I recently dug into a conversation with Marco Zappacosta, co-founder and CEO of Thumbtack, who has spent the last 13 years building the company into a billion-dollar business — and it’s his first and only job after graduating college. As someone who lives at the intersection of product management leadership and company-building, I was struck by how deliberately he navigates the deluge of advice that comes with being a first-time founder.
What resonated most was the way he differentiates between moments that demand a return to first principles and those that benefit from a tested playbook. In my own practice, I’ve found that product strategy and organizational design often require first-principles thinking, while operational cadence and execution rituals tend to scale best with proven patterns. The key is recognizing which game you’re playing — invention versus optimization — and applying the right mental models to filter input without losing velocity.
Marco’s approach to parsing counsel as a first-time CEO is refreshingly pragmatic. Rather than treating advice as binary, he triangulates from multiple data points, looks for invariants, and pressure-tests assumptions against the company’s unique context. I use a similar lens: anchor on the problem, map potential solutions to risk/return, and calibrate decisions with base rates where possible. It’s a disciplined way to turn a mountain of opinion into actionable signal — especially when stakes are high.
He also connects this discipline to stakeholder management, particularly in how he runs Thumbtack’s board so quarterly meetings become a critical resource, not just a time suck — and why he shares the board deck with the entire company. I’ve found this level of transparency to be a force multiplier: it aligns teams on priorities, elevates product roadmapping and sprint planning, and empowers leaders to make trade-offs with clarity. When the narrative is shared, accountability scales.
Marco candidly reflects on Thumbtack’s COVID-related layoff last year, and what he specifically did as CEO to ensure the folks who remained still had confidence in the company and his leadership moving forward. In hard moments like these, consistent communication, explicit prioritization, and a clear framework for decision-making matter more than ever. Trust is built by showing your work — why choices were made, what changes now, and how success will be measured.
Finally, he opens up his playbook for choosing what to spend his time on as a busy CEO with only so many hours in the day — and perhaps more importantly, how he stays accountable for these priorities. I’ve learned to pair outcome-oriented OKRs with a ruthless weekly schedule audit: if the calendar doesn’t reflect the strategy, the strategy won’t happen. This discipline creates focus, accelerates learning loops, and keeps leaders from becoming the bottleneck.
For builders at any growth stage, there’s a powerful takeaway here: cultivate a repeatable way to distill advice, clarify when to use first principles versus a playbook, operationalize board relationships as strategic assets, and turn time into your sharpest instrument. The result is a more resilient company — and a leadership practice that compounds.
AI has changed the tempo of product management, but not the timeless fundamentals. I’m living that paradox daily: the technology reshapes how we plan, build, and ship—yet the way we find real customer value hasn’t budged. Here’s how I reconcile both truths in practice.
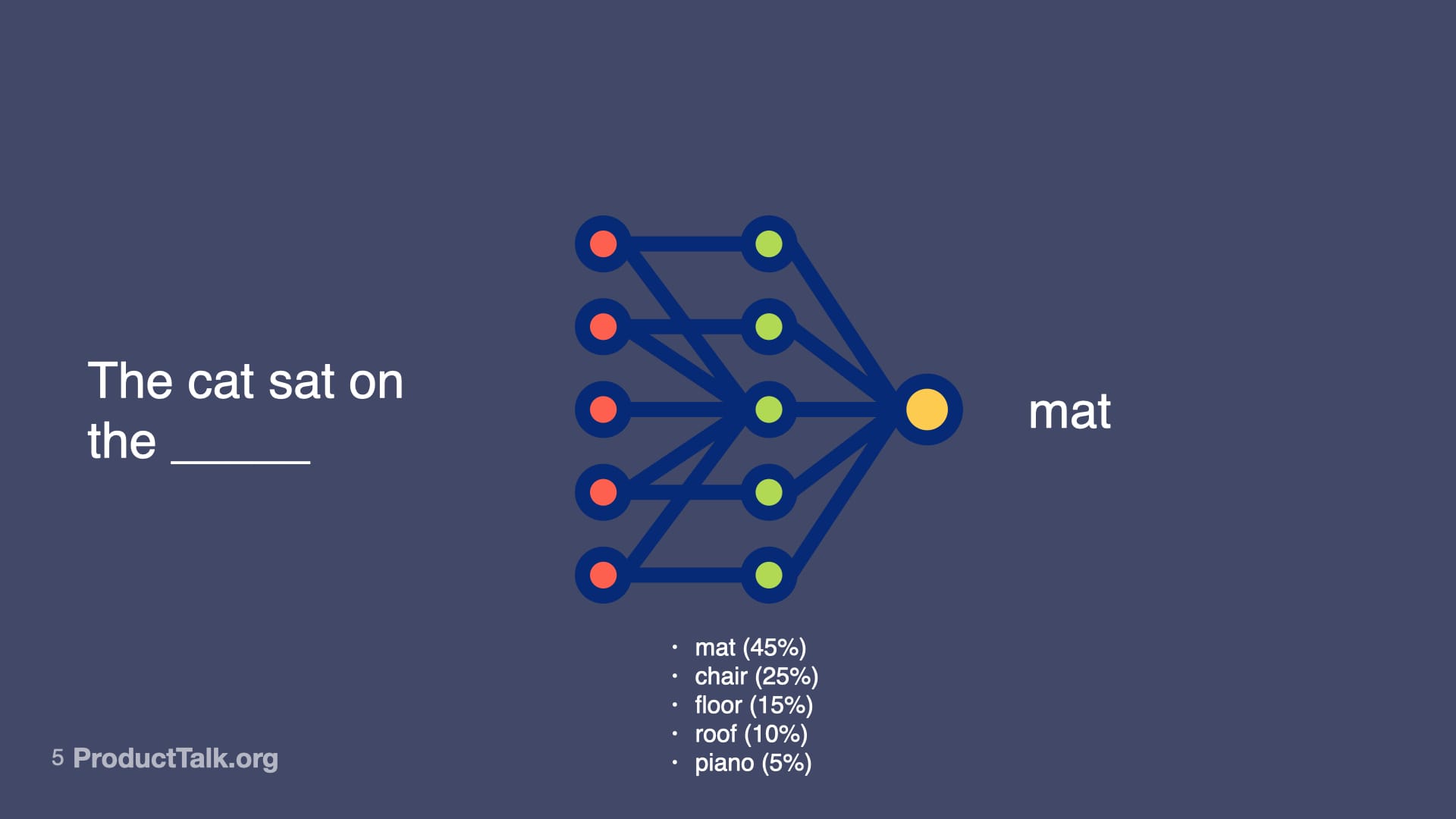
At their core, large language models predict the next token. That’s it. Consider the prompt, “The cat sat on the ____.” Mat is most likely. Chair is pretty likely. Floor, roof, piano—all possible, just less probable. When you give an LLM a prompt, it runs through a neural network—billions of parameters making calculations—to predict the most likely next word, then the next, then the next. That neural net represents not just facts, but relationships, patterns, context—and some might even argue reasoning capabilities—that all influence the probabilities of different outputs. So LLMs don’t just predict the next token. They predict the next token by drawing upon a vast amount of knowledge. LLMs are transformational.
Behind the magic, LLMs don’t “know”—they rank what likely comes next. This slide’s cat sentence with weighted options underscores how generative AI reshapes work while remaining probability-driven.
And yet, AI makes silly mistakes. The kind that make you wonder how it could be so smart and so dumb at the same time. No matter how hard I tried, I could not get ChatGPT-5 to fix the closing quote on an image. And it took 12 seconds of thinking to figure out that I asked for a meeting summary but didn’t include any meeting notes. Why do LLMs make these mistakes? Well, it’s because all the LLM is doing is predicting the next token based on patterns. And sometimes those predictions are wrong. And when it’s wrong, it can be confidently wrong. So what do we do?
A side-by-side visual pits an optimistic AGI rocket against a frowning skeptic with a thumbs-down, ending with the prompt 'Which is it?'—capturing the debate over whether generative AI is transformative progress or overhyped.
