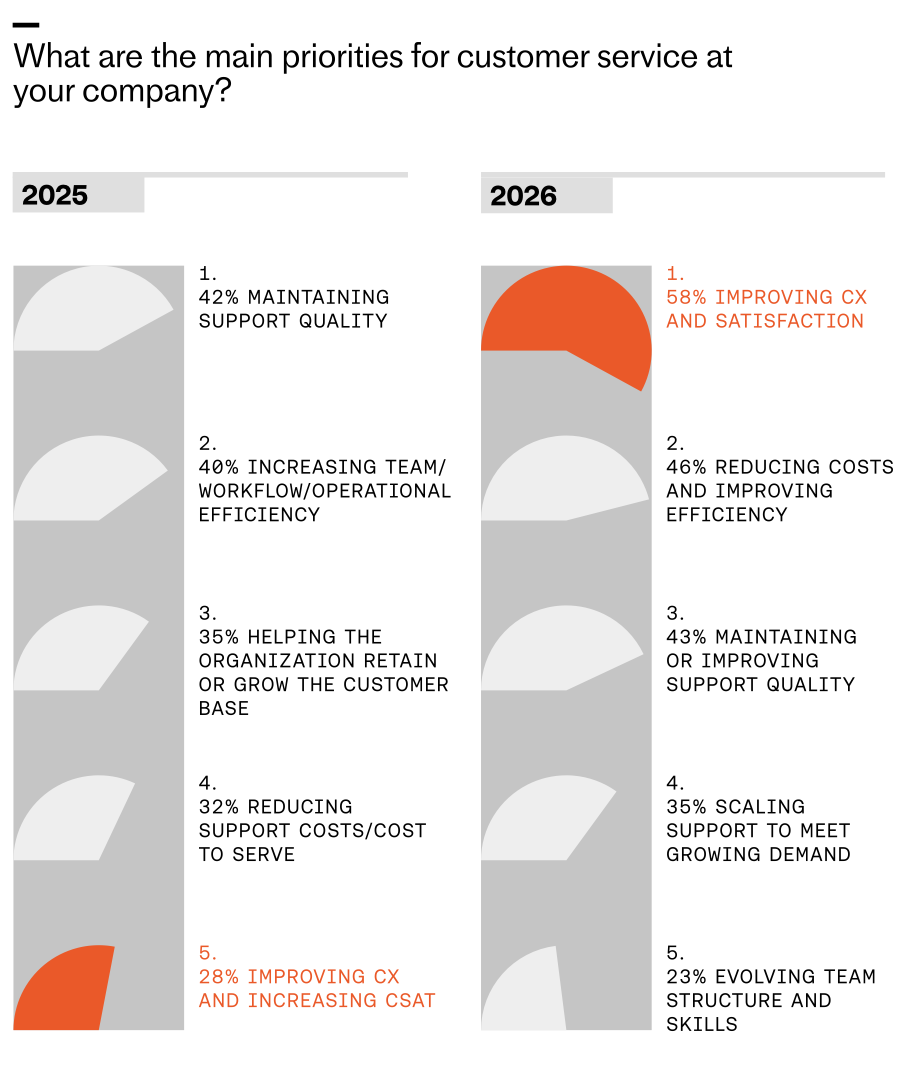
For years, I chased the elusive goal of delivering a perfect customer experience. Today, with AI embedded in our support operations, that standard is finally within reach—and it’s reshaping how we prioritize, design, and scale service.
In “The 2026 Customer Service Transformation Report,” teams report early, tangible wins from AI: faster responses, higher efficiency, and consistent coverage across languages and time zones. Those gains create the capacity we’ve always needed. The more we push the technology, the more quality improvements we unlock.
This marks a fundamental shift. As AI takes on more, our focus can finally move from firefighting to crafting the customer experience. When the AI is working, the measure of success becomes how well it’s working—across accuracy, tone, resolution, and end-to-end journey quality.
I’ve seen this transformation firsthand. Mature AI deployment gives my team “breathing room,” so we can design for consistently excellent outcomes rather than obsess over deflection. That means widening access to support, removing friction on the path to resolution, and anticipating customer needs before they escalate.
In our own support organization, we opened support to trial customers, accelerated first response times, and added consultative sessions during onboarding. We absorbed a 300% increase in total demand without adding headcount—made possible by deep integration of an AI Agent and a disciplined AI strategy.
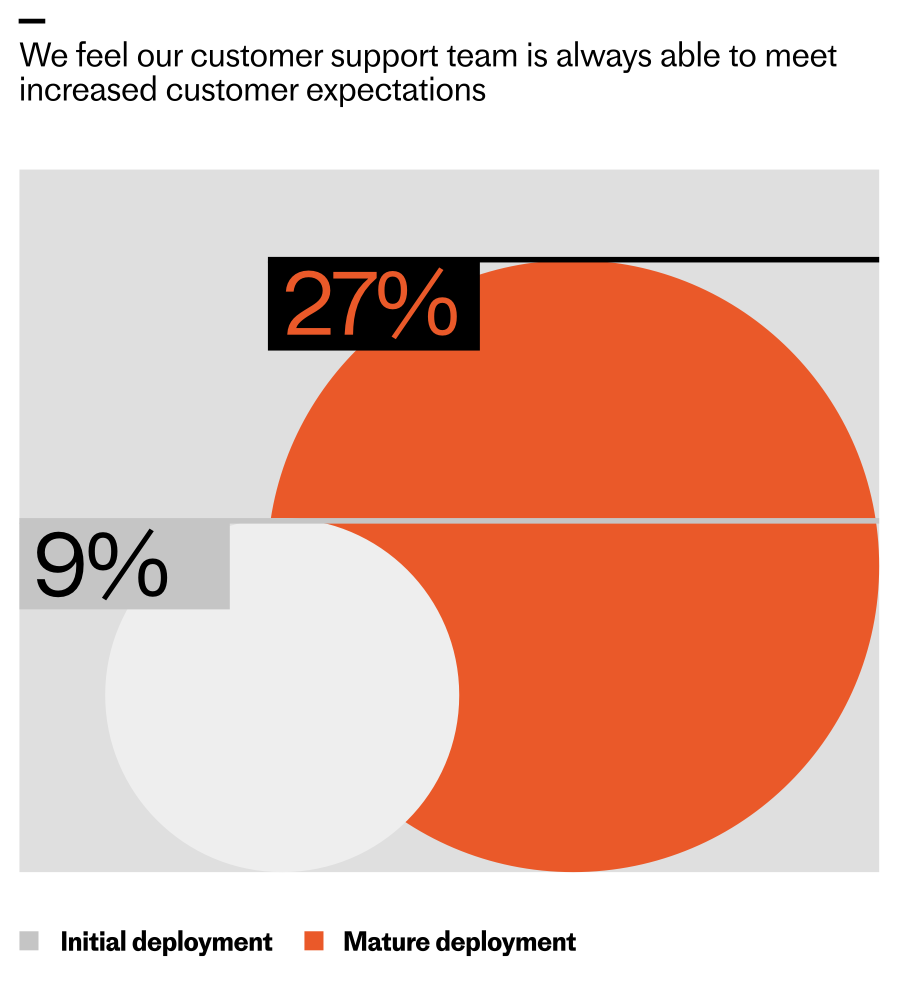
Teams with mature customer service deployments are nearly three times likelier to say they always meet increasing expectations—27% vs 9% at initial rollout—highlighted by bold orange and gray comparison bubbles.
Across the industry, the pattern is similar. When teams initially deploy AI, only 9% say they can always meet customer expectations. That number triples as teams reach a mature level of deployment. Even as expectations rise, the organizations that deeply integrate AI—complete with clear ownership, robust instrumentation, and continuous improvement loops—are the ones most likely to meet (and exceed) the bar.
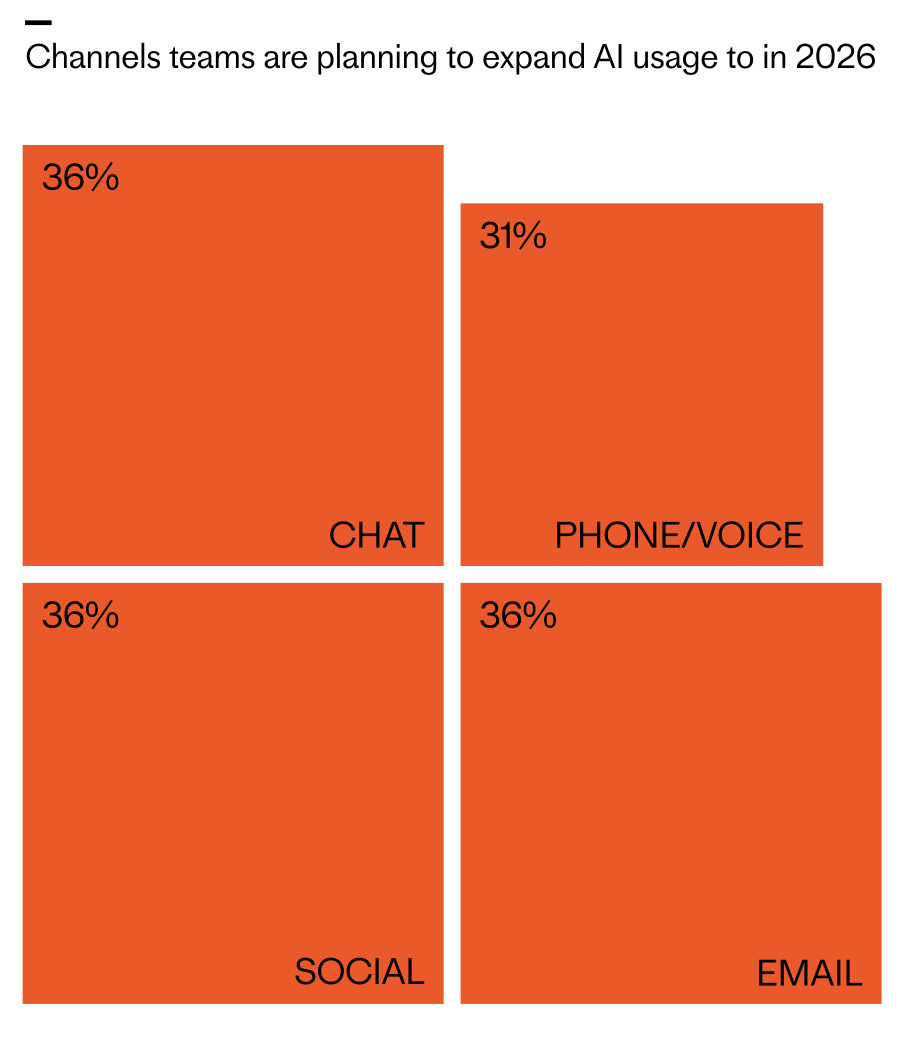
Looking ahead to 2026, I expect omnichannel consistency to become a key differentiator. The data shows planned investment is distributed nearly equally across chat, email, and social messaging (36% each), closely followed by phone/voice (31%). The question is no longer “Which channel should we optimize?” but “How do we deliver a consistent, AI-powered experience everywhere our customers are?”
