Weekly product reviews are where strategy meets execution, and over the past year I’ve turned them into a high-signal, low-friction ritual by leaning on agentic AI. As VP of Product Management at HighLevel, Inc., I’ve standardized a set of agent skills that compress preparation time, surface the right insights, and keep PMs, engineers, and designers focused on decisions—not document wrangling.
"Learn how our teams use agent skills with claude, cursor and codex to run product reviews as PMs, engineers, and designers. Here are 5 killer use cases for builder."
Below, I walk through the five skills I rely on most in our weekly cadence—each one mapped to a clear product management outcome. They’re simple to set up, easy to govern, and aligned with core practices like continuous discovery, product roadmapping and sprint planning, and eval-driven development.
Skill 1 — Backlog triage with signal extraction: I point an agent at fresh tickets, customer notes, and experiment results to cluster themes, tag impact, and flag regressions. Using a retrieval-first pipeline and Agent Analytics, the assistant ranks items by value, effort, and risk so our meeting starts with a prioritized, explainable shortlist instead of a raw queue.
Skill 2 — PRD and spec synthesizer: Ahead of the review, an agent drafts a one-page PRD update from design diffs, git history, and decision logs. With Claude Code and Cursor, it highlights interface changes, acceptance criteria, and open questions, linking back to sources. The result is a crisp, auditable brief that keeps product trios aligned without re-litigating context.
Skill 3 — Experiment and metrics analyzer: An analytics agent pulls A/B testing readouts, checks minimum detectable effect assumptions, and annotates anomalies. It turns raw telemetry into a narrative: what moved, by how much, and whether we trust it. This makes our discussion about tradeoffs, not spreadsheets, and speeds commitments on next steps.
Skill 4 — Voice-of-customer synthesizer: The assistant clusters interviews, support threads, and NPS verbatims into jobs-to-be-done and pain themes. It proposes opportunity solution tree updates and calls out places where our roadmap diverges from customer signal. That keeps continuous discovery alive in the room—even when time is tight.
Skill 5 — Roadmap and sprint planning co-pilot: After decisions, an agent converts outcomes into scoped backlog items, engineering tasks, and stakeholder updates. It drafts sprint goals, flags dependency risks, and aligns work to objectives. Because it’s grounded in the meeting record, it preserves intent while removing ambiguity.
Under the hood, prompt engineering patterns and guardrails keep these workflows predictable: a retrieval-first pipeline for context, eval-driven development for quality checks, and role-specific prompts for PMs, engineers, and designers. With Claude Code I generate structured diffs and test scaffolds; with Cursor I accelerate code-review summaries; and with codex I bootstrap utility scripts that keep the loop tight between insights and implementation.
The payoff is tangible: higher decision velocity, fewer meetings to “re-clarify,” and clearer accountability across the product organization. Just as important, governance and privacy-by-design are built in—every agent logs rationale, cites sources, and respects data boundaries—so leaders can scale AI workflows confidently.
If you’re looking to level up your product reviews, start with these five skills, measure impact with Agent Analytics, and iterate. Small automations compound quickly, and the more consistently you run them, the more your team’s attention shifts from preparing content to making better product decisions.
Inspired by this post on Amplitude – Perspectives.
I’m continually refining how we use analytics to elevate product marketing, and this collection brings together my most effective playbooks for driving measurable growth with Amplitude Analytics. If you’re focused on product-led growth, you’ll find pragmatic guidance on translating behavioral analytics into sharper positioning, stronger activation, and durable retention.
In my day-to-day work, I connect product strategy with go-to-market strategy by grounding every narrative in real user behavior. That means using event data to validate our value proposition, mapping journeys to uncover friction, and aligning product positioning with the moments that actually matter in-app. The outcome is a marketing engine that mirrors how customers discover, adopt, and expand within the product.
Activation and retention are where outcomes are won or lost. I detail how to set leading indicators for user activation, instrument key behaviors, and run retention analysis that distinguishes healthy engagement from noisy usage. You’ll see how I turn cohort insights into precise messaging, targeted onboarding, and experiments that compound over time.
Cross-functional execution is essential, so I share ways to operationalize a unified analytics platform across product, marketing, and customer success. With shared metrics, product trios can move faster from product discovery to launch, and marketing can scale campaigns that reflect what’s truly driving adoption. This tight loop reduces guesswork and increases our hit rate on both features and narratives.
If you’re building a modern product marketing function, these essays and guides will help you move from intuition-led storytelling to evidence-backed strategy. Dive in to learn how I connect behavioral analytics to positioning, packaging, and roadmap choices—so every campaign and release ladders up to meaningful customer outcomes and sustainable growth.
Inspired by this post on Amplitude – Perspectives.
Five years in, Continuous Discovery Habits continues to be one of the most practical frameworks I use to align empowered product teams, sharpen product strategy, and convert customer interviews into outcomes. To celebrate its impact, I’m hosting a community read-along and inviting you to dig in with me this May.
Each month, I’m releasing an in-depth reading guide to make learning stick. You’ll find the chapters we’ll be reading, a preview of the essential concepts, short videos to help you spread the ideas across your organization, individual and team discussion prompts, team exercises to put the concepts into practice, and additional reading if you want to go deeper. My goal is simple: help you turn product discovery into a steady habit, not a once-a-quarter activity.
We’ll discuss each month’s reading in the comments, and we’ll gather quarterly on a live call to compare notes and share what’s working. Joining late is absolutely fine—I monitor the conversation throughout the year. Start with the current month or rewind to January; you can ask for help, share wins and roadblocks, and connect with other readers anytime.
If you want to participate, grab a copy of the book (or dust off your old one), share the "Spread the Love" videos with your team, block focused time for the exercises, and register for the community sessions. Let’s do this together.
This Month’s Reading
Chapter: Chapter 6: Mapping the Opportunity Space
Estimated reading time: ~23 minutes
This month’s chapter will introduce you to why opportunity mapping is critical for structuring the ill-structured problem of reaching your desired outcome; how to move from overwhelming opportunity backlogs to well-structured opportunity spaces; the power of tree structures for depicting parent-child and sibling relationships between opportunities; how to identify distinct branches in your opportunity space using key moments in time; common anti-patterns to avoid when building your first opportunity solution tree; and why structure "gets done, undone, and redone" as you continue to learn.
Need a copy? Grab the book.
Share the Love with Friends and Colleagues
We learn best in community. Use these short videos to spread the core concepts from this chapter—then invite your team to join the book club with you.
The need for opportunity mapping – You will never fully satisfy your customers' desires
Understanding the structure of an opportunity solution tree – Depicting two types of relationships
Turn big intractable problems into smaller, more solvable problems – The power of decomposition
How to map an opportunity space – Getting started with opportunity solution trees
A well-structured opportunity space has distinct branches – Identify key moments in time
Reflect & Discuss What You Read
Reflection turns reading into capability. This chapter asks us to shift from reacting to every request to deliberately structuring the opportunity space. If you’ve ever felt overwhelmed by a never-ending backlog or pressure to ship output over outcomes, this is where the fog starts to lift. As you read, focus on how your team currently organizes (or doesn’t organize) what you hear from customers.
Individual Reflection
1) Think about your current product backlog or opportunity list. Is it a flat list, or do you have some structure to it? If you were to group similar opportunities together, what patterns would emerge?
2) When was the last time you heard a customer need and immediately jumped to a solution without exploring whether there were related opportunities? What would change if you took the time to map how that opportunity connects to others?
3) Review the anti-patterns from the chapter (opportunities framed from your company's perspective, vertical opportunities, opportunities with multiple parents, etc.). Which of these do you recognize in how your team currently talks about opportunities?
Team Discussion
1) As a team, pick a top-level opportunity you're currently working on. Try breaking it down into sub-opportunities together. Where do you struggle? Where do you disagree about how to frame or group opportunities? What does that tell you about gaps in your shared understanding?
2) Look at your experience map (from Chapter 4) and identify 3-5 distinct moments in time during your customer's experience. Could these become the top-level branches of your opportunity solution tree? Where do you see overlap, and where are there clear distinctions?
3) Discuss the quote from Barbara Tversky: "Structure gets done, undone, and redone." How does your team currently respond when you discover new information that changes how you understand the opportunity space? Do you treat your opportunity map as fixed or as something that evolves?
Put It Into Practice
Reading is step one; building your first opportunity solution tree is where the real learning happens. The exercises below are exactly how I coach product trios to transform ambiguous problems into aligned action.
Exercise: Build Your First Opportunity Solution Tree
Time: 60 minutes. Do this: With your product trio.
Start by reviewing your interview snapshots from the past few weeks. For each opportunity you captured, ask the three questions from the chapter:
Is this opportunity framed as a customer need, pain point, or desire (not a solution)?
Is this opportunity unique to one customer, or have we seen it in more than one interview?
If we address this opportunity, will it drive our desired outcome?
Then, using your experience map, identify 3-5 distinct moments in time to serve as your top-level opportunities. Group the opportunities from your interviews under these top-level branches.
Look for opportunities to add structure to each branch. Group similar opportunities together and identify a parent opportunity. Look for vertical stacks (one parent, one child) and fill in missing siblings. Reframe opportunities that are too broad or that could live in multiple branches.
Don’t aim for perfection. Get something on paper (or a digital canvas) and iterate the tree with every new interview.
Exercise: Practice Framing Opportunities from Your Customer’s Perspective
Time: 30-45 minutes. Do this: With your product trio.
Take 10-15 opportunities from your current backlog or list. For each one, ask: "Can I imagine a customer saying this?" If the answer is no, reframe it from your customer’s perspective. For example:
"Increase subscription conversions" becomes "I want to know if this product is worth paying for"
"Reduce support tickets" becomes "I can't figure out how to do X"
"Improve onboarding completion" becomes "I'm not sure what to do next"
This exercise helps you spot business-centric opportunities disguised as customer opportunities. It also trains your team to listen for opportunities in interviews that are framed from the customer’s point of view.
Go Deeper: Additional Reading
If you prefer an audio summary of this month’s reading, including the book chapters and the following resources, I’ve included an audio version for paid subscribers at the bottom of this post.