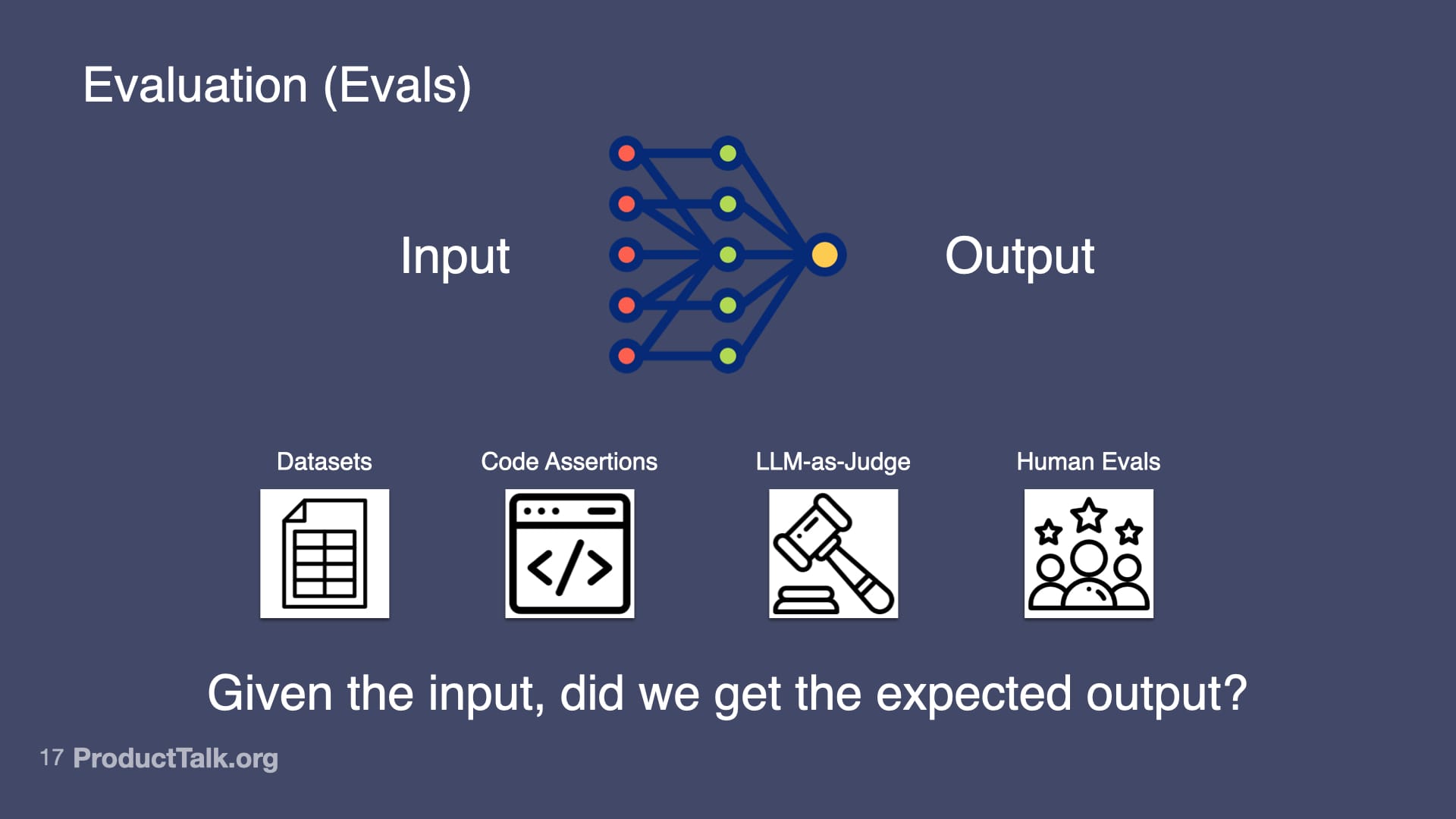
To build reliable AI features, I focus my team on four core skills: prompt engineering, context engineering, orchestration, and evaluation (evals). Together, they let us harness what’s powerful about generative AI while reducing unforced errors.
Generative AI isn’t magic—it’s inputs, training data, and models. This visual invites readers to examine how predictions are produced and why transparency, bias checks, and ethics shape responsible outcomes.
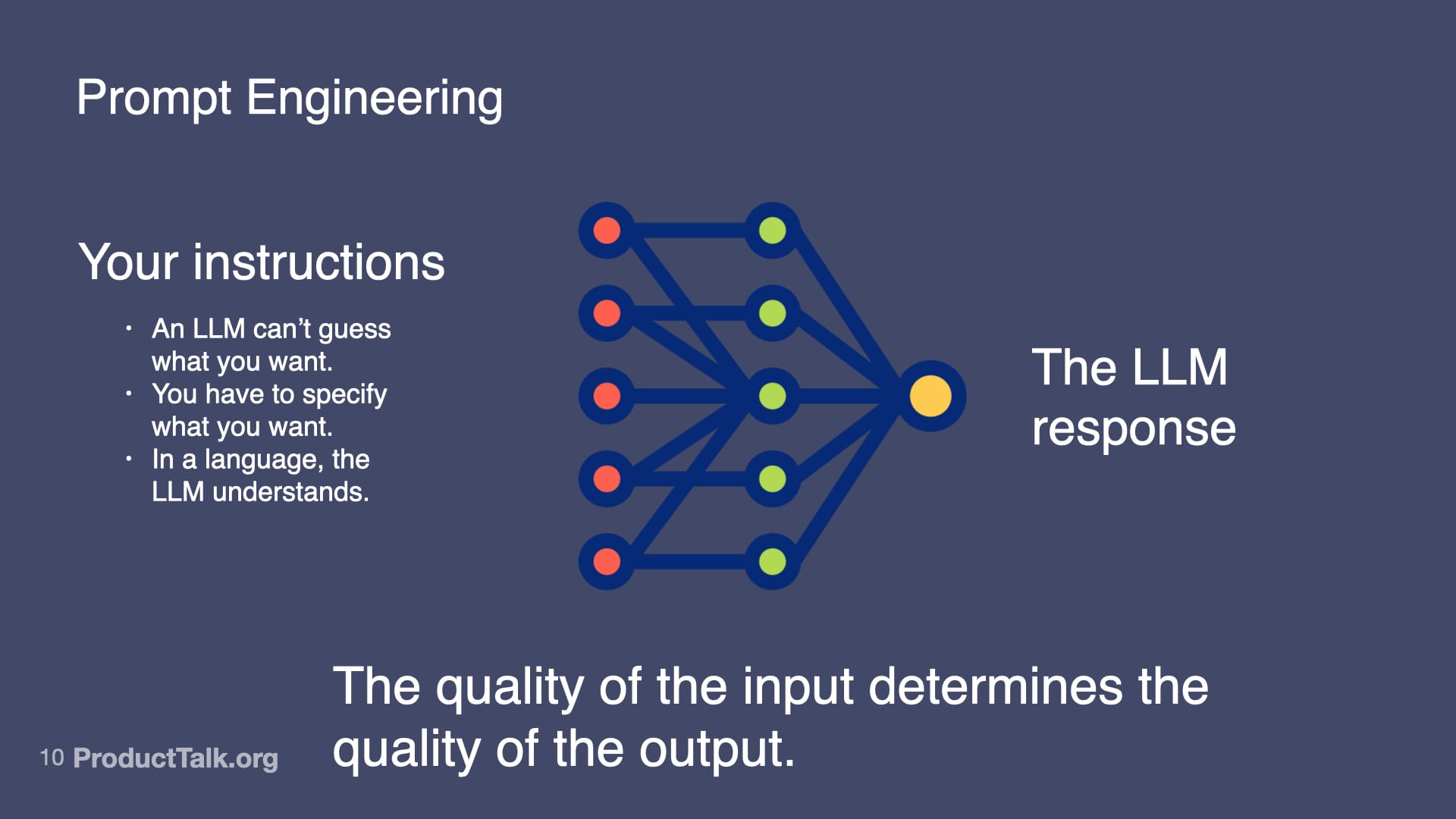
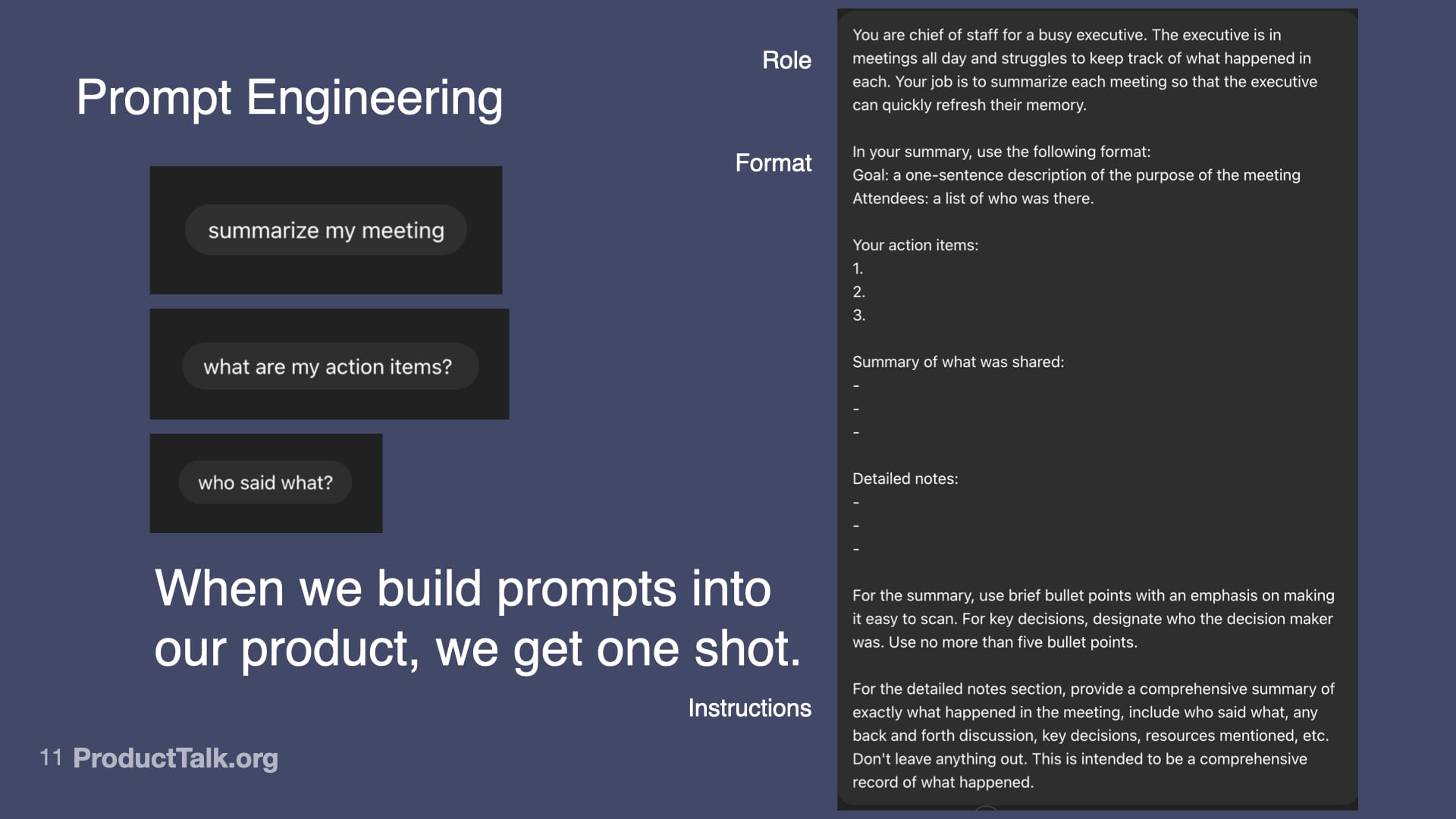
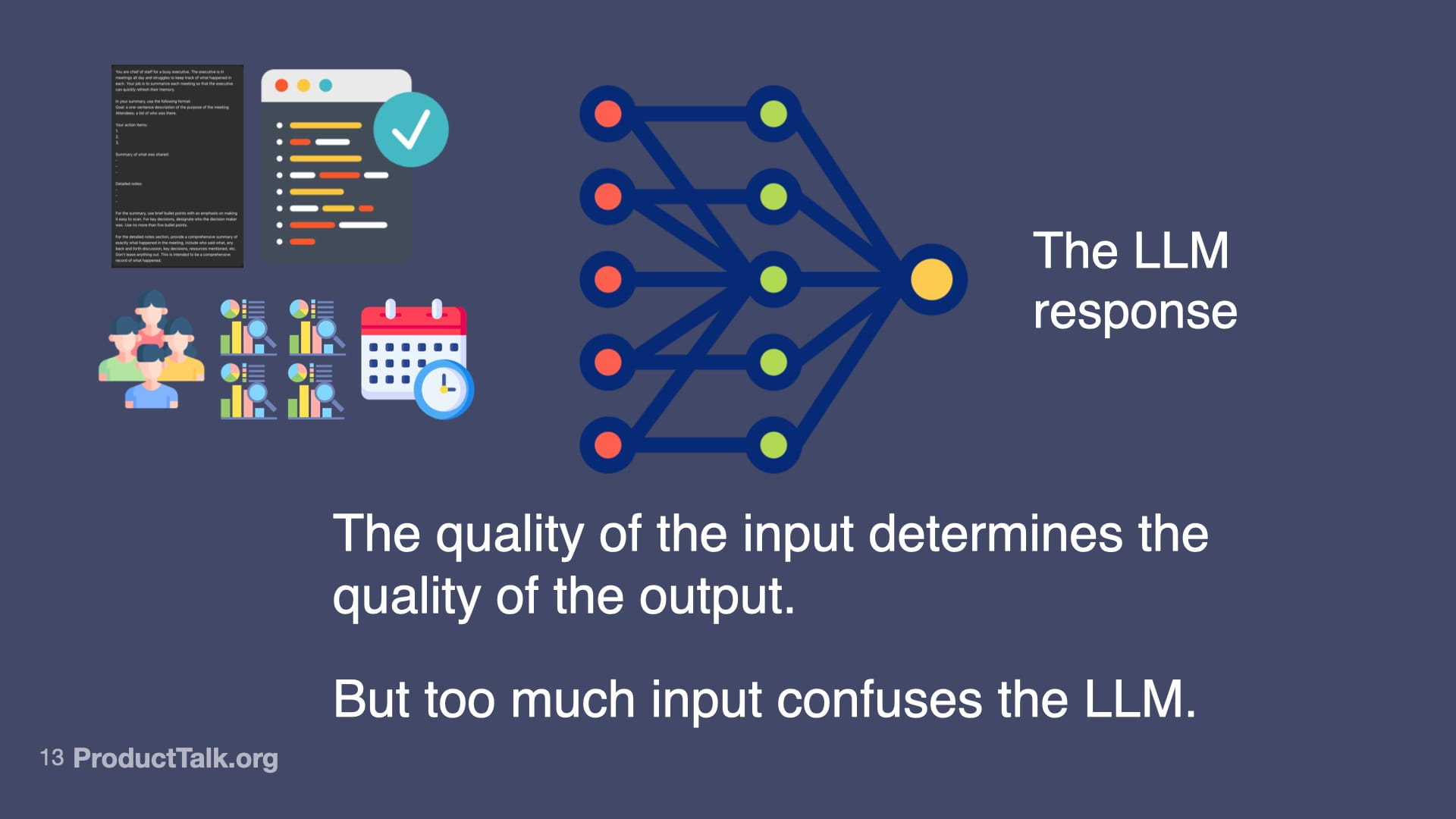
First, prompt engineering. With LLMs, the quality of the input determines the quality of the output. An LLM can’t guess what you want. You have to specify what you want in a language the LLM understands. In a chat, you can iterate with multiple turns. In a product, you get one shot. When we ship a meeting summarizer, for example, I design a production-ready prompt that assigns a role (“You are a chief of staff for a busy executive…”), specifies output format (e.g., a structured list of action items), and clarifies exactly what to include and how to structure it. This is prompt engineering. It’s like writing a really good product spec—but for an AI.
