Will AI replace software engineers or reshape their roles? Explore risks, opportunities, and alternative career paths in tech.
I’m often asked whether AI will make software engineers obsolete. My short answer: AI is already automating tasks, not eliminating the role. The engineers who learn to orchestrate models, systems, and stakeholders will create more value—not less. The real shift is from keystrokes to judgment, from writing code to designing socio-technical systems that deliver outcomes.
Today’s gen ai assistants—think Claude Code and ChatGPT connector—excel at unit test scaffolding, boilerplate generation, refactoring, docstrings, and code search. When integrated into CI/CD, they can open draft pull requests, annotate diffs, and propose fixes. This lifts developer productivity and frees time for higher-leverage work: problem framing, architecture decisions, and customer discovery.
What changes in the role? We spend more cycles on product discovery, privacy-by-design, and AI Strategy, and fewer on repetitive implementation. We design agentic AI workflows that combine retrieval, tools, and guardrails; we evaluate trade-offs that blend performance, cost, and safety; and we partner with empowered product teams to ship the smallest valuable slice, learn, and iterate.
Measure what matters. If AI is working, DORA metrics should improve: higher deployment frequency, shorter lead time for changes, stable change failure rate, and faster MTTR. Pair that with outcomes vs output OKRs to avoid gaming the system—shaving seconds off a build is meaningless if it doesn’t move activation, retention, or revenue. A unified analytics platform can help connect engineering signals to business impact.
Risk is real—and manageable. AI risk management and data governance are now core competencies, not afterthoughts. Protect IP with robust access controls, context window management, and red-teaming. In production, instrument threat detection and response to catch prompt injection, data leakage, and model drift. Treat this like any other reliability discipline alongside SRE.
If parts of coding get automated, where can great engineers thrive? Several high-impact paths are emerging: platform engineering for LLMs (tooling, evals, observability), SRE for AI-infused systems, developer evangelism and education, product management for AI-native experiences, security engineering focused on model and data threats, and forward deployed engineers who pair with customers to solve messy, real-world problems.
How to upskill fast: build an AI product toolbox and ship small. Prototype gen ai features end-to-end—retrieval, function calling, human-in-the-loop QA—and connect them to your CRM integration or support stack. Use A/B testing with a clear minimum detectable effect (MDE) to validate impact. Leverage CustomGPT workflows for internal enablement and in-app guides or product tours to onboard users safely.
Here’s a pragmatic 90-day plan. Week 0–2: audit your top 10 engineering tasks by time spent; identify 3 that are ripe for AI augmentation. Week 3–6: pilot inside CI/CD with explicit guardrails; track DORA metrics and developer sentiment. Week 7–10: productionize the wins; document runbooks; add incident management paths. Week 11–12: share learnings with product trios, refine your value proposition, and set next-quarter OKRs.
AI won’t replace software engineers; engineers who master AI will outpace those who don’t. If we embrace the shift—toward systems thinking, responsible governance, and customer outcomes—we’ll build better products faster and open new, rewarding career paths. The opportunity is here and compounding.
I’ve spent much of my career compressing the distance between a napkin sketch and something real customers can touch. At HighLevel, my product teams use generative AI to validate ideas faster, reduce risk earlier, and win stakeholder trust with evidence instead of slides. The goal isn’t to be flashy—it’s to be precise, testable, and repeatable.
Today, you can build it before you pitch it. AI prototyping can turn ideas into clickable demos in hours. Here are some tools to try and steps to follow.
I start every AI prototyping sprint by sharpening the problem statement and the outcome we care about. That means being explicit about the target user, jobs-to-be-done, and the riskiest assumptions. I define a minimum detectable effect (MDE) and tie it to outcomes vs output OKRs so everyone aligns on what “good” looks like before we touch a tool.
From there, I move from sketch to interface. I capture a rough flow (whiteboard, tablet, or even paper) and generate UI variations with my AI product toolbox—tools that translate structure into components and screens. I’ll iterate on information hierarchy and copy until the narrative supports the core job, borrowing techniques from UX writing. For product managers leaning into LLMs for product managers, this phase is about speed to feedback, not perfection.
Next, I wire data and logic. I connect a lightweight backend or spreadsheet, stitch in a CRM integration if needed, and add LLM calls through a ChatGPT connector or Claude Code. If the concept benefits from multi-step autonomy, I introduce agentic AI to orchestrate tasks across APIs. CustomGPT workflows help me encapsulate business rules so the demo behaves consistently in user paths we care about.
Governance is not optional at this stage. I apply privacy-by-design defaults, document data governance decisions, and run a quick AI risk management pass: input validation, prompt safety, rate limits, and fallback responses. This keeps the prototype credible and prevents false positives from polluting stakeholder perception.
With a click-through in hand, I instrument the experience so learning compounds. I drop in Amplitude analytics to track activation, task completion, and drop-off, and set up simple A/B testing when there’s a meaningful design or copy choice. This makes the prototype a learning vehicle, not just a demo.
Then I get it in front of users—fast. Five targeted conversations will beat fifty internal opinions. I run structured product discovery interviews, observe time-to-value, and capture objections. This is where empowered product teams shine: we make changes in real time, re-run the flow, and document what moves the needle for product-led growth.
When speed matters, I use a four-hour cadence: Hour 1 for problem framing and MDE; Hour 2 for sketch-to-UI generation; Hour 3 for data wiring and AI logic; Hour 4 for instrumentation and user walkthroughs. By the end, we have a clickable demo, preliminary analytics, and a clear decision on whether to advance, pivot, or park.
Finally, I translate insights into a concise artifact: the hypothesis we tested, the signal we observed, the trade-offs we made, and the next sprint plan for product roadmapping and sprint planning. The point is not to be right on the first try; it’s to learn precisely, cheaply, and quickly enough to invest with conviction.
If you adopt this approach, you’ll find that stakeholder management becomes easier, team energy rises, and your roadmap earns credibility. Build it before you pitch it, and let real interactions—not wishful thinking—do the heavy lifting.
AI search is quickly becoming the new homepage for startups. When a buyer asks a model for the best tools, they often take the short list at face value. I treat this moment as a product surface I can influence with strategy, content, structure, and distribution—much like any other go-to-market channel.
Early on, I set a simple objective for my team and me: "Learn how LLMs like ChatGPT and Perplexity decide which startups to recommend and what signals help a brand get discovered in AI search." That sentence became our north star for experiments, instrumentation, and content architecture.
Here is the mental model that consistently holds up in practice. Large language models synthesize answers from a knowledge graph built from crawled content, citations, and high-signal sources. They weight consensus, clarity, recency, authority, and machine-readability. I don’t pretend to know the internals, but across hundreds of tests, the same patterns correlate with being surfaced and cited.
First, I make our entity unambiguous. I standardize the company name, product names, and leadership bios across the site and external profiles. I implement Organization and Product markup with schema.org and link out with sameAs to authoritative profiles like LinkedIn, Crunchbase, GitHub, and key directory listings. The goal is to collapse ambiguity so AI search knows exactly who we are and which claims are attributable to us.
Next, I publish definitive, answer-first pages. For every core query—what we do, who it’s for, outcomes, differentiators, pricing, comparisons, and integrations—I ship a page that leads with a crisp summary, then supports it with evidence, examples, and plain language. I include Q&A sections, realistic use cases, and named case studies so models can quote and ground responses in verifiable facts.
I then make the site maximally machine-readable. I add schema.org for SoftwareApplication, Product, FAQPage, and HowTo where relevant. I keep titles, H1/H2 structure, internal links, and metadata descriptive and consistent. I expose last-modified dates, maintain an XML sitemap, and keep a visible changelog and release notes. Freshness matters—Perplexity, in particular, tends to privilege recent, well-cited material when answering time-sensitive questions.
Citations are non-negotiable. I earn credible mentions on third-party properties, analyst lists, comparison pages, and customer reviews. I prioritize authoritative placements over volume, then make sure our site references those sources to reinforce the signal. When Perplexity cites our page alongside a respected third-party review, our inclusion rate in answers rises noticeably.
I also design for developers, buyers, and machines at once. That means clean docs, integration pages, and transparent security and trust content. Clear API references, integration guides, and reliability notes give models concrete artifacts to summarize. Pricing, privacy, and support policies reduce uncertainty and increase the likelihood that an answer will include us.
Measurement turns this from a hunch into a system. I run controlled content experiments, track minimum detectable effect on discovery and mentions, and instrument referral patterns from AI assistants when citations appear. I monitor which prompts surface our brand, which sources are cited, and which pages are repeatedly used as references. When we move a KPI, we codify the pattern into our playbook and scale it.
Trust is the compounding advantage. I maintain a transparent trust center, privacy-by-design posture, and clear data governance practices. I remove vague claims, back up benefits with evidence, and keep all performance or security statements auditable. Models tend to lift brands that feel low-risk, well-documented, and widely corroborated.
If you want a fast start, here’s the checklist I rely on. Standardize your entity and ship schema.org. Publish answer-first pages for core jobs-to-be-done, comparisons, and integrations. Earn authoritative third-party citations and reference them. Keep release notes, changelogs, and dates current. Instrument AI discovery and iterate based on what gets cited. Do this consistently, and your startup earns a fair shot at being recommended when buyers ask AI for the best options.
