Can an AI agent actually run a credible content audit end to end? I put that to the test. In my role leading product at a high-growth SaaS and as a hands-on content strategist, I’m constantly balancing depth with reach. During a recent office-hours discussion, someone asked me to zoom out and explain when to use Claude Code. That prompt inspired me to launch a running series—Conversations with Claude—showing exactly how I apply it to real product management and SEO problems.
I’m a heavy user and share what works for me. I receive no compensation from Anthropic for this series; if that ever changes, I’ll disclose it. With that out of the way, let’s dive into how I had Claude conduct a full content audit—and why the results exceeded my expectations.
For the first installment, I chose a fairly complex use case: a comprehensive content audit of my site. I expected this to be a slog. Instead, it was refreshingly fast and rigorous once I set Claude up with the right scaffolding.
I kicked off with a simple directive: start by asking clarifying questions, proceed step by step, and capture notes in a shared task file. I also provided deep context—specifically, the CDH Book (15 chapters + intro) and my entire blog archive in markdown—so the model could reason with my actual corpus rather than guessing from sparse prompts.
Claude began with smart clarifying questions that framed the analysis well. Scope of keywords: Should it focus strictly on concepts unique to or heavily associated with my work like "opportunity solution tree" and "continuous discovery," or also include broader product management terms such as "product outcomes," "assumption testing," and "customer interviewing"? Keyword geography: Start with US-only or include UK/global? Blog coverage assessment: What counts as "well covered"—dedicated deep dives or credible coverage within broader posts? Output format: Add findings to the task file or create a separate deliverable?

I replied: 1. both 2. us only is a good place to start 3. evaluate this based on how well we rank for the keyword, if we rank reasonably well, you might suggest content improvements to rank better, if we don't rank at all, then you might suggest a whole new article 4. add to the task file
From there, Claude read the CDH Book, extracted roughly 100 keywords, ran them through Keywords Everywhere in two batches of 50 to capture search volume, and pulled current domain rankings and traffic metrics. Within minutes, I had a high-signal view of what’s working, where we’re invisible, and how to prioritize fixes.
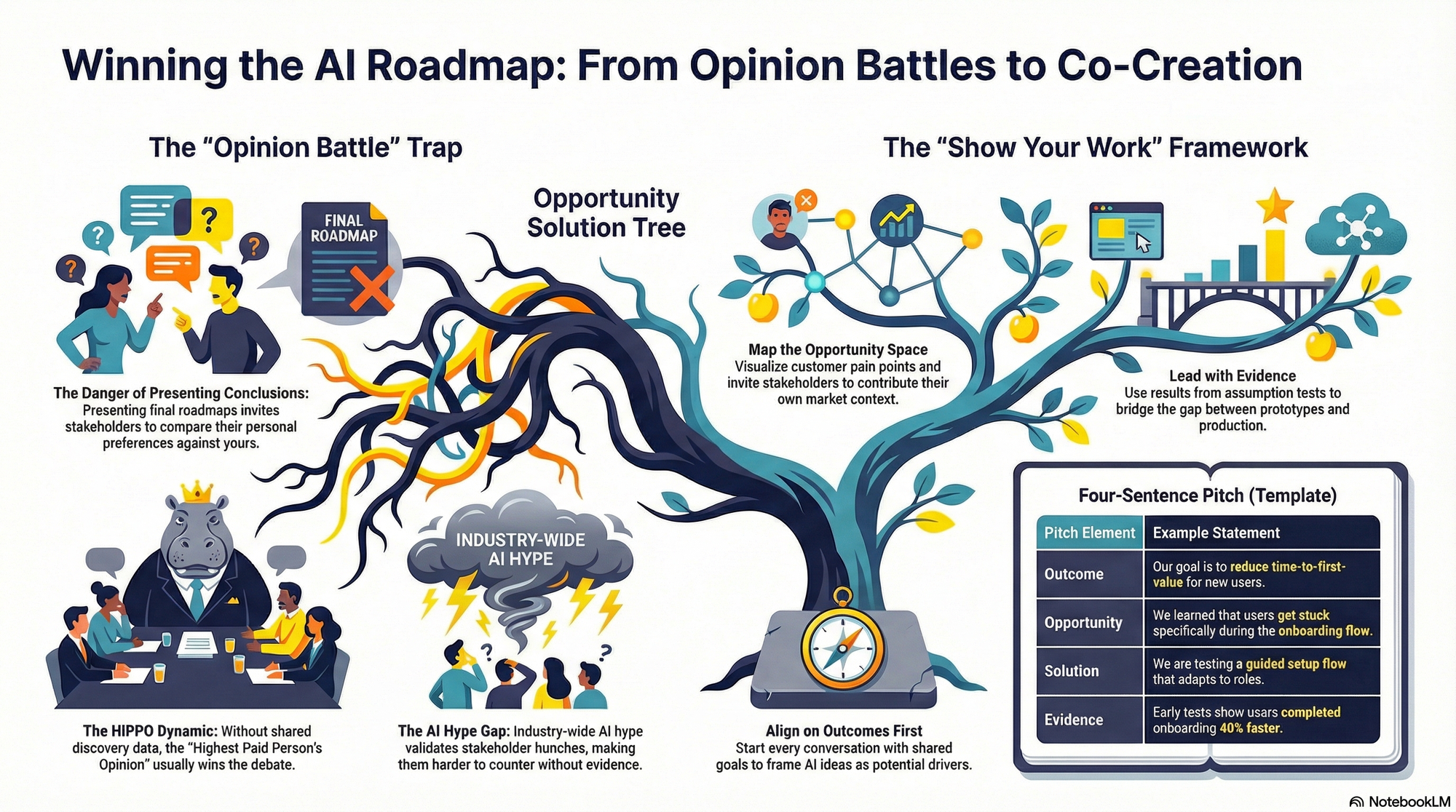
The good news came first: we own our branded terms—#1 for "product discovery," "opportunity solution tree," "continuous discovery," and "product trio." That brand equity is doing real work for us.
