Heading to ProductCon San Francisco 2025? I approach conference travel the same way I approach product strategy: optimize for outcomes, reduce friction, and invest in high-signal experiences. Here’s the playbook I use to choose the right hotel, find memorable meals, and make the most of every hour in the city.
For lodging, I prioritize walkability, safety, and quiet rooms so I can focus during sessions and recover at night. If you want to be steps from most venues and meetups, SoMa and the Yerba Buena corridor are ideal. InterContinental San Francisco, W San Francisco, and The Clancy (Autograph Collection) are reliable, business-friendly picks with strong Wi‑Fi and ample lobby space for impromptu one‑on‑ones. If you prefer classic energy and transit access, Union Square hotels like Hotel Nikko and The Westin St. Francis work well. For waterfront views and a calmer vibe, Hyatt Regency Embarcadero puts you by the Ferry Building with easy BART and Muni access.
My booking checklist is simple: reserve early, target a high floor away from elevators, and request early check‑in or late checkout around your session schedule. Loyalty programs often unlock better rates and quiet‑room preferences. If you need heads‑down time between talks, ask about day‑use meeting rooms or find a corner of the lobby with stable bandwidth. I also pack a compact power strip and a long USB‑C cable—two small upgrades that routinely save a day.
Coffee is the fuel of great product conversations. Near SoMa, I rotate between Blue Bottle (Mint Plaza), Sightglass (7th Street), and Philz (Front Street) for pre‑session caffeine and quick stand‑ups. If I’m on the Embarcadero side, the Ferry Building’s roasters are perfect for early starts, and morning lines move faster than you’d expect if you arrive just after opening.
For efficient lunches, I favor fast‑casual spots that can handle volume without sacrificing quality. Mixt, Souvla, Sweetgreen, Super Duper Burgers, and The Grove are dependable within a short walk of most downtown venues. When I need a higher‑signal lunch with a partner or prospect, I book a table slightly off the main corridor to avoid the rush—think Mourad for elevated Moroccan in SoMa or Boulevard along the Embarcadero for a polished, quiet conversation.
Dinner is where the best networking often happens, so I plan for atmosphere, acoustics, and a menu that works for mixed dietary needs. Kokkari Estiatorio (FiDi) excels for executive dinners. Liholiho Yacht Club is a creative, memorable choice for cross‑functional teams. Waterbar or Angler near the waterfront pair great food with views that impress visiting colleagues. For something more casual but still conversation‑friendly, Nopa or Sorella deliver consistently.
When it’s time for drinks, I think in terms of groups and goals. For panoramic views and small group catch‑ups, The View Lounge (Marriott Marquis) is a classic. For wine‑forward conversations with a quiet ambiance, Press Club near Yerba Buena works well. If you’re hosting a more energetic crew, Charmaine’s (SF Proper Hotel), Dirty Habit (Hotel Zelos), or 25 Lusk offer space, good music, and reliable service. For craft cocktails, Pacific Cocktail Haven and ABV are standouts if you don’t mind a short ride.
Transit and timing matter. From SFO or OAK, BART is often the fastest, most predictable route downtown; rideshare is convenient late at night. I walk whenever possible, but I time routes along well‑lit, busier streets and avoid sprinting between neighborhoods tight on time. Microclimates are real—bring layers, comfortable shoes, and a compact umbrella. I schedule 15‑minute buffers around key sessions to handle inevitable friend‑of‑a‑friend introductions.
If you need a professional setting for a quick working session, many hotels will extend lobby seating to guests and their visitors. For dedicated space, day passes at coworking operators like Industrious, CANOPY, or Regus are worth it when you’ve got a client briefing or board prep. For a more casual backdrop, Sightglass and Blue Bottle locations typically have reliable Wi‑Fi and just enough outlets if you arrive off‑peak.
Finally, a word on intent: I set a simple goal for each day—one meaningful connection, one surprising insight, and one concrete action to bring back to my team. ProductCon San Francisco 2025 is a catalyst if you design your experience with the same rigor you apply to your roadmap. If you spot me in a session or at a nearby cafe, say hello—I’m always up for trading notes on product strategy, pricing experiments, and what’s working in the field right now.
Quick note: restaurants and hours can change quickly—make reservations where possible and double‑check opening times the week of the event.
You have rewritten the roadmap as OKRs, asked teams to focus on outcomes, and changed the titles in the quarterly review. Yet feature requests still arrive as commitments, teams still need approval to change a solution, and leaders still celebrate launches more than customer behavior. The language changed. The operating model did not.
An outcome-driven product operating model changes who owns the problem, what leaders fund, how teams make decisions, and what evidence can alter the plan. If you are leading that transition, the practical test is simple: can each product team name the behavior it is trying to change, its current baseline, the business result that behavior should influence, its guardrails, and the decisions it can make without escalation?
Start with an outcome contract, not an outcome slogan
An outcome-driven model needs more than an outcome-shaped sentence. It needs a clear contract between leadership and the team.
Leadership defines the strategic direction, the customer or business result that matters, the constraints, and the boundaries of acceptable risk. The team owns discovery, solution choice, sequencing, and the experiments used to find a viable path. This division protects strategic alignment without turning leaders into backlog managers.
Describes the behavior or result that should change
More new accounts complete the first-value action
Metric
Measures that change
Activation rate or time-to-first-value
Target
Defines the desired movement and time horizon
The agreed improvement from the recorded baseline
Bet
States a possible way to create the outcome
Guided setup for the highest-friction step
Output
Names what the team may build or change
An in-app guide or revised onboarding flow
Keeping these elements separate matters. If the objective says “launch onboarding v2,” the solution has already been chosen. Discovery can only validate the predetermined answer. If it says “improve activation,” but there is no segment, baseline, causal explanation, or guardrail, the team has freedom without usable direction.
A strong outcome contract fits on one page and contains:
Target customer and problem: who is affected, where the friction appears, and why resolving it matters now.
Primary outcome: the single behavior or business result the team is expected to influence.
Baseline and target: the current measurement, desired movement, and decision horizon. If the baseline is unavailable, measurement is the first task rather than an assumption hidden in the plan.
Causal chain: the proposed connection from product change to customer behavior to business value.
Leading indicators: signals such as completion of a core action or time-to-first-value that can reveal movement before the lagging result is available.
Guardrails: measures that must not deteriorate, such as support demand, reliability, performance, satisfaction, privacy, or risk.
Constraints: non-negotiable regulatory, security, platform, brand, cost, or commercial boundaries.
Decision rights: what the team can decide, what requires consultation, and what requires leadership approval.
Evidence standard: what would justify continuing, changing, scaling, or stopping the bet.
The causal chain is the part most teams skip. “Build a dashboard to improve retention” jumps directly from output to business result. Ask what the customer will do differently because the dashboard exists, why that behavior should affect retention, and which signal would appear first. If no credible behavior connects the feature to the result, the feature is not yet a defensible bet.
Do not make the outcome so broad that no team can influence it. Company revenue, total churn, and overall customer satisfaction are often shared results shaped by pricing, sales, service, market conditions, and multiple product experiences. A team needs a customer behavior or operating result close enough to its work to guide daily choices, while still having a clear connection to the larger business outcome.
This is also why outputs should not disappear from planning. Teams still need delivery plans, quality standards, dependencies, and technical milestones. The mistake is treating those items as proof of value. Outputs tell you what changed in the product. Outcomes tell you whether that change mattered.
Give durable teams a problem and real decision rights
You cannot hold a team accountable for an outcome while reserving every meaningful decision for someone else. Outcome ownership without authority is delegated blame.
A durable team should own a customer problem or value area long enough to build context, observe behavior, test alternatives, and learn from the result. A stable product, design, and engineering partnership reduces the handoffs that appear when temporary project teams move from specification to design to implementation.
Durability does not mean a team owns the same feature forever. It means the team retains responsibility for an outcome space even as its solution changes. An activation team might work on guidance, setup defaults, education, performance, or removing a step entirely. The outcome provides continuity; the outputs remain flexible.
Make decision rights explicit at each level:
Executive leadership: chooses the strategic outcomes, sets material constraints, allocates investment across the portfolio, and resolves conflicts that cross organizational boundaries.
Product leadership: translates strategy into outcome spaces, defines evidence and review standards, protects coherent team boundaries, and makes portfolio trade-offs visible.
Product teams: investigate opportunities, choose solution hypotheses, decide how to test them, sequence delivery, and recommend whether a bet should continue.
Functional leaders: establish engineering, design, data, security, and product-management standards while developing the craft and capability of their people.
Stakeholders: contribute customer context, commercial needs, risks, deadlines, and operational knowledge. Their requests are important evidence, but they do not silently become roadmap commitments.
The wording of the boundary matters. “The team is empowered unless a senior stakeholder disagrees” is not a decision rule. Specify which constraints are binding, who can override a team decision, what evidence an override requires, and who decides which existing commitment will move as a result.
When a feature request arrives, use a short intake sequence:
Restate the request as a customer problem, business risk, or desired behavior change.
Identify the affected segment, current evidence, urgency, and consequence of doing nothing.
Compare it with the outcomes already assigned to the team.
If it fits, add it as an opportunity or solution hypothesis rather than an automatic commitment.
If it displaces an existing priority, ask the portfolio owner to make that trade-off explicitly and record what is being delayed.
This prevents the common pattern in which every request is individually reasonable but the combined roadmap is strategically incoherent.
Do not force enabling work into a fictional revenue claim. State the operational capability it must improve, the downstream product outcomes it enables, and the risk of postponing it. That gives platform and infrastructure investments a testable rationale without pretending every technical change has a direct, isolated effect on growth.
Manage a portfolio of bets instead of a feature queue
A feature roadmap creates the appearance of certainty too early. It commits the organization to solutions before the most important assumptions have been tested. An outcome-driven roadmap still communicates direction and sequencing, but it treats solutions as bets that can earn more investment through evidence.
Each roadmap item should answer four different questions:
Why this problem? The customer pain, strategic relevance, business consequence, and reason it deserves attention now.
What should change? The target behavior or result, baseline, leading indicators, and guardrails.
How might it change? The current solution hypothesis and the causal assumptions behind it.
What happens next? The evidence being gathered and the next continue, change, scale, or stop decision.
This format changes the roadmap conversation. Stakeholders can challenge the importance of the problem, the logic of the bet, or the quality of the evidence without treating a proposed feature as an irreversible promise.
Use a lightweight bet brief before substantial delivery begins. It should include:
The outcome contract and the strategic objective it supports.
The customer opportunity and evidence that the problem is real.
The causal chain from proposed change to behavior to business result.
The expected reach, frequency of exposure, and direction of behavior change.
The solution hypothesis and the riskiest assumptions within it.
Confidence, effort, dependencies, privacy implications, data requirements, and technical complexity.
The instrumentation, experiment, rollout, and guardrail plan.
The evidence that would change the decision.
A one-page impact brief is usually enough. If a team cannot express the logic concisely, expanding the document will not repair the missing understanding.
Prioritization frameworks can help compare bets, but they should expose judgment rather than replace it. Reach, impact, confidence, and effort are useful because they force assumptions into view. Cost of delay helps when timing matters. Neither method turns uncertain inputs into objective truth.
Pressure-test the inputs before trusting the score:
Is reach based on actual eligible users or the entire customer base?
Does “impact” refer to a behavior that can be measured, or merely to stakeholder enthusiasm?
Is confidence supported by behavioral evidence, customer discovery, prior experiments, or only opinion?
Does effort include instrumentation, rollout, migration, enablement, support, and dependencies?
Would the bet still rank highly if its most optimistic assumption were reduced?
The portfolio also needs balance. Some bets improve customer behavior directly. Others reduce material risk, strengthen a platform capability, or create the measurement needed to pursue later outcomes responsibly. Make those categories explicit so foundational work is not forced to compete through exaggerated short-term impact claims.
Set stopping conditions before enthusiasm and sunk cost distort the decision. A stopping condition might be failure to observe the necessary leading behavior, inability to reach the intended segment, unacceptable movement in a guardrail, or evidence that the customer problem is less important than assumed. Stopping a weak bet is not a delivery failure. Continuing it without a credible causal path is.
Make evidence change plans, funding, and reviews
The model becomes real only when evidence can change what the organization does. If every bet continues regardless of results, experimentation is theater. If quarterly reviews still focus on release counts, teams will optimize for releases.