Related In-Depth Guides
Opportunity Solution Trees: Visualize Your Discovery to Stay Aligned and Drive Outcomes
Customer Interviews: Uncover Hidden Insights from Every Conversation
Supplementary Reading
Prioritize Opportunities, Not Solutions
Product in Practice: Opportunity Mapping at Grailed
Product in Practice: Opportunity Mapping at trivago
7 Key Benefits of Using Opportunity Solution Trees
Getting Started with Opportunity Solution Trees at SuperAwesome
Bringing Order to Chaos: Using Opportunity Solution Trees in Everyday Life
Other Voices
Why Groups Struggle to Solve Problems Together by Al Pittampalli
More PM Problem Areas by Marty Cagan
Five Superpowers of Diagrams by Abby Covert
Critical Thinking is Product Management by This Is Product Management
Our Live Discussion Schedule
Our live discussion sessions are for paid subscribers. Sessions are not recorded. Invitations will go out to Supporting Members and CDH Members two weeks before the scheduled event. But reserve the time on your calendar now.
Tuesday, June 16, 2026: 9am-10am PDT
Thursday, September 17, 2026: 9am-10am PDT
Wednesday, December 16, 2026: 9am-10am PST
Audio Summary
This summary was produced by NotebookLM. The sources supplied were the book chapters as well as all of the additional reading.
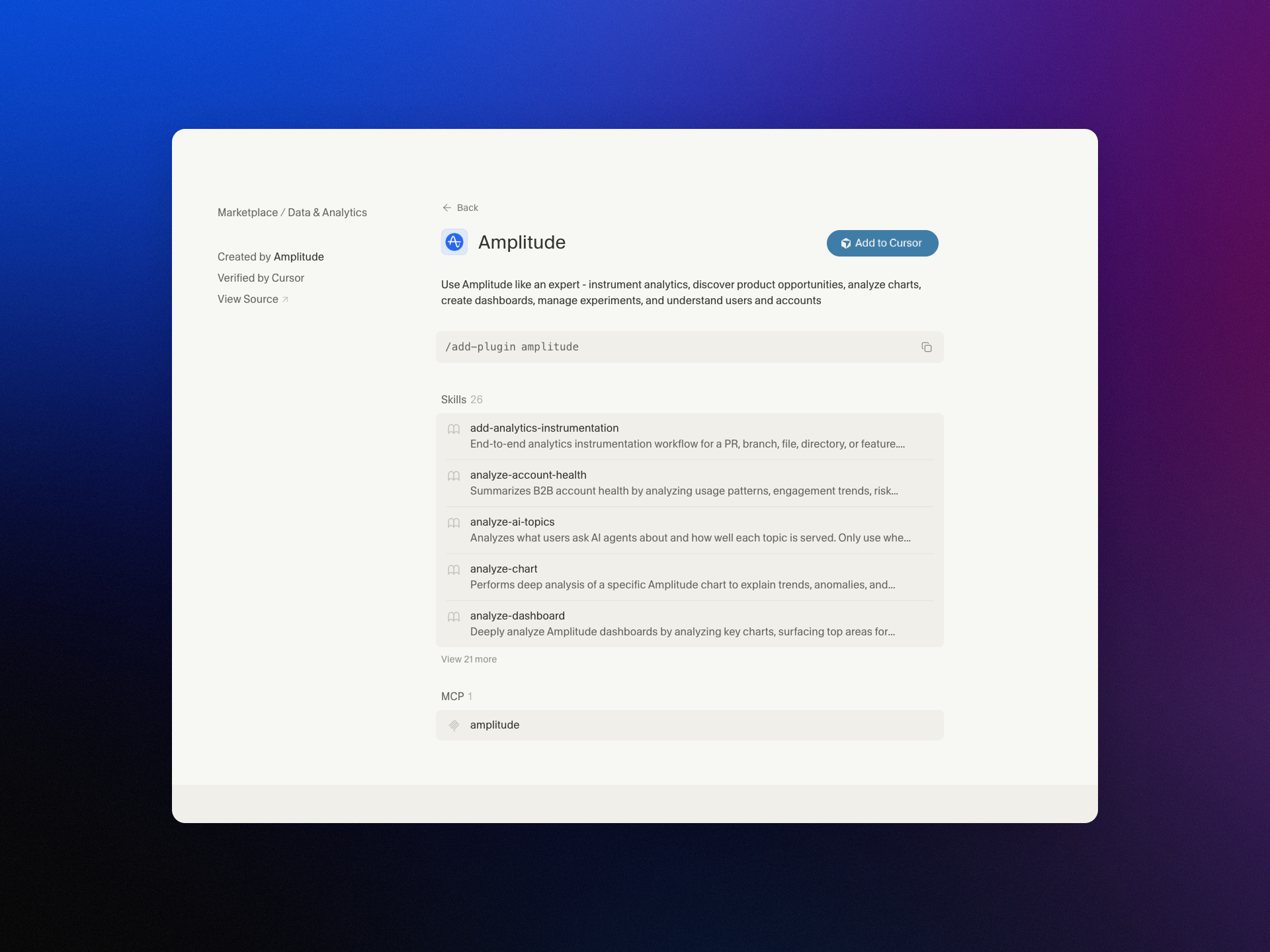
I’m excited to share that we’ve brought Amplitude Plug and Play to the Claude and Cursor marketplaces—a lightweight way to infuse your everyday prompts with serious product analytics context and speed.
"Learn more about our new AI plugin, the easiest way to turn your favorite AI client into an analytics expert with a single-install."
For years, I’ve watched teams lose momentum hopping between dashboards, docs, and spreadsheets just to answer simple questions like “What changed in activation last week?” or “Which cohort is driving retention?” With Amplitude analytics and behavioral analytics at the core, Amplitude Plug and Play collapses that friction by bringing the answers to where you already think and build—inside Claude and Cursor.
In practice, this means I can ask natural-language questions such as “Show me the funnel from signup to activation by region,” “Compare retention week over week for new users from our latest release,” or “Summarize our last A/B testing results on onboarding” and get structured, context-aware responses. The goal is to keep me in flow while still honoring the rigor of a unified analytics platform.
What I love most is how this elevates both discovery and delivery. Product managers can accelerate continuous discovery by querying cohorts, drivers, and anomalies mid-conversation. Engineers working in Cursor or with Claude Code can validate event definitions, sanity-check metrics, and spot regressions without leaving their IDE. The result is tighter feedback loops and better decision quality.
Just as importantly, the experience is designed for clarity and consistency. When I ask about activation, I expect the same canonical definition every time. When I explore a retention analysis, I want clear assumptions and transparent logic. By anchoring responses to well-defined metrics and event taxonomies, the plugin helps reinforce good data governance while keeping the interaction fast and conversational.
Getting started takes only a few minutes. Open the Claude or Cursor marketplace, search for Amplitude Plug and Play, complete the single-install flow, and connect to your Amplitude analytics workspace. From there, start prompting as you normally would—only now your AI client can reason with product context.
This launch is part of how I see gen ai reshaping AI workflows for product teams: less context switching, more signal per prompt, and a shared, accessible understanding of what’s really moving the business. If you’re ready to turn your AI assistant into a trusted partner for product insight, Amplitude Plug and Play is a powerful next step.
Inspired by this post on Amplitude – Best Practices.
Your Amplitude dashboard is populated, but the room still debates whether the numbers are real. Engineering sees successful requests. Product sees unexplained breaks. Each feature adds more events, yet confidence in the data keeps falling.
You do not fix this by collecting more data or polishing the dashboard. You fix it by treating instrumentation as a product interface: designed around a decision, expressed as a clear contract, reviewed with the code, tested against real journeys, and monitored after release.
Design the decision before you name the event
The most common instrumentation failure starts before an engineer writes code. A stakeholder asks to track a page, button, or feature without saying what decision the data must support. The resulting event may be technically valid and still be useless.
Begin with a decision statement: If this behavior differs by this segment or step, I will change this part of the product. That sentence forces you to identify the behavior, comparison, and possible action. If nobody can describe the action, the proposed event is probably speculative inventory rather than decision-grade data.
Suppose you need to decide whether team invitations are blocking activation. A useful behavioral sequence might contain Workspace Created, Invitation Sent, Teammate Joined, and First Shared Action Completed. The important work is not typing those labels. It is defining what each one means.
Does Invitation Sent fire when someone clicks the button, when the request succeeds, or when the message is accepted for delivery?
Does Teammate Joined mean the invite was accepted, the new user signed in, or the user entered the intended workspace?
Can retries emit the same behavior more than once?
Can an existing user join through a path that bypasses the invitation flow?
Which actor owns the event: the inviter, the invitee, the workspace, or some combination?
Those distinctions determine whether the funnel represents the customer journey or merely the user interface. A click is evidence of intent. A confirmed state change is evidence of completion. Track both only when you have a real use for both, and do not give them names that imply the same meaning.
Use events for behaviors that happened and properties for the context needed to interpret them. If email and link invitations represent the same business action, use one Invitation Sent event with an invitation channel property. Split them into separate events only when their meanings, lifecycles, or downstream decisions genuinely differ.
Before approving an event, require answers to five questions: Who will use it? What decision will it change? What exact condition emits it? What else could produce the same signal? What will you do if the result moves? This keeps the tracking plan small enough to govern and precise enough to trust.
Turn the tracking plan into an executable contract
A tracking spreadsheet is not a contract if the implementation can drift from it unnoticed. The definition must be specific enough for an engineer to implement, a reviewer to challenge, and an automated check to validate.
Data quality has several independent layers. Structural validity asks whether the payload follows the expected schema. Semantic validity asks whether the event means what its name claims. Coverage asks whether every intended surface and journey emits it. Identity integrity asks whether behavior is attached to the right user, account, or workspace. Passing one layer does not prove the others.
An event can therefore be perfectly formatted and analytically false. Invitation Sent with a valid channel property still misleads you if it fires before the backend confirms success. This is why human-readable names and strict schema validation are necessary controls, but not the whole quality system.
Contract field
What to specify
Failure it prevents
Decision and metric
The product question, downstream measure, and action the signal can change
Events collected without a defined use
Canonical event
One stable, human-readable name and any forbidden aliases
Several names for the same behavior
Trigger and completion boundary
The exact state transition, success condition, and behavior on failure or retry
Clicks or attempts being counted as completed outcomes
Emitter and source of truth
The client, server, worker, or other component responsible for emission
Double counting when multiple layers report the same action
Actor and entity
The user, account, workspace, or object to which the behavior belongs
Metrics grouped around the wrong unit of analysis
Required properties
Names, types, allowed values, null rules, and derivation logic
Broken segments and silent type drift
Identity behavior
Expected handling before sign-up, after login, after logout, and during account changes
Split histories, merged users, and misplaced account activity
Environment and release context
How production, test data, application versions, and relevant platforms are distinguished
Test traffic contaminating decisions or regressions being hidden in aggregates
Owner and lifecycle
The accountable team, review status, downstream consumers, and deprecation path
Orphaned events that nobody can safely change or remove
QA evidence
The automated assertion, tested journey, sample payload, and production verification
Approval based only on code inspection
Property rules deserve the same precision as event rules. Decide whether an absent value means unavailable, not applicable, or an instrumentation defect. Keep types stable. Define bounded values where the business vocabulary is bounded. Avoid using display copy as an analytical value because a harmless wording change can fragment the data.