Teams that solve for omnichannel consistency will bridge the long-standing gap between what customers expect and what support can deliver. Every touchpoint becomes an opportunity to exceed expectations and build durable trust.
Consider Clay, a team that scaled support without sacrificing quality. Support is one of their main growth drivers, and as their customer base expanded, ticket volume surged. Early on, they concentrated much of their effort in Slack, cultivating close, transparent community relationships. But relying on a single channel created friction as they grew; customers wanted the flexibility of email and in-app chat, and Clay needed to deliver the same high standard everywhere.
Where AI investment is headed for customer service in 2026: chat, social, and email lead at 36%, with phone/voice close behind at 31%. A bold visual snapshot of shifting channel priorities in CX.
By unifying their support experience with an AI Agent, Clay brought consistency across channels. Today, AI is involved in 90% of all queries and handles half of Clay’s total volume, upwards of 7,000 queries a month. First response rates improved significantly, freeing the team to focus on proactive, high-impact work.
That work includes identifying content gaps for education and content marketing, reaching customers before they need to ask for help, and surfacing feature requests and recurring challenges to product teams. Clay proves that when support is truly great, it becomes a competitive edge.
So how do you build a superior customer experience with an AI Agent? Here are five principles I use when scaling toward mature deployment.
1) Treat customer experience like a product. Treating support as a product means designing, building, and managing the support experience with the same rigor as your core product. You define goals (faster onboarding, higher CSAT or CX Score, lower churn). You map flows (AI starts the conversation, human handovers, proactive nudges). You instrument the journey (track handoffs, drop-offs, success states). You run tests and ship improvements (tone tweaks, fallback paths, training updates). You own the outcomes (gather feedback, measure performance, use insights to continuously improve the system).
Leaders are racing ahead with real AI in support. Explore the 2026 Customer Service Transformation Report to see where deployment is stalling, benchmark your team, and get practical steps to scale automation that delights.
2) Lead with AI, back with humans. AI isn’t replacing the human touch. It’s redefining when, where, and how it’s most valuable. In a scaled model, AI is the first responder and the end point for most conversations. Humans step in where they add the most value—particularly during high-stakes issues—and those handoffs should feel seamless. Meanwhile, your team focuses on improving AI performance and optimizing the end-to-end journey.
3) Be proactive. Use AI to anticipate needs, guide customers before problems arise, and nudge them toward successful outcomes. This is where customer support AI strategy shines—moving from reactive triage to journey orchestration that protects momentum and builds trust.
4) Build for trust. Many customers still carry the legacy of clunky chatbots that delivered vague answers and dead ends. You earn trust by showing that your system works. Don’t hide your AI Agent behind layers of “choose an option.” Get customers to the AI quickly, demonstrate real problem-solving, and ensure that when a human is needed, they join with full context to resolve complex issues efficiently.
5) Make it feel personal. Your AI Agent represents your brand. The way it speaks, follows policies, and responds matters. Use tone control, fallback logic, and language preferences to align the experience to your standards. Consistency builds trust; personality builds connection and loyalty.
Perfect really is possible. With deep AI implementation, you can scale comprehensive, fast, and personal support across channels—so customers feel supported not just when they reach out, but throughout their journey. That’s the promise of modern AI workflows in support, and it’s what will separate leaders from laggards in the years ahead.
Over the past few years, I’ve led cross-functional teams to deploy agentic AI in production, and I’ve learned that success rarely hinges on the model alone. It comes from methodically designing the right workflows, instrumenting every step, and building a feedback loop that compounds. Learn how companies like Replit are consolidating workflows, creating one-person departments, and building systems for scale with Amplitude.
When I talk about AI agents, I’m describing software that behaves like a focused teammate—owning a clear job to be done end-to-end. In practice, that means consolidating fragmented tasks into a single accountable “one-person department,” then giving it the context, tools, and analytics to perform reliably. This is how agentic AI moves beyond demos into durable business impact.
I start with outcomes, not algorithms. I map a driver tree from business goals (e.g., lower response time, higher activation, better retention) to the specific moments an agent can influence. This outcome-first alignment keeps scope tight, informs guardrails, and grounds the value proposition in measurable change instead of vanity metrics.
Next, I define the workflow the agent will fully own. I look for high-volume, rules-adjacent processes—think lead qualification, support triage, or billing inquiries—where clear decision criteria already exist but human time is the bottleneck. I document triggers, inputs, decision points, and handoffs, then design the ideal-state flow the agent will run autonomously, with transparent escalation paths to humans.
On architecture, I favor a retrieval-first pipeline to keep responses accurate and current. I scope the knowledge base, implement context window management, and standardize tools the agent can call (search, CRM actions, ticket updates). For teams new to this, I coach “LLMs for product managers” fundamentals so we make sensible trade-offs between speed and reliability rather than chasing model-of-the-week headlines.
Instrumentation is where the system becomes self-improving. I use Amplitude analytics and an Agent Analytics schema to track intent detection, tool usage, resolution rate, time-to-resolution, deflection, and escalation causes. A unified analytics platform lets me connect agent outcomes to core product metrics—activation, retention, and conversion—so we can see the real revenue and experience impact, not just local efficiency gains.
To validate impact, I run A/B testing when traffic allows, setting a minimum detectable effect (MDE) upfront to avoid inconclusive reads. In lower-volume scenarios, I lean on eval-driven development: curated test sets for edge cases, scenario-based regression suites, and error taxonomies that accelerate iteration. Feature flags let us stage capabilities safely (shadow mode, assistive, autonomous) while we monitor deltas before full rollout.
Reliability and trust are designed in from the start. I apply AI risk management practices—privacy-by-design, data governance, and policy-aligned prompt templates—paired with observability to trace decisions. Clear escalation policies, incident management runbooks, and human-in-the-loop checkpoints ensure the agent fails safe, not silently.
Shipping cadence matters. I use CI/CD to increase deployment frequency, keep prompts and tools versioned, and gate risky changes with targeted rollouts. As patterns stabilize, we scale horizontally to new use cases, sharing core capabilities (retrieval, analytics, guardrails) as a platform. This is how “one-person departments” multiply without multiplying overhead.
Change management closes the loop. I partner with product trios and frontline teams to co-design prompts, set acceptance criteria, and define what “good” looks like in plain language. In-app guides and product tours introduce the agent’s role and limits, and structured feedback channels feed directly into our discovery and iteration rhythm.
The throughline of this playbook is simple: treat agents like real teammates with a job description, operating procedures, and performance reviews. With disciplined workflow design, a retrieval-first pipeline, and outcome-level instrumentation in Amplitude, agentic AI stops being a science project and starts compounding into durable product-led growth.
Inspired by this post on Amplitude – Perspectives.
Over the last year, I’ve had the same conversation with a lot of support leaders.
They’ve deployed AI and are seeing initial efficiency gains, but want to push beyond these early results and achieve meaningful transformation.
When AI is first introduced, the gains show up quickly. Teams resolve higher volumes of queries, free up capacity, and deliver faster responses. But the real opportunity for impact extends well beyond those initial wins. As AI becomes more deeply integrated into support operations, taking on harder, more complex work, those results compound, new ways to create and measure value open up, and the economics of support change entirely. That shift is where I spend most of my time with leaders—turning early efficiency into durable business value.
This sits at the heart of “The 2026 Customer Service Transformation Report.” In this reflection, I explore how deeper integration compounds impact and why that makes business value easier to articulate across the organization—especially to finance and product peers who need to see outcomes, not just output.