Connect discovery, delivery, and measurement
Discovery is not a phase that ends when development begins. It is the work of reducing uncertainty throughout the bet. The useful sequence is:
Record the baseline. Confirm that the primary outcome and leading indicators can be measured for the relevant segment.
Map the causal chain. Identify the customer behavior that must change before the business result can move.
Test the riskiest assumption. Learn whether the problem, proposed value, usability, feasibility, or business logic is most uncertain.
Ship the smallest meaningful change. Reduce the scope needed to create observable behavior, not merely the number of tickets in the release.
Monitor leading and guardrail signals. Leading indicators may appear within days, while durable or lagging outcomes can require weeks to assess.
Write the learning memo. Record what happened, what remains uncertain, and whether the evidence supports continuing, changing, scaling, or stopping.
Instrumentation belongs in the bet, not in a cleanup backlog after launch. Define event names, eligibility rules, segments, exposure, dashboards, and metric ownership before the change reaches customers. Otherwise, the team may ship on time and still be unable to answer whether the intended behavior occurred.
Match the evidence method to the decision
Use an A/B test when you need causal confidence and can create valid comparison groups. Set the minimum detectable effect before the test so the team knows whether the available population and duration can detect a change large enough to matter. A test that cannot resolve the decision is activity, not useful evidence.
Not every change can be randomized. Sequential rollouts, pre-post comparisons, cohort analysis, and synthetic controls can still inform a decision, but their limitations should remain visible. Seasonality, selection effects, concurrent launches, and changes in traffic can produce movement that the product change did not cause. Label the conclusion with the strength of the evidence rather than presenting every dashboard shift as proof.
Also distinguish a negative result from an inconclusive one. A well-powered test that shows the necessary behavior did not change challenges the hypothesis. A test with weak exposure, broken instrumentation, or insufficient sensitivity says much less. The next decision should reflect that difference.
Replace status rituals with decision rituals
Each operating cadence should answer a distinct question:
Strategy reviews: Are the chosen outcomes still the right expression of the strategy, given current customer and business evidence?
Team reviews: What did the team learn about the problem, causal chain, solution, and metrics, and what will it test next?
Portfolio reviews: Which bets deserve more investment, which need to change, and which should stop?
Quarterly business reviews: What customer and business results changed, what was learned, and how should allocation change? Releases provide context, not the score.
A useful review page shows the baseline, current value, target, leading indicators, guardrails, confidence level, latest learning, and next decision. A release list without those fields is a delivery update, even if the slide is labeled “outcomes.”
Incentives must support the same behavior. Teams should be accountable for the quality of their discovery, the integrity of measurement, the speed with which they resolve material uncertainty, and the decisions they make from evidence. Treating every missed outcome as individual failure encourages conservative targets, favorable metric selection, and reluctance to stop weak bets. Outcomes are influenced, not manufactured on command.
Introduce the model through a real decision
A company-wide reorganization is not the safest starting point. Begin with an important product area where the current feature plan contains meaningful uncertainty and leadership is willing to let evidence change the solution.
Select one outcome and record its baseline, causal chain, leading indicators, and guardrails.
Assign it to a durable product trio with written decision boundaries.
Convert the planned initiative into a bet brief with assumptions and stopping conditions.
Change the existing team and portfolio reviews so they require evidence and an explicit decision.
At the end of the planning cycle, inspect where decisions still stalled: unclear strategy, missing data, dependency conflicts, weak skills, incentive mismatch, or executive overrides.
Repair those operating constraints before expanding the model to more teams.
Treat the operating model itself as a product. Its users are the teams and leaders making decisions. Its outcomes are clearer ownership, lower decision latency, stronger learning, and better allocation of effort. Changing an org chart without changing those behaviors is just another output.
Key takeaways for your next planning cycle
An outcome must name an observable change, not disguise a feature as an OKR.
Pair every outcome with a baseline, causal chain, leading indicators, guardrails, constraints, and an evidence standard.
Give durable teams authority over discovery and solution choices within explicit strategic and risk boundaries.
Manage solutions as bets that can earn, lose, or redirect investment as evidence changes.
Keep enabling work visible by naming the capability it improves, the outcomes it unlocks, and the risk of delay.
Review customer behavior, business movement, learning, and next decisions. Do not use delivery activity as a substitute for impact.
At your next roadmap review, take the most expensive planned initiative and rewrite it as an outcome contract and bet brief. If the room cannot agree on the target behavior, baseline, causal link, decision owner, and evidence that would stop the work, the initiative is not ready for a larger commitment. Resolve that uncertainty before adding more scope.
You are looking at a roadmap full of plausible ideas, yet nobody can explain which one is most likely to change customer behavior. Sales has requests, support has complaints, leadership has strategic themes, and the product team has solutions waiting for estimates. Everything sounds important because the outcome has not been made precise enough to disqualify anything.
Outcome-driven product discovery fixes that problem by connecting every roadmap bet to the same chain: business result, customer behavior, opportunity, assumption, experiment, and decision. It gives you a practical way to invest in innovation without turning every interesting idea into a delivery commitment.
Start with the behavior you need to change
A launch is an output. Completing a first meaningful workflow is a behavior. Activation is a product outcome. Retained revenue is a business outcome. Those concepts may sit in the same strategy, but they are not interchangeable.
Start discovery with the product outcome because it is close enough to the customer experience for a team to influence and measure. Then state the business result you expect it to support. That connection is a hypothesis, not an automatic fact. Improving engagement that has no relationship to customer value, retention, conversion, or another meaningful result simply produces a more active feature.
A useful outcome statement has five parts:
Segment: the specific users, accounts, or lifecycle stage whose behavior matters.
Behavior: an observable action that represents progress toward value.
Baseline and target: the current measurement and the change the team intends to produce.
Decision window: when you will review the evidence and decide what to do next.
Guardrail: the metric or customer consequence that must not deteriorate while the primary outcome improves.
Use this template: By [decision date], change [behavior] for [segment] from [baseline] to [target], because that behavior is expected to contribute to [business result], while protecting [guardrail].
Suppose a SaaS team wants to improve new-account activation. The feature-factory version of the goal is to launch a redesigned onboarding checklist. The outcome-driven version identifies the new-account segment, the value-bearing workflow those users need to complete, the current completion rate, the desired change, the review date, and a guardrail such as downstream retention or support burden. The checklist may become one solution, but it no longer owns the roadmap before discovery begins.
Keep three measures visible on the same decision page:
Primary outcome: the customer behavior you intend to change.
Business consequence: the commercial or strategic result that behavior is expected to influence.
Guardrail: the cost, quality, trust, or downstream behavior you refuse to sacrifice.
This is the practical difference between organizing goals around outcomes instead of output and attaching metrics to a feature after it has already been approved. The first approach creates choice. The second decorates a commitment.
Before accepting an outcome, ask four questions. Can the team observe it? Can the team influence it during the decision window? Does it represent customer progress rather than product activity alone? Is its expected connection to the business result explicit? If any answer is no, revise the outcome before collecting more ideas.
Key takeaways
Begin with a measurable customer behavior, not a feature, project, or launch date.
Treat the link between that behavior and the business result as a hypothesis that needs evidence.
Map opportunities before comparing solutions, so requests do not become commitments by default.
Combine segmented customer evidence with product telemetry; neither is sufficient on its own.
Give every experiment a decision rule, a meaningful effect threshold, and guardrails.
Judge discovery by the decisions it changes, including decisions to adapt, delay, or stop a bet.
Map opportunities before you rank solutions
Once the outcome is clear, resist the urge to run an idea workshop. First map the obstacles, unmet needs, and motivations that could explain why the desired behavior is not happening.
An opportunity describes a customer condition. A solution describes something you could build. For example, users abandoning setup because they cannot tell which information is required is an opportunity. A setup wizard, template, tooltip, or assisted service is a solution. Keeping those levels separate preserves more than one path to the outcome.
Translate feature requests with a simple sequence:
Ask which user or account segment is making the request.
Identify the job that person is trying to complete.
Locate the point in the journey where progress breaks down.
Describe the consequence of that breakdown in the customer’s terms.
Connect the problem to the target outcome.
Record the requested feature as one possible solution, not as the opportunity itself.
This translation matters because a request can be accurate about the pain and wrong about the remedy. It can also be valid for one enterprise account but harmful to the broader value proposition. Segmenting feedback by persona, account tier, lifecycle stage, and job prevents unlike signals from being combined into a misleading vote count. A founder, a new user, a power user, and an account approaching renewal are speaking from different contexts.
Build the map with a product trio: product management, design, and engineering working on the problem together. Early engineering involvement exposes feasibility constraints and cheaper implementation paths. Design brings the journey and interaction risks into view. Product management connects the opportunity to customer value, strategy, and commercial consequences. The benefit is shared reasoning, not another recurring meeting.
A practical outcome-driven operating model gives that trio room to investigate opportunities before delivery sequencing hardens. Without it, discovery becomes a product-manager document handed to design and engineering after the consequential decisions have already been made.
Use the following rubric to compare opportunities. Do not collapse it into a single total score. A tidy score can hide a fatal weakness, such as no evidence that the problem exists for the target segment.
Criterion
Decision question
Warning sign
Outcome proximity
If this problem is reduced, what customer behavior should change?
The connection depends on several untested assumptions.
Segment evidence
Which target users experience the problem, and in what context?
The evidence comes mainly from unsegmented requests or one loud account.
Severity and recurrence
Does the problem block value, repeatedly create friction, or merely inconvenience the user?
The team cannot distinguish a recurring obstacle from an isolated preference.
Strategic coherence
Would solving it strengthen the intended value proposition or differentiation?
The solution adds complexity without making the product more valuable to its chosen market.
Learning value
What important uncertainty would pursuing this opportunity resolve?
The team is committing substantial delivery capacity without identifying the risky assumption.
Downside and reversibility
What could break, and how easily could the change be contained or reversed?
Trust, data, operational, or platform risk is being treated as a post-launch concern.
The result should be an opportunity map, not a backlog. A backlog asks what can be built. An opportunity map asks where a change could produce the outcome, what evidence supports that belief, and what still needs to be learned.
Match the strength of evidence to the size of the commitment
Customer interviews alone do not tell you how widespread a problem is. Product analytics alone do not tell you why a behavior occurs. Strong discovery uses each form of evidence for the question it can answer.
Qualitative evidence reveals language, context, motivation, workarounds, and consequences.
Behavioral evidence shows where users progress, hesitate, abandon, return, or differ across cohorts.
Commercial evidence shows how the opportunity appears in sales, expansion, support, renewal, or churn conversations.
Experimental evidence tests whether a specific intervention causes the intended change under defined conditions.
Start with the journey connected to the outcome. Instrument the important steps, inspect funnels and cohorts, and then use interviews, support conversations, community discussions, and sales or customer-success notes to explain the patterns. This combination of telemetry and customer narrative is more useful than collecting more comments without a decision in mind.
When qualitative and quantitative evidence disagree, do not average them into a vague conclusion. Investigate the mismatch. The interview sample may represent power users while the funnel includes new users. The telemetry may be missing an offline step. A workflow may be painful but unavoidable, producing high completion despite poor experience. A small segment may have a severe problem hidden by an aggregate rate. Contradiction is often a segmentation or instrumentation clue.
Create a shared taxonomy so evidence remains usable after the meeting in which it was collected. Tag each item by:
problem statement;
persona or account segment;
job to be done;
journey step;
lifecycle stage;
evidence channel;
related outcome;
confidence and unresolved uncertainty.
Then produce a compact evidence packet for each opportunity under active consideration:
Outcome: the behavior the team wants to change.
Observation: the measured pattern, with its segment and journey context.
Customer explanation: the recurring need, obstacle, or workaround found in qualitative evidence.
Contrary evidence: what does not fit the current explanation.
Current hypothesis: why the opportunity may be causing the behavior.
Largest uncertainty: the assumption most capable of invalidating the bet.
Next decision: what the team will decide after the next learning step.
The required evidence should rise with the cost and irreversibility of the commitment. A reversible wording change can justify a lightweight test. A new core workflow, platform dependency, pricing model, or data-access pattern deserves deeper investigation because mistakes create migration cost, operational burden, customer confusion, or trust damage.
