I’ve long believed a simple truth about AI in customer support: if AI is going to earn trust, pricing has to be aligned with value. That principle has guided my product decisions and the way I hold our teams accountable for measurable outcomes, not activity.
When we shared our perspective on pricing AI Agents in 2023, we made a simple argument: if AI is going to earn trust, pricing has to be aligned with value. At the time for Fin, that value was clear. You pay when the AI resolves a customer’s problem. If it doesn’t, you don’t. That’s fair, easy to understand, and grounded in results, not activity. We were the first to introduce this pricing model because we believed that pricing and value should be inherently linked.
That belief hasn’t changed, it’s grown stronger over time. What’s changed is what Fin can do. As we expanded capabilities and pushed deeper into complex workflows, it became clear that measuring value solely by end-to-end resolutions no longer captured the full picture of impact.
Resolutions were the right place to start. Historically, we measured value based on whether Fin fully resolved a conversation on its own. These are known as resolutions and they gave support teams a clear way to measure ROI, easily comparing the cost of AI versus human support. They also aligned our incentives with our customers, as our revenue was directly tied to Fin’s performance.
That clarity worked. Today, more than 7,000 teams use Fin. Our average resolution rate across customers has increased every month and now stands at 67%, even as Fin increasingly handles more complex queries. That progress came from building an Agent that could take on harder problems and still deliver.
But as Fin got more powerful, “success” stopped being binary. I saw this first-hand in customer design sessions where policy, risk, and compliance needs rightly demanded human-in-the-loop confirmation. We weren’t failing to deliver value; we were delivering it differently.
Over the last couple of years, we invested heavily to ensure Fin could handle the most complex parts of support. As Fin’s capabilities expanded, customers began pushing what Fin can do for them by deploying Fin deeper into their workflows to handle the toughest queries.
In some cases, this required Fin to work in tandem with a human agent because that’s what customer policies and oversight needs dictated. Subscription changes, transaction disputes, billing issues, and other multi-step support scenarios can often require Fin to gather context, read and write to external systems, and execute actions before handing off to a human agent for confirmation.
Fin is still doing what it was configured for – intentionally handing off after doing more of the heavy lifting, saving valuable time for support teams and overall time to serve for their customers. But our pricing metric only recognized value when the conversation ended in a full “AI resolution” (i.e. a human was never involved).
That’s why we’re evolving Fin’s pricing metric from resolutions to outcomes. This shift reflects how customers now define value: not just in full automation, but in safe, efficient progress toward the right result across complex, multi-step, and policy-constrained workflows.
An outcome represents when Fin successfully completes the action it was configured to perform, as part of a conversation. Resolutions are still one type of outcome Fin can deliver, where it handles the issue end-to-end. Another type of outcome can be a Procedure where Fin gathers context, takes action, and hands the conversation off when that’s what customers configured it to do.
Kick off your journey with the #1 Agent—an AI partner designed to turn resolutions into real outcomes. Tap “Start a free trial” to explore faster, smarter customer service and see how Fin delivers value from day one.
Increasing end-to-end AI resolutions is still a core component of scaling Agents, but they are no longer the only measure of Fin's success and utility. Especially as Fin takes on more complex work. Moving to outcomes recognizes that solving a customer problem with full automation isn’t always appropriate. It’s about getting to the right result, safely, and efficiently.
As Fin’s capabilities expand, teams should feel empowered to use it in more nuanced, collaborative work. Outcomes support that by allowing customers to design workflows that meet compliance requirements and include a human agent when necessary. From a product management standpoint, this is how we align incentives, keep risk controls intact, and still accelerate time-to-value.
Fin is becoming even more powerful at handling complex, multi-step support queries. With outcomes, we can support that growth without constantly reinventing how value is measured. And this change gives us a strong pricing foundation that can scale as Fin continues to grow and take on more roles beyond service. This aligns with our vision of Fin becoming a “Customer Agent,” capable of handling the entire customer experience.
What this means for pricing is intentionally straightforward. An outcome will be counted when Fin successfully completes an action it was configured to perform, as part of a conversation. That keeps the model predictable for finance leaders while staying transparent for operators and product teams managing AI workflows.
The pricing model stays simple and the definition of value becomes more accurate. In other words, we’re doubling down on fairness, predictability, and competitiveness—core tenets for any consumption SaaS pricing strategy tied to real business impact.
When we first wrote about outcome-based pricing, we said that trust is the currency of AI. That’s still true. Trust is earned when customers see pricing move in lockstep with utility and risk posture, especially as gen AI and agentic AI take on higher-stakes tasks.
Pricing has to feel fair, it has to be predictable, and it has to stay competitive. Evolving from resolutions to outcomes isn’t a departure from that belief. It’s the natural maturation of how we measure value as AI moves from simple Q&A into complex procedures and human-in-the-loop collaboration.
Fin has grown more powerful because customers asked more of it. Outcomes are how we reflect that progress honestly, while staying true to the same principles that guided us from the start. This is product strategy in action: align incentives, measure what matters, and scale what works.
And as Fin continues to get stronger, we’ll keep holding ourselves to the same standard: price based on the value delivered. That’s how we build durable trust, sustainable ROI, and a better customer experience at scale.
Every update we shipped this month removed a specific constraint on what teams can do with Fin. In my world, the demo-to-production gap shows up as complexity, control, and confidence. Can the agent handle the query that actually matters? Will it sound right on a call? Can the team deploy it without filing an engineering ticket? Can managers understand what it’s doing? That’s the bar I hold us to.
This month, we delivered answers to all four. Here’s how.
Procedures and Simulations (0:51). The hardest problem in AI-powered customer service isn’t answering FAQs—it’s executing complex queries with real business logic and real consequences if anything goes wrong. Think billing refunds, multi-step flows, and actions that must be right the first time.
We made it dramatically easier to build and manage Fin for those complex queries—without pulling in an engineer. You can author in natural language, test every step in simulation, and deploy with confidence.
The workflow starts with AI drafting the procedure from your existing source material. You edit in natural language, with structured hooks to pull in live data, apply business logic, and add code for deterministic control where you need it. That’s how you handle multi-step flows with the precision that matters when things go wrong.
Simulations are the test environment. Define a test case, pass in the data Fin would receive in a real conversation, and watch it work through each step. You see what Fin is doing, why, and whether it’s meeting the criteria you set. Full transparency at every point. I’ve run these end-to-end myself, and there’s a particular confidence that comes from watching it work before it goes anywhere near a customer.
A conversational moment from the February Fin Product Updates recap: two teammates trade insights with laptops open, while a bold pull-quote drives home the promise—Fin removes complexity to start selling and supporting in under two minutes.
For a deeper look at Procedures and Simulations, head to fin.ai/procedures.
Fin Voice: three major updates. When something’s off in chat, it can take a few exchanges to notice; on a call, it’s immediate. Pronunciation, noise handling, and tone all matter because they’re the customer’s first impression.
Pronunciation rules (4:18). Fin has high out-of-the-box pronunciation accuracy, but it doesn’t know your brand—your product names, your industry terminology, the way your company uses certain words. Alihan Zinna, Staff ML Scientist, showed this with an IKEA example: without pronunciation rules, Fin mispronounced both “IKEA” and a product name; after adding rules, both were corrected and sounded natural.
New natural voices (5:48). We’ve added 11 new voices tuned to a range of brand tones so you can choose one that sounds like it truly belongs to your company—not a generic AI assistant.
Background noise reduction (6:28). People call from airports, shops, and busy offices. Fin now monitors background noise continuously and increases noise reduction when the environment demands it. No configuration needed. As Alihan put it, “This is one of those things customers really notice when it’s not working. The goal was to make it invisible. That’s what we built.”
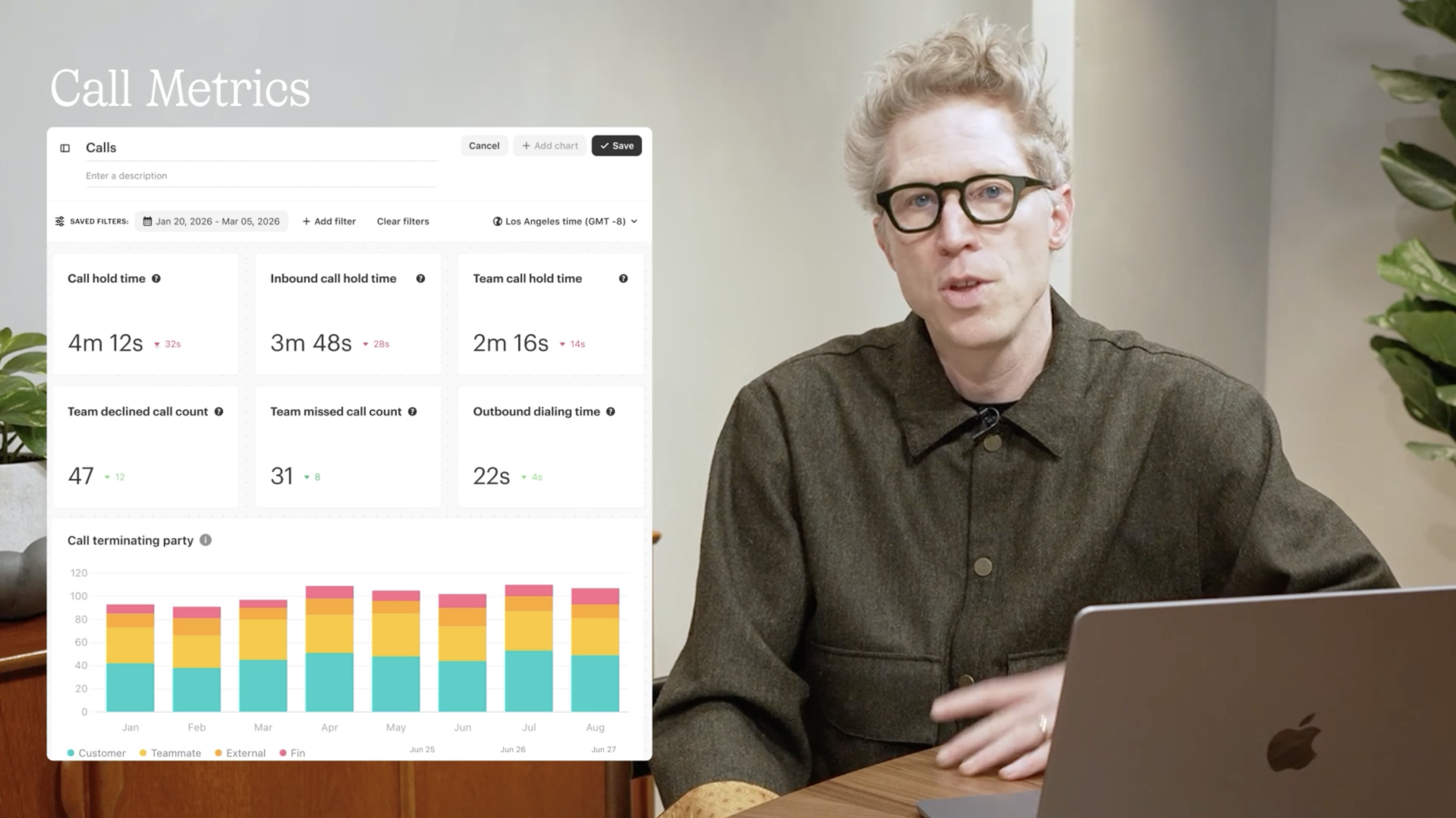
Catch up on February’s Fin Product Updates with a walkthrough of the Call Metrics dashboard—saved filters, hold‑time tiles, missed and declined call counts, and a monthly breakdown that helps support teams act faster.
Shopify setup experience (8:21). Fin began as a Service Agent and is quickly becoming a Customer Agent—working across the whole lifecycle to support, sell, and guide, even before a customer has an issue. The revamped Shopify setup is a clear step forward.
Shopify catalogs are complex—thousands of products, variants, and dynamic inventory—and connecting all of that to an agent has historically been painful. We removed the friction.
Setup now takes three steps: first, connect your store. Second, install the Messenger directly in Shopify—no code, just a few clicks. Third, deploy Fin. Total time: under two minutes. We timed it live.
What that unlocks is real. In the demo, a first-time snowboarder asked for recommendations. Fin searched the catalog, reasoned about attributes that matter to a beginner (there’s no “beginner” tag in the catalog), personalized suggestions by height and weight, and added a board to the cart.
Even better, one customer updated their website copy to promote a sale. Fin immediately picked up the new context and began recommending sale items, nudging shoppers to add more to the cart to access a discount—no extra configuration required. It read the situation and acted.