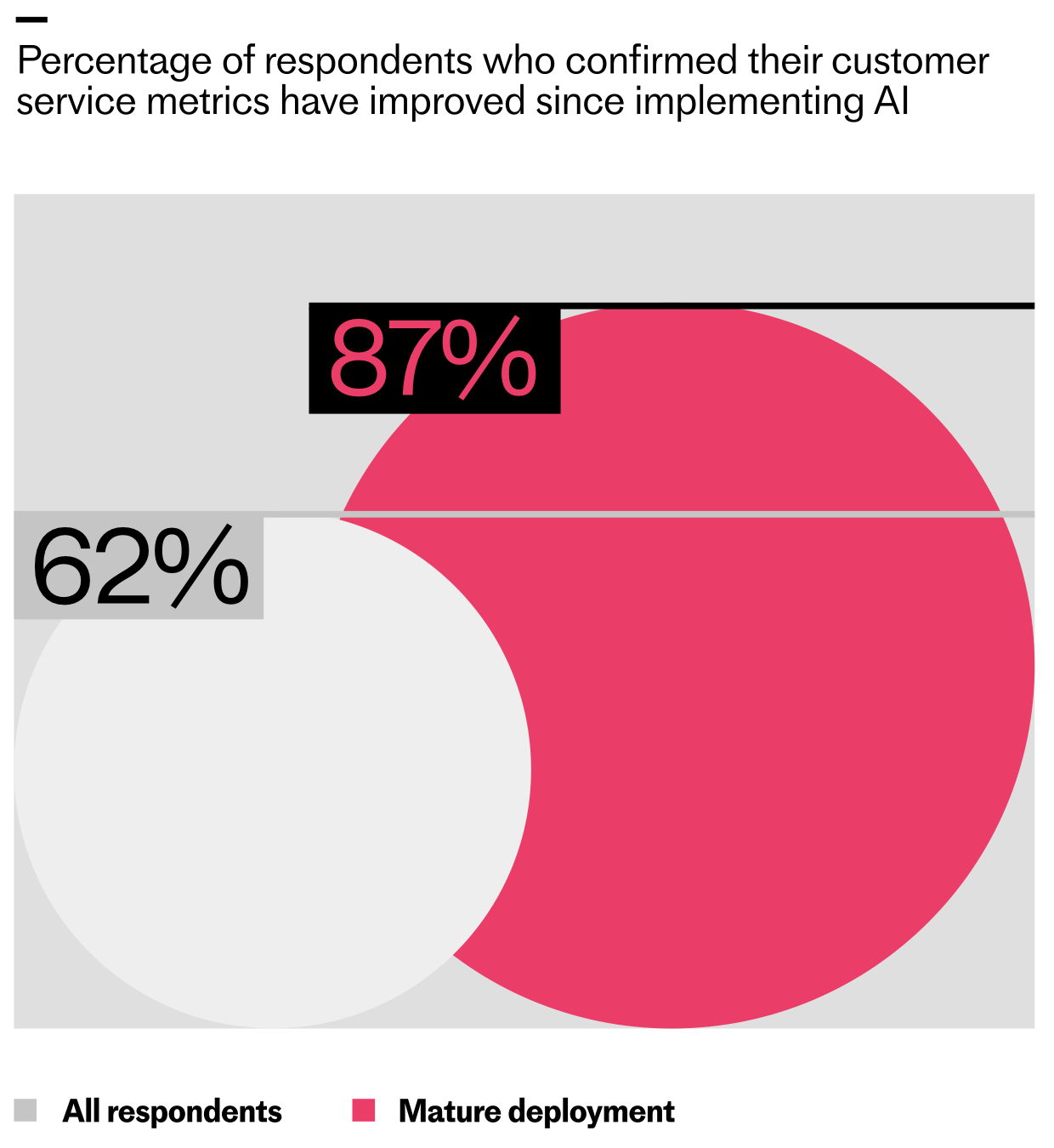
The teams going deeper are seeing higher returns. The research shows that 62% of support teams have seen their customer service metrics improve since implementing AI, with early wins showing up most clearly in speed and efficiency. But for teams that have reached mature deployment (where AI is fully integrated into operations) that number jumps to 87%.
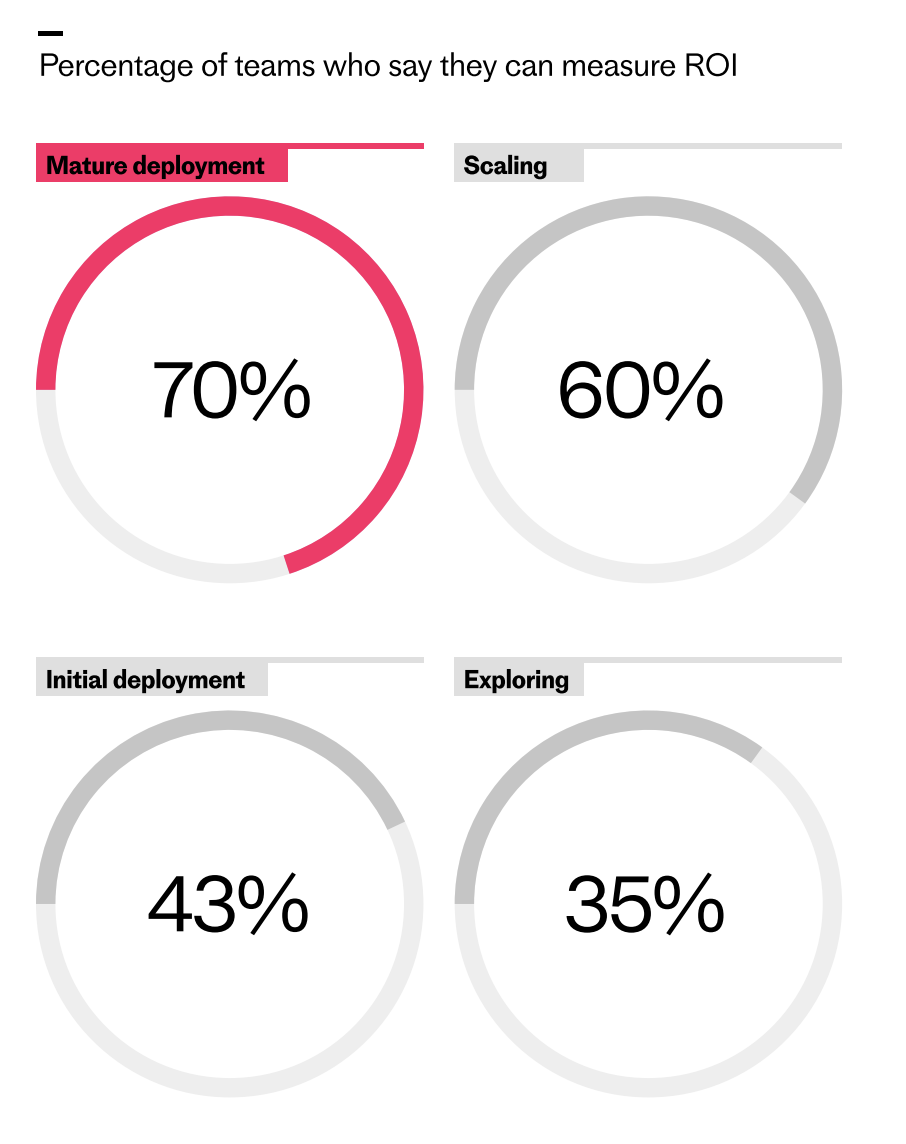
As AI programs advance, measurement confidence surges. This chart shows how ROI tracking rises from 35% in exploring to 70% in mature deployments—evidence of a widening execution gap in customer service.
The same pattern holds for the ability to measure ROI. Among teams in early exploration, just 35% say they can measure their return on AI investment, but for teams at the mature deployment stage, that rises to 70%. In my experience, this is the moment the conversation shifts from “is AI working?” to “how much leverage are we creating?”
As AI becomes more embedded in support workflows, what teams choose to measure starts to change. In the early stages of deployment, ROI is typically understood through improved customer response times, lower cost to serve, and freeing up capacity. Teams focus on how much time AI creates and whether it’s relieving pressure on the support organization. These signals help validate that the system is working, but they say little about how that capacity is ultimately used.
As deployments mature, measurement starts to reflect a different intent. Instead of stopping at time saved, teams look at where that capacity is reinvested—into higher value customer work and revenue-generating activities. ROI becomes less about relief and more about leverage. I encourage teams to set targets for capacity redeployment and tie them directly to activation, retention, and expansion outcomes.
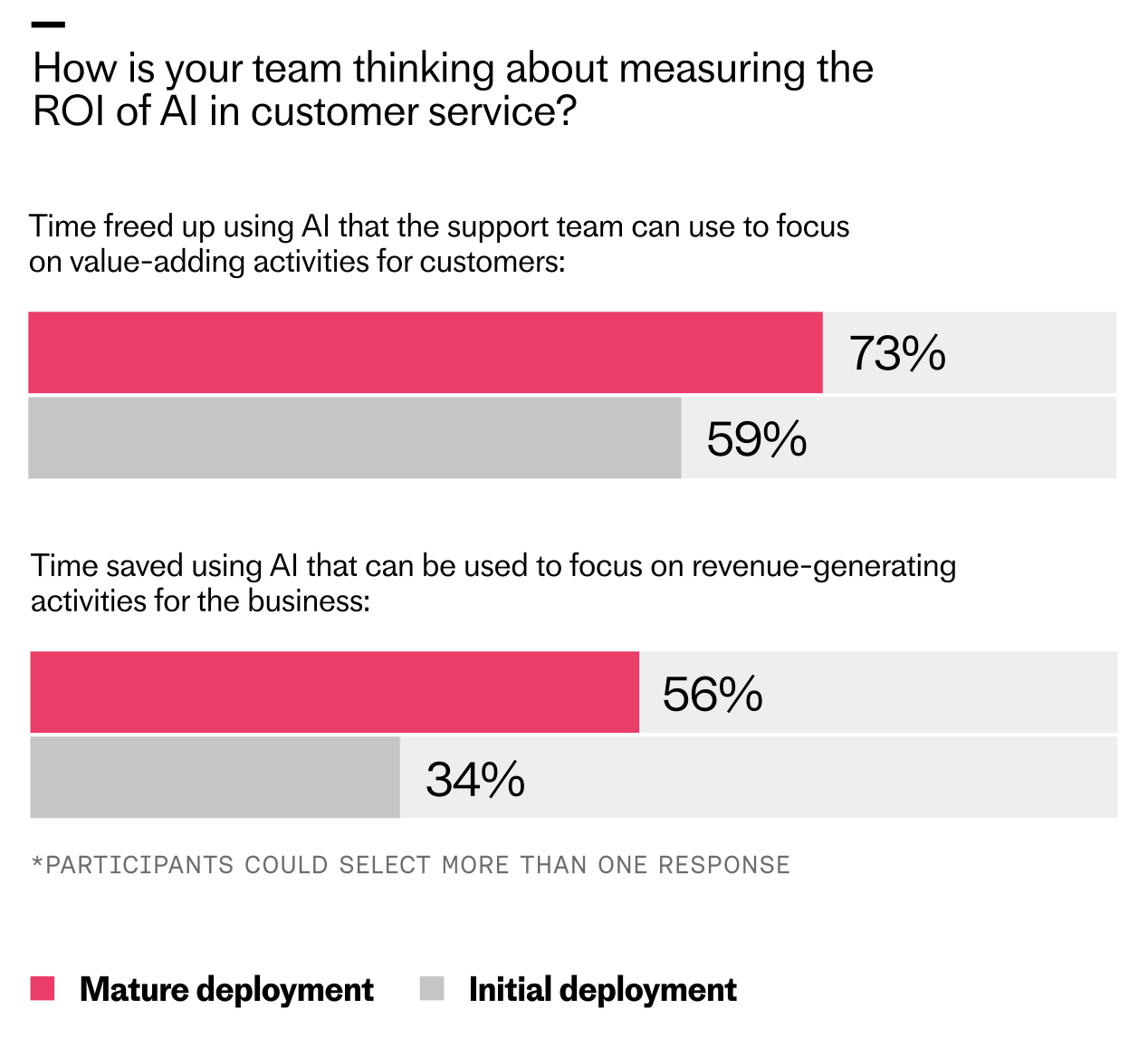
The report data shows this clearly. Across all maturity stages, the most commonly cited measure of ROI is "time freed up that the support team can use to focus on value-adding activities for customers." But at mature deployment, that signal intensifies, with 73% of teams citing it, compared to 56% at early exploration.
