I’ve learned that the smallest slice of your support queue often dictates the majority of your operating cost, customer memory, and automation ceiling. In product reviews and CX ops deep-dives, I see the same pattern: the “easy” tickets pad your resolution counts, but the complex, multi-step queries quietly own your handle time and your brand trust. If you care about compounding impact, your customer support AI strategy has to target that hardest percentage first.
Complex queries are a small percentage of your queue, but they consume a disproportionate share of your team’s time.
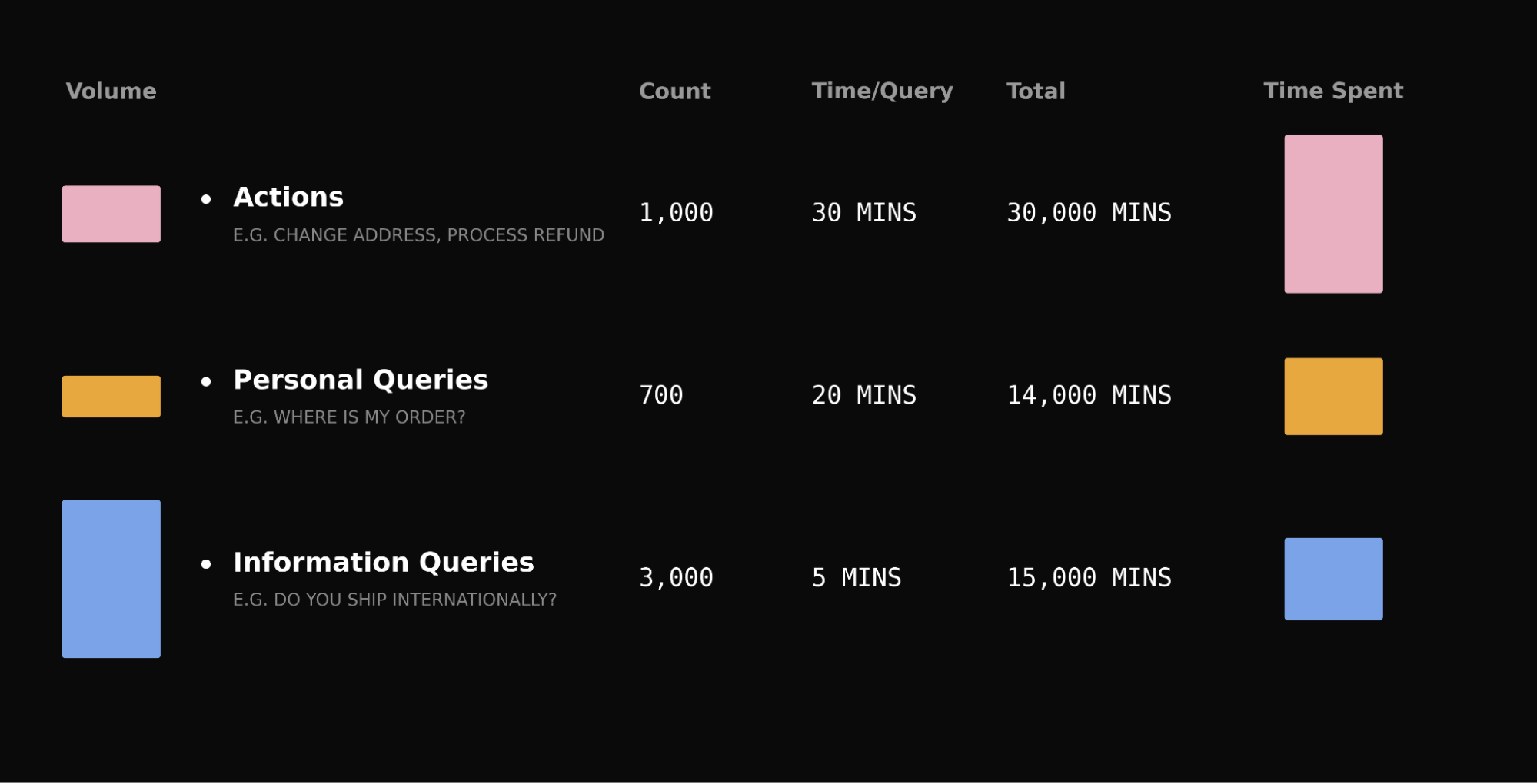
Take a typical queue: password resets outnumber refund disputes ten to one, but a reset takes five minutes and a dispute takes thirty. The “rare” query accounts for over a third of total handling time. The same pattern holds for account investigations, subscription changes, and billing disputes.
