Over the last year, I’ve had the same conversation with a lot of support leaders.
They’ve deployed AI and are seeing initial efficiency gains, but want to push beyond these early results and achieve meaningful transformation.
When AI is first introduced, the gains show up quickly. Teams resolve higher volumes of queries, free up capacity, and deliver faster responses. But the real opportunity for impact extends well beyond those initial wins. As AI becomes more deeply integrated into support operations, taking on harder, more complex work, those results compound, new ways to create and measure value open up, and the economics of support change entirely. That shift is where I spend most of my time with leaders—turning early efficiency into durable business value.
This sits at the heart of “The 2026 Customer Service Transformation Report.” In this reflection, I explore how deeper integration compounds impact and why that makes business value easier to articulate across the organization—especially to finance and product peers who need to see outcomes, not just output.
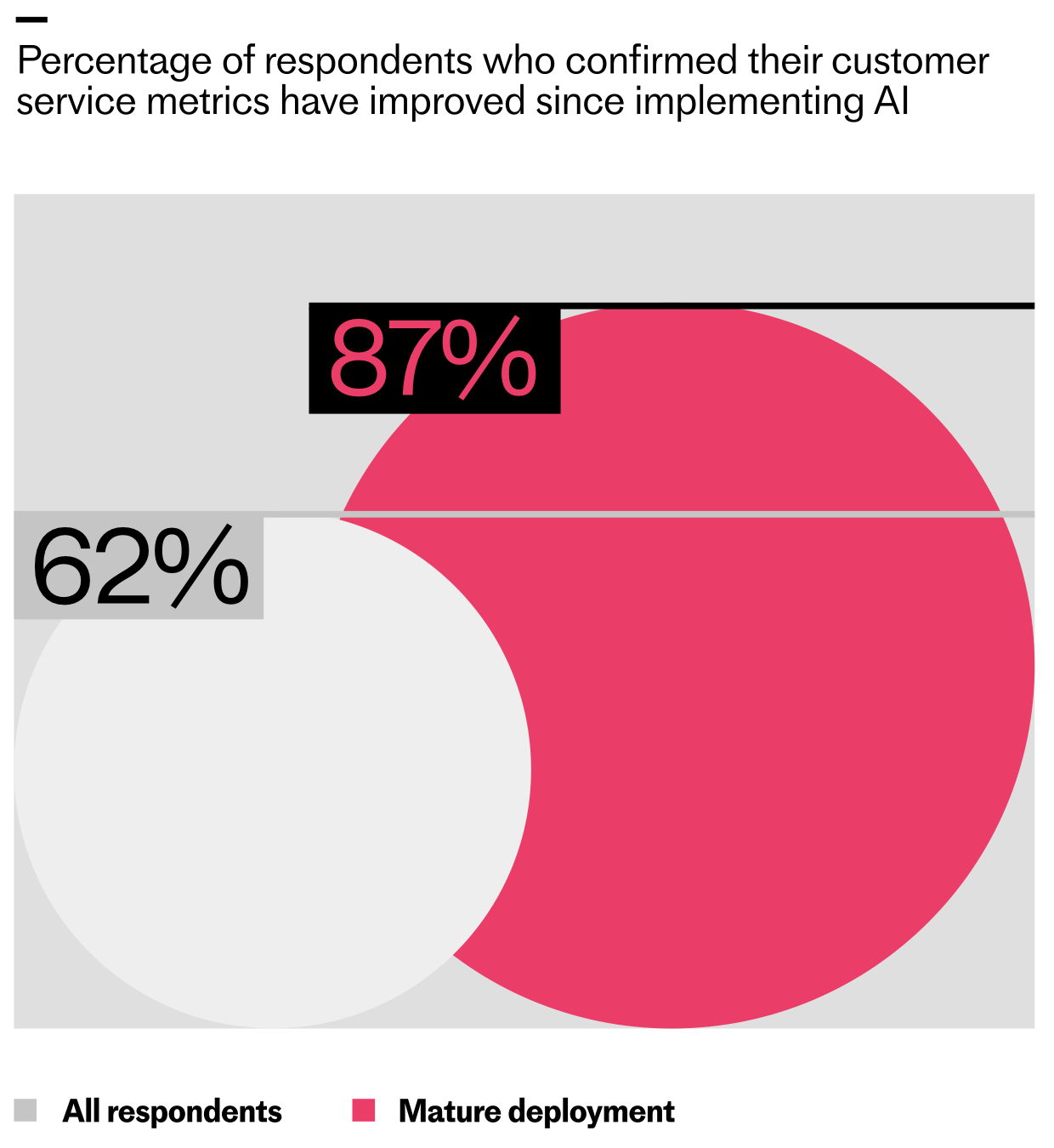
The teams going deeper are seeing higher returns. The research shows that 62% of support teams have seen their customer service metrics improve since implementing AI, with early wins showing up most clearly in speed and efficiency. But for teams that have reached mature deployment (where AI is fully integrated into operations) that number jumps to 87%.
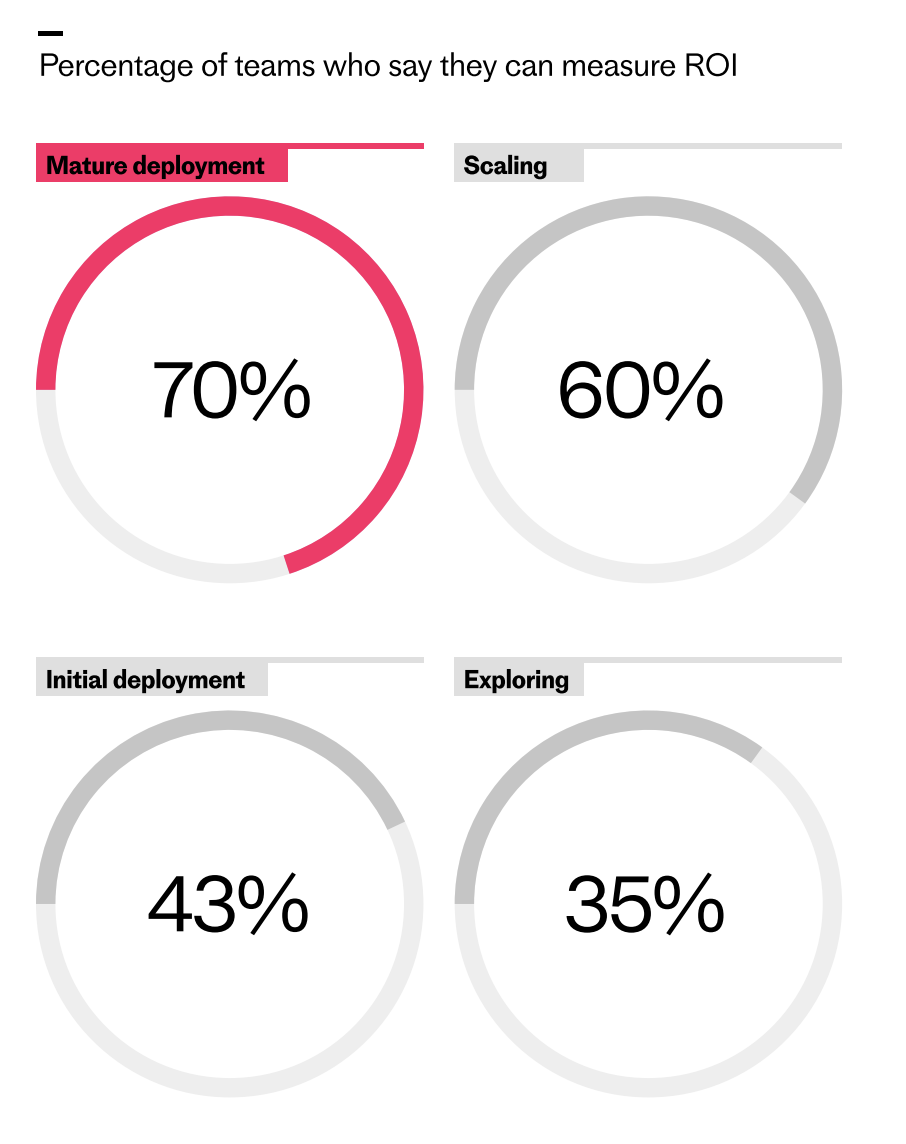
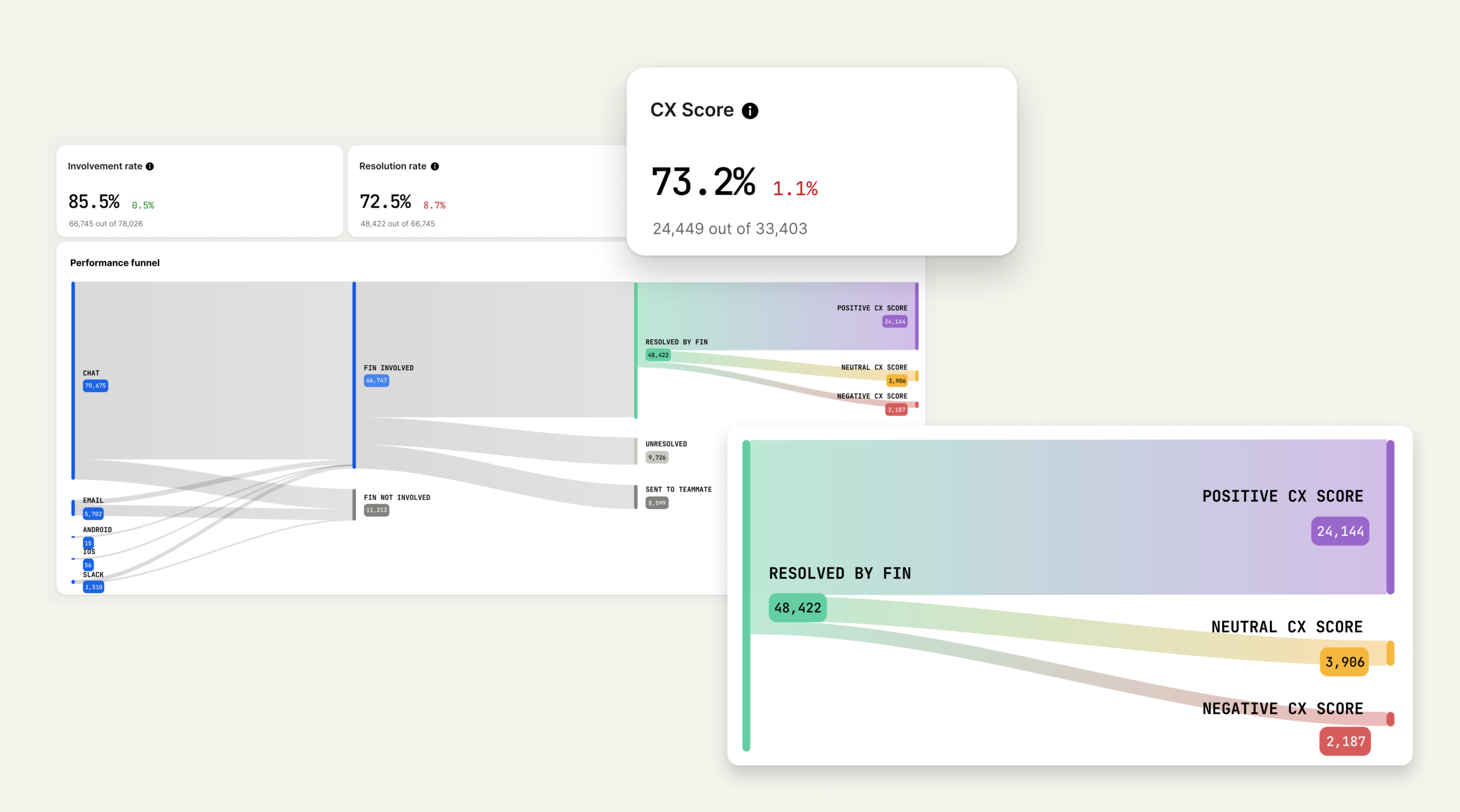
As AI programs advance, measurement confidence surges. This chart shows how ROI tracking rises from 35% in exploring to 70% in mature deployments—evidence of a widening execution gap in customer service.