A simple sentence becomes a window into generative AI: a neural network weighs options and selects 'mat,' showing how models rank likely words to produce fluent text—and why outputs feel confident yet probabilistic.
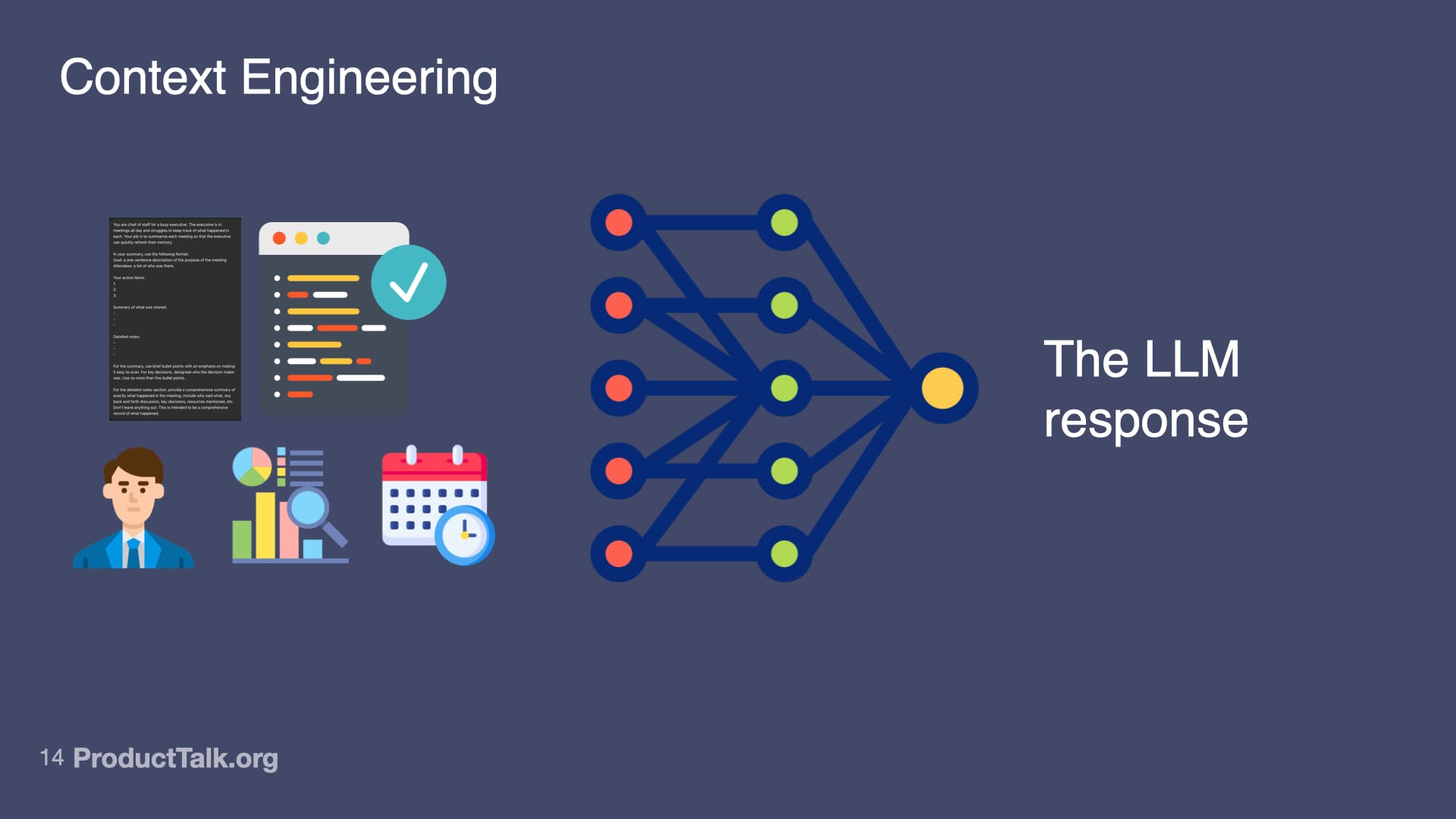
Second, context engineering. LLMs know a lot, but not everything. Imagine a takeaway reads, “Send the pipeline report to John by Friday.” When is Friday? Which John? What is the pipeline report? The model lacks today’s date, the roles of participants, and the specifics of our reporting vocabulary. If you dump every possible detail into the prompt, the model gets noisy input and the quality drops. The key is to add only the context the LLM needs to do the task at hand and nothing more. This is where techniques like RAG (Retrieval Augmented Generation) shine: retrieve just the relevant snippets—e.g., attendee roles, the precise definition of “pipeline report,” and the calendar context for “Friday”—and include only those in the prompt.
