it is not, you will stop or change a specific assumption.
Write down these five elements before the experiment begins:
- User and job: Name who encounters the problem, when it occurs, and what they are trying to complete. A broad label such as knowledge workers is not precise enough to design a useful test.
- Current alternative: Record what the user does now, including manual work, an existing product flow, a rules engine, or simply tolerating the problem. This is the baseline the AI must beat.
- Observable outcome: Choose a user or business result, not a model activity. Task completion, time-to-value, corrected routing, rework, repeat use, or downstream resolution can carry more meaning than generations or prompt volume.
- Success threshold and guardrails: Decide how much improvement would justify the cost and what must not deteriorate. Safety failures, latency, privacy exposure, retention, and cost per successful outcome can all constrain an otherwise positive result.
- Decision rule: State what evidence will trigger expansion, another iteration, a change in direction, or cancellation. Precommitting prevents enthusiasm for a polished demo from moving the goalposts later.
The threshold is not universal. It should reflect the value of the outcome, the implementation and operating costs, the consequences of errors, and the return available from competing roadmap work. Minimum detectable effect belongs here: define the smallest improvement that would actually change your decision, then size the test to detect that effect. A test that cannot distinguish a worthwhile gain from noise is not a faster test. It is a delayed decision.
A driver tree helps prevent a common measurement mistake. Start with the desired outcome, connect it to the user behaviors that could produce that outcome, and then connect those behaviors to system-level drivers. For an AI support-triage capability, the outcome might be faster correct routing. Accepted category and priority suggestions are leading signals; downstream corrections, reassignment, and resolution are closer to the outcome. Model classification accuracy matters, but it is only one driver in the chain.
If the proposal involves an autonomous or semi-autonomous agent, run a precondition check before planning the experiment. Volume, instructions, tolerance, access, and a learning loop expose whether agentic complexity is justified:
- Volume: Does the workflow happen often enough for automation to create meaningful leverage?
- Instructions: Can success, constraints, and exceptions be expressed in testable terms?
- Tolerance: Is the likely failure reversible, detectable, and contained?
- Access: Can the system use the necessary data and tools with reliable integrations and least-privilege permissions?
- Learning loop: Can you measure quality, latency, cost, and failures after launch?
A missing condition tells you what to validate next. Unclear instructions call for more discovery and rubric design. Weak access calls for an integration or data-quality spike. Low error tolerance calls for approvals and a narrower action space. Low volume may mean that a clear workflow, a rule, or better product UX is the better answer. The purpose of validation is not to prove that AI belongs in the solution; it is to discover whether it does.
Climb an evidence ladder instead of jumping to a pilot
An oversized pilot often mixes market, usability, model, integration, and operational risk into one expensive test. When the result disappoints, nobody knows which assumption failed. An evidence ladder gives each experiment one dominant question and increases fidelity only after the previous uncertainty has been reduced.
| Question to answer | Lean experiment | Evidence to inspect | What it does not prove |
|---|---|---|---|
| Do users care enough to act? | Painted door, landing page, waitlist, concierge offer, preorder, or deposit where appropriate | Click-through intent, qualified sign-ups, willingness to pay, and continued requests | Usability, AI quality, or scalable delivery |
| Can the proposed workflow help? | Wizard-of-Oz flow or realistic interactive prototype | Task completion, time on task, errors, material friction, and repeat use | Whether an AI system can deliver the experience reliably |
| Can the system perform the job? | Offline evaluation on a curated golden set plus targeted technical spikes | Rubric results by case type, failure patterns, latency, and cost | Whether the complete product changes user behavior |
| Does the product improve the target outcome? | Feature-flagged A/B test or holdout | Primary outcome, leading indicators, cohort effects, and guardrails | Long-term stability under every operating condition |
| Can it operate within acceptable risk? | Capped rollout with approvals, audit logs, monitoring, and rollback controls | Harm and privacy events, reversals, escalations, reliability, and cost per successful outcome | That future changes will remain safe without continued evaluation |
Use the first row when demand is the dominant risk. A painted-door click is a signal of curiosity, not proof of durable value. A qualified sign-up asks for more commitment. A preorder or deposit, when honest and operationally appropriate, tests willingness to pay. Repeated use of a manually delivered service provides stronger behavioral evidence. Do not collapse these signals into a single conversion metric; they represent different levels of commitment.
Once demand appears credible, use a prototype or Wizard-of-Oz flow to learn whether the proposed interaction helps. Pretotyping should answer whether the product deserves to exist, while prototyping should answer how it needs to work. Keeping those questions separate prevents a polished interface from disguising weak demand and prevents a crude early interface from killing a valuable idea before its workflow has been understood.
