Vibe is more than a brand voice—it’s the emotional resonance customers feel at every touchpoint, from onboarding to support. As I’ve scaled products and go-to-market motions, I’ve learned that preserving that resonance while introducing AI is both a strategic advantage and a delicate balancing act. In this three-part series, I’m sharing the approach I use to unlock AI-powered velocity without sacrificing authenticity or trust.
Learn how to get the benefits of AI-powered vibe marketing without accidentally killing the vibe for your customers in part 1 of our 3-part series.
When I say “vibe marketing,” I’m talking about the consistent, context-aware expression of your brand’s personality across channels—delivered with precision and warmth. GenAI can amplify that consistency at scale, but without the right safeguards, it risks drifting into uncanny, off-brand territory. In Part 1, I’ll center on strategy and governance—how we set up the foundation so the vibe feels intentionally human, even when AI assists the work.
Start with clarity: document your brand’s voice, tone, and emotional targets. I create a living voice and tone guide with examples of “do” and “don’t” language, aligned to specific customer moments like activation, upgrade prompts, renewal nudges, and recovery from a failed workflow. This artifact becomes the north star for prompts, training snippets, and review criteria—so AI doesn’t invent a persona you never approved.
Next, map the end-to-end journey and choose high-leverage use cases where AI can enhance relevance without increasing risk. My favorite entry points are in-app guides, lifecycle emails, contextual tooltips, and product tours—places where we can A/B test safely, measure impact on activation and retention, and iterate quickly. Keep the highest-judgment moments—pricing, security, compliance, and incident communications—squarely human-led, with AI supporting drafts and analysis, not final decisions.
Guardrails are non-negotiable. I establish prompt patterns that include brand attributes, audience, channel, goal, and constraints (length, reading level, regional spelling, accessibility). We also implement a human-in-the-loop review for net-new narratives, plus automatic checks for tone drift, sensitive topics, and jargon density. When governance is clear, teams move faster with more confidence—and customers feel the cohesion.
Measurement keeps the vibe honest. I track leading indicators like message clarity scores, reading time, and click-through alongside business outcomes such as activation rate, conversion to aha moment, support deflection, and retention analysis. Segment results by persona and lifecycle stage to catch subtle mismatches—what delights power users can overwhelm first-time builders.
Pragmatically, I use GenAI for rapid prototyping of variations. We generate multiple voice styles aligned to the guide, then test them in controlled experiments. The winner becomes the new baseline, and we codify it back into our prompt library. That tight loop—prototype, test, codify—prevents ad-hoc drift and compounds learning across product, marketing, and customer success.
Finally, empower product trios to own the vibe where it matters most: inside the product. Your PM, design, and engineering leaders should collaborate on UX writing and microcopy patterns, ensuring that AI-generated suggestions harmonize with product positioning and value proposition. This is how vibe marketing transcends campaigns and becomes a product-led growth advantage.
In Part 2, I’ll share playbooks and prompt templates for high-impact channels, including onboarding sequences, upgrade nudges, and contextual in-app experiences. In Part 3, I’ll cover instrumentation and analytics patterns so you can operationalize learning across teams.
For now, here’s the checklist I use to avoid “killing the vibe”: a codified voice and tone guide, journey-mapped use cases with risk tiers, prompt patterns with constraints, human-in-the-loop review, automated tone and compliance checks, and outcome-oriented experiments measured against activation and retention. With that foundation, AI stops being a gimmick and starts being a force multiplier for authenticity and growth.
Inspired by this post on Amplitude – Perspectives.
I’ve spent the past few years building in what often feels like an AI tornado—intense velocity, shifting requirements, and unforgiving expectations for security and quality. When I think about how to turn that chaos into momentum, I’m reminded of a guiding prompt: "Learn how Aparna Sinha, SVP of Vercel, builds in the AI tornado quickly and securely. Aparna shares her practical advice for builders everywhere." That mandate resonates with how I lead product teams to move decisively while protecting our customers and our brand.
In practice, building quickly and securely starts with clarity. I anchor the team on a crisp value proposition, define outcomes over output, and align product discovery with a tight feedback loop. We plan with product roadmapping and sprint planning that front-loads risk: data governance, threat modeling, and privacy-by-design are non-negotiable guardrails. This lets us unlock developer velocity without compromising trust—precisely the balance elite product management leadership aims to achieve.
On the execution side, I use lightweight gen ai experiments to accelerate insight and reduce uncertainty. For gen ai for product prototyping, we spin up narrow, testable slices that validate feasibility, usability, and safety in parallel. Two-week iteration cycles, clear exit criteria, and a secure-by-default posture keep us honest. We instrument a unified analytics view to measure real outcomes, then double down where signal is strongest and deprecate what doesn’t move the needle.
Team topology matters just as much as process. I empower product trios to own customer value end-to-end, pair forward deployed engineers with design and PM for rapid discovery, and practice developer evangelism to amplify adoption patterns early. This creates the foundation for product-led growth: a self-reinforcing loop where users teach us what to build next, and we respond with precision. Strong stakeholder management keeps go-to-market aligned so we can scale learnings into repeatable wins.
Security is everyone’s job, not a final checklist. We embed data governance and compliance considerations from day one—so speed becomes sustainable, not reckless. The outcome is a product culture that moves fast with conviction: disciplined experimentation, clear decision frameworks, and a shared commitment to quality.
If you’re building in the AI tornado, focus on three levers: sharpen outcomes (what matters), reduce uncertainty (prove it fast), and codify trust (bake in safety). Do this consistently, and your team will ship faster with fewer reversals—while compounding credibility with customers and the market.
Inspired by this post on Amplitude – Perspectives.
When I need fast, trustworthy insight into what to build next, I turn to product surveys. Done well, they feel respectful, take minutes, and deliver signal we can ship against. Done poorly, they frustrate users and mislead product teams. Over the years, I’ve refined a simple, repeatable approach that consistently yields high response rates and actionable insights across product discovery, onboarding, and product-led growth motions.
Create effective product surveys that capture actionable user feedback, improve features, and support smarter product decisions.
I always start with the decision I need to make. Am I validating a value proposition, prioritizing a feature, diagnosing friction in onboarding, or measuring retention risk? That clarity shapes everything—who I ask, when I ask, and how I phrase the questions. It also aligns the survey with outcomes, not outputs, so results directly inform product roadmapping and sprint planning instead of becoming a vanity report.
Question design is where UX writing discipline pays off. I keep surveys short (5–7 questions), bias-free, and written in the same voice we use in-app. I mix two or three crisp quant questions (e.g., confidence, usefulness, likelihood to continue) with one or two open-ended prompts to surface the “why.” That blend gives me both trend lines and the qualitative texture I need to make confident trade-offs with stakeholders.