Inspired by this post on Amplitude – Best Practices.
Note: This is part of the product creator series of articles, based on the overview article, The Era of the Product Creator. This series is for anyone who wants to create a successful product—whether or not you’ve had formal training or experience in product management, product design, or engineering.
Over the years, I’ve watched smart teams stumble because they treated a prototype like a product. The distinction is simple but vital: prototypes exist to learn; products exist to earn trust by delivering value reliably at scale. When we blur that line, we ship avoidable risk to customers and slow ourselves down later with rework.
When I build a prototype, I’m testing assumptions as quickly and cheaply as possible. It might be a clickable Figma mock, a Wizard‑of‑Oz demo, or a quick script stitching together a ChatGPT connector with a CustomGPT workflow. It’s intentionally disposable. I expect missing edge cases, fake data, hand‑waving on latency, and limited attention to security or privacy. The only goal is to answer the riskiest questions fast.
A product is a promise. It’s hardened for reliability, performance, security, and privacy‑by‑design. It’s observable with real analytics, supports CI/CD and rollback, meets accessibility guidelines, and can be maintained by empowered product teams. It has clear SLAs, incident management runbooks, and instrumentation that lets me track outcomes vs output OKRs and DORA metrics.
Keeping prototypes and products separate makes us faster and safer. Prototypes accelerate discovery; products operationalize value. If I catch myself “polishing” a prototype, I pause and either discard it or define the path to production with the right engineering rigor, data governance, and stakeholder management.
Here’s how I decide. In prototype mode, I timebox learning to days, not weeks, and focus on a single risky assumption—value, usability, or feasibility. I validate through qualitative research and usability tests, not vanity metrics. To graduate to product work, I require a crisp problem statement, evidence of problem‑solution fit, a technical plan for scale and observability, a privacy and threat modeling review, and a measurement plan (including minimum detectable effect) for upcoming A/B testing.
AI adds new wrinkles. For gen AI and agentic AI, I evaluate model behavior offline before exposing anything to customers. That includes prompt design, context window management, guardrails to minimize hallucinations, and clear fallback strategies. I define red‑team scenarios, logging for auditability, and policies for data retention and encryption as part of AI risk management.
A recent example: we prototyped an agent workflow in a day that felt magical in demos. We resisted the urge to ship. Instead, we added authentication, rate limiting, PII redaction, human‑in‑the‑loop review, observability, and in‑app guides and product tours for onboarding. Only then did we move to a limited release with a well‑defined go‑to‑market strategy and support readiness.
One more trap to avoid: calling a prototype an MVP. An MVP is still a product—minimal in scope but complete enough to deliver value, gather trustworthy data, and support customers. If you wouldn’t put your name on it or support it in production, it’s a prototype, not an MVP.
If you’re a product creator, align your product trios around this discipline. Use prototypes to learn quickly in discovery, and use products to deliver outcomes in delivery. That mindset protects customer trust, speeds iteration, and moves you toward product‑market fit with far less waste.
"Can you critique the landing page for my new Story-Based Customer Interviews course?" That simple ask used to kick off hours of back-and-forth where I fed an AI the same context over and over—only to get generic feedback that wouldn’t land with my audience or fit my products. As a product leader, that inefficiency was unacceptable; as a writer, it was just plain frustrating.
Not anymore. Today, Claude not only critiques my work, it helps me produce it. It generates marketing copy—in my voice. It helps me write blog posts. It knows what search terms are relevant to my business and helps me optimize my articles for SEO and now AEO. It helps me with competitive research, academic research, and discovery research. And it does all of this with little prompting from me.
I don’t upload files to a web-based project. I don’t manage elaborate prompt libraries. I don’t repeat myself. I ask for help and Claude knows exactly what to do. The shift happened when I learned how to give Claude Code a memory. Claude now knows who my target customer is, the key value propositions I focus on, the specific opportunities each product addresses, my revenue model, my marketing channels, and so much more.
A dark-themed strategy slide for the post Stop Repeating Yourself: Give Claude Code a Memory, showing how to lead with a CLAUDE.md glossary page, write clearly for nontechnical readers, and link glossary and article to boost discovery and engagement.
With that memory, I consistently get high-quality output tailored to my audience and aligned to my products and services. I don’t retype the same context; Claude just remembers. In this article, I’ll show you exactly how I set up that memory. It relies on Claude Code (which requires a Pro subscription), and it’s worth it. If you’re new to Claude Code, start with "Claude Code: What It Is, How It’s Different, and Why Non-Technical People Should Use It."
Here’s the underlying problem: with large language models, every conversation starts from scratch. Yes, ChatGPT can remember some things and Claude can search past conversations, but practically speaking each new thread wipes the slate clean. If I were working on a new landing page, I’d normally need to upload target customer context, product details, primary and secondary value propositions, FAQ questions and answers, plus testimonials and logos for social proof—every single time.
Start fast with Claude’s home screen: Sonnet 4.5 is ready, and quick actions for writing, learning, and coding sit beneath a clean prompt box—ideal for showing how memory cuts repetition and streamlines daily development.
Projects in web-based tools help a bit, but they introduce a new dilemma. When I move to the next landing page targeting the same customer but a different product and value proposition, do I start a new Project (tedious) or keep expanding the old one (which muddies the context window and degrades output quality)? The good news: Claude Code solves this by giving the model a precise, durable memory without overloading any single conversation.
Claude Code can read files on my local machine, which is an understated superpower. I use those files to create a persistent, reusable memory that works across all chats and Projects. Files can be mixed and matched, so I give Claude exactly what it needs for the task at hand—and nothing more. For a first landing page, I reference the target customer and the relevant product; for the second, I reuse the same target customer file and point to the new product file.
Dark-mode Notes screenshot captures Claude Code in action: it fetches producttalk.org, reads context files, and delivers a concise homepage evaluation—showing how memory streamlines repeated analysis tasks.
When you give an LLM the exact right context, output quality jumps. More context only helps if it’s the right context. For a landing page, Claude needs to know about the current product and perhaps related products for differentiation—but it doesn’t need to know about unrelated offerings. Structure your memory so Claude gets precisely what’s required.
Once I did this, Claude shifted from “intern who needs handholding” to trusted advisor and capable teammate. It doesn’t guess at my value propositions—I’ve already told it. It writes in my voice because it has my writing guide and samples. It knows who owns which course and which use cases map to which features. The setup takes a bit of upfront work, but it compounds: update a file when something changes and you’re done. Most of this information already lives in your system; the trick is making it easy for Claude to use.
See how Claude Code stops repetition: global and project CLAUDE.md files, plus custom reference docs, flow into the editor so the assistant remembers your preferences and context while you code and run commands.
Because the files live on my machine, I own the system. No vendor or device lock-in. I decide when and who to share with. I can work with Claude on one project and ChatGPT on another—both can rely on the same file-based memory strategy. It’s an AI strategy that scales with product discovery, accelerates go-to-market content, sharpens competitive differentiation, and supports product-led growth.
Here’s how I design the memory: I use three layers. Claude Code already encourages global preferences and Project-specific instructions, but the third layer—reference context—is where the real power lives.
Peek inside a markdown playbook for Claude Code: concise rules for writing, multi-level planning, and clear feedback that turn repeated reminders into reusable memory and smoother, faster coding sessions.
Layer 1: Global Preferences (Always on). The first time I launched Claude Code, I created a CLAUDE.md file at ~/.claude/CLAUDE.md. This is where I keep the cross-project rules of engagement—how I like to work with Claude. Mine includes: Always create a plan for me to review before you start any work; Give me direct feedback (no hedging, no gentle suggestions); Use bullet points for summaries; Ask clarifying questions one at a time so I can give complete answers; No emojis unless I explicitly ask for them. Claude Code automatically loads this file at the start of every session, so I never restate my preferences.
Layer 2: Project-Specific Instructions. Different projects have different rules. In my writing workspace, the Project CLAUDE.md sets the roles (I’m the primary writer; Claude is my thought partner and editor), defines a multi-round review flow (content → structure → accuracy → typos), prioritizes human readability over SEO, and points to my writing style guide. In my task management system, I include how my Trello integration works, file naming conventions for tasks, and how to process research papers into summaries. In my code projects, I specify the technology stack (Node.js vs. Python), testing framework (Jest for Node.js, pytest for Python), code style and conventions, project architecture and directory structure, and which dependencies and libraries to use. Each project directory has its own CLAUDE.md, and Claude automatically loads the relevant file when I’m working there.
Peek inside a markdown playbook for collaborating with Claude—covering session setup, roles, editorial standards, and research steps—to show how saved instructions create consistent results without repeating yourself.
Layer 3: Reference Context (Pull as Needed)—the real power. LLMs have a context window—a limit to how much they can process at once. Even within that limit, loading too much degrades performance due to “context rot.” The remedy is ruthless context management: small, targeted files that load only when needed. Keep CLAUDE.md files concise and focused on rules and workflows. For detailed knowledge, create separate reference files and list them in your CLAUDE.md so Claude knows they exist and when to fetch them. When I ask for help creating a landing page, Claude knows to use my business profile, the product file, and my target customers context.
