Your roadmap is full, every function has a planning ritual, and experienced people are working hard. Yet decisions still wait, priorities keep reopening, and substantial work reaches customers later than anyone expected. Adding another process layer will not solve that problem.
You need an execution system: explicit ownership, small batches, a dependable decision cadence, direct customer feedback, and a scorecard that distinguishes progress from activity. When those elements reinforce one another, your teams can move faster without lowering the quality bar or routing every judgment through you.
Give each team an operating contract, not just a roadmap
A roadmap identifies intended destinations. It rarely tells a team how to make the decisions required to reach them. That gap is where autonomy turns into ambiguity: product believes it owns the sequence, engineering waits for scope to stabilize, design explores a wider problem, and an executive assumes a requested feature is already committed.
Before an initiative becomes active work, give the team a short operating contract. It should fit on one page and answer these questions:
- Whose problem are you solving, and in what specific scenario does it occur?
- What observable customer or business outcome should change if the work succeeds?
- Who is accountable for the initiative and its sequence?
- Which constraints are fixed, and which assumptions remain open?
- What is explicitly outside the current scope?
- What is the smallest end-to-end slice that can produce useful evidence?
- What evidence will support the next decision?
- When will that decision be made, and who has the right to make it?
The owner is not the person who approves every task. The owner keeps the problem, outcome, sequence, and unresolved decisions coherent. Engineering, design, research, and product still make solution decisions together inside the stated boundaries.
This contract also protects the team from executive requests that arrive as solutions without context. When someone asks for a feature, do not turn the request directly into a backlog item. Translate it into a problem entry first: the affected customer, the workflow that breaks, the evidence behind the request, the relevant constraint, and the result the requester expects. A commercially important request can remain urgent after that translation, but the team can now evaluate it rather than merely obey it.
Set escalation boundaries at the same time. A team should escalate when decision rights are unclear, two constraints conflict, a priority change affects another team, or the work crosses an agreed risk boundary. It should not need escalation merely because a solution choice is consequential. If every consequential choice travels upward, the team is not autonomous; it is a queue feeding a senior leader.
Finally, maintain one prioritized backlog for the team. Separate executive, product, engineering, and sales backlogs create hidden competition. The operating contract establishes the logic, and the single backlog makes the resulting sequence visible.
Run a weekly loop around decisions and customer learning
Many product cadences organize meetings while leaving decisions to happen unpredictably. A useful cadence does the opposite. Every recurring touchpoint should help the organization choose, learn, or remove a constraint.
A workable leadership week looks like this:
- Monday: Confirm the few priorities that matter, identify decisions that could block progress, and resolve changes in sequencing. Do not reread the entire roadmap.
- Midweek: Review selected product requirements, design flows, research findings, and engineering readiness. Concentrate on ambiguity, batch size, and untested assumptions.
- Thursday: Spend time with customers and partners. Put working slices in front of them when possible, and bring the resulting evidence back to the team.
- Friday: Write down what changed in your understanding. Update the backlog, decision log, and operating contracts where the evidence warrants it.
The sequence matters. Monday establishes intent. Midweek exposes execution risk while there is still time to change course. Customer contact tests the team’s reasoning. Friday turns scattered observations into organizational memory. Without the synthesis step, customer conversations can become interesting anecdotes that never alter a decision.
Make the weekly demo the heartbeat of the team. A good demo starts with the user scenario and the intended outcome, shows the smallest working behavior, states what the team learned, and ends with the next decision. A tour of completed tickets is not a substitute. For platform or infrastructure work, demonstrate working behavior, operational evidence, or a retired technical risk rather than manufacturing a customer-facing screen.
When a team repeatedly has nothing meaningful to demonstrate, inspect the system before questioning effort. The batch may be too large. A dependency may lack an owner. Decisions may be waiting in an approval queue. The team may be building several disconnected components before completing one testable path. The correction is usually to narrow the slice, clarify the decision, or remove the dependency.