Mature AI deployments reveal clearer ROI: teams report more time freed for value-adding customer work (73% vs 59%) and more hours redirected to revenue-generating tasks (56% vs 34%) than initial rollouts.
What’s also interesting is that 56% of mature teams say freed capacity is being directed toward revenue-generating activities, up from 34% at initial deployment. That’s a powerful indicator that AI is shifting from a cost narrative to a growth narrative.
The result is a shift in economic intent: from measuring what AI saves to demonstrating how the capacity it creates is reinvested to drive growth. As a product leader, I anchor this conversation in outcome-based metrics and clear counterfactuals: what would it have cost to deliver the same experience without AI?
As AI takes on more work, the question moves from “does it save money?” to “how does it change the economics of support?” Legacy support economics were built for linear growth: more customer tickets meant more headcount, more outsourcing, and more software costs. Success was measured through containment—the number of queries that didn’t reach human agents. These models worked when volume and effort were tightly linked, but AI doesn’t scale linearly, and it needs to be evaluated differently.
To sustain AI investment and expand its impact, teams need to move beyond cost-cutting narratives and build a clearer case for business value. When done right, AI goes far beyond improving support efficiency. It rewires the financial model, breaking the link between support costs and revenue growth, and turning support into a contributor to customer activation, retention, and lifetime value. This means treating your AI Agent as a new workforce capability that changes how your support function creates and captures value. Here’s what value looks like in an AI-first model:
Deeper AI integration decouples growth from headcount. This split chart shows support volume surging while team size plateaus, revealing how automation unlocks scale, reduces costs, and makes ROI easier to prove.
Human productivity: Your team focuses on more strategic areas, not the queue.
System improvement: Every resolved query makes the system smarter.
Revenue influence: Support becomes a lever for activation, retention, and growth.
Organizational agility: You scale service without scaling headcount.
Leaders are racing ahead with real AI in support. Explore the 2026 Customer Service Transformation Report to see where deployment is stalling, benchmark your team, and get practical steps to scale automation that delights.
How does this look in practice? Intercom offers a compelling example with Fin. What started as a focused effort to improve their customer support experience has become one of the clearest illustrations of what happens when AI is fully embraced across an organization.
Since 2022, Fin has helped Intercom absorb more than a 300% increase in customer demand while improving the consistency of delivery—including supporting new routes into support for trial customers and website visitors. Today, Fin is involved in 97% of their customers' conversations. Of those, it resolves 83.5% end-to-end, putting their overall automation rate at 81%.
That depth of deployment allowed Intercom to scale service without scaling headcount. Without Fin, they would have needed at least 100 additional support teammates to meet rising demand and service standards.
As Fin took on the majority of day-to-day volume, the human support team shifted toward consultative work—helping customers adopt Fin more deeply, succeed faster, and unlock more value from the platform. Intercom now tracks metrics like “direct revenue generated” and “expansion revenue influenced” to understand the impact of these consultative support activities. This repositioned support from a cost center to an active contributor to long-term growth.
The throughline from The 2026 Customer Service Transformation Report is that deployment depth makes a significant difference. Teams that are investing in deeply integrating AI are reshaping how support scales and contributes to growth. Value becomes clearer as AI takes on more work, and support leaders can articulate that value to the rest of the business.
The gap between these teams and those still in the early stages is widening. A select group of pioneers are setting a new bar for what AI-powered customer service can deliver, and understanding what they’re doing differently is the first step toward closing that gap. If you want to dive deeper into the data and frameworks, you can download the report here: https://www.intercom.com/customer-transformation-report?utm_source=blog&utm_medium=internal&utm_campaign=20260128-report-owned-2026cstransformationreport&utm_content=chapterseries_2
If your team has plenty of dashboards but still spends too much time turning a product question into a cohort, an explanation, and a decision, the bottleneck is no longer data collection. It is the work between asking the question and acting on the answer.
Treat the upgrade as a decision system, not an AI shortcut
A weak rollout starts by giving everyone access and encouraging them to try prompts. That produces activity, but it does not establish whether the technology is improving product work.
Define the unit of value as a completed decision. Each use of AI Visibility should move through a traceable sequence:
Start with a specific product question that could change an action.
Translate the question into an explicit cohort and metric definition.
Examine the relevant behavioral evidence.
Draft a narrative that separates observations from interpretations.
Record the decision, owner, and next action.
The enhancements reduce different kinds of friction inside that sequence. AI chat can reduce the interface work involved in expressing a segment. Content generation can reduce the effort required to turn analysis into a readable brief. A clearer interface can make the workflow easier for cross-functional partners to follow. Reliability improvements can support confidence in the system. None of those changes removes the need to define the question or approve the conclusion.
I would begin with two or three recurring, high-value use cases, not every analytics task. A good pilot question appears often, has a trusted baseline for comparison, and ends in a recognizable decision. Activation analysis, churn exploration, and experiment reporting meet those conditions for many product teams.
Match each enhancement to a concrete product job
Do not ask a team to use AI for analytics in the abstract. Give each workflow an input contract: the decision being considered, the population, the behavior, the observation period, the metric, and the exclusions. This prevents a fluent prompt from hiding an underspecified question.
Find an activation bottleneck without redefining activation
An activation question usually sounds simple: which new users reach value, and where do the others stop? The difficult part is deciding what counts as a new user, what behavior represents value, how long the observation period lasts, and which internal or test activity should be excluded.
Set those definitions before opening AI chat. Then describe the desired cohort in behavioral language and use chat-driven segmentation to iterate on it. Before analyzing the result, compare the AI-created segment with a known cohort, a manually configured version, or an established dashboard. If the populations differ, investigate the definition rather than explaining the chart.
Once the segment is accepted, use content generation to draft a brief that identifies the observed drop-off, the affected population, the relevant comparison, and the question that deserves further discovery. Keep causal language out unless the evidence supports it. A funnel can show where behavior changes; it does not, by itself, explain why.
Explore churn precursors without turning correlation into cause
Churn analysis becomes unreliable when a cohort mixes users who never activated, customers who became inactive, and accounts that formally cancelled. Those are different states with different product implications.
Write a plain-language definition of the state you care about before generating the segment. A useful prompt pattern is: create a cohort of the specified customer population that completed the core behavior during the reference period but did not complete it during the comparison period; exclude internal and test activity; then separate the result by the business attribute relevant to the decision.
Use AI chat to test legitimate variations in that definition, not to invent the definition for you. When a behavioral difference appears, label it as a precursor or association until customer evidence or an experiment supports a causal explanation. The next action may be another analysis, a customer interview, or a retention experiment. It should not automatically be a roadmap commitment.
Draft experiment reports without delegating the decision
AI-generated experiment summaries are useful because the structure is repetitive even when the decision is not. Give the system the approved hypothesis, eligible population, exposure definition, primary outcome, guardrail measures, and underlying analysis. Ask for a draft that covers what changed, what remained uncertain, which segments require caution, and what decision the evidence supports.
The generated narrative should never become the statistical authority. The experiment analysis remains the record for effect estimates, uncertainty, and data-quality caveats. The brief exists to make that evidence understandable and actionable. If the prose and the analysis disagree, correct the prose before it travels to stakeholders.
Put human review around definitions and conclusions
AI can make a loosely defined request look finished. That is the central operating risk. The safest control is to review the workflow where meaning enters and where meaning leaves: validate the segment before interpreting the result, then validate the narrative before sharing it.
Validate the segment before reading the result
Confirm the identity unit. A user, device, workspace, and customer account are not interchangeable.
Check that event names and properties map to the team’s current tracking taxonomy.
Make inclusion rules, exclusions, sequence requirements, and observation periods explicit.
Compare membership or aggregate trends with a trusted manual definition when one exists.
Inspect surprising differences before using them as evidence. A mismatch may come from the cohort definition rather than user behavior.
Store a plain-language definition with the accepted cohort so another person can reproduce the analysis.
Validate the narrative before distributing it
Require each material claim to point back to a chart, table, or approved metric.
Separate observed behavior from a proposed explanation.
Verify that the population, date range, and comparison in the prose match the analysis.