My test is simple: can the team state what evidence would make it change course? If not, the work is advocacy rather than discovery. Evidence is being gathered to support a preferred answer, not to improve the decision.
Run experiments that force a roadmap decision
An experiment is useful only when its result can change what happens next. Before choosing a prototype or test method, write the decision the evidence must inform.
A concise experiment card should contain:
Hypothesis: If [segment] receives [intervention] in [context], then [behavior] will change because [reason].
Riskiest assumption: the belief that would make the solution unattractive, unusable, infeasible, unviable, or unsafe if false.
Method: the least expensive credible way to test that assumption.
Primary measure: the signal that directly answers the experiment question.
Meaningful effect: the smallest change that would justify a different product decision.
Guardrails: the customer, business, quality, or trust measures that must remain acceptable.
Decision rule: the conditions for advancing, adapting, stopping, or gathering different evidence.
Choose the method based on the uncertainty:
Use interviews and observation to understand the job, context, current alternative, and consequence of the problem.
Use concept tests to learn whether the proposition is understood and relevant.
Use clickable prototypes to find comprehension, interaction, and workflow problems before production work.
Use a manual or limited implementation to test whether completing the workflow creates enough value to justify automation and scale.
Use feature flags and progressive rollouts to contain operational risk and inspect real behavior.
Use an A/B test when you need a credible comparison of incremental behavior and have the traffic, instrumentation, and time to run it properly.
Do not ask one method to prove more than it can. Positive interview reactions do not prove adoption. A usable prototype does not prove retention. A short-term click improvement does not prove durable customer value. Each result should earn the next level of investment, not retroactively validate the entire strategy.
For A/B tests, define the minimum detectable effect before launch. This is the smallest difference worth reliably detecting for the decision, not the smallest fluctuation visible in a dashboard. Plan the sample around that threshold, avoid repeatedly checking results and stopping when they look favorable, and carry the analysis into downstream behavior where the hypothesis requires it. Statistical discipline and retention analysis prevent short-lived movement from being mistaken for a product win.
If the available traffic cannot support the planned effect within the decision window, do not run an underpowered test and interpret noise. Reduce the scope, extend the observation period where practical, use a stronger leading indicator, or select a different method. The method should fit the decision environment.
Guardrails deserve the same pre-commitment as the primary measure. An onboarding change that raises completion but also increases early cancellations, support contacts, errors, or later abandonment may have shifted friction rather than removed it. The team should know in advance which trade-offs are unacceptable.
End every experiment with one of four explicit decisions:
Advance: the evidence supports the assumption strongly enough to justify the next investment.
Adapt: the opportunity still matters, but the solution or segment hypothesis needs revision.
Stop: the expected outcome no longer justifies the cost, risk, or strategic distraction.
Reframe: the test exposed an instrumentation gap, a different opportunity, or an assumption that must be investigated first.
A failed solution test can still be a successful discovery decision. The value lies in avoiding a larger, poorly justified commitment.
Turn discovery into the operating system for innovation
Innovation is not measured by how unfamiliar a solution looks. It is measured by whether the team finds a better way to create and capture value under uncertainty. That requires a learning system, not a separate innovation theater filled with demos that never reach adoption.
Give every innovation bet a one-page brief:
the target segment and job;
the behavior and business outcome;
the current alternative and why it is insufficient;
the opportunity being pursued;
the intended value proposition and differentiation;
the riskiest value, usability, feasibility, viability, or trust assumption;
the next experiment and its decision rule;
the owner, review date, and current investment boundary.
This brief lets leadership compare bets without pretending that early ideas have precise forecasts. Mature work can be judged on measured outcome contribution. Earlier innovation should be judged on the importance of the opportunity, strategic fit, quality of evidence, cost of the next learning step, and whether uncertainty is falling fast enough to justify continued investment.
Differentiate deliberately. Some capabilities are points of parity that customers expect. Others are candidates for meaningful differentiation. Treating every competitor feature as strategically necessary fragments the product and consumes capacity that could strengthen the chosen value proposition. First-principles reasoning should establish which customer problem matters before competitive comparison influences the solution.
For AI products, trust belongs inside the outcome
An AI prototype can appear successful while hiding the operational conditions required for a durable product. Add trust and control questions to discovery from the beginning:
What happens when the output is wrong, incomplete, or inappropriate?
Which data can the system access, retain, or expose?
Where does a person need to review, approve, correct, or override the system?
Can the team observe failures and explain consequential actions?
Does the workflow create enough customer value after review, exception handling, and operating cost are included?
Privacy, data governance, transparent controls, and auditability are part of the product proposition, especially when the workflow has meaningful consequences. Moving from an AI demonstration to a durable capability requires evidence about the complete workflow, not just the quality of a favorable output.
Install a cadence that changes priorities
Discovery becomes operational when evidence repeatedly changes allocation decisions. A practical cadence is:
Weekly product-trio review: examine the target outcome, new evidence, contradictions, largest uncertainty, and next decision for active bets.
Monthly cross-functional synthesis: combine themes from product behavior, interviews, sales, support, and customer success; resolve segmentation questions; and identify implications for the roadmap.
Quarterly outcome lookback: compare expected and observed changes in activation, adoption, conversion, retention, or the relevant business result; inspect guardrails; and record which assumptions were right or wrong.
This feedback and synthesis cadence creates organizational memory. It also exposes a hollow process quickly. If repeated discovery reviews never stop, reorder, narrow, or reshape roadmap work, the organization has built a reporting loop rather than a decision loop.
Represent roadmap items as bets, with the outcome, segment, opportunity, evidence, hypothesis, guardrails, owner, and next decision visible. Delivery milestones still matter, but they sit beneath the reason for the work. That makes stakeholder conversations more precise. Instead of asking whether a requested feature made the roadmap, ask which outcome it supports, what problem it solves, what evidence exists, and what would justify investment.
Keep a short decision log after each review. Record the decision, evidence considered, assumptions still open, owner, and revisit condition. This prevents the organization from re-litigating old choices after context has disappeared, while allowing a decision to change when genuinely new evidence arrives.
Take the next substantial item scheduled to enter delivery and try to fill in its outcome statement, opportunity, evidence packet, riskiest assumption, experiment, guardrail, and decision rule. Any field you cannot complete is not paperwork to delegate. It is the uncertainty discovery needs to resolve before the commitment grows.
Do that with one bet first. When the resulting evidence changes an investment decision, use the same structure for the rest of the roadmap. That is the point at which discovery stops being a phase and starts becoming how innovation is managed.
Products without borders are exhilarating—and unforgiving. In my role leading product strategy, I’ve learned that “global” isn’t a launch plan; it’s a system. It’s the discipline of creating one product vision that flexes to many markets without breaking the core experience, the roadmap, or the business.
Here’s what a Global Product Manager does, key skills, tools, challenges, and how to grow into this high-impact role.
At its heart, the Global Product Manager role orchestrates product-market fit in multiple regions simultaneously. I translate a unified value proposition into localized realities—aligning product positioning, go-to-market strategy, pricing and packaging, and compliance—while keeping the platform cohesive. That means partnering closely with product trios, regional leaders, sales, customer success, and marketing to drive outcomes vs output OKRs that actually move the business.
Operationally, I start with deep product discovery across segments and geographies: what pains are universal, and where do we need regional nuance? From there, I map points of parity we must maintain globally and the differentiators we’ll localize—copy, workflows, payments, support models, and integrations. The art is delivering a consistent core with flexible edges so we can scale without fragmenting the codebase or the customer experience.
Trust is the non-negotiable. I build privacy-by-design into the product and roadmap, and I collaborate early with legal and security on data governance, data residency, and evolving regulations like GDPR. The right guardrails reduce rework later and enable faster regional launches—because compliance is a feature customers feel, even when they don’t see it.
On the commercial side, I partner on consumption SaaS pricing, product-led growth motions, and country-level market entry. Some markets need lighter onboarding and in-app guides; others demand concierge support or partner-led distribution. I use retention analysis to identify fit and inform sequencing, then adjust messaging and activation flows to shorten time-to-value and improve user activation by region.
My analytics and enablement stack is intentionally boring—and ruthlessly consistent. A unified analytics platform with Amplitude analytics gives us comparable funnels across countries. For experimentation, I run A/B testing with a clear minimum detectable effect (MDE) and disciplined rollout plans. Pendo powers product tours and in-app guides tailored by locale, while Intercom and CRM integration with HubSpot help me close the loop with GTM and support teams. The outcome is a learning system, not just a dashboard.
The hardest part isn’t translation—it’s alignment. Time zones, competing priorities, and matrixed ownership test even strong cultures. I rely on stakeholder management, crisp decision records, and product roadmapping and sprint planning rituals that respect regional input without derailing the global plan. When tension rises, I return to first principles decision making and the try do consider framework to make trade-offs transparent and repeatable.
If you’re growing into this role, start by owning a multi-region initiative end to end: lead localization for a critical workflow, run market-specific A/B testing with clear MDE, and publish a country launch plan that ties discovery insights to OKRs and resourcing. Build your credibility by shipping outcomes, not artifacts—then scale your impact by mentoring peers and creating shared templates for pricing, positioning, and experimentation. That’s how you shift from capable PM to trusted global operator.
Ultimately, a Global Product Manager is a force multiplier. We reduce complexity for the organization while increasing resonance for customers. If “products without borders” is your mandate, build the systems—analytics, governance, enablement, and decision-making—that make borderless execution reliable, repeatable, and fast.
Your product managers are probably already using AI to summarize feedback, draft requirements, and prepare planning documents. The harder question is whether any of that is improving the decisions behind the documents.
That distinction matters. Faster artifact production can create the appearance of progress while weak evidence, unclear ownership, and unresolved trade-offs remain untouched. A useful AI-enabled product operating model shortens the path from customer evidence to accountable action without treating fluent output as product judgment.
Start with a recurring decision, not a general-purpose assistant
The natural starting point is an assistant that can answer anything. It is also difficult to evaluate because every request has different inputs, quality criteria, and consequences. Start with one recurring decision whose current workflow you understand.
Define a decision contract before choosing a model or writing a prompt:
Decision: State the exact choice to be made. Replace improve onboarding with choose which activation barrier to address next.
Trigger: Name when the workflow runs, such as before roadmap review, after a discovery cycle, or when an anomaly appears.
Required evidence: Identify the interviews, support records, analytics, CRM context, experiments, and strategic constraints that must inform the choice.
Output contract: Specify the claims, citations, contradictory evidence, unknowns, and proposed next questions the AI must return.
Decision owner: Name the person accountable for accepting, rejecting, or changing the recommendation.
Red lines: Identify actions the system may not take, data it may not expose, and conclusions it may not present without review.
Outcome signal: Choose the product or workflow measure that will reveal whether the decision improved anything.
If you cannot name the decision owner and the action that follows the output, you have an AI demonstration rather than an operating workflow.
Product decision
What AI can prepare
What the PM must decide
Which problem to investigate
Clusters of interview, support, and behavioral signals with links to the underlying records
Whether the pattern is strategically important and which customers need follow-up
Which roadmap request deserves attention
Evidence by segment, frequency, workflow, and conflicting signal
Opportunity cost, strategic fit, and whether the request represents a problem or a proposed solution
Whether an experiment is ready
Hypothesis, acceptance criteria, instrumentation needs, and minimum detectable effect inputs
Whether the causal question is worth testing and whether the exposure risk is acceptable
How to position a capability
Customer language, points of parity, objections, and candidate messages
The value proposition and competitive differentiation the company can credibly defend
How to respond to an operational signal
Anomaly context, affected journey stage, supporting records, and candidate playbooks
Whether to intervene, whom to affect, and how to judge the result
The prompt should reflect that contract. A weak request says: summarize customer feedback. A decision-ready request says: for the specified segment and workflow, group evidence by customer problem, cite every supporting record, identify contradictions and missing coverage, separate observation from inference, and propose the next discovery question without recommending a roadmap commitment.
That change is small but important. It directs AI toward evidence preparation while preserving the PM’s responsibility for interpretation and commitment.
Build a context layer your PMs can interrogate and verify
A generic model knows language patterns, not the current state of your customers, product, strategy, or commitments. Copying a few notes into a prompt helps with an isolated task, but it does not create a reliable product-management system.