How you handle complex queries is also what customers actually remember about their support experience. When someone is dealing with a damaged order or a billing dispute, the stakes are higher, and a fast, good resolution is what separates a forgettable interaction from one that builds lasting trust.
Most AI Agents automate the easy, informational queries well. The question for your automation rate is whether they can handle the hard ones. That’s where agentic AI and robust AI workflows make or break your outcomes.
We’ve gotten really good at informational queries – the hard part is what comes next. I’ve seen teams invest deeply here, and for good reason: it lifts containment quickly and cheaply. But to break through the plateau, you have to execute actions across systems, not just answer with text.
We’ve invested deeply in informational Q&A. We built Apex, a specialized customer service model trained on billions of support interactions, as Fin’s core answering engine. Beneath that sits a custom retrieval model, a purpose-built reranker, and a unified RAG pipeline, all trained specifically for customer service. Fin resolves issues at a higher rate than general-purpose frontier models, with fewer hallucinations and at lower cost.
But informational Q&A only covers queries where text is the answer. Most Agents can handle that. Far fewer let you configure complex, multi-step actions without a forward-deployed engineer setting it up for you, which creates a gap.
Every query your team handles falls into one of three categories:
Informational: “Can you ship transatlantic by priority next day?” Answered with text from your knowledge base.
Personalized: “Where is my order?” Requires data unique to that user.
Action-led: “My order arrived damaged, I need a refund.” Requires doing something: checking a return window, cross-referencing transaction data, making a judgment call – reading from multiple systems and acting across them.
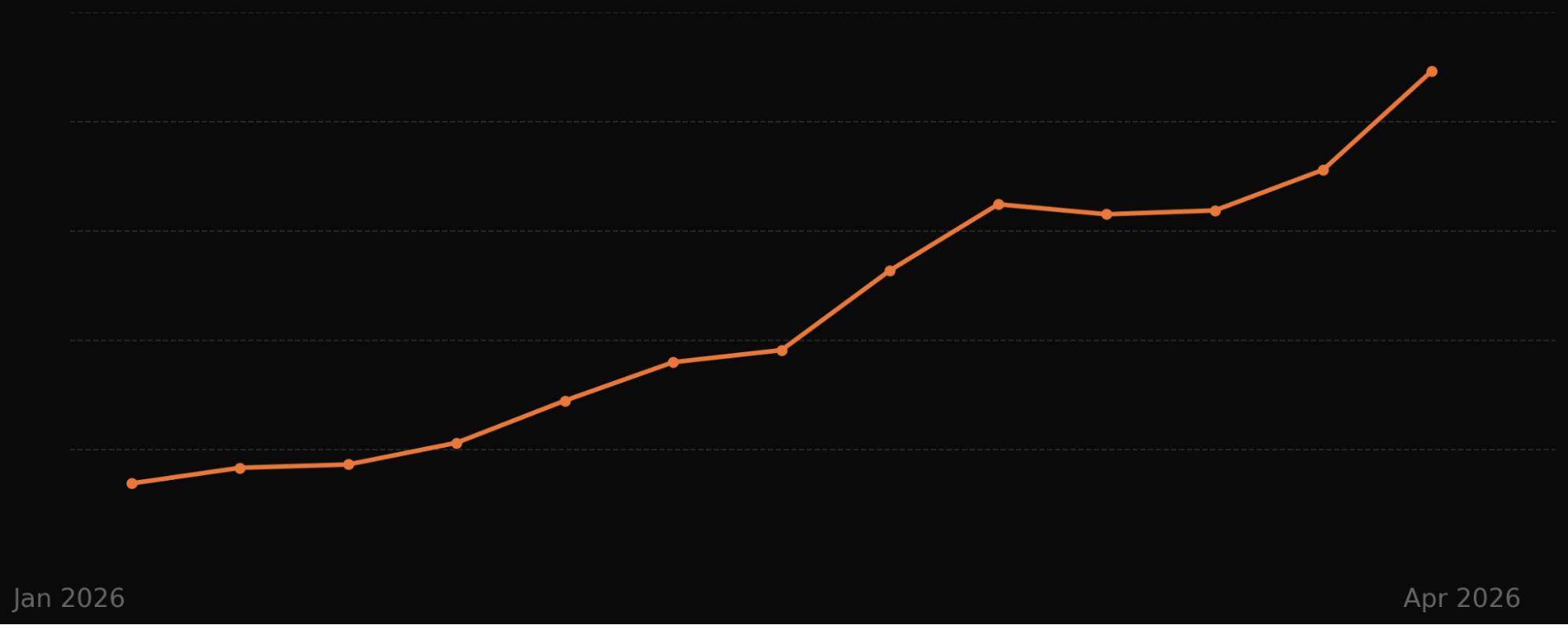
These complex queries, the ones that require multi-step processes across systems, aren’t edge cases; they’re the reason your support team exists. This is the gap Fin Procedures was built to close.