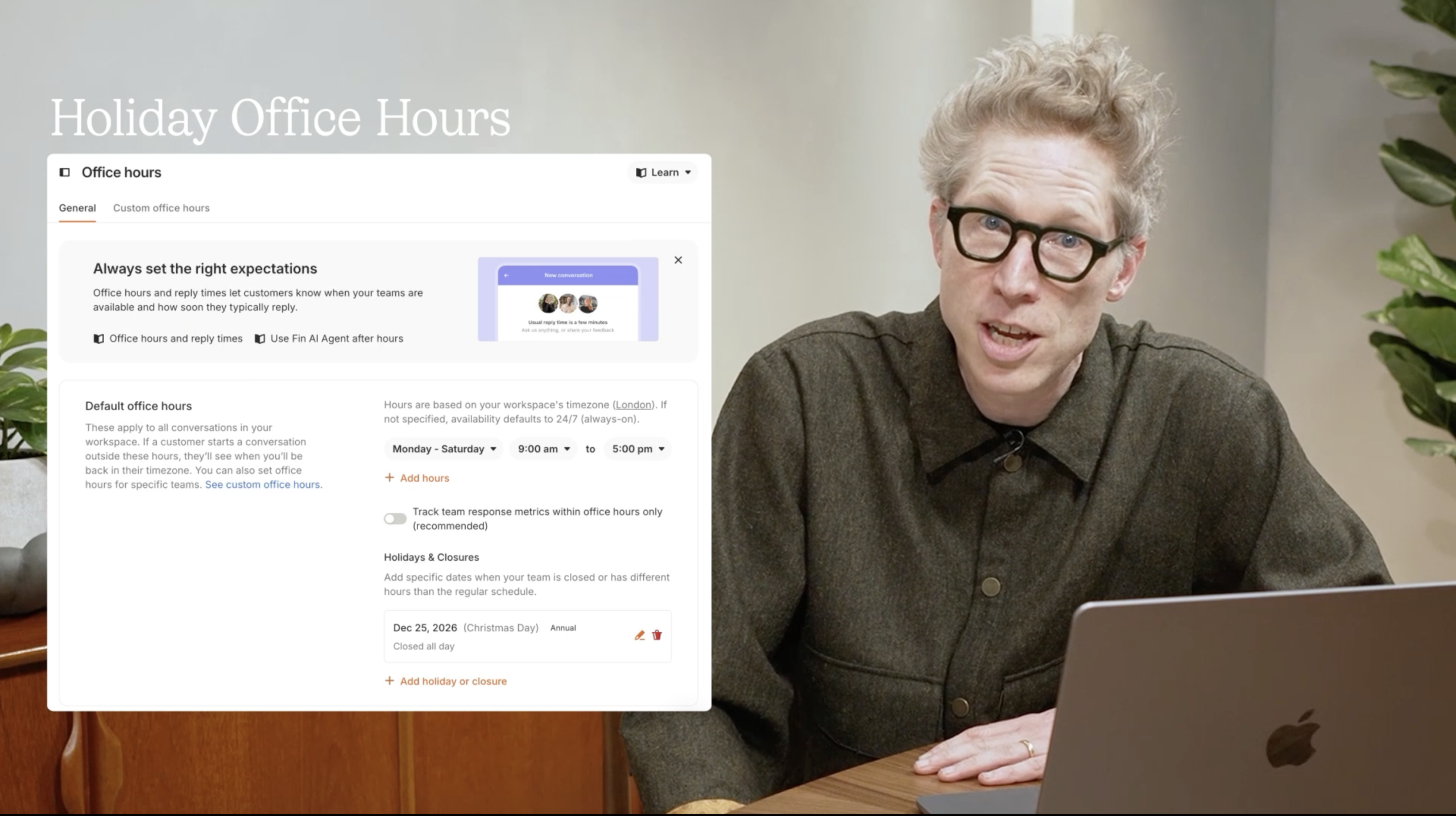
See how the latest Fin update streamlines support scheduling. A product expert walks through Holiday Office Hours, showing how to set default hours, track response metrics, and add closures so teams stay consistent.
Three steps, and you have a real-time shopping assistant that knows your store and sells on your behalf.
Helpdesk improvements (12:31). Fin works with any helpdesk, but many teams consolidate to take advantage of our native Intercom helpdesk integration. We’ve shipped 19 helpdesk improvements in 2026 so far; two from this month stand out.
11 new call metrics. Hold time, outbound dial time, missed and declined calls, call terminating party, and more. These give leaders the visibility to analyze workload distribution and call handling quality in detail.
Holiday office hours. Teams no longer need to manually update office hours for every public holiday. This was the most upvoted request in our community, and we shipped it.
Across the board, we removed the constraints that hold teams back: the complexity ceiling in automation, the quality ceiling in voice, the setup barrier in Shopify, and the operational overhead in the helpdesk.
We closed out the month with a Star Wars–style crawl of 22 additional updates. All features mentioned here are live and available now. Explore more at fin.ai/updates. More to come—see you next month.
Building a great end-to-end customer experience with AI means going beyond support, and I’ve seen firsthand how transformative that shift can be when we treat every interaction as part of one cohesive journey.
Every customer touchpoint, from the first sales conversation through to post-sales support and success, is an opportunity to get it right. Other teams are now turning to AI to transform how they show up for customers, and support, which led the way, has already written the blueprint. In my role, I focus on making that blueprint actionable across the entire lifecycle.
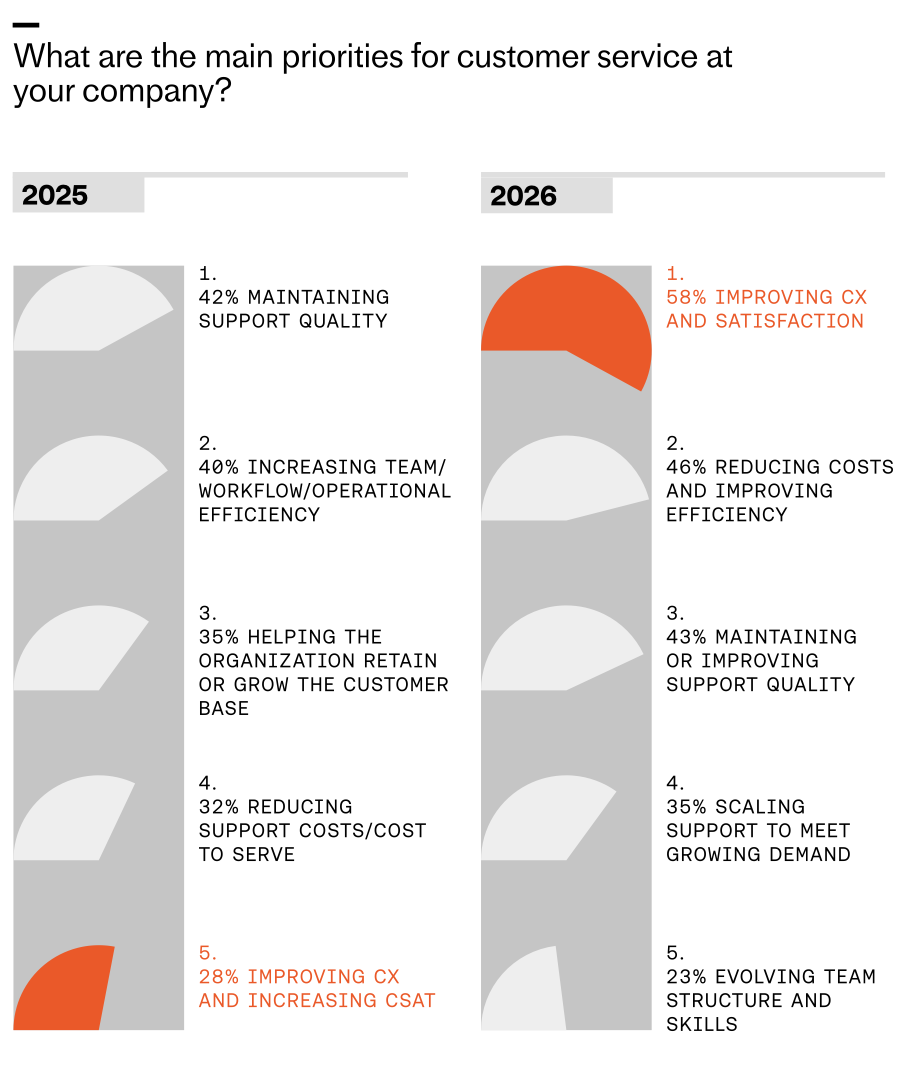
In The 2026 Customer Service Transformation Report, it’s clear most businesses are thinking about what’s next, with more than half planning to scale AI to other departments. Interestingly, they often cite their early success with AI in support as motivation for the move. This makes support teams uniquely positioned to help lead the transition, a strategic role unimaginable just two years ago.
In this piece, I share how teams are introducing AI to other parts of the business, how to think about this expansion effort, and the new opportunities it creates for support leaders who want to drive a unified customer experience.
Support was the first proving ground for AI, and our research suggests that businesses are now planning to expand its use to other areas based on the results it’s yielded so far. Fifty-two percent of respondents said that their organizations are actively planning to scale AI to other departments in 2026.
What will this look like? Leading companies are already finding out.
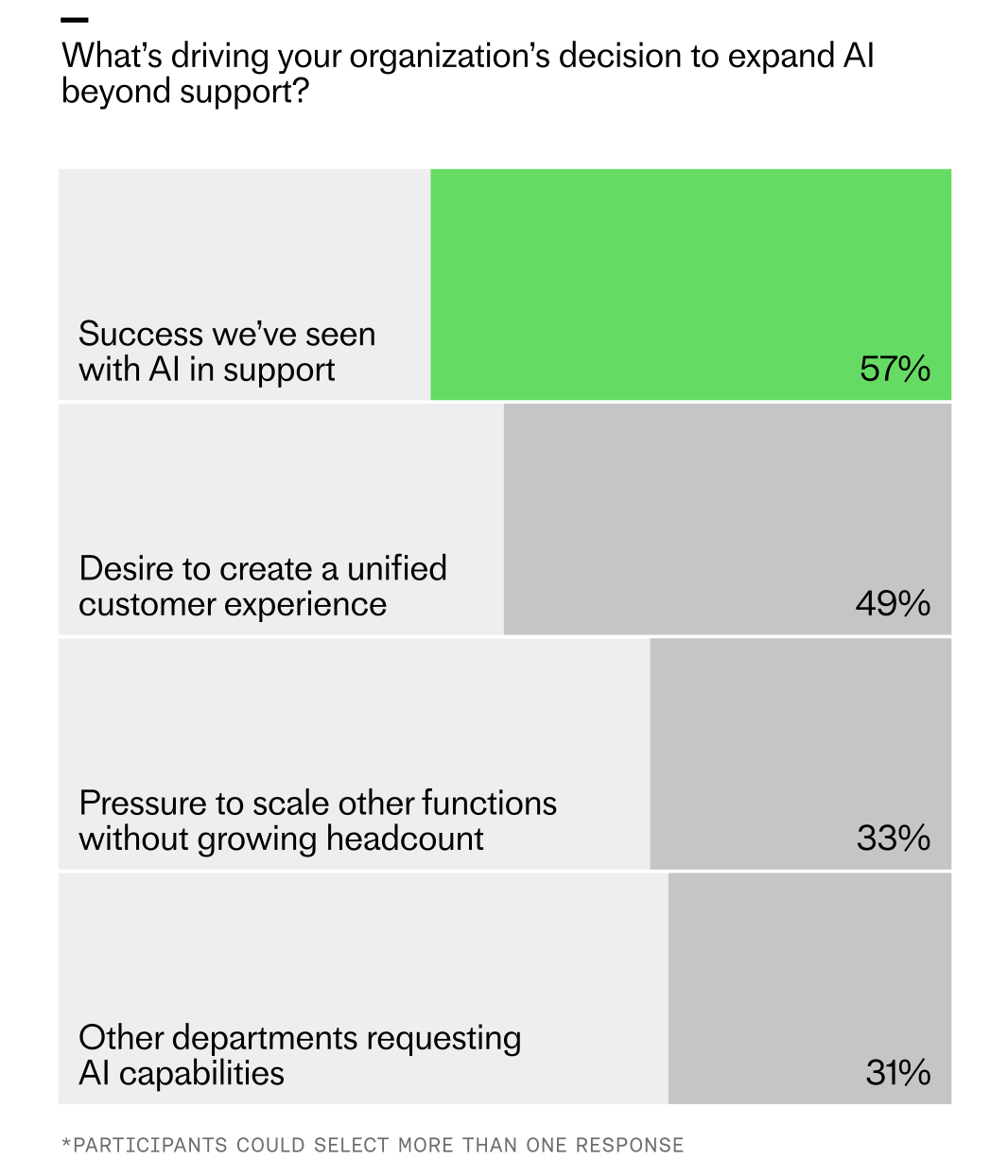
Wins in support are setting the pace for company-wide AI. Survey results rank the drivers: proven success in support (57%), the push for a unified customer experience (49%), scaling other functions without more headcount (33%), and cross-department demand (31%).
My favorite example is WHOOP, the fitness wearables company. They offer a premium product which makes their sales conversations more consultative than transactional. Customers want to know “Which membership is right for me?” or “How often do I need to charge my WHOOP?” According to Emily Shirley, Business Manager for Growth Product at WHOOP, if someone chatted with the inside sales team, they were twice as likely to convert, but they didn’t have enough reps to respond to incoming queries fast enough. Customers could wait more than 10 hours for a reply.
With a big product launch on the line and an anticipated spike in prospective customer conversations, their three-person team needed help. So they deployed Fin to the "Join" page, the final step before purchase.
With Fin resolving 84% of inbound questions, the sales team was able to focus on high-value leads. Together, they drove a 130% increase in attributable sales. The team is now exploring ways to expand Fin beyond FAQs, focusing on personalised conversation flows, multi-product recommendations, and richer data capture. As Emily says: “There are so many parts of the buyer journey where this applies. We’ve only scratched the surface.”
It’s clear there’s a desire to push AI to other parts of the customer lifecycle, but there is a risk hidden in this expansion. If sales, customer success, and other departments all launch their own Agent, each operating in isolation, you can end up fragmenting the very thing our research says teams want to create. The second-most cited reason for pushing AI beyond support: desire for a unified customer experience.
Without shared context, each handoff becomes a source of friction where customers could receive inconsistent answers or be asked to repeat information. I’ve watched even well-intentioned AI rollouts struggle here—great local wins, but an overall journey that feels disjointed.
A translucent UI visual maps a support-led AI blueprint that scales across the business—from SDR and sales to custom assistants—anchored by layers for goals, memory and user context, business knowledge, and interoperability.
The opportunity (and the challenge) is to keep the customer at the center. Instead of department-specific Agents that operate independently, we must strive for cohesion. That means shared memory, consistent governance, and connected AI workflows that respect the customer’s history and intent across channels.
This is the future I’m building toward: solutions like Fin becoming a “Customer Agent,” capable of handling the entire customer experience. This will mean Fin can function in many roles, supported by a memory that grows with the customer over time and deep knowledge of the business, creating a seamless experience for every interaction. In practice, that’s agentic AI designed to collaborate across teams, systems, and journeys—without losing context.
