Every update we shipped this month removed a specific constraint on what teams can do with Fin. In my world, the demo-to-production gap shows up as complexity, control, and confidence. Can the agent handle the query that actually matters? Will it sound right on a call? Can the team deploy it without filing an engineering ticket? Can managers understand what it’s doing? That’s the bar I hold us to.
This month, we delivered answers to all four. Here’s how.
Procedures and Simulations (0:51). The hardest problem in AI-powered customer service isn’t answering FAQs—it’s executing complex queries with real business logic and real consequences if anything goes wrong. Think billing refunds, multi-step flows, and actions that must be right the first time.
We made it dramatically easier to build and manage Fin for those complex queries—without pulling in an engineer. You can author in natural language, test every step in simulation, and deploy with confidence.
The workflow starts with AI drafting the procedure from your existing source material. You edit in natural language, with structured hooks to pull in live data, apply business logic, and add code for deterministic control where you need it. That’s how you handle multi-step flows with the precision that matters when things go wrong.
Simulations are the test environment. Define a test case, pass in the data Fin would receive in a real conversation, and watch it work through each step. You see what Fin is doing, why, and whether it’s meeting the criteria you set. Full transparency at every point. I’ve run these end-to-end myself, and there’s a particular confidence that comes from watching it work before it goes anywhere near a customer.

For a deeper look at Procedures and Simulations, head to fin.ai/procedures.
Fin Voice: three major updates. When something’s off in chat, it can take a few exchanges to notice; on a call, it’s immediate. Pronunciation, noise handling, and tone all matter because they’re the customer’s first impression.
Pronunciation rules (4:18). Fin has high out-of-the-box pronunciation accuracy, but it doesn’t know your brand—your product names, your industry terminology, the way your company uses certain words. Alihan Zinna, Staff ML Scientist, showed this with an IKEA example: without pronunciation rules, Fin mispronounced both “IKEA” and a product name; after adding rules, both were corrected and sounded natural.
New natural voices (5:48). We’ve added 11 new voices tuned to a range of brand tones so you can choose one that sounds like it truly belongs to your company—not a generic AI assistant.
Background noise reduction (6:28). People call from airports, shops, and busy offices. Fin now monitors background noise continuously and increases noise reduction when the environment demands it. No configuration needed. As Alihan put it, “This is one of those things customers really notice when it’s not working. The goal was to make it invisible. That’s what we built.”
Shopify setup experience (8:21). Fin began as a Service Agent and is quickly becoming a Customer Agent—working across the whole lifecycle to support, sell, and guide, even before a customer has an issue. The revamped Shopify setup is a clear step forward.
Shopify catalogs are complex—thousands of products, variants, and dynamic inventory—and connecting all of that to an agent has historically been painful. We removed the friction.
Setup now takes three steps: first, connect your store. Second, install the Messenger directly in Shopify—no code, just a few clicks. Third, deploy Fin. Total time: under two minutes. We timed it live.
What that unlocks is real. In the demo, a first-time snowboarder asked for recommendations. Fin searched the catalog, reasoned about attributes that matter to a beginner (there’s no “beginner” tag in the catalog), personalized suggestions by height and weight, and added a board to the cart.
Even better, one customer updated their website copy to promote a sale. Fin immediately picked up the new context and began recommending sale items, nudging shoppers to add more to the cart to access a discount—no extra configuration required. It read the situation and acted.
Three steps, and you have a real-time shopping assistant that knows your store and sells on your behalf.