Treat a property type change, trigger change, or identity change as a breaking contract change. Adding a new optional property is usually less disruptive than changing what an existing field means. When meaning must change, introduce an explicit migration plan and identify which historical comparisons will no longer be valid.
Identity needs its own test plan. Exercise an anonymous visit followed by registration, a returning-user login, logout on a shared device, switching between workspaces, and any cross-device journey you intend to analyze. Verify the resulting user and account histories instead of assuming the SDK calls produce the business behavior you want.
Apply data minimization at the contract boundary. Every property should have a decision use, an owner, and an acceptable data classification. Do not collect free-form or sensitive values merely because they might become useful later. Preventing unnecessary capture is safer than trying to contain it after it has entered the analytics pipeline.
Make the pull request your instrumentation quality gate
Developer-first instrumentation does not mean product hands analytics to engineering and walks away. It means the analytics contract follows the same change-management path as the behavior it describes. The code, definition, tests, and review evidence move together.
Start in a feature branch. Run the setup workflow there so configuration and instrumentation changes are visible before they reach the main branch.
Update the analytics contract in the same pull request as the feature. A behavior change without its contract delta is incomplete; a contract change without its implementation is unverifiable.
Review the emission boundary. Confirm that the event fires on the intended success condition, has one authoritative emitter, handles retries deliberately, and does not fire on rendering unless rendering is the behavior you mean to measure.
Run structural checks in CI/CD. Validate canonical names, required properties, types, permitted values, environment configuration, and forbidden fields. Fail the build when a known contract is violated.
Run behavioral tests around the analytics client. Exercise success, failure, cancellation, and retry paths, then assert which events should and should not be emitted. A negative assertion is often what catches inflated success metrics.
Verify the journey in a non-production environment. Capture the observed sequence and payload, then compare them with the contract. Keep this traffic distinguishable from production behavior.
Define the production check before merging. Name the owner, expected signal, dimensions to inspect, downstream chart or cohort affected, and response if the data does not match the release.
Automated checks are strongest at detecting known structural failures. They can prove that a required field exists; they cannot decide whether the field represents the right business concept. Keep a lightweight semantic review in the pull request. Engineering should own trigger and runtime correctness. The product or analytics owner should own meaning and downstream use. Bring in privacy or security review when the identity model or captured data changes.
The reviewer should be able to reconstruct the analytical meaning without reading every implementation detail. Include the decision statement, contract change, sample payload, tested journey, and affected measures in the pull request. That context preserves intent when the original team has moved on and makes later taxonomy changes auditable.
Do not turn the gate into an analytics committee. Most changes need a clear owner and one qualified reviewer, not a meeting. Escalate when a change redefines a shared event, alters identity, introduces sensitive data, or breaks historical comparability. Routine additions that conform to the contract should remain routine.
Prove production data is decision-grade, then keep proving it
A successful deployment proves that code reached production. It does not prove that actual customers, application versions, queues, retries, and identity transitions produce trustworthy analysis. The final quality gate operates on observed production behavior.
Inspect new or changed instrumentation by release, platform, environment, emitter, and relevant customer segment before relying on an aggregate. Aggregates can hide a missing platform, a version-specific regression, or duplicate client and server events.
Presence: Did the intended event appear after the release, and is an unexpected absence explained by traffic or by a defect?
Completeness: What share of observed events contains each required property, and where are missing values concentrated?
Conformance: Did new property values or types appear outside the agreed contract?
Uniqueness: Do retries, page transitions, or multiple emitters create suspicious duplicate patterns?
Sequence sanity: Can a completion event occur without the prerequisite behavior, and is that a legitimate alternate path?
Identity continuity: Do anonymous, authenticated, user, and account histories connect in the journeys that matter?
Comparability: Did the release change the meaning or population of an existing metric even though its name stayed the same?
Set alert and acceptance thresholds from expected traffic, historical behavior, and the cost of a wrong decision. A universal percentage would create false precision. An event used for an executive activation metric deserves a tighter response than a diagnostic event used occasionally by one feature team.
Give every important event a visible trust state. Proposed means the contract exists but the code does not. Instrumented means the code is deployed. Observed means production data has arrived and basic checks passed. Trusted means the owner has verified the real journey and approved downstream use. Deprecated means new analysis should stop depending on it. This vocabulary prevents a dashboard builder from treating mere event presence as approval.
When production data is wrong, treat it like a data incident. Record the affected event, properties, segments, and time window. Identify the dashboards, experiments, and decisions that consume it. Stop or correct the bad emission. Backfill only when the intended values can be reconstructed deterministically from reliable records; otherwise, preserve the gap and mark the period as non-comparable. A plausible-looking repair is more dangerous than an explicit hole because it hides uncertainty.
Add the failure mode to the contract test after the repair. If a retry caused duplicates, add a retry case. If one platform omitted a property, cover that platform. If identity changed during a workspace switch, turn that journey into a regression test. The incident should leave the instrumentation system harder to break in the same way.
Govern by change triggers rather than recurring ceremony. Review instrumentation when a team launches a new journey, moves an event between client and server, changes identity behavior, modifies a shared taxonomy, adds a platform, or sees unexplained production drift. This focuses attention where meaning can change.
Start every event with a decision, observable behavior, and named owner. If the possible action is unknown, do not collect the event by default.
Define trigger, emitter, actor, properties, identity behavior, environment handling, and QA evidence as one versioned contract.
Ship the contract, implementation, automated checks, and journey evidence in the same pull request.
Separate structural validation from semantic review. A valid payload can still represent the wrong behavior.
Promote events from instrumented to trusted only after production verification, and mark damaged periods instead of silently presenting them as comparable.
Use the next feature as the boundary for change. Pick one consequential customer journey, write its contract, put the instrumentation through the pull request, and verify it after release. Do not wait for a company-wide taxonomy rewrite. One fully governed journey will expose the missing standards and give you a working pattern for the next one.
If your team cannot show the contract, test evidence, production check, and current trust state behind a metric, do not use that metric for a roadmap or growth decision yet. Label the uncertainty, repair the signal, and make trust part of the definition of done.
You are not really deciding whether an LLM can chat about a menu. You are deciding whether it can turn a messy WhatsApp exchange into a correct, payable order without making the customer or venue staff repair its work.
That distinction changes the product. The hard parts are structured order state, deterministic commerce operations, response time, failure recovery, and venue-specific evaluation. Get those right and WhatsApp can become a genuine ordering channel. Get them wrong and you have a fluent chatbot sitting in front of an unreliable transaction.
Key takeaways
Define success as a confirmed, recoverable order in the system of record, not a conversation that sounded helpful.
Let the model interpret customer language, but keep menu data, prices, modifiers, delivery eligibility, payment state, and order commits behind deterministic tools.
Store the current order as structured state outside the transcript. A conversation is evidence of intent, not an order ledger.
Measure useful response time across the complete WhatsApp-to-POS path, then remove tool round trips and parallelize safe read operations.
Make item identification accuracy the primary trust metric, supported by guardrails for modifiers, payments, duplicate submissions, handoffs, and latency.
Evaluate every venue against its real menu and rules, then turn recurring configuration, tests, and operating procedures into reusable templates.
Define the product around a completed order
WhatsApp is the interface, not the product boundary. The product boundary should run from the customer’s first request to an order state that the venue can fulfill and the customer can verify.
Write an order contract before choosing models or orchestration frameworks. The contract is the minimum structured state required to fulfill, charge for, recover, and audit an order. It will usually include:
The venue and the applicable menu version.
Canonical item identifiers, quantities, and customer-facing item names.
Required and optional modifier selections, represented by identifiers rather than prose alone.
Fulfillment method, such as pickup or delivery.
The validated delivery result when delivery is requested.
A system-generated quote, including the values the customer must approve before payment or submission.
Payment-link and payment states, without treating a generated link as proof of payment.
Customer confirmation state, POS submission state, and the resulting order identifier.
The current owner of the interaction: agent, venue staff, or a defined recovery process.
The contract gives product, engineering, operations, and venue teams the same definition of done. It also exposes where autonomy is not yet safe. If the integration cannot validate a delivery zone, for example, the agent should collect the address and hand the order to a person. It should not infer eligibility from a conversational guess.
Order stage
The agent’s job
Condition before proceeding
Discover
Map natural language to menu candidates and explain relevant options.
One supported item is identified, or the agent asks a specific clarifying question.
Configure
Capture quantity, required modifiers, exclusions, and additions.
Every required choice is present and valid for that item.
Fulfillment
Resolve pickup or delivery and call the applicable eligibility checks.
The requested fulfillment method is supported for this order.
Quote and payment
Retrieve the authoritative quote and create the approved payment flow.
Prices and payment state come from the commerce system, not generated text.
Commit
Present the structured summary and submit the confirmed order once.
The customer has confirmed the current version and the POS returns a result.
Status and recovery
Report system-backed status or transfer the interaction with its context intact.
The response is tied to an order identifier or an explicit handoff owner.
Pay particular attention to the acceptance boundary. A friendly message such as “your order is being prepared” is an operational commitment. It must only appear after the system of record has accepted the order. If submission times out or returns an ambiguous result, the safe response is that confirmation is still pending, followed by a status check or human recovery. Guessing success can create duplicate orders, missed orders, and payment disputes.
You can still launch with partial automation, but name it accurately. Menu search, order drafting, and staff-assisted submission can deliver value while the integrations mature. The mistake is allowing the customer to believe the order was accepted when the product has only generated a plausible summary.
Keep the order deterministic even when the conversation is not
Customers do not speak in schemas. They change quantities, refer to items by incomplete names, add a second request before answering the first question, and revise earlier choices. Your architecture has to translate that non-deterministic conversation into structured, POS-compatible data without losing which version the customer actually approved.
My rule is simple: the model may interpret intent and propose an order-state change, but deterministic services must validate and commit it. The transcript should never be the only place where the current order exists.
A reliable turn can follow this sequence:
Load the current structured order, venue configuration, and relevant menu context.