A thin slice is not an arbitrary reduction in scope. It must preserve one coherent scenario, reach a state where someone can evaluate it, and create evidence for a consequential next choice. Backend, frontend, and enablement tasks can all be necessary, but completing them separately does not create a feedback loop.
Put product and revenue in the same operating loop
Product and revenue drift apart when they maintain different versions of the customer. Product sees research themes and usage behavior. Revenue sees active deals, objections, urgency, and willingness to pay. Neither view is sufficient on its own.
Use one customer narrative, one shared pipeline of problems worth solving, and one scorecard. Review them together every week. Each proposed problem should carry the customer segment, affected workflow, available evidence, commercial context, expected outcome, and complexity the solution could add.
Then make the sequencing decision explicit:
- Solve now: The problem is important enough, supported well enough, and compatible with the current strategy.
- Stage for scale: The need is credible, but the team must first validate the pattern, build a reusable foundation, or resolve a dependency.
- Do not add: The request is too narrow, conflicts with the product direction, or creates complexity that its value does not justify.
- Sunset: Existing functionality consumes attention without contributing enough customer value or strategic leverage.
This turns product-versus-sales conflict into a visible portfolio decision. Revenue contributes evidence and urgency. Product protects coherence and long-term defensibility. Both functions see why an item moved, waited, or stopped.
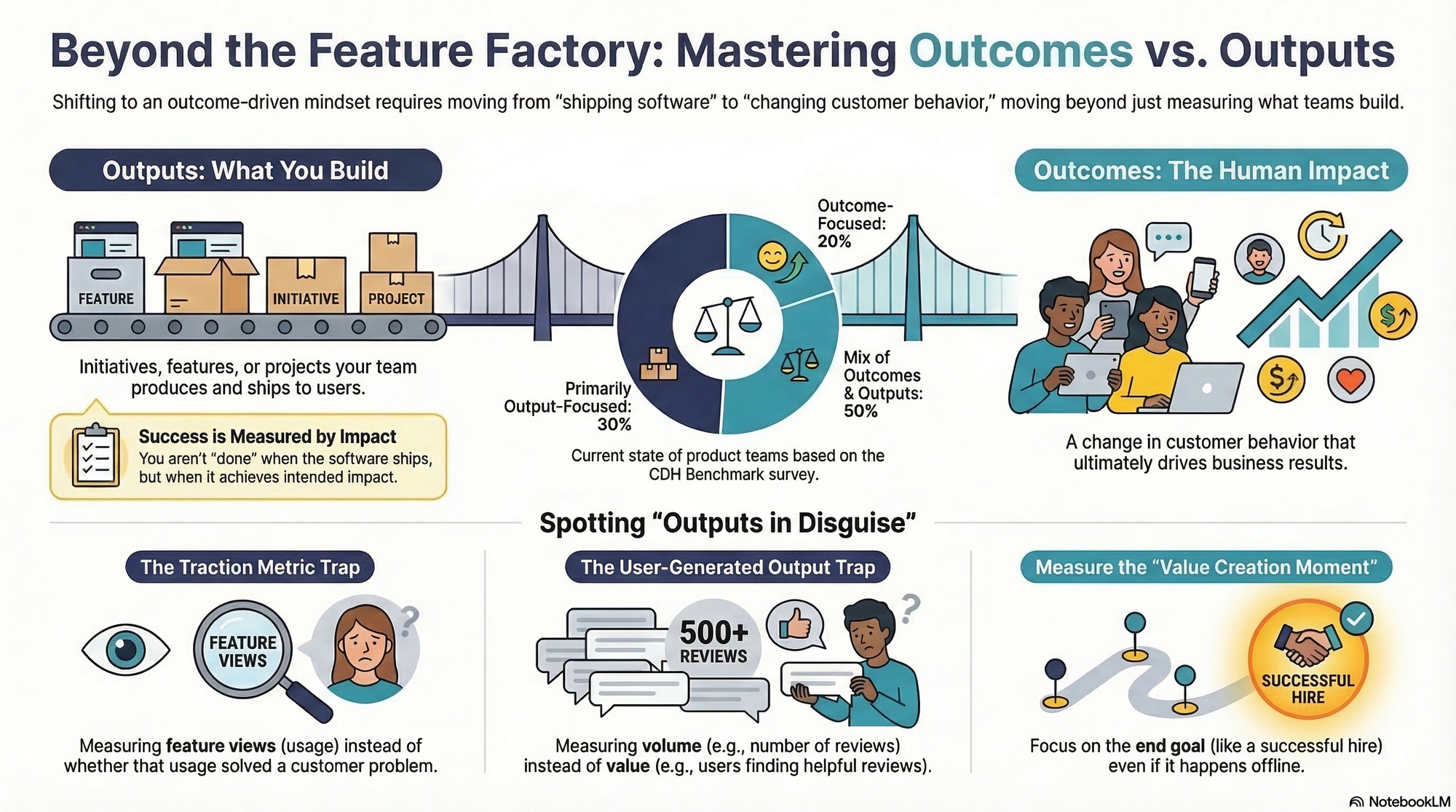
Measure outcomes, flow, and quality as separate signals
A team can ship frequently without improving a customer outcome. It can also improve an outcome temporarily while accumulating quality problems that make the pace unsustainable. Your scorecard needs to keep those conditions separate.
