You need a churn score soon. Customer success wants a prioritized account list, engineering wants requirements, and finance wants to know whether it is funding a vendor contract or a permanent internal capability. A polished model can still leave all three teams waiting if nobody has decided what happens after an account is flagged.
Start with the retention decision, not the algorithm. Once you know who will act, what they will do, and how you will measure the result, the build-versus-buy choice becomes much clearer.
Decide which capability you actually need to own
Churn prediction is often discussed as if it were a single model. In practice, it is an operating loop with several layers:
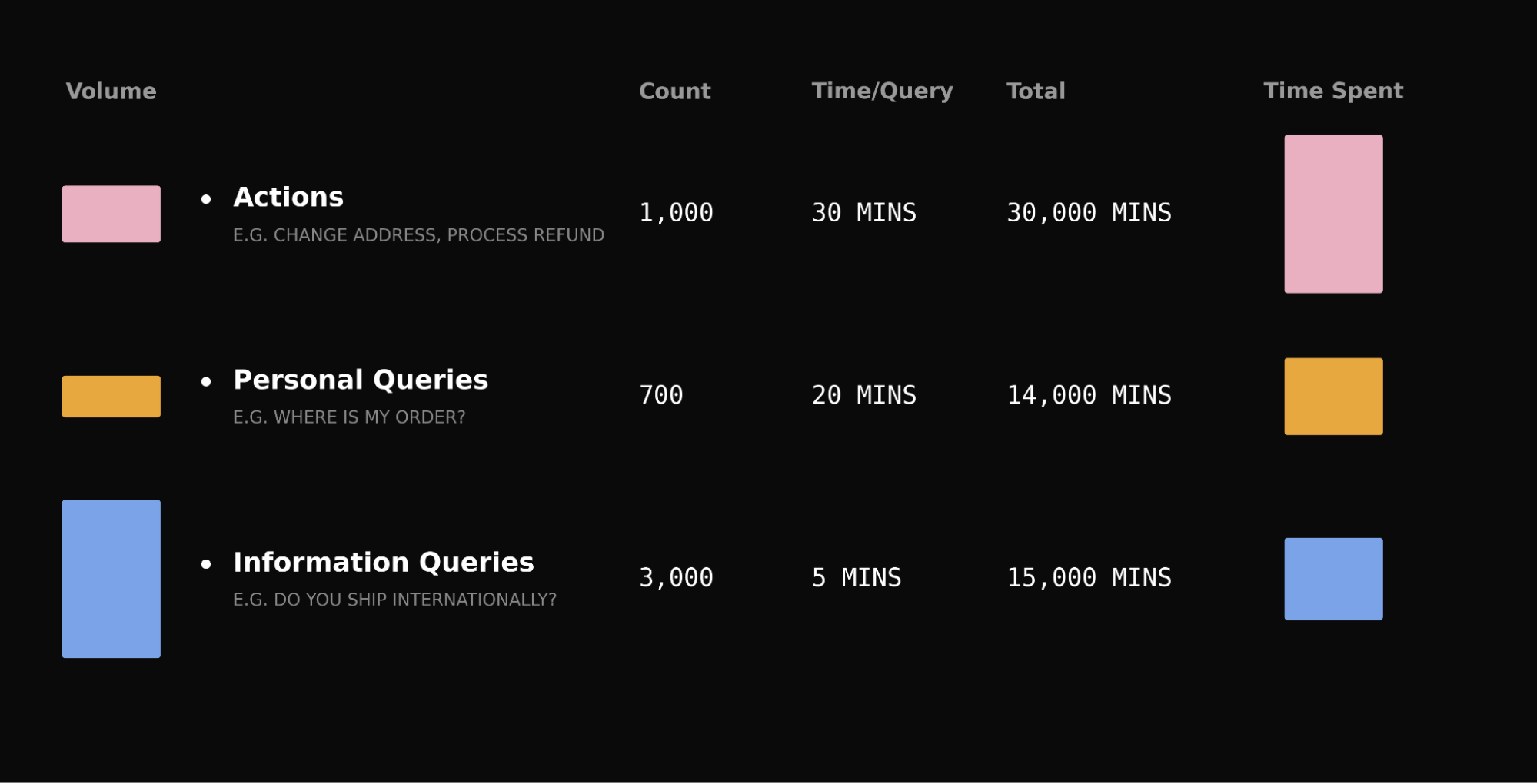
- Define the outcome. Specify which customers can churn, what event counts as churn, and the prediction window that gives your team enough time to intervene.