Retrieval-Augmented Generation connects an LLM to internal product, customer, and market knowledge so relevant material can be retrieved when a question is asked. For a PM, that knowledge may include interview notes, support tickets, win-loss records, QBRs, specifications, CRM data, and product analytics. The practical benefit is not merely a more personalized answer. It is an answer that can be checked against the company’s evidence.
Do not begin by indexing every repository. A large corpus increases coverage, but it also introduces stale specifications, duplicate tickets, conflicting terminology, inaccessible customer data, and documents whose status is unclear. Trust is usually lost at the corpus boundary before it is lost at the model layer.
A minimum trustworthy context layer needs:
Explicit scope: Document which repositories, products, segments, and time periods are included. The system should disclose when a question falls outside that scope.
Access enforcement: Apply user and tenant permissions during retrieval, not merely after an answer has been generated. A record being technically retrievable does not make it appropriate for every PM or every output.
Useful metadata: Preserve product area, customer segment, workflow, channel, date, product version, record owner, and status where available. These fields help distinguish current evidence from historical noise.
Evidence hierarchy: Decide how the system handles an approved specification that conflicts with an old planning note, or verified analytics that conflict with an anecdotal request. It should show the conflict rather than silently blending the two.
Answer boundaries: Require separate sections for supported facts, inferences, contradictory evidence, and unknowns. Require links to the records carrying each material claim.
Feedback history: Store reviewer corrections and the failure category behind each correction. A thumbs-down with no explanation does not tell you whether retrieval, reasoning, freshness, permissions, or presentation failed.
Start in read-only mode with a narrow, high-signal workflow, such as synthesizing support patterns for one segment. Ask reviewers to mark each important claim as supported, partly supported, or unsupported and to note relevant evidence that was missed. A polished answer with no traceable basis fails even when its conclusion happens to be plausible.
RAG does not turn internal data into truth. Retrieval can return stale, partial, or contradictory material, and a missing record is not proof that a customer problem does not exist. Your PM still has to assess coverage, distinguish signal from sampling bias, and decide when fresh discovery is necessary.
Privacy-by-design belongs in this layer as well. Support and CRM records may contain personal information, confidential commitments, or account-specific context. Minimize what is indexed, redact what is not needed, preserve access controls, and define which outputs may leave the internal workflow. Data governance is part of product quality here, not an administrative task to add after launch.
Match AI autonomy to the consequence of being wrong
Human review is too vague to be a control. It can mean a careful decision by an accountable owner, or a hurried click on an approval button after the work has effectively been accepted. Define autonomy according to the consequence and reversibility of each action.
Assist: AI transforms material without changing external state. Examples include transcribing notes, formatting requirements, clustering feedback, or drafting an internal brief. The user reviews the result before relying on it.
Recommend: AI interprets evidence and proposes a choice, but a named owner makes the decision. Roadmap evidence summaries, experiment proposals, and candidate positioning belong here.
Act reversibly: AI performs a bounded action that is observable and easy to undo, such as creating a draft ticket, applying an internal label, running an analysis, or staging an in-app guide in preview. Tool permissions, scope, and rollback must be enforced.
Act with material consequence: The workflow affects customers, exposure to an experiment, permissions, contractual commitments, published messaging, or data that cannot be restored easily. Require explicit approval from the accountable owner before execution.
For consequential actions, make the approval packet decision-ready:
The exact action the agent proposes to take
The affected product area, customer cohort, or internal system
The evidence supporting the action, with links
Contradictory evidence and unresolved uncertainty
The expected product outcome and how it will be observed
The rollback procedure and the conditions that trigger it
The approver, approval expiry, and complete action log
Enforce guardrails in the system rather than relying on prompt language. Use constrained service accounts, scoped tools, staging environments, rate limits, complete logs, and an accessible kill switch. A prompt is an instruction to a model; it is not a security boundary.
My rule is simple: if the accountable PM cannot explain how the evidence supports the proposed action, the workflow has not earned more autonomy. The right response is to improve the context and evaluation loop, not to make the approval interface easier to click through.
Evaluate the output, the workflow, and the product outcome
An AI initiative can generate more documents while making product management worse. More drafts may create review queues, spread unsupported claims, or encourage teams to reopen decisions that lacked new evidence. Measure three layers so local speed is not mistaken for organizational value.
Evaluation layer
Question
Evidence to inspect
Output reliability
Is the result grounded, complete enough for its purpose, appropriately uncertain, and safe to use?
Does AI reduce elapsed time and rework without moving effort into a hidden review step?
Time from trigger to decision, acceptance and editing patterns, handoffs, reopened work, and blocked decisions
Product impact
Did the resulting decision improve the customer or business outcome the workflow exists to influence?
The relevant activation, retention, experiment, support, or commercial measure, interpreted in the context of the decision
Baseline the existing workflow before introducing AI. Record its trigger, participants, elapsed time, common failure modes, and decision outcome. Otherwise, a faster AI run will be compared with an imaginary manual process instead of the work people actually perform.
Use outcomes rather than artifact volume when setting the objective. Drafts produced, prompts submitted, and active users describe activity. A shorter evidence-to-decision cycle, fewer unsupported roadmap claims, or better performance on the product outcome describes value. The metric must match the workflow; there is no universal AI productivity score.
A practical review loop looks like this:
Maintain a representative evaluation set containing ordinary cases, known failures, ambiguous inputs, permission boundaries, and contradictory evidence.
Run the current prompt, retrieval configuration, model, and tools against that set.
Have the relevant product, design, engineering, data, or domain reviewer score the output against the decision contract.
Classify each failure. Separate missing retrieval from unsupported inference, stale context, permission errors, incomplete instructions, and poor presentation.
Change one major component at a time so you can tell whether the prompt, corpus, retrieval rules, model, tool, or approval design improved the result.
Run the full evaluation set again before promoting the change. Keep prompts and retrieval configurations versioned so regressions can be traced and reversed.
Review production corrections and near misses, add them to the evaluation set, and revisit the autonomy level if the consequence profile has changed.
This is a good ritual for a product trio, with engineering or a forward deployed engineer handling system integration and observability where the workflow requires it. The PM owns the problem definition and decision quality; design protects the fidelity of customer interpretation; engineering owns the reliability and bounded behavior of the implementation. Subject-matter owners still review claims that cross their domain.
Expand in stages. Move from a single-segment synthesis to a cited discovery brief, then to roadmap evidence, experiment preparation, and only later to reversible execution. Do not promote the workflow when material claims remain uncited, permission failures are unresolved, reviewers cannot explain its conclusions, or downstream rework is increasing. Those are operating failures, even if the model’s prose looks strong.
Key takeaways
Choose one recurring product decision and define its owner, evidence, output, red lines, and outcome before selecting AI tools.
Use a governed retrieval layer to make internal context accessible, current, permission-aware, and traceable to the underlying records.
Separate evidence preparation from judgment. AI can organize and challenge the case; the PM remains accountable for the bet.
Increase autonomy only when actions are bounded, observable, reversible, and supported by an explicit approval model.
Evaluate output reliability, workflow performance, and product impact. Artifact volume is not a proxy for better product management.
Scale only after real corrections and failure cases have been added to a repeatable evaluation set.
Before your next planning cycle, pick one disputed decision that repeats often. Write its decision contract, assemble a small representative evidence set, and run the AI workflow in read-only mode beside the current process. If reviewers can trace the material claims, identify what is missing, and make the decision with less rework, you have a foundation worth expanding. If they cannot, improve the context and controls before adding another feature or agent.
It’s Monday morning, and my Slack and email are already overflowing with content requests: “Can you review this flow?”; “Can you rewrite this screen?”; “Can you name this feature?” I’m not freshly back from holiday—this is just a regular work week kicking off. If you’ve ever been a solo content designer supporting multiple teams, you’ll recognize the pressure. The pipeline for content in product design is always full, and the demand for expertise never stops.
Fixing this isn’t just a matter of better time management or incremental process tweaks. To truly scale, I needed to extend my reach by bringing AI into the design process—without sacrificing judgment, standards, or quality. That Monday morning, I realized I had to scale my skills, my judgment, and our systems, not just my calendar.
Building AI is fundamentally about building systems. I wanted to use AI to scale myself without devaluing critical thinking or flooding the product with generic, verbose content. I also knew a useful AI tool must do more than spit out microcopy—it has to plug into a system we can continually shape. As a content designer, the system is always the starting point. Strong design systems create strong content standards; then AI agents can produce content that meets those standards at speed, freeing me from the bulk of standardized work. That’s not a threat—it’s an advantage. To instruct AI well, our systems must be well constructed.
I often think about this work like a bakery. You need a recipe before you can make a loaf of bread. Most interface content churns out the same loaf, day in and day out. It’s better for the master bakers to focus on the unique, custom bakes—and how the recipe needs to change. With that mindset, I set out to build an AI content design agent.
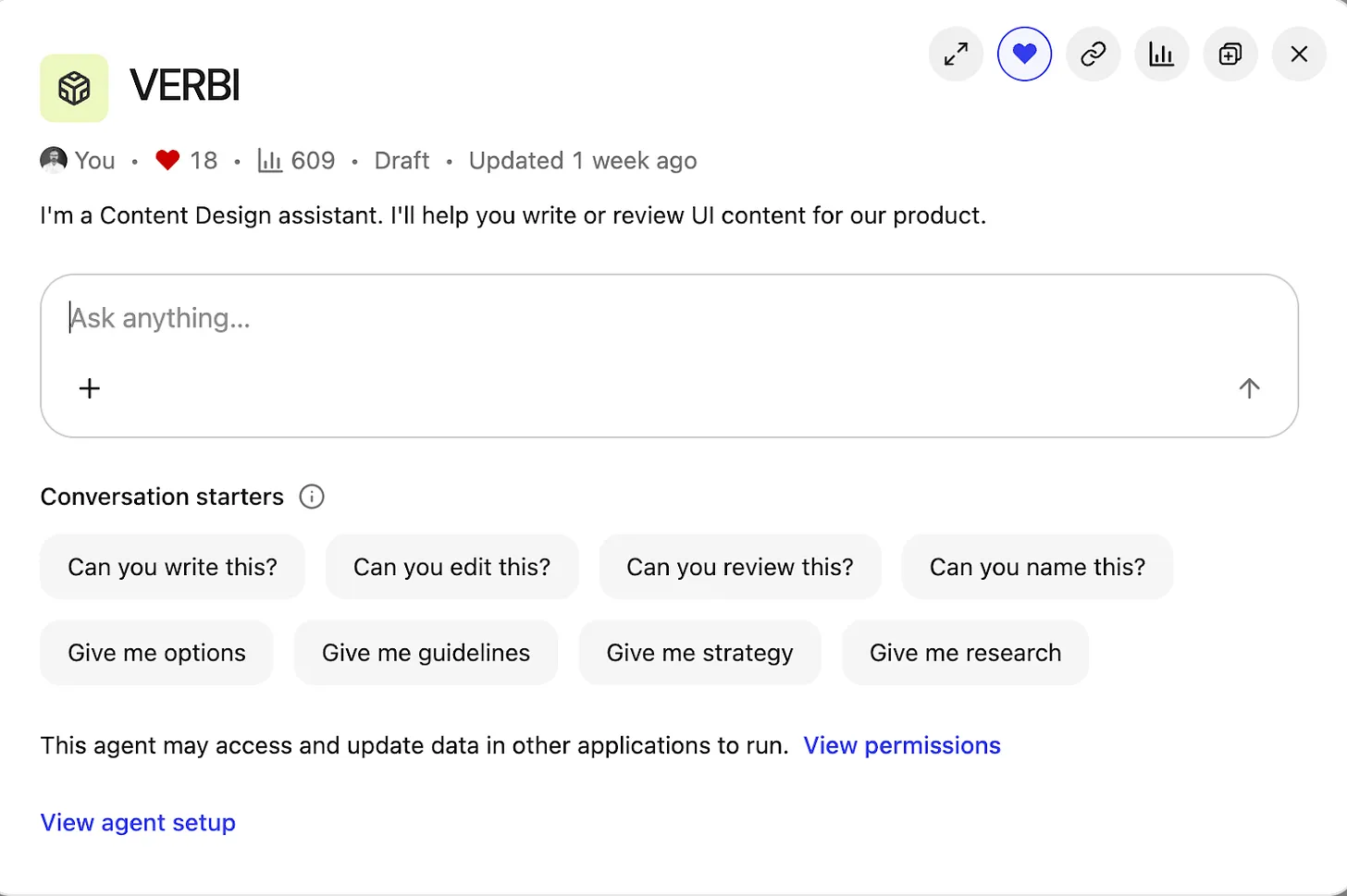
Inside the Content Design Agent workspace, a clean chat UI titled VERBI pairs a central prompt box with chips for writing, editing, and reviews, plus clear controls to view permissions and open the agent setup for product teams.