Here’s what most people miss: you don’t cram everything into global or Project files. You maintain small, reusable reference files that Claude only loads on demand. In my walkthrough, I share exactly which context files I created and why; how I got Claude Code to help me create them; how I break them into small, reusable components so Claude gets precisely what it needs; how I keep everything up to date; and step-by-step instructions so you can set up a similar memory system.
Three project notes funnel into Claude Code, turning reusable context into working output. This visual shows how saving key docs as memory lets the AI pick up where you left off and skip repetitive prompting across tasks.
I recently tuned into an insightful All Things Product episode featuring Teresa Torres and Petra Wille on how experimenting with AI in everyday life sharpens how we build AI-powered products at work. The core premise resonated deeply with my AI Strategy: low-stakes, personal experiments accelerate confidence, clarify limitations, and build an AI product toolbox we can bring into the office with rigor.
If you want to dive in, you can listen on Spotify or Apple Podcasts. I found the conversation especially relevant for product trios and anyone shaping LLMs for product managers in high-stakes environments.
The idea is simple but powerful: when I prototype with AI at home—where the stakes are low—I learn faster, make safer mistakes, and internalize critical product patterns. Over time, those patterns transfer directly to work: tighter context management, sharper bias awareness, clearer human-in-the-loop guardrails, and a more nuanced view of when to use AI as a thought partner versus when to consider agentic AI.
In my own practice, I’ve mirrored many of the scenarios discussed: using ChatGPT by OpenAI to plan meals, analyze public data sets like school budgets, and even sanity-check real estate evaluations. These seemingly mundane tasks are fertile ground for learning about context window limits, hallucination (artificial intelligence), AI bias, and privacy-by-design trade-offs. Each experiment helps me craft better prompts, structure data for clarity, and decide when a human review step is non-negotiable—core habits for AI risk management.
At work, I treat AI as a thought partner for writing, research synthesis, and contract review. I also explore when and how to responsibly evolve toward agentic AI for repeatable workflows. The distinction matters: a thought partner augments judgment; an agent automates execution. Building the right scaffolding—data governance, auditability, constraints, and escalation paths—ensures we unlock speed without compromising safety.
Three lines from the episode stayed with me: “I’m trying to write things that only I can write — that’s my guiding writing light right now.” — Teresa. “The more we use AI, the more we learn what it’s good at, what it’s not good at, and where context becomes a limitation.” — Teresa. “It’s a safer playground — we can build our toolbox at home before bringing those lessons to work.” — Petra. These are practical north stars for product management leadership in the GenAI era.
For anyone getting started, here’s what worked for me: begin with “low-stakes” personal experiments, write down your prompts and outcomes, and reflect on failure modes. Treat each activity as product discovery: What problem am I solving? What outcome matters? What data and context does the model need? Which decisions must stay human-in-the-loop? This discipline builds an AI product toolbox you can confidently apply to real customer problems.
I also keep a running toolkit of references and tools that inform my practice: Context window as a concept helps me size and sequence information. Visual and video tools like Midjourney and Sora expand how I think about multimodal experiences. I rotate between Claude by Anthropic and ChatGPT by OpenAI depending on task fit, and I’ve used Claude Code when I need structured assistance with code review. For knowledge capture and workflow, Readwise and Ghost help me structure insights and ship content.
If you want more structured learning paths, I found Josh Seiden’s Learn AI With Me, A 30-Day Sprint to be a practical primer, and the broader community conversation at Product at Heart Conference is invaluable. For a deeper grounding in risk, I recommend reviewing topics like Hallucination (artificial intelligence), AI bias, and Agentic AI—and revisiting the complementary episode, Context is King.
I’d love to hear how you’re experimenting: Where have you seen AI meaningfully reduce toil? Where does it still struggle? How are you balancing creativity, data safety, and compliance as you scale? Drop a comment below and let’s compare notes—especially on patterns that help product trios move faster without sacrificing trust.
Bottom line: start small at home, carry lessons into the office, and build with curiosity and intentionality. That’s how we level up our product discovery, sharpen our value proposition, and lead teams confidently through the GenAI transition.
Your team has several credible AI demos, every sponsor sees potential, and no one can answer the question that matters: which idea deserves more engineering time, customer exposure, and operating risk?
That is not an ideation problem. It is an evidence-design problem. A useful AI innovation strategy makes each investment earn its way forward through customer outcomes, representative evaluations, and explicit kill-or-scale decisions. The result is not less experimentation. It is faster learning with fewer expensive surprises.
Start every AI bet with a decision contract
Most AI roadmaps begin too far downstream. The discussion jumps to a model, an assistant, or an agent before the team agrees on the user problem or the evidence required to fund the next stage. The feature then acquires momentum simply because it exists.
Replace the feature brief with a decision contract. This is a short agreement about what the bet must prove, how it will be evaluated, and what happens when the evidence arrives. It connects vision, portfolio choices, and execution to measurable outcomes before implementation choices harden.
Name the user and the job. Specify who encounters the capability, what they are trying to accomplish, and which situations are out of scope. “Improve support with AI” is not a problem statement. “Help eligible customers resolve account questions without waiting for an agent” is testable.
Choose the business outcome and its baseline. Use resolution rate, time-to-value, activation, retention, revenue lift, or another measure of customer and business value. Record how the existing workflow performs so the AI is compared with a real alternative, not with an empty screen.
State the behavioral hypothesis. Explain how the proposed capability should cause the outcome to move. This exposes weak logic early. A faster response, for example, does not automatically produce a correct resolution.
Define the evidence stack. Identify the offline evaluations needed to establish behavioral confidence and the live experiment needed to validate customer impact. Neither can substitute for the other.
Set constraints and hard guardrails. Include unacceptable failures, privacy boundaries, safe-action requirements, latency expectations, and cost limits. A capability that is accurate but too slow, unsafe, or uneconomic is not ready.
Pre-commit to the decision. Record the minimum detectable effect for the live experiment, the evaluation thresholds that block release, the time at which evidence will be reviewed, and the conditions for killing, refining, or scaling the bet.
The contract should separate three metric layers. The outcome metric tells you whether customer or business value changed. Behavioral metrics tell you whether the AI performed its assigned job. Guardrails tell you whether that performance remained safe, reliable, responsive, and affordable. This prevents a team from celebrating a model score while the customer experience deteriorates.
Consider a customer-support assistant. Eligible deflection and first-contact resolution can represent the business outcome. Factuality against the approved knowledge base, helpfulness, tone, retrieval accuracy, and safe CRM actions describe the system’s behavior. Harmful-content rate, unsafe-action rate, response latency, and token cost act as guardrails. A live test can then examine customer satisfaction and resolution instead of merely counting generated replies.
This is the practical difference between an output and an outcome. Shipping an assistant is an output. Producing more successful resolutions without unacceptable safety, latency, or cost regressions is an outcome. Disciplined evaluation makes that distinction measurable.
Match the evidence burden to the type and consequence of the bet
A portfolio needs different kinds of AI innovation, but it should not evaluate every bet in the same way. Core optimization, adjacent expansion, and transformational innovation face different uncertainties. The label determines the strategic question. The consequence of failure determines the rigor.
Portfolio bet
Question it must answer
Evidence that matters most
Typical decision
Core optimization
Can AI improve an established journey without damaging what already works?
A reliable baseline, regression tests, live A/B results, and cost and latency guardrails
Adopt the change only when the improvement survives the existing quality bar
Adjacent expansion
Does the capability solve a known job for a new segment, channel, or use case?
Problem discovery, segment-representative evaluation cases, activation signals, and retention evidence
Expand only after the new audience reaches a meaningful value moment
Transformational innovation
Can a materially different workflow create value and be trusted?
Task-completion tests, human review, adversarial testing, safe tool-use checks, and a staged customer pilot
Increase autonomy and exposure only as reliability and business evidence mature
A core change can have a small strategic scope and still require a high evidence burden. An apparently simple classifier may sit inside a sensitive workflow. Conversely, a transformational concept can begin with a narrow, reversible prototype. Do not use “experimental” as permission to lower the bar for privacy, security, or consequential actions.
The same discipline improves build, partner, and buy decisions. Generic demonstrations do not reveal how a system will perform on your customers’ language, your knowledge, your policies, or your tools. Run every viable option through the same representative task set. Compare task quality, latency, cost, integration effort, data boundaries, governance fit, and failure recovery. The vendor category matters less than whether the option can satisfy the decision contract.
Portfolio funding should follow evidence maturity rather than presentation quality. Continue a bet when the team can identify remaining uncertainty and run a proportionate test to reduce it. Pause or kill it when customer value does not materialize, critical failure modes remain unresolved, or the required quality cannot fit inside the operating cost and latency envelope.
A neutral experiment is not automatically wasted work. It can eliminate a weak hypothesis and release capacity for a better bet. But a poorly instrumented or under-sensitive experiment does not produce a useful neutral result. Set the minimum detectable effect and instrumentation before launch so “no movement” has an interpretable meaning.
Build an evaluation stack that resembles the real product
An AI evaluation is useful only when it represents the decisions the product must make under realistic conditions. A polished answer to a convenient prompt is weak evidence. The production system also has to handle ambiguous requests, imperfect retrieval, policy boundaries, long-tail inputs, adversarial behavior, and tool failures.