- Assemble the signals. Connect product usage, account attributes, engagement, support, billing, and other permitted data to a consistent customer identity.
- Estimate risk. Produce a score, category, or ranking that separates accounts requiring attention from the rest of the portfolio.
- Activate the prediction. Route the result into the CRM, customer-success workflow, lifecycle message, or in-product experience where somebody can respond.
- Learn from the intervention. Measure whether the action changed retention, adoption, engagement, or Net Recurring Revenue rather than assuming that a plausible score created value.
You do not necessarily need to own every layer. A vendor might provide behavioral analytics, scoring, in-app guides, and CRM integration while you retain ownership of the churn definition, intervention policy, and experiment design. Conversely, you might build a specialized risk model but continue using commercial tools to collect events and deliver treatments.
My default is to separate model ownership from outcome ownership. Your company must own the definition of success, the permitted uses of the score, and the learning loop. It only needs to own the model code when that ownership creates a strategic advantage.
Before evaluating an architecture or vendor, complete this sentence:
When a customer in [defined population] crosses [risk condition], [named owner] will take [specific action] through [named system], and I will judge the intervention using [business outcome].
If you cannot complete it, pause the model decision. You have an intervention-design problem. Buying software will automate the ambiguity, while building will make the ambiguity more expensive.
Run six decision gates before choosing a path
The right answer depends on more than whether your team can train a model. Use these gates to expose the constraint that should control the decision.
| Decision gate | Evidence to inspect | What pushes you toward a path |
|---|---|---|
| Time to value | Decision deadline, current churn visibility, and readiness of the first intervention | Urgent activation favors buying; a longer strategic horizon makes building more viable |
| Data readiness | Outcome labels, identity resolution, event consistency, signal freshness, and usable history | Immature data favors a packaged baseline while you repair foundations; reliable proprietary data strengthens the case to build |
| Strategic differentiation | Signals or decisions competitors and general-purpose vendors cannot reproduce | A must-have retention capability favors buying; a defensible product advantage favors building |
| Operating talent | Named owners for data pipelines, production scoring, monitoring, governance, and intervention design | Missing ownership favors buying; durable cross-functional capacity makes building credible |
| Activation fit | CRM, customer-success, messaging, analytics, and in-product delivery requirements | Standard integrations favor buying; specialized actions or product-embedded scoring may require a build or hybrid approach |
| Risk and explainability | Privacy, access, retention, audit, explanation, and regulatory requirements | Standard controls may fit a vendor platform; domain-specific constraints can justify owning selected layers |
Time to value: is speed useful, or merely urgent?
A short deadline only matters when an intervention is ready. If customer success already knows what it will do with a high-risk account, buying can put usable signals into existing workflows sooner. If the team has not agreed on an action, a fast score simply creates a faster queue of unanswered alerts.
Ask for the date on which a real user must receive the first actionable score. Then work backward through integration, workflow design, governance review, enablement, and experiment setup. This prevents a vendor demonstration or model prototype from being mistaken for operational readiness.
Data readiness: can your records support the decision?
A custom model cannot rescue an unstable churn definition or inconsistent customer identity. Inspect whether product events can be joined to the correct account, whether the churn outcome is recorded consistently, whether important segments have comparable coverage, and whether signals arrive early enough to support action.
Do not interpret weak data as an automatic reason to buy. A vendor cannot manufacture missing labels or repair every instrumentation gap. It can, however, give you a practical baseline using the signals already available while your team improves the data foundation.
Differentiation: would model ownership change your product advantage?
Build when proprietary context can materially improve the decision. That may include distinctive behavioral signals, domain-specific anomaly detection, specialized explanations, or a risk score embedded directly into your product. These are stronger reasons than a general preference to own technology.