A minimalist slide demystifies how LLMs choose words: given 'The cat sat on the ____', the model ranks options by probability, showing that AI outputs are weighted predictions, not facts, which matters for ethics and product decisions.
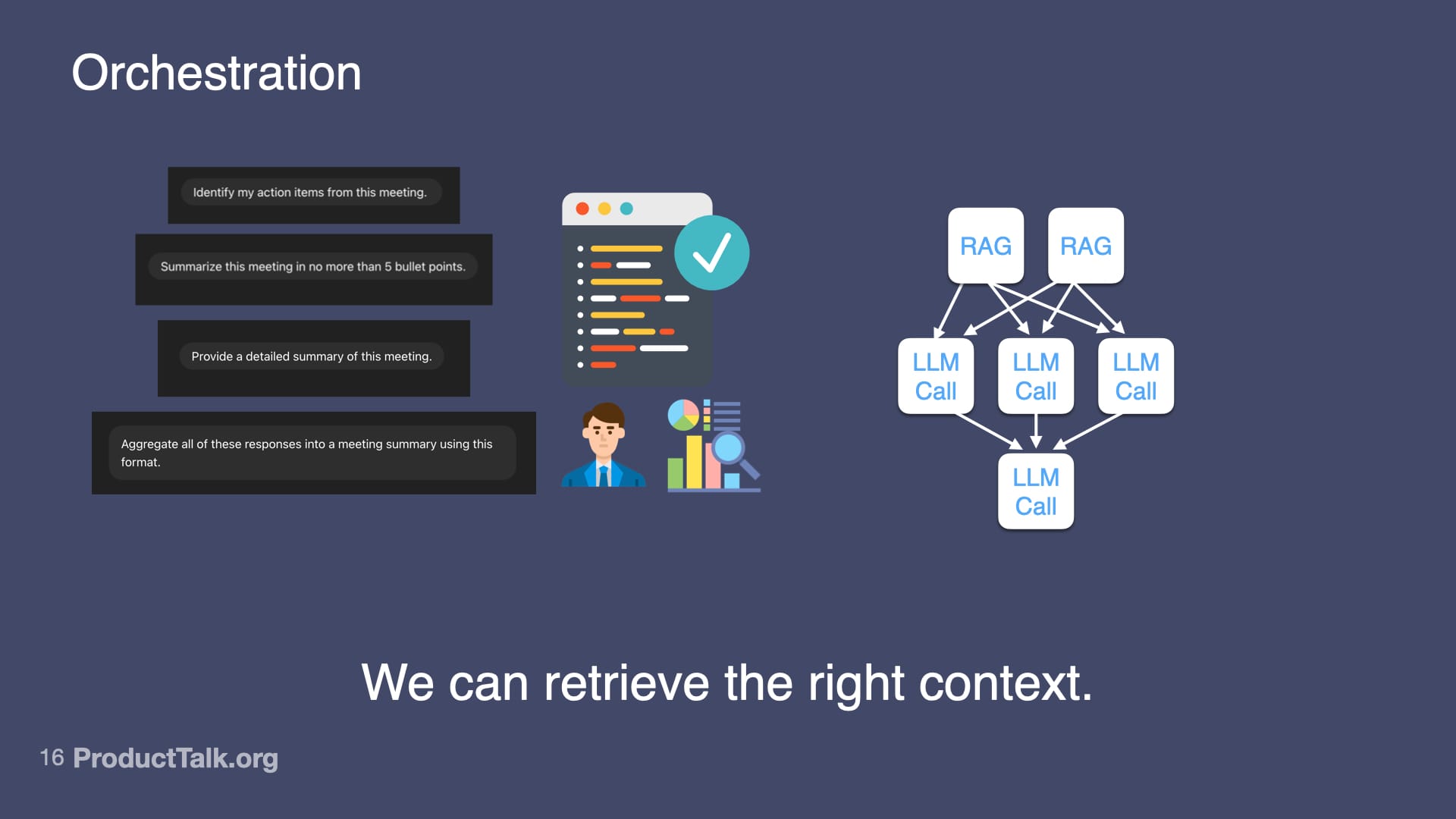
Third, orchestration. LLMs are better at simpler tasks. If you try to do everything in one prompt—identify action items, summarize the meeting, categorize by urgency, match to owners, check for clarity—the quality goes down. But if you break it into steps, each focused on one thing, the quality goes up. I design a workflow of multiple LLM calls that work together. For example: First call: identify action items from the transcript. Second call: categorize by urgency using lightweight project context. Third call: match to owners with a minimal team directory. Fourth call: generate calendar events via an API. Each step is simple. But together, they create something sophisticated.
From building apps by chatting to auto-cleaning video and translating comments, AI compresses complex tasks into simple prompts. This scene shows why it feels transformative—while nudging us to weigh its limits and ethics.
Fourth, evaluation (evals). Otherwise known as: Is my AI product any good? At the heart of evals is this question: Given the input, did we get the expected output? I use several approaches. Datasets: I collect 20–100 real examples, define expected outputs, run the prompt, and measure the success rate. Code assertions: I enforce rules the output must follow (for example, “Every action item must have a task, owner, and deadline”) and fail the test when they’re violated. LLM-as-Judge: I use a model to verify factuality (e.g., “Is each item in this summary in the meeting transcript? Yes or no.”). Human evals: I track whether users need to edit the output and by how much. Start simple; get more sophisticated as the stakes rise.
From “AI Changes Everything (And Nothing At All),” this slide contrasts bold promises with everyday glitches: optimism about LLMs and AGI on the left, and a meeting-summarizer that can’t find content on the right—reminding us AI still errs.
Here’s the hard truth: you can master all four skills and still ship the wrong thing. Why? Because you chose the wrong problem to solve. Who needs yet another meeting summarizer? The ease of building with generative AI tempts us to jump straight to solutions. Resist it.
A keynote slide from AI Changes Everything (And Nothing At All) urges teams to master AI by harnessing its power while minimizing errors, framing a practical, ethical approach to building trustworthy products.
Discovery matters more than ever. Before writing your first prompt, be explicit about the impact you want and set a clear outcome. Talk to your customers and ensure you understand their needs; choose the right opportunity before you chase a cool solution. Explore multiple options and use assumption testing to converge on what will actually move the needle.
Clear prompts shape better AI. This slide shows how explicit, well-structured instructions lead to stronger LLM responses, reminding builders that inputs drive outcomes—and that responsible prompting begins with clarity.
Prototype, test, and build iteratively. With AI products, it’s easy to get to a great demo and hard to get to a production-grade experience. I validated feasibility before I wrote a line of production code by experimenting directly in a model’s UI, pasting real transcripts, and shaping the system instructions and output format. Only after I had a repeatable prompt and useful feedback did I worry about deployment.
Designing prompts is product design. This visual pairs common meeting requests with a rigorous summary framework, reminding teams that when prompts are embedded in products, accuracy matters because you get one shot.
From there, I tested deployment paths with the smallest viable investment. I tried a custom chat in Replit and embedded it. It wasn’t the right interaction model for targeted feedback. I switched to a submission flow using a homework-style pattern: students upload their transcript, the system processes it, they get detailed feedback. Done. That worked—until automation reliability lagged. I wired it up in Zapier, then rebuilt it on AWS Step Function for robust retries and better error handling when scale introduced edge cases.