Turn the golden dataset into an executable product specification
Your golden dataset should express product intent through examples. Start with real, properly anonymized inputs from discovery, support, and product usage. Add important edge cases, long-tail situations, and adversarial prompts deliberately; waiting for production to reveal them transfers avoidable risk to customers.
Each case should carry enough context to diagnose a failure, not just assign a score:
The user input and relevant conversation or workflow state
The approved information or system state the response may rely on
The expected behavior, acceptable answer range, or permitted action
A rubric for correctness, helpfulness, tone, and safety
A risk label that distinguishes ordinary quality defects from release-blocking failures
Metadata for the user segment, use case, input pattern, or workflow stage
Keep the set versioned. Preserve cases that caught previous regressions, refresh it as customer behavior changes, and hold back examples that are not used for prompt tuning. Otherwise, the team can optimize for a familiar test set while making little progress on the wider product experience.
Privacy belongs in dataset design. Anonymization, access control, retention rules, and approved data boundaries should be established before customer interactions become test fixtures. Retrofitting those controls after an evaluation pipeline spreads sensitive data is slower and riskier.
Use several evaluators because each catches a different failure
No single evaluation method is a complete quality system. Layer methods according to what is being tested:
Deterministic tests are appropriate for business rules, schemas, required fields, forbidden actions, exact calculations, and tool arguments. If a rule can be checked directly, do not ask another model to guess whether it passed.
Grounded checks compare claims with an approved knowledge base or retrieved context. They are essential when the product promises answers based on company or account information.
LLM-as-judge scoring can cover subjective dimensions such as helpfulness, relevance, and tone at useful scale. Define the rubric tightly and calibrate the judge against human decisions. Consistency is not enough if the judge consistently applies the wrong standard.
Pairwise preference tests help compare prompt, retrieval, or model variants when an absolute score is hard to interpret. They answer which candidate better satisfies the same rubric.
Human review remains necessary for critical, ambiguous, policy-sensitive, or high-consequence cases. It also provides the reference needed to recalibrate automated judges.
Red teaming probes manipulation, unsafe requests, policy evasion, and unexpected combinations of otherwise valid instructions.
Agentic systems need evaluation beyond the final prose. A fluent confirmation can hide a failed or unauthorized action. Measure whether the agent chose the correct tool, supplied valid arguments, respected permissions and confirmation requirements, completed the intended task, and recovered safely when a dependency failed. Task-completion reliability and safe-action rate are more revealing than answer style alone.
Quality must also be evaluated inside the cost-quality-latency envelope. A larger model can improve a difficult generation task and still be the wrong default for a simple classification step. Test model routing, token budgets, caching, prompt structure, retrieval quality, and function-calling patterns by task. The goal is not to minimize each cost independently; it is to meet the product’s quality bar with an operating profile the business can sustain.
Turn evaluations into release gates and portfolio decisions
An evaluation document that lives outside delivery will eventually be skipped. The evaluation suite should run whenever a prompt, model, retrieval pipeline, knowledge source, tool schema, or workflow changes. That makes evaluation part of the release mechanism instead of a launch ceremony.
Use a gate sequence from discovery through production
Stage
Evidence to collect
Decision enabled
Problem discovery
User problem, current workflow, baseline, value hypothesis, and major risks
Decide whether the problem deserves an AI bet
Prototype
Representative golden-set results, failure taxonomy, latency, and estimated operating cost
Decide whether the capability has a credible path to the product bar
Pre-release
Regression suite, calibrated human review, adversarial cases, privacy checks, and safe-action tests
Block, revise, or approve a controlled rollout
Controlled rollout
Predefined A/B test, value-moment telemetry, satisfaction, guardrails, and incident signals
Validate whether offline quality creates customer and business value
Production scale
Continuous monitoring, segment-level failures, cost and latency trends, incidents, and refreshed evaluations
Scale, route, constrain, roll back, or retire the capability
Separate hard gates from optimization targets. A prohibited action, a privacy-boundary violation, or a broken business rule should block release. A modest tone improvement or non-critical cost regression may be handled as a tracked trade-off. If every metric is a hard gate, delivery stalls. If none is, the gate is theater.
I use a simple test for gate quality: if two accountable leaders can read the same result and reach opposite release decisions, the decision rule is incomplete. Define the failing threshold, affected cases, permitted exception process, and rollback action before the result arrives.
For systems that can change customer data, communicate externally, or trigger another consequential action, start with narrow permissions and human confirmation. Log the proposed action, the tool call, the result, and the reason for escalation. Increase autonomy only when the relevant task and safety evaluations hold under real usage. A human-in-the-loop control is most useful when the escalation path, response owner, and incident procedure are explicit.
Offline evaluations create confidence to expose the product. They do not prove business impact. A live experiment must test the stated outcome with a predefined minimum detectable effect while watching for novelty bias and segment-specific failures. Instrument the customer’s value moment, not merely clicks on the AI entry point. An assistant can attract curiosity without improving activation, retention, resolution, or satisfaction.
Production telemetry should feed back into the golden dataset. Add recurring failures, newly observed edge cases, incidents, and examples where users abandon or escalate. This turns customer reality into the next regression suite and prevents evaluation from freezing at the assumptions held before launch.
Carry one scorecard from the product team to the QBR
Leadership does not need a separate innovation narrative built from feature updates. Use one scorecard at product reviews, investment reviews, and QBRs. It should contain:
The portfolio class and strategic outcome
The target user, job, and current baseline
The causal hypothesis and non-AI alternative
The primary business metric and minimum detectable effect
The offline quality measures and live outcome measures
The safety, privacy, latency, reliability, and cost guardrails
The current evidence, unresolved uncertainty, and confidence level
The next test, accountable owner, review point, and kill-or-scale rule
This creates a common language for product, engineering, design, go-to-market, risk, and executive stakeholders. The conversation becomes: What did the bet need to prove? What evidence changed? Which uncertainty remains? What decision follows? It no longer depends on who presents the most persuasive demonstration.
The scorecard also protects speed. Teams with explicit boundaries can make routine prompt, retrieval, routing, and interface improvements without reopening the entire strategy. Leadership attention can stay on exceptions, material regressions, capital allocation, and bets whose evidence no longer supports the original thesis.
Key takeaways for your next AI portfolio review
Require a decision contract before an AI idea receives roadmap momentum: user, outcome, hypothesis, evidence, guardrails, and kill-or-scale rule.
Classify each bet as core, adjacent, or transformational, but set evaluation rigor according to the consequence of failure.
Build a versioned golden dataset from anonymized real inputs, important edge cases, long-tail situations, and adversarial prompts.
Layer deterministic checks, grounded tests, calibrated model judging, human review, preference testing, and red teaming.
Evaluate agent actions and task completion, not only the fluency of the final response.
Run relevant regressions whenever prompts, models, retrieval, knowledge, tools, or workflows change.
Use offline evaluation to control release risk and live experimentation to validate customer and business impact.
Fund, refine, pause, or kill bets based on evidence maturity rather than demo quality or sunk effort.
At your next roadmap review, pick one upcoming AI bet and pause the implementation discussion until its decision contract is complete. Then run the current workflow through a representative evaluation set before changing it. That baseline gives every later improvement something honest to beat.
When each investment has a visible path from user problem to evaluation to decision, AI innovation stops being a contest between plausible demos. It becomes a repeatable way to allocate attention, manage risk, and scale the capabilities that produce durable value.
It’s Monday morning, and my Slack and email are already overflowing with content requests: “Can you review this flow?”; “Can you rewrite this screen?”; “Can you name this feature?” I’m not freshly back from holiday—this is just a regular work week kicking off. If you’ve ever been a solo content designer supporting multiple teams, you’ll recognize the pressure. The pipeline for content in product design is always full, and the demand for expertise never stops.
Fixing this isn’t just a matter of better time management or incremental process tweaks. To truly scale, I needed to extend my reach by bringing AI into the design process—without sacrificing judgment, standards, or quality. That Monday morning, I realized I had to scale my skills, my judgment, and our systems, not just my calendar.
Building AI is fundamentally about building systems. I wanted to use AI to scale myself without devaluing critical thinking or flooding the product with generic, verbose content. I also knew a useful AI tool must do more than spit out microcopy—it has to plug into a system we can continually shape. As a content designer, the system is always the starting point. Strong design systems create strong content standards; then AI agents can produce content that meets those standards at speed, freeing me from the bulk of standardized work. That’s not a threat—it’s an advantage. To instruct AI well, our systems must be well constructed.
I often think about this work like a bakery. You need a recipe before you can make a loaf of bread. Most interface content churns out the same loaf, day in and day out. It’s better for the master bakers to focus on the unique, custom bakes—and how the recipe needs to change. With that mindset, I set out to build an AI content design agent.