The same pattern holds for the ability to measure ROI. Among teams in early exploration, just 35% say they can measure their return on AI investment, but for teams at the mature deployment stage, that rises to 70%. In my experience, this is the moment the conversation shifts from “is AI working?” to “how much leverage are we creating?”
As AI becomes more embedded in support workflows, what teams choose to measure starts to change. In the early stages of deployment, ROI is typically understood through improved customer response times, lower cost to serve, and freeing up capacity. Teams focus on how much time AI creates and whether it’s relieving pressure on the support organization. These signals help validate that the system is working, but they say little about how that capacity is ultimately used.
As deployments mature, measurement starts to reflect a different intent. Instead of stopping at time saved, teams look at where that capacity is reinvested—into higher value customer work and revenue-generating activities. ROI becomes less about relief and more about leverage. I encourage teams to set targets for capacity redeployment and tie them directly to activation, retention, and expansion outcomes.
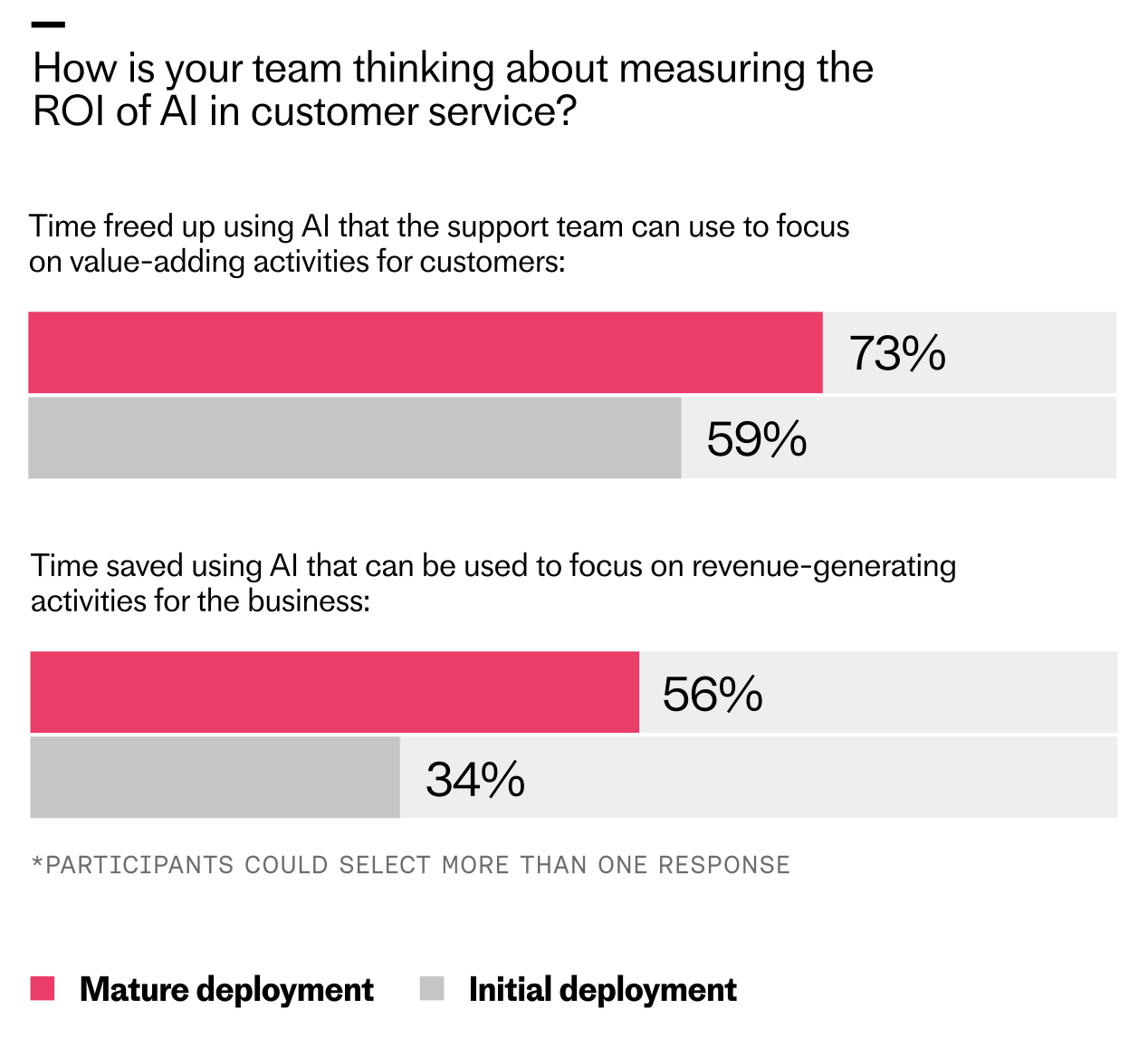
The report data shows this clearly. Across all maturity stages, the most commonly cited measure of ROI is "time freed up that the support team can use to focus on value-adding activities for customers." But at mature deployment, that signal intensifies, with 73% of teams citing it, compared to 56% at early exploration.
Mature AI deployments reveal clearer ROI: teams report more time freed for value-adding customer work (73% vs 59%) and more hours redirected to revenue-generating tasks (56% vs 34%) than initial rollouts.
What’s also interesting is that 56% of mature teams say freed capacity is being directed toward revenue-generating activities, up from 34% at initial deployment. That’s a powerful indicator that AI is shifting from a cost narrative to a growth narrative.
The result is a shift in economic intent: from measuring what AI saves to demonstrating how the capacity it creates is reinvested to drive growth. As a product leader, I anchor this conversation in outcome-based metrics and clear counterfactuals: what would it have cost to deliver the same experience without AI?
As AI takes on more work, the question moves from “does it save money?” to “how does it change the economics of support?” Legacy support economics were built for linear growth: more customer tickets meant more headcount, more outsourcing, and more software costs. Success was measured through containment—the number of queries that didn’t reach human agents. These models worked when volume and effort were tightly linked, but AI doesn’t scale linearly, and it needs to be evaluated differently.
To sustain AI investment and expand its impact, teams need to move beyond cost-cutting narratives and build a clearer case for business value. When done right, AI goes far beyond improving support efficiency. It rewires the financial model, breaking the link between support costs and revenue growth, and turning support into a contributor to customer activation, retention, and lifetime value. This means treating your AI Agent as a new workforce capability that changes how your support function creates and captures value. Here’s what value looks like in an AI-first model:
Deeper AI integration decouples growth from headcount. This split chart shows support volume surging while team size plateaus, revealing how automation unlocks scale, reduces costs, and makes ROI easier to prove.
Human productivity: Your team focuses on more strategic areas, not the queue.
System improvement: Every resolved query makes the system smarter.
Revenue influence: Support becomes a lever for activation, retention, and growth.
Organizational agility: You scale service without scaling headcount.
Leaders are racing ahead with real AI in support. Explore the 2026 Customer Service Transformation Report to see where deployment is stalling, benchmark your team, and get practical steps to scale automation that delights.
How does this look in practice? Intercom offers a compelling example with Fin. What started as a focused effort to improve their customer support experience has become one of the clearest illustrations of what happens when AI is fully embraced across an organization.
Since 2022, Fin has helped Intercom absorb more than a 300% increase in customer demand while improving the consistency of delivery—including supporting new routes into support for trial customers and website visitors. Today, Fin is involved in 97% of their customers' conversations. Of those, it resolves 83.5% end-to-end, putting their overall automation rate at 81%.
That depth of deployment allowed Intercom to scale service without scaling headcount. Without Fin, they would have needed at least 100 additional support teammates to meet rising demand and service standards.
As Fin took on the majority of day-to-day volume, the human support team shifted toward consultative work—helping customers adopt Fin more deeply, succeed faster, and unlock more value from the platform. Intercom now tracks metrics like “direct revenue generated” and “expansion revenue influenced” to understand the impact of these consultative support activities. This repositioned support from a cost center to an active contributor to long-term growth.
The throughline from The 2026 Customer Service Transformation Report is that deployment depth makes a significant difference. Teams that are investing in deeply integrating AI are reshaping how support scales and contributes to growth. Value becomes clearer as AI takes on more work, and support leaders can articulate that value to the rest of the business.
The gap between these teams and those still in the early stages is widening. A select group of pioneers are setting a new bar for what AI-powered customer service can deliver, and understanding what they’re doing differently is the first step toward closing that gap. If you want to dive deeper into the data and frameworks, you can download the report here: https://www.intercom.com/customer-transformation-report?utm_source=blog&utm_medium=internal&utm_campaign=20260128-report-owned-2026cstransformationreport&utm_content=chapterseries_2
I keep a simple mantra front and center: Figma is not the source of truth. The customer is. In practice, that means the only thing that truly counts is what we ship, how it performs, and whether users come back for more. Mockups are hypotheses; production usage is evidence. When my teams adopt this lens, velocity improves, judgment sharpens, and quality rises where it matters most.
So what does design actually do in a software company? At its best, design builds leverage for the whole system—engineering, product, and marketing—by clarifying problems, raising the quality bar, and making complex decisions legible. The standard I hold is ancient and still essential: products must be useful, usable, and desirable — and above all, used. When we calibrate around “used,” debates about pixels give way to outcomes, and cross-functional partners feel the difference.
I often trace the roots of our craft back well beyond the digital era. The lineage from industrial design to software is real; constraints, ergonomics, affordances, and systems thinking didn’t start with screens. If you’ve ever mapped delight, performance, and reliability in a Kano Model, you’ve touched this lineage. The translation to software is simple: design the full journey, not just the interface—prioritize what improves time-to-value, reduces cognitive load, and earns habitual use.
One lesson I’ve learned the hard way: why design leaders who stop designing stop leading. I still sketch flows, write UX copy, and prototype when it unblocks the team or sets a decisive quality bar. The altitude changes constantly—one hour I’m in a strategic roadmap review, the next I’m in a critique or poking at a prototype. Great design leaders jump up and down in altitude to connect vision to details without becoming a bottleneck.
Over time, I’ve come to rely on four pillars every design manager must master: craft (raising taste and execution), product strategy (clarifying choices and trade-offs), people leadership (coaching, feedback, and hiring), and systems (processes, rituals, and design ops that scale). Neglect any one of these and either quality, speed, or team health will eventually falter.
Perfectionism is a double-edged sword. Over-indexing on quality can paralyze decision-making, but lowering the bar indiscriminately is worse. I’ve seen moments where relaxing standards to “go faster” actually cost the business—rework piled up, trust eroded, and customer value stalled. The answer is principled delegation: I define what “must be true” at each milestone, delegate ownership with clear guardrails, and reserve my veto power for moments where product integrity is genuinely at risk.
Measuring success as a design leader starts with outcomes vs output OKRs. I care about activation, retention, time-to-first-value, NPS verbatims tied to key journeys, and the operational metrics that earn the right to build the next thing. Design output is visible; design outcomes are durable. When trade-offs are needed, I optimize for the smallest shippable surface that still proves the core value proposition, then expand with data.