Pushing AI into new parts of the business requires someone to own the process. And for many organizations, that’s the support team. Nearly a third of respondents (32%) confirmed their customer service teams are leading their business' AI transformation strategy.
This presents a real opportunity for support teams to shape the future of customer experience. Instead of each function reinventing the wheel, support can act as a center of excellence, defining shared standards, guardrails, and operating practices that drive performance.
“You already manage the most complex, high-volume customer interactions; you have rich data on customer needs and behavior; and you know how Agents perform in the real world. Those insights will be invaluable as AI scales across your business.”
Leaders are racing ahead with real AI in support. Explore the 2026 Customer Service Transformation Report to see where deployment is stalling, benchmark your team, and get practical steps to scale automation that delights.
In my organization, when we extended AI from support into sales, we deliberately brought our conversation design expertise, Agent Analytics, and governance models along with it. One team owns the orchestration, memory strategy, and CRM integration so a customer can start with a sales question and end up with a support one—without ever feeling a seam. That continuity is where journey mapping meets product strategy and turns into measurable outcomes.
As Agents like Fin expand their capabilities and move into new areas, I expect many customer service leaders will see their roles expand to include AI implementation across the customer journey. It’s a natural progression for product management leadership in support: owning the experience, the data, and the operating model.
Achieving perfect customer experience is AI’s biggest promise. But in order to get there, teams need to be smart about the solutions they deploy. A unified Customer Agent capable of handling the entire journey end-to-end will have a significant advantage, delivering consistent, context-aware experiences across every interaction.
The Customer Agent future is being built right now, and it’s starting with the team pioneering AI transformation from the very beginning: support. For leaders in these organizations, this is a rare opportunity to shape how customer relationships will be built and maintained in the AI era.
If you’d like to dig deeper into the data and benchmarks guiding these decisions, download The 2026 Customer Service Transformation Report.
"What if an AI could spot the moment two product teams start pulling in opposite directions — before it derails a quarter?" That question hooked me, because I’ve lived through the costly fallout of subtle misalignments that only surface at the end of a sprint—or worse, during quarterly business reviews.
I recently dug into an episode of Just Now Possible featuring Matthias and Charlotte Kleverud, co-founders of Momental. Their vision for "GitHub for product management" hits a nerve in the best possible way: find "merge conflicts" in strategy, not code, and do it early enough to save execution time, trust, and outcomes.
Here’s the core: Momental ingests documents, meeting transcripts, and voice recordings across an organization, then uses AI agents to map them into a structured context layer—a set of interconnected trees covering goals, decisions, learnings, and who's doing what. When it finds a conflict—say, one team betting on retention while another is prioritizing conversion—it surfaces the misalignment for humans to resolve, just like a merge conflict in code. That framing is both familiar (for anyone who’s shipped software) and powerful (for anyone who’s scaled product strategy across multiple teams).
Their journey tracks with what many of us have learned the hard way. "Starting in 2022 with DaVinci 002 and learning that the market wasn't ready for AI-assisted product thinking" pushed them toward experiments with agent teams. "The origin story: building a team of AI agents in 2024, only to discover agents hit the same alignment problems as humans" is exactly the kind of meta-lesson I’d expect when you scale autonomy without shared context. The breakthrough was an "OODA-loop-driven document processing agent" that continuously curates a living knowledge graph rather than relying on static prompts or brittle pipelines.
One model that stood out was "The product chain: signals → learnings → decisions → principles, and how AI maps it." That is the backbone of healthy product thinking. When this chain is explicit and inspectable, you can trace why a team chose Path A over Path B—and detect when new signals should invalidate old decisions. I’ve seen this accelerate continuous discovery and improve executive decision hygiene.
I also appreciated the organizational modeling: "Three trees that model an organization: the product tree (OKRs to epics), the wisdom tree (decisions and their reasoning), and the people/time tree." This maps cleanly to how we run quarterly planning at scale—tying outcomes to work, preserving rationale, and grounding ownership and timelines. With that structure, "How conflicts are detected, auto-resolved, or escalated to humans with merge options" becomes a pragmatic workflow, not a theoretical AI demo.
On the technical front, they’re blunt about limits: "Why traditional chunking and RAG breaks down at scale and what Momental does instead." Anyone who’s tried to stitch strategy from ad hoc notes knows that naive retrieval won’t cut it. You need durable context boundaries, rich metadata, and graph-aware reasoning. Which brings me to one of my non-negotiables: "Why metadata—who said it, when, and in what context—is critical to preventing hallucinations." In my world, we treat provenance like test coverage—you can’t ship without it.
Process-wise, the product philosophy resonated: "How a document processing agent uses OODA-loop thinking to extract and connect context across documents" reinforces the need for short feedback cycles, explicit hypotheses, and continuous refactoring of knowledge. Pair that with "The self-improving agent: collecting user feedback weekly and rewriting its own prompts" and you’ve got a blueprint for eval-driven development that keeps the system honest over time.
Their UI choices also mirror a pattern I’ve adopted: "Moving from chat-first to UI-first to proactive agents as an AI product design pattern." Chat can feel magical, but alignment work benefits from concrete artifacts—trees, timelines, driver trees, and opportunity solution trees—so people can reason together. Then, let proactive agents watch for drift and nudge teams before the cost of change spikes.
Two broader themes are worth calling out. First, "Specialized tools win" when the problem is deep, cross-functional context like product strategy. General-purpose chatbots struggle here; domain-specific models with strong information architecture have the edge. Second, product culture matters: "Discovery Versus Vibe Coding" is not just a catchy contrast—it’s a reminder that disciplined discovery beats intuition theater when stakes are high.
As for the roadmap, I’m encouraged by their "Design partner strategy and what's next for Momental's public launch." Early design partners are where you validate signal quality, precision of conflict detection, and the ergonomics of human-in-the-loop resolution. I’m especially curious how this intersects with LLMs for product managers, outcomes vs output OKRs, and product roadmapping and sprint planning in large portfolios.
Finally, a nod to the broader ecosystem. The conversation touched on "Claude Code" and a shift "Beyond documents and vectors" that many of us are living through—toward retrieval-first pipelines that respect context windows, stronger governance, and measurable improvements in decision quality. If you care about AI Strategy for empowered product teams, this is a space to watch—and to pilot.
Bottom line: If you’ve ever wished you could prevent strategy drift before it shows up in your dashboards, this "GitHub for product management" approach is worth your attention. Make the chain of signals, learnings, decisions, and principles explicit. Keep humans in the loop for the hard calls. And let proactive, agentic AI do what it does best: flag misalignments early, so your teams can move fast together.
I’ve been looking for a pragmatic way to put product analytics where my teams already work—inside Slack and Microsoft Teams. The moment insights are one message away, cycle time shrinks, debates get crisper, and experiments move faster. That’s why I’m bringing Amplitude Global Agent into our daily decision flow to deliver instant, source-backed answers with visual clarity and actionable next steps.
Connect Amplitude Global Agent to Slack or Microsoft Teams to answer questions with source-backed analytics, charts, and recommended actions like A/B tests.
What excites me most is the shift from dashboards to dialogue. Instead of digging through reports, I can ask a focused question in Slack—“How did activation change week-over-week for our self-serve cohort?”—and get a chart in-channel, complete with recommendations that point me toward the next best move. This is Agent Analytics done right: faster insight loops, reduced context switching, and more confidence in the decisions we make every day.
From a product management perspective, this integration strengthens continuous discovery and aligns product trios around the same truth. Engineers, designers, and PMs see the same chart, discuss trade-offs in the same thread, and can agree on an action—often an A/B test—within minutes. It’s a lightweight but powerful way to support product-led growth and keep our roadmap tied to measurable outcomes.
In practice, the questions I ask the most look like this: “Which onboarding step causes the biggest drop-off this month?”, “Which channels drive the highest L28 activation rate?”, and “Where did retention improve after our pricing change?” In each case, the Agent returns charts we can share instantly with stakeholders, plus recommended actions like A/B test ideas to validate hypotheses quickly. The result is a reliable rhythm: ask, see, align, act.
Governance matters just as much as speed. We’re configuring strict permissions, role-based access, and purposeful channel placement so analytics land where they should—no broader, no narrower. We’re also leaning into clear query prompts and naming conventions for events and properties to help the Agent retrieve precisely what’s needed, every time. The aim is a high-signal, low-noise system that maintains trust while accelerating decisions.
To embed this into our operating cadence, I plug the Agent into three moments: daily standups (to scan activation, conversion, and incidents), weekly product reviews (to align on experiment status and next bets), and executive QBR prep (to pull clean, shareable charts fast). Because the insights arrive in Slack or Microsoft Teams, our conversations stay focused and traceable, and decisions get documented in the same place they were discussed.
We’ll measure impact with simple, telltale indicators: fewer ad-hoc analytics requests, faster time from question to decision, increased A/B test velocity, and clearer links between recommended actions and outcome metrics like activation and retention. My bar is straightforward—if this Agent can help one team make a better decision per day, it will more than pay for itself across the org.
If you’re considering a similar move, start small: connect one high-signal channel, curate a handful of common queries, and coach your team on good prompts. Within a week, you’ll feel the difference. When analytics become conversational, momentum follows—and your product strategy benefits from sharper, faster, and more transparent decision-making.
Inspired by this post on Amplitude – Best Practices.
Shipping agentic AI into production is exhilarating—until a flaky output torpedoes trust. Over the past year, I’ve led teams at HighLevel to operationalize agents across customer-facing and internal workflows, and I’ve learned that reliability isn’t an afterthought; it’s an architecture. In this piece, I share the AI Agent Orchestration Patterns for Reliable Products that consistently deliver dependable outcomes at scale.
When we talk about orchestration, we’re talking about more than a single prompt. The shift is from monolithic calls to coordinated “agentic AI” where routers, planners, and specialists collaborate through structured “AI workflows.” In practice, I rely on a few canonical patterns: a planner–executor loop for multi-step tasks, a router–specialist setup for skill selection, and a “retrieval-first pipeline” that grounds generation with authoritative context before a single token is produced.
Reliability-by-design starts with typed inputs/outputs and strict validation. I standardize on JSON schemas, enforce tool/function signatures, and implement idempotency keys so retries don’t wreak havoc on downstream systems. Timeouts, circuit breakers, and backpressure protect the platform under load, while rate limiting and dead-letter queues keep failure modes contained. Most importantly, we engineer graceful degradation: agents “abstain” when uncertain, fall back to deterministic paths, and escalate to humans instead of guessing.
Safety is a first-class concern, not a bolt-on. Our “AI risk management” pipeline includes PII redaction, allow/deny lists for tools and data, and the principle of least privilege for every connector (yes, even the ChatGPT connector). We codify policy-as-code for repeatability and require human-in-the-loop approvals for sensitive or irreversible actions. In my experience, clear red lines and reversible defaults prevent the vast majority of regrettable outcomes.
Without strong “observability,” you’re flying blind. I instrument agents with an “Agent Analytics” layer that captures traces, spans, tool invocations, and token usage across the entire chain. The essential metrics are outcome quality (task success rate), latency (p50/p95), tool failure rates, cost per task, and user-level satisfaction signals. Cross-agent lineage allows us to pinpoint where a plan went awry and which tool or prompt introduced drift—vital for rapid remediation.
Quality improves fastest when it is measured relentlessly. I practice “eval-driven development” with golden datasets, rubric-based scoring, and risk-weighted sampling of edge cases. LLM-as-judge can help, but we always calibrate against human ratings and monitor agreement. In production, I blend online metrics with controlled “A/B testing” and plan experiments to hit a realistic minimum detectable effect (MDE). The result is a virtuous loop where prompt tweaks, tool changes, and retrieval adjustments are verified before wide rollout.
Agents need the same rigor we expect from any modern system. I gate releases through “CI/CD” with linting for prompts, schema checks for tools, and simulation runs for critical paths. “Feature flags” enable shadow and canary deployments so we can throttle exposure by segment or workflow. I also track reliability with “DORA metrics” and “deployment frequency,” and I partner closely with “SRE” for on-call coverage, runbooks, and incident postmortems tailored to agent failure modes.
Context is a resource to allocate, not a bottomless pit. Thoughtful “context window management” means curating retrieval, summarizing long-running threads, setting memory time-to-live, and constraining what the agent can see at any given step. I bias hard toward retrieval over recall, keep chunks small and semantically precise, and validate that the “retrieval-first pipeline” truly returns the right evidence—not just the nearest match.
In day-to-day product work, I lean on a compact playbook: a router that selects the best specialist; a planner that decomposes tasks and allocates tools; a deterministic guard that verifies preconditions; an execution loop with explicit budgets; and a fallback policy that prefers abstaining over hallucinating. Together, these patterns create an agent that behaves like a dependable teammate rather than a creative wildcard.
No architecture thrives without the right rituals. Product trios keep discovery continuous, while clear outcomes (not output) align teams on value instead of vanity. We map risks early, maintain a public quality dashboard, and rehearse failure recoveries so incidents never become improvisations. The cultural signal is simple: we celebrate root-cause clarity and safe iteration over heroics.
If you’re just starting, implement three patterns first: retrieval before generation, abstain-and-escalate for low confidence, and canary releases under feature flags. Instrument everything from day one, run a weekly eval review, and expand scope only when the data says you’re ready. With these habits, your agents will earn user trust—and keep it.
To truly transform with AI, I’ve learned it’s never just about the technology—it’s about redesigning how we work. The teams that win don’t bolt AI on; they re-architect around it. That means rethinking roles, workflows, and governance to build a system that sustains and improves AI performance over time.
In The 2026 Customer Service Transformation Report, teams at every stage of maturity describe human agents taking on more proactive work—training AI systems, handling the hardest queries, and owning tasks that demand judgment. Job descriptions are shifting, too, with many organizations explicitly adding AI-related responsibilities.
