Your analytics agent can turn a question into a chart. Then a product leader asks which activation definition it used, an analyst gets a different cohort result, or security discovers that the agent queried data the user could not normally access. That is where a promising pilot becomes an enterprise risk.
The way through is not a better chat interface. You need a controlled path from question to decision: approved definitions, bounded tools, task-level evaluations, visible evidence, and permissions that expand only after the agent proves it can handle a specific workflow reliably.
Before you give an agent a task, define its contract. The contract should answer five questions:
What decision is being supported? A request to explain a funnel is different from a request to change the funnel definition or publish a recommendation.
Which definitions are authoritative? Identify the canonical metric, its version, the population, the unit of analysis, the time window, and any approved exclusions.
What may the agent access and do? Specify datasets, fields, tools, credentials, and whether the task is read-only, produces a draft, or can trigger an action.
What evidence must accompany the answer? Require the metric identifier, query or tool calls, filters, lineage, assumptions, and enough result detail for an analyst to reproduce the work.
When must the agent stop? Define the ambiguities, policy conflicts, statistical gaps, and high-consequence actions that require clarification or approval.
Consider a seemingly simple question: Did activation decline for new accounts? The answer depends on the approved activation event or event sequence, cohort entry rule, identity resolution, time zone, date range, and exclusions. If the agent silently supplies one of those details, it has made a product decision while pretending to perform analysis.
The safe behavior is straightforward. The agent should retrieve the approved definition, display the material assumptions, and ask for clarification when the remaining ambiguity could change the result. It should not create a new activation definition in the course of answering the question. Changes to definitions belong in a governed workflow with an owner, review, version history, and rollback path.
This distinction also gives you a better definition of accuracy. An answer fails if it uses the wrong metric, violates an access rule, omits a material assumption, or cannot be reproduced, even when the final number happens to be correct. Trust is a property of the whole execution path, not only the sentence shown to the user.
Move through four levels of autonomy one task at a time
Teams often treat agent maturity as a platform-wide label. That hides risk. The same system may be mature enough to draft a funnel but not mature enough to interpret an under-specified experiment. Assign maturity to each task, dataset, and action instead.
Level
Agent role
Evidence required before moving forward
L0: Conversational interface
Summarizes charts or reports that already exist.
The agent accurately identifies the selected artifact, preserves its filters and caveats, and does not imply that it performed new analysis.
L1: Grounded retrieval
Retrieves definitions and context from the analytics catalog, taxonomy, or metric store before answering.
Canonical definitions are consistently selected, citations and assumptions are visible, and retrieval respects the requesting user’s permissions.
L2: Governed tool use
Reads schemas, generates safe SQL, calls approved tools, and reconciles results against canonical definitions.
Representative tasks pass golden-data and regression evaluations; queries, tool calls, lineage, errors, latency, and cost are observable.
L3: Bounded autonomous workflow
Completes an end-to-end workflow with approval gates, audit logs, feature flags, and rollback controls.
The exact workflow has a stable evaluation history, clear ownership, tested failure handling, and a reversible execution path.
L0 can still be useful. It reduces navigation work and helps a user understand an existing dashboard. The mistake is presenting that convenience as autonomous analytics. L1 improves trust by grounding language in the organization’s own definitions, but retrieval alone does not prove that a newly calculated result is correct.
L2 is the consequential transition. The agent is no longer explaining an approved artifact; it is producing analytical work. Schema awareness, safe SQL, result reconciliation, and complete traces become release requirements rather than optional diagnostics.
L3 should describe a narrow, governed workflow, not a general promise that the agent can handle anything. For example, an agent might autonomously refresh an approved weekly retention analysis while still requiring an analyst to approve a new cohort definition. Broaden the task boundary only after the additional behavior has its own tests and controls.
Build evaluations around the work people actually do
A generic chatbot benchmark will not tell you whether an agent can support your product decisions. Your evaluation unit should be a complete analytics task performed under your definitions, schemas, policies, and edge cases.
In my day-to-day building AI products, I’ve learned a simple truth: a single model can be brilliant, but a coordinated team of specialized agents is what consistently ships outcomes customers trust. That’s the promise of multi-agent systems—multiple AIs with distinct roles collaborating inside robust AI workflows to deliver accuracy, speed, and resilience you can’t get from a lone model.
Think of a multi-agent system as a well-run product trio for machines: a planner decomposes the job, specialists execute focused tasks, a reviewer checks quality, and an orchestrator keeps everyone aligned. This agentic AI approach mirrors how high-performing teams work—divide complex problems, play to strengths, and create tight feedback loops.
When does one AI stop being enough? Whenever tasks require tool use, domain retrieval, multi-step reasoning, or policy adherence under real-world constraints. In those moments, specialized agents shine—one for search using a retrieval-first pipeline, another for reasoning, another for action execution, and a final one for validation. The result is better accuracy with manageable latency and cost.
The core architecture I rely on starts with a planner that breaks a goal into steps, followed by execution agents equipped with tools and grounded context. I pair this with context window management to keep prompts lean and relevant, and I insert a verifier (or critic) to catch logic slips and policy violations before results reach customers. A lightweight orchestrator coordinates handoffs and retries to keep the whole flow resilient.
To make this production-grade, I treat observability as non-negotiable. Agent Analytics helps me see which agents are adding value versus adding latency, where failures cluster, and how prompts drift over time. From there, eval-driven development gives me measurable confidence: I codify representative tasks, run offline and shadow evaluations, and only promote changes that move accuracy and safety in the right direction.
Governance is equally critical. I design privacy-by-design from the start, restrict data movement with strong data governance, and enforce policy constraints inside the workflow rather than after the fact. This includes red-teaming failure modes, rate-limiting tools, and capturing immutable traces for audits and post-incident reviews—habits borrowed from SRE culture that map well to AI systems.
On the practical side, prompt engineering remains foundational, but it’s the system design that converts clever prompts into reliable outcomes. Tool access, retrieval quality, memory strategy, and error handling matter more than wordsmithing alone. I’ve found that small prompt improvements are amplified when the surrounding workflow is sound—and are overwhelmed when it isn’t.
If you’re just starting, begin with a narrow use case and a minimal set of agents—planner, executor, and verifier—then expand. Use continuous discovery with real users to learn where the workflow fails in the wild, and iterate with tight release cycles. Treat every agent like a microservice with clear contracts, test coverage, and metrics, and you’ll unlock compounding gains without losing control.
The payoff is tangible: faster shipping cycles, fewer regressions, and outcomes customers can actually rely on. When stakes are high and ambiguity is real, one AI is often a talented soloist—but a disciplined ensemble of agents is how I deliver dependable, scalable value at product velocity.
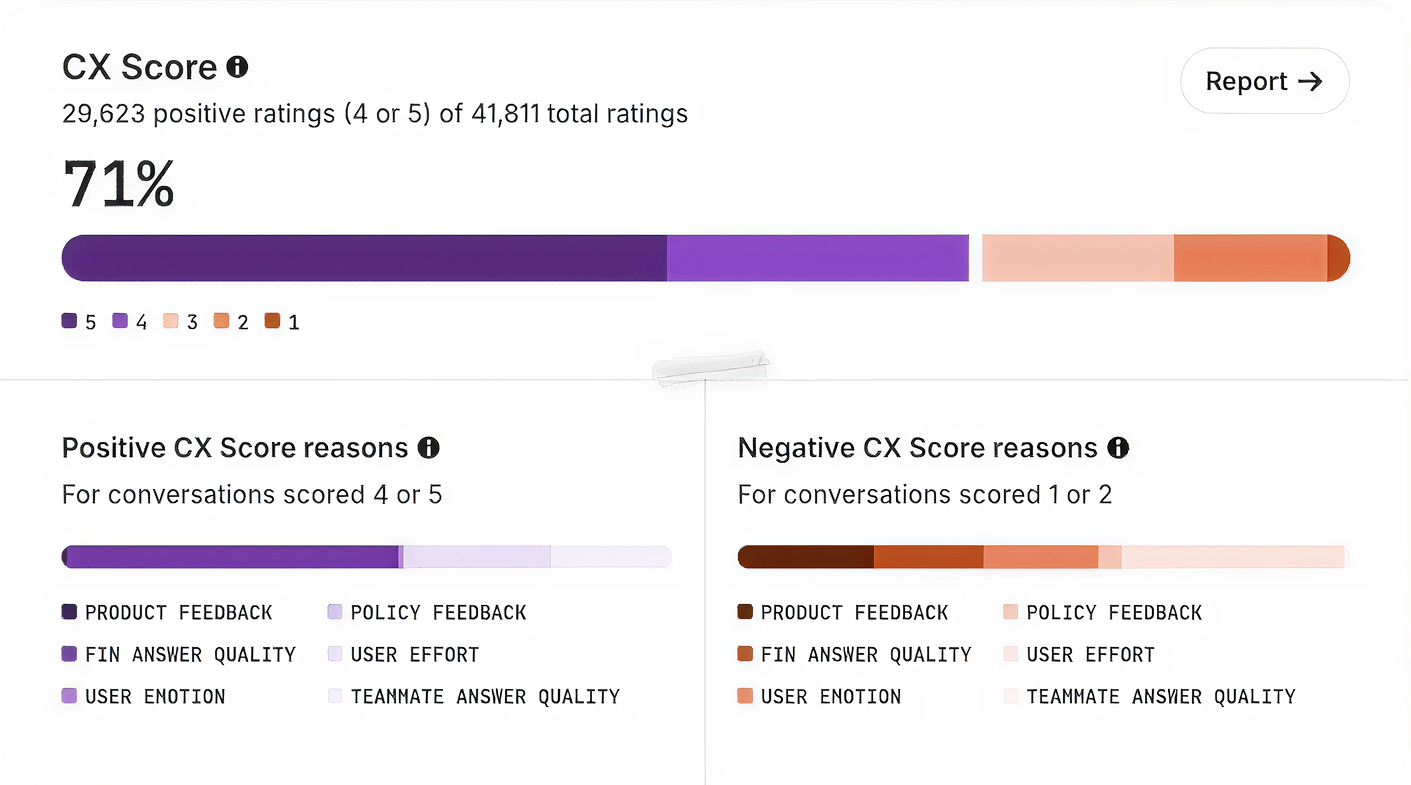
“You don’t have to trust the algorithm; you can see exactly why a conversation earned the score it did.”
We recently shared how we redesigned CX Score to deliver deeper, more actionable insights across every conversation. The most common follow-up from support leaders was simpler and incredibly important: “Can I trust it?” It’s the right question—and it’s the one I use as my own bar for whether a metric is ready for the C‑suite.
CS teams are the subject matter experts on customer experience. They understand the nuance of what customers feel, the context behind every interaction, and the difference between a technically resolved issue and a genuinely satisfied customer. I’ve learned, conversation by conversation, that any metric we ship has to capture that nuance at scale—or it doesn’t deserve to be used.
We built CX Score to give support teams a complete view of how their customers feel across every conversation. It surfaces what’s working, what’s not, and why—so leaders can communicate impact clearly and drive change across support, product, and the wider business.
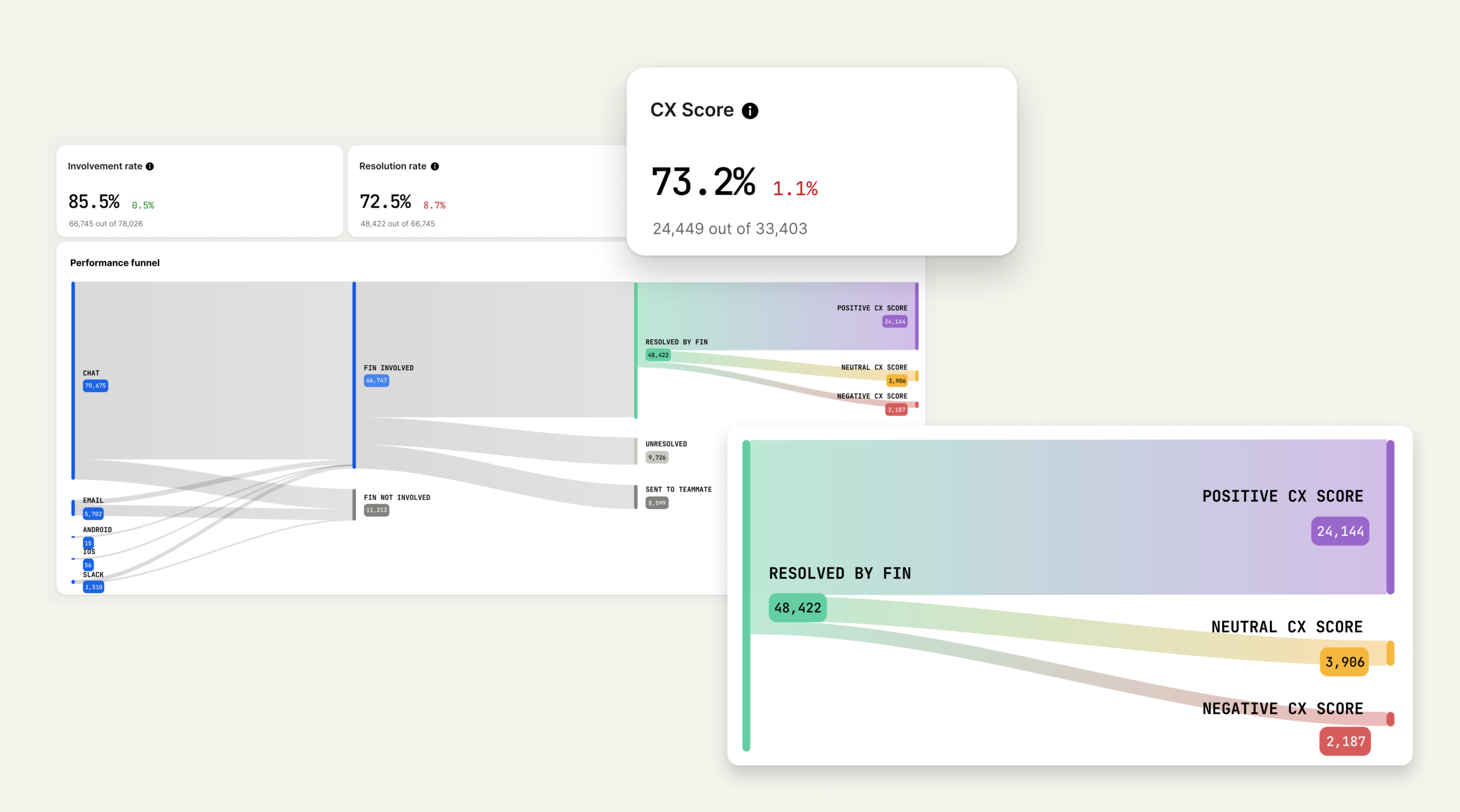
A CX Score in action: repeated CSV export failures trigger a low score and customer frustration, while the AI agent clarifies next steps and gathers details—turning raw signals into actionable support insights.