Scaling judgment is the multiplier. I build it through pattern matching—studying enduring product systems from companies like Airbnb, Amazon, Apple, Asana, Notion, Stripe, Nest, and others—to distinguish where polish compels usage versus where it’s ornamental. Strong opinions matter, but so does being easy to convince with new evidence. I encourage designers to articulate the pattern they’re invoking, why it fits the job-to-be-done, and how we’ll know it worked.
Operating cadence matters. My week is anchored around recruiting, crits, and staff meetings that actually make decisions. In critiques, I use the Do/Try/Consider framework to give actionable direction without micromanaging. On one-on-ones, the question isn’t “Should one-on-ones exist?” but “What are they for right now?”—coaching, performance, or clearing execution blockers. If a meeting doesn’t increase clarity or commitment, it gets redesigned or removed.
Execution-wise, I’ve taken inspiration from Rippling’s operating system—especially its emphasis on speed, precise ownership, and hard commitments. The lesson is timeless: go fast on the right things, make clear promises, and instrument your work so you can see reality quickly. When speed is paired with crisp decision rights and observable outcomes, momentum compounds rather than frays trust.
Hiring your first design leader? Look for someone who can set standards, scale judgment, and ship. They should be able to zoom from company narrative to interaction copy in a single afternoon, coach product trios, and build rituals that make taste and trade-offs explicit. Above all, they should have a point of view on where quality moves the business and where speed is the quality.
Here’s how my team’s approach differs from many: Figma is not the source of truth. We design in Figma, but we learn from production. We pair designers with engineering early, prototype in code when it reduces risk, and wire telemetry into every critical path. Product trios use discovery to validate “useful, usable, desirable — and used,” then commit to outcomes with clear, testable definitions of success. The result is faster iteration, fewer surprises, and experiences customers actually adopt.
The throughline is simple and demanding: design for reality, not for the board. Keep your standards where they create business value, scale judgment with explicit patterns, and instrument everything so learning never stops. When teams embrace that, the work gets better, customers feel it, and the roadmap starts to pull you forward.
I’ve been pushing hard to operationalize AI for real product work, and this episode zeroes in on the moment Claude Code stops feeling like a demo and starts behaving like a dependable teammate. If you’ve ever wondered how to go from clever prompts in the browser to durable, repeatable workflows on your machine, this walkthrough is for you.
Listen on: Spotify | Apple Podcasts.
My first honest reaction to installing and configuring the desktop agent was the all-too-relatable “this tool thinks everything is a code repo” reality. That framing helped me reset expectations fast: instead of treating it like a magical universal assistant, I began designing guardrails, context, and repeatable routines—exactly how I’d onboard a new team member.
The shift from Claude-in-the-browser to Claude Code on my machine was the unlock. Locally, it can finally work with my files, folders, and workflows. That meant I could ground it in real artifacts—project docs, meeting notes, product specs, and historical decisions—so responses weren’t just plausible; they were contextual and verifiable.
On setup, I now treat /init and Claude MD files as my product requirements. I define roles, boundaries, and canonical sources up front, then run in a deliberate “walled garden.” The “treat it like an intern” model works beautifully: scope access intentionally, expand privileges as trust grows, and keep a tight audit trail of what it can touch and why.
Surprisingly, task management became my ideal on-ramp. It’s easy to validate, the feedback loops are tight, and the ROI is immediate. I export calendar windows rather than granting full calendar access, then let the agent map priorities into Trello, reconcile time blocks, and surface trade-offs. Fast wins build confidence—mine and the agent’s.
Model switching matters more than I expected. When speed is king and “good enough” will do, Haiku keeps the loop snappy. When stakes are higher—complex synthesis, nuanced product strategy, or gnarly ambiguity—I step up to Claude Opus 4.5. Being intentional about when to optimize for latency versus depth is a quiet superpower.
Web tasks can still spiral. When that happens, I pause its autonomy, toggle to fewer steps, and ask, “What are you doing?” Paired with Claude’s Web fetch tool, this makes the agent explain its chain-of-thought planning without exposing hidden reasoning, so I can spot brittle assumptions, prune distractions, and re-ground the task.
Content retrieval has become a killer workflow. I point the agent at my archives—blog posts, book drafts, transcripts, notes—and ask, “Where have I talked about this before?” It assembles a map of prior art, connects themes I’d forgotten, and prevents me from reinventing work. Over time, this evolves into a Zettelkasten-style research system that upgrades rigor and accelerates synthesis.
I’ve also turned Claude Code into a publishing engine. From a single transcript, it drafts titles, descriptions, show notes, and chapters, then routes artifacts to Ghost for formatting. Before anything ships, I run fact-checking workflows that validate claims against transcripts and research sources. The output improves, but more importantly, the scaffolding makes quality repeatable.
Reusable workflows compound. I rely on slash commands to trigger common jobs, break down larger efforts with sub-agents, and wire in hooks and plugins where external systems are needed. This is agentic AI at its most practical: fewer hero prompts, more reliable processes.
Audience analytics and content prioritization are helpful with caveats. I let the agent cluster themes and flag gaps, then I pressure-test its suggestions against first-party data and strategic goals. As with any model-driven insight, triangulation beats blind faith.
Two metaphors guide my day-to-day. First, Claude Code is like a dog—sometimes it returns with the stick, sometimes it gets lost in the woods. Second, the “intern” framing keeps me honest: don’t hand it the whole company on day one. With that mindset, my output jumped—more volume without sacrificing quality—because the workflow scaffolding got better.
In this episode, I cover what Claude Code is and why it’s useful even if you’re not an engineer, the real difference between the browser experience and running locally, how to shape behavior with /init and Claude MD files, why task management is the perfect proving ground, when to export calendar windows versus connecting directly, and when model-switching makes sense—Haiku for speed, Opus for depth.
I also dig into debugging web tasks by asking “What are you doing?”, content retrieval workflows across personal archives, building reusable slash-command systems with sub-agents, hooks, and plugins, practical publishing stacks from transcripts, fact-checking against transcripts and research sources, and using analytics to prioritize content—with a healthy respect for uncertainty.
If you’ve been trying to make Claude Code feel less like “throwing a stick into the woods,” this is the candid, tactical tour I wish I’d had on day one. Drop your questions and experiments below—I’m eager to compare notes and refine the playbook together.
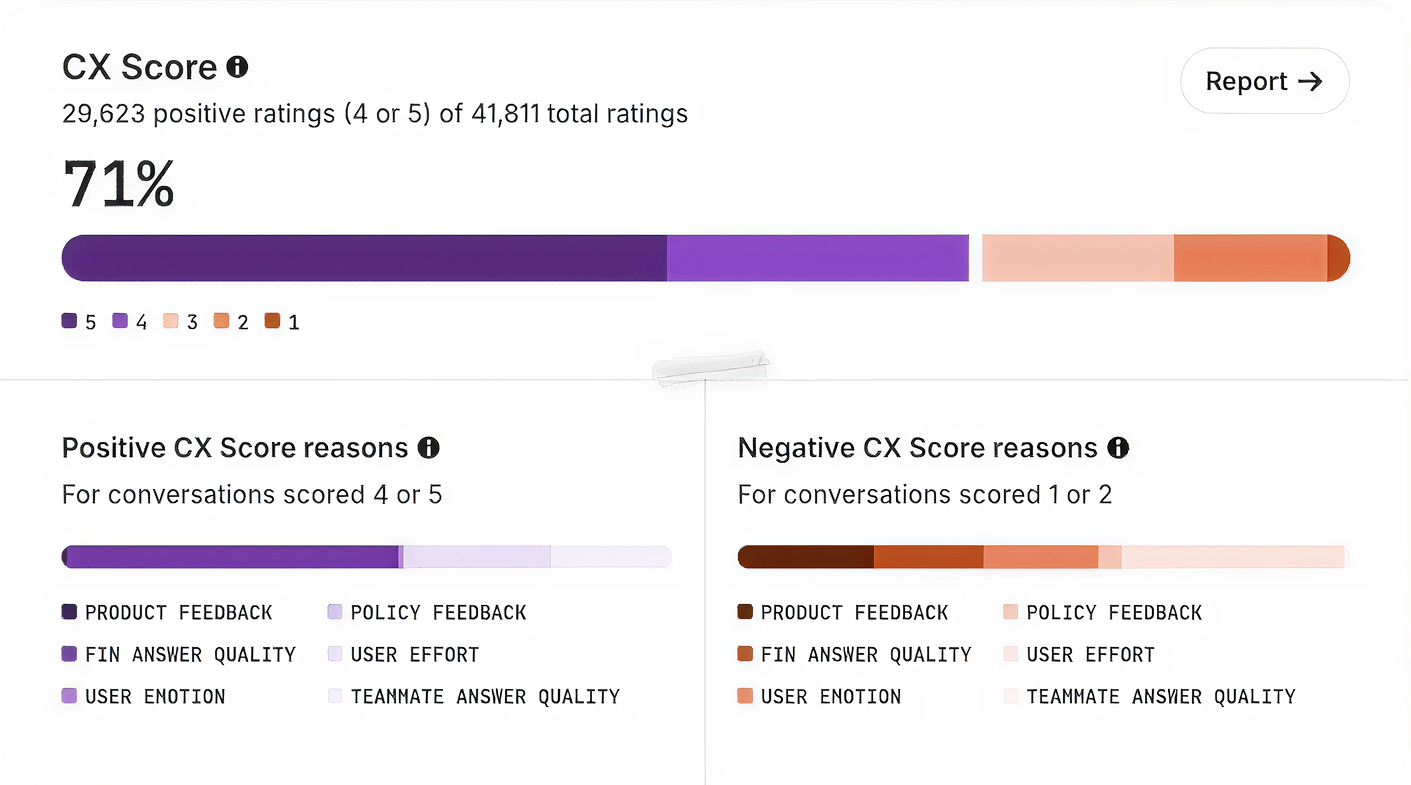
“You don’t have to trust the algorithm; you can see exactly why a conversation earned the score it did.”
We recently shared how we redesigned CX Score to deliver deeper, more actionable insights across every conversation. The most common follow-up from support leaders was simpler and incredibly important: “Can I trust it?” It’s the right question—and it’s the one I use as my own bar for whether a metric is ready for the C‑suite.
CS teams are the subject matter experts on customer experience. They understand the nuance of what customers feel, the context behind every interaction, and the difference between a technically resolved issue and a genuinely satisfied customer. I’ve learned, conversation by conversation, that any metric we ship has to capture that nuance at scale—or it doesn’t deserve to be used.
We built CX Score to give support teams a complete view of how their customers feel across every conversation. It surfaces what’s working, what’s not, and why—so leaders can communicate impact clearly and drive change across support, product, and the wider business.
