Executive hiring is one of those rare decisions that can bend a company’s trajectory. In my role leading product management at a high-growth SaaS company, I’ve seen the difference between a leader who compounds value and one who quietly drains momentum. That’s why I was eager to examine what actually makes (or breaks) these bets, and to share a practical lens you can use to improve executive hiring outcomes.
I sat down with Eeke de Milliano for a focused conversation on the realities of executive hiring, leadership transitions, and measuring success. We dig into the “buy or build a leader” decision, how to avoid common red flags, and what it takes to set executives up to thrive in hyper-growth environments.
Eeke de Milliano is the Head of Global Product at Stripe, helping drive innovation and success in the company’s product line. Before this role, she was Head of Product at Retool and co-founded Constellate. Eeke previously spent 6 years as Product Lead at Stripe, working with the company during their hyper-growth era.
In today’s episode, we discuss how to rigorously assess executive hiring fit, including the challenges companies face when hiring new executives and the most common red flags and pitfalls I see teams miss under time pressure. We also explore practical advice for measuring success, especially when outcomes vs output get muddled in the first 90–180 days.
A recurring theme for me is that learning your own strengths is an underrated piece of the process. If you don’t understand the leadership leverage you already have on the team, you’ll over-hire for breadth or under-hire for depth. Great executive hiring clarifies the complementary edge you need—then measures it.
On the buy vs build decision: early signals matter. If you’re “buying” an external leader, pre-align on scope, authority, and what great looks like before day one. If you’re “building” from within, design a clear on-ramp and operating cadence so the leader can scale without drowning. In both cases, my mental model is to instrument leading indicators (team health, decision velocity, stakeholder trust) well before lagging business metrics fully show up.
Two red flags I always watch for: first, leaders who default to playbooks without interrogating context; second, leaders who cannot articulate how they measure success beyond activity and output. In hyper-growth, pattern-matching is useful—but uncalibrated pattern-matching is dangerous.
The human dynamics matter just as much as the strategy. What creates dysfunctional exec relationships is often misaligned interfaces: unclear decision rights, overlapping charters, or incentives that reward local maxima. High-functioning executive teams are like parents—a united front in public, with candid debate in private, anchored to shared principles and measurable outcomes.
Influence starts with clarity. That’s the throughline I return to when I’m coaching founders and product leaders, and it’s why I keep revisiting the frameworks that sharpen how we communicate, persuade, and lead under pressure. Recently, I synthesized several powerful ideas that map directly to the realities of startup execution and product management leadership—ideas I’ve seen transform how teams align, how roadmaps get prioritized, and how outcomes (not outputs) become the default.
Wes Kao is an executive coach, advisor, and instructor, best known for her newsletter on high-impact communication, and for co-founding course platform Maven and the AltMBA with Seth Godin. Across her career, Wes has helped leaders communicate with clarity and conviction, whether it’s rallying a team, pitching investors, or influencing stakeholders.
From a founder’s seat, or in a VP of Product role, the question is always the same: How do I become more persuasive, play to my strengths, and raise the bar for myself and my team? Here’s how I’ve put these principles into practice—and what I recommend.
First, I rely on a “personality-message fit” mindset. The goal isn’t to copy someone else’s style; it’s to package your message so it amplifies your natural strengths. If you’re analytical, use structure and crisp logic. If you’re a storyteller, build vivid narrative arcs around data. In product reviews, I’ve seen the same idea land (or fall flat) entirely based on whether the delivery aligned with the speaker’s authentic style.
Charisma is often misunderstood. It’s not about volume or showmanship—it’s about presence, intent, and calibration. Authenticity isn’t performative; it’s the consistency between your values and your behavior. In practice, that looks like stating trade-offs plainly, owning uncertainty, and being consistent in how you make decisions. Teams don’t need theatrics; they need reliability and conviction.
Clarity in communication is the single highest ROI skill in leadership. Start with your ideal outcome: what do you want your audience to think, feel, and do? Then reverse-engineer your message. I frame every major communication around outcomes vs output, just as I would with OKRs. This shifts the discussion from activity (“we shipped”) to impact (“we moved this metric”). When the outcome is explicit, the argument becomes self-reinforcing—and far more persuasive.
Power dynamics shape how your message is received. Different stakeholders hear the same words through very different lenses. In board updates and investor pitches, calibrate not just content but posture: what decision are you asking for, what risks are you proactively naming, and what constraints are you strategically acknowledging? Influence often hinges less on brilliance and more on aligning incentives and expectations.
On the perennial question—should you work on weaknesses or double down on strengths?—I’ve found the most durable gains come from role-strength fit. Eliminate spiky weaknesses that are career-limiting (for example, unreliable follow-through), but invest disproportionately in the strengths that create asymmetric value. This is how leaders move from competent generalists to compelling, irreplaceable operators.
Effective self-reflection is a force multiplier. A deceptively powerful prompt I use with teams is: What do you resent? Resentment often points to violated boundaries, unclear roles, or recurring misalignments. Surface it, re-contract responsibilities, and redesign rituals. This isn’t soft work; it’s operational hygiene that protects focus and velocity.