Here’s exactly how I approached building a trustworthy metric that support leaders can inspect, explain, and defend.
1) It’s grounded in how support teams define quality. I started with how experienced support professionals actually evaluate conversations—collecting real examples of strong, mixed, and poor interactions across industries, identifying the specific factors that shape overall experience, and writing plain-English rules for each. The result: CX Score applies the same criteria a trained support professional would use, not generic LLM assumptions.
2) It’s aligned with human judgment. We created a dataset of thousands of real customer conversations spanning multiple industries, languages, channels, and agent types. Each was manually reviewed by experienced support professionals—with two reviewers per conversation where possible and disagreement resolution to create stable consensus labels. The result: CX Score is trained and tested to behave like an expert reviewer, not a language model making broad guesses.
A modern CX analytics view shows how conversations flow from chat, email, and mobile into AI assistance, then to resolutions and sentiment outcomes—turning messy support data into a single, defensible CX Score.
3) It’s engineered by AI specialists. CX Score isn’t a prompt attached to an LLM. It’s a production system built by Intercom’s AI Group: 37 ML scientists and 350 engineers whose full-time focus is AI for customer service. The system includes specialized handling for long transcripts, model configuration tailored for support language and subtle sentiment, prompt engineering designed to default to neutral when evidence is weak, and a multi-stage evaluation pipeline that checks for precision, consistency, and reliability. The result: A metric built by a team that understands LLM behavior in production support environments, where accuracy and consistency matter most.
4) It’s validated statistically, not qualitatively. Trust requires measurement, not vibes. We tested CX Score across standard ML metrics: Precision (when the model flags a negative experience, how often do humans agree?), recall (how many human-identified issues does it catch?), and F1 score (the balance between both). We set an explicit bar: F1 above 0.8, representing high agreement with human judgment. We reran these evaluations through every revision, checking for regressions or biases, and I focused especially on negative experiences, because a false negative hides a real problem. The result: CX Score meets a measurable standard before it ships—not a gut check, a statistical requirement.
5) It was battle-tested with real customers. Lab accuracy isn’t enough. Customer environments are messy: Varied ticket types, mixed languages, unpredictable edge cases. Before release, we ran a multi-phase field test—shadow-scoring conversations with both old and new models, validating sensible behavior across agent type and conversation length, then rolling out to a controlled customer group who confirmed the scores felt right, reasons were clear, and insights were actionable. The result: CX Score shipped because real teams told us it made sense in practice, not because it passed internal tests.
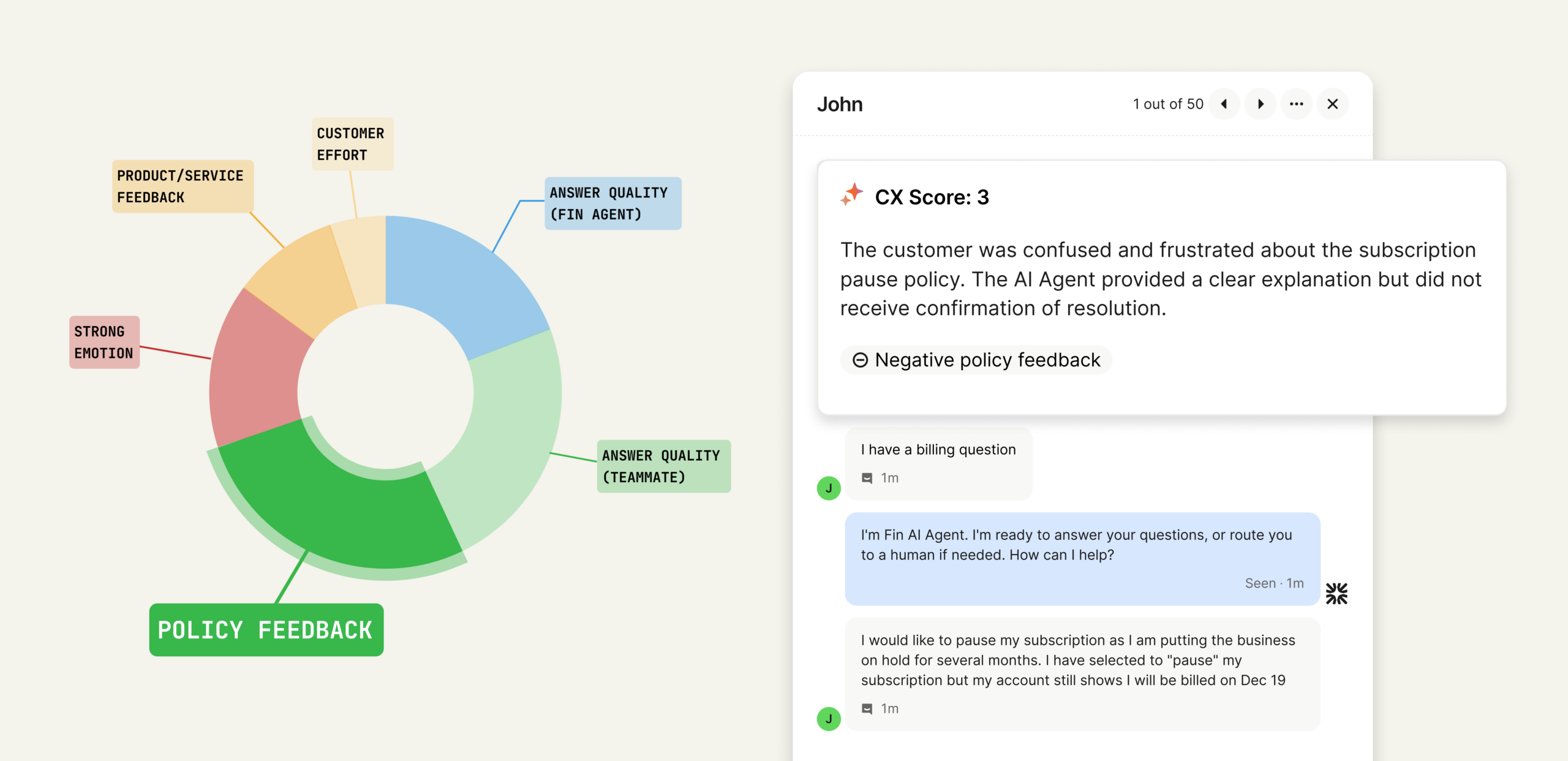
From conversation to clarity: this visual maps the drivers behind a CX Score. Explore how policy feedback, answer quality, and effort combine to produce defendable insights support leaders can act on.
The importance of explainability. One of the most critical choices I made was ensuring CX Score isn’t a black box. Every score comes with clear reasons, concrete excerpts, and a short explanation of what influenced the rating. This turns the metric into something you can inspect, audit, and explain to executives. You don’t have to trust the algorithm. You can see exactly why a conversation earned the score it did.
A metric that evolves with your business. Customer expectations shift. Products change. AI improves. A trustworthy metric can’t be static. CX Score evolves with the same commitments that shaped its redesign: Evaluate the real signals that shape customer experience, keep the logic simple and interpretable, and ensure leaders can make clear decisions from it. It’s built to be a durable source of truth across every conversation.
The takeaway. In a world where products look the same and AI can generate any interaction, customer experience is one of the few differentiators that actually matters. Support leaders have built that expertise conversation by conversation. What they’ve lacked is a measurement system that could validate it at scale—one that’s reliable enough to report to the C-suite, explainable enough to defend in strategy meetings, and rigorous enough to drive real decisions. That’s what CX Score is designed to be: A metric that reflects the reality support leaders see every day, backed by the technical rigor to make it credible everywhere else.
Want to see CX Score in your workspace? Ask your admin to enable it for your team, and start using explainable AI insights to improve customer experience and coach with confidence.
If your team has plenty of dashboards but still spends too much time turning a product question into a cohort, an explanation, and a decision, the bottleneck is no longer data collection. It is the work between asking the question and acting on the answer.
Treat the upgrade as a decision system, not an AI shortcut
A weak rollout starts by giving everyone access and encouraging them to try prompts. That produces activity, but it does not establish whether the technology is improving product work.
Define the unit of value as a completed decision. Each use of AI Visibility should move through a traceable sequence:
Start with a specific product question that could change an action.
Translate the question into an explicit cohort and metric definition.
Examine the relevant behavioral evidence.
Draft a narrative that separates observations from interpretations.
Record the decision, owner, and next action.
The enhancements reduce different kinds of friction inside that sequence. AI chat can reduce the interface work involved in expressing a segment. Content generation can reduce the effort required to turn analysis into a readable brief. A clearer interface can make the workflow easier for cross-functional partners to follow. Reliability improvements can support confidence in the system. None of those changes removes the need to define the question or approve the conclusion.
I would begin with two or three recurring, high-value use cases, not every analytics task. A good pilot question appears often, has a trusted baseline for comparison, and ends in a recognizable decision. Activation analysis, churn exploration, and experiment reporting meet those conditions for many product teams.
Match each enhancement to a concrete product job
Do not ask a team to use AI for analytics in the abstract. Give each workflow an input contract: the decision being considered, the population, the behavior, the observation period, the metric, and the exclusions. This prevents a fluent prompt from hiding an underspecified question.
Find an activation bottleneck without redefining activation
An activation question usually sounds simple: which new users reach value, and where do the others stop? The difficult part is deciding what counts as a new user, what behavior represents value, how long the observation period lasts, and which internal or test activity should be excluded.
Set those definitions before opening AI chat. Then describe the desired cohort in behavioral language and use chat-driven segmentation to iterate on it. Before analyzing the result, compare the AI-created segment with a known cohort, a manually configured version, or an established dashboard. If the populations differ, investigate the definition rather than explaining the chart.
Once the segment is accepted, use content generation to draft a brief that identifies the observed drop-off, the affected population, the relevant comparison, and the question that deserves further discovery. Keep causal language out unless the evidence supports it. A funnel can show where behavior changes; it does not, by itself, explain why.
Explore churn precursors without turning correlation into cause
Churn analysis becomes unreliable when a cohort mixes users who never activated, customers who became inactive, and accounts that formally cancelled. Those are different states with different product implications.
Write a plain-language definition of the state you care about before generating the segment. A useful prompt pattern is: create a cohort of the specified customer population that completed the core behavior during the reference period but did not complete it during the comparison period; exclude internal and test activity; then separate the result by the business attribute relevant to the decision.
Use AI chat to test legitimate variations in that definition, not to invent the definition for you. When a behavioral difference appears, label it as a precursor or association until customer evidence or an experiment supports a causal explanation. The next action may be another analysis, a customer interview, or a retention experiment. It should not automatically be a roadmap commitment.
Draft experiment reports without delegating the decision
AI-generated experiment summaries are useful because the structure is repetitive even when the decision is not. Give the system the approved hypothesis, eligible population, exposure definition, primary outcome, guardrail measures, and underlying analysis. Ask for a draft that covers what changed, what remained uncertain, which segments require caution, and what decision the evidence supports.
The generated narrative should never become the statistical authority. The experiment analysis remains the record for effect estimates, uncertainty, and data-quality caveats. The brief exists to make that evidence understandable and actionable. If the prose and the analysis disagree, correct the prose before it travels to stakeholders.
Put human review around definitions and conclusions
AI can make a loosely defined request look finished. That is the central operating risk. The safest control is to review the workflow where meaning enters and where meaning leaves: validate the segment before interpreting the result, then validate the narrative before sharing it.
Validate the segment before reading the result
Confirm the identity unit. A user, device, workspace, and customer account are not interchangeable.
Check that event names and properties map to the team’s current tracking taxonomy.
Make inclusion rules, exclusions, sequence requirements, and observation periods explicit.
Compare membership or aggregate trends with a trusted manual definition when one exists.
Inspect surprising differences before using them as evidence. A mismatch may come from the cohort definition rather than user behavior.
Store a plain-language definition with the accepted cohort so another person can reproduce the analysis.
Validate the narrative before distributing it
Require each material claim to point back to a chart, table, or approved metric.
Separate observed behavior from a proposed explanation.
Verify that the population, date range, and comparison in the prose match the analysis.
Remove unsupported causal language and any detail the audience is not permitted to access.
State the decision, the remaining uncertainty, and the person responsible for the next action.