I’m also seeing a clear rise in dedicated AI specialists. Conversation analysts, knowledge managers, and AI operations leads are fast becoming standard. For support professionals, this opens new, higher-leverage career paths—and creates a talent pipeline that blends service excellence, data fluency, and product thinking.
Support once centered on queue-level activity—ticket triage, routing, translations, and answering FAQs. Now, as AI handles more frontline interactions, our human roles are moving up the stack toward optimization, oversight, and continuous improvement.
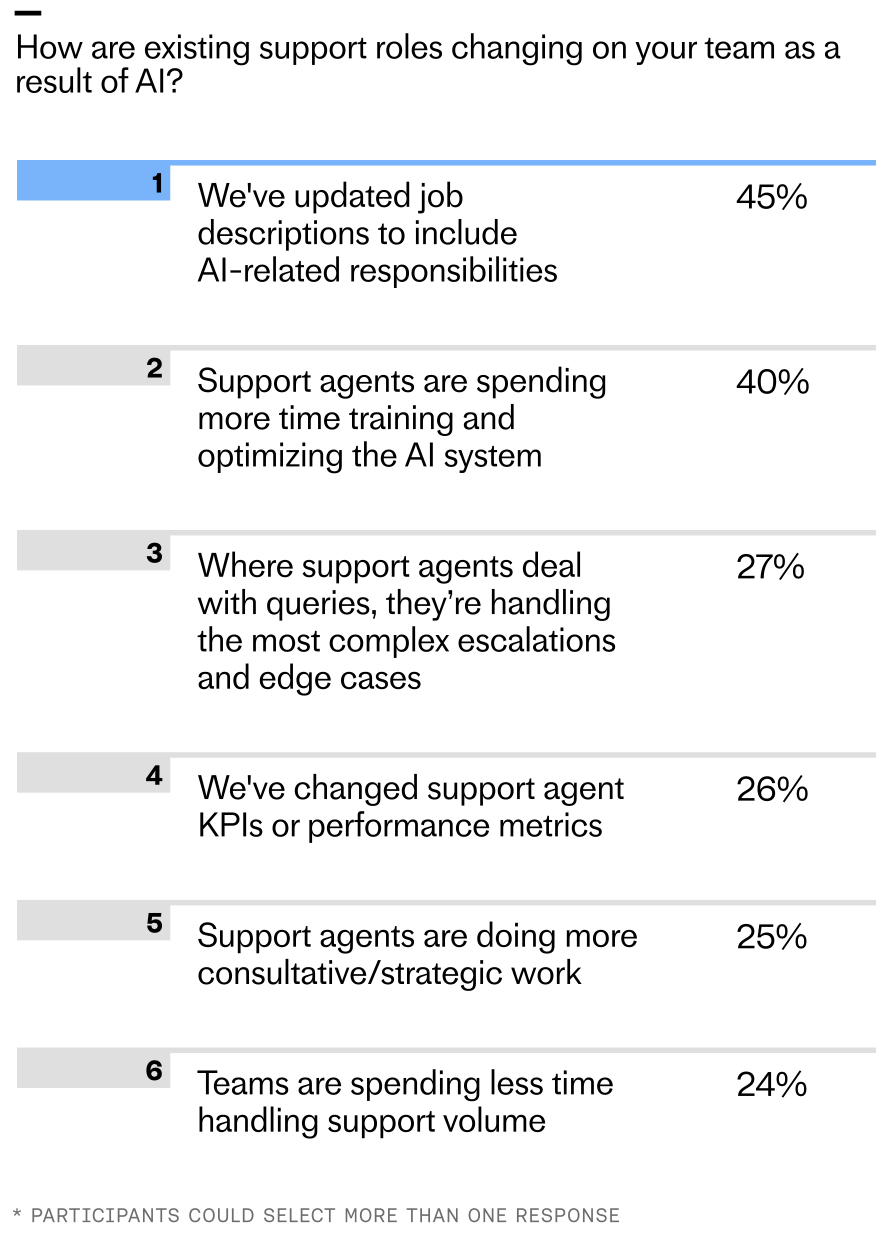
According to the latest research, 45% of teams report updating job descriptions to include AI-related responsibilities, with 40% saying their human agents are now more focused on training AI systems. Another 27% report that human agents primarily handle the most complex escalations and edge cases, while a quarter say agents are doing more consultative and strategic work.
Even at the initial deployment stage, 16% of teams report spending less time handling support volume since implementing AI – and among teams who’ve reached maturity, that figure rises to 28%.
When Intercom’s Research, Analytics & Data Science (RAD) team interviewed 166 of our customers, similar themes emerged. Nearly all participants (≈95%) reported meaningful workflow changes, with manual processes being handled by AI, and humans focusing more on monitoring or fine-tuning AI outputs. Eighty-three percent of participants also reported seeing their team’s roles and responsibilities change to become more strategic and supervisory in nature.
AI is reshaping support teams: organizations are adding conversation analysts (32%), knowledge managers (30%), AI operations leads (28%), and support automation specialists (24%). Just 8% report no new AI roles.
It’s not just the work that’s evolving; organizational structures are, too. Some teams are reallocating existing talent into AI-focused roles; others are hiring entirely new skill sets. Many of the most common job titles in this space didn’t exist two years ago.
Consider a Senior AI Knowledge Manager, Beth-Ann Sher, who transitioned from a help center manager role. Like many careers transformed by AI, her work evolved from administrative to strategic. Instead of focusing solely on customer-facing, self-serve content, her mandate expanded to designing and optimizing knowledge inputs that directly improve AI Agent Fin’s performance—work that materially lifts resolution rates.
Or look at a Senior Conversation Designer, Fred Walton, hired specifically for an AI-first function. He focuses on frictionless customer journeys with Fin, smoothing handoffs between automation and human support while keeping customer satisfaction front and center—hallmarks of mature AI workflows and conversation design.
In high-performing organizations, roles like these typically sit within a dedicated AI support team under senior CS leadership. Clear ownership and accountability for AI performance is critical; without it, optimization stalls and trust erodes.
These shifts aren’t isolated. Take Robb Clarke from RB2B. He went from Head of Technical Operations to Head of AI. With Fin, his focus moved from repetitive support questions to managing knowledge and improving the system behind it—freeing him to be proactive about product improvements and fix issues before they hit customers.
Or consider Eric Broulette from Bloomerang, a support leader who leaned into AI and became the VP of Support and Education. By deploying Fin, his team found breathing room to invest in what’s next. Agents stepped into new roles, contributed to meaningful projects, and built skills that had previously felt out of reach. As Eric puts it: “Do not wait to embrace AI. It will unlock more career growth for your teams than you can imagine.”
Leaders are racing ahead with real AI in support. Explore the 2026 Customer Service Transformation Report to see where deployment is stalling, benchmark your team, and get practical steps to scale automation that delights.
Bringing AI into support will eventually change every agent’s day-to-day work. For leaders at the start of the journey, that can feel daunting. My perspective: the most successful teams treat this as an operating model shift, not a tooling rollout—anchored in AI Strategy, governance, and continuous improvement.
Be transparent about what’s changing, why it matters, and how success will be measured. Define how AI performance will be evaluated (resolution rate, containment, CSAT impact), empower agents to train and improve the system, and communicate how responsibilities will evolve. When teams help build the AI, they’re invested in making it great.
Here’s the playbook I rely on with support leaders: First, reset expectations about time allocation—less time in the queue, more time improving the AI system that serves the queue. Second, elevate knowledge management as a core capability. Prioritize content quality and coverage for your AI Agent, and carve out dedicated “out of the inbox” time so every agent contributes. Third, keep outcome metrics—especially resolution rate—front and center. It gives the team a north star for experimentation and iteration.
Scaling AI is as much a people challenge as it is a technology challenge. As automation takes on more work, support roles become more proactive, strategic, and cross-functional—even early in the journey. Responsibilities expand, new roles emerge, and team structures adapt to concentrate on and amplify AI performance. In the process, support careers are transformed.
If you’re leading this shift, now’s the moment to reimagine your operating model: clarify ownership, invest in knowledge and conversation design, adopt eval-driven development, and build the muscle for continuous improvement. That’s how you move from tickets to strategy—and unlock compounding value for your customers, your business, and your teams.
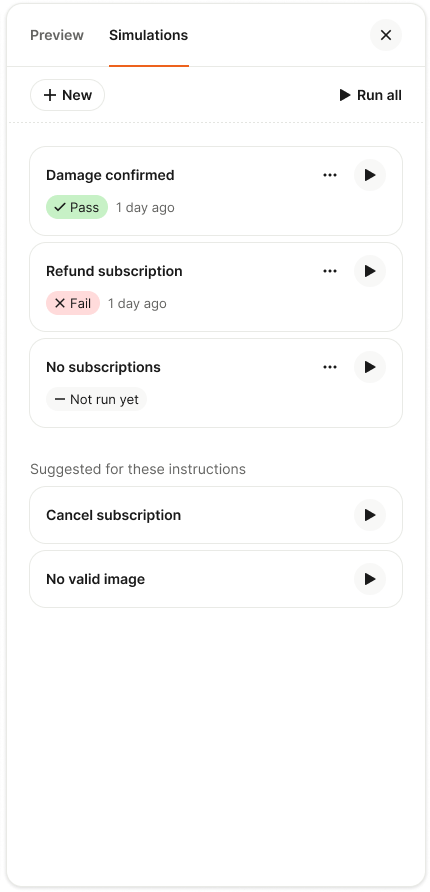
Today, I’m excited to share 12 major updates to Fin’s Procedures and Simulations—the foundation that lets Fin handle complex work while keeping teams fully in control of the customer experience.
In my work building AI workflows with product and support leaders, I’ve seen how the right blend of natural language instructions, deterministic controls, and fully agentic behavior turns Fin into a reliable problem solver. Procedures make this blend possible by enabling Fin to act like a human—yet with the repeatability and governance of software. Simulations then let us test those complex Procedures at scale before they reach customers, so we can deploy with confidence.
Together, these capabilities make Fin self-manageable, transparent, and ready for genuinely complex work.
Here’s what’s new at a glance: we’ve made Procedures easier to build and maintain; enhanced deterministic controls for precision and policy compliance; expanded agentic behavior so Fin can adapt in real time; and delivered more powerful Simulations to validate end-to-end workflows before go-live.
Why did we build this? Many teams see early AI gains in speed, coverage, and cost to serve—but then hit a ceiling. They keep AI confined to simple automation and information retrieval, rather than setting it up to handle the nuanced, multi-step workflows they still trust to humans. We designed Procedures and Simulations to remove that ceiling, so teams can confidently set up, govern, and iterate on complex AI workflows without bottlenecks.
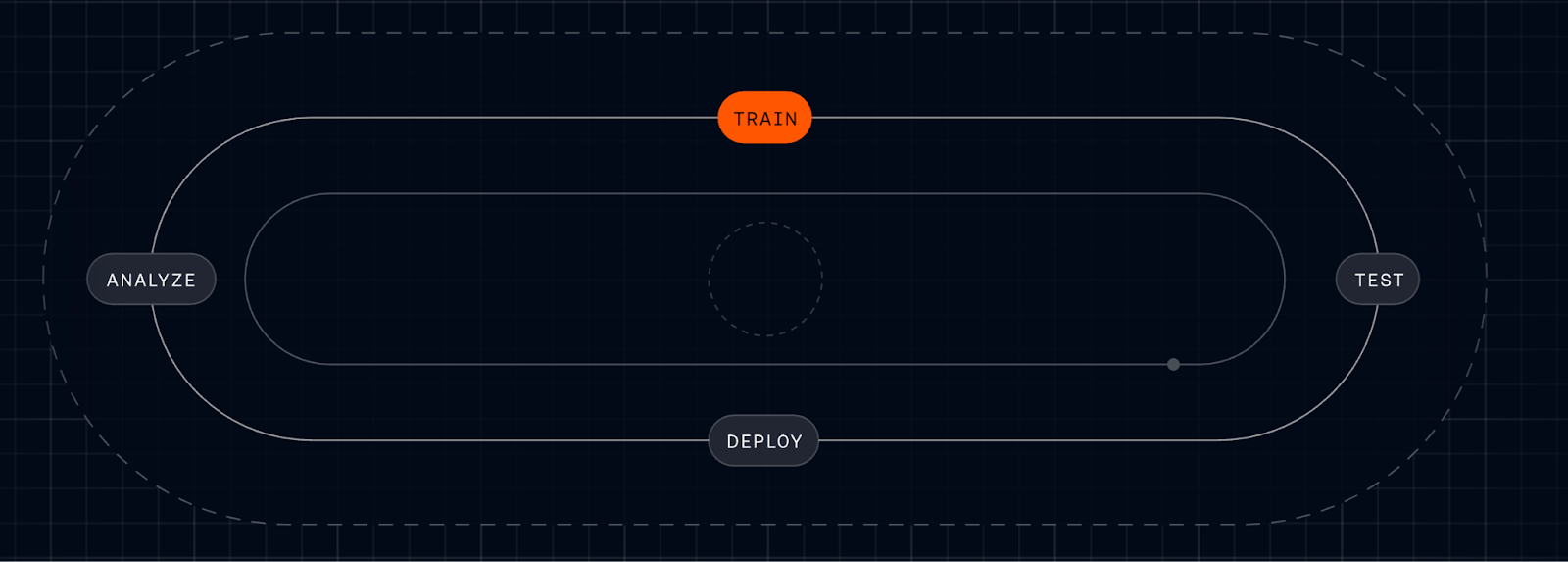
Follow the AI lifecycle as it cycles from Analyze to Train to Test to Deploy. This streamlined loop spotlights the TRAIN phase, underscoring faster iteration and feedback that power more capable procedures and realistic simulations.