Timing and targeting often matter more than question count. I trigger in-app micro-surveys at meaningful moments—right after a user finishes onboarding, explores a product tour, or engages with a newly released feature. For deeper discovery, I segment cohorts (new vs. power users, retained vs. churning) to avoid muddy averages. The right context earns higher completion rates and more honest feedback.
Trust drives participation. I set expectations upfront: how long it will take, why it matters, and how their feedback will shape the roadmap. I also share back the outcome—what we learned and what we shipped—so users see the loop closing. That simple follow-up builds goodwill and sustains response rates over time.
On analysis, I combine lightweight quant with rigorous qualitative synthesis. I chart response and completion rates, then use thematic coding on open text to spot repeating patterns. Where it helps, I apply gen AI to accelerate clustering and sentiment analysis, then validate the themes manually. Finally, I triangulate with product telemetry in Amplitude analytics to confirm that what users say matches what they do.
The most valuable step is translation: turning feedback into decisions. I map insights to clear problem statements, rank them by user impact and strategic fit, and convert them into opportunities on our roadmap. In planning, I pair these opportunities with success metrics tied to activation, adoption, or retention analysis, so we can measure whether changes actually move the needle.
Surveys aren’t a substitute for interviews, but they’re a powerful complement. They help me spot signals at scale, de-risk bets between cycles, and align cross-functional stakeholders around evidence rather than opinions. When surveys are concise, contextual, and connected to action, users feel heard—and teams ship smarter.
Inspired by this post on Amplitude – Best Practices.
I’ve learned that the fastest way to stall growth is to scatter your data across a maze of dashboards and point solutions. My guiding principle is simple: Escape fragmented tools with a unified analytics platform that accelerates growth, reduces costs, and empowers smarter, real-time decision-making. When every team can trust a single source of truth, momentum compounds.
By “unified analytics,” I mean a single platform that integrates product, marketing, sales, support, and finance data with consistent definitions, shared metrics, and strong governance. The right foundation pairs real-time instrumentation and event streaming with standardized taxonomies and role-based access. This is what transforms raw data into reliable insight that product managers and executives can act on with confidence.
Growth accelerates when hypotheses move faster from discovery to delivery. A unified analytics platform tightens the experimentation loop, informs product discovery, and aligns product roadmapping and sprint planning with measurable outcomes. It anchors outcomes vs output OKRs in trustworthy metrics, so QBRs and executive reviews focus on impact, not anecdotes. The result is clearer prioritization, sharper bets, and faster compounding wins.
Costs come down just as decisively. Consolidating analytics reduces redundant SaaS, manual reporting, and bespoke pipelines that are expensive to build and maintain. With one data model, we cut duplication, improve data quality, and negotiate smarter under consumption SaaS pricing. Teams spend less time wrangling CSVs and more time shipping value.
Real-time decision-making is where unified analytics truly pays off. Proactive alerts and cohort insights surface anomalies before they become churn. LTV, funnel, and retention forecasts inform pricing and packaging moves. Layering gen ai on top of clean, unified data speeds synthesis and narrative insight, while a thoughtful customer support AI strategy connects voice-of-customer signals directly to the roadmap.
Implementation starts with clarity. Identify the highest-impact decisions you want to improve, map KPIs to events, and instrument end-to-end tracking with quality SLAs. Establish governance early, align stakeholders across data, engineering, RevOps, and finance, and empower product trios to own their metrics. With disciplined stakeholder management and empowered product teams, the platform becomes a force multiplier rather than another tool to maintain.
The payoff is strategic agility: faster learning cycles, lower operating costs, and confident calls made in the moment, not after the fact. If you’re ready to break free from fractured dashboards and lagging reports, commit to a unified analytics platform and let your data become a competitive advantage.
Inspired by this post on Amplitude – Best Practices.
AI has changed the tempo of product management, but not the timeless fundamentals. I’m living that paradox daily: the technology reshapes how we plan, build, and ship—yet the way we find real customer value hasn’t budged. Here’s how I reconcile both truths in practice.
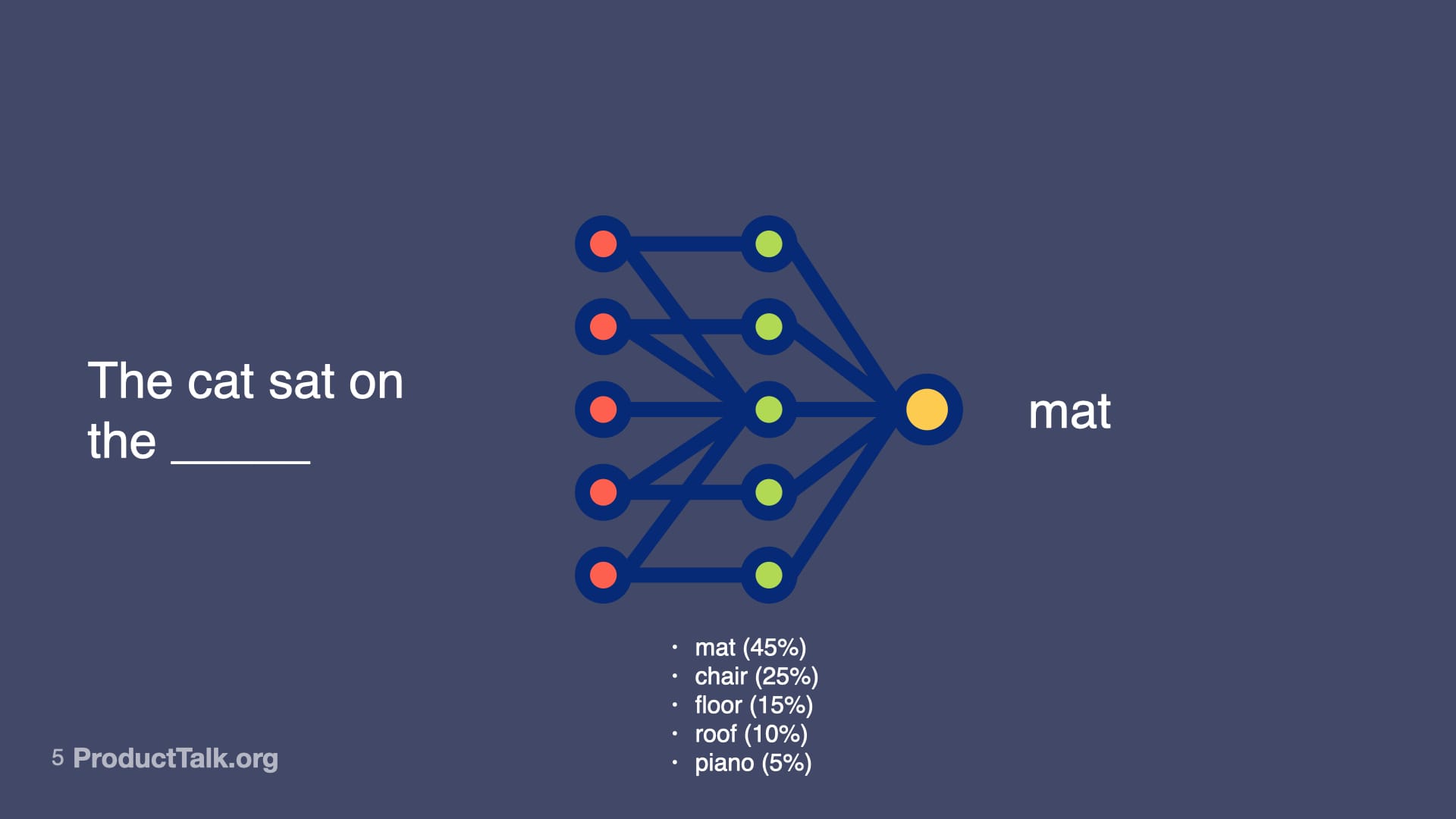
At their core, large language models predict the next token. That’s it. Consider the prompt, “The cat sat on the ____.” Mat is most likely. Chair is pretty likely. Floor, roof, piano—all possible, just less probable. When you give an LLM a prompt, it runs through a neural network—billions of parameters making calculations—to predict the most likely next word, then the next, then the next. That neural net represents not just facts, but relationships, patterns, context—and some might even argue reasoning capabilities—that all influence the probabilities of different outputs. So LLMs don’t just predict the next token. They predict the next token by drawing upon a vast amount of knowledge. LLMs are transformational.