Content generation reduces drafting work; it does not transfer review responsibility to the model. This distinction is especially important for executive briefs, where polished language can make a weak inference appear more certain than it is.
Govern prompts, access, and workflow changes
Basic prompt templates, access policies, review steps, and data-governance controls turn experimentation into a repeatable capability. A prompt template should specify the business question, required definitions, exclusions, expected output, evidence standard, and reviewer. Access should follow the same least-privilege principles applied to the underlying analytics data.
Reliability also needs operational visibility. Keep a lightweight record of the original question, accepted cohort definition, supporting analysis, generated brief, reviewer, and resulting decision. When an answer changes unexpectedly, that record helps you distinguish a tracking problem from a cohort change, a prompt change, or an interpretation error.
Measure whether the rollout changes product decisions
Prompt volume and generated summaries are adoption signals, not proof of value. Establish a baseline before the pilot, run the selected use cases through the new workflow, and compare the result using measures tied to decisions.
Signal
How to observe it
What a weak result means
Time-to-insight
Track elapsed time from an accepted question to a reviewed analysis brief.
If the time does not fall, find the handoff or review step that still creates delay.
Stakeholder adoption
Track whether product, design, engineering, growth, and leadership use the workflow in recurring decisions.
If only analysts use it, the interface or output may not fit cross-functional work.
Decision velocity
Track elapsed time from requesting evidence to recording an explicit decision or next action.
If output increases but decisions do not move sooner, the workflow is producing content rather than clarity.
Review quality
Count material corrections to cohort definitions, metrics, and conclusions before and after sharing.
If rework rises, improve the event taxonomy, prompt contract, validation process, or reviewer guidance before expanding access.
Trust exceptions
Record cases in which an AI-assisted result conflicts with validated analytics or cannot be reproduced.
If exceptions persist, pause expansion and resolve the data, definition, or workflow problem.
Judge the pilot as a system. Faster segmentation with heavy correction is not a win. Faster drafting with unchanged decision velocity is not a win either. The useful outcome is a shorter path from question to reviewed decision, with stable or improving quality.
Expand only after the pilot workflow is reproducible. At that point, turn the accepted prompt patterns, cohort definitions, review criteria, and measurement approach into a shared operating playbook. The cleaner interface can help more partners participate, but the playbook is what keeps participation consistent.
Key takeaways
Use Amplitude AI Visibility to shorten a decision workflow, not merely to increase the volume of segments and summaries.
Begin with two or three recurring use cases that have trusted baselines and recognizable decisions.
Define the population, behavior, period, metric, and exclusions before asking AI to create a segment.
Validate cohort meaning before interpreting behavior, then validate the generated narrative before sharing it.
Scale the workflow only when faster output is accompanied by reproducibility and sound review.
Choose the next recurring product decision that still involves too much manual translation. Write its input contract, capture its current path to a reviewed decision, and use that single workflow to determine whether AI Visibility is removing the right friction.
Build vs. buy is a decision that never truly goes away, and with AI reshaping the economics of software, I’m revisiting this question more frequently—and with more nuance—than ever. The temptation to “just build it” is real when prototypes are cheaper, shipping feels faster, and small tools can rival big platforms. But the real decision has never been about code; it’s about value, data, and long-term responsibility.
Across product orgs at every stage, I see the same pattern: AI makes building feel easier—but it doesn’t eliminate the tradeoffs. The hard part is separating what differentiates your product from what simply supports it. That’s why I start by asking whether the capability is truly core to my value stream, and then I force myself to reason about ownership and maintenance, not just velocity.
My rule of thumb remains simple: If something isn’t core to your value stream, don’t build it. And even when it is core, vendors may still be better positioned—especially for payments, invoicing, and infrastructure. Those domains carry deep operational complexity, continuous compliance, and reliability requirements that are easy to underestimate and painful to own.
Here’s how this plays out for me. I would never build my own blogging platform. I moved from WordPress to Ghost, because publishing isn’t where I differentiate, and the long tail of upgrades, security, and performance is a drag on focus. The platform does the job, my audience gets a better experience, and my team avoids owning commodity maintenance work.
On the other hand, I did build my own task management system—despite the abundance of excellent tools like Trello, Evernote, and OmniFocus. For me, tasks, notes, and workflows are deeply personal and idiosyncratic. I wanted my system to reflect how I think, plan, and communicate, with tight integration to my daily product rituals. In this case, the underlying data became the real product—and owning and controlling that data changed the equation.
That’s the heart of the decision: When the underlying data becomes the real product, ownership matters. Task management, notes, and workflows evolve into a personalized operating system. The moment your data model represents your unique value—and your future differentiation—build vs. buy is no longer a tooling choice; it’s a strategy choice.
AI is pushing this even further. Cheaper prototyping and “vibe coding” lower the cost of building. Tools like Claude Code and platforms from OpenAI make it viable to ship smaller, targeted tools that would have been uneconomical a few years ago. That expands the frontier of what teams can build without committing to a monolithic platform—and it puts pressure on vendors to improve data portability.
Which brings me to vendor lock-in. Exports aren’t always enough. When I evaluate CRMs or course platforms, I look for more than CSV dumps. I want robust, well-documented APIs, webhook coverage, import/export parity, schema transparency, and a clear migration path. I’ve seen teams drown in brittle integrations with Salesforce or HubSpot, struggle to unwind course data from Teachable, or get stuck in signature workflows around DocuSign without a clean escape hatch. Portability is table stakes now.
I treat build vs. buy as a discovery problem. Options are assumptions to test. On the build side, I run feasibility spikes: proof-of-concept integrations, latency checks, cost-to-serve models, and a sober read on maintenance. On the buy side, I trial vendors, not their marketing. I replicate a real workflow, test the edges, validate data portability, and simulate failure modes like vendor downtime or schema changes.
A word of caution on complexity: “we can build anything” is not the same as “we should build this.” Long-lived products accumulate hidden complexity over time—security, privacy, performance, observability, SRE runbooks, QA automation, documentation, and compliance. Be honest about engineering capabilities and maintenance costs, especially when uptime and regulatory exposure are in play.
My practical checklist looks like this: Is this core to our differentiation? Do we need to own the data model? How strong is data portability (APIs, webhooks, mapping, re-import)? What’s the true total cost of ownership over three years (people, ops, security, compliance)? Are there regulatory or reliability constraints better handled by a vendor? What’s the opportunity cost of not building something more strategic? And if we buy, what’s our exit plan?
Ultimately, build vs. buy isn’t just about speed or cost—it’s about core value, data ownership, and long-term responsibility. AI lowers the barrier to building, but it doesn’t erase complexity. Treat build vs. buy decisions like any other discovery effort: test assumptions, prototype, and validate before committing. Ask not just can we build it, but should we own it?
If you’re wrestling with vendor lock-in, fielding pressure to “just build it,” or rethinking your stack in an AI-first world, this lens will help you ask better questions before you commit. And if you’re exploring targeted builds alongside platforms like Stripe, Dropbox, Obsidian, or Ghost, I’d love to hear what’s working for you and where portability remains a hurdle.
Trust is the currency of any high-stakes AI product, and nowhere is that more true than in healthcare. I recently dug into how Healio built an AI assistant for physicians—an audience that can’t afford to be wrong—and it’s a masterclass in balancing accuracy, transparency, and speed without compromising credibility.
Healio, a 125-year-old medical publishing company, set out to create Healio AI to help clinicians prepare for patient care. From the outset, their guiding principle was simple: physicians won’t trust you until you prove it. That lens shaped every decision—from discovery and prototyping to architecture, evaluation, and ongoing validation.
Discovery started with a survey of 300 healthcare professionals to understand real-world needs at the point of care. The headline insight: physicians primarily want AI for preparation, not bedside use. Even more surprising, the top ask wasn’t purely diagnostic support; it was help with patient communication and empathy—translating complex information into clear, accessible conversation.
Momentum mattered. After beginning with Figma mockups to validate workflows, the team built a working prototype in a single weekend using Cursor. That velocity wasn’t about cutting corners; it was about proving value quickly, reducing ambiguity, and iterating with concrete feedback from physicians.
Under the hood, the system employs RAG and hybrid search—combining lexical search, vector search, and semantic search across multiple trusted sources like PubMed. As any PM who has integrated biomedical literature knows, "just use PubMed" isn’t simple—there are five different ways to access the same data, each with trade-offs. The team made pragmatic choices to balance freshness, coverage, latency, and cost while preserving trust in source quality.
Designing for trust extended all the way to the citation UX. The team leaned into citations that physicians actually trust: subscripts, hover states, and progressive disclosure. This gave clinicians verifiable threads back to source material without overwhelming the core interaction, aligning with how experts want to audit evidence under time pressure.
Evaluation wasn’t left to chance. They stood up eight LLM judges for evals: safety, medical accuracy, faithfulness, relevancy, completeness, reasoning, clarity, and overall quality. Just as importantly, they treated those signals as directional, not definitive. In a high-stakes domain, physician feedback trumps LLM-as-judge feedback—so they complemented automated evals with direct reviews from practicing clinicians to calibrate quality and reduce hallucinations.
On the safety front, the team implemented HIPAA compliance and input guardrails for masking personal health information. That choice reflects strong data governance and privacy-by-design thinking: protect PHI by default, constrain prompts to safe boundaries, and make compliance a first-class citizen in the product architecture.
They also addressed monetization without compromising experience. Serving contextual ads while the LLM processes queries is a practical approach that preserves physician workflow efficiency and creates a clear, non-intrusive revenue model.
Critically, the work didn’t stop at launch. The Healio Innovation Partners provide ongoing discovery and validation, ensuring the system evolves with physician needs and the medical evidence base. This is the operating cadence you want for any AI product that sits at the intersection of safety, accuracy, and fast-changing knowledge.
My takeaways for building AI in high-stakes domains: prioritize retrieval-first pipelines over model cleverness; couple RAG with hybrid search across vetted sources; design citations that earn trust at a glance; use eval-driven development, but let domain-expert feedback be the ultimate judge; and embed regulatory compliance into your product strategy from day one. If trust is your North Star, this is a playbook worth emulating.
Your AI feature has passed the demo. Customers want it, leadership wants a date, and the team believes the remaining risks can be handled before launch. The problem is that nobody can state what evidence would make the feature safe enough to release – or who can stop it when that evidence is missing.
This is where AI ethics has to become product governance. You need a repeatable way to classify risk, set release conditions, assign decision rights, test safeguards, and respond when production behavior differs from the demo. The goal is not to eliminate uncertainty. It is to make uncertainty visible and govern the consequences.
Start with a release contract, not a list of principles
For each AI capability, write a short release contract before implementation begins. It should answer:
What decision or task is the product helping with? Describe the user outcome, not the model output. Generating a response is an output; helping a support agent resolve a request accurately is an outcome.
What must the system never do? Name unacceptable behavior such as exposing restricted data, presenting unsupported claims as facts, acting without required confirmation, or concealing that AI influenced an outcome.
Who can be affected? Include people represented in the data, people discussed in generated content, employees asked to rely on the output, and anyone subject to a downstream decision.
How consequential is a wrong result? Separate an inconvenient suggestion from an output that can affect access, money, employment, safety, privacy, or another difficult-to-reverse outcome.
What evidence is required to ship? Tie every material risk to an evaluation, control, review, or operational test. Avoid release criteria such as reasonable quality or adequate safeguards; two reviewers can interpret those phrases differently.
What will stop or reverse the feature? Define the conditions for disabling an action, reverting a version, narrowing availability, or returning the workflow to human handling.
Treat these conditions as part of the acceptance criteria. If a trust condition fails, the feature has not passed release readiness even when its primary quality metric looks strong. That keeps ethical constraints from becoming optional work negotiated away at the end of the schedule.
Classify the use case by consequence, autonomy, and reversibility
A model does not have one fixed risk level. The same underlying model can draft a headline, recommend an account action, or execute that action. Governance should therefore follow the use case rather than the model name.
A practical classification starts with three questions:
Consequence: What happens if the output is wrong, biased, misleading, or disclosed to the wrong person?
Autonomy: Does the system inform a person, recommend a decision, or take the action itself?
Reversibility: Can the affected person notice the result, challenge it, and restore the prior state without disproportionate effort?
Use those answers to choose a product path. A reviewable drafting aid may rely on disclosure, editing controls, standard evaluations, and ordinary monitoring. A consequential recommendation needs stronger evidence, an accountable human reviewer, and a clear appeal or correction path. An autonomous, hard-to-reverse action should not launch until the team can justify the autonomy, constrain permissions, require confirmation where appropriate, and demonstrate a reliable override.
Do not confuse a human in the workflow with meaningful human oversight. A person who lacks context, time, authority, or a usable way to reject the output is functioning as a rubber stamp. For higher-risk actions, the reviewer needs the evidence behind the recommendation, a clear indication of uncertainty or limitations, and the authority to choose a non-AI path.
Record the classification in an AI risk register. Each entry should contain the risk scenario, affected parties, possible impact, warning signals, preventive control, detection method, response, owner, required evidence, residual risk, and the person authorized to accept that residual risk. A model defect belongs in the backlog; a plausible future failure belongs in the risk register; a failure already affecting users belongs in incident management. Keeping those states distinct prevents serious risks from disappearing into a generic bug queue.
Likelihood will often be uncertain before production. Do not turn that uncertainty into a convenient low-risk label. Record what is unknown, how the team will test it, and which production signal will cause a review. For a consequential or difficult-to-reverse feature, I would also separate the person implementing the control from the person accepting the remaining risk.