Interpret the latest message as a proposed change: add, remove, replace, modify, confirm, cancel, pay, or request status.
Resolve referenced items and modifiers to canonical identifiers.
Call read-only tools for availability, configuration, fulfillment rules, or quotes as needed.
Validate the proposed change against required modifiers and venue rules.
Write a new order-state version and generate the next response from that validated state.
Use a separate, idempotent write operation when the customer confirms submission.
This design makes corrections much safer. If the customer says, “Make the second one large and remove the fries,” the agent should apply a state delta to the identified lines, validate the revised configuration, and show the updated summary. It should not regenerate the entire order from memory and hope that unrelated details remain intact.
Tool contracts should be narrow and explicit. Menu search should return canonical candidates and the information needed to distinguish them. Item detail should return valid modifier groups. A quote tool should return authoritative values. A payment tool should return a system-created link or a structured error. An order-submission tool should return an accepted identifier, a definite rejection, or an unresolved state that triggers recovery.
Do not let the model invent a price, payment URL, availability claim, delivery decision, or order status. These are business facts with financial and operational consequences. The response composer can explain them in natural language, but the underlying values must come from an approved system.
Separate reads from writes in the architecture. Independent menu and item lookups can often run in parallel. Writes should be serialized against a known order-state version. Every commit operation should accept an idempotency key so a retry cannot create a second order. If the state changed after the customer saw the summary, require confirmation of the new version rather than silently committing it.
The same discipline applies to human handoff. Transfer the structured cart, unresolved question, relevant tool results, and submission state along with the transcript. A handoff that forces staff to reread the entire conversation and reconstruct the order is not graceful degradation; it is deferred manual work.
Choose the orchestration pattern from the service objective, not from architectural fashion. Under tight response constraints, AITropos chose direct tool calls instead of MCP or a multi-stage pipeline to reduce orchestration overhead. That is not a universal argument against MCP. It is a reason to benchmark the actual path. Compare end-to-end latency, traceability, schema governance, failure isolation, and engineering cost using representative ordering turns. If an abstraction adds useful control, keep it. If it only adds another round trip, remove it.
Manage latency as part of the customer experience
The model’s inference time is only one part of latency. From the customer’s perspective, the clock starts when the message is sent and stops when a useful next action arrives. Context retrieval, menu search, validation, payment calls, POS submission, message delivery, retries, and overloaded queues all sit inside that interval.
Instrument the complete path before optimizing it. Capture timestamps for message receipt, context assembly, model execution, every tool call, state validation, response creation, and outbound delivery. Report median and tail latency by turn type. A single average can hide a checkout path that is consistently slower than menu questions.
At minimum, separate these turn classes:
Menu discovery and recommendation.
Item identification and configuration.
Cart edits and corrections.
Delivery or fulfillment validation.
Quote and payment-link creation.
Order confirmation and POS submission.
Order-status retrieval.
Human escalation and recovery.
Set a service objective for each class from observed channel behavior and the operational risk of delay. There is no useful universal number. A status lookup and a multi-item order edit do different work. What matters is that the team can see which component consumes the budget and what happens when that component times out.
Optimize in the order that removes uncertainty as well as delay:
Remove unnecessary model and tool round trips. Load the active order and venue configuration before asking the model what to do.
Parallelize independent read operations, such as resolving multiple products mentioned in one message.
Prefetch likely item context so the agent does not discover basic menu facts one call at a time.
Inject only the context needed for the current turn. An oversized prompt moves latency rather than eliminating it.
Keep deterministic validation outside the model when a rule or schema check can answer immediately.
Give every external dependency a timeout, an observable error state, and a safe recovery path.
Use concise responses that advance the order. Extra prose increases reading time and can obscure the decision you need from the customer.
Watch the failure mode on the other side of aggressive optimization. Cached menu metadata can reduce retrieval work, but stale availability or price data can create a wrong commitment. Define which fields are stable enough to cache, how they are invalidated, and which values must be retrieved at quote or submission time. Speed is valuable only when the answer remains authoritative.
When a slow operation cannot be avoided, use an honest progress message and preserve the pending state. Do not fill the wait with repeated acknowledgements that imply completion. If the customer sends another message while the tool is running, the state machine should know whether to queue the change, cancel the pending operation, or ask the customer to wait for its result.
Evaluate each venue, then template what repeats
Make item accuracy precise enough to govern decisions
Item identification accuracy deserves to be the primary trust metric. If the agent resolves the wrong item, every later component can behave perfectly and still produce the wrong order. AITropos treats order item identification accuracy as its most important KPI, giving model, prompt, retrieval, and fallback decisions a common objective.
Define the metric before building a dashboard. I would count an attempted line item as correct only when the canonical item, quantity, and required modifier interpretation match the customer’s resolved intent. A necessary clarification is not automatically an error; it should count against a separate clarification-burden metric. Otherwise, the team may improve apparent accuracy by asking the customer to confirm every obvious detail.
Do not let the primary KPI hide transaction failures. Pair it with guardrails for:
Unsupported substitutions or invented items.
Missing and invalid required modifiers.
Customer corrections after the agent presents a summary.
Quote, payment-link, and POS tool failures.
False confirmations, unresolved submissions, and duplicate commits.
Order completion and abandonment by journey stage.
Human handoff rate, reason, and time to recovery.
End-to-end latency by turn class and venue.
Link corrections back to the original decision. If the customer changes an item because the agent misunderstood it, label the item-resolution turn rather than treating the correction as an unrelated edit. That is how production behavior becomes useful evaluation data instead of a collection of support anecdotes.
Simulate failures before customers encounter them
A venue-specific evaluation suite should use that venue’s menu identifiers, modifiers, availability behavior, delivery rules, payment flow, and POS adapter. A generic restaurant benchmark can test language understanding, but it cannot tell you whether the agent knows that a particular size requires a particular modifier or that two similar menu names map to different SKUs.
Build test families for:
Incomplete names, colloquial references, and ambiguous matches.
Several products requested in one message.
Required modifiers, exclusions, additions, and invalid combinations.
Quantity changes, replacements, removals, and cancellation.
Unavailable items and acceptable alternatives.
Pickup, delivery, and addresses that cannot be validated.
Quote changes before confirmation.
Payment failure, delayed payment state, and an abandoned payment flow.
Tool timeouts, malformed tool results, retries, and uncertain POS submission.
Interrupted conversations that resume with an existing cart.
Requests that require staff judgment rather than autonomous execution.
Generate the expected structured order independently from the agent being tested. Otherwise, the same model can reproduce its own misunderstanding in both the answer and the grade. Keep a small, human-reviewed set of critical conversations alongside the larger generated suite, and add every material production failure to the permanent regression set.
Scale matters when menus contain many combinations. Before each new venue goes live, AITropos runs thousands of simulated customer conversations overnight. The number alone is not the release gate. Coverage, a trustworthy expected answer, and clear failure categories are what make simulation useful.
Simulation also cannot reproduce every production condition. Follow it with a staff sandbox and a controlled production phase. Use only redacted, properly authorized customer conversations in evaluation systems, and retain no more personal data than the test requires.
I would treat any path that invents a price or payment state, falsely confirms an order, or can duplicate a commit as release-blocking. Other thresholds should reflect the venue’s menu complexity, existing human baseline, handoff capacity, and the cost of a wrong order. Record those thresholds before the final test run so launch pressure cannot redefine success afterward.
Roll out autonomy in observable stages
Start with a venue that is operationally manageable but representative enough to expose real modifiers, fulfillment rules, and integration behavior. An unusually simple pilot may produce a clean demo while postponing the problems that determine whether the product can scale.
Configuration: ingest and normalize the menu, map canonical identifiers, mark required modifiers, connect fulfillment and payment rules, and produce a completeness report. No customer-facing ordering is enabled.
Sandbox: let venue staff run realistic conversations while write tools remain disabled or point to a test environment.
Approval mode: allow the agent to prepare a structured order, but require a person to approve the commit. Measure how often the person changes it and why.
Constrained production: enable autonomous submission for the supported venue, fulfillment modes, and order types, with a staffed handoff path and rapid rollback.
Expansion: widen scope only after production traces confirm the accuracy, latency, recovery, and operational workload expected by the release criteria.
For every stage, decide who can pause the agent, how staff take over an active conversation, how the customer learns that a person has taken over, and how an uncertain submission is reconciled before another order is created. These are product requirements, not post-launch operating notes.
Once one venue works, resist copying its prompt and integrations into a new branch. Make venue differences configuration wherever possible: normalized menu schemas, modifier patterns, fulfillment policies, tool mappings, escalation contacts, evaluation packs, and dashboard dimensions. Keep truly distinct behavior explicit rather than burying it in prompt prose.
The scalability payoff can be substantial. AITropos reduced new-venue onboarding from three months to a few weeks, while domain templates are being used to shorten it further. Track your own onboarding work by category: configuration, data cleanup, integration, prompt or policy changes, evaluation, venue training, and launch support. If every venue still requires bespoke code and a rewritten conversation flow, the product has not yet separated its platform from its implementations.
Your next step should be concrete. Choose one representative venue and create three artifacts: the canonical order contract, a failure-and-recovery matrix for every tool, and a venue-specific evaluation set built from redacted, authorized scenarios. If those artifacts cannot show what happens when item resolution, a modifier, delivery validation, payment, or POS submission fails, the agent is not ready to accept orders. Once those states are explicit, model and architecture choices become testable decisions rather than matters of confidence.
You open a portfolio review and find an AI request from nearly every direction. One team wants an assistant. Another wants an agent. A third has a promising prototype that now needs production funding. Every request sounds plausible, yet approving all of them would spread the company across disconnected experiments.
This isn’t primarily a prioritization problem. It is a leadership-system problem. Your job as CPO is to define the customer advantage worth pursuing, concentrate attention on a few coherent bets, specify the evidence that earns more investment, and make it clear what the company will stop doing. The roadmap should record those choices. It should not make them for you.
Allocate attention before you allocate roadmap space
AI expands the number of things a product team can plausibly build. It does not expand engineering capacity, customer attention, management bandwidth, or the company’s tolerance for operational risk at the same rate. That mismatch is why an orderly backlog can still represent a deeply unfocused strategy.
A prototype adds to the confusion because it compresses the distance between an idea and a convincing demonstration. A good demo shows that a capability may be technically possible under selected conditions. It does not establish that customers will adopt it, that it will perform reliably across real workflows, that its economics will work, or that competitors cannot reproduce it.