When I started this project back in May 2025, many LLMs still had frustrating limitations. Google Gemini let me build a custom Gem agent, but I couldn’t share it with other users. ChatGPT could be customized, but only with static files: I couldn’t point it to live, updatable URL sources. I settled on Glean for three simple reasons: everyone at the company had access; Glean could access all internal documentation and treat URLs as sources of truth; and its then-new Agents feature made AI search customizable. Configuring an agent in Glean is straightforward—you choose a trigger, a set of prompts, and a set of actions—but first I needed to get the inputs right.
AI agents need focus. We had a wealth of internal information at Intercom, but not all of it was current or reliable. I curated exactly what the agent could access and assembled a tightly governed knowledge collection in Glean. Only essential information made the cut: the Intercom style guide—our definitive house style, including regularly-broken rules like “always write in US English” and “use sentence case everywhere”; tone of voice guidance for how we show up across mediums; a product glossary with hundreds of feature names and writing conventions; a monetization glossary for prices, plans, and add-ons; product marketing messaging guides with positioning for every feature and launch; core research insights across the product; and fin.ai and intercom.com/suite as the official, most up-to-date messaging sources.
This is classic RAG (retrieval-augmented generation) in action, ensuring every answer is grounded in approved sources of truth. With the collection in place, I instructed the agent to prioritize these resources above anything else.
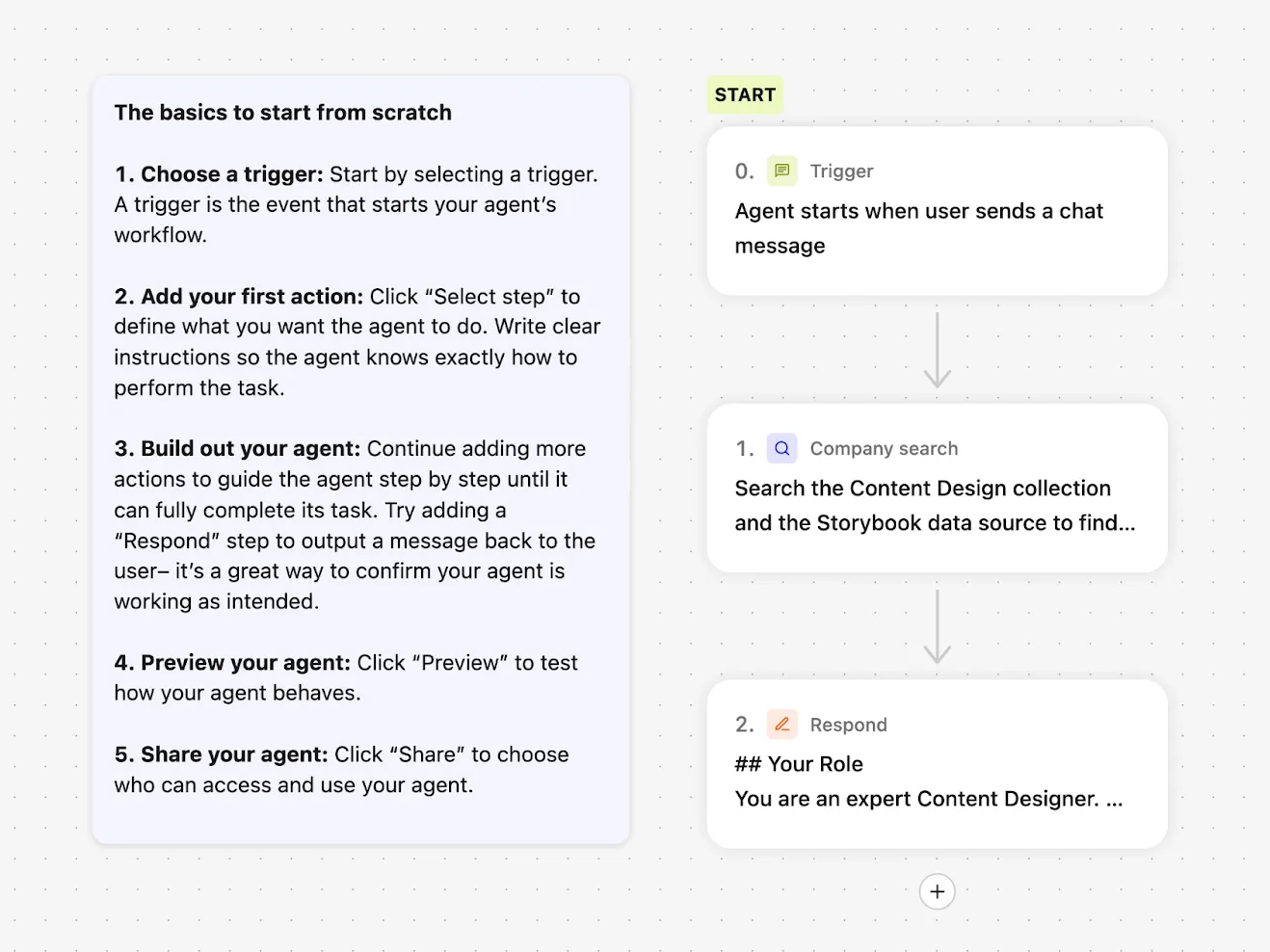
Step into a clean, no-code builder that shows how to assemble a Content Design Agent: kick off with a chat-trigger, run a company search, then respond with expert guidance, all guided by a simple starter checklist.
Then came the fun part—building and branding the agent. “Content Design Assistant” felt bland, so I named it VERBI, a nod to its “verbal” design job. When people interact with VERBI, they usually begin with a question, but the intent varies widely. I defined a set of task prompts to guide expectations and outputs: “Can you write this?”; “Can you edit this?”; “Can you review this?”; “Can you name this?”; “Give me options”; “Give me guidance”; “Give me strategy”; “Give me research.” This mirrors the real breadth of content design, from creation to critique to discovery.
To manage responses, VERBI needed three things: start with a specific task prompt; understand how to draw on the right resources each time; and connect with other systems. With task prompts defined, I wrote a detailed system prompt covering the essentials. Role: you are a content designer, supporting product designers. Employer: Intercom (consisting of Fin AI Agent and our next-gen Helpdesk). Resources: content design collection, research collection, Storybook design system. Tone of voice: follow a specific tone for our UI, adjust the tone for everything else. Components: for UI, use the specific guidelines in our design system only. Use cases: writing, editing, critiquing, naming, researching, and more.
One connection mattered most: our design system, recently rebranded as “Surge.” Surge contains detailed content guidelines for every component in our product UI, from accordions and banners to tabs and tooltips. That granularity took months of human effort to codify, and it paid off. Designers no longer guess how to write for a toggle, a button, or a tooltip—and now VERBI understands and enforces those rules, too. A great content design assistant isn’t just a clever system prompt; it needs deep, component-level guidance to retrieve.
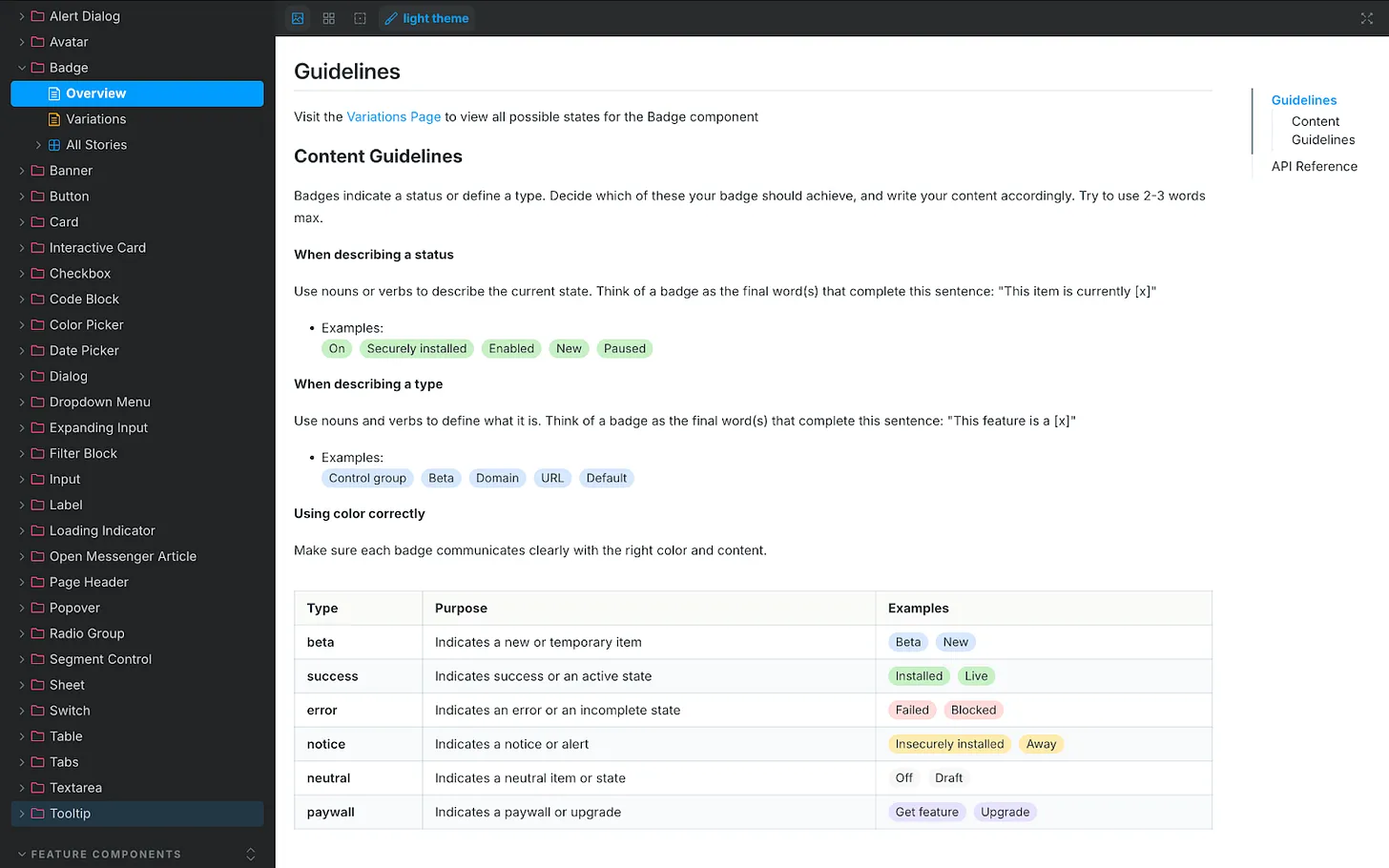
UI documentation showcases the Badge component’s content rules, teaching how to name statuses, define types, and apply color so labels read clearly. A handy visual for building a content design agent and ensuring consistent product messaging.
Accessing the design system wasn’t simple at first. It lives in Storybook, which Glean couldn’t access directly. I started by scraping guidance from Storybook into an HTML file with Cursor and uploading it to VERBI—a functional but clunky workaround that required re-scraping every few days. Then our IT team stepped in. They used the Glean Indexing API to turn Storybook into a live data source. Now VERBI connects to Storybook directly. Ask it something ultra-specific, like the correct date format for Japan, and it returns the right answer. That integration elevated the agent from helpful to indispensable—human-level precision, 24/7, at scale.