Turn governance into four evidence-based release gates
A governance meeting should inspect evidence, not collect reassuring opinions. Four gates cover the path from data collection to production response. The depth of each gate should match the use-case classification.
Data gate: prove that the inputs are governed
Trust problems often begin before a prompt reaches the model. The data gate should make the full path of customer and organizational data inspectable.
Document what data is collected, where it came from, why it is needed, and which product purpose it serves.
Identify the applicable basis for processing and make consent flows explicit where consent is used. Legal requirements depend on the product, data, and jurisdiction, so product teams should validate this with qualified privacy and legal partners rather than infer an answer from a generic checklist.
Remove fields that are not needed for the stated outcome. Data minimization reduces both privacy exposure and the number of inputs that can produce unexpected behavior.
Map data lineage across ingestion, retrieval, model calls, logs, analytics, support tools, and vendors. A deletion promise is not credible if the team cannot locate every copy.
Apply role-based access to raw inputs, retrieved context, generated outputs, and operational logs. Access to the application should not automatically imply access to all AI interaction data.
Set retention and deletion rules, then test that they work across the full data path rather than only in the primary database.
The gate passes when the team can trace an input, explain its permitted use, name who can access it, and show how it is removed. A policy document without an enforceable data path is not sufficient evidence.
Model gate: test the failures that matter to the use case
Map every important risk in the register to an evaluation. If a risk has no test, state which manual review or production control provides the evidence instead.
Define the passing condition before reviewing final results. Moving a threshold after seeing a disappointing result turns a gate into a negotiation.
Test normal requests, ambiguous requests, edge cases, adversarial prompts, and realistic multi-step interactions. A polished set of happy-path prompts will not expose operational failure modes.
Compare performance across the user groups and contexts relevant to the product. Aggregate quality can conceal a meaningful gap affecting a smaller group.
Red-team prompts, retrieved context, tool use, and permission boundaries. For an agentic workflow, the safety of the text is only one part of the problem; the allowed action is another.
Keep the evaluation set and results tied to the model, prompt, retrieval configuration, tools, and policy version that produced them. Otherwise, a passing report can outlive the system it evaluated.
When an LLM must answer from known organizational information, a retrieval-first pipeline can ground the response in authoritative material. It does not remove the need for evaluation. Test missing documents, conflicting documents, stale content, access-restricted content, and questions the knowledge base cannot answer. The safe behavior may be to abstain, ask for clarification, or route the task to a person.
Experience gate: help users exercise judgment and control
Disclosure is useful only when it changes what a person can understand or do. Place it near the AI-assisted decision, in plain language, and explain the limitation that matters in that moment. A broad statement hidden in terms and conditions does not help a user assess a specific output.
Make it clear when AI generated, transformed, recommended, or acted on information.
Let users inspect, edit, reject, or correct an output before a consequential action where that control is meaningful.
Separate generated content from verified facts in the interface. Do not use confident UX writing to imply certainty the system cannot support.
Explain what data the feature needs and what changes when the user turns it off.
Provide a non-AI or human-assisted path when the AI path is unsuitable for the task.
Test whether users understand the system’s role. A control that exists but cannot be found or understood is not an effective safeguard.
Match the amount of friction to the consequence. Requiring confirmation for every low-impact suggestion can train users to click through automatically. For a high-impact or hard-to-reverse action, the extra pause may be the safeguard that preserves meaningful control.
Operations gate: demonstrate that failure can be contained
Pre-launch evaluations cannot cover every production context. The operations gate determines whether the team can detect, contain, and learn from behavior that escaped testing.
Monitor model behavior and customer impact. Technical availability can look healthy while unsupported outputs, harmful actions, or repeated user corrections are increasing.
Assign an owner and response for each alert. An unowned dashboard is visibility without control.
Create a kill switch or permission cutoff for risky actions, plus a rollback path for model, prompt, retrieval, and tool changes.
Test the rollback under realistic access and dependency conditions. A safeguard that nobody has exercised may fail during the incident it was meant to contain.
Prepare an incident playbook covering triage, containment, evidence preservation, affected-user assessment, communication, recovery, and the decision to restore service.
Keep a human override for high-risk actions and verify that the operator can use it without depending on the failing AI path.
This gate passes when the team can answer three questions without improvising: How will the failure be detected? Who can stop it? What evidence is required before it is turned back on?
Assign decision rights across the product lifecycle
Governance slows teams when everyone can raise concerns but nobody knows who decides. Put decision rights beside the risk register and release gates.
Product: owns the intended outcome, use-case classification, release contract, customer trade-offs, and completeness of the risk register.
Engineering and data: produce evidence for system behavior, data lineage, access controls, evaluations, technical constraints, and remediation.
Design and research: verify disclosure, comprehension, correction, appeal, and user control in the actual workflow.
Security and privacy: examine access, abuse paths, data handling, vendor exposure, and response controls.
Legal and compliance: interpret applicable obligations and identify where a product decision creates legal exposure. Product leaders should bring these partners in while choices are still reversible.
SRE and operations: own observability, alerting, rollback mechanics, incident readiness, and production recovery with the product team.
Executive risk owner: accepts material residual risk when the decision exceeds the product team’s authority and ensures that the required mitigation has resources.
The review itself should be a decision forum, not a status meeting. Send the release contract, risk register, failed and passed evaluations, unresolved questions, and requested decision in advance. End with one of four outcomes: approved, approved with explicit conditions, returned for more evidence, or rejected. Record the rationale and the event that will trigger another review.
Apply the same discipline to purchased models and AI services. A vendor can operate part of the stack, but it cannot absorb your accountability to customers. Due diligence should cover model provenance, data use and retention, access, evaluation evidence, incident history, change notification, and subcontracted dependencies. Contracts should carry operational commitments such as service levels, deletion obligations, audit rights, and incident responsibilities into the vendor relationship.
If a vendor cannot answer a material question, record the item as unknown. Do not silently translate missing evidence into low risk. Decide whether a compensating control – limited data, narrower permissions, independent evaluation, or a manual workflow – makes the unknown acceptable. If not, change the design or supplier.
Treat launch approval as a monitored, reversible decision
Approval should attach to a defined system configuration and use case, not to the feature name forever. A model change, system-prompt change, new retrieval corpus, broader user group, expanded data access, new tool permission, or shift from recommendation to autonomous action can invalidate earlier evidence. Put those change triggers in the original approval.
Launch with the smallest exposure that can produce useful operational evidence. Watch model-quality signals alongside user corrections, overrides, complaints, unexpected actions, access violations, and downstream customer impact. Set an owner and response for each signal before rollout. Waiting for a broad satisfaction metric to move can leave a concentrated harm hidden inside an apparently successful launch.
Customer trust also depends on what you reveal outside the internal review. A customer-facing trust center can publish the AI system’s role, material limitations, relevant data practices, available controls, change history, and a path for reporting problems. Model facts, limitations, and change logs make responsible operation visible. Candor about a boundary is more useful than a vague claim that the system is responsible or safe.
Key takeaways
Govern the use case, not the model in isolation. Consequence, autonomy, and reversibility determine the controls you need.
Pair every success metric with an unacceptable outcome and observable release condition.
Use one living risk register to connect risk scenarios, evidence, owners, safeguards, residual risk, and review triggers.
Require evidence across data, model behavior, user experience, and production operations before release.
Treat human oversight as a designed capability. The reviewer needs context, time, authority, and a usable alternative.
Carry governance into vendor selection, contracts, monitoring, incident response, and material system changes.
Take one AI item from your current roadmap and write its release contract before the next planning or governance meeting. Name the intended decision, unacceptable outcomes, affected people, required evidence, stop conditions, and accountable risk owner. Any blank you cannot fill is not paperwork still to complete. It is product work you have found before customers find it for you.
You have an AI capability on the roadmap. A vendor can demonstrate something credible almost immediately, while engineering believes an internal version would fit the product better. Both claims may be true, and neither one answers the decision in front of you.
The useful question is not simply whether to build or buy. You need to decide which parts of the capability create strategic advantage, what you must learn before committing further, which obligations you are prepared to own, and how you will leave if the economics or technology changes.
Draw the capability boundary before comparing options
Most weak build-versus-buy debates begin with a label that is too broad. AI assistant, support automation, recommendation engine, and enterprise search each describe an experience, not a single technical capability. Comparing a vendor’s finished product with an imagined internal system at that level guarantees an uneven evaluation.
Break the experience into layers before discussing ownership. An AI product might contain data connectors, ingestion, domain retrieval, ranking, generation, orchestration, evaluation, observability, policy guardrails, workflow logic, a user interface, and a human handoff. You can make a different decision for each layer.
Classify every layer by its strategic role:
Differentiation: The layer materially affects why customers choose, retain, or expand with your product. It may encode a proprietary workflow, use unique data, or create a feedback loop competitors cannot easily reproduce.
Parity: Customers expect the capability, but it is not a meaningful reason to choose you. Reliable billing infrastructure, standard integrations, and generic analytics plumbing often belong here.
Control: The layer may not be visible to customers, but it determines whether you can satisfy security, regulatory, reliability, cost, or product-policy obligations. Control can justify ownership even when the layer itself is not differentiating.
If this layer became substantially better, would it change the product’s value proposition or merely close a feature gap?
Does operating it create proprietary data, evaluation evidence, workflow knowledge, or customer insight that compounds over time?
Would dependence on a vendor’s roadmap prevent you from making an important product promise?
Could a close competitor buy the same capability and achieve roughly the same result?
Do privacy, residency, auditability, reliability, or recovery requirements force you to retain direct control?
Can your team support the layer after launch, including incidents, upgrades, security work, and user adoption?
A retrieval-augmented generation system shows why this decomposition matters. The right answer may be to build the parts that encode domain knowledge while buying fast-moving infrastructure around them.
Layer
Strategic question
Plausible initial posture
Domain retrieval and ranking
Does relevance depend on proprietary content, metadata, permissions, or customer context?
Build when this is central to answer quality and differentiation.
Orchestration and observability
Would owning the runtime create customer value, or only infrastructure work?
Buy when a platform provides adequate reliability, APIs, and portability.
Prompts, policies, guardrails, and evaluation cases
Do these artifacts encode product behavior, risk tolerance, and domain expertise?
Own the specifications and evidence even if a vendor executes them.
User workflow and human handoff
Is the workflow part of the product’s distinctive experience?
Build the differentiated interaction; integrate commodity components behind it.
The point is not that every retrieval system should use this split. The point is to stop forcing one ownership decision across layers with different strategic value. A composed architecture can give you speed at the edges and control at the center.
Compare time to value and total ownership cost separately
Buying and building usually produce different cost curves. Buying can reduce the initial implementation burden and provide proven operations. Building concentrates cost and complexity near the beginning but may create a better fit and more favorable economics at scale. Neither profile is automatically cheaper.
Evaluate the decision across two horizons. The first is time to activated value: how long it takes before the intended users complete the intended workflow successfully. The second is total cost of ownership over the period in which the capability must operate, evolve, and eventually migrate.
Do not treat a signed contract, completed deployment, or merged pull request as time to value. Procurement, security review, data preparation, integration, enablement, in-product guidance, and user activation sit between acquisition and an actual outcome. A fast purchase with weak adoption is not a fast result.
A useful cost model is:
Total ownership cost = acquisition or development + integration + operations + change + risk exposure + exit.
Apply the same formula to both choices. Teams often present the vendor’s full commercial cost against only the internal development estimate, or compare a subscription price with an imagined build that excludes maintenance. Both comparisons are misleading.
Cost area
Evidence needed for a buy option
Evidence needed for a build option
Acquisition or development
Subscription, per-seat or consumption charges, implementation fees, support tier, and expected price changes with growth.
Product, design, engineering, data, security, and platform capacity required to reach usable scope.
Integration
Connector work, identity and permission mapping, data transformation, API constraints, testing, and CI/CD maintenance.
Interfaces with existing systems, migration of current workflows, data contracts, and platform dependencies.
Operations
Internal administration, vendor management, incident coordination, usage monitoring, and workarounds for roadmap gaps.
On-call ownership, observability, model and dependency updates, incident response, capacity management, and reliability work.
Change
Configuration limits, professional services, retraining, contract changes, and waiting for vendor roadmap delivery.
Continuing product development, evaluation maintenance, documentation, enablement, and the opportunity cost of displaced roadmap work.
Risk exposure
Vendor outages, security posture, data handling, roadmap dependence, quota changes, and concentration risk.
Internal security gaps, insufficient operational maturity, key-person dependency, and failure to meet compliance obligations.
Exit
Data export, contract termination, migration assistance, replacement integration, and reconstruction of non-portable artifacts.
Decommissioning, data migration, user transition, and replacement of internally coupled components.
Run an expected case and a stress case for both options. For a vendor, stress usage, API consumption, support requirements, and the cost of additional environments or features. For an internal system, stress incident load, model or infrastructure changes, evaluation maintenance, and continued product demands. The purpose is not to produce a perfectly precise forecast. It is to expose which assumptions can overturn the decision.
Record those assumptions in the decision memo. If vendor consumption cost must stay within an agreed envelope, state that envelope internally and assign someone to monitor it. If the build case depends on reuse across several product surfaces, name those surfaces and verify that their teams actually intend to adopt the component. An unowned assumption is not a forecast; it is hidden risk.
Turn the debate into an evidence-based decision
A scorecard is useful only when it forces explicit trade-offs. It should not turn judgment into decorative arithmetic. Establish hard gates first, agree on the relative importance of the remaining criteria before vendor demonstrations or internal prototypes create attachment, and then evaluate both options against the same outcome.
How directly does the capability support the value proposition or defensibility?