When someone tells you to “be more strategic,” they’re rarely asking for more slideware. They want clearer time horizons, sharper prioritization, and better sequencing. I lean on stack ranking to make trade-offs explicit. If everything is a priority, nothing is. Show what’s first, what’s second, and what you’re explicitly saying no to—and why. Strategy is the discipline of exclusion.
Two ideas I return to often: how formative programs start and how craft gets defined. The origin story behind community-driven learning like the AltMBA reminds me that great products are built with a point of view and a tight feedback loop. Defining your craft—naming it, practicing it, and holding a higher standard for it—creates a culture where excellence becomes normal, not exceptional.
If you’re a founder or product leader, a practical way to apply all of this next week is simple: decide the outcome, tailor the message to your natural style, acknowledge power dynamics up front, and stack rank your asks. Then, debrief with the team: What landed? What didn’t? What will we do differently next time? Communication is a craft, and like any craft, standards rise with deliberate practice.
Your teams can already generate briefs, code, prototypes, and research summaries in minutes. The harder question is whether that speed improves a customer outcome or merely fills the delivery system with more plausible work.
If you are deciding how to organize around AI, do not begin with a new title or a mandate to use a model in every workflow. Begin with accountability, evidence, and shared infrastructure. A useful AI-native operating model makes teams faster at learning while making failures easier to detect, contain, and correct.
Build around an outcome squad, not an AI request queue
An AI-native team is not defined by how many AI tools it uses. It is defined by how it turns customer signals into decisions, experiments, production changes, and measurable learning. A team building a conventional workflow can operate in an AI-native way. A team shipping an AI feature can still operate through slow handoffs, weak evidence, and unclear ownership.
Keep the autonomous product squad as the main unit of accountability. Give it a customer or business outcome, not a feature commitment. Surround it with an AI platform layer that provides reusable model access, evaluation tooling, observability, data controls, and safety mechanisms. This outcome-squad-plus-platform topology lets teams explore locally without rebuilding critical infrastructure in every squad.
The leadership move is to centralize intent rather than every decision. Strategy, outcome definitions, data boundaries, quality expectations, and escalation rules should be common. Teams should remain free to choose the solution. Without that balance, autonomy creates fragmented experiences; with it, shared constraints make local decisions more coherent.
Key takeaways
Make the squad accountable for a customer or business outcome, not AI adoption or a list of features.
Centralize reusable infrastructure, evaluation standards, data rules, and escalation paths.
Use AI to expand options, synthesize evidence, create test artifacts, and critique work. Keep customer validation and final accountability with people.
Measure product impact and AI-system quality separately. Neither can substitute for the other.
Prove the operating model through a bounded 90-day rollout before reorganizing the wider product organization.
Set decision rights before you add agents and automation
Most operating-model confusion is really decision-rights confusion. A central AI group starts choosing product priorities. Product squads select models without understanding data or cost constraints. A risk committee reviews every change manually. Each group is trying to help, but the result is either a bottleneck or unmanaged duplication.
Layer
Decides and owns
Should not decide
Company and product leadership
Strategy, outcome portfolio, investment boundaries, risk posture, and the conditions for scaling
The squad’s day-to-day solution choices
Outcome squad
Problem framing, hypotheses, customer evidence, experience design, solution choice, rollout, adoption, and the assigned outcome
Company-wide model access rules or shared infrastructure standards
AI platform team
Approved model access, shared gateways, evaluation infrastructure, observability, version tracking, latency controls, and cost controls
Which customer problem deserves priority
Risk and governance owners
Data classifications, prohibited uses, required reviews, red-team expectations, auditability, and escalation paths
Routine implementation details inside established boundaries
Community of practice
Reusable prompts, patterns, model cards, examples, and lessons that improve craft across squads
Binding product priorities or exceptions to governance rules
This arrangement keeps the platform team from becoming an AI feature factory. Its customer is the product organization, and its job is to make the safe path the easy path. The product squad still owns whether a capability is useful, usable, viable, and valuable to the customer.
Roles inside the squad also need sharper expectations. You may not need every specialist assigned full time, but you do need every responsibility covered:
Product management owns the outcome, problem framing, riskiest assumptions, sequencing of bets, and the quality of the decision. A model may draft the brief; it cannot own the commitment.
Design owns how uncertainty is communicated and controlled. That includes editable results, clear transitions from draft to commit, useful recovery paths, and confidence or reference cues where the experience supports them.
Engineering owns the whole system around the model: integration, data flow, evaluation harnesses, reliability, performance, fallbacks, versioning, and production observability.
Data or evaluation partners define target tasks, maintain evaluation data, protect metric integrity, and separate a model-quality change from a product-outcome change.
Forward deployed engineers or equivalent customer-facing technical partners shorten the distance between the squad and real customer environments, especially when integrations and edge cases determine whether the product works.
Give those roles one shared decision brief. It should name the desired outcome and current baseline, target user and task, riskiest assumptions, customer evidence, model and data choices, offline evaluation, online success signal, cost and latency budgets, safety boundaries, fallback, rollout plan, and human owner. Keep model, prompt, and evaluation versions attached to the decision so the team can reproduce what it approved.