A reminder that AI needs context: a simple instruction becomes ambiguous without dates, roles, recipients, and report details, highlighting the limits of LLM knowledge and the value of precise, shared prompts.
Each iteration tested a different assumption. Iteration 1 (Claude): Can AI even do this? What makes good feedback? Iteration 2 (Replit chat): How should people interact with it? Iteration 3 (Zapier): Can I integrate this into the existing workflow with minimal engineering? Iteration 4 (Step Functions): How do I make it reliable at scale when things inevitably go wrong? I didn’t know the answers up front; I learned by building, shipping, and observing.
From AI Changes Everything (And Nothing At All), this visual reminds builders that curated, high‑quality prompts yield better LLM responses, while overloaded, noisy inputs derail reasoning and reduce reliability.
Ethical data practices are non-negotiable. Improving AI products requires inspecting traces—the user input, system prompts, tool calls, and LLM responses. For a coaching flow, that includes the uploaded transcript, the system prompts that define evaluation criteria, and the AI’s feedback. To fix issues, I look at traces where things went wrong—but only with explicit user permission. Too many AI products collect everything by default and review traces without clear consent. Don’t do this.
A visual explainer showing how structured inputs—documents, verified code, roles, metrics, and timelines—flow into a network to shape a single, clear LLM response, underscoring the power of context in generative AI.
In my products, users must explicitly grant permission for me to review their data. The consent is clear and specific. If they say no, I don’t see their data. Full stop. That forces me to rely on synthetic data for many tests and to engineer privacy into the architecture from day one rather than bolt it on later. It’s the right thing to do, and increasingly, it’s required.
A visual guide to orchestration: break a complex meeting recap into smaller LLM calls, gather action items, bullet points, and a detailed summary, then aggregate the outputs to boost accuracy and reliability.
Everything changes—and nothing changes. Yes, there are new skills you should master: prompt engineering to get the right output the first time; context engineering to give the LLM exactly what it needs; orchestration to decompose complex tasks into simpler steps; and evals to systematically measure quality. And the fundamentals still rule: solve the right customer problems with strong discovery; prototype and iterate to de-risk; and uphold ethical data practices as a design constraint, not an afterthought. The teams that win with AI will master both the new technical craft and the timeless product fundamentals.
A presentation slide visualizes AI orchestration: user prompts generate meeting summaries while a graph of RAG and LLM calls routes tasks to the best sources, underscoring that retrieving the right context drives better outputs.
If this resonates, pick one active workflow, apply the four AI skills end-to-end, and run a short discovery and eval cycle against a clear outcome. Then ship. You’ll learn faster than any slide deck could ever teach you.
This presentation slide maps how to assess AI: link inputs to outputs with datasets, code assertions, LLM-as-judge checks, and human reviews—centering the question, "Given the input, did we get the expected output?"
I’ve led and observed AI initiatives across fast-moving product organizations, and one pattern is unmistakable: “The AI revolution needs a departmental leader.” When that leader is unclear, pilots stall, risk mounts, and value gets trapped in proof-of-concept purgatory. When it’s clear, AI moves from demos to durable outcomes.
In my experience, IT is uniquely positioned to play that leadership role. IT sits at the nexus of data, identity, security, and infrastructure—exactly where scalable AI capabilities live. IT also has the vantage point to connect use cases across teams, manage risk, and operationalize change without derailing core systems.
Put simply, this is the promise: “Learn the key reasons why IT teams are uniquely positioned to be the strategic leaders of your company’s AI projects.” The reasons are pragmatic—access to systems of record, stewardship of data governance, ownership of integration patterns, and accountability for reliability and compliance—yet the impact is strategic.
Here’s how I frame the operating model. IT provides strategic leadership and platform stewardship; Product owns the outcomes; Engineering delivers services and integrations; Security and Legal codify guardrails; and Finance supports cost modeling. We establish tight collaboration through product trios (Product, Design, Engineering) that plug into an IT-led AI platform, enabling empowered product teams to ship safely and quickly.
Governance turns intent into repeatable action. I use outcomes vs output OKRs to force clarity on value, pair them with lightweight QBR cadences for course correction, and require architecture reviews that cover model/data governance, observability, privacy, and vendor risk. This ensures we can scale gen ai without surprise failures or compliance gaps.
On the delivery side, forward deployed engineers embedded with business units accelerate discovery and reduce translation loss. We leverage gen ai for product prototyping to validate desirability and feasibility early, then harden solutions on our shared AI platform. This keeps experimentation fast while maintaining an enterprise-grade backbone.
Roadmapping balances ambition with throughput. I tie product roadmapping and sprint planning to value streams, not just features, and I make stakeholder management explicit—especially with customer support, finance, and operations—so we design for adoption. For example, a customer support ai strategy isn’t a chatbot alone; it’s an outcome-driven service redesign, with training, playbooks, and measurable deflection and CSAT targets.
Success demands the right metrics. Beyond typical velocity measures, I track time-to-first-value, model quality and drift, cost-to-serve, and risk posture. These roll into OKRs that link frontline improvements (e.g., resolution time) to enterprise outcomes (e.g., gross margin, retention), giving executives confidence and teams a clear definition of done.
If you lead IT, this is your moment to step into strategic ownership and elevate AI from scattered experiments to a coherent platform. If you lead Product, partner with IT to align discovery, outcomes, and guardrails so empowered teams can move fast and responsibly. Together, we can turn AI from a buzzword into a durable advantage.
I recently sat down with Melissa Tan to unpack the nuances between two PLG businesses and how growth strategy changes for a more complex product like Webflow. As I reflected on our conversation through the lens of product management leadership, I focused on what it really takes to design a high-impact growth organization, set rigorous goals, and evolve pricing and packaging without losing sight of customer value.
I spoke with Melissa Tan, GM of Self-Service and Head of Growth at Webflow and formerly Head of Growth and Monetization for Dropbox Business. Her experience scaling PLG motions across very different product surfaces offered practical signals on where to double down, what to sequence, and how to balance experimentation with long-term strategy.
Designing and structuring a growth org starts with mapping ownership to the user journey. I anchor cross-functional squads on outcomes across acquisition, activation, conversion, and expansion, with a shared platform and data foundation. Clear swimlanes, crisp interfaces with core product and marketing, and a consistent experimentation cadence keep velocity high while avoiding thrash. For PLG, I also recommend an embedded analytics function and strong partnerships with sales-assist and support to translate signals from self-serve to sales-led opportunities.
The right way to tackle goal-setting is outcomes-first. I favor outcomes vs output OKRs that ladder to a North Star and a small set of controllable, leading indicators (for example, activation rate, time-to-value, or successful workspace creation). I pair these with guardrail metrics to protect user experience and brand trust. Weekly reviews focus on decision quality and learning velocity, not just hit rates, so the team compounds insight even when experiments miss.
How Webflow’s pricing and packaging has evolved is a reminder that complex products require value-based packaging that clarifies who each plan is for and what milestones justify upgrade. When complexity rises, I encourage teams to simplify the fences, align packaging to clear value axes (usage, collaboration, security, or advanced workflows), and ensure in-product prompts communicate that value at the right moment in the journey.
How to calibrate pricing feedback comes down to triangulation. I segment qualitative input by customer size and use case, balance loud feedback with behavioral data (conversion by plan, downgrade reasons, add-on attach), and validate with structured research and live price tests. The aim is not to chase every request, but to isolate willingness-to-pay drivers, reduce friction for the majority, and preserve premium features that genuinely anchor expansion.
In this piece, I cover the essentials: designing and structuring a growth org, the right way to tackle goal-setting, how Webflow’s pricing and packaging has evolved, and how to calibrate pricing feedback. My goal is to leave you with a practical blueprint you can adapt to your PLG startup—one that aligns teams, accelerates learning, and translates product value into durable growth.
Org design is one of the highest-leverage tools I have as a product leader. When structure, incentives, and decision rights align, execution compounds. When they don’t, even great people and strategy stall. In this narrative, I share how I approach company structure, drawing on hard-won lessons from complex re-orgs, “GM-led” models, and the realities of pricing, packaging, and planning at scale.
Here’s the backbone of my philosophy. First, the principles of effective org design matter more than any single chart. I relentlessly return to five anchors: #1 Align on goals; #2 Separate design considerations from human considerations; #3 Define clear reasons each team exists; #4 Design for durability; #5 Be very intentional with comms. These make tradeoffs explicit, reduce churn, and clarify ownership so we can move faster with more confidence.
On timing, there are clear signs your company needs a re-org. When multiple teams chase overlapping goals, when decision latency rises, when cross-functional friction becomes the norm, or when strategy evolves but responsibilities don’t, it’s time to revisit the design. I look for outcome drift in OKRs, blurry escalations, and too many “two owners” problems as leading indicators.
Tradeoffs are inevitable. I surface them early: speed vs. cohesion, specialization vs. customer journey continuity, centralization vs. autonomy. I make the tradeoffs explicit in a one-page brief and tie them back to company goals. This keeps us honest about why we are changing the system—and what we expect to get in return.