Product strategy, roadmap commitments, customer workflow evidence, proprietary data advantages, and the importance of controlling behavior.
Build becomes more attractive as the capability determines why customers choose or stay.
Urgency and time to value
What is the cost of waiting, and when can users reach a meaningful outcome?
Procurement and security timelines, integration dependencies, build scope, launch readiness, enablement needs, and adoption path.
Buy becomes more attractive when delay is costly and the purchased path can reach activated value materially sooner.
Security and regulatory risk
Can either option verifiably meet non-negotiable obligations within the launch window?
Data-flow diagrams, privacy controls, residency, retention, audit logs, access controls, certifications, threat response, model lineage, and red-team practices.
An option that fails a mandatory obligation should be removed, regardless of its aggregate score.
Integration complexity
How much continuing work is hidden behind the initial connection?
Sandbox tests, API behavior, quotas, identity mapping, data contracts, failure modes, deployment workflow, and ownership of connectors.
Build gains ground when vendor constraints create persistent product or operational work; buy gains ground when internal integration and support exceed the apparent build scope.
AI leverage and portability
Which prompts, data, evaluations, embeddings, policies, and feedback become valuable, and can they move?
Export tests, API abstraction, model-routing options, ownership terms, deletion process, evaluation access, and migration design.
Build or a hybrid architecture gains ground when the vendor captures an asset central to future differentiation.
Security, regulatory compliance, and minimum reliability are gates, not preferences. A high score elsewhere cannot compensate for an option that cannot lawfully handle the data, meet a required recovery posture, or provide necessary audit evidence. The same logic applies to internal capacity: if no team can own production incidents, an attractive prototype is not a viable build option.
Use a product trio of product, design, and engineering to set the scorecard’s priorities. Bring security, data, finance, procurement, and operations into the criteria they own. This prevents a late-stage veto from appearing as a surprise when it was actually a missing requirement.
Then run comparable discovery work. Give the vendor a production-like workflow in a sandbox. Give the internal option a thin vertical slice that touches the real data and integration boundary. Test the same cases for outcome quality, failure handling, permissions, auditability, operator effort, integration behavior, and unit economics. A polished vendor demonstration and a rough internal prototype reveal different things; common acceptance cases make the evidence comparable.
Keep confidence separate from the decision direction. A criterion can favor building while resting on weak evidence. Mark it as an assumption and define the cheapest test that would resolve it. This is more useful than adding precision to a score whose inputs remain speculative.
The final memo should fit the decision, not the politics around it. Include the capability boundary, strategic classification of each layer, intended user outcome, hard gates, scorecard, cost assumptions, evidence quality, operational owner, exit path, and re-evaluation triggers. Anyone reading it later should be able to tell why the decision was reasonable at the time and which changed condition would justify revisiting it.
Run an AI-specific risk and portability pass
AI changes more than development speed. It introduces movable models, probabilistic behavior, data-dependent quality, metered usage, and artifacts that can become strategically valuable. A normal software procurement checklist will miss several of these dependencies.
Data route: Document what enters the system, which service receives it, where it is stored, how long it is retained, whether it can be used for training, how deletion works, and whether residency requirements apply. Include prompts, retrieved context, generated output, user feedback, and operational logs.
Model and quality governance: Require a way to identify the model, configuration, prompt, retrieval state, and policy version associated with important behavior. Decide who maintains evaluation cases, reviews regressions, investigates failures, and approves consequential changes.
Security and privacy: Verify role-based access, audit logs, PII handling, privacy-by-design controls, threat detection and response, and the vendor’s red-team and incident practices. For an internal build, require equally concrete evidence rather than assuming control equals safety.
Portability: Establish ownership and export mechanisms for source data, metadata, prompts, policies, evaluation sets, feedback, transcripts, and relevant logs. Treat a contractual right to export and a technically usable export as separate requirements.
Unit economics: Map every metered event in the actual workflow. Per-seat pricing, consumption charges, model usage, and orchestration can behave differently as adoption and workflow complexity grow. Test the economic model against expected and stressed usage.
Operational responsibility: Specify who diagnoses a failure that crosses your application, the vendor platform, a model provider, and a data source. Shared architecture does not remove accountability; it makes the handoffs more important.
Portability deserves an actual exit test. Ask the vendor to produce a representative export before the contract is final. Confirm its format, completeness, permission model, and usefulness in another environment. An export button is not evidence that you can reconstruct the product behavior that matters.
Prompts require the same caution. Access to prompt text is necessary, but equivalent behavior may still depend on a model, tool interface, retrieval implementation, or vendor-specific orchestration. Preserve the intent, policies, evaluation cases, and expected outcomes around a prompt, not just the string itself.
Embeddings can also create false confidence about portability. Preserve the original content, chunking inputs, metadata, permission relationships, and evaluation set so embeddings can be regenerated if the model or retrieval system changes. The derived vectors alone are not a complete migration asset.
For vendors, negotiate transparent API quotas, usable sandbox environments, data-export terms, growth price protections, and clear ownership of AI artifacts. Pressure-test the roadmap against your deployment cadence and ask how incidents, breaking changes, and model transitions are communicated. For an internal build, apply the same rigor to service levels, incident response, observability, model lineage, retention, and ongoing staffing.
Buying does not outsource your responsibility for the product’s behavior. Building does not prove that the behavior is controlled. Choose the implementation that can produce the evidence your risk level demands within the launch window.
Make a staged commitment with explicit re-evaluation triggers
A build-versus-buy decision does not need to be permanent to be disciplined. When uncertainty is high and speed matters, a bounded purchase can be a learning instrument. When differentiation or control is already clear, a minimum lovable internal slice can establish the core while purchased components accelerate everything around it.
For a buy-to-learn path, use this sequence:
Name the uncertainty. Decide whether you are testing demand, workflow fit, quality, integration feasibility, adoption, operational burden, or economics. Do not call a general implementation a pilot.
Bound the commitment. Limit initial scope, data exposure, coupling, and custom vendor work to what the learning objective requires. Preserve an adapter or interface where replacement would otherwise become expensive.
Instrument the outcome. Track whether intended users activate, return, complete the workflow, accept the output, escalate to a human, and create operational work. Monitor consumption and connector reliability alongside product use.
Review against prewritten triggers. Deepen the vendor integration if adoption is durable, economics remain acceptable, and integration pain is manageable. Move toward building if unique requirements emerge, strategic artifacts accumulate, vendor constraints block the roadmap, or costs reach the agreed inflection point. Stop if the user outcome does not materialize.
This approach works because a purchased solution can validate value before a deeper build commitment. The learning is reusable only if you retain the data model, evaluation evidence, workflow understanding, and user-behavior insight rather than burying them inside vendor-specific configuration.
For a build-to-differentiate path, keep the first scope narrow. Build the smallest end-to-end experience that proves the differentiating hypothesis. Buy mature infrastructure around it where doing so does not surrender the key data, policy, or product behavior. Isolate components behind explicit interfaces so a model, orchestration service, retrieval system, or observability layer can change without rewriting the entire experience.
Set re-evaluation triggers before launch, while nobody is defending a sunk decision:
Product trigger: Usage fails to become durable, or customers reveal a need that the current option cannot support.
Financial trigger: Consumption pricing, operating cost, or internal staffing moves outside the approved economic envelope.
Technical trigger: Integration maintenance, API limits, reliability, or roadmap mismatch begins delaying important releases.
Risk trigger: Data handling, retention, auditability, model governance, or regulatory obligations can no longer be met.
Strategic trigger: A previously generic layer begins creating proprietary data, workflow advantage, or meaningful differentiation.
Capacity trigger: The internal team can no longer sustain the operational burden, or gains the maturity needed to own a capability previously bought.
Assign an owner and a review event to each trigger. Without ownership, continuous re-evaluation becomes a good intention that loses to roadmap pressure. The decision memo should remain a living control surface for product, engineering, finance, security, and procurement, not an artifact filed after approval.
Do not neglect activation. Whether you build or buy, budget for workflow changes, onboarding, in-app guidance, support preparation, and measurement. Deployment creates availability. Repeated successful use creates value.
Key takeaways
Decompose an AI experience into layers before deciding who should own it.
Build differentiated or control-critical layers; buy parity where a vendor can accelerate activated value.
Compare both choices across time to value and total ownership cost using the same scope and service expectations.
Apply non-negotiable gates before a weighted scorecard, then test both options against common acceptance cases.
Own the data, policies, evaluation evidence, and migration path that protect your future leverage.
Use staged commitments and prewritten triggers so changing the decision becomes responsible management, not an admission of failure.
The next time this question reaches your roadmap review, do not ask for a permanent verdict on build or buy. Ask for a capability map, comparable evidence, an operational owner, a tested exit path, and the conditions that would change the answer. That gives you a decision you can defend now without mortgaging your ability to adapt later.
You probably do not have an AI ideas problem. You have a conversion problem. Promising prototypes appear across the company, but few survive the distance between a convincing demo and a dependable customer or business outcome.
The way out is to stop treating AI transformation as a feature portfolio. Treat it as a redesign of how your organization senses problems, makes decisions, takes safe action, and learns from production. The practical unit of change is one closed loop with an accountable owner, trusted context, explicit guardrails, and measurable results.
Key takeaways: the transformation system in brief
Start with a bounded customer or employee workflow, not a company-wide AI program or a preferred model.
Define the outcome, quality threshold, action boundary, and fallback before choosing the implementation.
Build capabilities in dependency order: governed data, grounded context, constrained workflows, task-specific evaluations, and production operations.
Measure customer outcomes, AI behavior, delivery reliability, and organizational learning separately. No single metric can represent all four.
Centralize reusable controls and infrastructure, but keep problem selection and outcome ownership inside the domain team.
Increase autonomy only after the system can detect failure, escalate uncertainty, limit permissions, and recover safely.
Start with a transformation wedge, not a transformation program
A broad mandate such as make every team AI-first sounds ambitious but gives teams no useful decision rule. It encourages tool adoption, disconnected pilots, and activity metrics. A narrower mandate forces the hard questions into the open.
I call that narrower unit a transformation wedge: a bounded, repeatable moment where intelligence can remove meaningful friction, where the result can be observed, and where a safe fallback already exists. The wedge is small enough to govern but important enough to prove a new organizational capability.
Use these gates when selecting it:
Meaningful friction: A customer or employee is losing time, making avoidable errors, or failing to complete an important job.
Observable outcome: You can instrument the desired behavior rather than relying on opinions about output quality.
Available context: The system can reach sufficiently trusted information without placing sensitive data into an uncontrolled context.
Repeatable demand: The workflow occurs often enough to produce learning that the team can use.
Bounded consequence: The system can be constrained, reviewed, escalated, or reversed when confidence is inadequate.
Reusable learning: At least one capability – such as retrieval, evaluation, telemetry, or an integration – can support the next workflow.
This distinction changes the conversation. Add a support chatbot is an implementation idea. Reduce the time to an accurate support resolution while preserving policy adherence is a transformation wedge. The second framing leaves room to choose retrieval, workflow automation, agentic behavior, or a simpler interface based on evidence.
Write the outcome contract before selecting a model
For the selected wedge, create a short outcome contract. It should be understandable to product, engineering, design, operations, security, and the executive sponsor without translation.
User and moment: Who encounters the friction, and at what point in the workflow?
Current behavior: What happens without the AI intervention, and what baseline evidence is available?
Primary outcome: Which customer or business behavior should change?
Quality guardrails: Which failure measures must remain within an agreed boundary?
Trusted context: Which data may be used, who owns it, and which sensitive fields must be removed or protected?
Action boundary: May the system summarize, recommend, communicate, or execute? Name prohibited actions explicitly.
Fallback: What happens when evidence is missing, the model is uncertain, an integration fails, or a policy conflict appears?
Release evidence: Which offline evaluations, controlled experiments, and production signals will justify expansion?
Accountability: Who owns the outcome, the AI behavior, the data, and incident decisions?
In a support workflow, for example, the contract might pair a resolution outcome with accuracy and policy-adherence guardrails. A retrieval-first path can ground the response in approved knowledge, while a defined escalation route gives the system somewhere safe to send ambiguity. That combination of grounding, constrained action, evaluation, and escalation is much more consequential than the choice of chat interface.
Instrument the baseline and the intervention from the beginning. If telemetry arrives after launch, the team will be able to show that an AI feature shipped but not whether the targeted behavior improved.
Build the capability stack and the product loop together
Teams often start in the middle of the stack: they select a model, write prompts, and then discover that the data is unreliable, evaluation is subjective, or production failures have no owner. Model capability matters, but it cannot compensate for missing organizational capability.
Build the stack in dependency order:
Governed data: Identify approved data, access rules, sensitive fields, and accountable owners. Privacy-by-design belongs in the workflow definition, not in a review added before release.
Trusted context: When the task depends on company or customer knowledge, retrieve the relevant context from approved systems and control what enters the model’s context window. Define what the system should do when evidence is incomplete or conflicting.
Constrained workflow: Separate model judgment from deterministic operations. Give each integration an explicit purpose, permission boundary, failure path, and audit trail. Agentic AI should orchestrate only the actions the organization is prepared to observe and govern.
Task-specific evaluation: Build scenarios from the real workflow. Include expected cases, ambiguous inputs, missing context, policy conflicts, and known high-consequence failures. Define acceptance criteria before comparing prompts, models, or vendors.
Release and operations: Use feature flags, controlled rollout, production telemetry, threat detection, and incident management. Assign authority to pause or limit the system when behavior drifts.
This order is not a waterfall. Retrieval quality may expose a data problem, while an evaluation failure may expose a poorly defined policy. The point is to preserve the dependencies: autonomous action cannot become dependable before context, evaluation, permissions, and operations exist.