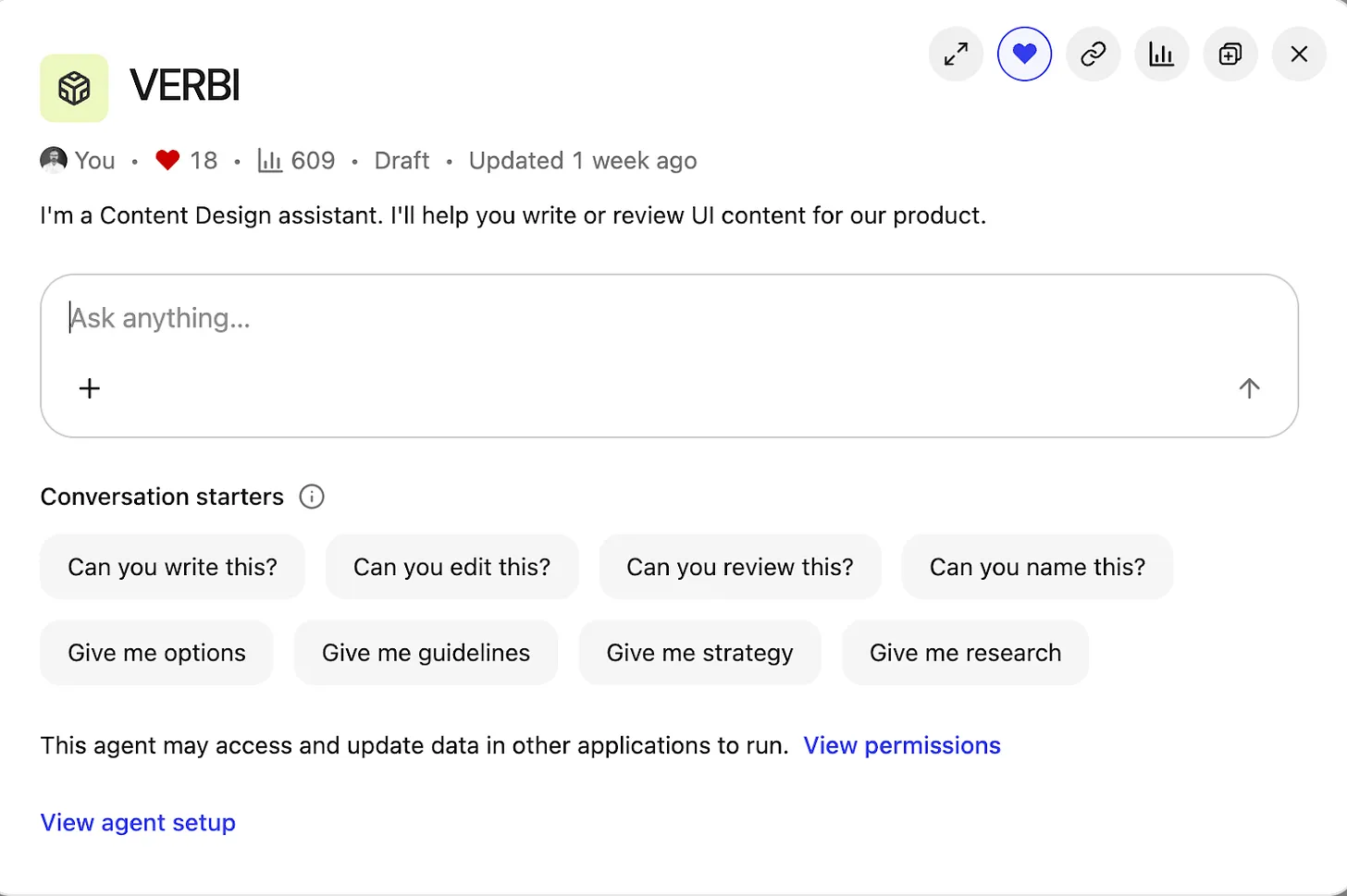
Inside the Content Design Agent workspace, a clean chat UI titled VERBI pairs a central prompt box with chips for writing, editing, and reviews, plus clear controls to view permissions and open the agent setup for product teams.
When I started this project back in May 2025, many LLMs still had frustrating limitations. Google Gemini let me build a custom Gem agent, but I couldn’t share it with other users. ChatGPT could be customized, but only with static files: I couldn’t point it to live, updatable URL sources. I settled on Glean for three simple reasons: everyone at the company had access; Glean could access all internal documentation and treat URLs as sources of truth; and its then-new Agents feature made AI search customizable. Configuring an agent in Glean is straightforward—you choose a trigger, a set of prompts, and a set of actions—but first I needed to get the inputs right.
AI agents need focus. We had a wealth of internal information at Intercom, but not all of it was current or reliable. I curated exactly what the agent could access and assembled a tightly governed knowledge collection in Glean. Only essential information made the cut: the Intercom style guide—our definitive house style, including regularly-broken rules like “always write in US English” and “use sentence case everywhere”; tone of voice guidance for how we show up across mediums; a product glossary with hundreds of feature names and writing conventions; a monetization glossary for prices, plans, and add-ons; product marketing messaging guides with positioning for every feature and launch; core research insights across the product; and fin.ai and intercom.com/suite as the official, most up-to-date messaging sources.
This is classic RAG (retrieval-augmented generation) in action, ensuring every answer is grounded in approved sources of truth. With the collection in place, I instructed the agent to prioritize these resources above anything else.
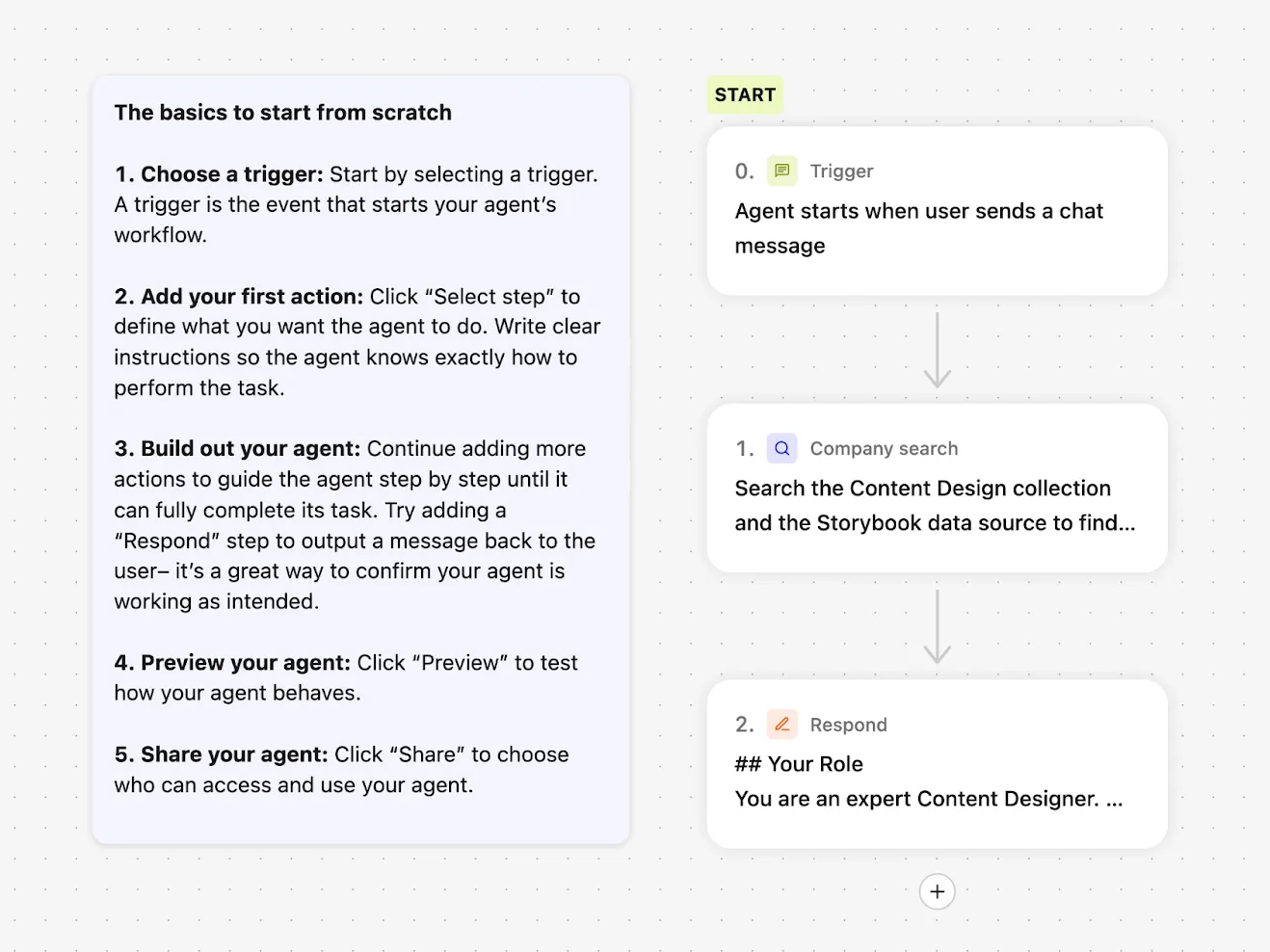
Step into a clean, no-code builder that shows how to assemble a Content Design Agent: kick off with a chat-trigger, run a company search, then respond with expert guidance, all guided by a simple starter checklist.