These experiments still owe users honest expectations. A painted door should reveal that the capability is unavailable after the user expresses interest, rather than pretending it already exists. A concierge or Wizard-of-Oz flow should be explicit about how data will be handled and what follow-up the participant can expect. Deception can manufacture a metric while damaging the trust the eventual product will need.
Advance when the evidence changes the dominant uncertainty. Strong demand does not authorize a production launch; it authorizes a workflow test. A usable workflow authorizes a system evaluation. An offline pass authorizes limited exposure. Each rung earns the next investment without pretending to answer questions it was not designed to answer.
Separate model quality from product value
A model can produce better answers while the product creates less value. Added latency can interrupt the workflow. A retrieval failure can ground an otherwise capable model in the wrong context. A user may spend more time checking and rewriting an answer than doing the task manually. This is why a single accuracy score cannot validate an AI product.
Build a golden set from the work users actually do
Eval-driven development starts before production traffic. Build a curated set of cases that reflects real user complexity, then turn your definition of good into a reproducible scoring process.
- Define the evaluation unit: Score the completed job whenever possible, not merely an isolated response. An agent that drafts a correct message but sends it to the wrong destination has failed the job.
- Represent meaningful variation: Include normal cases, longer and shorter inputs, ambiguous requests, important customer segments, and known edge conditions. A convenience sample of clean happy paths measures demo readiness.
- Tag each slice: Label cases by intent, complexity, risk, input type, or other distinctions that could conceal a concentrated failure. Aggregate performance can improve while a critical slice gets worse.
- Write a multidimensional rubric: Score correctness, completeness, groundedness, safety, tone, policy compliance, and any task-specific requirements separately. Add latency and cost as system measures rather than blending everything into an opaque average.
- Choose a real baseline: Compare the candidate with the current product, manual workflow, rules-based approach, or incumbent model. The relevant question is not whether the candidate looks capable in isolation; it is whether switching produces enough value.
- Preserve regression evidence: Keep a stable set for comparisons and add newly discovered failures to an evolving challenge set. This turns production learning into protection against recurrence.
Keep the measurement layers visible in every readout:
- Output quality: correctness, completeness, groundedness, tone, safety, and compliance.
- System performance: retrieval quality, tool execution, policy enforcement, latency, reliability, and cost.
- User outcome: task completion, time-to-value, edits, rejection, rework, escalation, and repeat use.
- Business consequence: the downstream result the initiative was funded to improve, along with retention or other core guardrails where relevant.
Each layer diagnoses a different problem. If output quality is weak, work on context, prompts, retrieval, tools, policies, or the model. If output quality passes but completion does not improve, inspect the interaction and workflow. If users succeed but the cost per successful outcome is unacceptable, narrow the use case or revisit the architecture. A composite score can hide these distinctions at exactly the moment you need them.
Test the behavior distribution, not a lucky response
AI output is variable, so a candidate should not pass because one run happened to look good. Use two evaluation modes. A regression configuration should be as controlled as the system allows, with model, prompt, retrieval, tool, temperature, top-p, and seed settings documented where they apply. A production-like configuration should match the variability users will experience and repeat cases often enough to reveal unstable behavior and tail failures.
- Run candidate and baseline systems on the same cases under comparable settings.
- Inspect results by slice and failure type, not only the overall average.
- Repeat stochastic cases so the team sees consistency, variance, and severe outliers.
- Automate clear rubric checks, but retain human review for ambiguous or high-consequence judgments.
- Version the model, prompt, retrieval configuration, tools, policies, and evaluation set so a change can be reproduced.
This creates a release gate instead of a demo contest. Offline evaluation will not prove market value, but it can prevent known regressions, unsafe behavior, and obviously weak variants from consuming customer trust in a live experiment.
Make the production test answer a business decision
Production exposure is justified when demand, workflow, and offline performance have enough evidence behind them. The live test should then answer a narrow causal question: does access to this capability improve the intended outcome for the eligible population, compared with the current experience, without violating the operating constraints?
Instrument the complete causal chain
Your event schema should connect eligibility to exposure, interaction, system behavior, task completion, and downstream consequences. At minimum, distinguish these moments:
- The user or account became eligible for the test.
- The treatment was actually shown or made available.
- The capability was invoked, whether explicitly or automatically.
- The system succeeded, failed, timed out, or triggered a safeguard.
- The output was displayed, accepted, edited, rejected, reversed, or escalated.
- The target task was completed or abandoned.
- The downstream outcome occurred, such as a correction, reassignment, reopening, or successful resolution for a support workflow.
Attach the cohort and the relevant model, prompt, retrieval, tool, and policy versions to the trace. Capture latency, cost, and safety results without indiscriminately logging sensitive payloads. Privacy-by-design and data governance determine which data may be retained, who may inspect it, and how long it should remain available.