Behind the magic, LLMs don’t “know”—they rank what likely comes next. This slide’s cat sentence with weighted options underscores how generative AI reshapes work while remaining probability-driven.
And yet, AI makes silly mistakes. The kind that make you wonder how it could be so smart and so dumb at the same time. No matter how hard I tried, I could not get ChatGPT-5 to fix the closing quote on an image. And it took 12 seconds of thinking to figure out that I asked for a meeting summary but didn’t include any meeting notes. Why do LLMs make these mistakes? Well, it’s because all the LLM is doing is predicting the next token based on patterns. And sometimes those predictions are wrong. And when it’s wrong, it can be confidently wrong. So what do we do?
A side-by-side visual pits an optimistic AGI rocket against a frowning skeptic with a thumbs-down, ending with the prompt 'Which is it?'—capturing the debate over whether generative AI is transformative progress or overhyped.
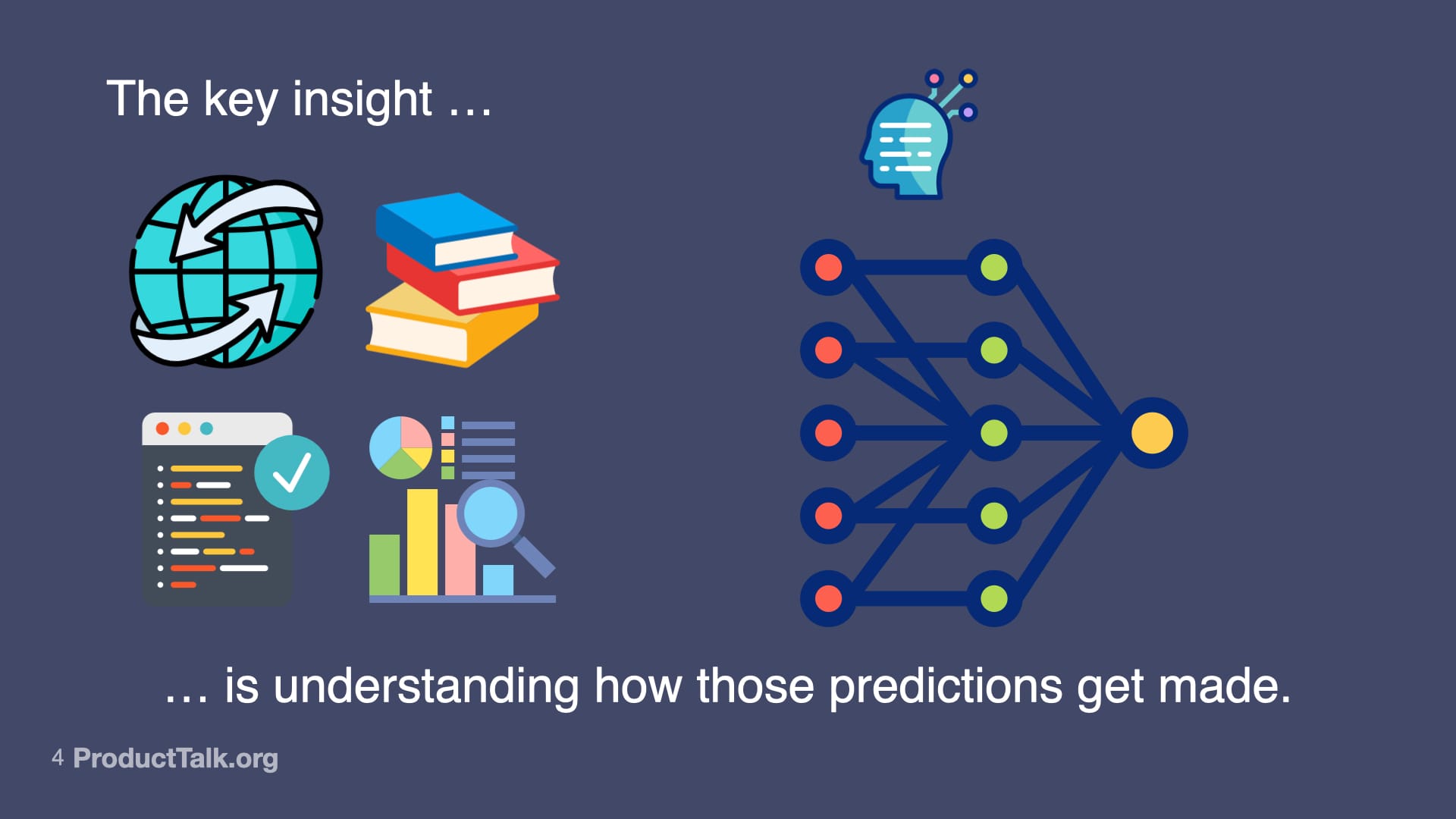
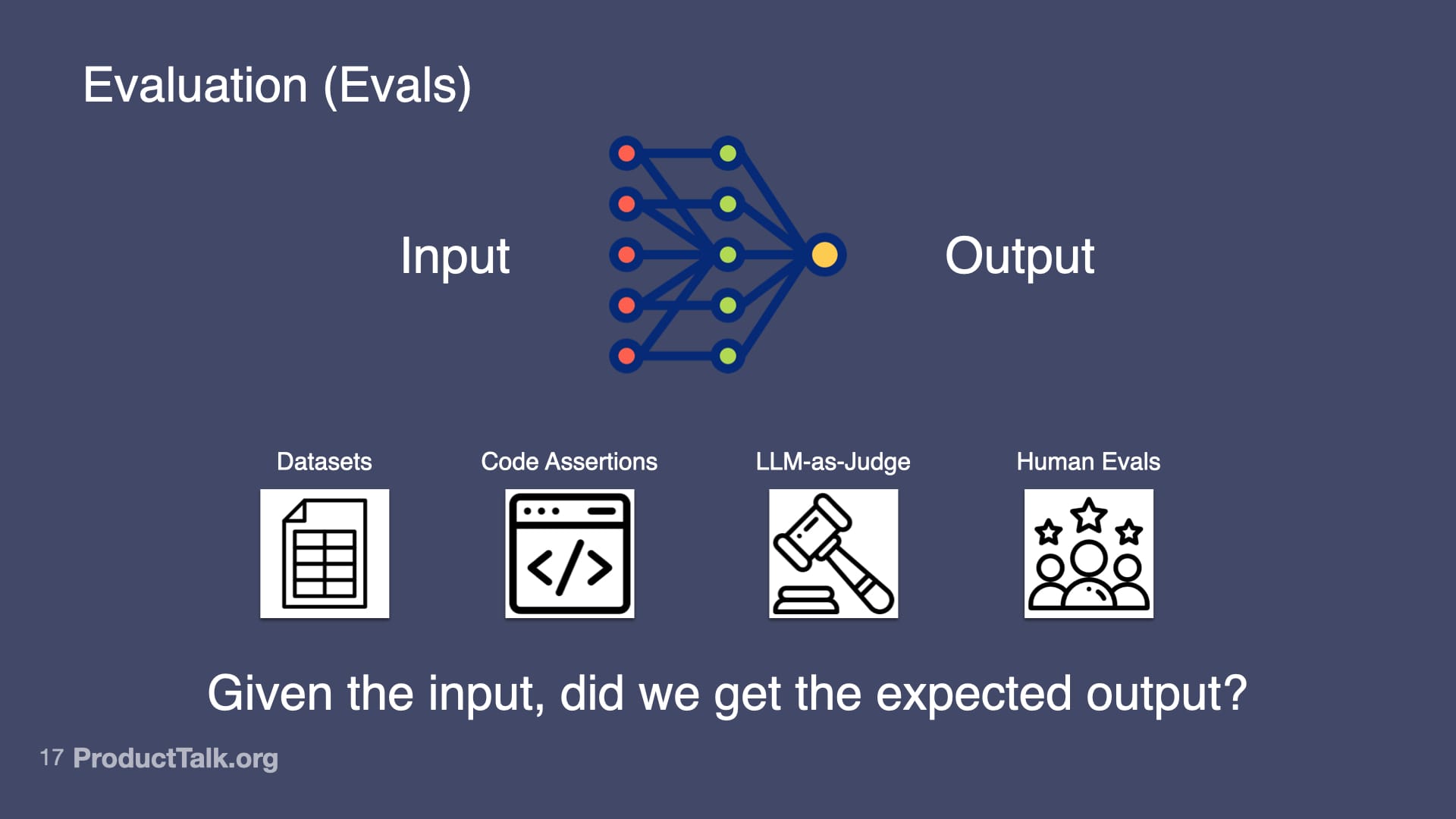
To build reliable AI features, I focus my team on four core skills: prompt engineering, context engineering, orchestration, and evaluation (evals). Together, they let us harness what’s powerful about generative AI while reducing unforced errors.
Generative AI isn’t magic—it’s inputs, training data, and models. This visual invites readers to examine how predictions are produced and why transparency, bias checks, and ethics shape responsible outcomes.
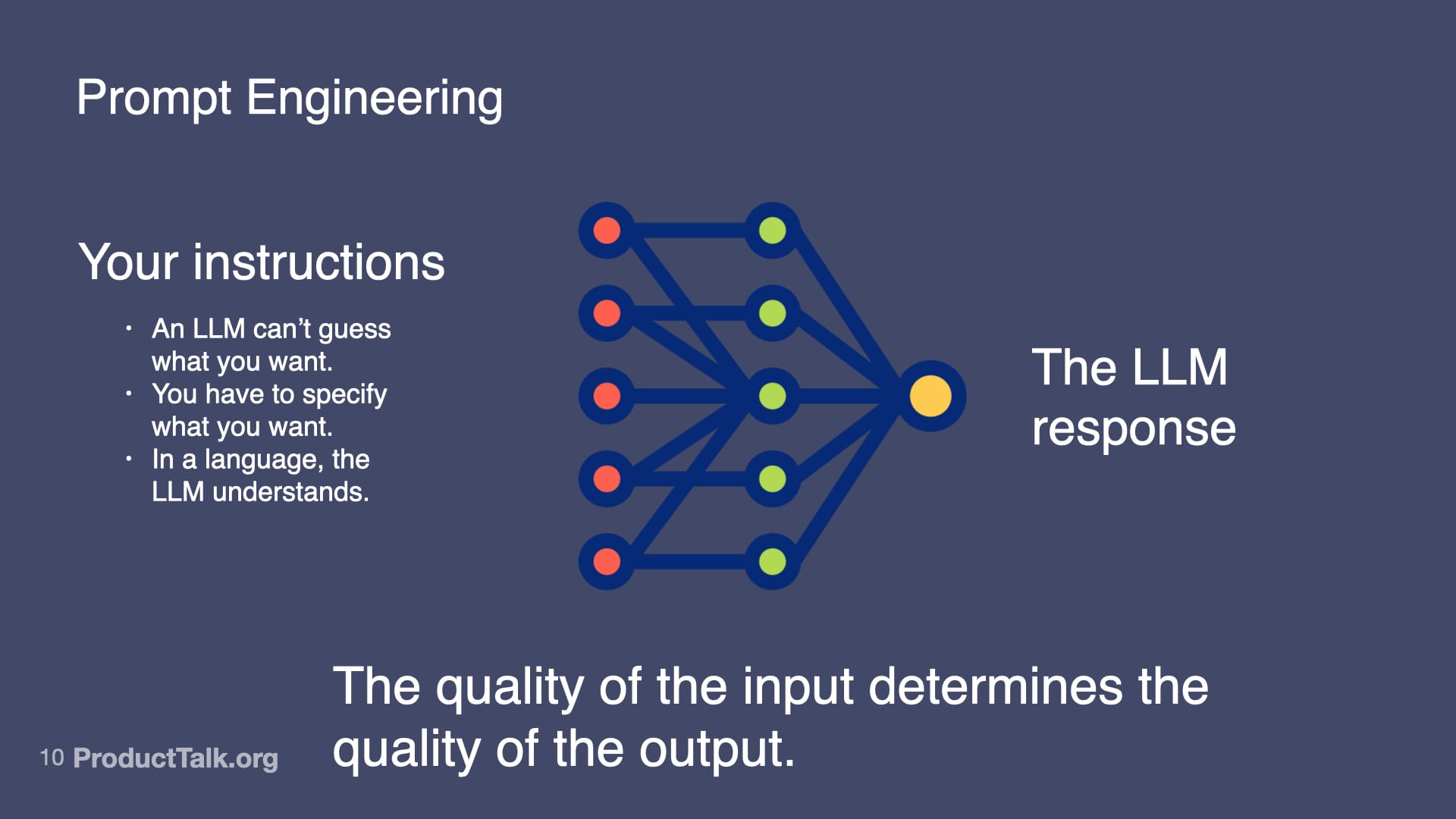
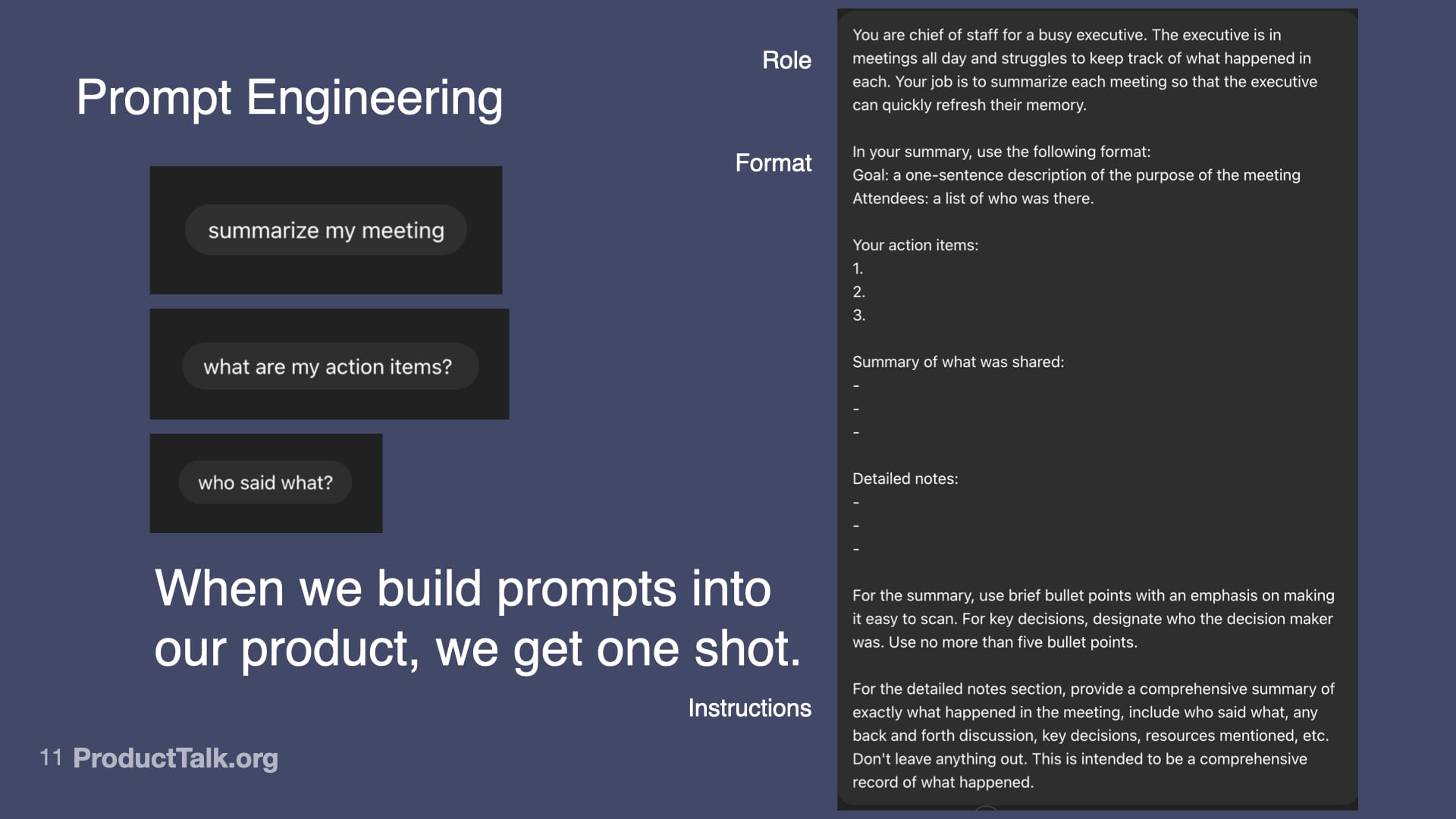
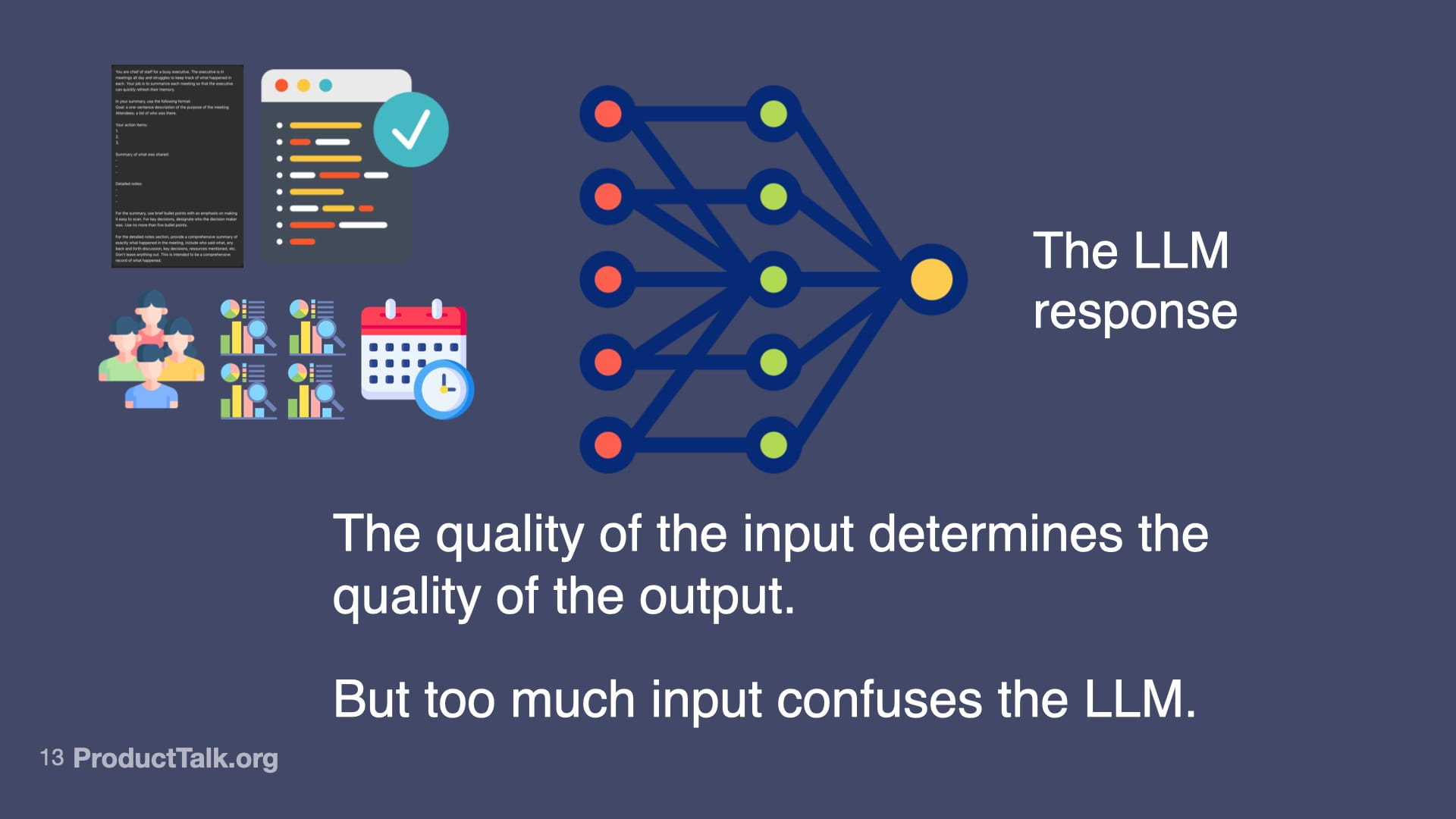