If competitors could buy an equivalent capability and churn prediction mainly helps customer success prioritize outreach, ownership is unlikely to be the differentiator. Put product and engineering attention into the intervention, customer experience, and learning loop instead.
Talent: can you operate the system after launch?
Having someone who can train a model is not the same as having an operating team. A production capability also needs data engineering, scoring infrastructure, monitoring for drift, feature maintenance, incident ownership, governance, and a product owner who connects model changes to retention outcomes.
Put a name beside every continuing responsibility. An empty cell is not a future hiring plan; it is part of the build cost. If the same scarce people are also responsible for your core product, include the opportunity cost of redirecting them.
Activation: can the score reach the moment of action?
A prediction trapped in a dashboard has little retention value. Confirm that a score can create the right CRM task, customer-success play, lifecycle message, product tour, contextual tooltip, or in-app nudge. The recipient also needs enough explanation to choose an appropriate response.
Evaluate activation with a concrete scenario, not a feature checklist. Give a candidate vendor or internal team one representative account and ask it to show the full path from new behavior to updated risk, reason, assigned owner, intervention, and measured outcome. Any manual handoff in that path belongs in the decision record.
Governance: what must remain controlled and explainable?
Document which data may be used, who may see the result, how long inputs and scores are retained, what explanations users need, and how a customer could be affected by a mistaken classification. Privacy-by-design, data governance, regulatory compliance, and AI risk management apply whether the prediction is purchased or built.
Building gives you more design control, but it also transfers the burden of evidence, monitoring, and remediation to your organization. Buying transfers implementation work, not accountability. Require the same governance review for both paths.
The pattern is straightforward: buy when speed, standard coverage, and workflow activation dominate; build when proprietary signals, specialized explanations, or product differentiation dominate; blend when you need results now but have a credible reason to own selected layers later. A useful default is to buy a working baseline and build only where your context can create an outsized advantage.
Compare the full economics, not a license and a prototype
The most common cost comparison is structurally wrong: an annual software license is placed beside the effort required to train an initial model. One is closer to an operating capability; the other is an experiment. Compare both options across the same time horizon and include four cost classes: starting, running, changing, and exiting.
What belongs in the buy case
- License, usage, seat, and service costs that apply to the intended customer population.
- Implementation work for event collection, identity mapping, historical data, and system integrations.
- Security, privacy, legal, regulatory, and procurement review.
- Internal administration, score interpretation, workflow ownership, and user enablement.
- Configuration or services needed for segments, reason codes, guides, alerts, and experiments.
- Limits on data access, exports, custom features, scoring frequency, and downstream activation.
- Migration effort if the vendor no longer fits, including preservation of historical scores and experiment records.
What belongs in the build case
- Instrumentation, data quality, identity resolution, label construction, and feature pipelines.
- Exploration, training, evaluation, explanation design, and production validation.
- Batch or real-time scoring, storage, APIs, access control, and reliability engineering.
- CRM, messaging, customer-success, analytics, and in-product integrations.
- Monitoring for drift, broken inputs, coverage gaps, and unexpected segment behavior.
- Retraining, feature maintenance, documentation, incident response, and ongoing product ownership.
- Privacy controls, audit evidence, risk review, retention rules, and regulatory compliance.
- Replacement or migration work when the architecture, churn definition, or business workflow changes.
Add cost of delay to both cases. Buying may carry a visible contract cost, but waiting for a custom capability can defer retention experiments and leave customer-success capacity poorly targeted. Building may require more internal investment, but a vendor that cannot express your signals or deliver the required intervention can delay learning in a different way.
Keep benefit assumptions separate from cost estimates. The model’s theoretical accuracy is not a financial return. Estimate value only through an intervention that can plausibly affect customer behavior, then validate that assumption with an experiment.
Your comparison should therefore show three views for each path:
- Capability: which parts of the signal-to-action loop will actually work?
- Economics: what will it cost to start, operate, change, and exit?
- Evidence: what experiment will determine whether the capability improves retention or NRR?
If one option looks cheaper only because a row is blank, resolve the missing responsibility before approving it.