Use AI to expand options and evidence to make commitments
The capability stack changes day-to-day product work only when it is connected to discovery, design, delivery, and adoption. The useful pattern is to let AI accelerate reversible exploration while keeping consequential decisions anchored in evidence.
Discovery: Use AI to cluster interview notes, support tickets, and session transcripts. Then inspect the underlying material and pressure-test important themes with live customer conversations. A fluent summary is a hypothesis generator, not customer validation.
Design: Generate several storyboards, interaction flows, or guidance variants early. Refine promising options through the design system, accessibility requirements, and human review rather than treating the first plausible generation as finished design.
Delivery: Use AI to prepare hypotheses, test cases, and experiment materials. Keep success metrics and the minimum detectable effect explicit, and release variants through feature flags so that speed does not erase experimental discipline.
Adoption: Generate targeted in-app guidance, release it to controlled segments, and measure activation and retention alongside the immediate interaction. Shipping the intelligent behavior and helping users adopt it are parts of the same product decision.
Replace status review with a weekly learning review
Whether the accountable unit is called a product trio or something else, give it a weekly operating rhythm focused on verified learning. A useful agenda is:
Review the primary outcome and every guardrail, including meaningful segment differences.
Inspect evaluation failures and trace them to context, model behavior, policy, workflow design, or integration behavior.
Read the latest experiment evidence and distinguish a result from an interpretation.
Review reliability changes, incidents, near misses, and unresolved escalation paths.
Make an explicit decision to continue, change, limit, or stop the current approach, with an owner for the next piece of evidence.
Do not let this become a prompt-tuning meeting. Prompt changes are only one possible response. A retrieval defect, unclear product policy, missing event, weak handoff, or badly chosen outcome may be the actual constraint.
Use a metric chain instead of one AI success number
AI pilots look healthy when they are measured by output: drafts generated, tasks attempted, people trained, or features shipped. Those numbers can describe activity, but they do not establish customer value, dependable behavior, or organizational readiness.
A transformation scorecard needs separate layers because each answers a different management question:
Measurement layer
Question it answers
Useful measures
Customer and business outcome
Did the important behavior improve?
User activation, time-to-first-value, support resolution rate or time, retention
AI quality and safety
Is the intelligent behavior reliable enough for this workflow?
Can the team improve the system quickly without destabilizing it?
Deployment frequency, lead time, change failure rate, mean time to recovery
Organizational learning
Is the organization reaching better decisions faster?
Cycle time, experiment throughput, decision quality against predefined evidence
The metric names are not definitions. Make each operational for the selected workflow. Accuracy might mean correct support answers, successful tool completion, or correct classification; those are different tests. A hallucination rate needs a declared denominator and a rule for what counts as unsupported. Decision quality needs a rubric tied to the evidence available when the decision was made, not whether the result later happened to be favorable.
Connect the layers as a metric chain. In grounded support, retrieval and response evaluations establish whether the system can produce an accurate answer. Product telemetry shows whether the customer receives a useful resolution or an appropriate escalation. Resolution and retention measures show whether that behavior matters to the business. Delivery and learning measures show whether the organization can improve the loop repeatedly.
Interpret disagreement between the layers
The disagreements are often more informative than the headline result:
If offline evaluations improve but customer behavior does not, inspect workflow placement, user trust, adoption, and whether the evaluated task matches the real job.
If customer outcomes improve while policy adherence deteriorates, do not expand the rollout. The apparent win is being financed by unmanaged risk.
If deployment frequency rises while change failure rate or recovery time worsens, the team has increased release activity rather than adaptive capacity.
If cycle time falls but decisions are repeatedly reversed for missing evidence, the system is producing faster motion, not better learning.
If averages look healthy but a target segment fails, keep the rollout segmented until the failure mechanism is understood.
Use the right method for the question. Evaluations test whether AI behavior meets defined quality and safety criteria. A/B testing tests whether a product intervention changes user behavior; setting the hypothesis, success metric, and minimum detectable effect before reading results protects that inference. DORA metrics reveal the health of the delivery system. None is a substitute for the others. Connecting model, product, business, and delivery measures is what turns telemetry into an operating mechanism.
Centralize guardrails and distribute outcome ownership
Organizational design usually fails at one of two extremes. A central AI group becomes a queue that is distant from customer problems, or every team builds its own prompts, data paths, evaluations, and incident process. The useful split is to centralize scarce controls and reusable capabilities while distributing domain decisions.
Centralize the capabilities that should not be reinvented
Approved data-access and privacy patterns
Retrieval, context-management, and model-routing components
Evaluation tooling, baseline scenarios, and reporting conventions
Observability, auditability, feature-flag, and incident-response patterns
Prompt and workflow libraries with named owners and change history
Security, regulatory, and procurement requirements
Keep product judgment inside the domain
Choosing the customer or employee problem
Defining the outcome and acceptable trade-offs
Validating whether retrieved context represents the domain correctly
Designing the experience, fallback, and human handoff
Running controlled rollout and interpreting segment behavior
Deciding whether to continue, constrain, redesign, or stop the bet
This division preserves empowered product teams without turning governance into optional advice. The central capability owner defines the safe road; the domain team remains accountable for choosing the destination and proving that it is worth reaching.
Scale controls with the consequence of being wrong
Do not use one approval process for every workflow. A drafting assistant and an agent that changes customer records do not create the same exposure. Classify a workflow by what it can do and what happens when it fails.
Advisory output: A person reviews the draft, summary, or analysis before it affects another party. Evaluate usefulness and factual reliability, and make the reviewer accountable for the final decision.
User-facing recommendation: The output reaches a customer or employee directly. Add grounding, policy tests, clear escalation, monitored rollout, and an accessible non-AI path.
Action-taking workflow: The system invokes tools or changes state. Limit permissions, constrain eligible actions, preserve an audit trail, test integration failures, and provide a reliable stop or recovery path.
Sensitive or regulated workflow: Add the relevant privacy, security, legal, and compliance owners before data or actions enter the system. If an approved path does not exist, keep the workflow out of production until it does.
A human in the loop is not a complete control by itself. Name what the person must inspect, what evidence is visible, when escalation is mandatory, and whether the person has enough time and authority to intervene. Otherwise, the human becomes ceremonial approval around an automated decision.
Redesign roles around judgment, not tool usage
AI can accelerate exploration, synthesis, and test preparation. People still have to interpret customers, choose outcomes, set quality thresholds, resolve policy ambiguity, and accept accountability for consequences. Role design and hiring should reflect that boundary.
A product manager should be able to write the outcome contract, connect model behavior to user behavior, and make trade-offs visible.
A designer should be able to generate and interrogate alternatives, preserve accessibility, and design uncertainty and fallback states.
An engineer should be able to separate probabilistic behavior from deterministic operations and build evaluation, observability, permission, and recovery paths.
A leader should be able to fund reusable capability, challenge vanity metrics, and stop a persuasive demo that lacks production evidence.
Use communities of practice to spread prompt patterns, evaluation baselines, reusable workflows, and failure lessons. They work best as distribution networks for repeatable product and evaluation practices, not as committees that absorb accountability from the teams shipping the work.
At your next portfolio review, select one transformation wedge and require its outcome contract, metric chain, evaluation set, fallback, and named owners. Put it into the weekly learning rhythm before funding another disconnected pilot. Once the loop works in production, extract the reusable components and make the next team faster. That is the point at which AI stops being a collection of features and starts changing how the organization operates.
Your support dashboard is green: agents answer quickly, resolution times are improving, and more requests are being deflected. Yet activation is flat, customers still struggle with the same workflow, and nobody can say whether the support motion changed product behavior.
That mismatch is a measurement problem and a governance problem. You need a controlled line of sight from customer friction to agent activity, product progress, business impact, and trust. The goal is not to collect more interaction data. It is to collect the minimum evidence required to make a specific decision, give the right people access to it, and scale only when support and adoption improve without weakening privacy or compliance.
Define one chain from support friction to product outcome
Agent performance is not an end state. A fast response can still leave the customer stuck. A short resolution time can reflect a solved problem, a prematurely closed case, or a workaround that never addresses the product friction. Deflection can reduce queue volume without proving that the customer completed the task.
Onboarding step, workflow attempt, segment, repeated help request
Fix the workflow, improve guidance, or change support coverage
Support execution
How did the support motion respond?
First-response time, time-to-resolution, deflection, agent activity
Change coaching, routing, knowledge, or intervention timing
Product response
Did the customer make meaningful progress?
Onboarding progress, user activation, time-to-value, feature usage depth
Keep, revise, or remove the intervention
Durable outcome
Did the improvement persist and create value?
Retention, support demand, cost-to-serve, customer satisfaction
Scale the pattern, continue testing, or stop
Write the intended decision before choosing the dashboard. A good decision statement looks like this:
For this customer segment, decide whether to scale, revise, or remove this support or in-product intervention based on a named product outcome, an operational outcome, and a trust guardrail.
The segment matters. An overall improvement can hide a poor experience for new customers, complex accounts, or users attempting a particular workflow. Define the eligible population before reading the result. Do not create segments after seeing the data merely to find a favorable story.
The denominator matters too. Raw ticket volume is difficult to interpret when the active customer base or number of workflow attempts changes. Normalize support demand against the relevant opportunity: active accounts, eligible users, onboarding starts, or workflow attempts. Use the denominator that matches the decision, and keep it consistent across the baseline and pilot.
Give every metric a definition sheet. Record its unit, numerator, denominator, start and stop events, exclusions, segment rules, data owner, and refresh cadence. Define activation as the first meaningful value event for your product, not as any login or page view. Define resolution using an actual workflow state rather than a convenient reporting label. If two teams calculate the same metric differently, the governance failure has already started.
Put every metric inside a governance contract
Governance cannot be a security review added after instrumentation. It has to shape what you collect, why you collect it, who can inspect it, and when it disappears. Before implementing an event or joining support data to product data, complete a measurement contract with the following fields:
Decision: the product, support, or risk decision this data will change.
Purpose: the allowed use of the data and any explicitly disallowed secondary uses.
Minimum telemetry: the smallest set of events, timestamps, outcome states, and segment attributes required for the decision.
Unit of analysis: user, account, workflow attempt, support case, or another clearly defined entity.
Identity handling: the join key, its sensitivity, and whether aggregated or pseudonymous data can answer the question.
Access: the roles permitted to view aggregate data, interaction-level data, and customer-identifying fields.
Retention and deletion: how long each data class remains available and how deletion obligations will be executed.
Consent and regulatory review: the consent state and jurisdictional requirements that security and legal must validate.
Audit and incident path: what gets logged, who reviews exceptions, and what happens if a control fails.
Owner: the person accountable for data quality, the decision, and retirement of telemetry that no longer has a valid purpose.
Conversation content deserves particular care. If timestamps, workflow identifiers, intervention exposure, and outcome states can answer the question, do not ingest raw messages merely because they are available. If content is genuinely necessary for quality analysis, document that need, restrict interaction-level access, define its retention separately, and prevent it from becoming a general-purpose data set.
Use aggregate reporting as the normal operating view. Grant access to individual interactions only when a defined task requires it, such as approved quality review or incident investigation. Role-based access is not a substitute for minimization: authorized people can still be given more customer data than their work requires.
Keep a data map that shows where each event originates, which identifier connects it to other systems, where it is stored, which vendor processes it, who can access it, and how deletion propagates. Complete vendor risk assessment and a data protection impact assessment where appropriate. Product leaders should not infer compliance from a platform default; security and legal need to validate consent, retention, and regulatory requirements for the actual implementation.
Your scorecard should carry trust measures beside business measures. Track access exceptions, unresolved audit findings, retention failures, consent-state mismatches, and open incidents alongside activation, retention, support demand, and cost-to-serve. A business result does not cancel a failed control. If a pilot improves adoption while violating an agreed privacy boundary, pause expansion and remediate the control before exposing more customers or data.
Test interventions without mistaking correlation for impact
A dashboard can show that customers who used a guide activated more often. It cannot, by itself, show that the guide caused the difference. Those customers may have been more motivated, more experienced, or already closer to activation.
Use a narrow pilot to separate plausible impact from convenient correlation. The test should begin at one documented friction point, for one eligible population, with one intervention and one primary product outcome. In-app guides, product tours, contextual tooltips, support coaching, and knowledge changes are different interventions. Do not bundle them into the same treatment if you need to know which one worked.
Select a friction point that can be observed in the product journey, such as failure to complete a complex workflow or stalled onboarding progress.
Capture a baseline using the same metric definitions, eligibility rules, and denominators that will be used during the pilot.
State the mechanism. Explain how the intervention should reduce effort or confusion and which customer behavior should change if that explanation is right.
Define the assignment unit. Use the account rather than the individual user when people in the same account could share the intervention or influence one another.
Choose a primary product outcome, a supporting operational outcome, and trust guardrails before looking at results.
Use randomized A/B assignment when it is feasible. When it is not, use a comparable cohort and state clearly that unmeasured differences may explain part of the result.
Predefine the decision rule for scaling, revising, or stopping. Include a stop condition for failed privacy, access, retention, or incident controls.
A practical test can instrument guidance for a difficult workflow and compare eligible cohorts on activation, retention, and support ticket volume. Add first-response or resolution time when the intervention is expected to change agent workload. Add feature usage depth when completion alone does not show whether customers adopted the workflow meaningfully.
Do not use guide engagement as the primary success metric. Opening a tour or clicking a tooltip proves exposure, not value. Treat engagement as a diagnostic signal that helps explain the outcome. If engagement rises while activation remains flat, the intervention attracted attention without moving the customer forward.