We also heard that teams needed an easy way to connect data so Fin could reliably check customer status or eligibility and then take action. And they didn’t want to route through engineering every time they needed to create or amend logic for mid-conversation decisions. Procedures combines natural language instructions and intuitive data connector setups. You tell Fin in your own words how you want it to behave, and you’ll be guided through creating conditional steps so Fin will react consistently, with the option to add in any code snippets for circumstances where absolute precision is required. Once you build one Procedure, we believe you’ll want to build several, so Fin will constantly read the conversation it’s in to ensure it’s following the most relevant Procedure, and jump to a more relevant one if the user intent changes.
I know that taking something like this live the first time can feel like a leap of faith. That’s exactly why we built Simulations—to test Procedures comprehensively, uncover edge cases, and launch with confidence.
Reaching mature deployment takes a deliberate, ongoing commitment to training workflows, validating them before deployment, measuring performance in production, and refining them over time. At Intercom, we call this the Fin Flywheel: train, test, deploy, analyze. Procedures form the foundation of the train stage, and Simulations make the test stage reliable at scale. Together, they enable Fin to handle complex work, and teams to stay in control of it.
Procedures: Define exactly how Fin handles complex work. With Procedures, I can set Fin up to resolve complex, time-consuming queries that require multiple steps or business logic. Fin follows standard operating procedures and applies sound judgment—just like a seasoned teammate—so even complicated queries are resolved in controllable, predictable ways.
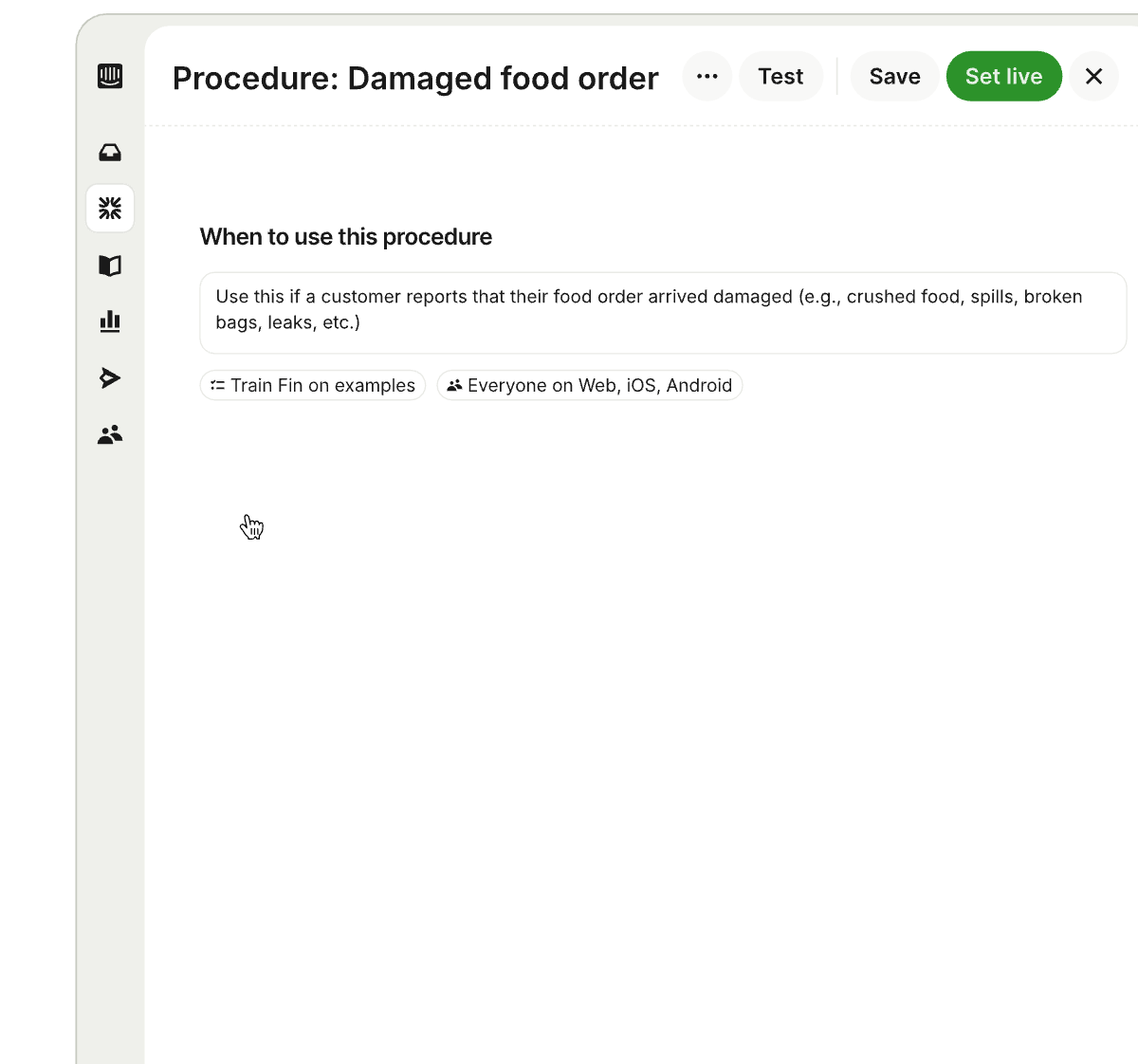
A snapshot of the Procedures builder in action, mapping a clear path for handling damaged food orders while letting teams train Fin on examples, target channels, quickly test updates, and publish with Set live.
Procedures combine three powerful elements. First, natural language instructions. You write a Procedure in plain language, just like documenting a process for a new teammate. You can paste in your existing SOPs, write from scratch, or let AI draft them for you, then iterate yourself.
What’s new: Draft Procedures with AI. Share an outline of your process and Fin drafts a complete Procedure using your conversation history, knowledge hub content, and relevant data. If additional context is needed, it prompts you with clarifying questions to make sure the Procedure is thorough and tailored to your use case, significantly reducing setup time. For example: if you’re creating a refund workflow, the system can draft conditional paths for eligibility, approval thresholds, and verification steps based on your historical cases and policies.
What’s new: Break complex workflows into Sub-procedures. Write a process once and reference it across multiple Procedures by breaking it down into reusable steps, called Sub-procedures. This makes workflows easier to read, faster to build, and simpler to maintain as things change.
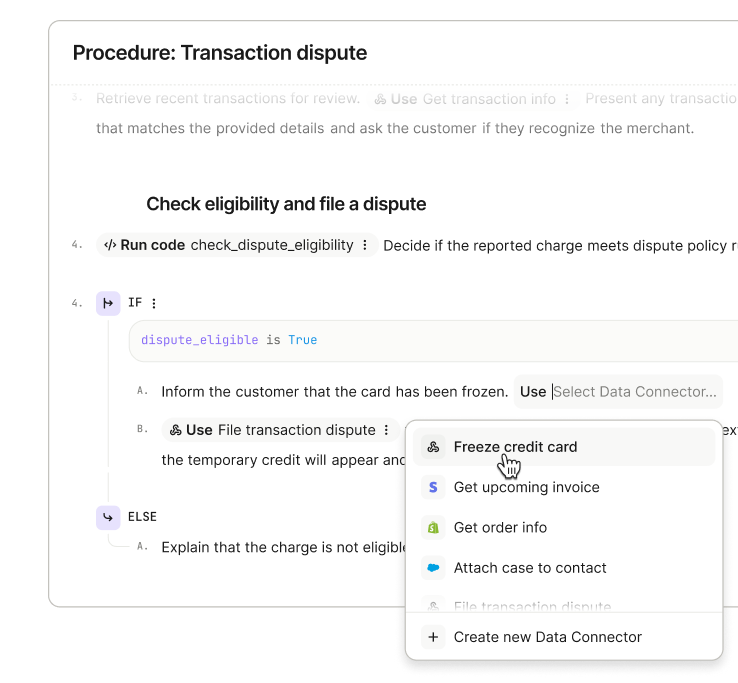
Second, deterministic controls. Natural language is flexible, but some steps need to be exact. You can layer in deterministic controls where precision matters, starting with a fully natural language Procedure and introducing structure gradually where it adds value: conditional steps (branching logic) to handle decision points so Fin’s behavior is consistent and predictable; data connectors so Fin can pull information from your tools or take actions automatically; code snippets for when absolute accuracy is essential; and checkpoints to pause for approval or hand off to a teammate.
Fin demonstrates structured troubleshooting: a transaction dispute flow with eligibility checks, clear IF/ELSE steps, and quick Data Connector actions like freezing a card or pulling invoices, streamlining complex support tasks.
What’s new: Instruct Fin to read specific content from your knowledge hub. You can set clear rules for Fin to reference a specific policy or article from your knowledge hub in defined situations so Fin always surfaces the right context in a conversation.
What’s new: Explicit Procedure switching under defined conditions. You can set rules that deterministically trigger a switch to a different Procedure, for example, escalating to a complaints Procedure if specific risk signals are detected mid-conversation.
What’s new: Internal notes for human handoffs. When Fin hands off to a teammate, it can now include internal notes with relevant context so the person picking up the conversation knows exactly what happened and what needs to happen next.
Third, fully agentic behavior. Because real conversations rarely follow the happy path, Procedures let Fin reason through what’s happening and adapt—jumping to the right step or switching Procedures entirely if a customer changes their mind or the issue shifts.
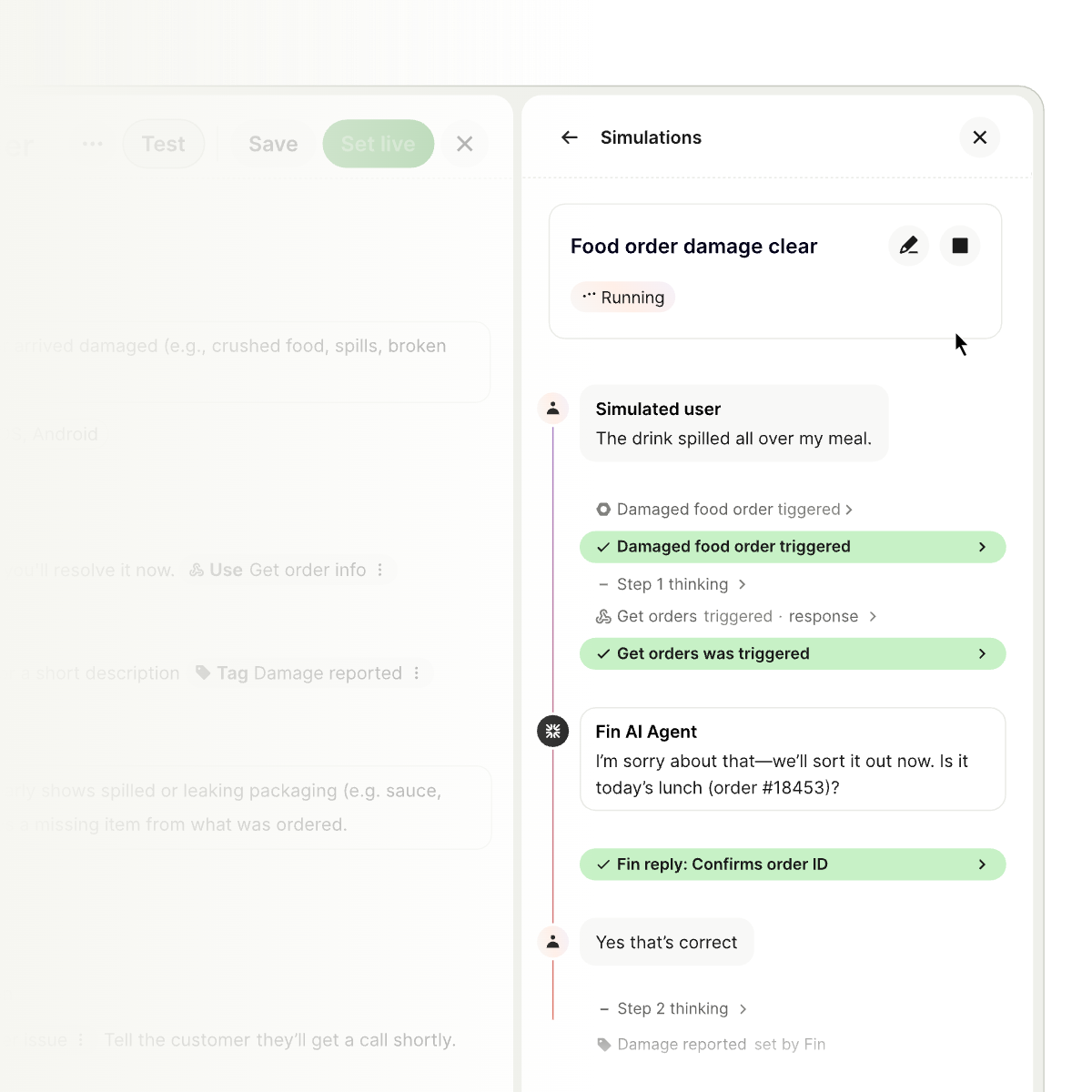
Procedures and Simulations in action: Fin rehearses a food order damage scenario, confirming details and progressing through each trigger. Teams validate complex flows end to end as steps turn green and outcomes are tracked.
What’s new: Automatic Procedure switching. If a customer starts in a billing workflow but then asks about cancelling their subscription, Fin transitions to the relevant Procedure without forcing the customer to restart.
What’s new: Structured data extraction from uploaded files. Fin can now extract structured data directly from PDFs and images uploaded by customers—like invoices, forms, or receipts—and use that data within the conversation. Customers don’t have to copy and paste or repeat themselves.
As MONY Group put it:
“ If a customer starts down one path but their issue turns out to be something else entirely, Fin adapts seamlessly – no more getting stuck in loops or forcing customers into the wrong workflow. ”
Simulations help teams rehearse procedures and verify outcomes before going live. Run all tests or launch a new one to ensure Fin handles tricky customer scenarios—from damage confirmation to refunds and missing subscriptions.
The result is a conversation that feels fluid, but always follows your intended rules.
Making complexity easier to manage is just as important as unlocking new capabilities. Beyond the core updates, we’ve focused on creation, governance, and scale—while keeping ownership with your team.