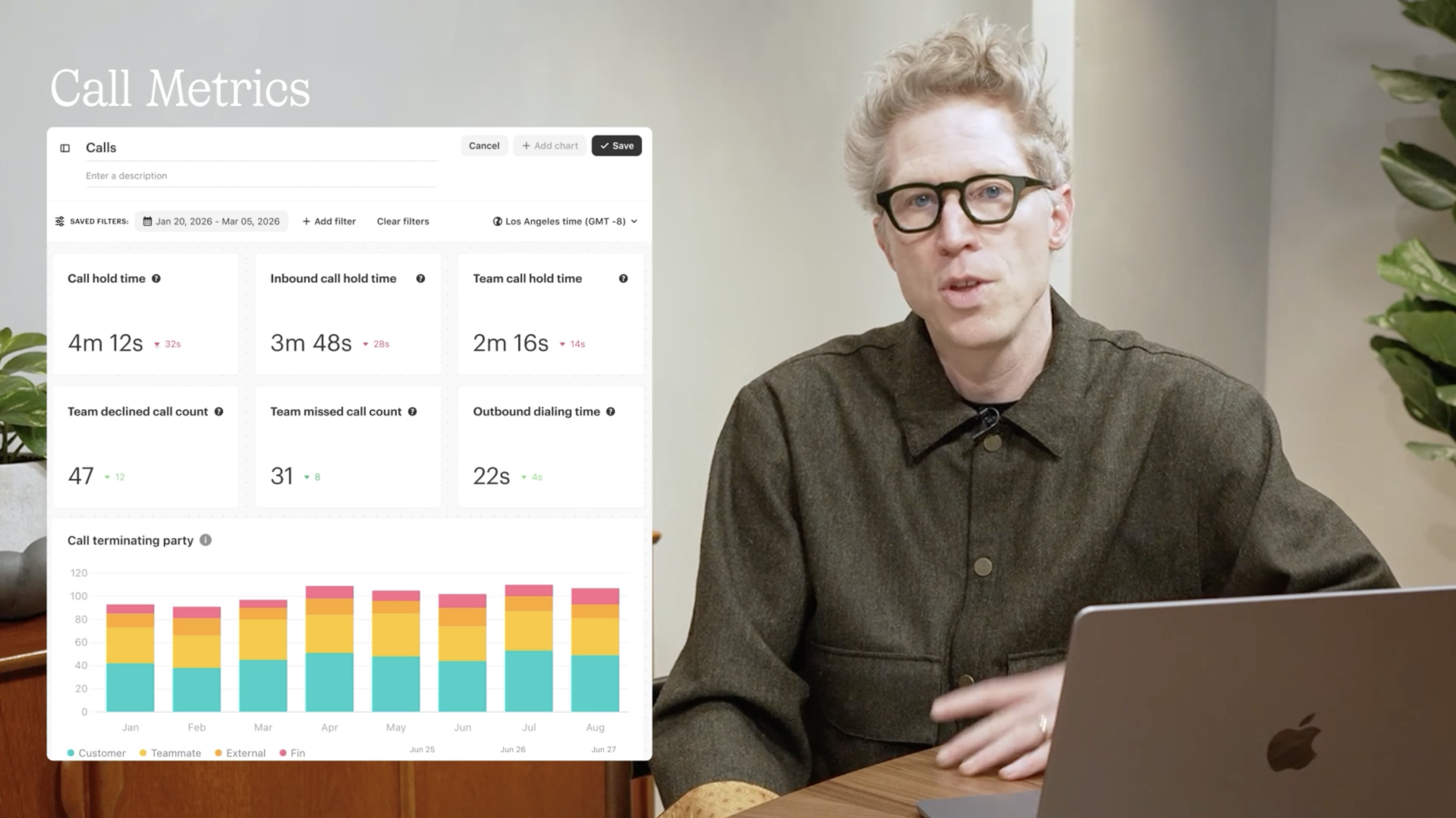
Helpdesk improvements (12:31). Fin works with any helpdesk, but many teams consolidate to take advantage of our native Intercom helpdesk integration. We’ve shipped 19 helpdesk improvements in 2026 so far; two from this month stand out.
11 new call metrics. Hold time, outbound dial time, missed and declined calls, call terminating party, and more. These give leaders the visibility to analyze workload distribution and call handling quality in detail.