Before discussing priority, force each proposed investment through four decisions:
Customer advantage: What will a specific customer be able to do materially better, faster, or more safely?
Behavioral outcome: What observable change would show that the advantage matters, such as stronger activation, repeated use, retention, or expansion?
Business consequence: Which company outcome should move if the customer behavior changes, such as NRR, gross margin, payback, or cost-to-serve?
Opportunity cost: Which existing initiative, workflow, or commitment will receive less attention if this bet is funded?
The fourth decision is where focus becomes real. If a proposal enters the portfolio without displacing time, money, or executive attention somewhere else, the company has not prioritized it. It has merely added it.
A shared driver tree makes these trade-offs visible. Start with the company outcome. Connect it to the customer behavior that must change, the product lever expected to change that behavior, and the evidence required from the current initiative. If a team cannot draw a credible path through those layers, pause the funding discussion until it can. That is more useful than arguing about whether the item belongs near the top or middle of a feature list.
Your leadership context changes how you create this clarity. In a founder-led company, you often need to influence without becoming deferential: preserve the ambition in the founder’s vision while pressure-testing assumptions with customer evidence, data, and portfolio consequences. Under a hired CEO, the emphasis shifts toward explicit investment theses, capital allocation, and a tighter connection among product, financial, and go-to-market plans.
In either setting, ambition must be more precise than a mandate to become an AI company. Name the customer capability you want to own, the workflow in which it matters, and the durable advantage the company can build around it. Technology is an ingredient. Customer advantage is the strategic claim.
Turn AI feature requests into testable investment theses
A feature request arrives with a solution already embedded in it. An investment thesis keeps the solution open long enough to test whether the opportunity deserves capital. That distinction matters when models, interfaces, and implementation patterns are changing faster than an annual plan can absorb.
Rewrite each material AI proposal using this structure:
You have an AI capability that demos well, yet its growth story is still unclear. Some users try it once. The team debates model quality. The roadmap fills with features, while the link to activation, retention, or revenue remains an assumption.
You can fix that by managing AI growth as a measurable path from user intent to trusted value, repeated behavior, and a business outcome. That path tells you where growth is breaking, which experiment to run next, and whether a more capable model would solve the problem at all.
Build the growth thesis as a measurable chain
AI products invite feature-shaped goals: launch a copilot, add an agent, improve the prompt, or introduce recommendations. Those goals describe output. They do not tell you whose behavior should change or why the change matters to the business.
In my product strategy work at HighLevel, I use a simple test: if a roadmap item cannot name the user behavior it should change and the business lever that behavior affects, it is not yet a growth strategy. A North Star and its driver tree force that connection into the open.
Build your driver tree from right to left. Start with the business outcome, identify the customer behavior that can produce it, and then identify the AI-assisted moments that can change that behavior. This order prevents model capabilities from dictating the roadmap.
Name the segment. Choose a group with a shared job and context. New administrators setting up an account are more useful than all users because their intent, constraints, and success event can be observed.
Define the value moment. State what the user can do after the AI interaction that was difficult before it. An answer displayed is not a value moment. A configured workflow, resolved issue, completed analysis, or approved action can be.
Select the behavior change. Decide whether you need more users to reach first value, reach it sooner, repeat a valuable workflow, or adopt an additional capability.
Connect the behavior to one growth mechanism. Activation, retention, and expansion require different product decisions. Choose a primary mechanism for the bet instead of claiming that one feature will improve all three.
Add quality and trust guardrails. Relevance, correctness, abandonment, corrections, unauthorized actions, privacy exposure, and recoverability can invalidate an apparent growth win.
A practical AI growth equation is: eligible users multiplied by discovery, first successful use, repeat successful use, and downstream conversion. You do not need to treat the equation as a financial model. Use it to locate the weakest link. More traffic will not repair poor first-use success, and better answers will not create growth if eligible users never discover the capability.
Turn the thesis into a one-page decision document before adding projects to the roadmap. It should contain:
The target segment and the high-value job it is trying to complete.
The current friction, supported by behavioral evidence or customer discovery.
The proposed AI intervention and why AI is necessary for this step.
The primary behavioral outcome and its baseline.
The activation, retention, or expansion lever that outcome should affect.
The leading indicators that can move before the business outcome does.
The quality, reliability, and trust guardrails that must not deteriorate.
The assumptions that would cause you to stop, narrow, or redesign the bet.
Your outcome statement can follow this form: increase a named behavior for a named segment by improving a specific driver, without degrading named guardrails. Supply the target only after you have a baseline and know what change your measurement system can detect. A target chosen for presentation value is not a strategy.
A worked example: turn AI search into an activation path
Consider a SaaS administrator who searches for help while configuring a workflow. A search team could optimize result clicks and declare success. A growth team traces the job further: query submitted, useful guidance received, setup started, workflow activated, and the workflow used successfully.
If result clicks rise but completed setups do not, the team improved engagement with search rather than activation. If setup completion rises but repeat use does not, the next constraint may be workflow value, onboarding, or the quality of the initial configuration. The query-to-outcome path makes those distinctions visible.
This is why every AI growth bet needs an explicit endpoint. The endpoint is not the response. It is the valuable behavior the response enables.
Choose an intent wedge before choosing the AI experience
A broad assistant usually creates a broad measurement problem. It serves unrelated intents, carries different failure costs, and leaves the team unable to explain why adoption changed. Start with an intent wedge: a narrow set of related requests from one segment, encountered at a meaningful point in its journey.
A strong first wedge has several useful properties:
The job recurs. Repetition gives the product a chance to create a habit or reduce recurring friction.
The current path is observable. You can see where users search, abandon, ask for help, switch tools, or fail to complete the workflow.
Success is verifiable. The product can observe a completed action or downstream outcome instead of relying only on a positive reaction to the answer.
The job is close to value. Improving it can plausibly affect activation, retention, or expansion.
The failure is recoverable. Early versions should avoid irreversible or high-cost autonomy when a suggestion, preview, or confirmation can solve the same problem safely.
The scope is evaluable. The team can assemble representative intents and define what an acceptable response or action looks like.
Use continuous discovery and journey mapping to find that wedge. Review behavioral funnels and query logs, then speak with users who completed the job, abandoned it, and avoided the AI experience entirely. The last group matters because usage data cannot explain a discovery problem among people who never entered the funnel.
Capture each candidate in an opportunity card. Record the segment, trigger, intent in the user’s own language, current workaround, failure consequence, next valuable action, available evidence, trust constraints, and outcome metric. This keeps prioritization centered on customer work rather than the novelty of a model capability.
When comparing opportunities, do not collapse everything into one unexplained score. Look separately at the strength of the evidence, proximity to a growth outcome, frequency of the job, severity of the friction, ability to measure success, and cost of a wrong answer or action. A high-frequency request with no meaningful downstream behavior may be less valuable than a narrower request sitting directly before activation.
Match autonomy to the evidence you have
AI product teams often jump from static software to autonomous agents in one roadmap step. A safer growth path increases autonomy only when the preceding level has demonstrated reliable value.
Visibility. Capture and classify what users are trying to accomplish. This exposes unmet demand before you automate anything.
Retrieval and explanation. Return relevant, grounded information that helps the user make the decision. A retrieval-first approach is often the cleanest starting point because the evidence and failure points are easier to inspect.
Recommendation. Suggest a next action using the user’s context, while keeping the decision with the user.
Guided or agentic execution. Prepare or perform a multi-step workflow with appropriate permissions, confirmation, observability, and recovery.
Move up a level when the current experience has repeat use, its major failure classes are understood, and the next level removes a documented point of friction. Do not add agency merely because the model can call tools. An agent that takes the wrong action creates a more serious problem than a search result that fails to earn a click.
The decision rule is straightforward: use the least autonomous experience that can produce the target behavior. This makes learning cheaper, limits risk, and shows whether users want the job completed before you invest in completing it on their behalf.
Instrument the full path from interaction to revenue
You cannot manage AI growth from a usage count. Monthly users of an AI feature can rise because of novelty, forced exposure, or repeated failure. Instrument a closed loop that connects intent, system behavior, user response, task completion, and the relevant business outcome.
A useful event spine contains the following stages:
Eligibility and exposure: Was the right user able to discover the capability at the right moment?
Intent: What job was the user trying to complete, and how was that intent classified?
Response: Which result, recommendation, or planned action did the system produce?
User judgment: Did the user select, accept, edit, reject, retry, or abandon it?
Execution: Did the user or agent start and complete the intended workflow?
Value: Did the product observe the success event defined in the growth thesis?
Business outcome: Did the relevant account activate, retain, expand, or contribute to Net Recurring Revenue through the defined path?
Concrete event names make implementation reviews easier. Depending on the experience, you might use events such as ai_query_submitted, ai_answer_shown, ai_recommendation_accepted, ai_action_started, ai_action_completed, ai_answer_corrected, and ai_flow_abandoned. The exact naming convention matters less than preserving the sequence and using it consistently.
Attach the properties needed to diagnose changes: segment, intent class, entry point, answer type, retrieval or ranking version, model and prompt version, experiment assignment, content identifiers, action type, completion status, and failure class. Carry account and customer identifiers into downstream systems only under your approved privacy and data-governance rules.
Raw prompts and conversations can contain personal, confidential, or commercially sensitive information. Logging them by default can create exposure that outlives the experiment. Define redaction, retention, access control, and deletion rules before broad collection. If a diagnostic goal can be met with a classified intent or structured error code, do not retain the raw text merely because it may be useful later.
Organize the resulting metrics into five views:
Reach: eligible users, exposure, discovery, and first use.
Experience: acceptance, correction, retry, abandonment, and progression to the next step.
Task value: successful workflow completion and time to the defined value event.
Repeat value: return use for the same job and successful use across relevant workflows.
Business impact: activation, retention, expansion, and revenue outcomes for the target segment.
Sentiment can help you locate frustration, but it should not become the success metric. A polite response can still be wrong, and a frustrated user can still complete the task. Pair inferred sentiment with observable behavior such as correction, abandonment, repeated queries, completion, and downstream product use.
Revenue attribution needs similar discipline. Connect experiment exposure and product behavior to the CRM or revenue system, choose an attribution window that matches the natural decision cycle, and distinguish influenced revenue from causally demonstrated lift. Users who voluntarily adopt an AI capability may already be more engaged, so a dashboard correlation does not prove that AI caused their retention or expansion.
