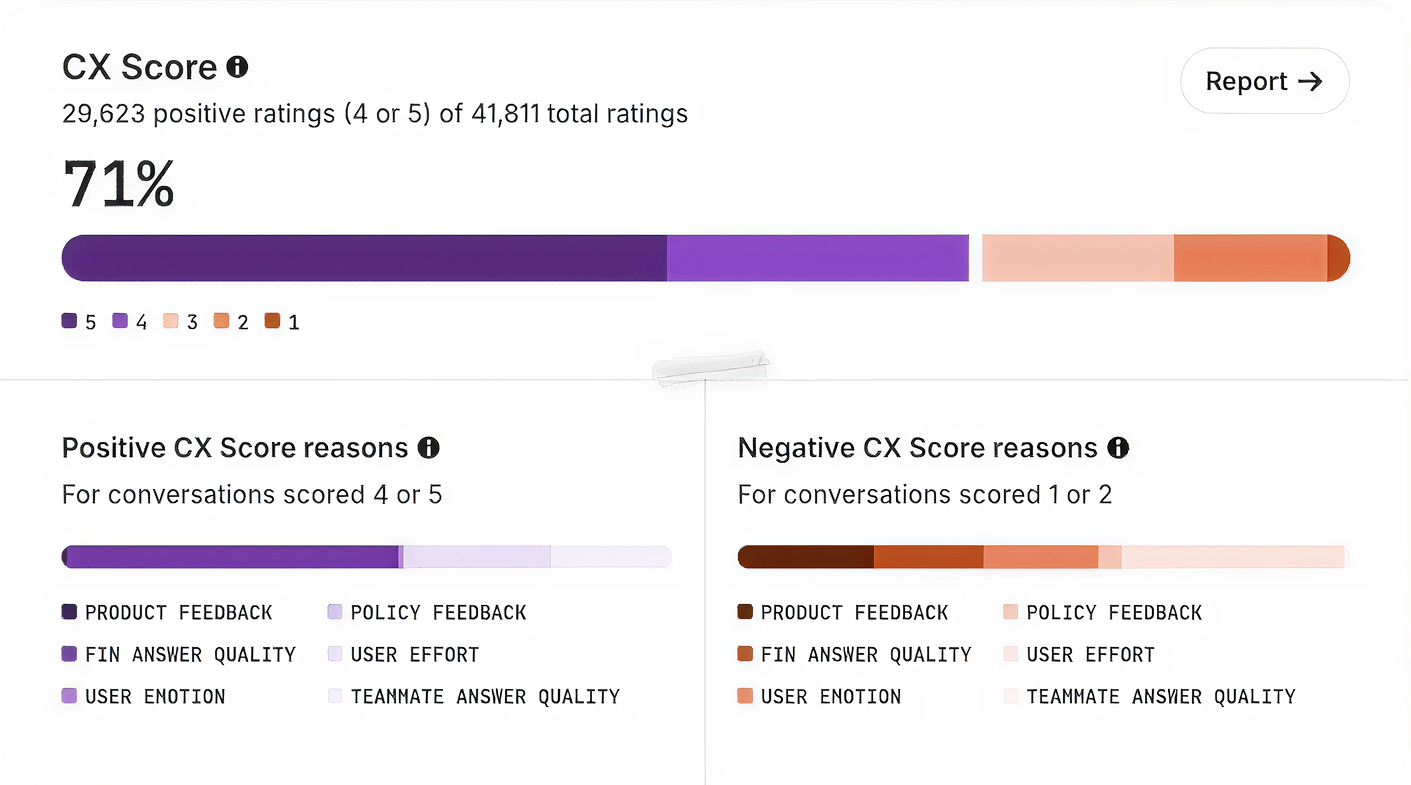
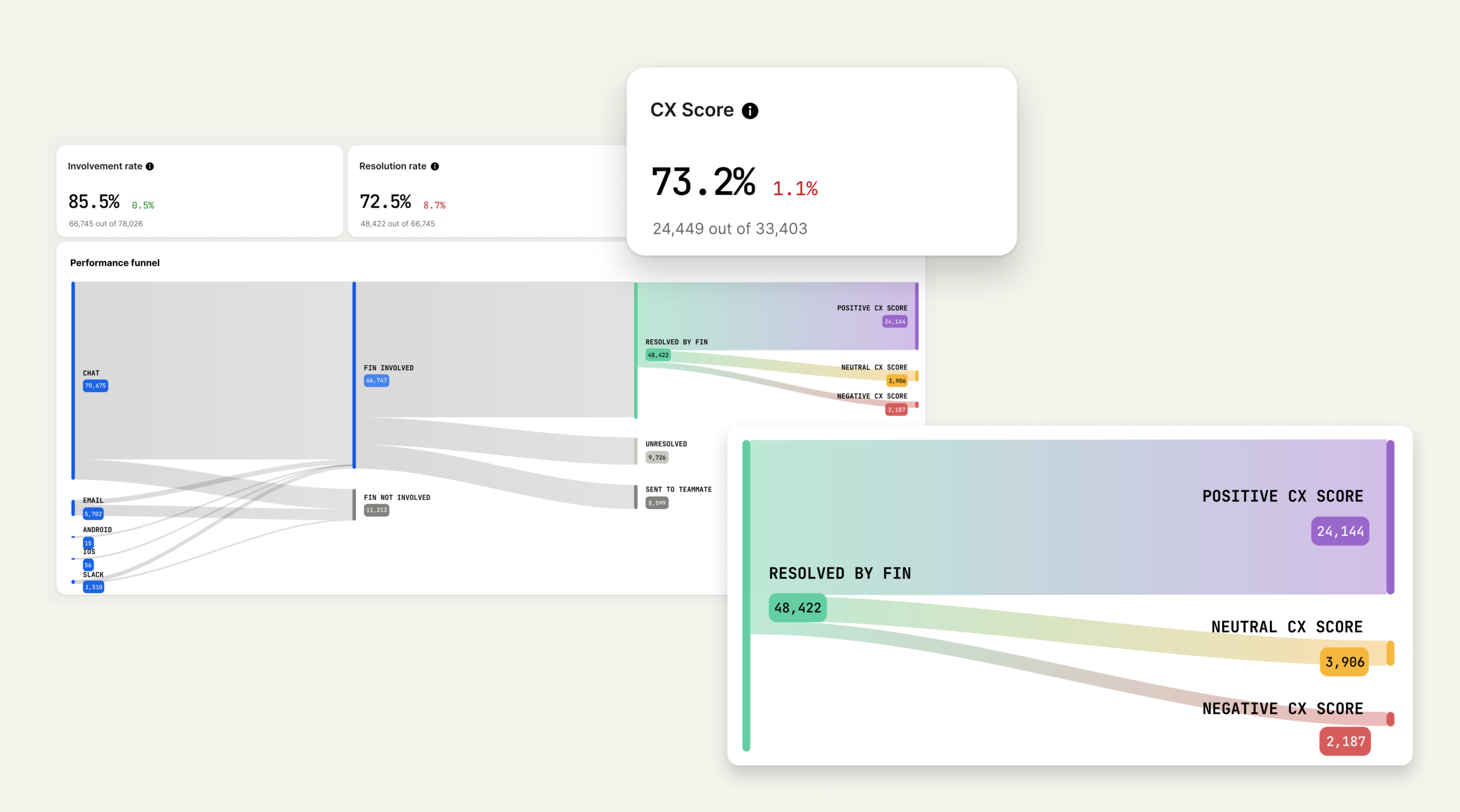
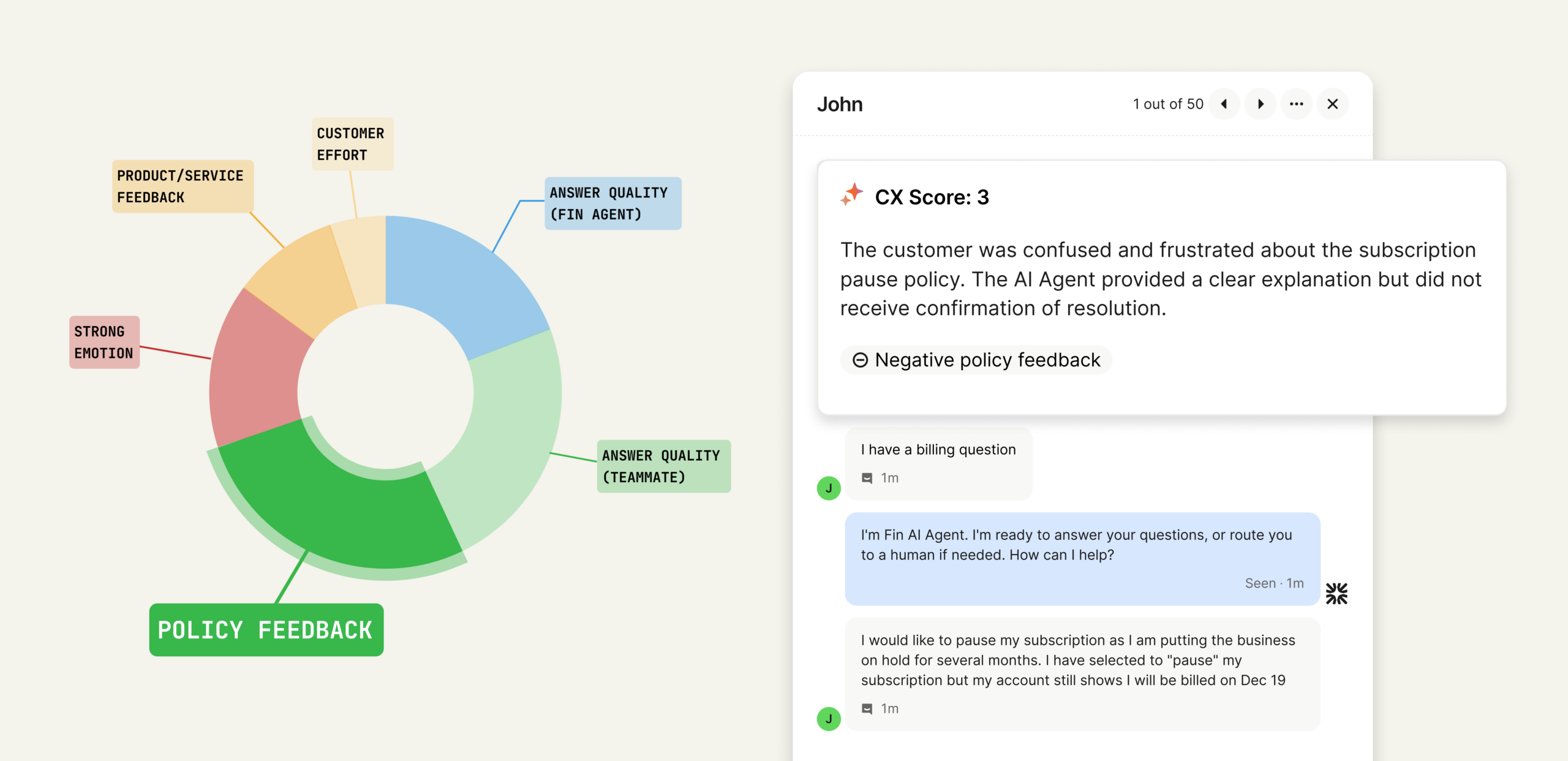
Your team can generate a PRD, summarize an interview, and draft acceptance criteria in minutes. Yet the product still may not ship faster. Customer evidence remains scattered, decisions lose their rationale at handoffs, and nobody knows whether an AI-generated recommendation deserves to be trusted.
An AI-native product development workflow fixes that operating system. It connects evidence, decisions, delivery, and evaluation in one traceable learning loop. The goal is not to produce more documents. It is to shorten the path from a customer signal to a reliable product decision, then carry the result back into the next decision.
Change the unit of work from an artifact to a decision
AI-assisted teams use a model inside an existing process. They write the same documents, hold the same handoffs, and make the same decisions, only with faster drafting. That can save time, but it leaves the fundamental bottlenecks untouched.