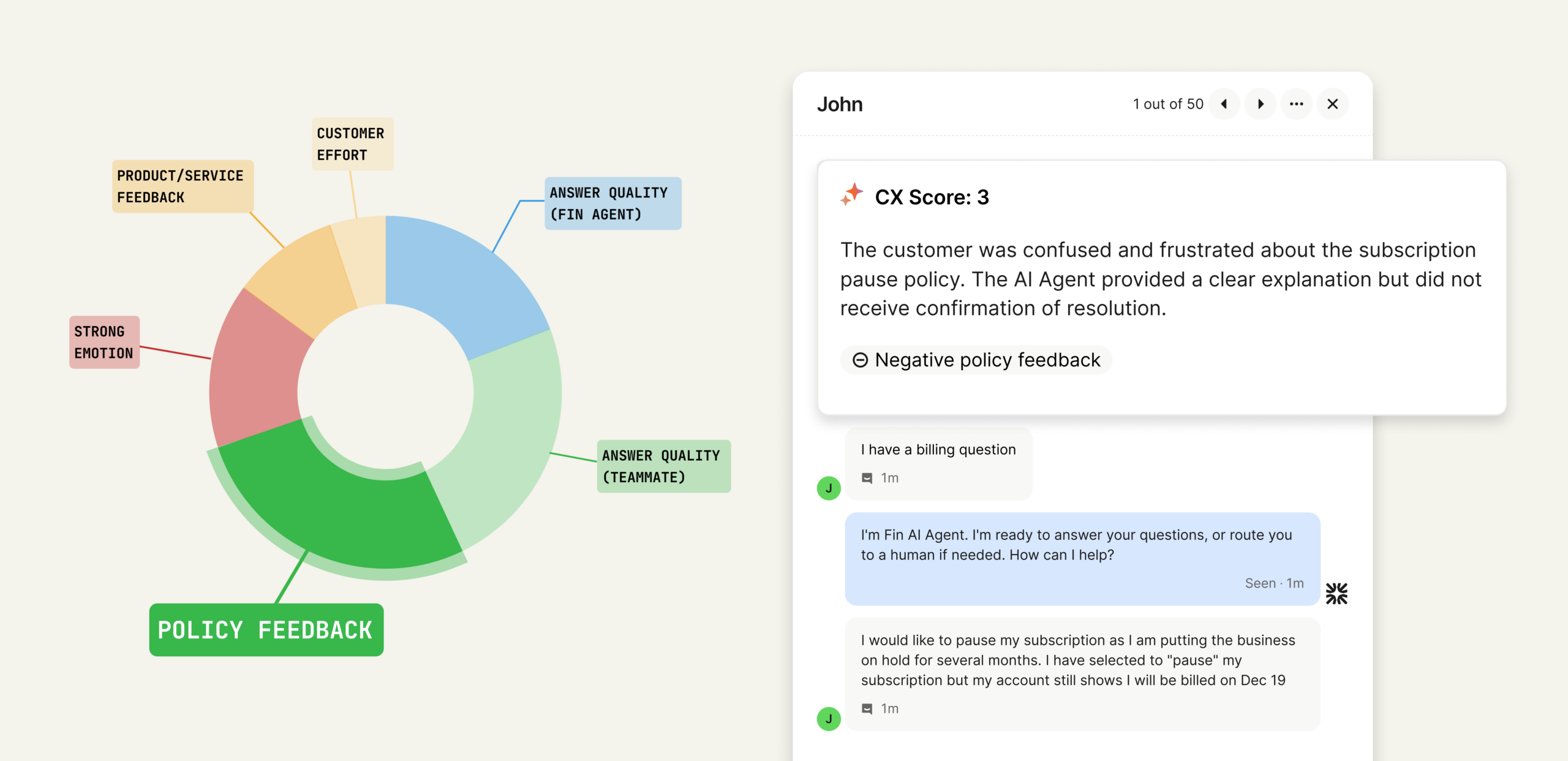
A CX Score in action: repeated CSV export failures trigger a low score and customer frustration, while the AI agent clarifies next steps and gathers details—turning raw signals into actionable support insights.
Here’s exactly how I approached building a trustworthy metric that support leaders can inspect, explain, and defend.
1) It’s grounded in how support teams define quality. I started with how experienced support professionals actually evaluate conversations—collecting real examples of strong, mixed, and poor interactions across industries, identifying the specific factors that shape overall experience, and writing plain-English rules for each. The result: CX Score applies the same criteria a trained support professional would use, not generic LLM assumptions.
2) It’s aligned with human judgment. We created a dataset of thousands of real customer conversations spanning multiple industries, languages, channels, and agent types. Each was manually reviewed by experienced support professionals—with two reviewers per conversation where possible and disagreement resolution to create stable consensus labels. The result: CX Score is trained and tested to behave like an expert reviewer, not a language model making broad guesses.
A modern CX analytics view shows how conversations flow from chat, email, and mobile into AI assistance, then to resolutions and sentiment outcomes—turning messy support data into a single, defensible CX Score.
3) It’s engineered by AI specialists. CX Score isn’t a prompt attached to an LLM. It’s a production system built by Intercom’s AI Group: 37 ML scientists and 350 engineers whose full-time focus is AI for customer service. The system includes specialized handling for long transcripts, model configuration tailored for support language and subtle sentiment, prompt engineering designed to default to neutral when evidence is weak, and a multi-stage evaluation pipeline that checks for precision, consistency, and reliability. The result: A metric built by a team that understands LLM behavior in production support environments, where accuracy and consistency matter most.
4) It’s validated statistically, not qualitatively. Trust requires measurement, not vibes. We tested CX Score across standard ML metrics: Precision (when the model flags a negative experience, how often do humans agree?), recall (how many human-identified issues does it catch?), and F1 score (the balance between both). We set an explicit bar: F1 above 0.8, representing high agreement with human judgment. We reran these evaluations through every revision, checking for regressions or biases, and I focused especially on negative experiences, because a false negative hides a real problem. The result: CX Score meets a measurable standard before it ships—not a gut check, a statistical requirement.
5) It was battle-tested with real customers. Lab accuracy isn’t enough. Customer environments are messy: Varied ticket types, mixed languages, unpredictable edge cases. Before release, we ran a multi-phase field test—shadow-scoring conversations with both old and new models, validating sensible behavior across agent type and conversation length, then rolling out to a controlled customer group who confirmed the scores felt right, reasons were clear, and insights were actionable. The result: CX Score shipped because real teams told us it made sense in practice, not because it passed internal tests.
From conversation to clarity: this visual maps the drivers behind a CX Score. Explore how policy feedback, answer quality, and effort combine to produce defendable insights support leaders can act on.
The importance of explainability. One of the most critical choices I made was ensuring CX Score isn’t a black box. Every score comes with clear reasons, concrete excerpts, and a short explanation of what influenced the rating. This turns the metric into something you can inspect, audit, and explain to executives. You don’t have to trust the algorithm. You can see exactly why a conversation earned the score it did.
A metric that evolves with your business. Customer expectations shift. Products change. AI improves. A trustworthy metric can’t be static. CX Score evolves with the same commitments that shaped its redesign: Evaluate the real signals that shape customer experience, keep the logic simple and interpretable, and ensure leaders can make clear decisions from it. It’s built to be a durable source of truth across every conversation.
The takeaway. In a world where products look the same and AI can generate any interaction, customer experience is one of the few differentiators that actually matters. Support leaders have built that expertise conversation by conversation. What they’ve lacked is a measurement system that could validate it at scale—one that’s reliable enough to report to the C-suite, explainable enough to defend in strategy meetings, and rigorous enough to drive real decisions. That’s what CX Score is designed to be: A metric that reflects the reality support leaders see every day, backed by the technical rigor to make it credible everywhere else.
Want to see CX Score in your workspace? Ask your admin to enable it for your team, and start using explainable AI insights to improve customer experience and coach with confidence.
Your calendar is full of approvals, but the problem probably isn’t that your team lacks initiative. The organization has learned that an important decision becomes safe only after you touch it.
You don’t fix that by telling people to be more empowered. You fix it by making authority, context, constraints, evidence, and escalation explicit. The goal is not to remove yourself from every decision. It is to ensure that your involvement is triggered by risk or abnormal variance, not by habit.
Delegation fails when you transfer work but retain judgment
A leader says, "You own this," but still expects to approve the plan, resolve every cross-functional conflict, and make the final tradeoff. The team receives responsibility without authority. It can prepare options, but it cannot truly decide.
The opposite failure is just as common. A leader transfers a decision with so little context that the owner must reconstruct the strategy, risk tolerance, and success criteria from scattered conversations. What looks like autonomy is actually abandonment.
Effective delegation sits between those extremes. You retain accountability for the quality of the operating system while another leader gains authority over a defined class of decisions. That person should know what outcome matters, which constraints are real, what evidence to use, and when the decision must return to you.
This is the transition many managers struggle with when they begin managing managers. Your value can no longer come primarily from supplying the best answer. It comes from installing mechanisms through which other leaders can repeatedly reach good answers.
Key takeaways
Delegate a decision domain, not merely the tasks required to prepare a decision.
Give each recurring decision one clearly named owner with enough authority to act.
Define constraints and escalation triggers before the owner encounters pressure.
Teach the reasoning behind past decisions so people can handle cases you did not anticipate.
Review outcomes and assumptions without reopening every decision you would have made differently.
Increase authority when judgment is consistently sound; intervene when risk, ownership, or evidence breaks down.
A useful test is to step away mentally and ask three questions: Would the priority remain intact? Would the relevant metrics continue to be watched? Would the team make approximately the same tradeoff without waiting for me? A no to any of them points to a missing mechanism, not automatically a weak employee.
Build a minimum decision contract
Before delegating a consequential decision, write a short decision contract. This is not a policy manual. It is the minimum context another capable leader needs in order to act without repeatedly requesting permission.
The contract should answer the following questions:
What decision is being delegated? Name the decision class precisely. "Own onboarding" is vague. "Choose and sequence onboarding experiments within the agreed quarterly outcome" is actionable.
Who decides? Assign one decision owner. Other people may contribute expertise, execute the work, or challenge assumptions, but shared input should not create ambiguous ownership.
What outcome governs the tradeoff? Connect the decision to an outcome and its driver tree. Without that connection, the owner will optimize for the loudest stakeholder or the most visible output.
What is inside the owner’s authority? State the product area, customer segment, time horizon, resources, and dependencies covered by the delegation.
Which constraints are real? Separate non-negotiable boundaries from preferences. If every preference is presented as a constraint, authority remains fictional.
What evidence is expected? Identify the metrics, customer evidence, technical inputs, or operating assumptions that should inform the choice.
What requires escalation? Define the conditions that change the decision from local to executive. Use observable triggers where possible.
When will the result be reviewed? Set the review around the availability of meaningful evidence, not the leader’s desire for reassurance.
Decision rights also need a verb. "Involved" is not a decision right. Use language such as recommend, decide, approve, execute, or advise. If two people both believe they approve, the real decision will drift upward when disagreement appears.
For a recurring product decision, the contract might say that a product leader decides which discovery opportunities to pursue, design and engineering advise on feasibility, and the executive is informed through the normal review cadence. Escalation occurs only if the choice changes the agreed strategy, creates an existential risk, lacks a credible metric owner, or exposes a material contradiction between the operating narrative and the numbers.
That final distinction matters. Notification is not permission. If a leader must wait for your reaction after every update, the supposed decision owner will learn to delay action until you respond.
Use a one-page decision brief for consequential choices
A decision brief makes judgment inspectable without forcing you into every working session. Keep it short enough to use under normal operating pressure:
Decision to make and why it must be made now
Owner and affected teams
Desired outcome and relevant driver-tree nodes
Options considered
Recommendation and rejected alternatives
Critical assumptions and evidence
Constraints and downstream consequences
Escalation triggers
Date or signal for reviewing the result
The brief should expose reasoning, not reward document production. If the owner cannot state the governing outcome, the most fragile assumption, and the reason for rejecting the strongest alternative, more pages will not solve the problem.
Teach judgment through driver trees and decision records
Rules cover familiar situations. Judgment covers the cases no rule anticipated. If you want delegated decisions to survive ambiguity, you have to make your mental models visible.