For each important bet, review three signal groups:
- Outcome: The observable customer or business result the team is trying to change, supported by current evidence rather than a list of releases.
- Flow: Deployment frequency and the age or state of the current thin slice. These signals reveal whether value and learning can move through the system.
- Quality: Change failure rate and the recurring friction exposed in customer feedback, support conversations, or postmortems.
Use the scorecard to direct attention, not to automate judgment. If deployment frequency is healthy but the intended outcome is not moving, inspect the hypothesis, target customer, and value proposition. More releases may simply deliver the wrong idea faster. If deployment frequency falls, examine batch size, dependencies, and delayed decisions. If change failure rate worsens, narrow the slice and strengthen readiness or recovery before asking the team to accelerate.
Do not rank unlike teams by raw deployment counts. Use trends within the relevant product and technical context. The point is to find constraints and make decisions, not to turn a diagnostic signal into a performance contest.
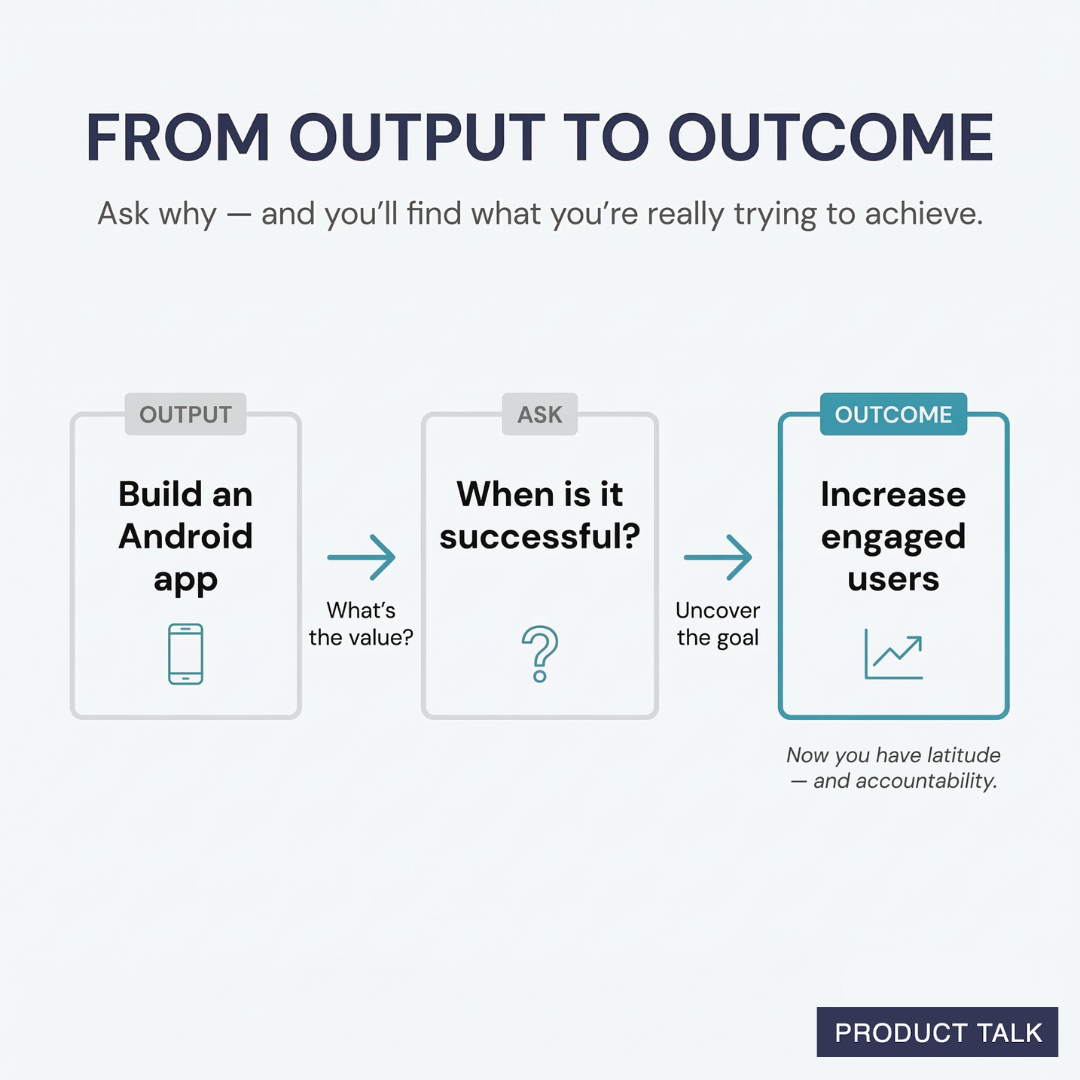
Write outcome-focused OKRs with enough precision to guide a trade-off. A useful structure is: for a named user and scenario, improve an observable result from its current baseline toward an agreed target by the review point, without damaging a stated guardrail. Establish the baseline before debating the target. If the team cannot observe the result, say that plainly and make instrumentation or customer evidence part of the initial slice.
Feature count, roadmap completion, tickets closed, and activity volume can help with local planning. They are not proof of customer value. Treat them as operational context, not as the headline definition of success.