First, prompt engineering. With LLMs, the quality of the input determines the quality of the output. An LLM can’t guess what you want. You have to specify what you want in a language the LLM understands. In a chat, you can iterate with multiple turns. In a product, you get one shot. When we ship a meeting summarizer, for example, I design a production-ready prompt that assigns a role (“You are a chief of staff for a busy executive…”), specifies output format (e.g., a structured list of action items), and clarifies exactly what to include and how to structure it. This is prompt engineering. It’s like writing a really good product spec—but for an AI.
A simple sentence becomes a window into generative AI: a neural network weighs options and selects 'mat,' showing how models rank likely words to produce fluent text—and why outputs feel confident yet probabilistic.
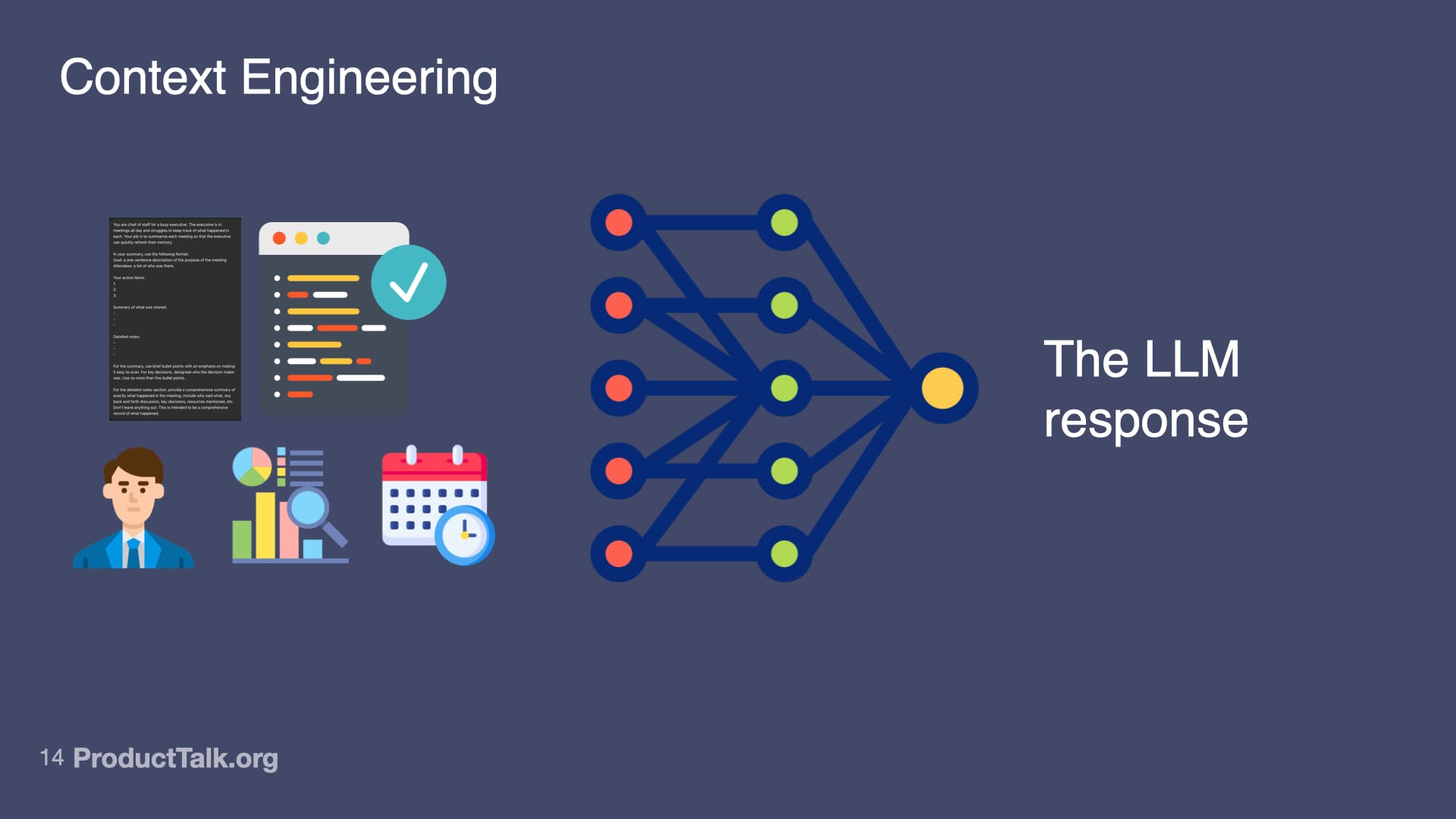
Second, context engineering. LLMs know a lot, but not everything. Imagine a takeaway reads, “Send the pipeline report to John by Friday.” When is Friday? Which John? What is the pipeline report? The model lacks today’s date, the roles of participants, and the specifics of our reporting vocabulary. If you dump every possible detail into the prompt, the model gets noisy input and the quality drops. The key is to add only the context the LLM needs to do the task at hand and nothing more. This is where techniques like RAG (Retrieval Augmented Generation) shine: retrieve just the relevant snippets—e.g., attendee roles, the precise definition of “pipeline report,” and the calendar context for “Friday”—and include only those in the prompt.