It works in practice, and the trajectory matters for product strategy and ops planning.
Procedures is live, it’s scaling, and the results are clear. Since launching in managed availability, Procedures has handled over 1.5 million conversations, and volume is doubling month over month across hundreds of apps in fintech, e-commerce, gaming, healthcare, and SaaS.
When customers hit complex, multi-step queries, the experience is dramatically better when Fin can do the work end-to-end. We tested this with a randomized 5% holdout – conversations where Procedures would normally run, but didn’t. CSAT was 28.93% higher when Procedures ran, a statistically significant result.
A product, not a services engagement. I’ve sat through too many “automation” projects that were really solutions engineering gigs: workshops, custom scripts, then a queue of change requests when policies shift. It’s fragile and slow.
The B2B AI industry has a consultingware problem. It’s not databases being forked anymore, it’s prompts. The economics of maintaining bespoke setups per customer don’t work. Either the application falls behind new models, or the vendor changes the model and quality degrades invisibly.
In my view, an agentic AI platform should be a product your team owns end to end: a natural language editor – literally paste your existing SOPs – branching logic, data connectors, and AI-powered simulations for testing. Your CX ops team configures this, iterates on it, owns it. If you need help, a forward-deployed team can assist, but they’re optional, not a dependency. You always have control.
And because it’s a unified product, improvement compounds. When the vendor optimizes a prompt, every customer’s Procedures get better. When they upgrade the model, they can A/B test across the entire customer base and know it’s better before rolling out. You can’t do that when every customer has a bespoke prompt. The consulting model isn’t just expensive, it’s structurally unable to compound.
Today, Fin Procedures is available to every Intercom customer – no waitlist or managed rollout, ready for all 8,000+ customers.
We’re iterating fast based on real customer feedback. Here’s what’s landed since the last major update, and why it matters for reliability and governance:
AI-powered Procedure review: Flags broken logic, missing references, and unreachable conditions before you deploy.

Procedure failure reporting: A new reporting dimension that lets you drill into conversations where Procedures failed, so you can diagnose and fix.
Version history with rollback: Track every change, compare versions, roll back if needed.
Data connector health monitoring: See at a glance if your integrations are healthy, degraded, or failing.
Optional data connector parameters: Fin only asks customers for information when it’s actually needed, instead of prompting for every field.
Email Simulation support: Test how your Procedures behave across chat and email before going live.
Agent in the Loop (Beta) unlocks the next tranche of automation. Even with Procedures, two things hold teams back from automating their most complex queries: missing integrations and policies that require a human sign-off on sensitive decisions.
“Agent in the Loop” is built for both. Need Fin to check your internal admin tools but haven’t built a data connector yet? Put a human checkpoint at that step. Fin handles the conversation, gathers context, and pauses, surfacing a structured summary for a human agent to verify or act, then resumes. You get automation on the 80% that doesn’t need the integration.
For compliance – identity verification, high-value refunds – Fin does the legwork, a human makes the final call and then hands it back to Fin. This works natively in the Intercom Inbox and via Slack. Some competitors don’t have an inbox-native variant at all, meaning humans need to leave their primary workspace to review AI actions.
Procedures are also built to let you collaborate with all your teammates – both human agents and AI Agents. Fin can work with them directly inside a Procedure, using APIs and webhooks to loop in another teammate mid-flow, hand off context, and pick back up once they’re done.
Making it easier, faster. Procedures is already self-serve, but the next step is making Procedure creation, testing, and maintenance significantly more streamlined and easy to do, with less manual editing and more AI-assisted building and debugging. There’s a lot coming in this space over the next few months – and it aligns perfectly with a retrieval-first pipeline and stronger governance at scale.
The hardest percentages matter the most. The biggest unlock for your automation rate won’t be answering more FAQs, it will be handling the complex, multi-step queries that consume your team’s time and define what customers remember about their experience with you.
That means working with an Agent that goes beyond answering questions and executes processes. A product your team owns and configures, not a service you buy and hope gets maintained. And a platform where every improvement compounds across every customer. That’s Procedures. Available now, for everyone.
Inspired by this post on The Intercom Blog.