This distinction changes roadmap decisions. Behavioral analytics can reveal where the path is breaking. Controlled experiments are needed when you want to know whether fixing that point changes behavior or dollars.
Turn evaluation and experiments into a delivery system
AI growth execution needs two evidence gates. Offline evaluation asks whether the system performs the intended task well enough to expose safely. Online experimentation asks whether the experience changes customer behavior. Passing one gate does not imply that you will pass the other.
Gate releases with eval-driven development
Build the first evaluation set from real intents in the chosen wedge. Cover common requests, ambiguous requests, known failures, and cases where a wrong answer or action carries a higher cost. Preserve segment and intent labels so an average score cannot hide a severe failure in an important slice.
Write the rubric before tuning. Define what must be true for the response or action to pass: correct intent, relevant evidence, accurate guidance, appropriate next step, permitted action, and recoverability where needed.
Separate failure classes. Coverage, retrieval, generation, interaction design, tool execution, permissions, and policy failures need different fixes.
Version the system. Record the model, prompt, retrieval configuration, content version, tools, and policy configuration associated with each result.
Review performance by slice. Inspect high-value intents and high-consequence failures instead of relying only on the aggregate.
Keep human review where judgment is material. Automated scoring can accelerate evaluation, but uncertain or consequential cases still need an accountable review path.
Promote real failures into the eval set. Production corrections and abandoned workflows should make future regressions easier to catch.
Do not treat every low score as a prompt problem. If the required information is absent, fix content or data coverage. If the right material exists but is not retrieved, fix retrieval or ranking. If the answer is accurate but users cannot act on it, fix interaction design or the handoff into the workflow. Prompt iteration cannot compensate for every layer of the system.
Use online experiments to answer growth questions
Once the experience passes its release gate, write an experiment card that another product leader could audit without attending the planning meeting.
The target segment and eligibility rule.
The behavior you expect to change and the mechanism behind that change.
The control and variant, including model, prompt, ranking, content, or interaction differences.
One primary behavioral outcome tied to the growth thesis.
Quality, reliability, cost, privacy, and business guardrails relevant to the change.
The randomization unit, especially when users within the same account can affect one another.
The natural usage or buying cycle the test must observe.
The decision rule for shipping, iterating, narrowing, or stopping.
Good early tests isolate a decision. Compare retrieval or ranking approaches when users cannot find the right information. Compare concise and detailed answer formats when comprehension or action is the constraint. Test prompt variants when the failure is genuinely in instruction following or response construction. Test a guided workflow against a static answer when users understand the answer but fail at the next step.
A click is an acceptable primary metric only when the click itself represents value. Otherwise, measure the completed behavior downstream. A compelling answer that produces no useful action is engagement without growth.
Run the first 90 days around evidence, not launch theater
A 30-60-90 operating sequence gives the team enough structure to create momentum while preserving room to learn.
Days 1-30: establish the truth. Select the segment and intent wedge. Baseline the driver tree. Map the current journey. Audit events and data access. Build the initial evaluation set. Define privacy and permission constraints. Write the first growth thesis and identify the assumptions most likely to break it.
Days 31-60: ship the smallest complete path. Release a thin experience behind a feature flag. Instrument the full event spine. Run offline evaluations and the first controlled experiment. Review failed intents and abandoned workflows every week. Fix the largest diagnosable constraint rather than adding adjacent features.
Days 61-90: prove, prune, and scale. Aim to land two or three measurable wins, remove low-signal bets, and decide whether the wedge deserves more distribution, deeper personalization, or greater autonomy. Standardize the operating cadence only after the team has learned which reviews lead to decisions.
The product trio should co-own problem framing and solution shaping. Product owns the growth thesis and trade-offs. Design owns comprehension, control, feedback, and recovery in the interaction. Engineering owns system behavior, instrumentation, reliability, and safe delivery. Data science should help design evaluations, experiments, and attribution. Customer-facing teams should validate whether the job and value proposition match the language customers actually use.
Every two-week sprint: ship a testable improvement, review the evidence, and update the decision record.
Monthly: review the driver tree, experiment portfolio, business impact, costs, and cross-functional blockers.
Quarterly: reset outcomes, stop bets that have lost their evidence, and fund the next constraint in the growth path.
Feature flags, CI/CD, and observability are growth infrastructure because they reduce the cost and risk of learning. They let you separate code deployment from customer exposure, compare variants, detect regressions, and reverse a problematic release. Privacy-by-design, data governance, and observability should be release requirements rather than work deferred until scale.
Watch for five failure modes
The roadmap is organized by AI features. Reorganize it around segments, intents, and outcomes so multiple solution types can compete for the same problem.
One quality score hides the system. Break performance into coverage, retrieval, generation, interaction, execution, and policy slices so the owner of the next fix is clear.
The team optimizes prompts while the funnel is broken elsewhere. Locate the failing step before choosing the technical intervention.
Autonomy arrives before trust. Start with visibility, retrieval, or recommendations, then increase agency when reliable task completion and recovery have been demonstrated.
AI usage becomes a vanity metric. Keep the primary outcome downstream of the interaction and tie it to activation, retention, or expansion.
Key takeaways
An AI growth strategy must connect a defined segment and intent to a valuable behavior and one primary business lever.
Start with a narrow intent wedge whose success is observable, repeatable, and close to activation, retention, or expansion.
Use the least autonomous experience that solves the documented friction, then earn the right to add agency.
Instrument eligibility, intent, response, user judgment, execution, value, and business outcome as one path.
Use offline evaluations to manage quality and controlled experiments to establish behavioral or revenue impact.
Treat feature flags, observability, privacy, and data governance as part of the growth system.
Review failures weekly, ship testable improvements in two-week sprints, and prune bets that do not change customer behavior.
Start with one segment, one recurring intent, and one outcome. Trace the current path event by event, identify its weakest link, and write the smallest experiment that can test your explanation. That is enough to turn AI growth from a feature campaign into a learning system.
You don’t have a chatbot problem. You have an operating-model decision: which customer outcomes may an AI agent own, when must a person take over, and who is accountable when the system gets it wrong?
Get those decisions right and one frontline system can qualify buyers, resolve routine requests, and give specialists better conversations. Get them wrong and you will automate confusion: weak meetings enter the pipeline, unresolved tickets look like successful deflection, and customers repeat themselves after every handoff.
Give the agent a job with an observable finish line
The phrase ‘handle customer conversations’ is not a usable product requirement. It describes a channel, not a job. An agent needs a bounded responsibility, the information and actions required to perform it, and an event that tells you whether the work was completed correctly.
Write a job card before designing prompts or choosing a model. It should specify:
Customer job: the need the agent is expected to address, such as qualifying an inbound buyer or resolving a known setup question.
Eligible intents: the requests it may own and the requests it must immediately transfer.
Allowed actions: retrieve an approved answer, update a permitted field, schedule a meeting, initiate a workflow, or route to a named queue.
Completion event: a correctly qualified meeting, a documented disqualification, a verified resolution, or an accepted handoff.
Failure event: an unsupported answer, an incorrect action, a dropped conversation, a lost handoff, or an outcome that violates policy.
Accountable owner: one person who owns performance across the model, knowledge, workflow, integrations, and operating policy.
The finish line matters because apparent activity is easy to mistake for value. A calendar booking is not a sales success if the buyer does not meet the qualification rules. A conversation that ends without a human transfer is not a support resolution if the customer simply gives up.
Correct disqualification and justified escalation should count as valid outcomes. The objective is not to force every conversation into automation. It is to move every eligible conversation to the right outcome with the least avoidable effort.
Start by running the agent beside an existing human path. Parallel operation gives you a visible fallback, preserves service while the system is learning, and makes outcome quality easier to compare. Broaden ownership only after the agent performs reliably on the job it already has.
Route by customer intent, not your organization chart
Customers do not arrive thinking in sales and support queues. A question about a feature may come from an anonymous buyer, a trial user, an existing customer considering an upgrade, or a customer blocked from completing a task. The words can be identical while the correct response, permitted data, and next action are completely different.
This is why CRM integration and conversation context are core parts of the product rather than optional enrichment. The agent needs enough verified context to determine which job it is performing. It should not expose account-specific information, alter a record, or initiate a commercial workflow until identity and permissions are clear.
A practical conversation policy follows this sequence:
Establish the relationship. Determine whether the person is an anonymous visitor, prospect, trial user, customer, or authorized account contact.
Classify the job. Identify the outcome the customer wants, not merely the keywords in the message.
Retrieve permitted context. Load only the account, conversation, product, and lifecycle information needed for that job.
Ask for missing facts. Collect the minimum qualification or troubleshooting details required to make the next decision.
Complete or transfer. Take an approved action when confidence, policy, and permissions allow it. Otherwise, move the conversation to the correct person.
Record the disposition. Store the recognized intent, facts collected, actions attempted, outcome, and reason for any handoff.
The handoff is part of the agent experience. It should contain the person’s identity and account state, the stated goal, relevant facts, knowledge consulted, actions already attempted, results, and the recommended next step. A transcript dump is not enough. It makes the human reconstruct the problem and usually makes the customer repeat it.
Define transfer triggers before launch. Useful triggers include missing or contradictory approved knowledge, insufficient identity, an action outside the agent’s permissions, repeated failed attempts, an explicit request for a person, a commercial exception, or a conversation where relationship judgment matters more than speed.
Keep the commercial objective visible without letting it corrupt support. Resolve the customer’s blocking issue before introducing an upgrade unless the customer explicitly asks about buying. Likewise, a low-intent visitor does not need to be forced into a meeting. The agent can direct that visitor to useful self-service material and preserve context for a later conversation.
Measure sales creation and support resolution separately
A single automation rate hides the decisions you need to make. Sales and support share an interface, but they create different outcomes. Give each motion its own scorecard and connect the two through shared measures for handoff quality, trust, and customer effort.
Motion
Primary outcome
Diagnostic signals
Downstream proof
Sales
A correctly qualified meeting, documented disqualification, or appropriate nurture path
Qualified, disqualified, dropped, routed, and handoff-accepted conversations
Opportunity creation, attributable pipeline, and revenue
Support
A correct routine resolution or a context-rich transfer
Intent, topic, repeated attempt, escalation reason, time to resolution, and where customers abandon the flow
Successful resolution, repeat contact, sentiment, and CSAT
Shared experience
A trustworthy completion with no unnecessary restart
Unsupported answers, incorrect actions, lost context, policy violations, and customer-requested transfers
Outcome quality by intent, channel, customer type, and agent version
Give agent-originated sales conversations a distinct origin field in the CRM. Retain the conversation identifier, final disposition, and qualification facts, then follow each cohort through opportunity and close. If agent results disappear inside total inbound performance, you cannot tell whether the system created incremental pipeline, shifted work from another channel, or merely booked more low-quality meetings. Meetings, pipeline, and revenue need explicit attribution.