With prompts and resources in place, I launched VERBI and pressure-tested it. It was accurate and well-informed most of the time, but like any AI agent, it had quirks. I needed it to act as a gatekeeper, not a brainstorming partner that might bend rules or invent new ones. So I added a few explicit guardrails to the system prompt. Stopping sycophancy: “Inform, challenge, and assist. Never placate. Don’t agree by default. If something’s wrong, say so. Challenge assumptions.” Halting hallucinations: “If you don’t find the information required in our resources, say you don’t know the answer. Don’t guess and don’t give answers based on general knowledge.” Avoiding verbosity: “Keep answers short and to the point. Cut the fluff. Skip all niceties and social padding. Only give longer answers if the user asks you to.” These constraints keep responses crisp, correct, and consistent. Like any living system, the prompt needs occasional tune-ups, but the maintenance is minor compared to the upside.
Where we are now: VERBI has been triggered 700+ times since launch. The benefits are tangible. For me, quality scales without constant policing; repetitive questions about naming, style, or punctuation have dropped significantly. I reclaim time because the agent drafts and checks V1 content across teams, enabling me to focus on higher-impact work. For the design team, iteration is faster, confidence is higher, and strategic clarity improves because shared language and grounded guidelines make decisions easier and more consistent.
I used to spend too much time mopping up basic content mistakes and untangling spaghetti-like UI copy prone to human error. VERBI removes those errors at the source. The real advantage is speed: we get from blank slate to a high-quality first draft quickly, which means we can spend our energy deciding whether the content is right, not just “good enough.” Design is the whole interface—words, visuals, interactions—so reviews now happen with real content, never “copy TBD.” Our principle to sweat the details applies equally whether work is human-made or AI-assisted.
Knee-jerk critiques of AI-driven content design often assume teams generate content from nothing and ship it. In reality, great AI is the outcome of great human decisions and strong systems. Its value is pulling us together faster—getting us to a complete, standards-compliant design we can review as a team before sharing it with the world. That’s how AI helps us win: by turning chaos into consistency, and consistency into velocity.
Over the past year, I’ve been shipping agentic AI into production and coaching product teams on what it really takes to make these systems trustworthy in the wild. One story that crystallizes the playbook comes from Trainline’s move to an agentic architecture for travel assistance—an approach that mirrors what I’ve seen work in high-stakes, real-time customer experiences.
Trainline—the world’s leading rail and coach platform—helps millions of travelers get from point A to point B. Now, they’re using AI to make every step of the journey smoother.
I studied how "David Eason (Principal Product Manager) Billie Bradley (Product Manager), and Matt Farrelly (Head of AI and Machine Learning)" approached the build of "Travel Assistant, an AI-powered travel companion that helps customers navigate disruptions, find real-time answers, and travel with confidence." Their work exemplifies the kind of end-to-end thinking required to move beyond demos into dependable, on-the-go assistance.
They share how they: Identified underserved traveler needs beyond ticketing; Built a fully agentic system from day one, combining orchestration, tools, and reasoning loops; Designed layered guardrails for safety, grounding, and human handoff; Expanded from 450 to 700,000 curated pages of information for retrieval; Developed LLM-as-judge evals and a custom user context simulator to measure quality in real-time; Balanced latency, UX, and reliability to make AI assistance feel trustworthy on the go.
I align strongly with their core takeaways: "AI assistants need both scalable reasoning and deep domain context to be useful." "Tool design and guardrails are as critical as prompt design in agent systems." "LLM-as-judge evals make it possible to measure open-ended systems without massive labeling costs." And perhaps most importantly, "Even legacy companies can move fast when they embrace experimentation and tight PM–engineering collaboration."
From an AI strategy perspective, starting "fully agentic" was the right call. When the problem space is dynamic—disruptions, route changes, fare conditions—reasoning loops and orchestration aren’t luxuries; they’re table stakes. Tool selection becomes product design: you need the right retrieval interfaces, constraint-aware planners, and API contracts that are resilient to partial failures. Layered guardrails for safety, grounding, and human handoff reduce hallucination risk while preserving responsiveness—critical when users are standing on a platform waiting for an answer.
The retrieval scale-up—"Expanded from 450 to 700,000 curated pages of information for retrieval"—is a classic inflection point. I’ve seen teams stall here when they treat content growth as a pure indexing problem. The winning move is curation and structure: normalize sources, encode policy-level constraints, and align retrieval chunks to decision boundaries the agent actually uses. That’s how you keep precision high while coverage explodes.
Evaluation is where most open-ended assistants fail quietly, which is why I was encouraged to see "Developed LLM-as-judge evals and a custom user context simulator to measure quality in real-time." In practice, LLM-as-judge gives you scalable, scenario-based scoring without prohibitive labeling, while a user context simulator surfaces regressions tied to persona, itinerary state, and device constraints. The combination closes the loop between model behavior, tool layer changes, and UX outcomes.
On product delivery, the decision to have the system "Balanced latency, UX, and reliability to make AI assistance feel trustworthy on the go" shows mature prioritization. For travel, trust accrues in seconds: fast-enough responses, graceful degradation when upstream data lags, and explicit handoff when confidence dips. This is where guardrails meet UX writing—clear, bounded language signals competence even when the system defers.
Finally, the organizational pattern matters. The teams that win in agentic AI are cross-functional, experimentation-driven, and ruthless about instrumentation. Tight PM–engineering collaboration, explicit safety thresholds, and an eval stack that mirrors real user journeys are what turn promising architectures into dependable products.
It’s a behind-the-scenes look at how an established company is embracing new AI architectures to serve customers at scale.
If you’re building agentic AI in production, borrow these moves: invest early in tool and guardrail design, scale retrieval with curation not just volume, adopt LLM-as-judge plus context simulation for continuous evaluation, and treat latency and reliability as core product requirements—not afterthoughts. That’s how you ship AI assistance that customers trust when it matters most.
Context is king in AI-powered product work—and I felt that deeply while digging into “Context is King – All Things Product Podcast with Teresa Torres & Petra Wille.” The conversation affirmed a truth I see daily: AI becomes a powerful teammate only when we give it the right context, just as we do with empowered product teams. When we treat AI like a colleague joining mid-flight—without our company history, industry nuances, or strategy—we instantly unlock better outcomes.
Listen to this episode on: Spotify | Apple Podcasts
Here’s what stood out and how I’m applying it. First, most AI outputs fail without proper context. That’s not a model problem; it’s a leadership problem. Thinking of AI like onboarding a new intern is the right mental model—start with the minimum viable context, then iterate. Practical first steps matter: decision logs, clear success metrics, and structured documentation. The art is balancing enough context to guide performance without overloading the system. The parallels are striking: the way we create strategic context for product trios and teams is the same way we’ll empower agentic AI systems.
In my teams, we prepare for AI collaboration by operationalizing context. We keep decision logs to capture the why behind choices, use outcome-based success metrics (not just output), and maintain machine-readable documentation that LLMs for product managers can parse reliably. We define guardrails up front—constraints, customer segments, privacy-by-design considerations, and the non-goals that often trip up gen ai. This foundation turns AI from a novelty into a force multiplier for product discovery and product roadmapping and sprint planning.
I use a simple “context pack” to onboard AI agents and teammates alike: 1) business goals and outcomes, 2) constraints and guardrails, 3) canonical artifacts (like PRDs, journey maps, interview notes), 4) domain vocabulary and definitions, and 5) operating procedures (how we make decisions, when to escalate, what good looks like). Start small, then refine as the AI demonstrates capability. This mirrors great onboarding—and it works just as well for agentic AI as it does for humans.
Not all context is helpful. More isn’t better; the minimum effective context is. I resist the urge to dump our entire Confluence on an AI system. Instead, I progressively reveal relevant details—just like I would with a new PM on a complex problem space. This keeps signals high, noise low, and performance measurable against clear success metrics.
If your org isn’t adopting AI yet, don’t wait. You can become AI-ready now by documenting strategic intent, decision rationale, and definitions in structured, searchable, machine-readable ways. Treat this as core AI Strategy work that strengthens empowered product teams—regardless of tooling—while building your AI product toolbox for tomorrow.
For those who want to explore further, these resources and mentions are a strong complement to the episode’s themes.
Follow Teresa Torres: https://ProductTalk.org
Follow Petra Wille: https://Petra-Wille.com
Agentic AI
Teresa’s new podcast, Just Now Possible in Youtube, Apple Podcast, and Spotify
Petra’s Coaching Packages
ChatGPT
Henrik Kniberg’s talk at Product at Heart on treating AI agents like interns
Teresa’s webinars on how she built the Product Talk Interview Coach: Behind the Scenes: Building the Product Talk Interview Coach and How I Designed & Implemented Evals for Product Talk’s Interview Coach
Josh Seiden’s blog series about AI
Teresa’s new blog posts: 15 Ways to Use AI at Home (and Fill Your AI Product Toolbox) and 21 Ways to Use AI at Work (And Build Your AI Product Toolbox)
Petra's new blog post: Why Context, Not Just Data, Will Define AI-Ready Product Teams
Have thoughts on this episode or how you’re preparing your teams to collaborate with AI? Leave a comment below—let’s compare playbooks and level up together.
Digital transformation rewired our systems; AI transformation rewires how we learn, decide, and compete. “AI transformation goes beyond automation to create adaptive, intelligent organizations. Discover why it’s the next imperative and how to measure success.” That statement captures what I experience daily: we’re moving from scripted workflows to living systems that improve with every interaction.
When I talk about AI transformation, I’m not describing a tool rollout. I’m describing an operating model where data, models, and product strategy converge to create compounding advantage. In practice, that means agentic AI orchestrating tasks, robust data governance and privacy-by-design from day one, and empowered product teams that ship, measure, and iterate at high tempo.
The imperative is strategic, not merely technical. Markets are compressing cycle times, and customers now expect intelligent experiences by default. Organizations that master AI Strategy and product-led growth will set the pace—using AI for competitive differentiation rather than feature parity.
This shift changes how I build teams and backlogs. I lean on product trios, forward deployed engineers, and tight product discovery loops to reduce uncertainty early. We design for resilience and learning: human-in-the-loop feedback, clear escalation paths, and telemetry that turns every interaction into a hypothesis test.
Governance is a first-class feature. AI risk management, data governance, and threat detection and response sit alongside performance metrics in the same dashboard. We codify guardrails—policy, provenance, and permissions—so innovation scales safely and sustainably.
Measurement is where transformation becomes real. I anchor on outcomes vs output OKRs tied to customer value and revenue impact. At the product layer, I track activation, time-to-value, retention, and adoption by persona. For ML quality, I monitor precision/recall, coverage, hallucination rate, and model drift. In experimentation, A/B testing with a thoughtful minimum detectable effect (MDE) prevents false wins, while Amplitude analytics, Pendo, and Intercom instrumentation expose where guidance or UX writing can unlock activation.
The fastest wins often start in service and sales. A customer support ai strategy can deflect tickets with high-resolution answers while escalating edge cases to humans with full context. CRM integration with HubSpot and a ChatGPT connector enables reps to generate next-best-actions, summarize calls, and personalize outreach—measurably lifting conversion and lowering cost-to-serve.
On the build side, LLMs for product managers and gen ai for product prototyping accelerate discovery cycles. I use CustomGPT workflows to validate value propositions quickly, then harden successful flows with engineering. Throughout, product positioning and a crisp value proposition ensure that what we ship is understandable, differentiated, and priced to match ROI—consumption SaaS pricing when usage scales value.
If you’re getting started, begin with a single, high-frequency journey, instrument it deeply, and publish transparent OKRs. Pair empowered product teams with clear governance, and iterate toward agentic AI experiences. The payoff isn’t a one-time launch; it’s a continuously learning system—and a culture—that compounds advantage release after release.
I’m fascinated by how the most credible legal-tech platforms operationalize AI in the enterprise, where risk tolerance is near zero and trust is the product. When I evaluate solutions in this space, I look for rigor in model design, governance, and go-to-market execution—not just raw model performance.
Discover how Luminance CEO Eleanor Lightbody builds Legal-Grade™ AI for enterprise. See how their specialized, agentic AI models lawyers trust at scale.
That framing resonates with me. “Legal-Grade™” isn’t a slogan; it’s a product requirement that implies auditable decisions, explainable outputs, robust data governance, and demonstrable accuracy under real-world legal workflows. “Agentic AI” adds another layer: autonomous orchestration of tasks with explicit guardrails, role definitions, and escalation paths to humans-in-the-loop.