A minimalist slide demystifies how LLMs choose words: given 'The cat sat on the ____', the model ranks options by probability, showing that AI outputs are weighted predictions, not facts, which matters for ethics and product decisions.
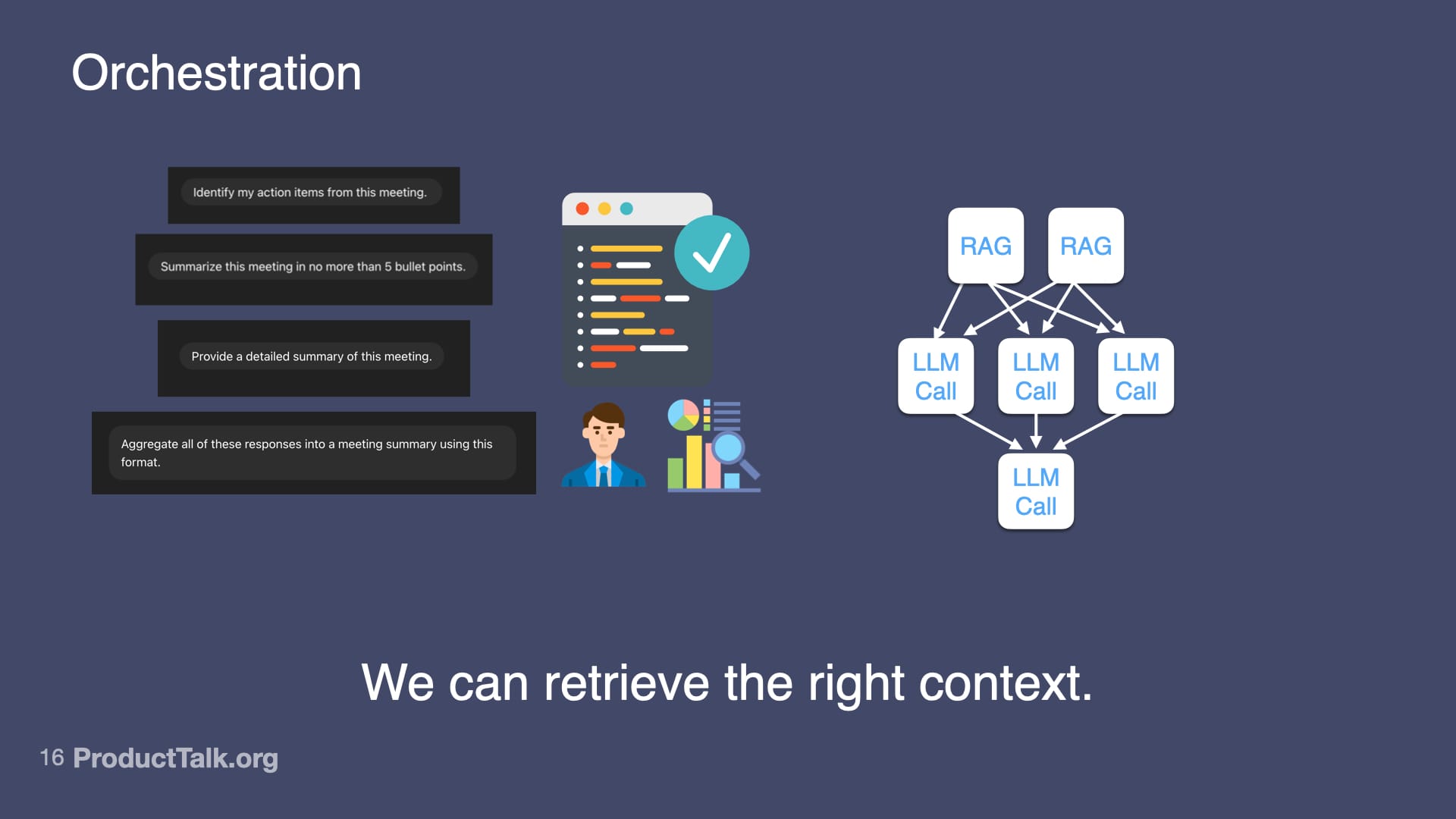
Third, orchestration. LLMs are better at simpler tasks. If you try to do everything in one prompt—identify action items, summarize the meeting, categorize by urgency, match to owners, check for clarity—the quality goes down. But if you break it into steps, each focused on one thing, the quality goes up. I design a workflow of multiple LLM calls that work together. For example: First call: identify action items from the transcript. Second call: categorize by urgency using lightweight project context. Third call: match to owners with a minimal team directory. Fourth call: generate calendar events via an API. Each step is simple. But together, they create something sophisticated.
From building apps by chatting to auto-cleaning video and translating comments, AI compresses complex tasks into simple prompts. This scene shows why it feels transformative—while nudging us to weigh its limits and ethics.
Fourth, evaluation (evals). Otherwise known as: Is my AI product any good? At the heart of evals is this question: Given the input, did we get the expected output? I use several approaches. Datasets: I collect 20–100 real examples, define expected outputs, run the prompt, and measure the success rate. Code assertions: I enforce rules the output must follow (for example, “Every action item must have a task, owner, and deadline”) and fail the test when they’re violated. LLM-as-Judge: I use a model to verify factuality (e.g., “Is each item in this summary in the meeting transcript? Yes or no.”). Human evals: I track whether users need to edit the output and by how much. Start simple; get more sophisticated as the stakes rise.
From “AI Changes Everything (And Nothing At All),” this slide contrasts bold promises with everyday glitches: optimism about LLMs and AGI on the left, and a meeting-summarizer that can’t find content on the right—reminding us AI still errs.
Here’s the hard truth: you can master all four skills and still ship the wrong thing. Why? Because you chose the wrong problem to solve. Who needs yet another meeting summarizer? The ease of building with generative AI tempts us to jump straight to solutions. Resist it.
A keynote slide from AI Changes Everything (And Nothing At All) urges teams to master AI by harnessing its power while minimizing errors, framing a practical, ethical approach to building trustworthy products.