Support needs the same discipline. Do not treat a lack of escalation as proof of resolution. Examine whether the requested task was completed, whether the answer came from approved knowledge, whether the customer returned with the same issue, and whether the handoff arrived in a usable state. Topic and intent analytics should reveal where demand is rising, where customers get stuck, and which workflows actually shorten resolution.
Use a high-performing human on the same channel as the operational benchmark. That comparison is more useful than a generic automation target because it preserves the standards customers already experience. It is a target for your system, not a claim that every agent meets it. Compare like with like: the same eligible intents, customer mix, qualification policy, and access to knowledge.
Before expanding eligibility, use eval-driven development and controlled experiments. Keep the eligibility rules stable during a comparison, segment results by intent, and change one major layer at a time. If the prompt, knowledge base, routing policy, and action permissions all change together, a better aggregate score will not tell you what improved or which new failure mode you introduced.
Put one owner over knowledge, guardrails, and iteration
A customer-facing agent is a production system, not a launch asset. Product knowledge changes. Qualification rules change. Integrations fail. Customers find language the original tests did not cover. Performance will drift unless someone owns the whole loop.
That owner needs program-level responsibility. In sales, the role may be an AI SDR program lead. In support, it may sit with an AI operations or product leader. The title matters less than the decision rights: the owner must be able to change eligibility, knowledge, prompts, workflows, routing, evaluation criteria, and rollout scope.
The operating loop should be explicit:
Review outcomes by intent. Inspect successful completions as well as failures; a passing aggregate can conceal one dangerous category.
Classify the failure. Separate knowledge gaps, intent errors, policy mistakes, tool failures, permission problems, poor handoffs, and correct answers delivered in an unhelpful way.
Fix the smallest upstream cause. Update the audited knowledge when the fact is missing, the workflow when the action is wrong, the policy when the boundary is unclear, or the conversation design when the interaction creates friction.
Replay representative evaluations. Test the changed component against known successful cases, known failures, ambiguous requests, and transfer scenarios.
Release to limited eligibility. Preserve the human fallback and monitor the affected intent before increasing traffic or adding actions.
Record the change. Version the knowledge, prompt, policy, workflow, and evaluation set so a metric movement can be traced to a real product change.
Ground answers in a retrieval-first pipeline backed by audited knowledge. The generative layer should explain and adapt approved information; it should not invent product behavior, policy, eligibility, or commercial commitments. When the agent can take action, give each action its own identity checks, required fields, permission boundary, confirmation behavior, and failure path.
CRM context improves relevance, but it also increases the cost of a permission mistake. Apply privacy-by-design at the workflow level: retrieve only what the current job needs, verify identity before exposing account details, restrict actions by role, and preserve an audit trail of what the agent saw and did. A fluent response does not compensate for unauthorized access.
The rollout is incomplete until human work changes. Salespeople should gain time for higher-conversion conversations, multi-stakeholder account development, guided trials, and situations where judgment affects the buying process. Support specialists should receive the nuanced, emotionally sensitive, or genuinely novel problems with the context already assembled.
Is the job bounded? The eligible intents, required context, allowed actions, and prohibited actions are written down.
Is success observable? Sales quality reaches pipeline and revenue; support quality reaches real resolution rather than mere non-escalation.
Is the transfer designed? Triggers are explicit, the receiving queue is known, and the human receives a structured handoff instead of a raw transcript.
Is attribution separate? Agent-originated conversations, dispositions, downstream outcomes, and versions can be analyzed without disappearing into channel totals.
Is trust engineered? Approved knowledge, evaluations, identity controls, action permissions, privacy rules, and audit records exist before broad access does.
Has human capacity been reassigned? Sales and support specialists have named higher-value work to absorb the time the agent releases.
If any answer is no, do not widen the agent’s scope yet. Tighten the job, instrumentation, or boundary that is missing. More traffic will amplify an unclear operating model faster than it will improve one.
Your next move is small but concrete: choose one frequent intent with audited knowledge and an unambiguous finish line. Write its job card, run it beside the existing human path, assign one accountable owner, and track the outcome through the system that ultimately matters. Expand only when the agent is reliably completing that job and the human team is using the released capacity deliberately.
You are deciding whether Amplitude Agents deserve a place in your product operating system. A fluent answer or polished insight is easy to admire. The harder question is whether the agent helps someone make a better decision, complete a valuable task, or change user behavior.
That distinction determines how you should instrument, evaluate, and roll out the experience. Treat Amplitude as the measurement spine connecting agent activity to funnels, cohorts, experiments, retention, and product outcomes. Otherwise, you will know that the agent was used without knowing whether it was useful.
Pick a workflow with an observable finish line
Do not begin with a broad ambition such as helping everyone understand the data. It cannot be measured cleanly, and it gives the agent too much room to produce plausible output without resolving a real job.
Write a workflow contract before configuring dashboards or prompts:
User: Name the role doing the work, such as a product manager investigating onboarding friction.
Trigger: Describe the event that makes the job necessary, such as a drop in activation or an unexpected cohort difference.
Bounded job: State exactly what the agent should help accomplish.
Required evidence: Identify the events, funnels, segments, or cohorts that should support the output.
Done state: Define the observable action that marks useful completion.
Fallback: Decide what happens when the inputs are missing, the evidence conflicts, or the agent cannot complete the task reliably.
For an onboarding investigation, the contract might ask the agent to help identify where a defined cohort leaves the activation journey and produce evidence-backed hypotheses for the product manager to review. The task is not complete when text appears. It is complete when the user reviews the relevant evidence and records a decision, launches a follow-up analysis, or creates an experiment.
Use a simple outcome ladder to keep the team honest: eligible users see the experience, some start it, some reach the workflow’s done state, some act on the result, and the intended product outcome changes. Each level answers a different question. Collapsing them into an agent usage metric hides the point at which value disappears.
Instrument the agent journey, not just the final answer
Your event design should let you reconstruct the journey from opportunity to outcome. The names below are examples, not an official Amplitude schema. Adapt them to your existing naming convention and governance rules.
Journey stage
Question it answers
Suggested event
Eligible
Who could reasonably use this workflow?
agent_workflow_eligible
Exposed
Who actually saw an entry point?
agent_entry_viewed
Started
Who chose to begin?
agent_run_started
Evidence reviewed
Who engaged with the information needed to judge the output?
agent_evidence_viewed
Completed
Who reached the workflow-specific done state?
agent_task_completed
Actioned
Who used the output in a downstream decision or action?
agent_output_applied
Handed off
Where did the experience require a deterministic flow or human review?
agent_handoff_triggered
Returned
Who came back when the job occurred again?
agent_run_started, segmented by prior successful completion
Add properties that explain why behavior differs: workflow identifier, product surface, user role, account cohort, journey stage, agent version, prompt or instruction version, completion reason, handoff reason, and error class. Version properties are essential. Without them, a release can change output quality while the dashboard incorrectly treats the experience as one stable product.
If prompts may contain customer or company data, do not log the raw text by default. Prefer derived classifications, structured outcome fields, or properly redacted samples governed by your retention and access policies. Product analytics should increase observability without creating an unnecessary copy of sensitive input.
Build each metric with an explicit denominator:
Discovery rate: exposed eligible users divided by eligible users.
Start rate: users who start divided by users exposed to the entry point.
Completion rate: users reaching the workflow-specific done state divided by users who start.
Action rate: users taking the defined downstream action divided by users who complete.
Retained use: previously successful users who return when the job recurs divided by previously successful users who had another opportunity.
The eligibility and opportunity conditions matter as much as the numerator. A user cannot retain to a workflow that has not recurred, and someone who never saw the entry point should not be treated as a failed starter.
In Amplitude, separate the views rather than forcing everything into one chart. Use an exposure funnel for discoverability, a workflow funnel for completion, cohorts for segment differences, retention analysis for repeat behavior, and a guardrail view for errors, retries, and handoffs. Use Agent Analytics for the execution signals available from the agent, then connect those signals to the behavioral events that represent product value.
Keep output quality and product impact on separate scorecards
Behavioral analytics cannot tell you whether an answer was correct. An evaluation set cannot tell you whether customers changed their behavior. You need both views because they fail in different ways.
Before widening access, create an evaluation set drawn from the workflow contract. Include ordinary cases, incomplete inputs, ambiguous requests, conflicting evidence, and cases that should trigger a handoff. Grade the output against criteria that can be reviewed consistently:
Correctness: Does the conclusion match the available evidence?
Grounding: Can the user see which events, funnels, cohorts, or other inputs support it?
Task adherence: Did the agent solve the bounded job rather than produce a generic analysis?
Uncertainty handling: Does it distinguish supported conclusions from hypotheses?
Handoff behavior: Does it stop or redirect appropriately when required evidence is unavailable?
Actionability: Can the intended user make the next decision without reconstructing the analysis?
Record pass or fail for non-negotiable criteria such as unsupported conclusions and failed handoffs. Keep graded usefulness criteria separate. A high average score should not conceal a smaller set of serious failures.
Run the same evaluation set when you change instructions, tools, model configuration, retrieval behavior, or the data made available to the agent. This is the practical value of eval-driven development: a fast release becomes a controlled product change rather than an untraceable shift in behavior.
Your online scorecard should then contain distinct layers:
Primary outcome: the workflow-specific completion or downstream action that represents value.
Adoption diagnostics: eligibility, exposure, start rate, and first successful completion.
Quality diagnostics: evaluation results, user corrections, retries, and unsupported-output flags.
Operational guardrails: errors, latency appropriate to the workflow, abandonment, and handoffs.
Product impact: the activation, feature adoption, retention, or other behavioral outcome the workflow is intended to influence.
Choose one primary outcome before launch. The other measures explain why it moved or protect against a misleading win. If every metric is primary, the team can always find one that improved after the fact.
User ratings can help diagnose tone, relevance, or missing context, but they are not a substitute for observed outcomes. A response can feel impressive and still produce no action. It can also look concise while helping an expert complete the job quickly. Pair stated feedback with completion, downstream action, and return behavior.
Run an experiment that can survive executive scrutiny
Do not compare enthusiastic agent adopters with everyone who ignored it. Those groups selected themselves, so their product outcomes may have differed before the agent appeared. Establish a baseline and create a controlled comparison wherever the workflow and traffic permit it.