Start with the outcome. Decompose it into the controllable levers that could plausibly move it, instrument those levers, and assign each one a single-threaded owner. Document the assumptions that connect one level of the tree to the next. This forces a team to distinguish a desired result from the mechanism expected to produce it.
Suppose the desired outcome is stronger customer expansion. A team might initially examine the eligible expansion base, adoption of additional capabilities, realized usage, retention, and the acceptance of relevant offers. That is a hypothesis about causality, not a permanent truth. The team should test whether those nodes actually explain movement in the outcome and revise the tree when the evidence disagrees.
This changes the delegation conversation. Instead of asking, "Do I like this roadmap?" you can ask:
Which driver is the decision intended to move?
What evidence connects the proposed work to that driver?
Which assumption would invalidate the recommendation?
How quickly would the team detect that the assumption was wrong?
Who owns the metric after the decision is made?
What other driver might deteriorate as a result of this choice?
Those questions teach a reusable method. Simply giving the answer teaches the team that your presence is the method.
Record why the decision made sense at the time
A lightweight decision record should preserve the recommendation, assumptions, evidence, expected effect, owner, and review trigger. Its purpose is not to create an audit trail for blame. It is to make organizational learning possible.
Without the original assumptions, a later review is distorted by hindsight. A good outcome can hide poor reasoning, while a bad outcome can follow a sound decision made with incomplete information. Evaluate the process and the result separately.
Decision records also reveal patterns that coaching conversations miss. You may discover that a leader consistently underweights second-order effects, treats weak signals as conclusive, escalates too late, or avoids choices that create short-term metric pressure. That is actionable feedback because it concerns a repeatable reasoning pattern rather than one disputed answer.
Shared metric definitions matter here. If product, sales, marketing, and customer success use different meanings for activation, retention, or expansion, their decisions can appear aligned while optimizing different realities. Define the metric, its data source, its owner, and the assumptions beneath it. Shared language reduces the amount of executive translation required at every cross-functional seam.
Review variance without taking the decision back
A review cadence can scale judgment, or it can quietly recreate centralized approval. The difference lies in what the meeting is designed to do.
Monthly business reviews and quarterly business reviews should connect narrative to numbers. They should reveal whether assumptions still hold, where performance has deviated, who owns the response, and whether the deviation crosses an agreed threshold. They should not become ceremonies in which every team waits for an executive to rewrite its plan.
I use variance as the cue for changing altitude. A stable system with credible owners deserves space. An existential risk, an unowned metric, or a conflict between the explanation and the data warrants a deeper dive.
Signal
Leadership response
What to avoid
Metrics remain within agreed control limits and the owner explains the drivers credibly
Stay at the outcome level and let the owner act
Re-litigating tactics because you have a different preference
A leading indicator departs from its expected range
Ask for a focused diagnostic, owner, and next decision point
Changing the entire strategy before identifying the affected driver
The narrative and the numbers conflict
Inspect definitions, data sources, assumptions, and causal reasoning
Accepting a persuasive story without resolving the contradiction
A material metric has no credible owner
Clarify ownership before debating solutions
Becoming the permanent owner by default
The downside could threaten the business
Enter the decision directly and make the risk explicit
Preserving the appearance of delegation at the expense of accountability
The same class of mistake keeps recurring
Repair the decision mechanism and coach the reasoning pattern
Correcting each incident as though it were isolated
When you dive deep, tell the team why. Otherwise, a risk-based intervention can be interpreted as a permanent withdrawal of authority. Say which trigger fired, what part of the decision you are entering, and what authority the owner still retains.
When you step back, do that explicitly too. Silence is ambiguous. The owner needs to know whether you trust the decision, missed the update, or expect another approval request.
Run post-decisions, not blame sessions
After meaningful evidence arrives, compare the result with the original decision record. Ask what happened, which assumptions held, which failed, what signal appeared first, and how the decision mechanism should change.
Do not use the review to prove that your preferred option would have worked. That teaches leaders to protect themselves through escalation and excessive consensus. The useful output is a better assumption, threshold, driver tree, or decision right that improves the next choice.
Grow authority as leaders demonstrate judgment
Delegation should expand with evidence. A leader may begin by developing options and making a recommendation. As the leader demonstrates sound framing, timely escalation, and consistent tradeoffs, the role can move toward deciding within guardrails and then owning the domain with routine visibility rather than prior approval.
The progression should depend on decision quality, not confidence, tenure, or presentation skill. Look for observable behavior:
The leader frames the decision around an outcome rather than a preferred deliverable.
The strongest alternatives are represented fairly before being rejected.
Assumptions are made explicit and matched to evidence.
Short-term gains are weighed against longer-term consequences.
Cross-functional effects are surfaced before they become escalation points.
Bad news moves upward early enough to preserve options.
Results and learnings are documented without defensiveness.
The leader improves the mechanism after a miss instead of merely promising more effort.
This is where demanding and supportive leadership must coexist. Set an unambiguous bar for reasoning and ownership. Then provide fast feedback, coaching, access to context, and the resources required to meet that bar. High expectations without mechanisms create anxiety. Support without a clear bar creates dependence.
Ask leaders to bring a proposed path with the problem, but do not turn that expectation into a penalty for early escalation. The useful behavior is: "Here is what changed, here is my current diagnosis, here are the options, and here is where I need help." Requiring a polished solution before escalation delays the moment when executive context is most valuable.
Repeated escalations are diagnostic data. If capable people keep returning the same decision to you, inspect the system before questioning their courage. The constraint may be a disputed metric, incompatible incentives, an absent owner, an unclear strategic boundary, or a consequence they lack the authority to absorb.
You should also inspect your own behavior. If you routinely reverse reasonable decisions without explaining the mental model, demand visibility that functions as approval, or punish a well-reasoned miss, the organization will rationally centralize around you.
Know when the system is working
A delegated decision system is becoming durable when priorities survive your absence, tradeoffs remain legible across functions, and teams escalate exceptions instead of routine choices. Leaders can explain not only what they decided but why the decision fits the strategy, metrics, time horizon, and risk boundaries.
Your calendar should change as a consequence. Less time goes to status translation and habitual approvals. More time goes to strategy, architecture, resourcing, talent, and the small number of deviations that genuinely need executive attention.
Start with one recurring decision that currently waits for you. Name its owner, write the minimum decision contract, define the escalation triggers, and schedule a review around evidence. Then resist the urge to improve the decision by taking it back. Improve the system that produced it.
References
Shivam.Consulting Blog — Mastering 30,000-Foot Vision and Ground-Level Execution: Systems That Decide Without You
Your AI agent may look convincing in a demonstration and still disappear from daily work. If people try it once but return to spreadsheets, dashboards, tickets, and manual handoffs, you do not have an awareness problem. You have a workflow design problem.
Real adoption begins when a specific user can delegate a meaningful part of a recurring job, understand the agent’s limits, and see that the resulting decision or action is better. Product leaders create those conditions by narrowing the workflow, defining the agent’s authority, measuring the complete decision loop, and expanding autonomy only after the evidence supports it.
Choose a workflow, not a place to add AI
Starting with “Where can I deploy an agent?” pushes the team toward a feature. Start with “Which recurring decision or action is unnecessarily difficult?” That question keeps the work tied to customer or business value.
A good first workflow is frequent enough to generate feedback, narrow enough to evaluate, and bounded enough that a mistake can be caught before it causes material harm. It also has an identifiable beginning and end. “Help people be more productive” is not a workflow. “Use approved customer evidence to prepare the next-best-action options for a campaign review” is much closer.
Evaluate candidate workflows against six practical criteria:
Trigger: The user can recognize the moment when the agent should enter the workflow.
Frequency: The job repeats often enough for the user to form a habit and for the team to learn from actual use.
Grounding: The agent can retrieve the approved data, policies, history, or customer evidence required to do the job.
Completion: The team can observe whether the task reached a useful end state, rather than merely whether the model returned text.
Decision boundary: Everyone can state what the agent may decide, what requires approval, and what it must never do.
Recoverability: An incorrect recommendation or action can be rejected, corrected, or reversed without disproportionate damage.
Mark each candidate high, medium, or low on those criteria. Do not hide a weak decision boundary behind an attractive use case. A repetitive workflow with clear evidence and a review point is usually a better adoption bet than an ambitious end-to-end process with unclear ownership.
This is also why natural-language access alone is not an agent strategy. It can lower the barrier between a user’s question and an analytical answer, which may improve activation. Adoption becomes more valuable when the answer connects to a defined next action and the eventual impact of that action can be observed.
Write the selected workflow in one sentence before approving a roadmap:
When [user] encounters [trigger], the agent uses [approved context] to [recommend, prepare, or execute an action]; [person or policy] controls [decision boundary], and success is measured by [workflow or customer outcome].
Agent workflow template
If the team cannot complete that sentence without vague language, discovery is not finished.
Write an adoption contract before writing the roadmap
An agent changes who performs work, which information informs it, and where accountability sits. That is an operating-model decision disguised as a product feature. A one-page adoption contract makes the change explicit before implementation creates momentum around the wrong behavior.
The contract should answer seven questions:
Who is the intended user? Name the role and the situation, not a broad department.
What job is being delegated? Separate information retrieval, analysis, recommendation, preparation, and execution. They carry different risks.
What outcome should improve? Connect the workflow to an existing customer or business outcome, not to the amount of AI content produced.
Which information is authorized? Identify the systems of record, retrieval scope, freshness requirements, and data that must remain unavailable.
Where does human judgment remain mandatory? Put approval at the consequential decision, not at an arbitrary screen in the interface.
How should uncertainty and failure appear? Define when the agent should cite evidence, ask for missing context, abstain, escalate, or report that a tool failed.
What earns expansion? Specify the quality, adoption, outcome, and risk signals required before the agent receives more users, tools, or autonomy.
This contract prevents a common measurement error: treating interaction volume as value. Conversations, generated documents, and tool calls are outputs. They can help diagnose behavior, but they do not show that the workflow improved. Activation, successful completion, repeat use at the next relevant trigger, and retention are stronger adoption signals. They still need to connect to a journey outcome such as a better decision, a completed customer task, or a validated change.
Use outcomes versus output OKRs to keep the distinction visible. An output key result might promise to launch an agent or add integrations. An outcome key result should describe the behavior or customer result that the workflow is intended to change. The delivery milestone belongs in the plan; it should not masquerade as proof of adoption.
The contract also makes prioritization easier. A request for another model, data connector, or agent tool must improve a named part of the workflow. If it cannot be tied to grounding quality, task completion, user control, or the target outcome, it is probably infrastructure enthusiasm rather than a product requirement.
Earn autonomy through observable stages
Do not jump from a chat interface to autonomous execution because the happy-path demo worked. Autonomy should advance in stages, with a different role for the user and a different standard of evidence at each stage.
Capability stage
What the agent does
Human responsibility
Evidence needed to advance
Explain
Retrieves and synthesizes approved information
Checks the evidence and interprets it
Grounding, completeness, and answer-quality evals
Recommend
Produces alternatives or ranks possible next actions
Makes the decision and records important overrides
Relevance, reasoning, boundary, and decision-support evals
Prepare
Creates a draft action, configuration, or artifact without committing it
Edits and approves before execution
Task-specific correctness, policy, format, and exception evals
Act
Executes a bounded action through approved tools
Supervises exceptions and reviews consequential cases
Reliable task completion, tool behavior, auditability, and recovery controls
The stages are not a maturity contest. Some workflows should remain in recommendation or preparation mode because the consequences of an incorrect action outweigh the benefit of removing approval. Human-in-the-loop design is useful when the person has evidence, authority, and enough context to intervene. A mandatory click from someone who cannot evaluate the result adds friction without adding control.