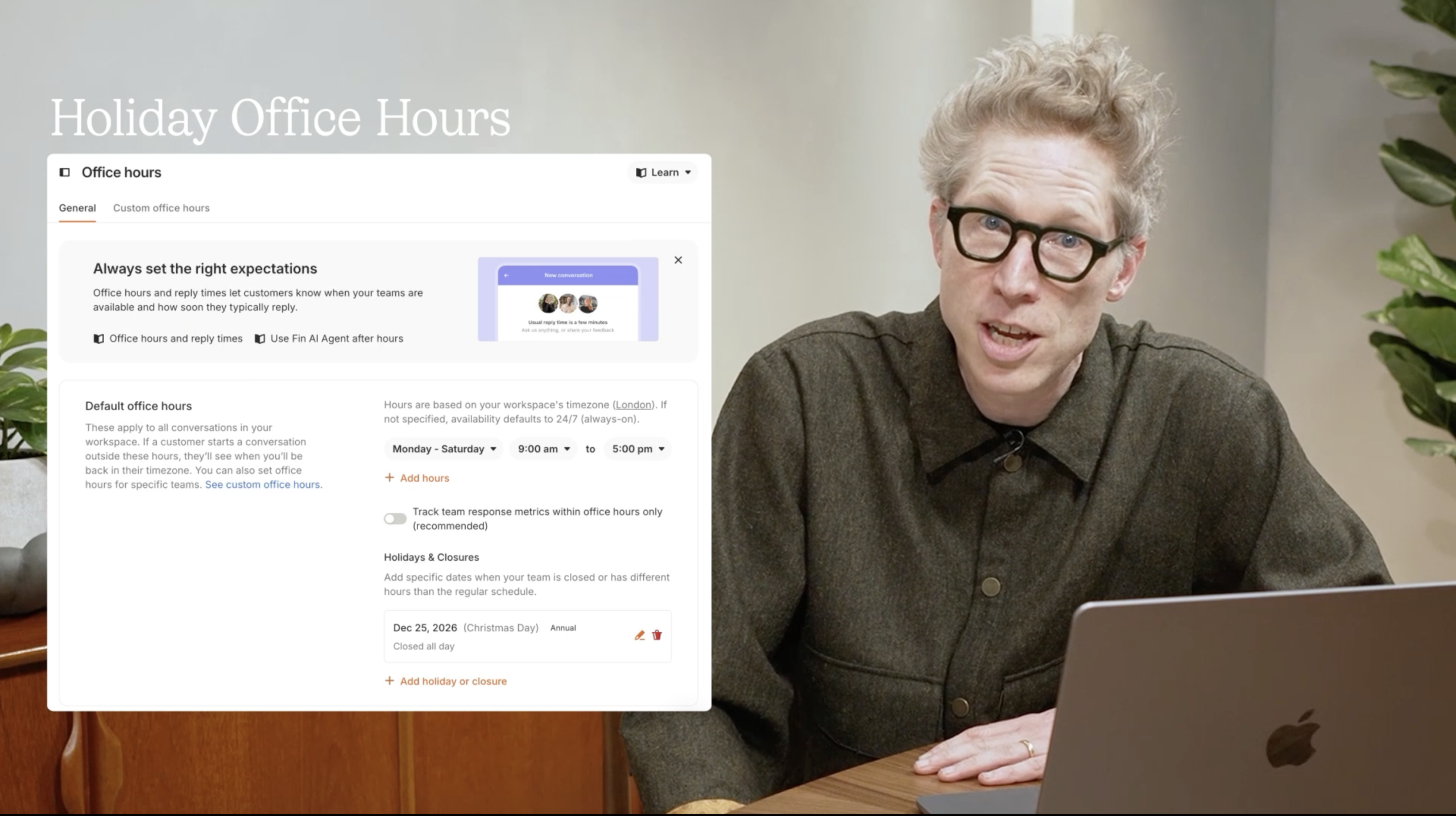
Holiday office hours. Teams no longer need to manually update office hours for every public holiday. This was the most upvoted request in our community, and we shipped it.
Across the board, we removed the constraints that hold teams back: the complexity ceiling in automation, the quality ceiling in voice, the setup barrier in Shopify, and the operational overhead in the helpdesk.
We closed out the month with a Star Wars–style crawl of 22 additional updates. All features mentioned here are live and available now. Explore more at fin.ai/updates. More to come—see you next month.
Inspired by this post on The Intercom Blog.