Write the hypothesis in behavioral terms. Name the user, workflow, expected action, and product outcome.
Measure the current workflow before introducing the agent. Capture completion, abandonment, downstream action, and relevant guardrails.
Define eligibility before assignment so the comparison includes people with the same underlying job.
Choose the assignment unit that matches how the workflow spreads. Use an account-level unit when teammates share agent output; use a user-level unit only when experiences are genuinely independent.
Expose the treatment through a feature flag or controlled rollout, while keeping the existing path available as the comparison and fallback.
Evaluate the primary outcome and guardrails together. Do not call a faster workflow successful if output quality, error handling, or downstream behavior deteriorates.
Inspect cohorts to understand a credible result, not to search endlessly for a segment that happens to look positive.
The metric pattern often tells you where to investigate next:
High exposure with low starts can indicate weak positioning, poor timing, or an irrelevant eligible population.
Healthy starts with low completion can indicate that the promise is attractive but the workflow, inputs, or output quality is failing.
High completion with low downstream action can indicate that your done state is too shallow or the output is not trusted enough to use.
Strong agent engagement without movement in the product outcome can indicate a locally pleasant experience that does not change the broader journey.
Strong first use with weak return behavior can indicate novelty, unreliable value, or a job that simply occurs infrequently. Check opportunity before interpreting it as churn.
Good aggregate results with concentrated handoffs in one cohort can indicate missing context, permissions, or data for that segment.
Guardrails should be operational, not aspirational. Validate required inputs. Make the agent’s task and evidence boundaries clear. Route the user to a deterministic flow or human review when observable conditions show that the task cannot be completed. Missing data, failed tool calls, validation failures, and unsupported claims are stronger handoff triggers than an agent merely describing itself as confident.
Scale only when value repeats under real conditions
A spike in usage after launch mainly proves that people noticed something new. Scale when the complete chain repeats: eligible users discover the workflow, finish it, act on the result, and return when the same job appears again.
Segment that chain by role, account cohort, use case, journey, and agent version. A workflow that helps an experienced product analyst may confuse a first-time manager. An onboarding investigation may need different evidence and handoffs from a retention investigation. Aggregate adoption can hide both realities.
Expand the rollout when the primary outcome improves, evaluation quality remains stable across relevant cohorts, guardrail failures stay controlled, and repeat use matches the natural frequency of the job. Redesign when successful users cannot find the entry point, retries cluster around the same step, completed outputs rarely lead to action, or results depend on one unusually capable cohort.
Pause expansion when the agent does not improve the existing workflow, important outputs cannot be audited back to evidence, or failures cannot be routed safely. More exposure only creates more ambiguous data when the workflow contract itself is weak.
Key takeaways
Define one bounded workflow and an observable done state before measuring adoption.
Connect agent execution signals to exposure, completion, downstream action, and product outcomes in Amplitude.
Use evaluation sets for output quality and behavioral analytics for real-world impact; neither replaces the other.
Compare the agent with the existing workflow among equally eligible users.
Treat retries, errors, unsupported outputs, and handoffs as product signals, not merely engineering logs.
Scale repeatable value across cohorts and versions, not a launch-driven usage spike.
Your next move should fit on one page: the workflow contract, event map, evaluation criteria, experiment metric, and fallback path. If those elements are clear, Amplitude can show where the agent creates value and where it merely creates activity. If they are not clear, narrow the workflow before you widen the rollout.
When uncertainty spikes, I notice many organizations snap back to "Command and control." It feels fast, safe, and decisive—especially when the stakes are high. But in product management leadership, speed without shared context is often an illusion, and control without trust rarely scales. I’ve learned that what looks like strength from the top can quietly create bottlenecks, missed signals, and disengaged teams.
Why do smart companies revert in tough times? Familiarity. Centralizing decisions can reduce short-term cognitive load and signal clarity. Yet the cost shows up quickly: leaders become single-threaded on context they cannot possibly hold, and teams spend cycles asking for permission rather than creating value. The result is slower learning and weaker product strategy just when continuous discovery and iteration matter most.
Here’s the hard truth: no single leader can hold all the context required to make every decision in a modern, cross-functional environment. The hidden complexity of customer segments, technical debt, data signals, and go-to-market constraints outstrips any one person’s bandwidth. That’s why empowered product teams, staffed with domain experts, outperform command centers—provided they’re aligned on outcomes and guardrails.
I like the burning house analogy: in a true emergency, crisp direction helps—"take the stairs, not the elevator"—because the problem is clear, the time horizon is short, and the action is obvious. But most product work is not a single burning house; it’s a city with evolving fire codes, shifting weather, and neighborhoods that look different block to block. In that environment, distributed action scales better than centralized control.
Strong leadership is not the same as command-and-control. In practice, it means setting a compelling direction, defining guardrails, and running tight feedback loops. I aim for what I call the "Flotilla of kayaks": we’re all headed to the same lighthouse, but each kayak navigates its own currents based on local information. That’s aligned autonomy—fast, resilient, and deeply accountable.
People often ask why some command-and-control companies still succeed. My view: beneath the surface, there’s usually more trust and unofficial autonomy than their org charts suggest. Teams earn freedom by shipping reliably, sharing decision rationales, and showing outcomes. Leaders tolerate—and even quietly endorse—those pockets of autonomy because they see the results.
It’s a spectrum, not a binary. I flex my style based on risk, reversibility, and time horizon—what I’d call spectrum thinking. Early in a bet, or when risks are existential, I raise the altitude and tighten the cadence. As confidence builds, I widen autonomy and shift the team to outcomes over outputs. Beware "Founder mode" when it drifts from vision-setting into day-to-day decision vetoes; it’s intoxicating early and suffocating at scale.
On decision-making, I prefer a simple principle: let the person with the most relevant expertise decide, while incorporating the right input. That’s "Consultative decision-making" in practice. In some regions, you’ll hear it called "Konsultativer Einzelentscheid." The point is to seek counsel without defaulting to consensus that bogs down speed. One person owns the call, and everyone commits to the decision once it’s made.
Practically, here’s what works for my teams: we clarify decision rights up front, draft pre-reads with clear options and risks, involve the smallest set of stakeholders required, and document the decision and expected signals ahead of time. Product trios keep discovery tight with design and engineering, while stakeholder management focuses on context, not sign-offs. We track outcomes vs output OKRs and hold regular decision reviews so we can reverse or double down fast.
My key takeaways are consistent: "Command and control" can feel efficient, but it doesn’t scale in complex environments. No leader can hold all the context. Strong leadership is about direction, guardrails, and feedback loops—not control. High-performing teams balance autonomy with alignment. Decision-making should sit with the person closest to the problem, supported by the right input and transparent reasoning. Trust is built and earned over time—and it changes how teams operate.
Reflection prompts I use with my leads: Where does your team sit on the command-and-control ↔ autonomy spectrum? Are the highest-context people truly making the decisions? What would it take to increase trust and autonomy—better instrumentation, clearer guardrails, or tighter cadences? Which calls require consensus, and which deserve a decisive, single-threaded owner?
If you’re wrestling with speed, alignment, and autonomy in your organization, start small: pilot "Consultative decision-making" on one consequential decision, set explicit guardrails, and measure the outcome. You may be surprised how quickly aligned autonomy compounds into better product discovery, sharper product strategy, and stronger execution.
In the age of AI, I’ve come to believe we’re all builders—yet not all building is the same. There is a very meaningful difference between building to learn (known as product discovery) versus building to earn (known as product delivery). When we confuse the two, we waste precious time, budget, and team energy on output over outcomes. My goal in this FAQ-style reflection is to clarify when and how to choose each mode so we can make smarter, faster, more confident product decisions.
Why does this distinction matter so much right now? Because as the cost of product delivery continues to drop, the scarce resource shifts from shipping capacity to clarity of problem, solution, and value. Cloud infrastructure, CI/CD, feature flags, and even gen AI code assistance have made it cheaper to launch. That’s great—but if we don’t learn the right things before we scale, we’ll efficiently deliver the wrong product. Discovery is how we de-risk that.
What do I mean by build to learn? I use discovery to quickly validate problems, test value, and shape solutions before committing delivery teams to scale. In practice, that means continuous discovery with customer interviews, rapid prototyping, and lightweight experiments that put us in front of real users fast. I rely on product trios and empowered product teams to co-own outcomes, not just output, and I anchor decisions with outcomes vs output OKRs so we stay focused on measurable impact.
How do I structure discovery sprints? I start with an opportunity solution tree to map customer pain points and candidate solutions, then select the smallest test that can invalidate a risky assumption. When signals are ambiguous, I refine the questions and instrument better learning loops rather than pushing harder on delivery. For experiments, I keep a bias to speed: clickable prototypes, concierge tests, or gen ai for product prototyping often reveal more in days than a coded MVP does in weeks. When experiments go live, I use a clear minimum detectable effect (MDE) and resist reading noise as signal.
Where does AI change the calculus? LLMs for product managers are turbocharging discovery by accelerating research synthesis, persona drafts, and early concept validation. I pair that with eval-driven development to set crisp acceptance criteria for AI behaviors before any production integration. Prompt engineering and conversation design are part of the toolkit, but the same rule applies: prototype to learn, not to impress. AI can make bad ideas cheaper to build—so disciplined discovery matters more than ever.
So when do I switch to build to earn? Once I have evidence of value and feasibility, I shift into product delivery to scale with quality, security, and reliability. This is where I bring in product roadmapping and sprint planning, DORA metrics to monitor deployment frequency and lead time, and strong SRE and observability practices to safeguard the user experience. The handoff isn’t a wall; discovery continues inside delivery to refine scope, reduce risk, and maintain momentum.
What pitfalls do I watch for? The biggest is treating delivery as discovery—shipping features to “see what happens” without a clear learning thesis. Another is tech-first decisions driven by technology FOMO instead of product strategy and customer value. I also see teams set output-based commitments that crowd out learning; outcomes vs output OKRs keep us honest. And when considering build vs buy, I evaluate whether the capability differentiates us; if not, I’ll buy to preserve discovery capacity on what truly matters.
My operating conviction is simple: invest early and deliberately in build to learn so build to earn becomes high-confidence, high-velocity, and high-impact. In practical terms, that means smaller bets, faster feedback, clearer outcomes, and tighter collaboration across product, design, and engineering. If we get discovery right, delivery feels inevitable—and customers feel understood.