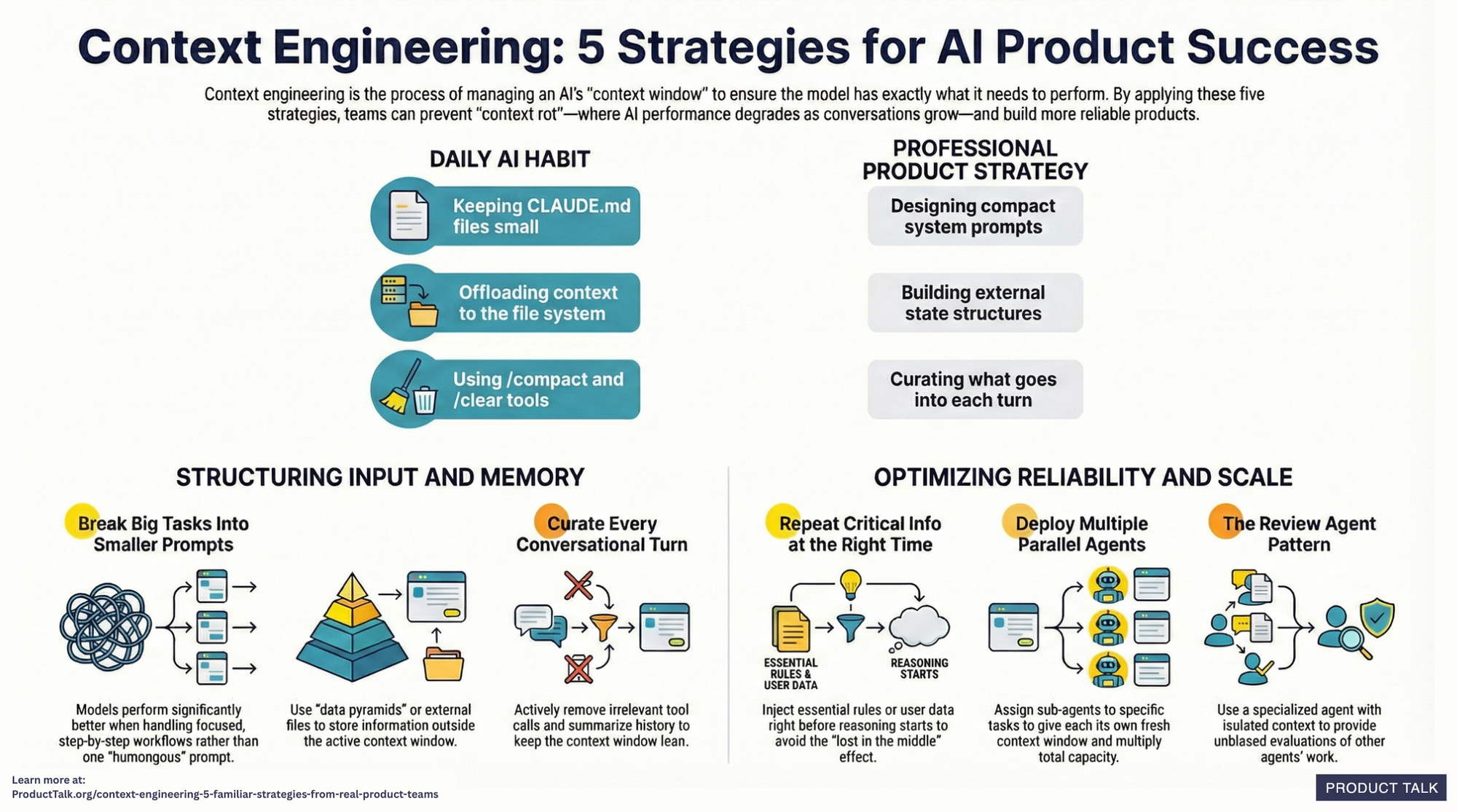
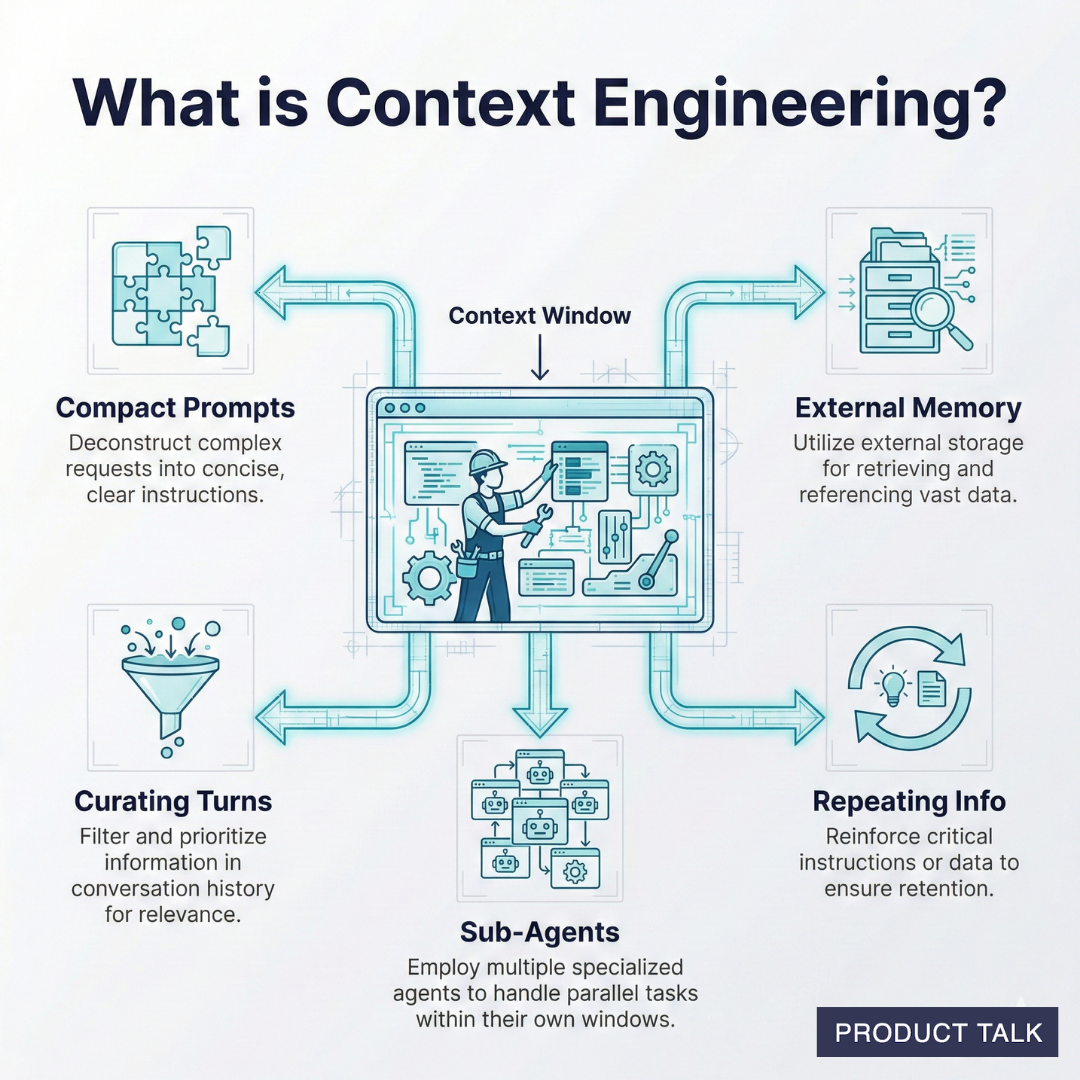
In my day-to-day building AI products, I’ve learned a simple truth: a single model can be brilliant, but a coordinated team of specialized agents is what consistently ships outcomes customers trust. That’s the promise of multi-agent systems—multiple AIs with distinct roles collaborating inside robust AI workflows to deliver accuracy, speed, and resilience you can’t get from a lone model.
Think of a multi-agent system as a well-run product trio for machines: a planner decomposes the job, specialists execute focused tasks, a reviewer checks quality, and an orchestrator keeps everyone aligned. This agentic AI approach mirrors how high-performing teams work—divide complex problems, play to strengths, and create tight feedback loops.
When does one AI stop being enough? Whenever tasks require tool use, domain retrieval, multi-step reasoning, or policy adherence under real-world constraints. In those moments, specialized agents shine—one for search using a retrieval-first pipeline, another for reasoning, another for action execution, and a final one for validation. The result is better accuracy with manageable latency and cost.
The core architecture I rely on starts with a planner that breaks a goal into steps, followed by execution agents equipped with tools and grounded context. I pair this with context window management to keep prompts lean and relevant, and I insert a verifier (or critic) to catch logic slips and policy violations before results reach customers. A lightweight orchestrator coordinates handoffs and retries to keep the whole flow resilient.