Remove unsupported causal language and any detail the audience is not permitted to access.
State the decision, the remaining uncertainty, and the person responsible for the next action.
Content generation reduces drafting work; it does not transfer review responsibility to the model. This distinction is especially important for executive briefs, where polished language can make a weak inference appear more certain than it is.
Govern prompts, access, and workflow changes
Basic prompt templates, access policies, review steps, and data-governance controls turn experimentation into a repeatable capability. A prompt template should specify the business question, required definitions, exclusions, expected output, evidence standard, and reviewer. Access should follow the same least-privilege principles applied to the underlying analytics data.
Reliability also needs operational visibility. Keep a lightweight record of the original question, accepted cohort definition, supporting analysis, generated brief, reviewer, and resulting decision. When an answer changes unexpectedly, that record helps you distinguish a tracking problem from a cohort change, a prompt change, or an interpretation error.
Measure whether the rollout changes product decisions
Prompt volume and generated summaries are adoption signals, not proof of value. Establish a baseline before the pilot, run the selected use cases through the new workflow, and compare the result using measures tied to decisions.
Signal
How to observe it
What a weak result means
Time-to-insight
Track elapsed time from an accepted question to a reviewed analysis brief.
If the time does not fall, find the handoff or review step that still creates delay.
Stakeholder adoption
Track whether product, design, engineering, growth, and leadership use the workflow in recurring decisions.
If only analysts use it, the interface or output may not fit cross-functional work.
Decision velocity
Track elapsed time from requesting evidence to recording an explicit decision or next action.
If output increases but decisions do not move sooner, the workflow is producing content rather than clarity.
Review quality
Count material corrections to cohort definitions, metrics, and conclusions before and after sharing.
If rework rises, improve the event taxonomy, prompt contract, validation process, or reviewer guidance before expanding access.
Trust exceptions
Record cases in which an AI-assisted result conflicts with validated analytics or cannot be reproduced.
If exceptions persist, pause expansion and resolve the data, definition, or workflow problem.
Judge the pilot as a system. Faster segmentation with heavy correction is not a win. Faster drafting with unchanged decision velocity is not a win either. The useful outcome is a shorter path from question to reviewed decision, with stable or improving quality.
Expand only after the pilot workflow is reproducible. At that point, turn the accepted prompt patterns, cohort definitions, review criteria, and measurement approach into a shared operating playbook. The cleaner interface can help more partners participate, but the playbook is what keeps participation consistent.
Key takeaways
Use Amplitude AI Visibility to shorten a decision workflow, not merely to increase the volume of segments and summaries.
Begin with two or three recurring use cases that have trusted baselines and recognizable decisions.
Define the population, behavior, period, metric, and exclusions before asking AI to create a segment.
Validate cohort meaning before interpreting behavior, then validate the generated narrative before sharing it.
Scale the workflow only when faster output is accompanied by reproducibility and sound review.
Choose the next recurring product decision that still involves too much manual translation. Write its input contract, capture its current path to a reviewed decision, and use that single workflow to determine whether AI Visibility is removing the right friction.
“Continuous Discovery Habits” turns five this year, and I’m celebrating by reading the book together with you. Each month, I’m releasing an in-depth reading guide designed for empowered product teams and product trios—complete with the chapters we’ll read, a preview of the key concepts, short shareable videos, individual and team discussion prompts, team exercises you can run immediately, and additional reading to go deeper.
We’ll discuss each month’s reading in the comments, and we’ll gather quarterly for live calls. If you’re joining late, no problem—I’ll be monitoring comments throughout the year. Start with the current month or go back to January (https://www.producttalk.org/lets-read-continuous-discovery-habits-together-january-2026/). Jump in where it serves you best, ask for help, share what’s working, and connect with other readers any time.
If you want to participate, grab a copy of the book (https://amzn.to/3hGkNYT?ref=producttalk.org)—or dust off your old one—share the “Spread the Love” videos with your colleagues, set aside time to run the team exercises, and register for the community sessions. Let’s do this.
This Month’s Reading
Chapters: Chapter 3: Focusing on Outcomes Over Outputs
Estimated reading time: ~22 minutes
This chapter zeroes in on the critical difference between business outcomes and product outcomes—and why it matters which one your team is assigned; how to translate lagging business metrics into actionable product outcomes you can actually influence; why setting outcomes should be a two-way negotiation between leaders and product trios; when to start with a learning goal versus a performance goal; and five common anti-patterns that derail outcome-focused teams. Need a copy? Grab the book (https://amzn.to/3hGkNYT?ref=producttalk.org).
Share the Love with Friends and Colleagues
We learn best in community. I like to seed conversations across my org with short, high-signal content—especially when I’m shifting a culture from outputs to outcomes and sharpening OKRs. Use these short videos to bring peers into the conversation and invite them to read along:
“What’s an outcome?” (https://videos.producttalk.org/videos/ea9fdab71d1ee3c263/whats-an-outcome?ref=producttalk.org) — The real value of starting with an outcome. “Business outcomes vs. product outcomes” (https://videos.producttalk.org/videos/069fd5b5101ee2c78f/business-outcomes-vs-product-outcomes?ref=producttalk.org) — Why product teams need product outcomes, not business outcomes. “What’s the difference between OKRs and outcomes?” (https://videos.producttalk.org/videos/069fdab61919e4c38f/whats-the-difference-between-okrs-and-outcomes?ref=producttalk.org) — Any outcome can be represented as an OKR. “Understanding revenue model formulas” (https://videos.producttalk.org/videos/799fd5b5101ee2c4f0/understanding-revenue-model-formulas?ref=producttalk.org) — How to identify the business outcomes your company cares about. “Revisit your outcome every quarter” (https://videos.producttalk.org/videos/449fd5b4111ee0cfcd/revisit-your-outcome-every-quarter?ref=producttalk.org) — Don’t abandon your outcome, but do revisit how you measure it.
Reflect and Discuss What You Read
Reflection is the conversion rate optimizer for learning. When we pause to discuss what we’re reading, we retain more and apply it faster—especially in product discovery and product strategy work. This chapter challenges us to update our definition of success: away from features shipped and toward outcomes achieved. This month, I’m examining my own relationship with outcomes—where I’ve been rigorous, where I’ve drifted, and how I can help my teams strengthen day-to-day behaviors.
Individual Reflection
If your team isn’t working toward an outcome, look at the features or projects on your roadmap and ask: What impact are they supposed to have? If they succeed, what customer behavior or business result would change? If your team does have an outcome, consider whether it’s a business outcome, a product outcome, or a traction metric—and how that choice shapes your daily decisions and discovery cadence. Finally, think about the last time your team’s outcome changed: Was it a deliberate strategic shift, or did it feel like ping-ponging from one priority to the next?
Team Discussion
As a team, classify your current outcome: Is it a business outcome, a product outcome, or a traction metric? If it’s a business outcome, identify the leading customer behaviors that would signal momentum; if it’s a traction metric, broaden it to a product outcome that gives you more room to explore. Then, name which of the five anti-patterns (pursuing too many outcomes, ping-ponging, individual outcomes, outputs as outcomes, or tunnel vision) shows up for you and pick one concrete change. Finally, assess how outcomes are set: Are they handed down, or does your product trio co-create them? What would it take to make this a true two-way negotiation?
Put It Into Practice
Understanding the difference between business outcomes and product outcomes is table stakes. Translating one into the other is where product management leadership shows up. These exercises will help you connect company goals to customer behavior, avoid outcomes vs output OKRs traps, and increase your span of control over meaningful change.
Exercise: Map Your Revenue Model
Time: 30 minutes. Do this: Solo first, then share with your team. Start with this question: How does your company make money? Write out the formula for your revenue model. For example, a subscription business might be: Revenue = Number of Customers × Average Monthly Spend × Retention. Once you have the formula, identify each variable as a potential business outcome. Then, for each business outcome, brainstorm two to three product outcomes (customer behaviors or sentiments) that might be leading indicators. Which of these product outcomes is your team best positioned to influence?
Exercise: Audit Your Current Outcome
Time: 45 minutes. Do this: With your product trio. Take your team’s current outcome and run it through a quick diagnostic: Is it a business outcome, product outcome, or traction metric? If it’s a business outcome, what product outcomes might drive it? If it’s a traction metric, how might you broaden it to a product outcome? Is it a leading indicator or a lagging indicator? Can you measure progress weekly, or do you have to wait months? Is it within your team’s span of control? Based on your answers, draft a revised outcome that offers more actionable feedback while still connecting to business value, and prepare to discuss this with your product leader.
Go Deeper: Additional Reading
If you prefer an audio summary of this month’s reading, including the book chapter and the resources below, I’ve included an audio version at the end of this post for paid subscribers.
Related In-Depth Guide: Shifting from Outputs to Outcomes: Why It Matters and How to Get Started (https://www.producttalk.org/shifting-from-outputs-to-outcomes/).
Supplementary Reading: Empower Product Teams with Product Outcomes, Not Business Outcomes (https://www.producttalk.org/2020/05/product-outcomes/). Defining Product Outcomes: The 8 Most Common Mistakes You Should Avoid (https://www.producttalk.org/2022/12/defining-product-outcomes/). Understanding How Product Outcomes Connect to Revenue and Costs (https://www.producttalk.org/2023/04/connecting-product-outcomes-to-revenue-and-costs/). Product in Practice: Iterating to an Actionable Outcome at tails.com (https://www.producttalk.org/2020/08/actionable-outcomes/). Product in Practice: Iterating on Outcomes with Limited Data (https://www.producttalk.org/2023/12/iterating-on-outcomes-with-limited-data/). Measurable Outcomes – All Things Product with Teresa Torres and Petra Wille (https://www.producttalk.org/measurable-outcomes-all-things-product-podcast-with-teresa-torres-petra-wille/).