What’s new: Improved instruction authoring. We’ve made it easier to write, edit, and structure Procedures, so building and updating them takes less time and requires less effort.
What’s new: Reporting on when Procedures trigger, resolve, or hand off. You can now track how Procedures are performing directly within the Procedures UI, seeing exactly when they trigger, when they resolve, and when they hand off to a teammate. This visibility helps you spot issues early and improve over time.
Customer stories from Raylo and Mony Group show how Fin now resolves payment issues and complex claims in-chat, checks account data via APIs, and lifts CSAT to about 94%, highlighting the impact of Procedures and Simulations.
Simulations: Test complex workflows at scale before they reach customers. Simulations let you validate how Procedures will perform before anything goes live, and continuously revalidate as things change. Deploying complex AI can feel uncertain; Simulations remove that uncertainty so you can launch with confidence and iterate safely.
You can simulate full conversations. For any Procedure, choose a user or customer segment and run a complete, multi-turn simulated conversation. You see every step Fin takes, how it applies your rules, reasons through decisions, and where it passes or fails—giving you the observability to debug and fix issues before they ever reach customers.
What’s new: Upload images for richer testing. Simulations now support image uploads, so you can test workflows that involve receipts, invoices, or forms—the same inputs your customers actually send.
What’s new: Clearer visibility into Fin’s reasoning. You can now see exactly how Fin is thinking through each step of a Simulation, making it easier to understand behavior, catch unexpected decisions, and refine Procedures with confidence.
You can also use AI to create, store, and rerun tests. Writing test coverage manually doesn’t scale. Fin’s AI Assistant generates Simulations directly from your Procedures, suggesting realistic edge cases like partial refund disputes, missing invoice uploads, or no subscription found, so you can expand coverage without expanding overhead. All the Simulations you create are stored in a central library. When a product changes, a policy updates, or a Procedure is edited, hit “run all” to instantly check whether anything has regressed. This applies the same rigor to AI automation that engineering teams bring to software testing.
What’s new: AI-suggested Simulations. You can now use AI to generate a full set of Simulations from any Procedure. The AI Assistant suggests realistic variations based on your workflow, so you can build comprehensive test coverage fast.
Customers are already seeing this in production. “Fin can now handle payment-related queries that were never possible before… The impact on CSAT and overall CX has been pretty shocking – the Payment Information procedure CSAT is sitting at ~94%, and CX score is significantly higher than our average.” – Raylo
“Procedures have fundamentally changed what we can achieve with Fin. Previously, complex processes like cashback claim investigations could only be handled through a static form on our website… Now, Fin can handle these sophisticated scenarios in real-time within the conversation itself. It checks account information via API calls, makes complex decisions, and guides customers through the entire claims process dynamically.” – MONY Group
Procedures and Simulations are available now. I’m eager to see how teams use these updates to scale agentic AI, deliver faster resolutions, and raise the bar for customer experience—without sacrificing control, compliance, or quality.
For years, I chased the elusive goal of delivering a perfect customer experience. Today, with AI embedded in our support operations, that standard is finally within reach—and it’s reshaping how we prioritize, design, and scale service.
In “The 2026 Customer Service Transformation Report,” teams report early, tangible wins from AI: faster responses, higher efficiency, and consistent coverage across languages and time zones. Those gains create the capacity we’ve always needed. The more we push the technology, the more quality improvements we unlock.
This marks a fundamental shift. As AI takes on more, our focus can finally move from firefighting to crafting the customer experience. When the AI is working, the measure of success becomes how well it’s working—across accuracy, tone, resolution, and end-to-end journey quality.
I’ve seen this transformation firsthand. Mature AI deployment gives my team “breathing room,” so we can design for consistently excellent outcomes rather than obsess over deflection. That means widening access to support, removing friction on the path to resolution, and anticipating customer needs before they escalate.
In our own support organization, we opened support to trial customers, accelerated first response times, and added consultative sessions during onboarding. We absorbed a 300% increase in total demand without adding headcount—made possible by deep integration of an AI Agent and a disciplined AI strategy.
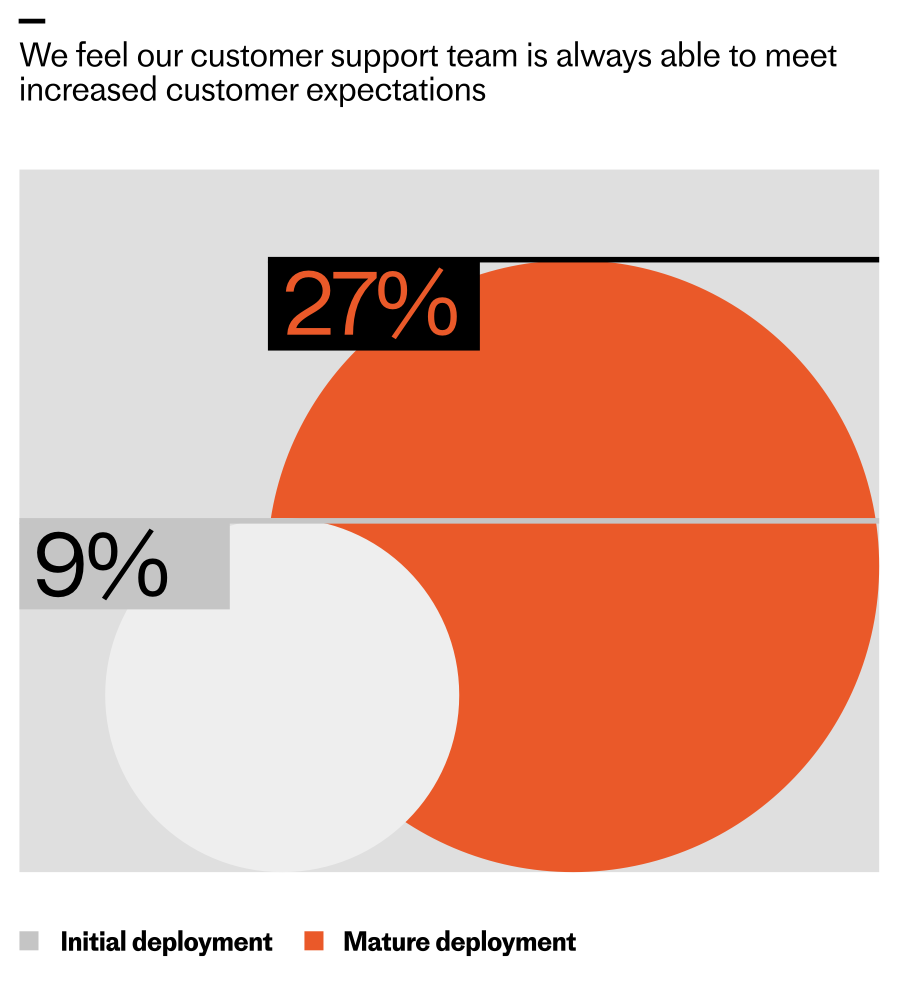
Teams with mature customer service deployments are nearly three times likelier to say they always meet increasing expectations—27% vs 9% at initial rollout—highlighted by bold orange and gray comparison bubbles.
Across the industry, the pattern is similar. When teams initially deploy AI, only 9% say they can always meet customer expectations. That number triples as teams reach a mature level of deployment. Even as expectations rise, the organizations that deeply integrate AI—complete with clear ownership, robust instrumentation, and continuous improvement loops—are the ones most likely to meet (and exceed) the bar.
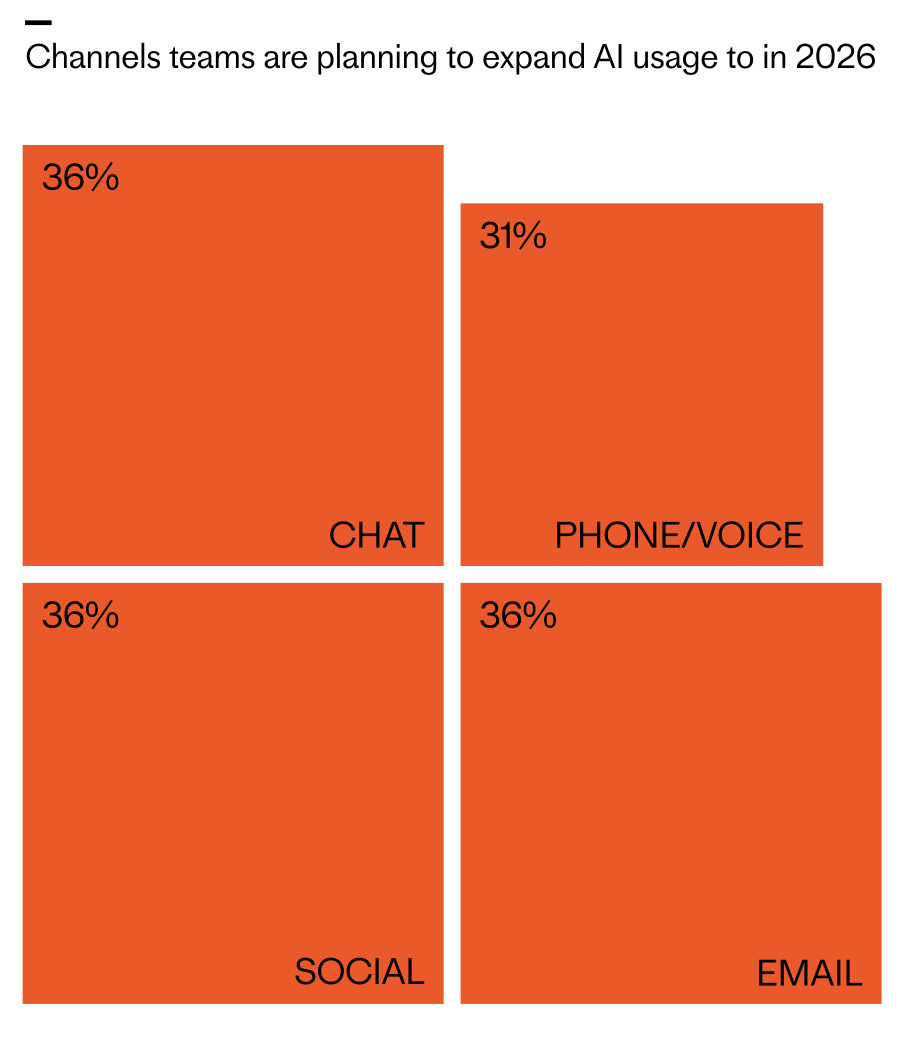
Looking ahead to 2026, I expect omnichannel consistency to become a key differentiator. The data shows planned investment is distributed nearly equally across chat, email, and social messaging (36% each), closely followed by phone/voice (31%). The question is no longer “Which channel should we optimize?” but “How do we deliver a consistent, AI-powered experience everywhere our customers are?”
Teams that solve for omnichannel consistency will bridge the long-standing gap between what customers expect and what support can deliver. Every touchpoint becomes an opportunity to exceed expectations and build durable trust.
Consider Clay, a team that scaled support without sacrificing quality. Support is one of their main growth drivers, and as their customer base expanded, ticket volume surged. Early on, they concentrated much of their effort in Slack, cultivating close, transparent community relationships. But relying on a single channel created friction as they grew; customers wanted the flexibility of email and in-app chat, and Clay needed to deliver the same high standard everywhere.
Where AI investment is headed for customer service in 2026: chat, social, and email lead at 36%, with phone/voice close behind at 31%. A bold visual snapshot of shifting channel priorities in CX.
By unifying their support experience with an AI Agent, Clay brought consistency across channels. Today, AI is involved in 90% of all queries and handles half of Clay’s total volume, upwards of 7,000 queries a month. First response rates improved significantly, freeing the team to focus on proactive, high-impact work.
That work includes identifying content gaps for education and content marketing, reaching customers before they need to ask for help, and surfacing feature requests and recurring challenges to product teams. Clay proves that when support is truly great, it becomes a competitive edge.
So how do you build a superior customer experience with an AI Agent? Here are five principles I use when scaling toward mature deployment.
1) Treat customer experience like a product. Treating support as a product means designing, building, and managing the support experience with the same rigor as your core product. You define goals (faster onboarding, higher CSAT or CX Score, lower churn). You map flows (AI starts the conversation, human handovers, proactive nudges). You instrument the journey (track handoffs, drop-offs, success states). You run tests and ship improvements (tone tweaks, fallback paths, training updates). You own the outcomes (gather feedback, measure performance, use insights to continuously improve the system).
Leaders are racing ahead with real AI in support. Explore the 2026 Customer Service Transformation Report to see where deployment is stalling, benchmark your team, and get practical steps to scale automation that delights.
2) Lead with AI, back with humans. AI isn’t replacing the human touch. It’s redefining when, where, and how it’s most valuable. In a scaled model, AI is the first responder and the end point for most conversations. Humans step in where they add the most value—particularly during high-stakes issues—and those handoffs should feel seamless. Meanwhile, your team focuses on improving AI performance and optimizing the end-to-end journey.
3) Be proactive. Use AI to anticipate needs, guide customers before problems arise, and nudge them toward successful outcomes. This is where customer support AI strategy shines—moving from reactive triage to journey orchestration that protects momentum and builds trust.
4) Build for trust. Many customers still carry the legacy of clunky chatbots that delivered vague answers and dead ends. You earn trust by showing that your system works. Don’t hide your AI Agent behind layers of “choose an option.” Get customers to the AI quickly, demonstrate real problem-solving, and ensure that when a human is needed, they join with full context to resolve complex issues efficiently.
5) Make it feel personal. Your AI Agent represents your brand. The way it speaks, follows policies, and responds matters. Use tone control, fallback logic, and language preferences to align the experience to your standards. Consistency builds trust; personality builds connection and loyalty.
Perfect really is possible. With deep AI implementation, you can scale comprehensive, fast, and personal support across channels—so customers feel supported not just when they reach out, but throughout their journey. That’s the promise of modern AI workflows in support, and it’s what will separate leaders from laggards in the years ahead.