A pilot brief you can copy
Decision: Should this intervention be scaled for the eligible segment?
Friction point: Which product step is failing, and how is failure observed?
Population: Who is eligible, who is excluded, and what is the assignment unit?
Intervention: What changes for the treatment group, and what remains unchanged?
Primary outcome: Which activation, onboarding, time-to-value, or feature-depth measure represents customer progress?
Operational outcome: Which response, resolution, deflection, or support-demand measure should move?
Trust guardrails: Which consent, access, retention, audit, and incident conditions must remain satisfied?
Evidence rule: What predeclared material change would justify scale, revision, or termination?
Owner and review: Who makes the decision, and when will the evidence be reviewed?
Read product and support outcomes together. If resolution time improves but activation does not, you probably have an operational improvement rather than evidence that the product friction disappeared. If activation improves while support demand remains unchanged, the intervention may create customer value without reducing cost-to-serve. If both improve but a trust guardrail fails, the correct decision is to pause scale. The purpose of the experiment is to expose these tradeoffs, not compress them into one composite score.
Run a weekly decision review and scale through gates
Agent analytics becomes useful when it produces a repeatable operating decision. Review outcomes weekly during an active pilot, but do not turn the meeting into a tour of charts. Start with the previous decision, inspect what changed, and finish with a new decision, owner, and follow-up date.
Validate the evidence. Check instrumentation changes, missing events, denominator shifts, assignment integrity, and segment mix before interpreting movement.
Read the primary product outcome by the predefined eligible population and important segments.
Inspect operational outcomes to determine whether the intervention reduced effort or merely moved it between the customer, the product, and the support queue.
Review trust controls, including access exceptions, retention execution, consent handling, audit findings, and incidents.
Record one decision: scale, revise, continue collecting evidence, diagnose a measurement problem, or stop.
Do not let an overall average decide the rollout. A guide can help new users and distract experienced ones. A support change can improve a common workflow while degrading a complex segment. Review the segments chosen before the pilot, then decide whether the intervention needs targeted delivery instead of universal exposure.
Require every proposed expansion to pass distinct gates:
Measurement gate: the events, definitions, eligibility logic, and joins are reliable enough to support the decision.
Outcome gate: the primary product measure clears the material threshold declared before analysis.
Operational gate: support performance improves or remains acceptable without shifting unreasonable effort to the customer or another team.
Passing one gate never compensates for failing another. Strong activation does not excuse an access-control failure. Faster resolution does not establish durable adoption. Clean governance does not make an ineffective intervention worth scaling.
Assign ownership at the decision level. Product owns the customer outcome, causal hypothesis, and intervention choice. Support operations owns operational definitions and changes to coaching or workflow. Data owners maintain instrumentation, cohorts, and metric quality. Security and legal define the applicable control criteria. Put the final decision and its evidence in a durable log so later teams can see why an intervention was scaled, limited, revised, or retired.
Retire telemetry as deliberately as you launch it. If a metric no longer informs a live decision, confirm whether another approved purpose still requires it. If not, remove the collection path and apply the retention policy. Unused data creates continuing governance obligations without creating product value.
Key takeaways
Measure a chain from customer friction through agent activity to activation, feature use, retention, and support demand. Do not treat queue efficiency as proof of adoption.
Normalize support metrics using the opportunity that created the demand, and define every numerator, denominator, event boundary, exclusion, and segment before the pilot.
Attach purpose, minimum telemetry, identity handling, role-based access, retention, consent review, auditability, incident response, and ownership to every measurement decision.
Test one intervention at one friction point with a predefined product outcome, operational outcome, trust guardrails, and decision rule.
Scale only after the measurement, outcome, operational, and trust gates all pass. A favorable business metric cannot offset a failed control.
Your next move is to choose one recurring support friction point and write its measurement contract before adding another dashboard. Map the customer behavior, agent signal, product outcome, operational outcome, and trust guardrail on a single page. That narrow decision loop will show you which telemetry is necessary, which access is justified, and what evidence must exist before you scale.
Your dashboard can show growing AI agent usage while the product itself gets worse. Users may invoke the agent, wait for an answer, rewrite it, repeat the task manually, or discover too late that an action needs to be undone. An invocation count records activity. It does not tell you whether the agent was useful, safe, or worthy of more authority.
If you own an agent roadmap, the practical question is not whether the model can complete an impressive demo. It is whether you can see what the agent did, limit what it was allowed to do, connect its behavior to a user or business outcome, and stop or reverse a bad release. Product analytics should be the control system that helps you answer those questions.
Key takeaways
Define the agent’s job, eligible users, data boundary, action boundary, target outcome, and failure conditions before choosing dashboard metrics.
Join product behavior, agent decisions, tool activity, and business outcomes with shared run and workflow identifiers. A model trace or product funnel on its own is incomplete.
Treat permissions as product logic. Read access, recommendations, reversible actions, and high-consequence actions need different controls and evidence.
Version prompts, retrieval sources, models, tools, policies, and event schemas together so that a change in performance can be traced to a release.
Use quality, safety, experience, business, and operational gates to decide whether an agent should expand, remain constrained, be revised, or be retired.
Define the outcome and authority before the events
Teams often start by instrumenting what is easiest to count: conversations, messages, tool calls, and thumbs-up feedback. That produces a busy dashboard without a decision model. Start one level earlier. What job is the agent responsible for, and what evidence would justify giving it more reach or authority?
Write a one-page agent contract
An agent contract is a product artifact, not a legal document. It creates a stable reference for instrumentation, evaluation, access control, and rollout decisions. Write down:
Job: the decision or task the agent helps complete. Avoid broad mandates such as improve support or assist product managers.
Eligible workflow: the exact point at which the agent may appear or run. Eligibility must be measurable even when the user never invokes the agent.
Eligible users and accounts: the roles, segments, or environments included in the release, plus explicit exclusions.
Inputs: the approved resources, fields, retrieval collections, and user-provided context the agent may inspect.
Outputs: whether the agent answers, recommends, drafts, updates a system, contacts someone, or triggers another workflow.
Human checkpoints: the actions that require review, the person authorized to review them, and what that person must be shown.
Target outcome: the user or business result, its denominator, its measurement window, and the system that records it.
Known failure states: unsupported answers, irrelevant retrieval, repeated retries, blocked tools, abandoned approvals, incorrect actions, and failed handoffs.
Stop condition: the quality, risk, reliability, or outcome signal that pauses the rollout and identifies who owns the decision.
The eligibility definition matters more than it appears. If you count only people who chose to use the agent, your dashboard excludes people who ignored it, did not notice it, distrusted it, or could not access it. Record the eligible population first. That gives adoption, completion, and outcome metrics a defensible denominator.
Keep the first contract narrow. A practical starting footprint is one valuable question, a small team, and one assistant. Narrow scope is not merely easier to ship. It makes failures interpretable and limits the consequences of a bad policy, prompt, connector, or event definition.
Translate authority into enforceable policy
I use a strict definition of governance: the agent has a bounded objective, a known identity, limited data access, limited tools, recorded policy decisions, an escalation route, and a named owner. A policy page that the runtime cannot enforce is guidance, not governance.
Authority level
What the agent may do
Evidence to retain
Default release control
Retrieve
Read approved analytics, records, or knowledge without changing a system
Resource identifiers, applied scope, retrieval status, policy version, and references used
Pre-approved resources with least-privilege access and data minimization
Recommend
Explain, summarize, rank, draft, or propose an action
Agent version, supporting references, presentation status, and user response
The user decides whether to accept, edit, reject, or escalate
Act reversibly
Create a note or make another bounded change that can be reliably undone
Tool, target, before-and-after state, approval, execution result, and reversal path
Explicit approval during the bounded rollout, followed by evidence-based expansion
Act with high consequence
Send an external communication, alter access or entitlements, disclose sensitive data, or perform a hard-to-reverse operation
Everything above, plus approver identity, policy result, purpose, and incident linkage
A human makes the consequential decision; eligibility and tool scope remain narrow
Technical reversibility is not the same as consequence reversibility. A database field may be restored while a customer message, exposed record, or lost trust cannot be recalled. Classify authority by the real-world consequence, not by whether an API offers an undo method.
Model Context Protocol can make the policy surface clearer because it separates read-only resources from bounded tools and gives agents a standard way to discover them. That interface is useful, but the protocol does not decide who should access a resource, which fields are permitted, or whether an action needs approval. Authentication, authorization, redaction, policy enforcement, retention, and audit logging still belong in your architecture.
Apply controls before the model call and again before every tool execution. Prompts, retrieved context, logs, and third-party services can all become paths for sensitive-data leakage. Redact data the task does not require, keep secrets outside prompts, use scoped credentials, validate structured tool inputs, and record blocked requests as carefully as successful ones. A denied request is evidence that your policy worked, but repeated denials may also reveal a broken workflow, an overly broad prompt, or an attempted attack.
Build telemetry that joins agent decisions to user outcomes
Product analytics and AI observability answer different halves of the same question. A trace can show which context was retrieved, which policy ran, and which tool was called. Product analytics can show what the user did before and after the interaction, which cohort they belonged to, and whether the workflow reached its intended result. Neither view alone proves that the agent created value.
Join them with two identifiers. An agent run identifier follows one execution from trigger to final status. A workflow identifier connects that execution to the broader task, including manual steps, retries, handoffs, and the eventual business outcome. A user may start several runs inside one workflow, so treating every run as an independent success will inflate apparent demand and hide rework.
Use a minimum viable event contract
The following event model is deliberately small. Adapt the names to your analytics conventions, but preserve the states and identifiers.
Suggested event
Required properties
Decision it supports
agent_eligible
Workflow identifier, use case, surface, cohort, eligibility reason, and policy version
Who could have used the agent, including people who did not invoke it?
agent_run_started
Run identifier, workflow identifier, agent version, entry point, and initiating actor type
Where is the agent being invoked, and how often do workflows require retries?
agent_answer_presented
Run identifier, answer status, retrieval status, reference status, latency band, and fallback status
Did the user receive a grounded answer, a fallback, or no usable response?
agent_action_requested
Run identifier, tool, target type, authority level, required scope, approval requirement, and policy result
What is the agent attempting, and where are requests blocked or escalated?
agent_action_finished
Run identifier, tool, execution status, error class, approver state, reversibility state, and duration band
Did an approved action actually complete, fail, time out, or require recovery?
agent_handoff_started
Run identifier, workflow identifier, handoff reason, destination, context-transfer status, and user choice
Why did automation stop, and could the receiving person continue without reconstructing the task?
agent_run_outcome
Run identifier, workflow identifier, completion state, user response, correction state, and failure taxonomy
Was the output accepted, edited, rejected, abandoned, retried, or escalated?
workflow_outcome
Workflow identifier, outcome name, outcome state, measurement window, and source system
Did the underlying product or business result occur?
Put the agent, model, prompt, retrieval, tool, policy, and event-schema versions on the relevant records. Without version lineage, a quality shift produces debate instead of diagnosis. You will know that performance changed but not whether the cause was a prompt edit, a new model, a retrieval update, a permission change, a tool release, or broken instrumentation.
Do not make raw prompts and complete responses the default payload in a general-purpose analytics tool. They can contain personal data, secrets, customer content, or retrieved text that the analytics audience should not see. Send structured classifications and reference identifiers to product analytics. Keep any detailed trace required for investigation in an access-controlled store with explicit retention rules.
Use enumerated properties for states such as accepted, edited, rejected, blocked, failed, and handed off. Free-text status fields fragment quickly and make reliable cohorts impossible. Preserve a limited diagnostic field only where someone owns its review and classification.
Measure a stack, not a vanity metric
A useful scorecard separates five layers. Each layer answers a different management question:
Reach and adoption: Of eligible workflows, where was the agent offered and invoked? This shows discoverability and voluntary use, not value.
Task experience: Of started workflows, how many completed, retried, fell back, transferred to a person, or were abandoned? Segment edits and overrides instead of treating every acceptance as equally successful.
Agent quality: Was the answer supported by approved context, relevant to the request, structurally valid, and consistent with the task-specific evaluation criteria?
Governance and safety: Which tool requests were allowed, denied, escalated, or attempted outside the approved scope? Which redaction, moderation, or policy checks failed?
Business outcome: Did the downstream result move for the eligible workflow and intended cohort? Examples include completed onboarding, resolved cases, qualified leads, retained users, or a shorter cycle, depending on the contract.
Always display the numerator and denominator behind a rate. A falling handoff rate may look positive until you discover that completions also fell. A high acceptance rate may hide repeated runs if the dashboard counts only the final answer. A rising task outcome may reflect a changing user mix rather than the agent. Cohort, version, eligibility, and workflow-level views prevent those misreadings.
Behavioral analytics can establish association and expose where to investigate. It does not automatically establish causality. When the decision requires a causal claim, use a controlled experiment only after both variants meet the same safety and access requirements. Prompts, decision rules, and handoff designs can be tested across appropriate user cohorts; known unsafe behavior, privacy controls, and access boundaries are not experiment variants.
Turn analytics into release gates, not retrospective reporting
A governed agent release includes more than a prompt. It includes the model configuration, instructions, retrieval sources, tool definitions, permission scopes, policy rules, user disclosures, approval flow, handoff design, and telemetry. Change any of those and you have changed the product behavior.
That is why evaluation belongs in delivery, not in a quarterly review. Task-specific test sets, reference answers, error classifications, and pass-or-block thresholds can gate model and prompt changes in CI/CD. Production analytics then checks whether the behavior generalizes to real workflows without weakening the controls established before launch.