From a product management perspective, I start with outcomes. For legal teams, the jobs-to-be-done are concrete: contract analysis and redlining, due diligence, compliance reviews, investigations, and eDiscovery. The success criteria are equally concrete: precision and recall on domain-specific clauses, latency under load, traceability of sources, and the ability to scale across matter types, jurisdictions, and languages without degrading trust.
Building that foundation requires deliberate AI strategy. I look for domain-specialized models, retrieval-augmented generation tuned to legal corpora, evaluation harnesses with gold-standard datasets, and continuous red-teaming. Just as important are deployment choices—on-prem or VPC isolation, encryption in transit and at rest, strict PII handling, and granular access controls—to satisfy the security posture of enterprise legal and compliance teams.
Governance is where “legal-grade” is won or lost. Robust audit trails, versioned prompts and policies, model cards, clear data lineage, and event logs that support defensibility are table stakes. Human review workflows, explainability tooling, and remediation paths ensure the system remains trustworthy when edge cases arise.
On product process, I favor empowered product teams and forward-deployed engineers partnering directly with attorneys and legal ops. Co-designing workflows with subject-matter experts surfaces the right constraints early: how redlines are presented, what confidence thresholds trigger review, and where to anchor the user experience in familiar legal tools and document structures.
Competitive differentiation and product positioning hinge on clarity: what specific legal outcomes are delivered faster, safer, or more accurately than alternatives? I prioritize transparent benchmarking against baselines, proof-of-value pilots that mirror production data conditions, and pricing that aligns to measurable outcomes (e.g., time-to-first-draft, review throughput, or risk reduction) rather than abstract usage metrics.
Go-to-market strategy in enterprise legal is a discipline in itself. Expect rigorous InfoSec reviews, stakeholder alignment across legal, IT, and procurement, and the need for customer references that demonstrate “trust at scale.” Clear messaging around value proposition, safety posture, and operational readiness shortens cycles and builds confidence among risk-averse buyers.
The big takeaway for product leaders: Legal-Grade™ AI isn’t about novel models; it’s about orchestrating specialization, safeguards, and enterprise-grade delivery into a coherent system that lawyers can rely on daily. When agentic AI is harnessed with the right guardrails and domain depth, it becomes a force multiplier for legal teams—accelerating work without compromising standards.
Inspired by this post on Amplitude – Perspectives.
Your funnel says users are leaving during setup. Your survey says they want more features. Sales thinks the positioning is wrong. Each signal may be valid, but none of them is a product decision yet.
To turn product insight into growth, you need a loop that answers four questions in order: where behavior breaks, why it breaks for a specific group, what small change could alter it, and whether that change improved durable behavior. Skip one, and a plausible idea can consume a sprint without teaching you much.
Start with the decision your insight must support
Do not begin with a request to explore the data or understand the customer. Those instructions are too broad. Start with a decision that someone is prepared to make.
I use a simple test: if the answer cannot change a roadmap choice, an onboarding choice, or an experiment, the question is not specific enough. Write a short decision brief before opening an analytics dashboard or sending a survey.
Decision: What choice will this work inform? For example, whether to simplify verification, change setup guidance, or reconsider the activation milestone.
Audience: Which users does the decision affect? Separate new users from returning users and identify the relevant channel, plan, role, device, or geography.
Outcome: Are you trying to improve activation, feature adoption, or retention? Pick one primary outcome.
Unknown: What must you learn before choosing? A location, cause, affected segment, or expected impact is more useful than a general request for feedback.
Alternatives: List the realistic actions available. Insight is valuable when it helps you choose among them.
Disconfirming evidence: State what would make you reject the leading explanation. This keeps the analysis from becoming a search for support.
The activation milestone deserves particular care. It should represent the first meaningful value a user receives, not merely an account action that is easy to count. Compare the retention of users who reach a proposed milestone with the retention of those who do not. That cohort contrast can reveal whether the behavior is associated with a more durable relationship. It does not prove causation, but it gives you a stronger milestone to test than intuition alone.
Do not let feature requests define the decision brief. A request is one expression of a need, filtered through the solution a user happens to imagine. Record it, then identify the underlying job, obstacle, and affected outcome before it reaches the roadmap.
Use behavioral data to locate the growth constraint
Behavioral analytics should first tell you where to investigate. It cannot reliably tell you why a user hesitated, but it can narrow a large product journey to a specific transition, cohort, and moment.
Start with a minimum viable activation map. A useful first pass is four to six events that cover the path from entry to first value. A typical sequence might be sign-up, verification, initial setup, and the first key action. Add an event only when it represents a meaningful state change or helps distinguish between competing explanations.
Before interpreting the funnel, verify the instrumentation. Use one event taxonomy, consistent names, and properties that let you isolate important groups. Channel, plan, device, role, geography, and cohort are useful when they correspond to a real product or go-to-market decision. An event called setup completed is not trustworthy until the team agrees on exactly what completion means and when it fires.
Build the funnel: Measure completion and drop-off at every transition from entry to first value.
Check event quality: Look for missing properties, duplicate events, unexpected ordering, and definitions that changed between releases.
Segment the loss: Compare channel, device, geography, plan, role, and new versus returning users. A product-wide average can conceal a concentrated problem.
Inspect paths: Look at what users do immediately before and after the weak transition. Repeated steps, detours, and exits help you form a more precise question.
Connect activation to retention: Compare users who reached the milestone with those who did not, then review relevant retention checkpoints.
Day 1, day 7, and day 30 are useful retention checkpoints alongside lifecycle and unbounded retention views, but they are not universal definitions of success. Match the interpretation to the natural rhythm of your product. A daily workflow and an occasional administrative task should not be judged by the same return pattern.
Segmentation changes the action. If a drop-off is concentrated on one device, a product-wide tour is likely too broad. If it is concentrated in one acquisition channel, the promise made before sign-up may be attracting users whose expectations do not match the product. If every segment struggles at the same step, the task itself deserves attention before you add more messaging.
Ask users when the behavioral evidence becomes interesting
Once the funnel identifies a consequential moment, ask users about that moment. A quarterly survey sent to the entire customer base mixes different jobs, lifecycle stages, and memories. A contextual survey triggered after onboarding, a product tour, or use of a new feature gives the respondent a concrete experience to evaluate.
What, if anything, made the task difficult to complete?
What did you expect to happen next?
The first question identifies the job. The two rating questions create trendable measures. The open prompts expose vocabulary, expectations, and failure modes that predefined answer choices can miss. Adjust the wording to the actual moment; do not ask someone who abandoned setup to rate a result they never saw.
Target cohorts separately. New users can explain expectation and comprehension gaps. Power users can expose workflow limitations. Retained and churning users can describe different value patterns. Combining them into one score produces an average that may represent none of them well.
Tell people why you are asking, how long the survey will take, and how the response will inform a decision. Then close the loop by sharing what changed. This is not ceremonial communication. It gives users evidence that thoughtful feedback does not disappear into a backlog.
For a large volume of open text, generative AI can accelerate initial clustering and sentiment labeling. Treat that output as a sorting aid, not a conclusion. Validate the themes manually and compare them with product telemetry. Models can merge comments that use similar language but describe different jobs, or separate comments that describe the same obstacle in different words.
Survey respondents are also a selected group: they were available and willing to answer. Compare their behavior with the full target cohort before generalizing. If respondents complete setup far more often than nonrespondents, their explanation may not represent the users you most need to understand.
Triangulate evidence instead of letting signals vote
Behavior and feedback do not need to agree perfectly. Their job is to constrain the explanation. Telemetry shows what happened at scale. Contextual feedback supplies possible reasons. Retention indicates whether the behavior mattered beyond the immediate session.
Behavioral signal
User feedback
Interpretation to test
Next move
Users stall before the key action
They report an unclear next step
Comprehension or discoverability may be blocking progress
Test clearer guidance at the exact transition
Users stall before the key action
They describe an error or failed dependency
Execution friction may matter more than education
Fix the failure before adding tours or tooltips
Users complete the funnel
They rate the outcome as having low usefulness
The milestone may measure activity rather than value
Revisit the activation definition and value proposition
Users reach first value and rate it highly
Later retention remains weak
The problem may occur after activation
Analyze the post-activation path and repeat-value moments
Use each row as a hypothesis, not a diagnosis. The same behavioral pattern can have several causes. A user might leave verification because the instructions are unclear, because the task fails, because the requested information feels unnecessary, or because the value promised before sign-up was not compelling enough. The next evidence or experiment should distinguish among those explanations.
Translate the combined evidence into a problem statement before discussing solutions:
When [specific cohort] tries to [job], they stall at [event or transition]. We observe [behavioral evidence], and contextual feedback repeatedly describes [theme]. This appears to affect [activation, adoption, or retention outcome].
This format prevents a popular feature request from outranking a larger but less vocal obstacle. Rank the resulting opportunities by user impact, strategic fit, and strength of evidence. Then connect each selected opportunity to a measurable activation, adoption, or retention outcome rather than treating delivery as success.
Conflicting evidence is useful when you investigate the conflict. High reported ease alongside high funnel abandonment may indicate respondent bias, a faulty event definition, or a hidden segment with a different experience. High activation among completers alongside severe pre-activation loss may point to an onboarding gate around a valuable product. Those patterns lead to different decisions, even if the top-line conversion rate is identical.
Convert one insight into a testable growth bet
An insight is not finished when it becomes a presentation. It is finished when it changes a decision and creates a measurable test. Capture the bet in one experiment card:
Problem: The cohort, job, and transition described in the problem statement.
Hypothesis: The mechanism you believe is causing the observed behavior.
Change: The smallest intervention that tests that mechanism.
Audience: The exact users who should encounter the change.
Primary metric: The activation, adoption, or retention behavior expected to move.
Guardrail: A behavior that should not deteriorate while the primary metric improves.
Evaluation: How you will distinguish the effect of the change from ordinary variation.
Next decision: What you will do if the result is positive, neutral, or negative.
Match the intervention to the suspected mechanism. An in-app guide can help a user resume a setup sequence. A product tour can expose a core workflow that users consistently overlook. A tooltip can resolve uncertainty at one control or decision point. None of them will repair a broken task, a misleading acquisition promise, or a weak value proposition.
Prefer a focused change over a wholesale onboarding redesign because it gives you a clearer learning signal. When traffic and risk allow, compare the changed experience with an appropriate control. Define the success measure before launch. Do not declare victory from higher setup completion if users still fail to reach first value or if the relevant retention behavior does not improve.
Put the bet into normal product roadmapping and sprint planning, and keep the evidence visible on a shared dashboard. Product, engineering, design, customer support, and customer-facing technical roles each see a different part of the journey. Their observations should refine the hypothesis, while the agreed metric remains the arbiter of the result.
When the decision is made, update the insight record with the result: observed, validated, tested, adopted, or rejected. Share the outcome with the users who contributed feedback when practical. Closing both the analytical loop and the communication loop makes the next round of discovery easier.
Key takeaways
Define the decision, cohort, outcome, and disconfirming evidence before collecting more data.
Map four to six trustworthy events from entry to first value, then segment the weak transition.
Use retention to check whether the proposed activation behavior is associated with durable value.
Trigger a five-to-seven-question survey at a meaningful product moment and combine ratings with open prompts.
Treat telemetry and feedback as inputs to a hypothesis, not competing votes on the roadmap.
Ship the smallest intervention that tests the suspected mechanism, then measure the downstream behavior that matters.
If you have one hour, choose one activation journey, verify the four to six events that describe it, segment new and returning users, and identify one consequential drop-off. Write one problem statement and one experiment card before refining the dashboard. That is enough to turn a vague growth discussion into a decision the team can act on.
You have a plausible startup idea, encouraging conversations, and a backlog that is already starting to grow. The danger is that activity begins to feel like evidence. A polished prototype, a busy launch, or a full pipeline can still conceal a weak problem, the wrong buyer, or a product people try but do not keep.
Treat discovery, validation, and growth as one decision system. At each stage, identify the assumption most capable of killing the business, run the least expensive credible test, and let the result determine the next investment. The goal is not certainty. It is to replace the largest unknown with evidence strong enough for the next decision.
Key takeaways
Start with a specific customer, triggering situation, painful consequence, and current workaround. Do not start with the product you hope to build.
Track four separate risks: value, usability, feasibility, and viability. A positive result against one risk does not automatically resolve the others.