Square’s “GM-led” structure offers a useful reference point. The core idea: give a single accountable owner end-to-end responsibility for a business (product, P&L, and cross-functional performance), then architect adjacent teams to enable—not dilute—that accountability. In my practice, I define crisp swimlanes, escalation paths, and shared principles for collaboration at the seams so GMs move fast without fragmenting the customer experience.
Why Square centralized GTM speaks to a broader truth I’ve seen across SaaS: fragmentation in go-to-market creates inconsistent messaging, pricing confusion, and channel conflict. Centralizing GTM can raise the quality bar on positioning, funnel health, and field enablement—while GMs retain the voice of the customer and set product priorities. The key is a tight contract: who owns narrative, who owns quota, and how we arbitrate tradeoffs.
Managing pricing and packaging across a complex org is a system design problem. I establish a single authority for pricing strategy and guardrails, with clear input rights from GMs and Finance. We define canonical metrics for willingness to pay, price elasticity, bundle attach, and churn. This lets us run structured experiments while protecting long-term brand trust and ARR quality.
I put real weight on written principles. Examples of Square’s written principles remind me that great organizations reduce ambiguity by codifying how decisions get made. In my teams, we document decision rights (DACI/RACI), escalation patterns, and what “good” looks like for roadmaps, customer research, and launch criteria—so we don’t reinvent governance in every meeting.
How Square determines what each GM owns maps well to a pattern I use: define the customer journey first, then assign ownership in contiguous slices that minimize handoffs. If an interface is high-traffic or monetization-critical, it deserves a single accountable GM. Shared platforms (data, identity, payments) live in enablement groups with SLAs and portfolio-level success metrics.
Collaboration across GMs and products improves when we create durable seams. I use recurring GM councils, shared north-star metrics, and documented interface contracts. We align on joint bets for the year, budget for cross-org work, and maintain escalation rituals so debates are fast, respectful, and final.
Key lessons on planning and decision-making at scale: time-bound strategy, principle-led tradeoffs, and ruthless clarity on who decides. I anchor annual and quarterly planning in a brief that includes goals, constraints, risks, and assumptions. When we disagree, we escalate once, decide once, and document why—so we can move on without reopening settled questions.
Designing incentives across a massive org means aligning pay, promotions, and recognition to the outcomes we claim to value. I tie variable comp to a balanced scorecard: growth and retention, customer satisfaction, quality of execution, and platform health. If incentives reward only top-line ARR, we’ll get short-term wins at the expense of durability.
Two reasons GM structures go wrong: ambiguous decision rights and platform underinvestment. If GMs can’t tell what they truly own, or if shared services don’t meet their needs, the model will fail. I fix this by clarifying ownership in writing and by setting platform SLAs backed by leadership enforcement.
When it’s time to change the structure, I follow a disciplined playbook. 6 Step re-org walkthrough: Step 1: Triggering the re-org—document the triggers and the goals; Step 2: Sketching a proposed org design—present two to three viable options with tradeoffs; Step 3: Checking against key criteria—stress-test against strategy, customer journey, incentives, and interfaces; Step 4: Finalizing approach with leadership—drive alignment and decision in a single forum; Step 5: Planning comms—sequence messaging for managers, then teams, then partners; Step 6: Executing comms—deliver clear narratives, FAQs, and next steps on the same day.
Signals a re-org worked vs failed show up quickly: decision speed rises, escalations drop, and outcomes improve without heroics. If confusion persists, shadow processes form, or engagement declines, the design needs another pass. I run 30/60/90-day health checks and tune incentives or interfaces before small issues calcify.
I continue to learn from industry operators, including 5 lessons from Alyssa Henry, CEO at Square, that reinforce my own approach: design for clarity, empower accountable owners, write down how we work, invest in platforms early, and communicate like the strategy depends on it—because it does. When we treat org design as a product, we earn compounding execution and a culture built to scale.
The product operating model is getting a lot of airtime for good reason. In my experience leading product and driving change across complex organizations, it offers a pragmatic way to build technology-powered solutions that customers love while delivering measurable business results.
What is the product operating model? I anchor teams on first principles: it’s not a process checklist—it’s a way of operating. As one leading thinker puts it, “The product operating model, also referred to as the product model, is a conceptual model based on a set of first principles that leading product companies believe to be true about creating products.” It’s “about consistently creating technology-powered solutions that deliver value to customers and that also drive results for the business. It’s about achieving outcomes versus merely producing output.” That framing matches exactly what I’ve seen separate high performers from the rest.
A clean visual distills the product operating model—covering how products are built, how problems are solved, and how to choose which problems to tackle—ideal for teams moving from pilots to enterprise-wide transformation.
Why adopt it? Because too many organizations swing between two extremes—beloved products that can’t sustain the business, or hard-charging business tactics that burn customer trust. The product model forces a both/and mindset: customer value and business outcomes. The biggest triggers I see for making the shift are heightened competition, visible frustration with the status quo (lots of spend, little impact), and a clear view of the upside when you manage by outcomes instead of deliverables.
Clean, modern visual underscores a core promise of the product operating model: delight customers and deliver measurable business outcomes. A timely teaser for organizational change content on scaling from pilot teams to full transformation.
How is it different from the project model? Projects start and stop; products evolve. When you manage by projects, you optimize for scope, budget, and dates—often at the expense of learning. When you operate as a product organization, cross-functional leaders (product, design, engineering) own the problem space and decide which customer problems to prioritize, in continuous conversation with stakeholders about business context and constraints. The litmus test: are teams funded and measured by outcomes, or by a backlog of features and deadlines?
A crisp reminder that projects end while products evolve—the mindset shift at the core of a product operating model. Great for posts on moving from pilot teams to enterprise adoption and delivering continuous customer value.
Can a hybrid approach work? Early on, yes—and it’s often the smart path. I strongly recommend piloting with a small number of teams while the rest of the organization continues working in the project model. Use pilots to learn, de-risk, and build internal proof points. That said, some work will remain project-based (e.g., regulatory, compliance, or one-off migrations). The goal isn’t purity; it’s pragmatism.
Change works best in waves, not a tidal surge. This visual champions pilot teams and staged rollout, showing how a product operating model scales successfully when leaders avoid all-at-once transformation.
How does continuous discovery fit? Continuous discovery is the operating system for deciding which problems to solve and how to solve them. Practically, that means weekly customer touchpoints by the team building the product, lightweight research to learn fast, mapping opportunities, and testing assumptions to reduce risk—all in pursuit of a clearly defined outcome. If you don’t learn continuously, you default to guessing continuously.
Continuous discovery helps teams choose the right problems and solutions. Explore how the Product Operating Model moves from pilot teams to enterprise-wide adoption—and why discovery is the engine of transformation.
How long does transformation take? Longer than most leaders think. Changing funding models, planning rituals, decision rights, and team habits is measured in years, not months. Pace yourself, stage the rollout, and expect to iterate on org design, coaching, and governance.
Big change isn’t overnight. This visual from our Product Operating Model series highlights the reality: scaling from pilot teams to full transformation takes time, steady learning loops, and aligned leadership.
Is your organization ready? I look for two CEO-level signals: a genuine belief that how you operate today won’t win tomorrow, and felt pain with the current results (missed targets, margin pressure, slipping share). Transformation is hard; without executive conviction, resistance will stall progress.
Even in heavily regulated sectors, a product operating model can thrive. Learn how to adapt governance and compliance without losing speed—from pilot teams to enterprise-wide scale.
What are signs it’s working? During planning, you fund teams and outcomes—not projects. Day to day, outcomes trump outputs. Product teams are empowered to solve customer problems (not merely deliver requests). Stakeholders contribute context and constraints, not solutions. Most importantly, your outcome metrics improve over time.
A side-by-side snapshot of how product work changes from early startups to large enterprises—shifting from directional outcomes to transparent processes, stakeholder management, and accountable leadership.
Will it work in regulated industries? Yes. Constraints shape the solution space, but the underlying truth remains: products are never done. In highly regulated environments, continuous discovery, tight risk management, and fast feedback loops are even more critical.
Shift from big-bang training to smart scaling. Start with pilot teams, learn fast, and extend practices that work. This post explores how a phased product operating model reduces risk and builds lasting capability.
Startups vs. enterprises: Early-stage teams can start with a directional outcome (who you serve and what you aim to change) and evolve to measurable outcomes as signal strengthens. The anti-pattern is “idea-first” debates that devolve into whether-or-not arguments. Even with an idea in hand, interview customers, map the opportunity space, story-map solutions, and surface assumptions to test. In large enterprises, the challenge shifts to scale: more stakeholders and gatekeepers, a greater need to show your work concisely, and stronger accountability rituals so leaders can manage by outcomes without dictating outputs.
To scale a product operating model, leaders must be all-in. This graphic spotlights two CEO mindset shifts: accepting that the old operating mode fails and recognizing the real cost of the status quo.