The biggest gaps were in broad topics the CDH Book covers but where there’s no targeted content. "Outcomes vs outputs" (1,300/mo) — Arguably THE central thesis of CDH, and no ranking. This is the single biggest gap. "Product roadmap" (4,400/mo) — I have a strong anti-roadmap POV but no content targeting this. "Product strategy" (1,900/mo) — Ch 7 argues strategy = opportunity selection. Strong differentiator, no ranking. "Story mapping" (5,400/mo) — I use story maps uniquely (for surfacing assumptions). Huge volume. "Stakeholder management" (2,900/mo) — Ch 13 is entirely about this. No ranking. "Pre-mortem" (4,400/mo) — I cover this as a product discovery technique. No ranking.

The trojan horse opportunity: High-volume generic terms like story mapping, pre-mortem, and usability testing could bring in readers who don't know about CDH yet. Write about these broadly-searched topics with my specific product-discovery angle.
In just a few minutes, Claude generated an analysis of what keywords we ranked for and at what position, a ranked set of high-, medium-, and lower-volume (but strategic) keywords where we didn’t rank yet had relevant content, concrete net-new topics to close the gaps, and a list of existing articles to update to lift their SERP positions. It worked far better than I expected.
Here’s how I set it up so the model could deliver: I didn’t simply ask Claude.ai to "audit my site" and hope for the best. I supplied rich, relevant context (my book and all blog posts as markdown) so it could anchor on my language, frameworks, and mental models. I paired that with live data via APIs like Keywords Everywhere to ground recommendations in actual search volume and competitive rankings. With the right inputs, Claude Code behaved like a capable research analyst and an SEO strategist—able to reason, prioritize, and suggest high-leverage actions.
Next, I went deeper and used the findings to draft a long-form article that addresses the biggest gap—"Outcomes vs outputs"—and ties it directly to product roadmapping and sprint planning. I wove in continuous discovery practices, opportunity solution tree techniques, and product trios collaboration to make it actionable for empowered product teams. I’ll share the end-to-end workflow—including files, prompts, and the editorial QA checklist—in a follow-up.
If you’re new to Claude Code and want a practical starting point, replicate the setup above: assemble your canonical sources in markdown, define a clear evaluation rubric, and ground keyword research with reliable volume data. If you want my exact task file, clarifying-question template, and step-by-step audit rubric, tell me which content gap you’d prioritize first and why—I’ll tailor the walkthrough to the highest-interest topic.
Inspired by this post on Product Talk.