Then came the fun part—building and branding the agent. “Content Design Assistant” felt bland, so I named it VERBI, a nod to its “verbal” design job. When people interact with VERBI, they usually begin with a question, but the intent varies widely. I defined a set of task prompts to guide expectations and outputs: “Can you write this?”; “Can you edit this?”; “Can you review this?”; “Can you name this?”; “Give me options”; “Give me guidance”; “Give me strategy”; “Give me research.” This mirrors the real breadth of content design, from creation to critique to discovery.
To manage responses, VERBI needed three things: start with a specific task prompt; understand how to draw on the right resources each time; and connect with other systems. With task prompts defined, I wrote a detailed system prompt covering the essentials. Role: you are a content designer, supporting product designers. Employer: Intercom (consisting of Fin AI Agent and our next-gen Helpdesk). Resources: content design collection, research collection, Storybook design system. Tone of voice: follow a specific tone for our UI, adjust the tone for everything else. Components: for UI, use the specific guidelines in our design system only. Use cases: writing, editing, critiquing, naming, researching, and more.
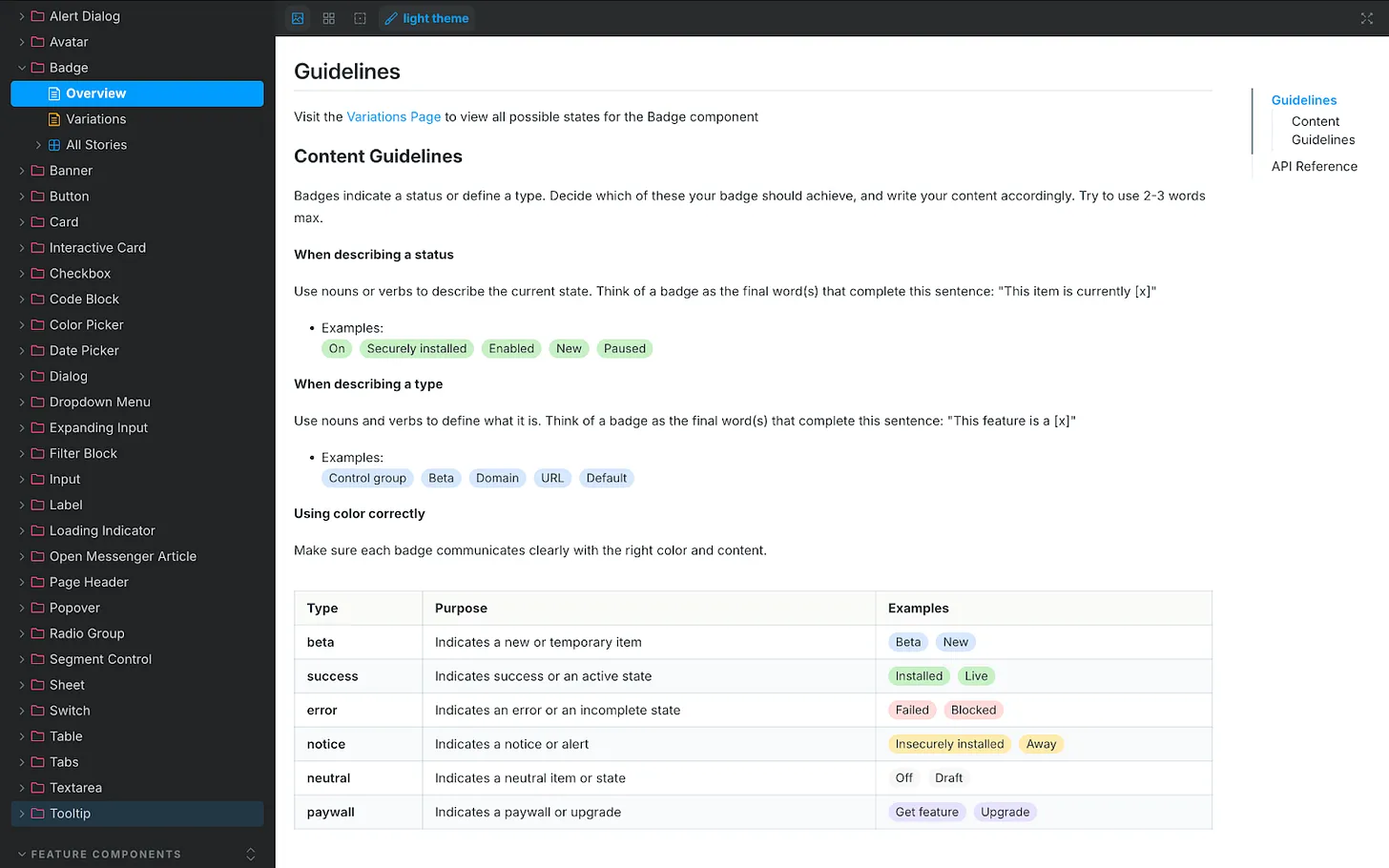
One connection mattered most: our design system, recently rebranded as “Surge.” Surge contains detailed content guidelines for every component in our product UI, from accordions and banners to tabs and tooltips. That granularity took months of human effort to codify, and it paid off. Designers no longer guess how to write for a toggle, a button, or a tooltip—and now VERBI understands and enforces those rules, too. A great content design assistant isn’t just a clever system prompt; it needs deep, component-level guidance to retrieve.
UI documentation showcases the Badge component’s content rules, teaching how to name statuses, define types, and apply color so labels read clearly. A handy visual for building a content design agent and ensuring consistent product messaging.
Accessing the design system wasn’t simple at first. It lives in Storybook, which Glean couldn’t access directly. I started by scraping guidance from Storybook into an HTML file with Cursor and uploading it to VERBI—a functional but clunky workaround that required re-scraping every few days. Then our IT team stepped in. They used the Glean Indexing API to turn Storybook into a live data source. Now VERBI connects to Storybook directly. Ask it something ultra-specific, like the correct date format for Japan, and it returns the right answer. That integration elevated the agent from helpful to indispensable—human-level precision, 24/7, at scale.
With prompts and resources in place, I launched VERBI and pressure-tested it. It was accurate and well-informed most of the time, but like any AI agent, it had quirks. I needed it to act as a gatekeeper, not a brainstorming partner that might bend rules or invent new ones. So I added a few explicit guardrails to the system prompt. Stopping sycophancy: “Inform, challenge, and assist. Never placate. Don’t agree by default. If something’s wrong, say so. Challenge assumptions.” Halting hallucinations: “If you don’t find the information required in our resources, say you don’t know the answer. Don’t guess and don’t give answers based on general knowledge.” Avoiding verbosity: “Keep answers short and to the point. Cut the fluff. Skip all niceties and social padding. Only give longer answers if the user asks you to.” These constraints keep responses crisp, correct, and consistent. Like any living system, the prompt needs occasional tune-ups, but the maintenance is minor compared to the upside.
Where we are now: VERBI has been triggered 700+ times since launch. The benefits are tangible. For me, quality scales without constant policing; repetitive questions about naming, style, or punctuation have dropped significantly. I reclaim time because the agent drafts and checks V1 content across teams, enabling me to focus on higher-impact work. For the design team, iteration is faster, confidence is higher, and strategic clarity improves because shared language and grounded guidelines make decisions easier and more consistent.
I used to spend too much time mopping up basic content mistakes and untangling spaghetti-like UI copy prone to human error. VERBI removes those errors at the source. The real advantage is speed: we get from blank slate to a high-quality first draft quickly, which means we can spend our energy deciding whether the content is right, not just “good enough.” Design is the whole interface—words, visuals, interactions—so reviews now happen with real content, never “copy TBD.” Our principle to sweat the details applies equally whether work is human-made or AI-assisted.
Knee-jerk critiques of AI-driven content design often assume teams generate content from nothing and ship it. In reality, great AI is the outcome of great human decisions and strong systems. Its value is pulling us together faster—getting us to a complete, standards-compliant design we can review as a team before sharing it with the world. That’s how AI helps us win: by turning chaos into consistency, and consistency into velocity.
Over the past year, I’ve been shipping agentic AI into production and coaching product teams on what it really takes to make these systems trustworthy in the wild. One story that crystallizes the playbook comes from Trainline’s move to an agentic architecture for travel assistance—an approach that mirrors what I’ve seen work in high-stakes, real-time customer experiences.
Trainline—the world’s leading rail and coach platform—helps millions of travelers get from point A to point B. Now, they’re using AI to make every step of the journey smoother.
I studied how "David Eason (Principal Product Manager) Billie Bradley (Product Manager), and Matt Farrelly (Head of AI and Machine Learning)" approached the build of "Travel Assistant, an AI-powered travel companion that helps customers navigate disruptions, find real-time answers, and travel with confidence." Their work exemplifies the kind of end-to-end thinking required to move beyond demos into dependable, on-the-go assistance.
They share how they: Identified underserved traveler needs beyond ticketing; Built a fully agentic system from day one, combining orchestration, tools, and reasoning loops; Designed layered guardrails for safety, grounding, and human handoff; Expanded from 450 to 700,000 curated pages of information for retrieval; Developed LLM-as-judge evals and a custom user context simulator to measure quality in real-time; Balanced latency, UX, and reliability to make AI assistance feel trustworthy on the go.