What does failure look like? A narrow transformation that trains product managers but leaves funding, planning, decision rights, and stakeholder behaviors unchanged. If you spot this pattern, pause and reset: recommit at the executive level to outcomes-based funding, change the operating cadence, and invest in coaching for leaders and teams.
In a product operating model, managers are coaches first. This quote underscores that real transformation starts by developing people's skills, building capable teams before scaling from pilot initiatives to enterprise-wide change.
The biggest mistake I see is trying to roll out to everyone at once. Broad, simultaneous training creates confusion, fuels resistance, and overwhelms your enablement capacity. Start small, prove value, fix systemic blockers, and then scale.
Meet the Product Trio—product manager, designer, and software engineer—the nucleus for moving from pilot teams to full transformation, aligning collaboration across discovery and delivery.
How does remote or distributed work affect the model? It raises the bar on clarity and connection. Define core collaboration hours, codify working norms, and be explicit about when to switch from async to live. Build lightweight rituals—discovery reviews, outcome check-ins, assumption-test demos—that create trust and fast feedback across time zones.
Pilot teams prove the product operating model can work. This clean visual highlights the first step of transformation—start small, validate results, and build momentum toward organization-wide change.
Roles and responsibilities change in meaningful ways. The CEO must champion outcomes-based funding and empower teams to own the problem space. Product leadership’s primary job is coaching—developing skills, modeling outcome management, and making strategic context accessible. Teams operate as small, cross-functional units (often a product manager, designer, and engineer, plus data or product marketing when needed). Keep the group as small as possible while still making informed decisions; bigger groups slow decisions and dilute ownership.
Pilot teams expose the friction and blockers you’ll face on the path to a full product operating model. This clean visual underscores the message: surface resistance early so transformation can progress.
Empowerment doesn’t mean teams do whatever they want. It means they own figuring out the best way to achieve an outcome within clear business constraints. Leaders provide the why and the guardrails; teams own the how.
Launching a product operating model starts with the right pilots. This graphic spotlights five factors to weigh—relationships, learning mindset, existing skills, access to customers, and the product's lifecycle stage.
Pilot teams are your change engine. I select a handful of teams most likely to become bright spots—familiar with each other, hungry to learn, fully cross-functional, with reliable customer access, and working on products in an “explore” or “invest” lifecycle stage. Small organizations might start with one pilot; mid-size with two to four; large with up to five. The point is to learn, not to boil the ocean.
Kickstart your product operating model with pilot teams set up to win: align on business context, ensure customer access, equip the right tools, remove friction so they move fast, and foster cross-functional collaboration.
How do I set pilots up for success? First, give them a clear outcome and rich business context. Second, insist on regular customer conversations to uncover unmet needs and prioritize opportunities. Third, build the muscle for evaluating whether they built the right thing through quick, targeted assumption tests. Fourth, shorten delivery cycles by right-sizing work to accelerate learning. Fifth, teach collaboration skills—show your work, externalize your thinking, and respect each discipline’s expertise—so the team can storm and reform productively.
Kickstart your product operating model with pilot teams. This visual spotlights three musts: back their outcomes, understand outcome‑focused work, and foster transparency and collaborative decision‑making.
What should leaders do differently during pilots? Align on the team’s outcome and invite relevant stakeholders into outcome definition and context-sharing. Learn to manage by outcomes, not outputs, and clarify when feedback is a suggestion versus a decision. Create predictable rituals where teams share what they’re learning, what they’ll learn next, and what’s blocking them. Transparency builds trust; trust enables speed.
Scale your product operating model by making learning public. Encourage forums, demos, and showcases where teams share insights, turning pilot wins into organization-wide momentum.
Which rituals help pilots share progress? I like “discovery-delivery demos” where teams show the latest insights, the opportunity space they’re focusing on, the assumptions they’re testing, early signals from tests, and the decision implications. Keep it concise and outcome-linked so leaders and peers can coach effectively.
Before taking a product operating model beyond pilot teams, fix the patterns you've found. Resolve recurring issues early to reduce risk, build confidence, and enable a smoother, organization-wide transformation.
How do you scale beyond pilots? Start by fixing systemic issues that surfaced across pilots: upgrade planning and funding to outcomes, standardize access to customers, invest in capability building, and clarify decision rights. Then expand in waves, pairing newer teams with experienced coaches and reusing the same operating cadence that worked in pilots.
Leaders can boost pilot teams by setting rituals, reducing bias, and making communication explicit. This quick checklist shares four habits that keep work visible and aligned during a product operating model transformation.
Expect and manage resistance. From pilot teams, you’ll hear, “We don’t have time,” “I don’t want to be a beginner again,” or “That will never work here.” Treat these like objections to understand. Unpack delivery pressures, normalize the discomfort of learning, and make the case for change by contrasting current pain with desired outcomes. From leaders and stakeholders, expect attachment to favored solutions, discomfort with reduced control, and update bottlenecks. Address this by sharpening outcome definitions, making strategic context accessible, and committing to clear check-in points.
Pilot teams often push back with time, comfort, and context concerns. Naming these patterns sparks constructive dialogue and clears the path from experimental pilots to a durable, organization-wide product operating model.
The mindset shift that unlocks everything is outcomes over outputs. Success isn’t shipping; success is impact. Without a clear, meaningful outcome, teams stay busy but struggle to move the needle—and they can’t tell what’s working. Tie work to outcomes, instrument the experience, and let evidence guide decisions.
Leaders can stall a product operating model by clinging to old habits—prescribing solutions, holding tight to control, and demanding every decision cross their desk. Use this prompt to spark dialogue and reset expectations.
Collaboration is the other non-negotiable. When product, design, and engineering collaborate from the start, you reduce rework, make smarter trade-offs, and ship solutions that are valuable, usable, and feasible within your constraints. Silos optimize individuals; collaboration optimizes outcomes.
Move from shipping more to achieving more. This visual underscores the product truth: prioritize measurable outcomes over busywork outputs to steer teams from early pilots to scalable, organization-wide transformation.
If you’re embarking on this journey, start small, learn loudly, coach relentlessly, and scale what works. That’s how you move from pilot teams to full transformation without losing momentum—or your people.
When I first heard, “Welcome to In Depth, a new podcast from First Round Review that’s dedicated to surfacing the tactical advice founders and startup leaders need to grow their teams, their companies and themselves,” I immediately thought: this is the kind of operating wisdom I reach for every week. As a product leader who obsesses over product management leadership and the realities of scaling teams, I’m drawn to resources that move beyond inspiration and deliver concrete playbooks I can put to work on Monday.
The promise here is refreshingly pragmatic: “We’ll cover a lot of ground and a wide range of topics, from hiring executives and becoming a better manager, to the importance of storytelling inside of your organization. But every interview will hit the level of tactical depth where the very best advice is found.” That’s exactly where the hard problems get solved—whether you’re navigating the IC to manager transition, tuning your approach to product discovery, or tackling employee retention at startups when growth forces you to rewrite the org playbook.
From my vantage point, the most valuable conversations unpack the patterns behind great executive hiring, the cadence of outcomes vs output OKRs, and how storytelling shapes alignment across product, engineering, and go-to-market. I’m eager for insights that translate directly into product roadmapping and sprint planning, lessons on product-market fit that stand up under scale, and founder-led GTM tactics that keep teams focused on what matters.
I’m all in for discussions that get specific—what to ask in a VP interview, how to structure a 30/60/90 for new leaders, and the rituals that keep quality high without slowing velocity. If you’re building, leading, or leveling up your craft, this is time well spent.
I hope you’ll join us. Subscribe to “In Depth” now and learn more at firstround.com
I sat down with Molly Graham, a seasoned exec and builder who particularly excels at helping startups to go not from 0 to 1, but from 1 to 2. She helped build and scale Facebook, Quip, The Chan Zuckerberg Initiative in their early days, and is now the COO of Lambda School. Every time I revisit her playbook, I find fresh, practical insights that resonate with my day-to-day leading product and scaling teams.
Today, I zero in on management. In my role leading product management at HighLevel, I’ve seen — just as Molly has — how so many startup mistakes come down to general management issues. We unpack the traps that are easy to fall into, how to avoid reactionary leadership, and why deliberate operating mechanisms matter when the team and roadmap are growing fast.
One counterintuitive practice I double down on: spend more time with your highest — not your lowest — performers. Your top talent sets the quality bar, accelerates product discovery, and protects employee retention at startups; investing in them compounds. I share how I structure 1:1s, goal-setting, and outcomes vs output OKRs so high performers stay aligned, unblocked, and energized.
We also talk about managers who shaped our philosophies, the messy IC to manager transition, and the cadence that keeps teams focused without stifling autonomy. Expect concrete tactics you can use tomorrow, whether you’re a first-time manager or a seasoned leader scaling from dozens to hundreds.
Two themes I return to often: codify your culture early, and ‘give away your Legos’. As scope expands, leaders who consciously hand off ownership create more opportunity, reduce bottlenecks, and build a resilient organization. On compensation, I outline a startup compensation strategy and the principles for setting up your first comp system so it’s fair, explainable, and scalable.