Before releasing each stage, create an evaluation set that represents the actual workflow. Include normal cases, ambiguous requests, missing or stale context, policy boundaries, conflicting evidence, and tool failures. For every case, record the expected behavior, unacceptable behavior, scoring rubric, and evidence the evaluator should inspect.
Do not collapse evaluation into a single pass rate. An answer can be fluent and wrong, properly grounded but irrelevant, or correct while attempting an unauthorized action. Score the dimensions that matter independently: retrieval and grounding, task correctness, tool selection, instruction adherence, policy compliance, escalation behavior, and completion quality.
Treat prompts and evaluation datasets as versioned product assets. When the model, prompt, retrieval logic, tool definition, or policy changes, rerun the relevant evaluation set and preserve the result with the release. Otherwise, a team can improve one visible behavior while silently degrading another.
A retrieval-first design is especially important when the workflow depends on institutional knowledge. The agent should use authorized context before relying on general model knowledge, expose enough evidence for the user to inspect, and ask for clarification or abstain when required context is unavailable. That behavior may look less magical in a demonstration, but it is much easier to trust in repeated work.
Measure the entire agent loop, not the chat surface
A traditional feature funnel can tell you who opened an agent and who returned. It cannot explain whether the agent retrieved the right context, selected the right tool, required extensive correction, or produced an action that affected the intended outcome. Agent Analytics must reconstruct the path from intent to result.
Instrument the workflow as a connected event chain:
Intent and eligibility: Which workflow was triggered, and was the user and situation within scope?
Context: Which approved knowledge or data was retrieved, and was essential context unavailable?
Reasoning path: Which plan or action sequence did the system select?
Tool behavior: Which tools were called, which arguments were passed, and where did errors or retries occur?
Human intervention: Did the user accept, edit, reject, override, or abandon the result?
Completion: Did the workflow reach its defined end state?
Outcome: Did the customer or business indicator named in the adoption contract move in the intended direction?
Apply privacy-by-design to that event model. Logging every raw prompt, retrieved record, or tool payload by default can create unnecessary exposure. Decide which fields are required for product learning, who may access them, how sensitive data is handled, and how long the information is retained. Data governance belongs in the instrumentation design, not in a review after launch.
Review four layers together:
Quality: Evaluation results by task and failure dimension.
Behavior: Activation, successful completion, repeat use, abandonment, edits, and overrides.
Outcome: The customer or business result attached to the workflow.
Risk and reliability: Boundary violations, unsupported claims, tool failures, escalations, and consequential incidents.
Each layer corrects a possible misreading. High usage with weak quality can mean users are compensating for the system. Strong offline quality with little repeat use can mean the workflow is not important or the interaction arrives at the wrong moment. Completion without an outcome can mean the agent is accelerating work that should not have been done. Outcome movement without traceability makes it difficult to know whether the agent deserves credit or whether the result will persist.
Use qualitative evidence to explain those patterns. Review corrections and overrides, collect feedback at the point of use, and connect support signals to roadmap decisions. A generic satisfaction question is less useful than asking what evidence was missing, which step the user repeated manually, or why the recommendation could not be acted on.
When comparing user-facing variants, define the primary outcome and minimum detectable effect before running an A/B test. This prevents the team from declaring success based on an incidental movement in a convenient metric. A/B testing is appropriate only where traffic, exposure, and risk make controlled experimentation meaningful; rare or consequential actions need direct evaluation, review, and guardrails instead.
Make agent adoption an operating change
A launch campaign can create trials. It cannot resolve unclear ownership, weak evaluation, missing context, or a workflow that asks users to supervise the agent without giving them useful control. Sustainable adoption requires a product operating model around the capability.
Give a product trio responsibility for the complete workflow and pair it with the people who can close the distance between a prototype and production use:
Product management owns the user problem, target outcome, decision boundary, adoption contract, and expansion decision.
Design owns how intent, evidence, uncertainty, approval, correction, and escalation appear in the experience.
Engineering owns retrieval, tool permissions, system behavior, observability, release controls, and recovery paths.
A forward deployed engineer or equivalent customer-facing technical partner helps expose the real context, integrations, and exceptions hidden by a clean prototype.
Data and risk owners define acceptable model behavior, privacy constraints, access rules, and the evidence required for governance.
The leadership cadence should follow the learning loop. Discovery identifies a high-value workflow and pressure-tests it with user evidence. Pre-release review examines evaluations and failure modes. A narrow rollout tests the workflow with explicit human checkpoints. Operating reviews examine quality, behavior, outcomes, and incidents together. Expansion adds a capability, population, tool, or level of autonomy only when the prior boundary is performing as intended.
This model should influence AI hiring as well. A strong AI product candidate should be able to turn a broad ambition into a bounded workflow, define an evaluation rubric, separate model quality from product outcomes, place human judgment at the right decision, and explain what evidence would justify more autonomy. Prompt fluency without those skills is not product leadership.
Key takeaways
Start with one recurring, bounded workflow whose completion and outcome can be observed.
Write an adoption contract covering the user, trigger, delegated job, approved context, decision boundary, failure behavior, and expansion criteria.
Progress from explanation to recommendation, preparation, and bounded action only as evaluation and production evidence improve.
Version prompts, retrieval logic, tool definitions, and evaluation datasets with releases.
Instrument intent, context, tool calls, human intervention, completion, and downstream outcomes as one decision loop.
Scale when quality, repeat use, workflow outcomes, and risk controls agree – not when a demonstration attracts attention.
Your next move does not need to be a company-wide agent mandate. Put three candidate workflows through the six selection criteria. Choose the one with the clearest trigger, evidence, completion point, and decision boundary. Then write its adoption contract and evaluation set before funding a broad build. If the narrow workflow earns repeat use and improves its named outcome, you will have evidence for the next capability – and a repeatable method for every agent that follows.
This is the year to build your personal operating system. For me, that line isn’t a slogan; it’s a commitment to eliminate context switching, compress decision cycles, and turn fragmented information into a reliable source of truth. As a product leader, I needed a system that blends judgment, data, and automation—so I built mine around Claude Code.
When I say “personal operating system,” I mean an integrated set of AI workflows, rituals, and tools that capture knowledge, structure decisions, and automate execution. It’s where product discovery meets delivery: a place to synthesize signals, prioritize with clarity, and move from insight to action without friction. The outcome is fewer ad hoc decisions, more deliberate strategy, and a calmer, more focused day.
Claude Code sits at the center because it helps me translate intent into working software and repeatable processes. I use it to scaffold small utilities, write adapters for APIs, and evolve prompts into robust patterns. It accelerates everything from research synthesis and PRD drafting to backlog grooming and stakeholder updates—while keeping me in the loop for final judgment.
Under the hood, I run a retrieval-first pipeline that connects notes, docs, tickets, research transcripts, and roadmaps into a searchable, living memory. With careful context window management, I feed only the most relevant snippets into Claude Code, preserving accuracy and speed. The result: richer answers, fewer hallucinations, and an assistant that “remembers” what matters without drowning in noise.
My daily loop is simple: capture, synthesize, decide, and act. I capture customer signals and meeting notes into a personal knowledge management vault; synthesize patterns with prompt engineering that emphasizes evidence; decide using outcomes vs output OKRs; and act by generating drafts, creating tasks, and updating artifacts. Claude Code helps me wire this end-to-end, so the system works even on my busiest days.
If you’re implementing this from scratch, start small. Pick one high-friction workflow—say, product feedback triage—and build a narrow agentic AI flow to classify, summarize, and route items. Use eval-driven development to test prompts against known edge cases. Add guardrails and privacy-by-design practices from day one, then expand to neighboring workflows once the first loop is reliable.
Governance matters. I treat AI risk management, data governance, and security as first-class citizens: limited data scopes, clear audit trails, human-in-the-loop approvals, and rollback plans. Feature flags control changes; observability tracks drift and quality; and a simple playbook documents how we deploy, monitor, and improve the system.
Measure what this personal operating system earns you. Track decision latency, cycle time from signal to action, meeting-to-output ratios, and the signal-to-noise ratio of inputs. When the system is working, you’ll feel it: fewer meetings, more momentum, and sharper product strategy supported by trustworthy AI workflows.
The goal isn’t to automate judgment—it’s to protect it. By letting Claude Code handle the glue work and information wrangling, I preserve energy for high-leverage thinking: positioning, sequencing, and trade-offs. Build your personal operating system now, and make this the year your product practice runs with clarity and composure.
Is hiring broken—or just badly designed? I’ve been sitting with that question after a recent conversation that crystallized what I see across product organizations: AI-fueled application overload, sprawling interview loops, and fuzzy criteria that invite groupthink at exactly the wrong moments. If you’ve ever watched a promising candidate stall out late in the process, you’re not alone. Listen to this episode on: Spotify | Apple Podcasts.
Here’s the reality I’m observing in the market: Layoffs and hiring freezes have flooded the funnel, while AI tools make it trivial to submit hundreds of applications. Companies are overwhelmed, so they respond by adding more interviews and more stakeholders, hoping more touchpoints equal better signal. In practice, that complexity often dilutes accountability and increases noise—especially for product management leadership roles where clarity, not consensus theater, determines success.
I’ve seen too many offers derailed by “one last step.” A candidate clears every structured interview, then a casual lunch or unframed panel suddenly becomes the deciding factor. The team isn’t briefed on what to evaluate, one lukewarm comment lands, and group dynamics cascade into a no-hire. That’s not rigor—it’s randomness masked as prudence.
Groupthink ≠ good hiring decisions. When everyone has veto power, risk-averse no-decisions become the default. Focus-group-style interviews create bias, not signal, and “culture fit” often becomes a proxy for stereotyping or personal preference. As product leaders, we’d never ship a feature based on vibes; we shouldn’t make high-stakes hiring calls that way either.
There’s a better way—and it mirrors how we run great product discovery. Define who you’re hiring before writing the job description. Set clear success metrics for the role. Assign each interviewer specific criteria to evaluate. Treat hiring like product discovery: intentional, structured, and evidence-based. In my teams, that looks like tight scorecards, interviewer calibration, and a decision owner who synthesizes evidence—not a popularity contest where the loudest voice wins.
Chemistry checks still matter, but only when we define what collaboration actually means for the role. Introversion, debate style, or lunch-table small talk are not performance indicators. I look for behaviors we value in empowered product teams—clarity of thinking, healthy dissent, co-creation under constraints—often via a real working session with the future product trio. Diverse teams outperform homogenous ones, even if not everyone “vibes,” so I optimize for complementary strengths over sameness.
If you’re a candidate, remember: When a process feels broken, it’s often not about you. Ask how you’re being evaluated to gauge process maturity; a thoughtful team will happily walk you through their rubric and what great looks like. For structure and support, I’ve seen “Who: The A Method for Hiring” help leaders clarify requirements; “Never Search Alone” and joining a Job Search Council (JSC) can give you peer accountability and sharper narratives. For current openings, I regularly point PMs to Scott Baldwin’s PM job postings on LinkedIn.
My challenge to fellow product leaders: Audit your hiring process the way you’d audit your roadmap. Where are decisions getting stuck? Where are you over-indexing on consensus and under-indexing on evidence? Tighten the criteria, streamline stakeholders, and instrument the funnel so you can learn and improve. The payoff is faster, fairer, more confident decisions—and teams that reflect the rigor we expect in product strategy and stakeholder management.