Keep the executive view compact. Each team should be able to present its intended outcome, current evidence, deployment-frequency trend, change-failure trend, most important customer learning, and next unresolved decision. If a metric never changes a question, a priority, or an intervention, remove it from the review.
Stay close to the work without taking the work away
Product leaders lose judgment when they only consume summaries. They become bottlenecks when they join every working session. The useful middle ground is deliberate sampling: inspect enough real work to calibrate your view, then give feedback that strengthens the team’s next decision.
Each week, sample a rotating set of artifacts such as a product requirements document, a design flow, customer research notes, a postmortem, or a customer thread. You are not trying to approve every artifact. You are checking whether the operating system is producing clear thinking.
Use questions that reveal decision quality:
- Does the requirement name a user scenario and a problem, or does it begin with a predetermined feature?
- Does the design expose a complete path that can be tested, or only polished fragments?
- Do the research notes separate what customers did and said from the team’s interpretation?
- Does the postmortem change an operating mechanism, or merely remind people to be careful?
- Does the customer thread reveal a pattern, an important exception, or one loud request?
- Can the team state the next decision this artifact is meant to support?
Feedback should create motion. Name the user scenario, identify the friction or ambiguity, state the decision principle, propose a smaller testable slice when appropriate, and clarify the next decision. A vague comment such as make this more strategic forces the team to guess what you mean and then wait for another review.