Other Voices: The Business Equation by Brett Bivens (https://venturedesktop.substack.com/p/the-business-equation?ref=producttalk.org). KPI Trees: How to Bridge the Gap Between Customer Behavior, Product Metrics, and Company Goals by Petra Wille and Shaun Russell (https://www.petra-wille.com/blog/kpi-trees-how-to-bridge-the-gap-between-customer-behavior-product-metrics-and-company-goals?ref=producttalk.org). Persistent Models vs. Point-In-Time Goals by John Cutler (https://cutlefish.substack.com/p/tbm-2553-persistent-models-vs-point?ref=producttalk.org). Is It Time to Ditch the Old SaaS Metrics? by Kyle Poyar (https://openviewpartners.com/blog/saas-metrics-plg/?ref=producttalk.org). How Engagement Metrics Can Be Misleading by Oleg Yakubenkov (https://gopractice.io/blog/how-engagement-metrics-can-be-misleading/?ref=producttalk.org). Subscription Churn Metrics and Benchmarks for Operators by Elena Verna (https://www.elenaverna.com/p/subscription-churn-benchmarks-and?ref=producttalk.org).
Related Courses: Business Fundamentals: Navigate Your Business Context with Confidence (https://learn.producttalk.org/course/business-fundamentals?utm_source=Product+Talk&utm_medium=cdh-book-club-february-2026).
Our Live Discussion Schedule
Our live discussion sessions are for paid subscribers and will not be recorded. Invitations will go out to Supporting Members and CDH Members (http://members.producttalk.org/?ref=producttalk.org) two weeks before each event—reserve time on your calendar now so you can participate fully and bring real examples from your team.
Wednesday, March 18, 2026: 9am–10am PDT and 4pm–5pm PDT. Tuesday, June 16, 2026: 9am–10am PDT and 4pm–5pm PDT. Thursday, September 17, 2026: 9am–10am PDT and 4pm–5pm PDT. Wednesday, December 16, 2026: 9am–10am PST and 4pm–5pm PST.
Audio Summary
Prefer to listen? I’ve included an audio summary—Stop Measuring Code Start Measuring Behavior—at the end of this post so you can review the main ideas on your commute or between meetings.
I’m excited to dive into outcomes with you this month. As a product leader, I’ve seen teams transform their product discovery, product roadmapping and sprint planning, and OKR quality when they anchor on clear product outcomes tied to business value. Let’s build that muscle together and make this a quarter where we stop measuring output and start driving outcomes.
I stopped treating churn as a postmortem and started treating it as a forecasting problem. When we instrument our product, connect the dots across journeys, and embed those signals into our daily operations, churn becomes predictable—and preventable. This shift has been one of the most impactful product strategy moves my teams have made for product-led growth and retention analysis.
"Discover why and how CS teams can use digital analytics to take a proactive, predictive approach to churn, stopping it before it happens." That is exactly the mindset I bring to customer success and product collaboration: anticipate risk, intervene with precision, and demonstrate measurable impact.
The practical work starts with leading indicators. I look at user activation milestones, time-to-first-value, feature adoption depth, frequency and recency of key events, account-level coverage (are multiple users active or just one champion?), usage volatility, and friction signals like repeated errors or stalled onboarding. These behavioral inputs are stronger predictors of churn than survey sentiment alone.
From there, I create a churn risk score. Early on, a transparent rules-based model is usually enough to separate healthy from at-risk accounts. Over time, we can layer in supervised learning if the data supports it. I rely on Amplitude analytics, Pendo, or a unified analytics platform to tag events, build cohorts, and compute risk in near real time. This is where we consistently see the patterns that matter—especially around user activation and sustained adoption.
Signals without action won’t save a customer, so I connect the model to our systems of engagement. Through CRM integration, at-risk accounts trigger clear playbooks for CSMs and lifecycle marketers. Inside the product, in-app guides address gaps exactly where they occur—guiding users to the next best action, unblocking onboarding, or showcasing the value hidden behind underused features.
Because not every nudge works for every segment, we treat intervention design as a product problem and run A/B testing on copy, timing, channel, and offer. We test whether a contextual tooltip outperforms an email sequence, whether a short product tour beats a knowledge base link, and which incentives accelerate onboarding without cannibalizing expansion.
Operationally, this is a team sport. Product, CS, and marketing meet in product trios to review risk cohorts, prioritize root-cause fixes, and tune playbooks. We run a weekly risk review to turn insights into decisions, and we use monthly business reviews to connect leading indicators to lagging outcomes like retention, expansion, and NRR.
Measurement is non-negotiable. We pair retention analysis with qualitative feedback to understand whether our interventions truly change behavior. The goal is to close the loop: when a risk cluster improves, we codify the playbook; when a tactic underperforms, we learn, adjust, and try again. Over time, the organization builds a muscle for proactive, data-informed customer health management.
If you’re getting started, begin by instrumenting events tied to value moments, define a simple health score, and stand up a basic alerting workflow. Pilot one or two interventions, measure lift, and iterate. Within a single quarter, you’ll have enough signal to prioritize product improvements and scale the practices that reliably reduce risk.
Churn rarely surprises teams that listen to their data and respond in real time. With disciplined analytics, thoughtful in-product guidance, and tight alignment across CS and product, we can move from reacting to predicting—and keep more customers succeeding with far less effort.
Inspired by this post on Amplitude – Perspectives.
Customer feedback is the most reliable compass I have for product strategy and execution. Over the years leading product at HighLevel, I’ve built and refined a system that turns raw signals from users into clear, prioritized decisions our teams can confidently ship.
A practical guide to collecting and using product feedback in product management (from AI tools to early-stage tactics) for better product decisions.
My playbook starts with continuous discovery. I keep a steady flow of insights from sales calls, customer support threads, community forums, and in-product behavior so I can triangulate patterns rather than chase loud anecdotes. This mix of quantitative and qualitative data helps me separate urgent noise from strategically meaningful trends.
On the quantitative side, I rely on product analytics to ground the conversation. Amplitude analytics gives me activation, retention cohorts, and feature engagement, while controlled experiments and A/B testing validate whether an idea actually moves a target metric. Tying these signals to specific customer segments helps me see where product-led growth is working—and where it’s stalling.
For qualitative insight, I combine in-app guides and lightweight surveys (via tools like Pendo) with structured interviews and support escalations (often surfaced through platforms like Intercom). I map problems using the Kano Model to understand which requests are basic expectations, which are performance drivers, and which are potential delights. This keeps our roadmap focused on outcomes, not just outputs.
AI now accelerates the synthesis step. With LLMs for product managers in my AI product toolbox, I summarize interview transcripts, cluster themes across thousands of notes, and quantify sentiment without losing nuance. I still review raw artifacts to avoid hallucinations and preserve context, but AI reduces the time from signal to insight dramatically—freeing me to spend more energy on judgment and storytelling.
In early-stage contexts, I bias toward speed and proximity to users. I schedule founder- or PM-led discovery calls weekly, instrument product tours early, and launch scrappy in-product prompts to validate demand before over-investing. When data is sparse, I focus on high-signal channels (power users, churned customers with qualified use cases) and document crisp problem statements that connect directly to activation, retention analysis, and revenue outcomes.
Prioritization ties everything together. I translate insights into hypotheses aligned to outcomes vs output OKRs, then pressure-test them with feasibility and strategic fit. We run small, measurable experiments, track deltas in activation and retention, and adjust the product roadmapping and sprint planning cadence based on what the data and customers teach us.
This approach builds trust with stakeholders and creates empowered product teams. By grounding decisions in a transparent trail of feedback, analytics, and experiments, we reduce thrash, move faster, and—most importantly—ship product moments that customers value.
If you’re refining your own feedback engine, start by instrumenting the basics, set a weekly discovery rhythm, and let AI handle the heavy lifting on aggregation and synthesis. The compounding effect is real: better insights lead to better bets, which lead to better outcomes for your users and your business.
Your roadmap can be coherent, the launch can go smoothly, and adoption can still stall. The usual gap is not a lack of effort. Product strategy, field discovery, technical validation, and post-launch adoption were treated as separate activities, so each team learned something that the others could not use.
You can close that gap by treating solutions engineering as part of the product learning system. The goal is not to give sales more technical coverage or product managers a larger queue of requests. It is to turn real customer conditions into testable product decisions, then follow those decisions until customers reach and repeat the intended outcome.
Key takeaways
Define adoption as an observable customer behavior before you approve features or plan a launch.
Ask solutions engineers to capture evidence in a consistent format, separating what happened from what the team thinks it means.
Treat demos and proofs of value as experiments with a hypothesis, baseline, value event, and decision rule.
Measure the entire path from promise to repeated value. A login, click, or feature visit is rarely sufficient evidence of adoption.
Route each adoption problem to the right response: positioning, enablement, onboarding, integration, product design, or core capability.
Carry launch learning into roadmap and operating reviews so that adoption changes product decisions instead of becoming a reporting exercise.
Write the adoption contract before debating the roadmap
Product strategy becomes operational only when it specifies whose behavior should change, why that change matters, and what evidence would show that the product created value. Without that translation, teams can agree on a strategic theme while holding incompatible ideas about what success means.
Write an adoption contract for every significant product bet. This is not a legal document or a long requirements package. It is a compact agreement among product, engineering, design, solutions engineering, sales, and customer success about the outcome being pursued.
Target user: Name the persona and operating context. A broad account segment is not enough when different people inside the account perform different jobs.
Starting condition: Describe the workflow, constraint, or workaround that exists before the change. This gives you a baseline against which the new experience can be judged.
Desired outcome: State the progress the customer wants, not the capability you intend to ship.
Value event: Identify the observable behavior showing that the user reached meaningful value. Opening a page may indicate exposure; completing the intended workflow is stronger evidence.
Repeat condition: Define what sustained use looks like at the natural cadence of the workflow. Daily activity is useful only when the job itself occurs daily.