Your team can turn a behavioral anomaly into a polished prototype within hours rather than over weeks, yet still stall when it is time to choose a problem, approve a test, or act on the result. That is the central trap in AI-accelerated product development: producing artifacts faster does not automatically produce better decisions.
The useful unit of acceleration is the complete learning loop: detect a meaningful signal, frame the opportunity, explore distinct hypotheses, validate the riskiest assumptions, ship with controlled exposure, and use production evidence to decide what happens next. You need one operating model across that loop, not a collection of disconnected AI shortcuts.
Key takeaways
Optimize for time from signal to a decision backed by evidence, not the number of analyses, prototypes, or tickets generated.
Give every investigation an outcome contract: the customer behavior, target cohort, primary metric, guardrails, and decision that the work is intended to inform.
Use AI to create alternatives that represent different value hypotheses. More cosmetic variants usually create more review work without expanding what you can learn.
Carry the same cohort, metric definitions, hypothesis, and constraints from discovery into the production experiment. This prevents the handoff from silently changing the question.
Let agents act only where their permissions, thresholds, audit trail, and rollback path are explicit. Autonomy should expand with evidence, reversibility, and trust.
Design one loop from a product signal to a decision
Most teams first apply AI to individual tasks. An agent summarizes a dashboard. A model drafts a product requirements document. A design tool generates a flow. A coding assistant implements it. Each task becomes faster, but the work still waits between tasks because nobody has defined what evidence is sufficient, who can make the next decision, or what outcome the change should affect.
An agent that discovers more anomalies while the product trio reviews opportunities through the same overloaded process has created a longer inbox. The bottleneck has moved; it has not disappeared. The remedy is to treat a decision-ready hypothesis, rather than an AI-generated artifact, as the unit of product work.
A practical discovery loop has the following sequence:
Write the outcome contract. Name the customer behavior you want to change, the cohort in which it matters, the primary outcome metric, the metrics that must not deteriorate, and the decision this evidence will support.
Map the driver tree. Break the outcome into observable behavioral drivers. This gives the agent a bounded search space and prevents a broad metric movement from producing an equally broad list of possible features.
Issue an investigation brief. Tell the agent which definitions, segments, releases, and time comparisons it may use; which data it may access; what it should monitor; and whether it may only recommend or may also initiate an approved workflow.
Require an evidence packet. An anomaly should arrive with the affected cohort, direction and materiality of the movement, relevant timing, instrumentation checks, plausible alternative explanations, and the next question worth answering.
Record the decision. The product trio should accept, reject, defer, or refine the hypothesis and state why. That decision becomes context for the next investigation instead of disappearing into a meeting.
For an onboarding problem, the outcome contract might identify accounts attempting their first meaningful setup, define the activation behavior precisely, name downstream retention and support demand as guardrails, and authorize the agent to investigate friction without changing the customer experience. That is much more useful than asking AI to find onboarding insights. The broad request has no stopping condition and no decision attached to it.
The driver tree then narrows the investigation. Activation might depend on starting setup, completing required configuration, reaching an initial value-bearing action, and returning to use that value. The point is not to make the tree exhaustive. It is to show which behaviors could plausibly explain the outcome and which are observable in your product data.
This is where continuous agents can provide real leverage. They can monitor established metrics, inspect funnel and cohort movements, and surface material changes such as an activation decline in a valuable cohort or a retention change following a release. They can also compare segments and assemble supporting context without waiting for a fresh manual analysis request.
But the alert is not yet an opportunity, and correlation is not a causal explanation. A broken event, a changed identity rule, a traffic-mix shift, or a simultaneous release can resemble a change in customer behavior. Make instrumentation confidence and alternative explanations mandatory fields in the evidence packet. If either is weak, the next action is to improve the evidence, not to generate a feature.
The product trio still owns the consequential judgment: whether the problem is worth solving, what tradeoff is acceptable, which customer evidence is missing, and whether the likely value justifies the delivery cost. AI should remove investigative toil and expose overlooked evidence. It should not hide a strategic choice inside an automated recommendation.
Use AI to expand hypotheses without expanding waste
Generative design changes the economics of exploration. Once a measurable opportunity is clear, high-fidelity flows can be produced in hours instead of stretching across weeks. That makes it practical to inspect several possible mechanisms before production code is written.
Cheap variation also creates a new failure mode. If every stakeholder can request another screen, the team spends its saved production time reviewing undifferentiated options. The prompt should therefore ask for distinct value hypotheses, not a gallery of cosmetic alternatives.
Build the prototype brief from the evidence packet. It should contain:
Target user and context: the affected cohort, the job it is trying to complete, and the point at which friction appears.
Observed evidence: the behavioral signal, qualitative context if available, instrumentation caveats, and alternative explanations that remain open.
Value hypothesis: why a proposed mechanism should change the target behavior, stated in a form that can be rejected.
Meaningfully different mechanisms: alternatives that change how value is delivered, explained, sequenced, or experienced rather than merely changing visual treatment.
Outcome and guardrails: the primary behavior to influence and the accessibility, privacy, brand, reliability, and business constraints that every variation must respect.
Instrumentation needs: the events and properties required to tell whether people encounter, understand, use, and benefit from the proposed experience.
A useful review question is: If these alternatives perform differently, will you learn something about customer value? If the answer is no, the variations probably differ in presentation but not in hypothesis. Asking AI for more of them will not improve the decision.
Match the validation method to the uncertainty:
Concept validation addresses whether the intended user understands the proposition and considers it relevant.
Usability validation addresses whether the user can recognize the next step, complete the flow, and recover from confusion.
Production experimentation addresses whether exposure changes actual behavior under real product conditions.
Cohort-level follow-through addresses whether an immediate movement is accompanied by the activation, retention, or expansion outcome the team ultimately cares about.
Do not ask a prototype to answer a production question. A polished interaction can expose comprehension and usability problems, but it cannot establish that the experience will improve retention. Conversely, do not consume production capacity to answer a basic usability question that a prototype could resolve before engineering begins.
Define the decision rule before each validation step. State what evidence would cause the trio to advance the hypothesis, revise it, or stop. This prevents a compelling AI-generated design from becoming the default simply because it exists. High fidelity is a communication advantage, not proof of value.
Carry the discovery contract into production
The discovery-to-delivery handoff often introduces more error than the tools remove. A metric is renamed, a cohort becomes broader, a design constraint disappears from the ticket, or an experiment is configured to answer a slightly different question. The team ships quickly and then debates what the result means.
Before implementation begins, the trio should be able to point to a compact delivery contract containing:
The customer problem, target cohort, and value hypothesis.
The primary outcome metric and the metrics that protect against unacceptable side effects.
The exact event, property, identity, and segment definitions needed for evaluation.
The minimum detectable effect, meaning the smallest change that would be consequential enough to alter the product decision.
The planned exposure controls, eligibility rules, rollback conditions, and owner.
The accessibility, privacy, data-governance, reliability, and brand constraints inherited from discovery.
The result that would lead to shipping, iteration, further investigation, or rollback.
Set the minimum detectable effect before examining experiment results. The question is not merely whether a statistical difference can be found. It is whether the experiment can detect an effect large enough to matter to the decision. If realistic exposure cannot provide decision-worthy power, acknowledge that limitation. Consider a more substantial intervention, a longer evidence path, or a different validation method instead of asking an underpowered test for certainty it cannot provide.
Risky changes should be gated behind feature flags and delivered through a controlled CI/CD path. A flag limits exposure and creates a rollback mechanism; it does not, by itself, make a release an experiment. You still need stable assignment, defined eligibility, trustworthy instrumentation, and a predeclared interpretation plan.
Not every change is suitable for an A/B test. Some changes are required, too interconnected for clean isolation, or exposed to too little eligible traffic for a decision-worthy test. The discipline still applies: state the expected behavioral change, release progressively when possible, validate the instrumentation, inspect guardrails, and choose the review point before launch.
When production data arrives, evaluate more than the aggregate primary metric. Confirm that exposure and events behaved as intended. Inspect the cohorts named in the original opportunity. Check whether the result varies across important segments. Then follow the downstream activation or retention signal that justified the work. Production conditions include latency, reliability, real data, competing tasks, and repeated use; prototype enthusiasm does not remove any of them.
Finally, record the product decision and feed it back into the system. The agent should know which hypothesis was accepted, what actually shipped, what the experiment showed, and why the team chose to scale, revise, or stop. Without that context, the next automated investigation starts from activity rather than accumulated learning.
Give agents decision rights, guardrails, and a balanced scorecard
Agentic workflows become risky when a team discusses autonomy as a general capability. Decision rights need to be assigned to a defined action in a defined context. The same agent may safely monitor an established metric, recommend an investigation, prepare a prototype, and still require explicit approval before changing a customer experience.
Use the following as a starting policy, then tighten it to your data sensitivity, product risk, and operational controls:
Work
Agent role
Human decision gate
Required control
Monitor an established metric
Run continuously within approved read access
Metric definitions and alert conditions approved in advance
Access boundaries, instrumentation-health checks, and an audit log
Investigate an anomaly
Assemble evidence and recommend hypotheses
Product trio decides whether the signal represents a meaningful opportunity
Cohort context, alternative explanations, confidence, and traceable queries
Generate a prototype or implementation draft
Prepare alternatives and supporting artifacts
Design and engineering approve customer experience and technical choices
Accessibility, privacy, brand, architecture, and data-use constraints
Launch a customer-facing experiment
Prepare configuration; execute only when policy explicitly permits it
Named owner approves exposure, success criteria, and rollback path
Feature flag, eligibility rules, MDE, guardrails, monitoring, and rollback
Trigger a CRM or in-app workflow
Act only inside preapproved conditions
Owner approves audience, message, frequency, and stop rules
Consent-aligned data, bounded actions, suppression logic, and reviewable history
The key distinction is not human versus autonomous work. It is whether the action is bounded, observable, reversible, and aligned to an approved outcome. An agent can be highly autonomous inside a narrow monitoring job and strictly advisory when a decision affects customers, commitments, or sensitive data.
Three governance questions should appear in every agent brief: What may the agent observe? What may it decide? What may it change? Add the owner who reviews its reasoning, the evidence it must preserve, and the mechanism that stops or reverses an action. This turns broad principles such as decision rights, reasoning transparency, and outcome alignment into enforceable operating rules.
Measure flow, quality, outcomes, and risk together
A scorecard focused only on speed will reward premature action. A scorecard focused only on business outcomes will hide whether the operating system is actually improving. Track four dimensions:
Flow: time to insight, time to action, manual analysis effort, and waiting time between investigation, decision, validation, and release.
Decision quality: whether investigations include instrumentation checks and alternative explanations, and whether experiments have a hypothesis, MDE, guardrails, and interpretation rule before launch.
Customer and business outcomes: the relevant movement in activation, retention, expansion, or another outcome named in the contract, including differences across the target cohorts.
Risk: actions outside approved permissions, privacy or access violations, misleading analyses caused by instrumentation problems, customer-impacting errors, and rollbacks.
The relationships between these measures are diagnostic. Shorter time to insight with unchanged time to action means the decision queue is now the bottleneck. More agent-initiated initiatives with flat activation or retention means the organization has increased automation, not product value. Lower manual analysis effort paired with weaker evidence packets means the work became cheaper by discarding necessary scrutiny.
The percentage of initiatives initiated by agents can be useful as an adoption indicator, but it is a poor destination metric. The meaningful result is a shorter, more reliable path to customer and business impact. Keep outcome measures beside time-to-insight, time-to-action, agent-initiated work, and manual analysis effort so local efficiency cannot masquerade as progress.
Start with one bounded learning loop
Do not begin by making every product workflow agentic. Choose one recurring, measurable problem in a trusted part of the data, such as onboarding friction, activation, or retention for a defined cohort. Then roll out the operating model in sequence:
Timestamp the current stages from signal detection through decision, validation, release, and post-launch review. This establishes where work actually waits.
Stabilize the outcome, cohort, event, and segment definitions. If the instrumentation is not trustworthy, repair it before automating interpretation.
Run the agent in read-only, recommendation mode. Require the standard evidence packet and audit whether its conclusions can be reproduced.
Connect approved investigations to the prototype brief. Ask the product trio to select among distinct hypotheses and document why.
Carry the selected hypothesis into the delivery contract, feature flag, instrumentation plan, and evaluation rule.
Permit automated actions only after the team has defined bounded permissions, monitoring, stop conditions, ownership, and rollback.
Review whether the loop became faster without weakening decision quality, customer outcomes, or governance. Expand the model only where that balance holds.
If an agent cannot show how it reached a conclusion, keep it in an investigative support role. If the team cannot state what result would change its decision, pause the experiment design. If cycle time falls but no relevant outcome improves, revisit the opportunity selection and hypothesis quality rather than adding more automation.
For your next active product problem, write the outcome contract before requesting an AI analysis or prototype. Give the agent a bounded investigation brief, require the trio to compare meaningfully different hypotheses, and move the chosen hypothesis into production without changing its metric or cohort. That single end-to-end loop will tell you more about your AI readiness than a long inventory of tools.
The test is straightforward: if AI helps you reach a consequential, auditable product decision sooner and learn from the result, it has accelerated product development. If it merely creates more things to review, it has accelerated output.
Your team may already use AI to draft emails, summarize calls, research accounts, and answer website questions. Yet the lead still waits in a queue, the seller still reconstructs context, and the customer still repeats the same information after every handoff.
If you are deciding how to make go-to-market genuinely AI-native, do not start with another list of tools. Decide which part of the revenue journey can run as a complete, observable workflow: AI handles defined decisions and actions, humans take over at explicit boundaries, and both work from the same customer state.
Redraw the revenue workflow before automating its tasks
Adding an assistant to every department can make individual tasks faster without making the revenue system faster. Marketing produces more content, sales receives more research, and customer success gets more summaries, but the queues and handoffs between those functions remain intact. More output can even make those bottlenecks worse.