I align strongly with their core takeaways: "AI assistants need both scalable reasoning and deep domain context to be useful." "Tool design and guardrails are as critical as prompt design in agent systems." "LLM-as-judge evals make it possible to measure open-ended systems without massive labeling costs." And perhaps most importantly, "Even legacy companies can move fast when they embrace experimentation and tight PM–engineering collaboration."
From an AI strategy perspective, starting "fully agentic" was the right call. When the problem space is dynamic—disruptions, route changes, fare conditions—reasoning loops and orchestration aren’t luxuries; they’re table stakes. Tool selection becomes product design: you need the right retrieval interfaces, constraint-aware planners, and API contracts that are resilient to partial failures. Layered guardrails for safety, grounding, and human handoff reduce hallucination risk while preserving responsiveness—critical when users are standing on a platform waiting for an answer.
The retrieval scale-up—"Expanded from 450 to 700,000 curated pages of information for retrieval"—is a classic inflection point. I’ve seen teams stall here when they treat content growth as a pure indexing problem. The winning move is curation and structure: normalize sources, encode policy-level constraints, and align retrieval chunks to decision boundaries the agent actually uses. That’s how you keep precision high while coverage explodes.
Evaluation is where most open-ended assistants fail quietly, which is why I was encouraged to see "Developed LLM-as-judge evals and a custom user context simulator to measure quality in real-time." In practice, LLM-as-judge gives you scalable, scenario-based scoring without prohibitive labeling, while a user context simulator surfaces regressions tied to persona, itinerary state, and device constraints. The combination closes the loop between model behavior, tool layer changes, and UX outcomes.
On product delivery, the decision to have the system "Balanced latency, UX, and reliability to make AI assistance feel trustworthy on the go" shows mature prioritization. For travel, trust accrues in seconds: fast-enough responses, graceful degradation when upstream data lags, and explicit handoff when confidence dips. This is where guardrails meet UX writing—clear, bounded language signals competence even when the system defers.
Finally, the organizational pattern matters. The teams that win in agentic AI are cross-functional, experimentation-driven, and ruthless about instrumentation. Tight PM–engineering collaboration, explicit safety thresholds, and an eval stack that mirrors real user journeys are what turn promising architectures into dependable products.
It’s a behind-the-scenes look at how an established company is embracing new AI architectures to serve customers at scale.
If you’re building agentic AI in production, borrow these moves: invest early in tool and guardrail design, scale retrieval with curation not just volume, adopt LLM-as-judge plus context simulation for continuous evaluation, and treat latency and reliability as core product requirements—not afterthoughts. That’s how you ship AI assistance that customers trust when it matters most.
I’m excited to share that we’re opening our next R&D hub in Berlin to support significant investment in our AI customer service platform, Intercom, and market-leading AI Agent, Fin. We intend to hire 100 people in Berlin over the year ahead across engineering, AI, data science, product, and design. This move reflects our AI Strategy, our commitment to product management leadership, and our focus on building enduring product-led growth.
We believe that in a short number of years, the vast majority of customer service will be done by AI. Fin is already the world’s best Customer Service Agent. At Pioneer, our recent summit for AI customer service leaders in NYC, we talked about how Fin will become a true end-to-end Customer Agent, extending far beyond service. We showcased how companies like WHOOP, Anthropic, and Lightspeed are already pushing Fin in ways that help them grow their business.
This market opportunity is massive and expanding at unprecedented pace. Our ambition is to earn our place as one of the most successful AI businesses during this wave of AI disruption, and we want more brilliant people on our team to pursue this as aggressively as possible. If you’re motivated by Generative AI, LLMs, and building real products that scale, you’ll find both challenge and impact here.
We are already on track to be one of the fastest growing private software companies. Fin is the primary contributor to this, and is months away from passing $100m in ARR. So far, more than 7000 businesses have transformed their customer service with Fin, including German companies like electricity provider Ostrom, smart home technology provider tado°, and grocery delivery company Flink, along with global leaders like Vanta, Clay, Lovable, and Miro.
Why Berlin? We’re drawn to the city’s rare blend of deep technical talent and rich creative culture—within a vibrant, globally connected ecosystem close to our R&D hubs in Dublin and London. It’s a place where top-tier engineers and designers thrive, and where ambitious builders from around the world want to relocate and create category-defining products.
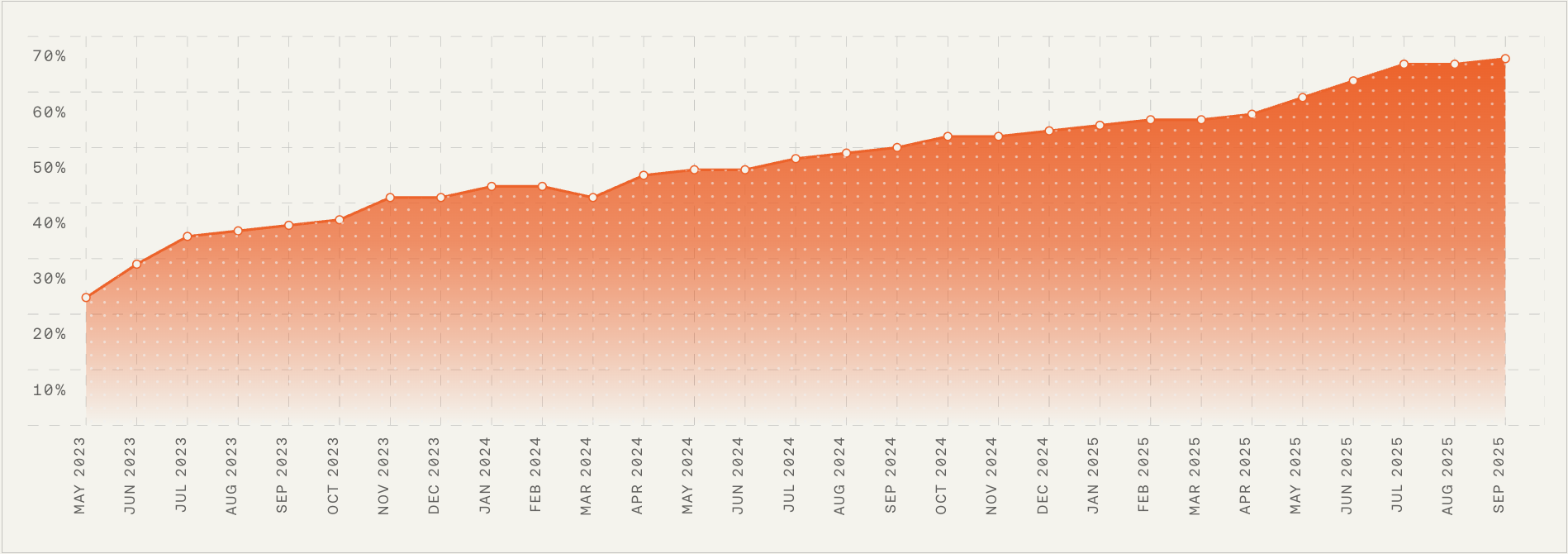
Momentum is building: this month-by-month chart shows a consistent rise from the mid-20s to nearly 70% between May 2023 and Sep 2025—signaling strong progress as we expand engineering, AI, and automation at our new Berlin R&D hub.
We needed a new location that would sustain the high ambition and standards held by our world-class AI teams in Dublin and London. Berlin has emerged as one of Europe’s hottest centers for AI talent, with a high density of AI-focused startups, applied research labs, and practitioners who bring exceptional literacy, optimism, and ambition. It’s the right accelerator for our AI hiring and a place to bring in brilliant minds to shape the future of our product and business.
While Intercom’s reach is global with our headquarters in San Francisco, our R&D leadership remains anchored in Dublin, where half of the executive team sits—making Berlin both geographically and strategically an ideal next location for our growth.
This isn’t our first time expanding our footprint; we previously bet on London and are delighted with how that’s been working. When we shared our Berlin news internally, the energy was palpable, with many teammates volunteering to help spin up the hub successfully—including colleagues who helped make London a big success, like Danny. That level of ownership and momentum is exactly what we aim to cultivate in Berlin.
We’re looking for people who thrive in a high-intensity, high-ambition, high-standards environment and want to help build one of the world’s best AI companies. For builders like that, the opportunity for impact, growth, and career progression is extraordinary. As with London and Dublin before it, the early Berlin cohort will have a disproportionate influence on team norms, culture, and long-term outcomes. We are in the middle of a huge disruptive wave with AI, and Fin is one of the leading examples of commercially successful AI applications. Joining Intercom is an opportunity to be part of this disruptive wave, and help us build out our vision for Fin becoming the world’s best Customer Agent.
On a minimalist stage, four speakers share insights on AI research, automation, and engineering as part of a panel tied to Berlin expansion and the launch of a new European R&D hub.
There are plenty of AI companies to join, but our technology and culture set us apart. Any AI product is only as good as the AI layer powering it. Ours is industry-leading, built by a highly talented, ambitious, and technical team of over 40 machine learning scientists, engineers, and designers in Europe who continuously optimize Fin’s performance through cutting-edge research, experimentation, and innovation. Fin’s average resolution rate increases 1% every month. That kind of steady, compounding improvement is exactly what great customer support AI strategy looks like in practice.