Decision evidence: Agree on the metric, qualitative evidence, technical constraints, and guardrails that will determine whether to continue, change, or stop the bet.
Suppose a product automates part of an operations workflow. Increase feature adoption is too weak to guide a team. A more useful contract says that the operations manager can complete the target workflow, obtain the intended result, and return to it when the job recurs without relying on the old workaround. The team can now examine setup, permissions, integrations, comprehension, completion, and repetition as separate parts of the same outcome.
This contract also changes roadmap conversations. A feature request no longer competes on enthusiasm alone. You can ask which persona it serves, which blocked outcome it unlocks, what evidence supports the problem, and which customer behavior should change if the solution works. If those questions have no answers, the request needs more discovery before it needs an estimate.
Keep the contract stable enough to align the organization, but do not protect it from evidence. If customers repeatedly pursue a different outcome, struggle with an unanticipated dependency, or assign value to another part of the workflow, revise the contract explicitly. Silent reinterpretation is dangerous because every function can declare success against a different definition.
Turn solutions engineering into a field evidence system
A solutions engineer sees details that rarely survive a conventional feature request: the customer’s existing architecture, the sequence of the workflow, the people involved in approval, the point at which a demonstration loses credibility, and the difference between a stated objection and an actual blocker. That information can improve strategy, but only if the organization captures it in a form that product teams can compare and act on.
Do not send raw call notes into a backlog and call it discovery. Use a consistent field record containing:
The persona, account context, and job being attempted.
The customer’s desired outcome and current way of achieving it.
The specific moment where the current product or proposed solution created friction.
The relevant technical condition, such as an integration, data, permission, security, or scalability constraint.
The evidence observed: customer behavior, workflow review, demonstration response, deployment result, or instrumented product data.
The proposed interpretation and any plausible alternative explanation.
The next question or test that would reduce uncertainty.
Within that record, separate observation, interpretation, and request. They are not interchangeable.
Observation: The administrator could not complete configuration because a required permission was unavailable.
Interpretation: The permission model may not match how this persona operates.
Request: Add a new administrative role.
The observation is evidence. The interpretation is a hypothesis. The request is merely a candidate solution. Keeping them separate prevents the first proposed feature from becoming the definition of the problem.
Product leaders also need to protect this system from deal gravity. A commercially urgent request can be important without representing a widespread product problem. Conversely, a small implementation detail can reveal a structural barrier affecting an entire target persona. Evaluate field evidence with questions that make those differences visible:
Does the problem recur for the same persona, workflow, or environment?
Does it block the value event, or does it affect a peripheral preference?
Is the root cause a missing capability, product usability, configuration, integration, positioning, or customer process?
Does the problem appear in the strategic segment the product is designed to serve?
Can a smaller or reversible test distinguish competing explanations?
What roadmap decision would change if the hypothesis were confirmed?
The last question is a useful filter. If no plausible answer would change a decision, the team may be collecting interesting information rather than decision-grade evidence.
Bring the strongest records into the product trio’s learning cycle. Field evidence can then sharpen roadmaps, sprint planning, positioning, integration decisions, and stakeholder conversations. The solutions engineer contributes technical discovery and customer context. Product management synthesizes patterns and owns tradeoffs. Design examines behavior and workflow. Engineering tests feasibility and exposes architectural consequences. Sales contributes commercial context without converting urgency into automatic priority. Customer success adds evidence about repeated use after the initial deployment.
This arrangement does not require every customer conversation to become a committee meeting. It requires a common evidence format, clear decision ownership, and a route by which meaningful field learning reaches the people making product choices.
Run demos and proofs of value as product experiments
A polished demo can prove that a presenter understands the product. It does not prove that a customer can adopt it. Even a successful technical pilot can produce a false positive if the solutions engineer performed work that the target user cannot repeat, the environment was unusually controlled, or the team never defined what customer value would look like.
Design every proof around a falsifiable outcome hypothesis. A practical structure is:
For [persona] in [context], enabling [change] should produce [observable behavior] because [value mechanism]. The hypothesis is supported if [agreed evidence] meets [predefined decision rule] without violating [guardrail].
The brackets force useful decisions. You have to name the user, the operating condition, the expected behavior, and the reason the behavior represents value. You also have to decide what would count as failure before enthusiasm about the result changes the standard.
Build the proof plan around the following elements:
Baseline: Document how the customer handles the job now, including meaningful friction and dependencies.
Scope: State which workflow, persona, environment, and constraints the proof includes. Anything outside that boundary remains unvalidated.
Value event: Identify the customer action or result that demonstrates progress toward the desired outcome.
Instrumentation: Decide which product events and qualitative observations will show where users advance or stop.
Enablement: Record how much assistance the customer receives. Heavy expert intervention can validate technical feasibility while leaving self-service adoption unproven.
Decision rule: Define what evidence will justify progression, iteration, repositioning, or stopping.
Learning owner: Name the person responsible for translating the result into a product, go-to-market, or adoption decision.
A compact learning record can follow Insight – Hypothesis – Experiment – Metric. The sequence matters. A customer comment produces an insight, not a roadmap commitment. The insight leads to an explanation that can be tested. The test produces evidence against a metric or decision criterion.
Capture objections with the same discipline. An objection about missing functionality may actually reflect an unclear value proposition, concern about integration effort, lack of trust in the output, or a mismatch between the buyer and the eventual user. Ask what the customer is unable or unwilling to do because of the concern. That question moves the discussion from the requested feature to the blocked behavior.
At the end of a proof, classify what was learned:
Value validated: The target persona reached the intended outcome under representative conditions.
Need validated, capability missing: The problem matters, but the product cannot yet support the required workflow.
Capability works, adoption friction remains: The product can deliver value, but setup, comprehension, trust, or workflow design prevents the user from reaching it reliably.
Technical path blocked: An integration, architecture, data, permission, or operational constraint prevents deployment.
Positioning mismatch: The product can do what was promised, but the outcome is not important enough for the target persona or was framed in the wrong terms.
Evidence inconclusive: The test did not represent the intended user or environment, or the decision criteria were not measurable.
These outcomes lead to different work. A positioning mismatch belongs in messaging and discovery. Adoption friction may require onboarding or product design. A recurring technical blocker may deserve roadmap investment. An inconclusive test deserves a better test, not a success story.
Demos and early deployments become high-signal learning mechanisms when their evidence returns to product strategy instead of ending in the opportunity record. That closed loop is what allows solutions engineering to improve both customer execution and the underlying product.
Measure adoption as a path, then act at the break
Adoption is not a single metric. It is a sequence that begins with a credible promise and ends when the customer repeatedly receives value. Measuring only the end hides the reason users failed. Measuring only clicks overstates progress.
Map the path for the persona named in the adoption contract:
Promise understood: The user or buyer can connect the product to a relevant outcome.
Entry: The intended user begins setup or enters the target workflow.
Readiness: Required data, permissions, integrations, and configuration are in place.
Activation: The user reaches the first meaningful value event.
Repetition: The user returns when the underlying job recurs and reaches value again.
Expansion: Appropriate users, workflows, or capabilities are added because the initial value is credible.
Retention: The product remains part of the operating workflow because it continues to produce the desired outcome.
Instrument enough of this path to locate the break. For each event, retain the eligible persona or account, relevant product context, action attempted, result, and connection to the intended outcome. Always state the denominator. Activation among configured users answers a different question from activation among all purchased accounts.
Use metrics such as time-to-value, daily active usage, and feature adoption only when they match the product’s natural workflow. A monthly administrative task should not be judged by daily activity. A high feature-visit count does not establish value if users repeatedly enter the feature because they are confused. Pair behavioral data with the qualitative context collected during proofs, implementations, and customer conversations.
Observed pattern
Question to investigate
Likely response area
Interest is high, but eligible users do not begin
Is the value proposition relevant and credible to this persona?
Positioning, targeting, or enablement
Users begin, but readiness fails
Which data, permission, configuration, or integration dependency is blocking progress?
Onboarding, implementation, or platform capability
Users complete setup, but do not reach the value event
Does the workflow lead clearly to the promised outcome?
Product design, guidance, or core capability
Users activate, but do not return
Is the job recurring, and was the first outcome valuable enough to change behavior?
Discovery, workflow fit, trust, or value proposition
Adoption differs sharply by persona or context
Was the product designed and positioned for the segment that is actually succeeding?
Segmentation, strategy, or packaging
Usage is high, but retention or customer outcomes remain weak
Is activity measuring value, required effort, or repeated friction?
Metric design, product quality, or outcome alignment
Match the intervention to the break. Use onboarding checklists, empty-state prompts, in-app guides, and product tours when the user needs contextual direction. Do not use a tooltip to conceal a broken permission model, an unreliable integration, or a workflow that does not create enough value. Guidance can reduce comprehension friction; it cannot repair a missing capability.
When you test an intervention, define the intended behavior change and success criterion in advance. Segment the result by the persona and context in the adoption contract. An aggregate improvement can hide a deteriorating experience for the strategic user, while a neutral aggregate can hide a strong response in the segment the product is meant to serve.
The adoption contract and any evidence that challenges it.
Progress through the journey, segmented by the intended persona and context.
The strongest field observations, with interpretations kept separate.
The active hypotheses and experiments.
The product, positioning, enablement, integration, or onboarding decision each experiment may change.
The owner responsible for making that decision and returning the result to the group.
Use operating reviews and QBRs to evaluate outcomes, not to count shipped features or completed guides. Ask which hypothesis was confirmed, which constraint was removed, where customers still stop, and what the organization will do differently. If an experiment has no route to a decision, revise it or stop it.
For your next significant product bet, start before the launch plan. Write the adoption contract, ask a solutions engineer to challenge it with field conditions, and define the evidence that would change your mind. That small discipline gives every later conversation – roadmap, demo, onboarding, analytics, and QBR – the same customer outcome to pursue.