An AI-native workflow reorganizes the process around decisions. Every meaningful unit of work should carry enough context for the next person or system to understand what is being decided, why it matters, and what evidence would change the decision.
Use a decision packet with five parts:
- Decision: State the exact choice in front of the team. Replace broad assignments such as improve onboarding with a decision such as whether to change the first-session setup flow for a defined customer segment.
- Evidence: Link the customer examples, research moments, usage data, and business constraints that support the problem. Preserve the original evidence rather than storing only an AI summary.
- Assumptions: Separate what the team knows from what it believes. An assumption should be written so that new evidence can confirm or challenge it.
- Success condition: Name the customer or business behavior expected to change. For an experiment, define the hypothesis and, where appropriate, the minimum detectable effect before exposure begins.
- Decision state: Record the owner, status, unresolved questions, next test, and reason for the latest change.
The model can retrieve evidence, compress it, identify inconsistencies, draft alternatives, and check whether required fields are missing. A person still owns the interpretation, trade-offs, priority, and release decision. This boundary prevents polished language from being mistaken for product judgment.
Apply a simple test to every AI-generated artifact: what decision will this change? If the answer is unclear, the artifact is probably workflow noise. If the answer is clear, attach the artifact to the decision packet instead of allowing it to become another disconnected document.
Build an evidence spine before adding more automation
Most product workflows fragment evidence before a model ever sees it. Support tickets sit in one system, sales notes in another, interviews in folders, and behavioral data in an analytics platform. A prompt cannot recover relationships that the operating system never preserved.