We also build in public and share our progress and learnings with the AI community at large. Recently, our Chief AI Officer Fergal Reid and SVP of Engineering Jordan Neill joined leaders from Cognition, Harvey, and Perplexity in San Francisco to share real lessons, challenges, and breakthroughs from building frontier AI products. Our AI team regularly publishes their insights on the AI research blog; from optimizing inference speed and availability, to building our own proprietary models that outperform general purpose models for CX.
Our AI group and the broader R&D org they operate within work at extraordinary scale and speed. We recognize that moving fast can’t be taken for granted—you must fight for it—and we’re doing just that, embracing the capabilities AI tooling brings us to achieve 2x the throughput. One example of this mindset in practice is us “Betting on the future of frontend at Intercom,” making a technology choice that optimizes for our teams’ ability to build high-quality product, fast.
Our design and product teams are world-class and forward-thinking; they’re embracing AI to evolve how they work, as shared in our 3-point framework for AI-driven design and recently presented by Emmet Connolly, our SVP of Design, at this year’s Hatch conference in Berlin. As a product leader, I’m grateful to work alongside brilliant product and design thinkers—it gives me confidence that we’re solving the right problems, solving them well, and driving real impact.
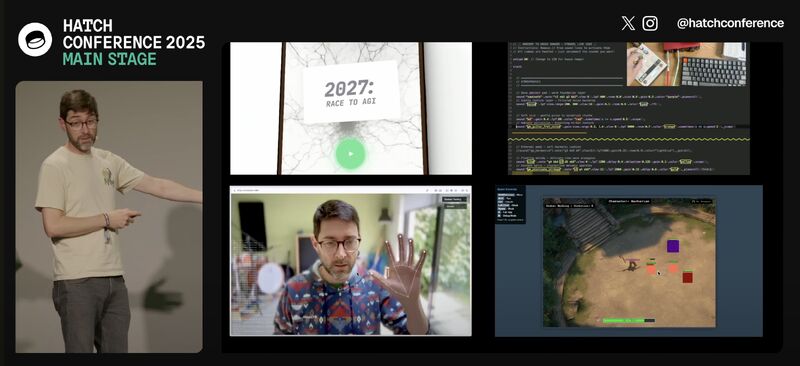
From live demos to hands-on coding, this snapshot captures the momentum we're bringing to our Berlin R&D hub – AI experiments, hand-tracking prototypes, and simulation tools powering our next wave of engineering.
We plan to open our Berlin office space in December or January. To get the office started, we’re hiring Senior Product Engineers, Machine Learning Scientists, Product Managers, Senior Product Designers, Engineering Managers, and Data Scientists immediately. If your craft sits at the intersection of LLMs for product managers, agentic AI, and empowered product teams, you’ll be right at home.
You can learn more about our open roles, company, culture, and locations on our careers site, or feel free to reach out to me, Jordan, Fergal, or Brian directly on LinkedIn if you have any questions.
Some of our engineering team will also be at LeadDev Berlin on November 3rd—come say hi if you’re attending.
I’m looking forward to continuing to build Intercom as one of our generation’s best AI companies—and I’m excited for our expansion into Berlin to be a major contribution to that success.
Context is king in AI-powered product work—and I felt that deeply while digging into “Context is King – All Things Product Podcast with Teresa Torres & Petra Wille.” The conversation affirmed a truth I see daily: AI becomes a powerful teammate only when we give it the right context, just as we do with empowered product teams. When we treat AI like a colleague joining mid-flight—without our company history, industry nuances, or strategy—we instantly unlock better outcomes.
Listen to this episode on: Spotify | Apple Podcasts
Here’s what stood out and how I’m applying it. First, most AI outputs fail without proper context. That’s not a model problem; it’s a leadership problem. Thinking of AI like onboarding a new intern is the right mental model—start with the minimum viable context, then iterate. Practical first steps matter: decision logs, clear success metrics, and structured documentation. The art is balancing enough context to guide performance without overloading the system. The parallels are striking: the way we create strategic context for product trios and teams is the same way we’ll empower agentic AI systems.
In my teams, we prepare for AI collaboration by operationalizing context. We keep decision logs to capture the why behind choices, use outcome-based success metrics (not just output), and maintain machine-readable documentation that LLMs for product managers can parse reliably. We define guardrails up front—constraints, customer segments, privacy-by-design considerations, and the non-goals that often trip up gen ai. This foundation turns AI from a novelty into a force multiplier for product discovery and product roadmapping and sprint planning.
I use a simple “context pack” to onboard AI agents and teammates alike: 1) business goals and outcomes, 2) constraints and guardrails, 3) canonical artifacts (like PRDs, journey maps, interview notes), 4) domain vocabulary and definitions, and 5) operating procedures (how we make decisions, when to escalate, what good looks like). Start small, then refine as the AI demonstrates capability. This mirrors great onboarding—and it works just as well for agentic AI as it does for humans.
Not all context is helpful. More isn’t better; the minimum effective context is. I resist the urge to dump our entire Confluence on an AI system. Instead, I progressively reveal relevant details—just like I would with a new PM on a complex problem space. This keeps signals high, noise low, and performance measurable against clear success metrics.
If your org isn’t adopting AI yet, don’t wait. You can become AI-ready now by documenting strategic intent, decision rationale, and definitions in structured, searchable, machine-readable ways. Treat this as core AI Strategy work that strengthens empowered product teams—regardless of tooling—while building your AI product toolbox for tomorrow.
For those who want to explore further, these resources and mentions are a strong complement to the episode’s themes.
Follow Teresa Torres: https://ProductTalk.org
Follow Petra Wille: https://Petra-Wille.com
Agentic AI
Teresa’s new podcast, Just Now Possible in Youtube, Apple Podcast, and Spotify
Petra’s Coaching Packages
ChatGPT
Henrik Kniberg’s talk at Product at Heart on treating AI agents like interns
Teresa’s webinars on how she built the Product Talk Interview Coach: Behind the Scenes: Building the Product Talk Interview Coach and How I Designed & Implemented Evals for Product Talk’s Interview Coach
Josh Seiden’s blog series about AI
Teresa’s new blog posts: 15 Ways to Use AI at Home (and Fill Your AI Product Toolbox) and 21 Ways to Use AI at Work (And Build Your AI Product Toolbox)
Petra's new blog post: Why Context, Not Just Data, Will Define AI-Ready Product Teams
Have thoughts on this episode or how you’re preparing your teams to collaborate with AI? Leave a comment below—let’s compare playbooks and level up together.
Digital transformation rewired our systems; AI transformation rewires how we learn, decide, and compete. “AI transformation goes beyond automation to create adaptive, intelligent organizations. Discover why it’s the next imperative and how to measure success.” That statement captures what I experience daily: we’re moving from scripted workflows to living systems that improve with every interaction.
When I talk about AI transformation, I’m not describing a tool rollout. I’m describing an operating model where data, models, and product strategy converge to create compounding advantage. In practice, that means agentic AI orchestrating tasks, robust data governance and privacy-by-design from day one, and empowered product teams that ship, measure, and iterate at high tempo.
The imperative is strategic, not merely technical. Markets are compressing cycle times, and customers now expect intelligent experiences by default. Organizations that master AI Strategy and product-led growth will set the pace—using AI for competitive differentiation rather than feature parity.
This shift changes how I build teams and backlogs. I lean on product trios, forward deployed engineers, and tight product discovery loops to reduce uncertainty early. We design for resilience and learning: human-in-the-loop feedback, clear escalation paths, and telemetry that turns every interaction into a hypothesis test.
Governance is a first-class feature. AI risk management, data governance, and threat detection and response sit alongside performance metrics in the same dashboard. We codify guardrails—policy, provenance, and permissions—so innovation scales safely and sustainably.
Measurement is where transformation becomes real. I anchor on outcomes vs output OKRs tied to customer value and revenue impact. At the product layer, I track activation, time-to-value, retention, and adoption by persona. For ML quality, I monitor precision/recall, coverage, hallucination rate, and model drift. In experimentation, A/B testing with a thoughtful minimum detectable effect (MDE) prevents false wins, while Amplitude analytics, Pendo, and Intercom instrumentation expose where guidance or UX writing can unlock activation.
The fastest wins often start in service and sales. A customer support ai strategy can deflect tickets with high-resolution answers while escalating edge cases to humans with full context. CRM integration with HubSpot and a ChatGPT connector enables reps to generate next-best-actions, summarize calls, and personalize outreach—measurably lifting conversion and lowering cost-to-serve.
On the build side, LLMs for product managers and gen ai for product prototyping accelerate discovery cycles. I use CustomGPT workflows to validate value propositions quickly, then harden successful flows with engineering. Throughout, product positioning and a crisp value proposition ensure that what we ship is understandable, differentiated, and priced to match ROI—consumption SaaS pricing when usage scales value.
If you’re getting started, begin with a single, high-frequency journey, instrument it deeply, and publish transparent OKRs. Pair empowered product teams with clear governance, and iterate toward agentic AI experiences. The payoff isn’t a one-time launch; it’s a continuously learning system—and a culture—that compounds advantage release after release.