Define the behavior that would support or disprove your hypothesis before customers see the test.
Treat compliments, clicks, and sign-ups as limited evidence. Payment, workflow change, realized value, and repeat use carry more weight.
Run growth experiments at the tightest constraint in the customer journey. Scaling acquisition before activation and retention are credible only sends more people into a leaking system.
Turn the startup idea into a risk ledger
Discovery should begin with a problem inventory, not a pitch deck. The useful question is not whether an idea sounds novel. It is whether a recognizable group of people encounters the problem often enough, feels a meaningful consequence, and already spends time, money, attention, or political capital trying to solve it. This disciplined loop from exploration to falsifiable validation prevents an attractive solution from outrunning the problem underneath it.
For each possible problem, capture:
User and context: Who experiences the problem, and in what situation?
Trigger: What event makes the problem urgent enough to act on?
Current behavior: What does the person do today instead of using your product?
Consequence: What becomes slower, more expensive, riskier, or less reliable if the problem remains unresolved?
Buying path: Who feels the pain, who approves a purchase, and who can block adoption?
Existing alternatives: Which product, service, spreadsheet, manual process, or decision to do nothing are you competing against?
Your advantage: What access, expertise, workflow insight, distribution, or credibility gives you a plausible right to win?
Fatal unknown: Which unproven assumption could invalidate the opportunity?
Customer interviews should reconstruct real events. Ask the person to walk through the last occurrence, what triggered it, what happened next, who became involved, and how the situation ended. Ask what they have already tried and why it was insufficient. Questions such as Would you use this? or Do you like this idea? invite politeness and speculation. They reveal little about what the person will do when time, money, and organizational friction enter the decision.
Keep observations separate from interpretations. The customer exports data every Friday and reconciles it manually is an observation. The customer wants an automated analytics platform is an interpretation. That distinction matters because several products could address the observed problem, including a process change that makes your proposed product unnecessary.
Will the target customer change behavior to obtain this outcome?
Problem interviews, a focused offer, a landing page, a fake door, or a concierge workflow
The right customer takes a meaningful next step, accepts switching effort, or makes a commercial commitment
Usability
Can the customer understand the product and reach the value without excessive help?
Paper flow, clickable prototype, or a guided simulation using realistic tasks
The customer completes the critical path, and observed confusion identifies specific design changes
Feasibility
Can the riskiest part work within the relevant technical, data, security, and operational constraints?
Engineering spike, API mock, data-model prototype, or throwaway service
The uncertain path works under representative constraints, or the team discovers the limitation before committing to production
Viability
Can the company sell, deliver, support, and sustain the product?
Pricing and packaging test, manual sales process, pilot proposal, or business-model comparison
The buying process, delivery burden, economics, and organizational obligations are compatible with the business you intend to build
Do not use a result in one row to declare the entire idea validated. A customer completing a clickable workflow establishes neither willingness to pay nor technical feasibility. A successful engineering spike says nothing about demand. A paid concierge service can support the value hypothesis while leaving scalability and margin unresolved. The ledger exists to stop evidence from being stretched beyond what the test actually measured.
Match the test to the next decision, not the final product
The smallest useful experiment is not always the fastest artifact to create. It is the fastest test that can produce credible evidence for the decision in front of you. A survey may be quick, for example, but it is a poor substitute for observing a buyer evaluate a defined offer and confront a real trade-off.
Use this sequence to design the experiment:
Name the decision. State what you will decide after the test: continue, change the segment, revise the offer, investigate a technical constraint, or stop.
Write a falsifiable hypothesis. Include the customer segment, triggering situation, proposed outcome, observable behavior, and result that would weaken the belief.
Select the unresolved risk. Decide whether the test is about value, usability, feasibility, or viability.
Choose the lightest honest test. Use only enough fidelity to make the target behavior realistic.
Predefine the evidence. Decide what will count as support, contradiction, or an inconclusive result before exposure to customer reactions.
Make the decision. Record whether you will proceed, pivot, pause, or run a narrower follow-up test.
A practical hypothesis might read: For operations leaders facing a recurring reconciliation problem, an assisted workflow that produces a review-ready output will lead qualified buyers to begin a paid pilot; I will reconsider the offer if the problem is acknowledged but buyers will not accept the commercial next step. The strength of the statement is not its prose. It connects a defined customer and trigger to a behavior that can prove you wrong.
Know what each lightweight test can prove
A story-based interview can establish that a problem occurs, reveal its context, and uncover existing workarounds. It cannot establish demand for your proposed product.
A message or landing-page test can measure whether a defined audience recognizes the promise and takes an initial step. It cannot establish realized value or retention.
A fake door can reveal intent inside a realistic journey. It should disclose the capability’s actual status before the user makes a consequential commitment, then provide a truthful next step.
A concierge or manual workflow can show whether the outcome matters before automation exists. It cannot establish scalable delivery economics unless the manual effort is also measured.
A pricing or pilot test can expose budget, authority, objections, and willingness to commit. A hypothetical price question is weaker because the respondent gives up nothing by answering.
A clickable prototype can reveal whether the workflow is understandable. It cannot prove that the underlying problem is urgent.
An engineering spike can retire a difficult technical assumption. It should remain disposable unless it also meets the standards required of production software.
Focused prototypes are often suitable for 24-72-hour timeboxes. Generative AI can compress that work by creating realistic interface states, drafting microcopy, generating test data, simulating edge cases, or scaffolding a throwaway service. That speed is valuable, but it creates a subtle trap: a convincing artifact can increase internal confidence before customer evidence has changed. AI accelerates the test surface; it does not validate the assumption.
For early traction, keep the channel stable while testing the offer. If you change the audience, message, channel, and price at the same time, a positive result is hard to explain and a negative result tells you little about what failed. A one-channel test gives you fewer variables to interpret. Once the mechanism is clearer, test whether it transfers.
Do not borrow a generic conversion benchmark and call it validation. The required evidence depends on the decision, the cost of being wrong, the maturity of the product, and the commitment you asked customers to make. Set the decision rule in advance, then examine the behaviors and objections by customer segment. An aggregate result can look promising while the intended buyer consistently rejects the offer.
Read the evidence without promoting weak signals
Validation is not a binary label attached to an idea. It is a progression from evidence that the problem exists to evidence that a repeatable business can solve it. The further a customer moves down that progression, the more real trade-offs enter the decision.
Problem evidence: The target customer describes a concrete past event, its consequence, and the workaround already used.
Intent evidence: The customer gives time, information, access, or organizational attention to explore the offer.
Commitment evidence: The customer accepts a meaningful next step such as a commercial discussion, pilot process, procurement action, workflow change, or payment.
Realized-value evidence: The customer reaches the promised outcome, not merely the end of onboarding.
Repeat-value evidence: The customer returns, continues the workflow, or relies on the outcome again.
Expansion or referral evidence: The value is strong enough to justify wider use, greater spend, or a credible introduction.
Early signals are still useful when interpreted narrowly. A click can tell you that a message attracted attention. A waitlist can reveal which promise generated interest. A demo request can open a discovery conversation. The mistake is promoting any of those signals into proof of retention, pricing power, or product-market fit.
Watch especially for false positives created by the wrong audience. Broad curiosity can produce traffic while the intended buyer remains unmoved. Free access can produce usage that disappears at the first commercial conversation. Heavy founder involvement can create successful outcomes that the product cannot yet reproduce. Paid acquisition can add enough volume to hide weak activation and retention for a while. Segment the evidence and name the operator effort behind it.
Find the customer’s locksmith moment
I use locksmith moment as a practical label for the instant when the product unlocks a stubborn problem with surprising ease. It is more precise than sign-up, account creation, or feature adoption. If the promise is faster reconciliation, the locksmith moment is not connecting a data source. It is obtaining a trustworthy reconciled result with less effort than the previous process required.
Define that moment in observable terms. Instrument the steps leading to it. Interview people who reached it and people who abandoned the path. Then adjust the message, onboarding, defaults, and assistance so qualified customers reach the same outcome sooner and more reliably. This turns activation from a convenient product event into evidence that value occurred.
Use three decision outcomes consistently:
Proceed when the intended segment displays the predicted behavior and the remaining uncertainty belongs to the next risk in the ledger.
Pivot when the underlying pain is credible but the segment, trigger, promise, workflow, price, or business model is wrong.
Pause when supportive language does not translate into costly current behavior, meaningful commitment, realized value, or a plausible path to viability.
An inconclusive result is not a hidden success or failure. It usually means the audience was poorly selected, the test did not create a realistic decision, the behavior was ambiguous, or multiple variables changed together. Repair the test before changing the strategy.
Run growth experiments at the tightest constraint
Growth is not a collection of channels. It is the result of moving customers through awareness, activation, retention, revenue, and referral without a severe break in the journey. The highest-leverage experiment usually sits at the tightest constraint, not at the stage with the most fashionable tactic.
Before product-market fit, narrow the motion
If prospects do not recognize the urgency, start with the ideal customer profile and value proposition. Narrow the segment, identify the triggering event, use the customer’s language, and lead with a wedge use case that produces a visible outcome. Do not compensate for unclear positioning by increasing traffic.
Keep early discovery, selling, and messaging close to the founder. Founder-led go-to-market and early willingness-to-pay tests expose objections that dashboards cannot explain. Delegation becomes safer when you can describe the target account, buying trigger, urgent use case, common objections, commercial path, onboarding sequence, and value moment without relying on founder intuition to fill the gaps.
Early paid acquisition is usually a poor diagnostic tool. It can tell you whether an offer converts in that channel, but it can also mask a weak core by replacing churned users with new ones. Use direct outreach, customer interviews, founder-led sales, and product-led loops to understand the mechanism first. Paid channels become useful multipliers after the journey converts and retains the right customers with credible economics.
Choose the experiment from the journey symptom
Qualified awareness is weak: Test a narrower ICP, a different buying trigger, clearer problem language, a more focused wedge, or a channel where the target customer already seeks help.
Interest is strong but activation is weak: Remove setup steps, improve defaults, clarify the next action, add concierge assistance, or bring the promised outcome closer to the start of the journey.
Customers activate but do not retain: Investigate whether the problem recurs, whether the result remains trustworthy, and whether the workflow fits the customer’s normal operating rhythm. Acquisition is not the priority yet.
Customers use the product but resist paying: Revisit who captures the economic value, which outcome belongs in the offer, and whether subscription, usage-based, or hybrid packaging fits the way value accumulates.
Retention is credible but acquisition is constrained: Test a focused channel, referral prompt, sales motion, integration, partnership, or product loop without changing the core offer at the same time.
Sales cycles stall: Tighten discovery questions, connect the demo to the buying trigger, prove a fast wedge outcome, and give an internal champion evidence that can travel through the organization.
A practical sequence is to tighten the ICP, sharpen the value proposition, reduce the path to first value, establish retention, resolve pricing and delivery viability, and then scale acquisition. The order matters because each stage amplifies the one before it. Sending more prospects into an unclear offer increases noise. Sending them into a clear offer with broken activation increases abandonment. Sending activated users into a product without recurring value increases churn.
Make each growth experiment produce a decision
Every experiment brief should identify the current bottleneck, target segment, causal hypothesis, proposed change, directly affected behavior, downstream guardrail, and decision rule. The guardrail matters. An onboarding shortcut may improve completion while bringing poorly qualified users into the product, increasing support burden, or weakening retention. A local metric moving up is not automatically business progress.
Maintain an experiment log that records the hypothesis, risk, customer segment, test, observed behavior, disconfirming evidence, decision, and next unknown. Review the log alongside journey drop-offs and recent customer conversations. Select the next experiment from the current constraint rather than from an unranked backlog of tactics.
This also protects you from optimizing a local maximum. Improving a call-to-action does not solve a poorly chosen ICP. Polishing onboarding does not create a recurring job. Lowering price does not repair an outcome customers do not value. Stop the experiments that merely decorate the bottleneck, and concentrate effort on the interventions that change customer behavior.
Before your next roadmap or growth review, take the most important startup bet and write down its customer trigger, four risks, largest unknown, falsifying behavior, and lightest honest test. Put that test ahead of the feature. When the result arrives, make a proceed, pivot, or pause decision and update the constraint. That is how you earn the right to build more and, eventually, to scale.