A retrieval-first intake can unify customer feedback, support tickets, sales notes, research transcripts, and usage analytics. Embeddings can help cluster related signals and remove duplicates, but the useful output is not a list of themes. It is a navigable path from a theme to representative evidence and then to the decision it informed.
Build that path as a closed sequence:
- Normalize incoming evidence while preserving its source identifier, relevant customer or segment context, and access permissions.
- De-duplicate repeated signals and cluster related evidence without erasing meaningful differences between customers or use cases.
- Retrieve a small set of representative examples for the decision being made. Do not dump the entire evidence store into the model context.
- Write the approved decision, its assumptions, and its rationale into durable external state.
- Return experiment results, release outcomes, and new qualitative feedback to the same evidence system.
Keep three forms of information distinct. The evidence store contains raw and normalized inputs. Working context contains only the material needed for the current task. The decision log contains approved conclusions, rejected alternatives, owners, and changes. Mixing all three creates stale prompts, contradictory instructions, and summaries that can no longer be audited.
A prioritization recommendation, for example, should link back to representative customer records and the relevant analytics view. A summary without those links is compression, not evidence. When somebody challenges the recommendation, the team should be able to inspect the underlying material without asking the model to reconstruct its reasoning from memory.
This is also where data governance belongs. Decide which systems the workflow may retrieve from, which fields require redaction, who can see sensitive records, and how model outputs will be retained before connecting those systems. Privacy-by-design, cybersecurity, and regulatory controls need to sit alongside the workflow, not appear as a review after customer information has already crossed an inappropriate boundary.
Run one closed loop from discovery to shipped learning
The product trio remains important in an AI-native workflow. Product, design, and engineering use automation to reach the evidence faster and explore more alternatives, while keeping explicit human gates around interpretation, feasibility, customer experience, and risk. Clear handoffs between context design, external memory, and orchestration make those responsibilities easier to see.
For each stage, name the AI job, the human gate, and the durable output. That turns a collection of AI tools into an operating workflow.
| Stage | AI accelerates | Human gate | Durable output |
|---|---|---|---|
| Intake and triage | Normalize, de-duplicate, cluster, and retrieve representative customer signals. | Verify that a cluster reflects a real customer problem rather than repeated wording or a noisy channel. | An opportunity record linked to original evidence. |
| Discovery | Draft interview guides, summarize transcripts, extract entities, and tag moments of friction. | Interpret what the customer meant, identify contradictions, and decide which uncertainty deserves another conversation. | An evidence-backed problem narrative with open questions. |
| Opportunity sizing | Organize evidence against a driver tree and assemble available inputs about potential impact. | Choose the outcome, inspect data quality, expose assumptions, and make the prioritization trade-off. | A ranked opportunity with decision criteria and explicit assumptions. |
| Solution shaping | Generate alternatives, first-pass flows, PRD sections, acceptance criteria, and experiment ideas. | Test desirability, usability, feasibility, strategic fit, and the cost of being wrong. | A solution hypothesis, acceptance criteria, and a test plan. |
| Planning and execution | Break an approved bet into sequenced work, surface dependencies, and check artifacts for missing requirements. | Set scope, choose rollout controls, confirm instrumentation, and approve release readiness. | An instrumented release plan connected to feature flags, CI/CD, and observability. |
| Iteration | Compare expected and actual outcomes, organize qualitative feedback, and surface anomalies for review. | Decide whether to scale, revise, stop, or collect more evidence. | An updated decision record returned to the evidence spine. |
Exit criteria keep each stage honest. Discovery is not complete because the transcripts have been summarized. It is complete enough to move forward when the team can name the customer problem, the supporting evidence, and the uncertainty it intends to resolve next. Solution shaping is not complete because a PRD exists. It is complete when the hypothesis, constraints, acceptance criteria, test method, and required telemetry are clear enough for a responsible decision.
Plan measurement before release. If the team will use an A/B test, write the hypothesis and minimum detectable effect before looking at the result. If controlled experimentation is not appropriate, name the expected behavior change and the qualitative evidence that would support or challenge it. Feature flags provide controlled exposure, while observability helps the team understand why behavior changed rather than merely showing that it changed.
The workflow closes only when actual outcomes return to discovery. Comparing expected and actual outcomes, harvesting qualitative feedback, and feeding the result back into the evidence system turns a release into organizational learning. Without that return path, the model keeps retrieving yesterday’s beliefs even after the product has disproved them.
Engineer context, evaluations, and decision rights together
Reliability cannot be added as a final quality check. Every AI transformation can lose evidence, introduce unsupported language, or carry stale assumptions into the next stage. The workflow needs controls at the moment each failure can occur.