I use a simple leadership boundary: push hard on problem clarity, sequencing, and the quality bar; leave room on solution design and implementation. That boundary keeps accountability with leadership without converting senior judgment into remote-control product management.
Exemplars make this boundary easier to scale. Keep a small, current library of strong problem statements, concise narrative memos, useful research syntheses, clear acceptance criteria, and honest postmortems. Show why each example is effective. Teams learn a quality bar faster from visible work than from an expanding rulebook.
Create short paths for decisions and uncomfortable information
Open office hours give anyone a direct route for a difficult escalation, unfinished design, customer insight, or cross-team conflict. Run them as a decision forum, not an extra status meeting. Capture the decision, owner, rationale, and follow-up so people who were not present can still act consistently.
Keep weekly one-to-ones with your leaders as well. Office hours expose work across the organization; one-to-ones develop judgment, surface recurring constraints, and help a leader notice when someone is absorbing ambiguity on behalf of the system.
Fast feedback from leadership matters because waiting expands batches. When teams expect a long approval cycle, they tend to gather more material and seek approval for more decisions at once. Publish clear decision rights and a dependable response path. If you do not need to make the decision, say so immediately and return it to the named owner.
Spend unscripted time with individual contributors, too. Formal reporting lines filter information. Direct exposure to the people building, researching, designing, supporting, and selling the product helps you hear where the written process and actual work have diverged.
Install the system without reorganizing first
You do not need a company-wide transformation program to test this operating model. Start with one important initiative that is moving slowly or generating repeated disagreement. Keep the current reporting structure and change the mechanics around the work.
- Capture the current friction. Identify where the initiative waits, where priorities conflict, which decisions keep reopening, and where work returns for avoidable clarification.
- Write the operating contract. Name the problem, outcome, owner, constraints, non-goals, initial thin slice, required evidence, and next decision.
- Collapse the work into one sequence. Bring product, engineering, executive, and commercial requests into one prioritized backlog. Preserve their context rather than preserving separate queues.
- Run the weekly loop. Set priorities on Monday, inspect selected artifacts midweek, expose work and assumptions to customers, and synthesize the learning on Friday.
- Publish the compact scorecard. Show the intended outcome, deployment frequency, change failure rate, newest customer evidence, and next decision. Do not wait for a perfect dashboard.
- Inspect the mechanism after a full loop. Remove one gate that added waiting without adding learning, divide one oversized batch, and clarify one decision right that caused an escalation.
During the review, ask concrete questions: What waited for a decision? What was redone because the original problem was unclear? Which customer signal changed the plan? Which metric caused an intervention? Which request arrived without enough context? Where did leadership provide useful boundaries, and where did it take ownership away from the team?
Expand the model only after the team can explain how it changed actual work. Copying the ceremonies without the decision rights, customer exposure, and scorecard will create more meetings, not a stronger execution system.
Key takeaways
- Start each important initiative with a one-page operating contract that connects a real customer problem to an owner, outcome, constraints, thin slice, and next decision.
- Protect autonomy with explicit boundaries. Escalate conflicting priorities and constraints, not every consequential solution choice.
- Organize the week around decisions, working evidence, customer contact, and written synthesis rather than status reporting.
- Read outcomes, deployment frequency, and change failure rate together. No single signal can tell you whether the team is delivering sustainable value.
- Sample real artifacts and give specific feedback, while leaving solution and implementation ownership with the team.
- Give product and revenue one customer narrative, one problem pipeline, and one scorecard so trade-offs become visible sequencing decisions.
At your next Monday priority review, choose one live initiative and write its operating contract before discussing another roadmap change. The missing answers will show you where execution is actually slowing down. Fix that mechanism, run the loop, and let evidence determine where the system should expand next.
References
- Shivam.Consulting Blog — The CPO Playbook I Wish I’d Had: Ditch Bad Wisdom, Ship Faster, and Lead with Clarity