If you’re building from 1 to 2, this conversation is a management field guide: clear mental models, practical rituals, and candid lessons learned from scaling product, people, and culture.
I recently reflected on an insightful conversation with Jean-Denis Grèze, Head of Engineering at Plaid, which securely connects your bank to your apps. Before joining Plaid, he served as Director of Engineering at Dropbox, and even has law school and one year as a lawyer under his belt before diving deep into the world of CS. That unconventional path sharpened his perspective on leadership and culture in ways that deeply resonate with how I build product and engineering teams.
Jean-Denis calls becoming a lawyer a “four-year detour he probably didn’t need,” yet the discipline and judgment he developed there clearly inform his approach. He strongly favors pragmatism over perfection — a stance I share. In product management leadership, that bias toward outcomes, rapid iteration, and accountability is the backbone of a healthy engineering culture of ownership.
What stood out most was his modern playbook for engineering leadership, stitched together from years at Plaid and Dropbox. Ownership starts with clarity: sharp priorities, explicit decision rights, and fast feedback loops that connect product roadmapping and sprint planning to measurable business outcomes. When teams understand the why and can see their impact in the right KPIs, they lean into responsibility rather than waiting for directives.
We also dug into org design choices that amplify ownership. His engineering org doesn’t have titles. In my experience, removing titles can reduce ego-driven friction and elevate scope, impact, and outcomes as the true signals of growth. But it requires strong frameworks for leveling, compensation, and the IC to manager transition so people still understand expectations and career paths.
I was particularly intrigued by the one question he asks every engineering manager candidate. While the question itself is simple, the signal it seeks is profound: can this leader create clarity, foster accountability, and drive outcomes across ambiguous, cross-functional work? When I hire, I look for the same traits — leaders who translate strategy into outcomes vs output OKRs and consistently raise the team’s bar for execution.
We also unpacked the perennial balancing act: prioritizing technical debt and keeping the lights on versus sexy, brand-new projects. My approach mirrors his emphasis on sustainability — dedicate explicit capacity for reliability, security, and platform health, anchor the roadmap to product and engineering KPIs, and make trade-offs transparent. When technical debt is framed as risk mitigation and velocity enablement, it earns its rightful place alongside new customer-facing bets.
This conversation is a must-listen for technical leaders or anyone eyeing the engineering leadership track. From motivating a team to tracking the right KPIs, the tactics and stories from Plaid and Dropbox offer practical guidance for cultivating an engineering culture that owns outcomes, moves fast with judgment, and scales without sacrificing quality.
I’m constantly looking for systems that outlast leaders and market cycles. When I picked up “Working Backwards,” which provides an inside look at the leadership principles and business processes that have made the company so successful, I recognized a playbook product teams can trust when the stakes are high and ambiguity is higher.
Bill Carr and Colin Bryar bring rare operator credibility to the topic. Bill started at Amazon in 1999, and went on to launch and run the Prime Video, Amazon Studios, and Amazon Music businesses before he left the company in 2014. Colin joined Amazon in 1998, as the Director for Amazon Associates and Amazon Web Services Programs. He also spent two years as Jeff Bezos’ technical advisor or “shadow,” and later served as the COO for IMDb.com.
Their stories illuminate Amazon’s culture of innovation and the origin stories of the Kindle, AWS, and Prime businesses. From granular details about the “working backwards” process, to an inside look at how players like Jeff Bezos and incoming CEO Andy Jassy operated up close, the lessons sharpen what “dive deep” and operational excellence look like in practice.
Several ideas have become mantras for my product management leadership practice: why innovation can’t be a part-time job, the perils of taking a “skills-forward” approach to exploring new opportunities, and why mechanisms are more important than good intentions. These principles reinforce the shift from outputs to outcomes and bring needed rigor to outcomes vs output OKRs.
At HighLevel, we apply a working-backwards mindset to product discovery: we start from the customer benefit, pressure-test the narrative with real users, and map success metrics before we write a line of code. This discipline accelerates product-market fit lessons, reduces thrash in product roadmapping and sprint planning, and clarifies trade-offs when timelines and resources are tight.
Mechanisms turn intent into results. For us, that means single-threaded ownership for critical bets, decision logs that preserve context, lightweight written narratives that force clear thinking, and weekly business reviews that highlight leading indicators. These habits create the tight feedback loops needed to dive deep, course-correct quickly, and scale operational excellence.
If you’re a founder, product creator, or operator scaling a SaaS platform, the throughline is simple: make innovation a full-time commitment, resist “skills-forward” biases when exploring new opportunities, and demand mechanisms that institutionalize good judgment. That’s how durable systems outlast any single leader.
I rarely get to trace a consumer product’s journey from a blank slate to one billion users, end to end. In reflecting on my conversation with David Lieb, Director of Google Photos, I was struck by how deliberate product discovery, clear problem framing, and thoughtful org design compounded into outsized impact.
David’s arc is instructive. Previously, he was the founder/CEO of Bump, an app that allowed users to swap contact information by physically bumping phones. Bump was acquired by Google in 2013, and formed the basis for the design of Google Photos, which launched in 2015 and passed the 1 billion users mark in 2019.
He walked me through building a consumer product from scratch and scaling it to over a billion users in just four years. What resonated most was the candid recounting of early mistakes at Bump, the realities of navigating big company politics at Google, and the methodical way the team pinpointed the core problem in the photo-sharing space.
The rigor of product discovery stood out. From the precise questions they asked in user interviews, to how they stack ranked for the canonical users, the team built conviction by prioritizing the right people and the right jobs to be done. I’ve seen too many teams spread thin across edge cases; this approach forces clarity on who you serve first and what you ship next.
We also dug into what it takes to operate at Google’s scale: planning discipline, org design that minimizes cognitive overhead, and mechanisms that keep outcomes ahead of output. For me, the difference between motion and progress is how crisply goals are defined and how tightly execution aligns to them—especially when the stakes and surface area grow.
On org design, I appreciated the practical nods to models like the Spotify “squads’ model, emphasizing cross-functional accountability and autonomy calibrated for speed without sacrificing cohesion. The key is empowering teams to ship independently while keeping a shared strategy and metrics that ladder up.
My playbook takeaways are direct. Narrow the problem statement until it becomes unambiguous. Use user interviews to validate the problem, not to seek applause for your solution. Stack rank canonical users and ruthlessly prioritize. Translate that focus into product roadmapping and sprint planning tied to measurable outcomes—not vanity metrics. And as you scale, evolve the structure so teams can move fast while the product narrative stays singular.
Whether you’re an early product builder or leading a mature platform, this blend of founder scrappiness and big-company craftsmanship is a blueprint. The path to one billion users isn’t a growth hack; it’s clarity of problem, empathy for users, and organizational design that compounds over time.
When I think about building enduring startups, one principle guides my approach: treat the company itself as the product. That mindset came into sharp focus as I studied the operating systems behind Kevin Fishner, Chief of Staff at HashiCorp. The rigor and clarity of his approach offer a blueprint any product management leader can adapt to scale with speed and integrity.
As the first business hire at the cloud infrastructure automation company, he previously built out the sales, marketing and product management teams. That trajectory matters: it’s rare to see one leader connect go-to-market, product management, and operational cadence so cohesively. The result is a system that aligns strategy, execution, and learning loops without creating organizational drag.
Now as chief of staff, he’s focused on building a strong foundation of company-wide systems, now that the team has grown to over 1000 people. This is where great product management leadership shines—codifying how decisions are made, how work moves, and how teams align around outcomes as headcount and complexity expand.
In today’s conversation, Kevin shares a detailed look at how they run meetings, set and track progress toward goals, and make decisions through writing at HashiCorp. I’m a strong proponent of a writing-first culture as the backbone of a scalable operating cadence: crisp memos reduce meetings, strengthen decision quality, and preserve context. Combined with clear meeting charters, owner-defined agendas, and time-boxed decision-making, this turns process into a lever for speed—without sacrificing rigor.
He also shares incredibly tactical advice for making annual planning more effective, including the unique business simulation they run, their scorecard system, and the weekly and quarterly meetings that help them stay focused on important KPIs. My lens: anchor annual planning in outcomes vs output OKRs, then connect those outcomes directly to product roadmapping and sprint planning. Use QBRs vs OKRs thoughtfully—QBRs to pressure-test business performance and assumptions, OKRs to lock in the next set of measurable bets. The scorecard becomes the single source of truth for progress and trade-offs, while the business simulation stress-tests priorities before they hit roadmaps.
Whether you’re a chief of staff, a founder spinning up a company from scratch, or a manager scaling a team, you’ll find practical takeaways here to make your organization more effective. I’ve distilled templates, prompts, and visuals to help you adopt a writing-first decision model, stand up a repeatable meeting rhythm, and operationalize goal tracking so KPIs stay front and center—not buried in dashboards.
If you’re serious about building startup systems that scale, adapt these practices: align on a few critical outcomes, document decisions in writing, instrument scorecards that ladder to KPIs, and commit to weekly and quarterly cadences that turn strategy into execution. That’s how you build an organization that learns faster than it grows.