Give each task a context contract
One large prompt that tries to perform discovery, prioritization, specification, and planning will accumulate irrelevant material and conflicting instructions. Break the workflow into smaller tasks, each with a compact context contract:
- The decision or job the output must support.
- The approved evidence the model may use.
- The constraints and non-negotiable requirements.
- The information the model must not infer.
- The required output structure.
- The conditions that require human review.
Compact task prompts, curated turns, external memory, repeated critical instructions, and isolated sub-agents are practical ways to manage a limited context window. Use external state for durable decisions and retrieve only the relevant slice for the current task. Repeat a critical constraint when the context grows rather than assuming an earlier mention will retain equal influence.
Use a sub-agent when a task benefits from an isolated context or a separate review, such as checking a PRD against approved evidence. Do not add one merely to make the system look agentic. Every additional agent creates another handoff whose inputs, outputs, permissions, and failure behavior must be evaluated.
Build an evaluation harness before scaling the workflow
An evaluation should answer a repeatable question: does this workflow produce an acceptable result on representative work? A few impressive demonstrations do not tell you whether a prompt, retrieval change, or model update made the system more dependable.
Start with real task types your team already performs. Preserve representative inputs, the evidence that should be used, the requirements an acceptable output must satisfy, and known failure conditions. Then run those cases whenever you change the prompt, model, retrieval logic, tool permissions, or output schema.
Evaluate at least these dimensions:
- Grounding: Can each important claim be traced to approved evidence?
- Fidelity: Did the output preserve material differences, uncertainty, and constraints rather than flattening them into a convenient narrative?
- Completeness: Are the fields required for the next decision present?
- Decision usefulness: Does the output help a named owner make a specific choice?
- Data handling: Did the workflow respect access, redaction, and retention rules?
- Format and tool behavior: Did the model follow the schema and use only permitted systems or actions?
Eval-driven development makes prompts and heuristics repeatable. It also gives you a safer way to adopt new models: compare them against the same task set instead of judging them from a fresh demo with different inputs.
Measure learning flow, not AI activity
Documents generated, prompts executed, and summaries produced are activity measures. They can rise while product decisions become less reliable. Use four layers of measurement instead:
- Learning flow: Time from a customer signal to an evidence-backed decision, time spent waiting at handoffs, and rework caused by missing context.
- AI quality: Evaluation results by task, unsupported claims found during review, required fields missed, and human corrections before approval.
- Customer outcome: The activation, adoption, retention, or other behavior named in the original hypothesis.
- Delivery health: Deployment frequency, change failure rate, and the operational signals relevant to the release.
Keep decision rights visible beside those measures. The model may propose a priority, but the accountable product leader approves it. The model may draft a customer interpretation, but the product trio validates it against evidence. The model may prepare a release plan, but engineering owns operational readiness. Feature flags, access controls, and human approval are not signs that the workflow is insufficiently automated. They are what make greater automation responsible.
Log the decision, evidence references, model version, prompt or workflow version, retrieval configuration, evaluation result, and approving owner. Documenting decisions, model versions, and test artifacts makes a nuanced call auditable and gives the team a concrete starting point when quality changes.
Key takeaways: a 30/60/90-day rollout
Do not begin by automating the full product lifecycle. Start with one recurring decision, connect its evidence to its outcome, and prove that the loop can be operated reliably. A practical 30/60/90 sequence expands from the evidence foundation to selected workflows and then into planning and delivery.
- Days 1-30: Map the evidence systems used for one recurring product decision. Define the decision packet, access rules, retrieval path, current human gates, and initial evaluation cases. Build the smallest retrieval-first pipeline that can preserve links from a recommendation back to original evidence.
- Days 31-60: Pilot continuous discovery and PRD drafting. Keep approval manual, evaluate representative cases, record recurring corrections, and tighten the context contract. Do not expand until the team can identify why an output passed or failed.
- Days 61-90: Extend the proven pattern to prioritization and experiment design. Connect approved outputs to planning, CI/CD, feature flags, and observability. Feed release outcomes and customer feedback back into the evidence spine.
By the end of the rollout, you should be able to trace an AI recommendation to customer evidence, reconstruct why a decision changed, detect a quality regression after a workflow update, and compare the expected outcome with what happened after release. If one of those paths is missing, fix it before adding another agent or automating another handoff.
Your next move can be small. Choose one product decision scheduled for this week. Put its evidence, assumptions, success condition, and state into a decision packet. Then follow that packet through discovery, delivery, and the first outcome review. That single trace will reveal where your workflow is genuinely AI-native and where faster drafting is only hiding an old bottleneck.