Every quarter, I watch product teams move from gut feel to data-informed decisions—until instrumentation bottlenecks slow them to a crawl. That’s why I’ve become an advocate for codeless analytics: it removes the dependency on engineering sprints for basic event tracking and lets teams answer product questions in hours, not weeks.
We explain what codeless analytics are, why (and how) Pendo supports them, plus responses to the top three myths about low-code/no-code solutions.
Here’s how I frame it with my teams: codeless analytics enables product managers, designers, and customer success to tag features visually, track interactions, and analyze adoption without shipping code. The goal isn’t to replace engineered events; it’s to accelerate discovery, speed up iteration, and reduce context-switching for developers. In practice, this means cleaner prioritization, faster validation of hypotheses, and tighter product-led growth loops.
Why Pendo? In my experience, Pendo’s codeless model shortens the distance from question to insight. Visual tagging makes event setup accessible, in-app guides and product tours let us experiment with onboarding and activation, and governance controls ensure data remains trustworthy across teams. The result is a unified analytics approach where we reserve custom instrumentation for complex logic while using codeless tracking for everyday product questions.
Let’s address the top three myths I hear most often. Myth 1: “No-code is only for simple use cases.” In reality, most decisions we make weekly—feature adoption, path analysis, funnel drop-offs, and retention analysis—do not require custom code. Codeless analytics handles these well, and when we need deeper context (like server-side events), we complement it with engineered tracking. It’s a both/and, not an either/or.
Myth 2: “Codeless data isn’t accurate.” Accuracy comes from governance, not the method. I set clear standards: naming conventions, tagging reviews, ownership, and periodic audits. With disciplined process, codeless tracking yields consistent, decision-grade data. The added benefit is visibility—non-technical stakeholders can validate the instrumentation themselves, reducing misalignment.
Myth 3: “Engineers must instrument everything to scale.” Engineering time is precious; we should spend it on differentiated capabilities, not on routine click tracking. Codeless analytics scales by empowering product teams to self-serve, while engineering focuses on back-end, performance, and edge cases. When paired with a unified analytics platform and clear data contracts, this model scales cleanly across product lines.
For teams adopting this approach, I recommend a simple operating model: define your core product questions up front, tag features aligned to those questions, connect insights to in-app guides for experiments, and measure user activation and retention continuously. Whether you run Pendo alongside Amplitude analytics or within a broader unified analytics platform, the key is to keep the insight-to-action loop tight.
The future of product analytics is codeless because it puts insights where they belong—directly in the hands of the people designing the experience. When we remove bottlenecks, we learn faster, ship smarter, and drive measurable PLG impact. That’s how we turn product analytics from a reporting function into a competitive advantage.
Across my teams and portfolio, I’m watching AI fundamentally reshape product-led growth—from static funnels and one-off playbooks to adaptive, compounding growth loops that learn in real time. The shift isn’t just technological; it’s an operating model change that rewards continuous discovery, rigorous instrumentation, and outcome-driven product strategy.
"Learn how AI is transforming PLG with a new generation of growth loops that can turn your product into a self-optimizing platform." That line captures what I’ve been building toward: systems that sense user intent, decide the next best action, act contextually, and learn to improve the loop with every interaction.
Here’s the core pattern I rely on. First, sense: unify product analytics and behavioral signals (think Amplitude analytics, Pendo events, Intercom conversations) into a single, queryable, privacy-safe layer. Second, decide: apply AI Strategy—LLMs for product managers, rules, and retrieval—to segment users by intent and probability of success. Third, act: deliver in-app guides, product tours, tooltips, or personalized nudges that accelerate user activation and time-to-value. Finally, learn: run A/B testing with a clear minimum detectable effect (MDE), then feed outcomes back into the model for continuous optimization.
Activation is where the gains start compounding. With gen ai, I can auto-generate tailored onboarding checklists, dynamic walkthroughs, and contextual help that adapts to the user’s role, data maturity, and current friction points. We’ve moved from generic product tours to precision guidance that updates based on real-time behavior—often lifting first-week activation and shortening time-to-first-value without adding support load.
Experimentation is the governor that keeps speed and quality in balance. I instrument every growth loop end to end and pair eval-driven development with A/B testing to confirm incremental impact. Amplitude analytics gives me cohort views and path analysis; Pendo or Intercom can deliver in-app variants; a unified analytics platform closes the loop on retention analysis so I’m not optimizing for click-through at the expense of long-term value.
Retention and expansion are where AI shines as a compounding engine. Retrieval-first pipeline patterns allow instant, contextual support that deflects tickets and boosts perceived product competence. Agentic AI can orchestrate next-best actions—prompting power users toward advanced features, surfacing value moments, or timing expansion prompts when success signals appear. The result is a virtuous cycle: better guidance drives deeper adoption, which improves model accuracy, which unlocks more relevant guidance.
None of this works without guardrails. I bake in AI risk management from the start: strict data governance, privacy-by-design, human-in-the-loop review for high-impact actions, transparent user consent, and continuous drift monitoring. The goal is reliable automation that users trust—augmented by clear fail-safes when confidence drops.
Operationally, I anchor the work in empowered product teams and product trios, focus on outcomes vs output OKRs, and practice continuous discovery to validate problems and solutions before scaling. The baseline metrics I watch: activation rate, time-to-value, week-four retention, PQL/PQA conversion, expansion revenue, and support deflection—each tied to a specific growth loop hypothesis.
If you’re starting fresh, begin with the highest-leverage loop: user activation. Instrument your onboarding journey, define the critical path to value, ship two to three personalized interventions, and measure impact with a precommitted MDE. Scale what wins, drop what doesn’t, and iterate weekly. Once activation is compounding, extend the same approach to adoption depth, collaboration features, and expansion triggers.
In practical terms, AI-powered PLG is less about flashy features and more about disciplined feedback loops. Build the sensing fabric, keep the decision layer auditable, ship small actions quickly, and treat learning as the product. Do that, and your product doesn’t just grow—it becomes a self-optimizing platform.
I set out to create a lightweight, high-impact “Pendo Wrapped” experience for our users—and I did it in under 10 minutes with Pendo MCP. As a VP of Product Management, I’m constantly looking for fast, pragmatic ways to turn product insights into moments that drive engagement. This experiment was about transforming raw analytics into a concise, celebratory year‑in‑review that motivates customers to explore more value.
When I say “Pendo Wrapped,” I mean a simple, narrative-style summary of usage highlights: what got adopted, which moments mattered, and where value showed up most clearly. Framed well, that story reinforces product‑led growth by reminding users why they chose us, nudging them toward the next best action, and strengthening activation and retention without heavy development work.
My approach was straightforward: define a clear objective (celebrate milestones and prompt the next step), choose a focused set of metrics (adoption, engagement, and activation), and target relevant segments. Then I layered the narrative on top of existing analytics using in‑app guides and product tours to deliver the experience where it matters most—inside the product.
The reason it took minutes, not hours, is that Pendo MCP let me work with what we already had—segments, saved reports, and proven guide templates—so I could spend time on the story, not the scaffolding. No code, minimal configuration, and a crisp call to action made it feel polished without being heavy.
Increase revenue, cut costs, and reduce risk with Pendo’s Software Experience Management platform. Optimize the entire software experience to drive adoption and improve engagement.
If you want to replicate this quickly, start by selecting one user segment and three metrics that matter to them, write a two‑sentence narrative that connects those metrics to outcomes, and ship a short in‑app guide with a single, purposeful CTA. That’s enough to deliver a personalized year‑in‑review feel and spark immediate exploration—no new infrastructure required.
What surprised me most was how a small, story‑driven touch created outsized alignment across customers and internal teams. It turned analytics into advocacy, reminded our users of the value they’re already getting, and opened the door to deeper adoption. If you’re pursuing product‑led growth, a fast “Pendo Wrapped” is one of the highest‑leverage experiments you can run this week.
2026 is closer than it feels, and the signals are already clear. I’ve been synthesizing what I’m seeing across empowered product teams, boards, and cross-functional partners into a practical view of what matters next. A sharp look at product management trends for 2026. Not guesses, but signals from top product leaders shaping how PMs will actually work next.
In this analysis, I distill eleven shifts that are changing the craft—from outcomes vs output OKRs and continuous discovery to stronger product strategy and tighter product roadmapping and sprint planning. The throughline is simple: prioritize customer value, ship with focus, and measure what moves the business. These aren’t headline trends; they’re working patterns I’m seeing across high-performing organizations.
AI is no longer a side project—it’s part of the product manager’s core toolkit. Agentic AI, LLMs for product managers, and trustworthy AI workflows are accelerating discovery, sharpening problem framing, and enabling faster iteration. The best teams pair this with disciplined evaluation and experimentation, so insight compounds without sacrificing safety, privacy, or product quality.
Execution is getting crisper through product trios and stronger stakeholder management. When design, product, and engineering co-own discovery and delivery, teams reduce handoffs and increase clarity. That alignment translates into better prioritization, fewer context-switches, and a roadmap that reflects real trade-offs—not wish lists.
On growth, product-led growth remains a durable engine when it’s anchored in a compelling value proposition and instrumented end-to-end. Clear activation moments, in-app guides, and thoughtful product tours outperform brute-force acquisition. When we connect these motions back to product strategy and the roadmap, we create a repeatable loop that compounds adoption and retention.
Governance and trust are now table stakes. Privacy-by-design, data governance, and a pragmatic approach to regulatory compliance protect both users and velocity. Teams that build these practices into their operating model move faster because they avoid late-stage rework and maintain stakeholder confidence.
If you’re leading a product org—or aspiring to—this is your field guide to 2026. I’ll unpack where these shifts are strongest, how to apply them in your context, and the pitfalls to avoid. The aim is to give you clear language, concrete practices, and a sharper edge as you shape what your team builds next.