To make this production-grade, I treat observability as non-negotiable. Agent Analytics helps me see which agents are adding value versus adding latency, where failures cluster, and how prompts drift over time. From there, eval-driven development gives me measurable confidence: I codify representative tasks, run offline and shadow evaluations, and only promote changes that move accuracy and safety in the right direction.
Governance is equally critical. I design privacy-by-design from the start, restrict data movement with strong data governance, and enforce policy constraints inside the workflow rather than after the fact. This includes red-teaming failure modes, rate-limiting tools, and capturing immutable traces for audits and post-incident reviews—habits borrowed from SRE culture that map well to AI systems.
On the practical side, prompt engineering remains foundational, but it’s the system design that converts clever prompts into reliable outcomes. Tool access, retrieval quality, memory strategy, and error handling matter more than wordsmithing alone. I’ve found that small prompt improvements are amplified when the surrounding workflow is sound—and are overwhelmed when it isn’t.
If you’re just starting, begin with a narrow use case and a minimal set of agents—planner, executor, and verifier—then expand. Use continuous discovery with real users to learn where the workflow fails in the wild, and iterate with tight release cycles. Treat every agent like a microservice with clear contracts, test coverage, and metrics, and you’ll unlock compounding gains without losing control.
The payoff is tangible: faster shipping cycles, fewer regressions, and outcomes customers can actually rely on. When stakes are high and ambiguity is real, one AI is often a talented soloist—but a disciplined ensemble of agents is how I deliver dependable, scalable value at product velocity.
Inspired by this post on Product School.