What’s one change you can make this week—reworking the scorecard, calibrating interviewers, or replacing an unstructured lunch with a real collaboration exercise? Small improvements compound. Let’s build hiring systems that are worthy of the talent we’re trying to attract.
“Continuous Discovery Habits” turns five this year, and I’m celebrating by reading the book together with you. Each month, I’m releasing an in-depth reading guide designed for empowered product teams and product trios—complete with the chapters we’ll read, a preview of the key concepts, short shareable videos, individual and team discussion prompts, team exercises you can run immediately, and additional reading to go deeper.
We’ll discuss each month’s reading in the comments, and we’ll gather quarterly for live calls. If you’re joining late, no problem—I’ll be monitoring comments throughout the year. Start with the current month or go back to January (https://www.producttalk.org/lets-read-continuous-discovery-habits-together-january-2026/). Jump in where it serves you best, ask for help, share what’s working, and connect with other readers any time.
If you want to participate, grab a copy of the book (https://amzn.to/3hGkNYT?ref=producttalk.org)—or dust off your old one—share the “Spread the Love” videos with your colleagues, set aside time to run the team exercises, and register for the community sessions. Let’s do this.
This Month’s Reading
Chapters: Chapter 3: Focusing on Outcomes Over Outputs
Estimated reading time: ~22 minutes
This chapter zeroes in on the critical difference between business outcomes and product outcomes—and why it matters which one your team is assigned; how to translate lagging business metrics into actionable product outcomes you can actually influence; why setting outcomes should be a two-way negotiation between leaders and product trios; when to start with a learning goal versus a performance goal; and five common anti-patterns that derail outcome-focused teams. Need a copy? Grab the book (https://amzn.to/3hGkNYT?ref=producttalk.org).
Share the Love with Friends and Colleagues
We learn best in community. I like to seed conversations across my org with short, high-signal content—especially when I’m shifting a culture from outputs to outcomes and sharpening OKRs. Use these short videos to bring peers into the conversation and invite them to read along:
“What’s an outcome?” (https://videos.producttalk.org/videos/ea9fdab71d1ee3c263/whats-an-outcome?ref=producttalk.org) — The real value of starting with an outcome. “Business outcomes vs. product outcomes” (https://videos.producttalk.org/videos/069fd5b5101ee2c78f/business-outcomes-vs-product-outcomes?ref=producttalk.org) — Why product teams need product outcomes, not business outcomes. “What’s the difference between OKRs and outcomes?” (https://videos.producttalk.org/videos/069fdab61919e4c38f/whats-the-difference-between-okrs-and-outcomes?ref=producttalk.org) — Any outcome can be represented as an OKR. “Understanding revenue model formulas” (https://videos.producttalk.org/videos/799fd5b5101ee2c4f0/understanding-revenue-model-formulas?ref=producttalk.org) — How to identify the business outcomes your company cares about. “Revisit your outcome every quarter” (https://videos.producttalk.org/videos/449fd5b4111ee0cfcd/revisit-your-outcome-every-quarter?ref=producttalk.org) — Don’t abandon your outcome, but do revisit how you measure it.
Reflect and Discuss What You Read
Reflection is the conversion rate optimizer for learning. When we pause to discuss what we’re reading, we retain more and apply it faster—especially in product discovery and product strategy work. This chapter challenges us to update our definition of success: away from features shipped and toward outcomes achieved. This month, I’m examining my own relationship with outcomes—where I’ve been rigorous, where I’ve drifted, and how I can help my teams strengthen day-to-day behaviors.
Individual Reflection
If your team isn’t working toward an outcome, look at the features or projects on your roadmap and ask: What impact are they supposed to have? If they succeed, what customer behavior or business result would change? If your team does have an outcome, consider whether it’s a business outcome, a product outcome, or a traction metric—and how that choice shapes your daily decisions and discovery cadence. Finally, think about the last time your team’s outcome changed: Was it a deliberate strategic shift, or did it feel like ping-ponging from one priority to the next?
Team Discussion
As a team, classify your current outcome: Is it a business outcome, a product outcome, or a traction metric? If it’s a business outcome, identify the leading customer behaviors that would signal momentum; if it’s a traction metric, broaden it to a product outcome that gives you more room to explore. Then, name which of the five anti-patterns (pursuing too many outcomes, ping-ponging, individual outcomes, outputs as outcomes, or tunnel vision) shows up for you and pick one concrete change. Finally, assess how outcomes are set: Are they handed down, or does your product trio co-create them? What would it take to make this a true two-way negotiation?
Put It Into Practice
Understanding the difference between business outcomes and product outcomes is table stakes. Translating one into the other is where product management leadership shows up. These exercises will help you connect company goals to customer behavior, avoid outcomes vs output OKRs traps, and increase your span of control over meaningful change.
Exercise: Map Your Revenue Model
Time: 30 minutes. Do this: Solo first, then share with your team. Start with this question: How does your company make money? Write out the formula for your revenue model. For example, a subscription business might be: Revenue = Number of Customers × Average Monthly Spend × Retention. Once you have the formula, identify each variable as a potential business outcome. Then, for each business outcome, brainstorm two to three product outcomes (customer behaviors or sentiments) that might be leading indicators. Which of these product outcomes is your team best positioned to influence?
Exercise: Audit Your Current Outcome
Time: 45 minutes. Do this: With your product trio. Take your team’s current outcome and run it through a quick diagnostic: Is it a business outcome, product outcome, or traction metric? If it’s a business outcome, what product outcomes might drive it? If it’s a traction metric, how might you broaden it to a product outcome? Is it a leading indicator or a lagging indicator? Can you measure progress weekly, or do you have to wait months? Is it within your team’s span of control? Based on your answers, draft a revised outcome that offers more actionable feedback while still connecting to business value, and prepare to discuss this with your product leader.
Go Deeper: Additional Reading
If you prefer an audio summary of this month’s reading, including the book chapter and the resources below, I’ve included an audio version at the end of this post for paid subscribers.
Related In-Depth Guide: Shifting from Outputs to Outcomes: Why It Matters and How to Get Started (https://www.producttalk.org/shifting-from-outputs-to-outcomes/).
Supplementary Reading: Empower Product Teams with Product Outcomes, Not Business Outcomes (https://www.producttalk.org/2020/05/product-outcomes/). Defining Product Outcomes: The 8 Most Common Mistakes You Should Avoid (https://www.producttalk.org/2022/12/defining-product-outcomes/). Understanding How Product Outcomes Connect to Revenue and Costs (https://www.producttalk.org/2023/04/connecting-product-outcomes-to-revenue-and-costs/). Product in Practice: Iterating to an Actionable Outcome at tails.com (https://www.producttalk.org/2020/08/actionable-outcomes/). Product in Practice: Iterating on Outcomes with Limited Data (https://www.producttalk.org/2023/12/iterating-on-outcomes-with-limited-data/). Measurable Outcomes – All Things Product with Teresa Torres and Petra Wille (https://www.producttalk.org/measurable-outcomes-all-things-product-podcast-with-teresa-torres-petra-wille/).
Other Voices: The Business Equation by Brett Bivens (https://venturedesktop.substack.com/p/the-business-equation?ref=producttalk.org). KPI Trees: How to Bridge the Gap Between Customer Behavior, Product Metrics, and Company Goals by Petra Wille and Shaun Russell (https://www.petra-wille.com/blog/kpi-trees-how-to-bridge-the-gap-between-customer-behavior-product-metrics-and-company-goals?ref=producttalk.org). Persistent Models vs. Point-In-Time Goals by John Cutler (https://cutlefish.substack.com/p/tbm-2553-persistent-models-vs-point?ref=producttalk.org). Is It Time to Ditch the Old SaaS Metrics? by Kyle Poyar (https://openviewpartners.com/blog/saas-metrics-plg/?ref=producttalk.org). How Engagement Metrics Can Be Misleading by Oleg Yakubenkov (https://gopractice.io/blog/how-engagement-metrics-can-be-misleading/?ref=producttalk.org). Subscription Churn Metrics and Benchmarks for Operators by Elena Verna (https://www.elenaverna.com/p/subscription-churn-benchmarks-and?ref=producttalk.org).
Related Courses: Business Fundamentals: Navigate Your Business Context with Confidence (https://learn.producttalk.org/course/business-fundamentals?utm_source=Product+Talk&utm_medium=cdh-book-club-february-2026).
Our Live Discussion Schedule
Our live discussion sessions are for paid subscribers and will not be recorded. Invitations will go out to Supporting Members and CDH Members (http://members.producttalk.org/?ref=producttalk.org) two weeks before each event—reserve time on your calendar now so you can participate fully and bring real examples from your team.
Wednesday, March 18, 2026: 9am–10am PDT and 4pm–5pm PDT. Tuesday, June 16, 2026: 9am–10am PDT and 4pm–5pm PDT. Thursday, September 17, 2026: 9am–10am PDT and 4pm–5pm PDT. Wednesday, December 16, 2026: 9am–10am PST and 4pm–5pm PST.
Audio Summary
Prefer to listen? I’ve included an audio summary—Stop Measuring Code Start Measuring Behavior—at the end of this post so you can review the main ideas on your commute or between meetings.
I’m excited to dive into outcomes with you this month. As a product leader, I’ve seen teams transform their product discovery, product roadmapping and sprint planning, and OKR quality when they anchor on clear product outcomes tied to business value. Let’s build that muscle together and make this a quarter where we stop measuring output and start driving outcomes.
“Speed is not the enemy of safety; it is the prerequisite for it.” I live by this principle. In our organization, the average time from merging code to it being used by customers in production is just 12 minutes, and that short window is fundamental to how we build, ship, and learn.
In January 2026, we are averaging 180 ships per workday – roughly 20 deployments every hour. Conventional wisdom suggests that to increase stability, you must slow down. I believe the opposite. Speed is not the enemy of safety; it is the prerequisite for it. Accumulating code creates risk; shipping small batches minimizes it. Shipping is our company’s heartbeat.
Maintaining this frequency while targeting 99.8+% availability has required over a decade of focused investment in systems, principles, and processes. We protect the integrity of our systems through three layers of defense: an automated pipeline that is simple, reliable, and removes the need for manual intervention, a shipping workflow that promotes ownership and uses guardrails as accelerants, and a recovery model that optimizes for mitigating inevitable failures. Here’s how we’ve built each layer so that velocity is our greatest source of stability.
While our platform consists of various services and frontend applications, I’ll focus here on our Ruby on Rails monolith. It is our core application and the one we deploy most frequently; we also deploy it to three different data‑hosting regions with independent pipelines. Our other services follow similar pipeline principles and safeguards, but the Rails monolith is the clearest example of how we ship at scale.
The automated pipeline is designed to move code from merge to production as fast as possible while enforcing strict safety checks. It is fully automated, and the vast majority of releases require no human intervention—critical for CI/CD at high deployment frequency.
Once an engineer merges code to GitHub, two things happen immediately. First, the build: we compile the Rails application and its dependencies into a deployable asset (a slug) in about four minutes. Second, parallel CI: our test suite runs alongside the build; through extensive optimization, parallelization, and test selection, the vast majority of CI builds finish in under five minutes.
As soon as the slug is built, it’s deployed to a pre‑production environment. CI does not block the progression of the slug to pre‑production. Deploying to pre‑production takes around two minutes. This environment serves no customer traffic, but it is connected to our production datastores, mirrors our production infrastructure variants (e.g., web serving, asynchronous worker), and is configured so that requests exercise the pre‑release code and workers.