An AI-native workflow has a different unit of design. It owns a bounded outcome over time. It can observe an event, retrieve approved context, choose among permitted actions, update the CRM, evaluate what happened, and either continue or escalate. The distinction matters: generating a follow-up email is a task; noticing that a qualified buyer has gone quiet, selecting the appropriate follow-up, sending it under policy, recording the attempt, and changing course based on the response is a workflow.
Map one live customer journey before discussing models or vendors. For every transition, write down six things:
Trigger: What observable event starts the work? Examples include a demo request, an unanswered question, a completed trial action, or a missed follow-up.
State: What must be known before anyone acts? Include the account, buyer, stage, previous interactions, consent, product usage, and open commitments that matter.
Decision: What choice is being made? Qualification, routing, next-best action, escalation, or disqualification should not be hidden inside a vague prompt.
Action: What is the agent actually allowed to do? Drafting, sending, booking, calling, demonstrating, updating a field, or creating a human task are different permission levels.
Evidence: What will prove that the action was appropriate and completed? Preserve retrieved passages, tool results, timestamps, policy checks, and the resulting CRM change.
Exception owner: Who takes responsibility when confidence is low, the buyer objects, the data conflicts, or the request falls outside policy?
This map exposes where AI can remove elapsed time rather than merely reduce typing. Baseline the current path using measures you already trust: time between stages, abandonment points, manual touches, repeated discovery, and incomplete CRM records. Then choose one customer outcome, such as completing a qualified next step, instead of treating generated messages as success.
My test is simple: if the proposed system cannot identify its current state, show why it acted, and recover from a failed action, it is still a feature. It is not yet part of the revenue operating system.
Start with a bounded inbound motion, then earn more autonomy
I would usually start where the buyer has already expressed intent. An inbound visitor asking a product question or requesting a demonstration gives you a clear trigger, an identifiable job, and a natural human fallback. You can observe whether the interaction advances the buyer without asking an agent to manufacture demand across an ambiguous market.
A strong first workflow has five properties:
The entry event and desired next state are unambiguous.
The agent can answer from an approved and maintainable body of knowledge.
Most actions are reversible, or a human can approve them before execution.
Failure and frustration can be detected quickly.
The business outcome appears in a system of record rather than a separate AI dashboard.
Inbound qualification, guided product education, demo support, meeting preparation, and structured follow-up often fit these conditions. A practical early implementation can be deliberately modest: a voice interaction, reusable product demonstrations, and a retrieval-first knowledge layer. Retrieval gives the agent current, company-approved material without forcing every sales fact into a prompt, and it gives evaluators evidence against which to judge an answer.
Treat the interaction surface as part of the workflow, not as decoration. In one documented implementation, adding a realistic avatar changed how prospects behaved: they interrupted, probed, and requested demonstrations in ways associated with a live sales conversation. That is evidence that an interface changes the behavior it invites, not proof that every buyer or sales motion needs an avatar. Test chat, voice, and video against the buyer’s actual job. Do not choose the most human-looking interface by default.
Expand autonomy in gates rather than with one large launch:
Shadow: The agent recommends an answer, decision, or next action while a human remains responsible for execution. Use disagreements to build the first evaluation set.
Constrained execution: The agent handles approved questions and actions, writes every result to the CRM, and routes exceptions to a named person.
Bounded workflow ownership: The agent can continue across interactions and days, but only inside an explicit state machine, policy envelope, and escalation contract.
Adjacent expansion: Reuse proven capabilities in another stage, such as onboarding or customer success, only after the first workflow is stable and measurable.
Gate movement on evidence, not enthusiasm or a calendar date. The agent should not receive a new action merely because it can generate plausible language. It should receive that action when you can detect a bad decision, contain its consequence, and restore the customer journey.
Give agents distinct jobs and humans a real handoff contract
A single prompt that qualifies, pitches, retrieves facts, controls tools, remembers history, evaluates itself, and decides when to escalate becomes difficult to test. It also mixes goals that can conflict. A persuasive sales response and a conservative policy check should not compete for attention in the same undifferentiated instruction block.
A useful architecture separates five responsibilities:
Knowledge or creator agent: Turns approved documentation, training material, and transcript patterns into versioned playbooks and retrievable knowledge.
Conversation agent: Handles the live interaction, asks the next appropriate question, and stays within the current objective.
Workflow orchestrator: Maintains state across channels and time, selects the next permitted step, invokes tools, and pauses when an exception occurs.
Evaluator: Scores the interaction for grounding, policy compliance, conversation quality, sentiment, and task completion.
Human owner: Resolves ambiguity, negotiates unusual terms, restores trust, and changes the playbook when the system exposes a recurring gap.
Specialized conversation roles can also help manage latency, context limits, and model weaknesses. Greeting, discovery, qualification, and pitching do not necessarily need identical instructions or context. The important design move is not the number of agents; it is the ability to isolate a responsibility and test it. Deterministic paths can handle predictable stages while orchestration manages contextual departures.
Do not split a workflow into a swarm merely because multi-agent architecture sounds advanced. Start with the fewest independently testable components. Split one when its context becomes noisy, its latency threatens the experience, its permissions need separate control, or its failures require a different evaluation method.
The orchestrator should persist a compact state record that another worker can understand. At minimum, capture the current objective, stage, known facts, supporting evidence, confidence, unresolved questions, commitments already made, next permitted action, and current owner. Keep the transcript available, but do not force every downstream decision-maker to reconstruct state from raw conversation history.
A human handoff is a product contract, not an emergency notification. Define its triggers before launch. Useful triggers include:
The agent cannot find approved evidence for a material answer.
Confidence falls below the level you have defined for that action.
The buyer repeats a correction, expresses frustration, or explicitly requests a person.
The request involves commercial, security, legal, or contractual judgment outside the approved playbook.
A tool fails, CRM state conflicts with the conversation, or the proposed action would duplicate an existing commitment.
The receiving person needs more than a transcript link. Send the buyer’s goal, the current stage, facts already established, the reason for escalation, supporting evidence, actions attempted, promises made, urgency, and the decision the human must make. Pause further automated outreach until ownership is acknowledged. Otherwise, the agent can send a cheerful follow-up while a seller is handling a sensitive objection.
After the human resolves the case, specify whether control returns to the workflow and what state must change first. That return path is where many pilots quietly become permanent manual operations.
The CRM must carry this shared state in both directions. Agents should read the latest account context and write back decisions, actions, outcomes, and evidence. A system that conducts a convincing conversation but leaves the record incomplete creates invisible work for the next person. Tight CRM integration and persistent workflow orchestration are what turn an interface into an operating capability.
Use evaluations and revenue governance as the control plane
A polished demonstration proves that a workflow can succeed once. Revenue leaders need evidence that it succeeds repeatedly, fails visibly, and improves without silently regressing. That requires an evaluation system tied to release decisions.
Build the control loop in this order:
Define the failure taxonomy. Separate unsupported facts, policy violations, missed discovery, poor routing, broken tools, excessive latency, incorrect CRM updates, weak handoffs, and incomplete outcomes. A single quality score hides the repair you need.
Create a representative evaluation set. Include common interactions, important segments, known edge cases, adversarial requests, tool failures, and examples that should trigger escalation. Label the expected action and unacceptable actions, not only an ideal sentence.
Review production conversations aggressively at the start. One practical deployment pattern reviews every interaction during early operation and tapers toward a sample of about 5% as confidence grows. The reduction is earned through observed quality; it is not a default schedule. Customer review, evaluator scoring, and sampling can operate as one quality loop.
Turn failures into regression tests. When a human corrects an answer, routing decision, or handoff, add a durable test before changing the prompt or playbook. Otherwise, fixing one conversation can break another without detection.
Release progressively. Use proof-of-concept validation, controlled exposure, A/B rollout where appropriate, CRM logs, and dashboards. Preserve a rollback path for prompts, models, playbooks, tools, and policies.
Expand authority only after two kinds of evidence agree. Agent quality must remain acceptable, and the intended business outcome must improve without shifting damage into complaints, bad-fit pipeline, downstream rework, or customer churn.
Your dashboard should distinguish system quality from business performance. Both are necessary, and neither can substitute for the other.
Qualified progression, completed bookings, stage movement, activation, retention, and downstream rejection of poor-fit opportunities
Operating health
Can the capability run and improve reliably?
CRM completeness, failed actions, recovery, human review load, overrides, version history, and cost per completed outcome
Do not reward the agent for conversion alone. A system can raise a local conversion metric by overpromising, qualifying weak opportunities, or making escalation harder. Review performance by segment and release version, and keep quality and downstream outcome guardrails beside the target metric.
Governance also needs named owners. The CRO should own the end-to-end revenue outcome and the interlocks across marketing, sales, solutions engineering, onboarding, and customer success. Product and AI leaders should own agent behavior, experience, evaluation infrastructure, and release gates. Revenue operations should own CRM state, definitions, attribution, and operational dashboards. Functional leaders should own their playbooks and exception policies. Humans in the workflow should own judgment where trust, negotiation, and ambiguity matter.
Centralize the parts that must remain consistent: data definitions, core tooling, pricing guardrails, evaluation standards, and foundational enablement. Let segment plays, partner motions, and contextual field execution stay closer to the teams that understand them. This avoids two common extremes: every function buying its own disconnected agent, or a central AI group becoming the queue for every revenue experiment.
Pair gated releases with a 24-26 month design horizon. The longer view is not a promise that you can forecast models or markets precisely. It forces you to ask what breaks at higher volume, which capabilities must remain centralized, how roles will change, and what data or evaluation debt would block the next level of autonomy. The release in front of you can remain small while the operating architecture anticipates scale.
The first leadership review should produce five concrete artifacts: a workflow map, an agent charter, a human handoff contract, an evaluation set, and a dashboard with a named decision-maker for every release gate. If the meeting ends with only a vendor shortlist, the transformation has not yet been designed.
Key takeaways
If an agent cannot read and update shared customer state, it is an interface attached to the revenue system, not a worker inside it.
If the handoff criteria and return path are unclear, the agent’s autonomy is already too broad.
If production failures do not enlarge the evaluation suite, the organization is collecting incidents rather than compounding learning.
If a buyer must repeat discovery after escalation, the context architecture has failed even when the AI behaved politely.
If the roadmap is organized around tools instead of revenue-state transitions, no executive truly owns the transformation.
At your next go-to-market review, choose one live inbound path and walk a real lead through it from trigger to next customer outcome. Assign state, evidence, permissions, and an exception owner at every transition. Automate only the steps whose failure you can detect and recover from. That is how you earn the right to give AI more of the revenue journey.
Over the past few years, I’ve led cross-functional teams to deploy agentic AI in production, and I’ve learned that success rarely hinges on the model alone. It comes from methodically designing the right workflows, instrumenting every step, and building a feedback loop that compounds. Learn how companies like Replit are consolidating workflows, creating one-person departments, and building systems for scale with Amplitude.
When I talk about AI agents, I’m describing software that behaves like a focused teammate—owning a clear job to be done end-to-end. In practice, that means consolidating fragmented tasks into a single accountable “one-person department,” then giving it the context, tools, and analytics to perform reliably. This is how agentic AI moves beyond demos into durable business impact.
I start with outcomes, not algorithms. I map a driver tree from business goals (e.g., lower response time, higher activation, better retention) to the specific moments an agent can influence. This outcome-first alignment keeps scope tight, informs guardrails, and grounds the value proposition in measurable change instead of vanity metrics.
Next, I define the workflow the agent will fully own. I look for high-volume, rules-adjacent processes—think lead qualification, support triage, or billing inquiries—where clear decision criteria already exist but human time is the bottleneck. I document triggers, inputs, decision points, and handoffs, then design the ideal-state flow the agent will run autonomously, with transparent escalation paths to humans.
On architecture, I favor a retrieval-first pipeline to keep responses accurate and current. I scope the knowledge base, implement context window management, and standardize tools the agent can call (search, CRM actions, ticket updates). For teams new to this, I coach “LLMs for product managers” fundamentals so we make sensible trade-offs between speed and reliability rather than chasing model-of-the-week headlines.
Instrumentation is where the system becomes self-improving. I use Amplitude analytics and an Agent Analytics schema to track intent detection, tool usage, resolution rate, time-to-resolution, deflection, and escalation causes. A unified analytics platform lets me connect agent outcomes to core product metrics—activation, retention, and conversion—so we can see the real revenue and experience impact, not just local efficiency gains.
To validate impact, I run A/B testing when traffic allows, setting a minimum detectable effect (MDE) upfront to avoid inconclusive reads. In lower-volume scenarios, I lean on eval-driven development: curated test sets for edge cases, scenario-based regression suites, and error taxonomies that accelerate iteration. Feature flags let us stage capabilities safely (shadow mode, assistive, autonomous) while we monitor deltas before full rollout.
Reliability and trust are designed in from the start. I apply AI risk management practices—privacy-by-design, data governance, and policy-aligned prompt templates—paired with observability to trace decisions. Clear escalation policies, incident management runbooks, and human-in-the-loop checkpoints ensure the agent fails safe, not silently.
Shipping cadence matters. I use CI/CD to increase deployment frequency, keep prompts and tools versioned, and gate risky changes with targeted rollouts. As patterns stabilize, we scale horizontally to new use cases, sharing core capabilities (retrieval, analytics, guardrails) as a platform. This is how “one-person departments” multiply without multiplying overhead.
Change management closes the loop. I partner with product trios and frontline teams to co-design prompts, set acceptance criteria, and define what “good” looks like in plain language. In-app guides and product tours introduce the agent’s role and limits, and structured feedback channels feed directly into our discovery and iteration rhythm.
The throughline of this playbook is simple: treat agents like real teammates with a job description, operating procedures, and performance reviews. With disciplined workflow design, a retrieval-first pipeline, and outcome-level instrumentation in Amplitude, agentic AI stops being a science project and starts compounding into durable product-led growth.
Inspired by this post on Amplitude – Perspectives.