Discovery matters more than ever. Before writing your first prompt, be explicit about the impact you want and set a clear outcome. Talk to your customers and ensure you understand their needs; choose the right opportunity before you chase a cool solution. Explore multiple options and use assumption testing to converge on what will actually move the needle.
Clear prompts shape better AI. This slide shows how explicit, well-structured instructions lead to stronger LLM responses, reminding builders that inputs drive outcomes—and that responsible prompting begins with clarity.
Prototype, test, and build iteratively. With AI products, it’s easy to get to a great demo and hard to get to a production-grade experience. I validated feasibility before I wrote a line of production code by experimenting directly in a model’s UI, pasting real transcripts, and shaping the system instructions and output format. Only after I had a repeatable prompt and useful feedback did I worry about deployment.
Designing prompts is product design. This visual pairs common meeting requests with a rigorous summary framework, reminding teams that when prompts are embedded in products, accuracy matters because you get one shot.
From there, I tested deployment paths with the smallest viable investment. I tried a custom chat in Replit and embedded it. It wasn’t the right interaction model for targeted feedback. I switched to a submission flow using a homework-style pattern: students upload their transcript, the system processes it, they get detailed feedback. Done. That worked—until automation reliability lagged. I wired it up in Zapier, then rebuilt it on AWS Step Function for robust retries and better error handling when scale introduced edge cases.
A reminder that AI needs context: a simple instruction becomes ambiguous without dates, roles, recipients, and report details, highlighting the limits of LLM knowledge and the value of precise, shared prompts.
Each iteration tested a different assumption. Iteration 1 (Claude): Can AI even do this? What makes good feedback? Iteration 2 (Replit chat): How should people interact with it? Iteration 3 (Zapier): Can I integrate this into the existing workflow with minimal engineering? Iteration 4 (Step Functions): How do I make it reliable at scale when things inevitably go wrong? I didn’t know the answers up front; I learned by building, shipping, and observing.
From AI Changes Everything (And Nothing At All), this visual reminds builders that curated, high‑quality prompts yield better LLM responses, while overloaded, noisy inputs derail reasoning and reduce reliability.
Ethical data practices are non-negotiable. Improving AI products requires inspecting traces—the user input, system prompts, tool calls, and LLM responses. For a coaching flow, that includes the uploaded transcript, the system prompts that define evaluation criteria, and the AI’s feedback. To fix issues, I look at traces where things went wrong—but only with explicit user permission. Too many AI products collect everything by default and review traces without clear consent. Don’t do this.
A visual explainer showing how structured inputs—documents, verified code, roles, metrics, and timelines—flow into a network to shape a single, clear LLM response, underscoring the power of context in generative AI.
In my products, users must explicitly grant permission for me to review their data. The consent is clear and specific. If they say no, I don’t see their data. Full stop. That forces me to rely on synthetic data for many tests and to engineer privacy into the architecture from day one rather than bolt it on later. It’s the right thing to do, and increasingly, it’s required.
A visual guide to orchestration: break a complex meeting recap into smaller LLM calls, gather action items, bullet points, and a detailed summary, then aggregate the outputs to boost accuracy and reliability.
Everything changes—and nothing changes. Yes, there are new skills you should master: prompt engineering to get the right output the first time; context engineering to give the LLM exactly what it needs; orchestration to decompose complex tasks into simpler steps; and evals to systematically measure quality. And the fundamentals still rule: solve the right customer problems with strong discovery; prototype and iterate to de-risk; and uphold ethical data practices as a design constraint, not an afterthought. The teams that win with AI will master both the new technical craft and the timeless product fundamentals.
A presentation slide visualizes AI orchestration: user prompts generate meeting summaries while a graph of RAG and LLM calls routes tasks to the best sources, underscoring that retrieving the right context drives better outputs.
If this resonates, pick one active workflow, apply the four AI skills end-to-end, and run a short discovery and eval cycle against a clear outcome. Then ship. You’ll learn faster than any slide deck could ever teach you.
This presentation slide maps how to assess AI: link inputs to outputs with datasets, code assertions, LLM-as-judge checks, and human reviews—centering the question, "Given the input, did we get the expected output?"
I’ve led and observed AI initiatives across fast-moving product organizations, and one pattern is unmistakable: “The AI revolution needs a departmental leader.” When that leader is unclear, pilots stall, risk mounts, and value gets trapped in proof-of-concept purgatory. When it’s clear, AI moves from demos to durable outcomes.
In my experience, IT is uniquely positioned to play that leadership role. IT sits at the nexus of data, identity, security, and infrastructure—exactly where scalable AI capabilities live. IT also has the vantage point to connect use cases across teams, manage risk, and operationalize change without derailing core systems.
Put simply, this is the promise: “Learn the key reasons why IT teams are uniquely positioned to be the strategic leaders of your company’s AI projects.” The reasons are pragmatic—access to systems of record, stewardship of data governance, ownership of integration patterns, and accountability for reliability and compliance—yet the impact is strategic.
Here’s how I frame the operating model. IT provides strategic leadership and platform stewardship; Product owns the outcomes; Engineering delivers services and integrations; Security and Legal codify guardrails; and Finance supports cost modeling. We establish tight collaboration through product trios (Product, Design, Engineering) that plug into an IT-led AI platform, enabling empowered product teams to ship safely and quickly.
Governance turns intent into repeatable action. I use outcomes vs output OKRs to force clarity on value, pair them with lightweight QBR cadences for course correction, and require architecture reviews that cover model/data governance, observability, privacy, and vendor risk. This ensures we can scale gen ai without surprise failures or compliance gaps.
On the delivery side, forward deployed engineers embedded with business units accelerate discovery and reduce translation loss. We leverage gen ai for product prototyping to validate desirability and feasibility early, then harden solutions on our shared AI platform. This keeps experimentation fast while maintaining an enterprise-grade backbone.
Roadmapping balances ambition with throughput. I tie product roadmapping and sprint planning to value streams, not just features, and I make stakeholder management explicit—especially with customer support, finance, and operations—so we design for adoption. For example, a customer support ai strategy isn’t a chatbot alone; it’s an outcome-driven service redesign, with training, playbooks, and measurable deflection and CSAT targets.
Success demands the right metrics. Beyond typical velocity measures, I track time-to-first-value, model quality and drift, cost-to-serve, and risk posture. These roll into OKRs that link frontline improvements (e.g., resolution time) to enterprise outcomes (e.g., gross margin, retention), giving executives confidence and teams a clear definition of done.
If you lead IT, this is your moment to step into strategic ownership and elevate AI from scattered experiments to a coherent platform. If you lead Product, partner with IT to align discovery, outcomes, and guardrails so empowered teams can move fast and responsibly. Together, we can turn AI from a buzzword into a durable advantage.