Immediately after deployment, we run and await several automated approval gates. We verify that the application boots cleanly on hosts (boot test), confirm the parallel test suite passed (CI check), and execute functional synthetics using Datadog Synthetics on critical flows—such as loading or editing a Fin workflow. If any gate fails, the release is halted and does not go to production.
Once approved, we promote the code to thousands of large virtual machines. A deployment orchestrator triggers these deployments simultaneously, while a decentralized, staggered rollout avoids changing the state of the entire fleet at the same millisecond. Within each machine, a rolling restart mechanism removes a process with old code from the serving path, lets it drain gracefully, and replaces it with a fresh process running the new code. From the moment a deployment starts, first requests are served by new code within roughly two minutes, and the vast majority of the global fleet updates transparently within six minutes. When restarts trigger on every machine, production unblocks so the next deployment can begin.
We treat a stalled pipeline as a high‑priority incident. If the automated system rejects three consecutive release attempts, it pages an on‑call engineer. These are pre‑production blocks, but if the shipping lane stops moving, changes pile up—and our stability relies on building and shipping in small steps. The on‑call’s job is to restore flow so that tiny, safe, frequent updates continue to keep risk low.
Our shipping workflow is built on extreme ownership: tools assist, but the engineer is accountable for quality and the decision to merge. I insist that you are present when you ship. The practical benefit of a 12‑minute deployment cycle is that engineers remain in the zone, focused on the problem they just solved, and ready to validate behavior as it goes live.
A rocket lifts into a luminous sky, a metaphor for shipping code fast without breaking things, where precision, automation, and guardrails power 180 safe deployments a day.
To support this, our deployment system sends Slack notifications the moment code is submitted and as it advances through stages, embeds direct observability links to relevant dashboards and logs in every PR and message, and prompts verification so engineers actively watch the dials and test features in production. It is not acceptable to rely on green builds. You’re expected to watch your change go live and if you’re not prepared to rollback, you’re not prepared to ship. We maintain a no‑blame culture: quick rollbacks and immediate reverts are signs of vigilance and ownership, not failure.
We make extensive use of feature flags to turn deployment into a non‑event. By decoupling deployment (moving code to servers) from release (turning features on), we shrink the blast radius of change. Flags can be enabled for all customers, a specific subset, or disabled for everyone in under 60 seconds through our backend UI. Engineers can group flags into beta features and run phased rollouts; we also ensure flags work consistently across non‑monolith applications. In the past three months, we created over 560 flags—and we actively manage them to avoid permanent complexity.
For complex refactors—especially when behavior should not change—we leverage GitHub Scientist, an open‑source experimentation library. It runs candidate logic (new code) in parallel with existing logic (old code) in production, instruments both paths for result and timing comparisons, and keeps existing behavior user‑visible. That means we can iterate on and validate new code under real load without risking the experience, then switch seamlessly when confident.
When engineers need to go deeper before merging, they can generate a slug and deploy it to a virtual machine, detaching a running production host from the serving path and connecting for manual testing. They can also put a pre‑release slug on a serving machine that handles a small percentage of jobs or web requests. Single‑host validation lets us slice observability to those hosts, compare against the main release, and make low‑level changes safer. Staging is a simulation; production is reality. Testing on a single production host validates assumptions with real‑world data without risking the fleet.
Our recovery model starts from a simple principle: stop monitoring systems; start monitoring outcomes. Traditional monitoring tells you if a server is healthy; we care whether customers are healthy. We rely on heartbeat metrics—vital signs that represent the core value our product provides—such as the rate at which messages and comments are created.
Unlike standard uptime checks, heartbeat metrics are binary in spirit. If message send rates dip below baseline, it does not matter if infrastructure dashboards are green. Down is down, and if customers can’t do their job, uptime percentages are irrelevant. By tracking real‑world success rates as a high‑level signal, we catch subtle degradations that traditional alerting either misses or over‑alerts on.
Because we ship in small, incremental steps and maintain previous releases on our virtual machines, our Time to Recover (TTR) is generally very fast. If a heartbeat metric drops or a critical anomaly is detected right after a ship, the system can trigger an automatic rollback, reverting to the release that was running 20 minutes ago—often restoring service before an engineer responds. For complex issues, engineers can initiate a manual rollback through our deployment UI; doing so also locks the production pipeline to prevent further releases while we investigate and remove problematic code.
Resumption of service is not the end. Every incident prompts an incident review, and we don’t just fix the bug. We ask, “How did the machine allow this to happen?” Then we harden the system so it cannot happen again. This loop—fast shipping, fast recovery, rigorous learning—compounds resilience over time.
This operating model aligns to DORA metrics: high deployment frequency, short lead time for changes, low change failure rate, and rapid time to restore service. It’s a CI/CD and SRE‑informed approach that converts speed into a defensive advantage rather than a liability.
Shipping 180 times a day isn’t a vanity metric; it’s a deliberate choice to protect the customer experience. With a 12‑minute window from code to customer, the feedback loop is tight and engineers retain context—and accountability—for the immediate impact of their work. Maintaining this pace requires more than fast CI; it requires judgment, extreme ownership, disciplined use of feature flags, and a recovery model that monitors outcomes. We rely on human expertise, augmented by these layers of defense, to catch issues before they turn into customer pain. We don’t ship fast despite our need for stability; we ship fast to stay in control of change.
I just tuned into the latest conversation on the upcoming Product at Heart 2026, and it hit on the exact challenges product leaders are navigating right now: curating meaningful content in a world where AI moves faster than our agendas, designing formats that create real connection, and ensuring every minute earns its place. Listening to Petra Wille and Teresa Torres map out the speaker lineup, workshops, and structural shifts, I found myself nodding along—this is the kind of thoughtful curation we need if we want product teams and product leaders to walk away with practical value, not just inspiration.
Listen to this episode on: Spotify | Apple Podcasts
What stood out immediately is the bold move to a single-track conference for 2026. In an era of gen ai hype and endless breakouts, this choice signals clear intent: tighter curation, a shared experience, and less FOMO. The team isn’t carving out a separate AI track—and I love that decision. Their stance is simple and sensible: No AI track—AI will show up everywhere, but not as a siloed topic. The team sees it as part of the everyday toolkit. That mirrors how high-performing, empowered product teams actually work today—AI Strategy and AI workflows are part of the operating system, not a side show.
The keynote lineup is already compelling. Christian Idiodi (SVPG) brings storytelling that turns product principles into habits you can actually use on Monday. Elaine Kasket, cyber-psychologist, exploring digital afterlife and AI replicas, will push us to think more deeply about the human side of our systems. And Teresa Torres will be sharing what she’s learning about AI—exactly the kind of continuous discovery mindset we need as we integrate LLMs into product discovery and delivery.
I’m also thrilled to see roundtables become what they’re calling an “alternative track.” That’s a smart way to deepen learning without fragmenting attention. The best conference ROI I’ve had often comes from targeted small-group conversations—where product trios compare approaches, swap metrics frameworks, or challenge each other’s product strategy assumptions. It’s a design choice that rewards curiosity and builds communities of practice.
We also get a behind-the-scenes look at Teresa’s Maker Studio workshop, where participants will build personal AI workflows. That’s exactly the hands-on, practitioner-first approach teams need right now—less demo theater, more systems that stick. If your roadmap includes integrating LLMs into continuous discovery or augmenting your team’s decision velocity, this kind of guided practice is gold.
The broader workshop slate looks deep and balanced. Expect returning favorites and practical frameworks: Rich Mironov on the realities of product leadership in complex orgs; Büşra’s metrics workshop translating outcomes into action; and an overview of additional workshops from Rich Mironov, Büşra Coşkuner, Marcus Castenfors, and Özlem Yüce. From success metrics to toolkits for product managers, the content spans IC to product management leadership—ideal if you’re stepping into new roles or scaling empowered product teams.
One of the most exciting evolutions is the Product Leadership Event, now a 1.5-day retreat. The format blends talk sessions, mini-workshops, dinners, and small-group excursions (boat rides, improv, etc.), giving leaders time and space to exchange playbooks, stress-test decisions, and build real relationships. It’s capped at 60 attendees (all in product leadership roles) to keep it intimate and useful. As someone who believes in outcomes vs output OKRs and first principles decision making, I appreciate how this structure encourages depth over breadth—and real accountability among peers.
Here are the core takeaways I’m carrying into my own planning: single-track means tighter curation, so every talk has to earn its place. Roundtables are growing into an “alternative track,” offering more ways to engage beyond stage talks. Workshops go deep and meet you where you are—IC, manager, or executive. And the leadership retreat expands to maximize learning from peers, not just from the stage. If you care about product discovery, product strategy, and conference networking that leads to actual business impact, this program looks thoughtfully engineered.
If you’re planning your 2026 calendar—or just curious how conferences evolve alongside the craft—this is a thoughtful walkthrough of what to expect. Come say hi to Teresa and Petra—on stage, at a roundtable, or somewhere in the hallway conversations that make these events memorable.
For more context and resources mentioned, explore: Product at Heart, Arne Kittler, Mind the Product, Christian Idiodi of Silicon Valley Product Group, Elaine Kasket, House of Beautiful Business, The 7 Habits of Highly Effective People by Stephen Covey, Rich Mironov, Marty Cagan, Claude Code, Codex by OpenAI, Marcus Castenfors, Büşra Coşkuner and her Success Metrics: A Playbook for Product Managers, Özlem Yüce’s Essential Toolkit for Product Managers, Petra’s Product Leadership Wheel (PLwheel), and Netlight.
Follow Teresa Torres: https://ProductTalk.org
Follow Petra Wille: https://Petra-Wille.com
Full transcripts are only available for paid subscribers.
I set out to create a lightweight, high-impact “Pendo Wrapped” experience for our users—and I did it in under 10 minutes with Pendo MCP. As a VP of Product Management, I’m constantly looking for fast, pragmatic ways to turn product insights into moments that drive engagement. This experiment was about transforming raw analytics into a concise, celebratory year‑in‑review that motivates customers to explore more value.
When I say “Pendo Wrapped,” I mean a simple, narrative-style summary of usage highlights: what got adopted, which moments mattered, and where value showed up most clearly. Framed well, that story reinforces product‑led growth by reminding users why they chose us, nudging them toward the next best action, and strengthening activation and retention without heavy development work.
My approach was straightforward: define a clear objective (celebrate milestones and prompt the next step), choose a focused set of metrics (adoption, engagement, and activation), and target relevant segments. Then I layered the narrative on top of existing analytics using in‑app guides and product tours to deliver the experience where it matters most—inside the product.
The reason it took minutes, not hours, is that Pendo MCP let me work with what we already had—segments, saved reports, and proven guide templates—so I could spend time on the story, not the scaffolding. No code, minimal configuration, and a crisp call to action made it feel polished without being heavy.
Increase revenue, cut costs, and reduce risk with Pendo’s Software Experience Management platform. Optimize the entire software experience to drive adoption and improve engagement.
If you want to replicate this quickly, start by selecting one user segment and three metrics that matter to them, write a two‑sentence narrative that connects those metrics to outcomes, and ship a short in‑app guide with a single, purposeful CTA. That’s enough to deliver a personalized year‑in‑review feel and spark immediate exploration—no new infrastructure required.
What surprised me most was how a small, story‑driven touch created outsized alignment across customers and internal teams. It turned analytics into advocacy, reminded our users of the value they’re already getting, and opened the door to deeper adoption. If you’re pursuing product‑led growth, a fast “Pendo Wrapped” is one of the highest‑leverage experiments you can run this week.