Missing links create predictable misreadings. Without an exposure event, low adoption can be confused with low visibility. Without version information, a regression cannot be tied to a system change. Without the downstream event, acceptance can be mistaken for value even when users later undo the AI’s work.
Choose the design and sample around the decision
- Randomization: Choose user, account, workflow, or time window based on where contamination can occur. If people in one account share outputs, user-level assignment may mix treatment and control experiences.
- Population: Define eligibility before launch. Balance or stratify meaningful groups such as new accounts and power users when their behavior or exposure differs.
- Primary metric: Select one outcome that can settle the main question. Treat diagnostic measures as supporting evidence, not a menu from which to pick a winner later.
- Guardrails: Monitor core experience, retention where relevant, time-to-value, safety, privacy, reliability, and cost. Write rollback conditions for unacceptable movement before exposure begins.
- Effect size and power: Set the minimum detectable effect from the business decision, estimate the required sample, and acknowledge when available traffic cannot support the desired conclusion.
- Exposure control: Use feature flags, a capped rollout, and a holdout so you can stop quickly and preserve a valid comparison.
Standard A/B testing fits many product changes. Ranking and retrieval changes can benefit from interleaving when alternatives can be compared within the same experience. Switchback designs can help when time, seasonality, or shared operating conditions make simultaneous assignment misleading. Match the design to the interference in the workflow instead of defaulting to the experiment template you use for deterministic UI changes.
AI variability also changes the readout. Aggregate outcomes across the multiple interactions users have, compare cohorts, and track confidence intervals over time. A snapshot p-value should not overrule an underpowered test, an unstable effect, or a concentrated safety failure. A statistically inconclusive result means the test did not resolve the decision; it does not prove that the feature has no effect.
Prewrite the scale, iterate, and stop rules
I prefer four explicit decision states because they force the readout to connect evidence to action:
- Scale: The primary outcome clears the meaningful threshold, guardrails hold, important cohorts do not show an unacceptable reversal, and reliability and cost remain viable.
- Iterate the AI system: User intent is strong, but a defined output or system failure blocks value. The next test should target that failure rather than repeat the same broad pilot.
- Change the product experience: Offline quality passes, but users cannot discover, trust, control, or efficiently use the capability. Treat this as workflow evidence, not an automatic reason to swap models.
- Stop or reframe: Demand is weak, the economics cannot work, the necessary data or access is unavailable, or credible risk remains outside tolerance.
Risk must be part of the launch rule, not a review added after a positive metric appears. Include toxicity and personally identifiable information checks where relevant, enforce least-privilege access, retain appropriate audit logs, and make rollback operational before exposure. For irreversible financial actions, sensitive regulatory decisions, or any workflow where the acceptable error rate is effectively zero, keep a qualified human approval step or defer autonomy. Faster execution does not compensate for an unacceptable blast radius.
Autonomy should be earned in stages. Begin with assistance that the user can inspect. Move to required approval before actions. Allow autonomous execution only for narrow, low-stakes, reversible actions after stability is demonstrated. Expand permissions and exposure only when monitoring shows that the earlier guardrails continue to hold.
The experiment does not end at launch. Model behavior, retrieval content, user mix, prompts, tools, and operating costs can change. Continue tracking quality, latency, cost per successful outcome, safety, and cohort behavior. Feed new failures into the evaluation set and keep a holdout when the decision warrants one. A weekly readout should identify what changed, which assumption the evidence affected, and what decision follows; it should not become a tour of every available dashboard.
Key takeaways
- Start with a precommitted decision contract: user, job, baseline, outcome, threshold, guardrails, and next action.
- Validate demand before usability, usability before system capability, and system capability before broad production impact.
- Compare the AI with the user’s current alternative, not with an abstract standard of impressive output.
- Measure output quality, system performance, user outcomes, and business consequences separately so failures remain diagnosable.
- Treat stochastic behavior as a distribution: document configurations, repeat runs, inspect slices, and watch severe outliers.
- Use feature flags, holdouts, exposure caps, auditability, and prewritten rollback rules to contain risk while learning.
At your next AI review, ask for the experiment contract instead of another demo. If the team cannot name the dominant risk, current baseline, meaningful threshold, guardrails, and action for each possible result, the next step is not production exposure. It is a sharper test.
Start with the smallest experiment that could credibly invalidate the idea. Evidence that survives that test earns the right to spend more, increase fidelity, and expose more users.
References
- Product School — AI Agents That Truly Help Product Teams: A Practical Framework for When—and When Not—to Use Them
- Product School — AI Experimentation Mastery: How I Test Faster, Tame Variability, and Ship with Confidence
- Product School — Pretotyping vs. Prototyping: How I Validate Ideas Fast and Build Products Customers Love