Use a hybrid path without creating two disconnected systems
A hybrid strategy is more than running a vendor score and an internal score at the same time. Done well, it sequences the work: buy the common layers needed for speed and activation, learn which proprietary signals matter, and build only the components that earn their continuing cost.
Phase one: establish a usable baseline
Choose one defined customer population, one churn outcome, and one intervention. Configure the purchased capability to produce a risk signal and a usable reason, then route both into the workflow where the named owner can act.
Record three different kinds of evidence:
- Prediction evidence: coverage, signal freshness, ranking or precision, stability across relevant segments, and the usefulness of explanations.
- Operational evidence: whether scores arrive in time, whether users understand them, and whether a flagged account reliably receives the intended treatment.
- Business evidence: whether the intervention changes retention, adoption, engagement, or NRR.
Do not use prediction quality to claim business impact. It is possible to identify high-risk accounts accurately and still deliver an ineffective intervention. It is also possible for a broad model to create value because it reaches the right team at the right moment. These are different questions and need different measures.
Phase two: test where proprietary context adds value
Use retention analysis to identify behaviors that appear meaningfully connected to continued use or churn. Focus on information a general-purpose platform cannot represent well, such as domain-specific sequences, unusual account structures, specialized failure states, or product-specific anomalies.
Introduce one material improvement at a time. Compare the resulting decisions with the baseline: which accounts move, whether the reason becomes more actionable, and whether the intervention performs better. A more complex score is not automatically a better product.
Use A/B testing or another appropriate controlled rollout to evaluate the intervention. Set the minimum detectable effect before the test so the team agrees on the smallest change worth detecting and whether the experiment can support the decision. Where withholding an intervention is inappropriate, compare credible treatments or use a phased rollout rather than treating measurement as optional.
Phase three: build only the layer that proved distinctive
The result may not be a complete vendor replacement. You might own a proprietary feature pipeline, domain-specific anomaly detector, custom explanation layer, or specialized risk score while retaining commercial analytics and activation. That is often a cleaner boundary than recreating collection, dashboards, integrations, guides, and workflow delivery.
Before moving a custom component into production, require evidence that:
- The proprietary signal changes a meaningful decision rather than merely changing a score.
- The resulting intervention has a credible path to measurable retention or NRR impact.
- A named team owns data quality, production reliability, drift monitoring, governance, and retraining.
- The migration preserves the activation loop instead of sending users to a separate dashboard.
- The added value justifies both the continuing cost and the engineering capacity displaced by the work.
Create a canonical risk contract before two systems coexist. Define the eligible population, outcome, prediction window, score meaning, reason codes, refresh expectations, owner, permitted actions, and measurement plan. Without that contract, teams will compare incompatible scores and select whichever one confirms their prior belief.
Run the custom component beside the baseline before switching interventions. Inspect coverage, stability, explanations, workflow behavior, and segment differences without changing several parts of the retention program at once. This makes the eventual migration a product decision supported by evidence, not an infrastructure milestone searching for a justification.
Key takeaways
- Buy when your immediate need is dependable coverage, rapid activation, and standard integrations for customer success or product-led growth.
- Build when proprietary signals, domain-specific risk scoring, specialized explainability, or product differentiation can create material value and you can fund continuing operations.
- Blend when you need a working baseline now and have a testable hypothesis about where your data or context can outperform a general-purpose capability.
- Do not approve any path until every score has a named recipient, a defined action, a delivery system, and a business outcome.
- Compare equivalent total costs, including data work, integrations, monitoring, governance, activation, opportunity cost, and migration.
- Measure the model and the intervention separately. Prediction quality can prioritize attention; only an effective action can improve retention.
Take a one-page decision memo into your next review. It should name the churn definition, first population, intervention, deadline, available signals, proprietary advantage, workflow, operating owners, governance constraints, total-cost boundary, and experiment. End the meeting with a selected path and an explicit condition for reconsidering it.
Start with the smallest path that closes the loop from behavior to action to measured outcome. Earn the right to build more by proving that your own data changes the decision and that the decision changes retention.