Use a staged promotion path
Validate the interface. Enumerate the resources, tools, schemas, scopes, and denial behavior. Run harmless requests and confirm that unavailable capabilities remain unavailable.
Run task evaluations. Test representative requests, known failure cases, adversarial inputs, missing context, malformed tool arguments, and handoff conditions. Classify failures by consequence rather than relying on one blended quality score.
Exercise the workflow without autonomous consequence. Use dry runs or recommendation-only behavior. Confirm telemetry, references, approvals, fallback, escalation, and rollback before enabling writes.
Release to a bounded eligible cohort. Keep tool scopes narrow and consequential actions under human control. Compare observed behavior with the contract, not with the enthusiasm generated by the demo.
Experiment inside the approved boundary. Test prompt, retrieval, interaction, and handoff variants only after they independently satisfy the safety gate. Analyze results by workflow and version.
Promote or constrain deliberately. Expand access or authority only when the relevant gates pass. A failed safety gate can restrict a release even when adoption or the business metric improves.
Pre-commit the gates
Choose thresholds and blocking conditions before reading the launch results. If the team sets them afterward, a promising outcome can quietly lower the quality bar, while a favored feature can turn every failure into an exception.
Gate
Evidence
Blocking condition
Typical response
Quality
Task evaluations, grounded-answer checks, correction categories, and unsupported-output reviews
A consequential failure class exceeds the pre-agreed tolerance or lacks a reliable detector
Revise instructions, retrieval, output constraints, or task scope
The workflow cannot meet its reliability requirement or cannot fail safely
Reduce dependency surface, improve fallback, or pause promotion
Do not average these gates into a single agent score. A composite score can let strong adoption cancel a serious security failure or let low latency hide poor answer quality. Keep each gate visible, assign its owner, and specify which failures block promotion without negotiation.
Release decisions should also be reversible. Keep prior prompt, policy, retrieval, and tool configurations identifiable. Define how the runtime disables a tool, narrows a cohort, returns to recommendation-only behavior, or routes directly to a person. A rollback plan that depends on diagnosing the root cause first is too slow for a live incident.
Make the dashboard an operating system for the product team
The best agent dashboard does not attempt to show every event. It puts the release decision in view. Organize it in the order the team should reason:
Outcome: eligible workflows, target business result, comparison group where appropriate, and results by cohort and release version.
Quality and trust: grounded status, acceptance, substantive edits, rejection, retries, corrections, fallback, and qualitative feedback categories.
Governance and operations: allowed and denied tools, approval states, out-of-scope attempts, redaction failures, incidents, errors, latency, and dependency health.
Every panel should filter by agent version, policy version, tool, entry point, cohort, and workflow outcome. A top-line average is useful for orientation, but releases fail in slices: a user role with missing permissions, a workflow with poor retrieval, a new policy that blocks a required tool, or a handoff destination that cannot use the transferred context.
Which intended outcome moved, for which eligible cohort, and under which release version?
Where did users retry, edit, reject, abandon, or request a person, and what does the failure taxonomy show?
Which permissions were never needed, and which denied requests reveal either a valid attack defense or a mismatch between the job and the available tools?
Did the agent reduce user work, or did it move that work into reviewing, correcting, approving, and recovering?
Are outcomes consistent across important roles and workflow entry points, or is the top-line result hiding a weak segment?
What changed since the prior release across the model, prompt, retrieval corpus, tools, policies, user experience, and instrumentation?
Should the team expand, hold, revise, restrict, roll back, or retire the current behavior?
Record the decision beside the release lineage: the hypothesis, eligible scope, versions, expected outcome, gates, observed evidence, known risks, owner, and next review condition. This turns governance into an operating history. It also prevents the same debate from restarting when a metric moves or a stakeholder changes.
Ownership must be explicit. Product owns the job, intended outcome, and promotion decision. Engineering owns runtime reliability, tool boundaries, traceability, and rollback mechanics. Design owns disclosure, user control, approval clarity, correction, and handoff. Data or analytics owns event integrity and metric definitions. Security and legal own the policies and incident requirements within their mandates. Shared input is valuable; shared accountability without a decision owner is not.
Start with one consequential workflow. Write its contract, add the eligibility event and shared identifiers, classify every available tool by authority, pre-commit the release gates, and review the first bounded cohort against the business outcome. Do not broaden the agent until you can explain why it ran, what it was permitted to see and do, what the user did next, whether the workflow improved, and how you would stop it safely.
You have Web Vitals in a dashboard, but the hard question is still unanswered: does a slower or less stable experience materially change activation, conversion, or retention? If your instrumentation cannot answer that, collecting more performance data will only make the dashboard busier.
The useful setup is not simply Browser SDK plus LCP, INP, and CLS. It is a measurement system that preserves the user’s real experience, attaches enough product context to explain the result, and connects performance to an outcome your team can improve.
Build the measurement contract before the dashboard
Start with the decision you want to make. A good Web Vitals implementation should tell you which experience is degraded, who encounters it, whether it is associated with a meaningful product outcome, and which intervention deserves engineering time.
I would use one normalized event, such as web_vital_observed, rather than inventing event names for every metric and route. The metric, value, page context, and audience context then become properties. That keeps the taxonomy manageable while preserving the dimensions needed for analysis.
Retain the raw measurement
Record LCP, INP, and CLS as distinct metric names with their raw values and units. LCP and INP are timing measures, while CLS represents visual stability, so combining their values in one aggregate would be meaningless. A separate metric-name property lets one event schema support all three without pretending that they are interchangeable.
Do not put labels such as good, acceptable, or poor into the event name. If you want performance bands, derive them from the raw value during analysis or store the band as an additional property. Keeping the underlying value allows you to change a threshold without rewriting history.
Add context that leads to a decision
The minimum useful context is not the maximum available browser context. Attach only properties that help you isolate a problem or compare an outcome:
page_group: a stable product category such as landing page, pricing, signup, checkout, or application workspace.
device_class: enough detail to separate materially different experiences without creating a fragmented taxonomy.
geography: the approved regional level, not unnecessarily precise location data.
traffic_source: useful when acquisition channels land users on different page experiences.
user_cohort: new, returning, activated, subscribed, or another state that matters to your product.
experiment_variant and release_id: the connection between a performance change and the product change that may have caused it.
measurement_timestamp: when the experience occurred, kept separate from the time Amplitude received the event.
sampling_policy: whether the event came from full collection or a documented sample.
Prefer a controlled page group over an unrestricted URL. Raw URLs can create excessive cardinality, split one product surface across many records, and expose identifiers or query-string data that should not enter analytics. Normalize the route and redact sensitive values before transmission.
Your event contract is ready when an analyst can move from a weak metric distribution to a specific page group, audience, release, and business outcome without asking engineering to reconstruct the session.
Protect the experience from the code measuring it
A Browser SDK runs in the same environment whose performance you are trying to understand. That makes collection overhead part of the product decision. An analytics implementation that worsens loading or responsiveness is not merely inefficient; it contaminates its own measurement.
Keep the client-side footprint and payload focused. Collect properties that support segmentation or governance, not every value the browser can expose.
Make telemetry fail safely. Rendering, navigation, and interaction must continue if analytics initialization, collection, or delivery fails.
Use offline queuing and retry behavior without confusing delivery time with experience time. A delayed event still belongs to the session and release in which it was measured.
Sample consistently when full collection is unnecessary. A stable sampling policy is more defensible than selectively collecting only certain devices, routes, or observed performance states.
Put schema validation and compatibility checks in CI/CD. Product releases should not silently rename properties, change units, or remove the context that existing dashboards depend on.
Sampling deserves particular care. If slow sessions are more likely to be abandoned, a delivery mechanism that captures only completed journeys can underrepresent the experience you most need to see. Keep collection independent of the outcome wherever possible, document the sampling rule, and monitor coverage by page group and device class. A sample is useful only when you know what population it represents.
Retries create a different risk: duplicate or chronologically misplaced observations. Use a stable measurement identifier when your implementation needs deduplication, and preserve the original measurement timestamp. Otherwise, a recovered connection can make an earlier performance problem appear to belong to a later release.
Make privacy part of the event design
Consent-aware collection, edge redaction, and regional routing should be decided before rollout. Do not send a property and hope to clean it later. Once sensitive data enters an analytics pipeline, deletion and access obligations become harder to manage across queues, retries, exports, and downstream reports.
Review each property with a simple test: does this value materially change a product decision? If a precise URL, identifier, or location does not pass that test, replace it with a stable category or leave it out.
Analyze distributions alongside product outcomes
An average Web Vital hides the pattern product teams need. One page can look acceptable on average while a valuable device segment or acquisition cohort has a consistently poor experience. Start with distributions, then segment them by page group, device, geography, traffic source, and user cohort.
Next, pair those performance distributions with funnels and cohorts. Compare activation, conversion, retention, or revenue outcomes across ranges of LCP, INP, and CLS. Keep the metrics separate, because load speed, responsiveness, and visual stability can affect different moments in a journey.
Question
Amplitude view
Decision it supports
Where is the experience degraded?
Metric distribution by page group and device class
Select the surface and audience to investigate
Does the degradation matter to the product?
Outcome rate across performance ranges
Estimate the strength and shape of the association
Which change caused an improvement?
Experiment variant compared on both the vital and the outcome
Ship, revise, or reject the intervention
Did a release create a regression?
Performance distribution trended by release
Escalate, roll back, or investigate the affected page group
Look for a cliff rather than assuming a smooth relationship. Conversion might remain similar across much of the distribution and then deteriorate after a particular range. That pattern gives you a more useful target than a site-wide average: move the affected population away from the range where the outcome changes.
Do not confuse that pattern with causation. Device capability, network conditions, geography, traffic source, and user intent can affect both performance and conversion. Segmentation reduces obvious confounding, but it does not eliminate it.
Use experiments to prove the product effect
Once you find an important association, test an intervention. Image optimization, lazy-loading changes, and navigation changes are useful candidates because each can alter a specific part of the experience. Randomize the intervention, not the Web Vital, and measure two results together:
Did the treatment improve the intended LCP, INP, or CLS distribution?
Did the same treatment improve activation, conversion, retention, or another declared outcome?
A treatment that improves a performance score but leaves the product outcome unchanged may still be worthwhile for experience quality or regression prevention. It should not, however, be presented as a proven growth lever. Conversely, an outcome lift without the expected Web Vital movement means your proposed mechanism was probably incomplete.
Prioritize opportunities using four factors: the size of the affected population, the outcome gap associated with the performance range, your confidence that the relationship is actionable, and the team’s ability to change the relevant surface. This keeps a dramatic problem on a low-traffic page from automatically outranking a smaller but widespread problem in signup or checkout.
SEO can be a compounding benefit, but it should not replace the product case. Improve the experience for real users, verify the effect on their behavior, and treat search performance as a downstream outcome rather than the sole reason to optimize a synthetic score.
Turn the first week into an operating loop
Start with your top three entry pages. A one-week diagnostic is a sensible time box for establishing visibility, not a promise that you will prove causality in seven days. The first goal is to expose the distribution, validate the event quality, and identify one segment worth investigating.
Choose three entry pages and assign each to a stable page group.
Instrument LCP, INP, and CLS with the same normalized contract.
Verify coverage, missing properties, sampling behavior, timestamps, consent handling, and unexpected values before interpreting a chart.
Plot each metric’s distribution by page group and device class.
Overlay one outcome that occurs close enough to the experience to support a useful decision, such as signup completion or activation.
Select one high-impact segment and define an intervention that could plausibly change its experience.
Keep the first scope narrow. Adding every route, cohort, and outcome at once creates an instrumentation program before you have proven that the model produces decisions. Once the first three pages generate a credible hypothesis, extend the same event contract instead of creating a new one for every squad.
Define ownership before the first regression
Product should own the page groups, business outcomes, and prioritization logic. Engineering should own collection performance, delivery resilience, release metadata, and regression guardrails. Data or analytics should own schema quality, coverage checks, and the analytical definitions used in dashboards. The appropriate privacy owner should approve consent behavior, PII controls, and regional routing.
Then define product-level service objectives for LCP, INP, and CLS by key page group. Review performance distributions beside activation and retention in QBRs, and add release guardrails so a feature cannot quietly trade away responsiveness or stability. A site-wide objective is too blunt if signup and a low-traffic support page carry different user and business consequences.
Your instrumentation is operational when it has all of the following:
A versioned event contract with documented metric units and required properties.
Automated checks that catch schema drift during CI/CD.
Known coverage and sampling behavior across important page and device groups.
Consent, redaction, and routing rules applied before data leaves the browser.
A distribution view for each Core Web Vital rather than one blended score.
At least one product outcome connected to the performance experience.
A named owner and a release response for regressions.
This is where Web Vitals stop being a periodic performance project. They become a shared decision system for product, engineering, analytics, and privacy.
Key takeaways
Use one normalized Web Vitals event and preserve the raw metric value; derive performance bands without discarding the underlying measurement.
Attach stable page, audience, experiment, release, timestamp, and sampling context only when it supports analysis or governance.
Keep analytics collection lightweight, failure-tolerant, consent-aware, and protected by schema checks.
Analyze distributions by meaningful segments, then connect them to activation, conversion, retention, or revenue.
Treat correlations as hypotheses. Use an experiment to verify that a performance intervention also changes the intended product outcome.
Begin with three entry pages, one nearby outcome, and one actionable segment before expanding coverage.
On your next instrumentation ticket, require three fields beyond the SDK task: the decision the data will support, the outcome it will be joined to, and the owner who will respond when it regresses. That small change turns Web Vitals collection from telemetry into product management.