A community of practice is useful only when it changes work. Convert shared learning into a problem-framing exercise, a prototype, a customer check, and an update to the decision log. That learn-apply-record cycle builds common language without turning enablement into a document library that nobody uses.
Run four connected learning loops instead of a delivery chain
A conventional delivery chain moves work from research to product to design to engineering to support. Information degrades at every handoff, and support learns about failure only after release. An AI-native operating model closes those gaps with four connected loops.
Signal loop: Combine customer interviews, support conversations, behavioral data, sales context, and operational events. Use AI to cluster, summarize, and retrieve evidence, but keep links to the underlying material. The output is a prioritized problem with traceable evidence, not a generated feature request.
Discovery loop: Use AI to widen the option set, expose assumptions, draft research questions, create experiment variants, and simulate edge cases. Then validate the important claims with customers. AI is good at helping you explore breadth; customers still determine whether the problem and proposed value are real.
Evidence loop: Build a thin vertical slice that includes the interaction, model behavior, constrained output, representative data, and lightweight evaluators. Test the target task rather than presenting an isolated model demo. A technically impressive response that does not help the user finish the job is failed product evidence.
Production loop: Release in a bounded way, observe product and model behavior, capture failure categories, and route uncertain cases to a safe fallback or a person. Feed production failures and support cases back into the evaluation set and the next discovery cycle.
Give AI a bounded role inside each loop. It can act as synthesizer, option generator, prototype builder, editor, reviewer, or skeptic. Those roles are more useful than an open-ended instruction to act as the product manager. Planning with grounded context and using separate reviewer roles can expose gaps without pretending that generated critique is independent customer evidence.
Cadence keeps the loops connected. A practical pattern is a weekly review of leading indicators, a monthly examination of lagging outcomes, and a quarterly retrospective on the quality of the OKRs and bets. The purpose of that weekly, monthly, and quarterly rhythm is not to produce three status meetings. It is to make different kinds of evidence visible at the speed at which they become meaningful.
In the weekly review, ask what changed, which assumption became weaker, which failure pattern grew, and what the team will stop or test next. In the monthly review, decide whether leading activity is translating into customer or business behavior. In the quarterly retrospective, examine whether the objective, metric definitions, time horizon, and portfolio of bets were sound.
Keep the reasoning legible between meetings. Prompts, hypotheses, constraints, evaluation results, and decision logs should be living artifacts with named owners. Making assumptions and decisions explicit allows autonomy to scale because another person can understand not just what changed, but why.
Use a two-level scorecard: product outcome and system quality
AI teams often mix product metrics and model metrics into one dashboard. That makes weak results easy to rationalize. A model can score well offline while customers ignore the experience. Adoption can rise while latency, cost, bias, or failure severity makes the feature unsustainable. Keep two levels of evidence and require both to be healthy.
Level one: did customer or business behavior change?
Start with the outcome the squad owns. It might be improved activation, reduced onboarding time to first value, greater use of a valuable workflow, higher conversion, stronger retention, or lower cost to serve. The exact choice depends on the problem. It should describe an effect, not an activity such as launching a copilot, generating more artifacts, or completing an integration.
Objective: the meaningful customer or business change the team is pursuing.
Key Result: the operationally defined outcome metric, including the population and time horizon.
Leading behavior: the earlier behavior that should move if the hypothesis is working.
Baseline: the current state measured before the AI-assisted change.
Decision rule: what evidence will cause the team to continue, change, stop, or expand the bet.
Instrument the outcome before scaling the solution. If the event schema or metric definition changes during the test, annotate it and avoid treating the series as continuous. Reliable event definitions and product analytics are part of outcome ownership, not cleanup work after launch.
Level two: is the AI system fit for the target task?
Define target tasks and build a golden evaluation set before an online experiment. The set should have provenance, expected criteria, meaningful edge cases, and examples of unacceptable behavior. It is not a collection of polished demo prompts. It is a repeatable test of the situations the product is expected to handle.
The relevant measures include task success, user confidence, time to first value, latency, and cost per resolution. Add the dimensions demanded by the risk: privacy, fairness, accessibility, explainability, secure data handling, and success of the human escalation path. Track model and prompt versions so a score can be reproduced after either changes.
Do not borrow a universal quality threshold. The acceptable threshold depends on the task, the consequence of a wrong result, the visibility of the uncertainty, and the strength of the fallback. A drafting assistant with easy undo has a different failure boundary from an automated action that changes customer data.
Turn governance into release questions the squad can answer:
Is every data path allowed for this use, with unnecessary personal data removed?
Does the evaluation set represent the intended tasks and important edge cases?
Do pinned model and prompt versions meet the agreed quality threshold?
Are latency and cost within the budgets required for the experience and business model?
Can the user inspect, edit, undo, or decline the output where control is necessary?
Does the fallback work when the model is unavailable, uncertain, or outside its supported scope?
Can telemetry identify the product version, model version, outcome, and failure category?
Is there a named owner and escalation path for drift, harmful output, or a data incident?
If the team cannot answer a question, the work may remain a prototype, but it is not ready for an uncontrolled production release. This is why an AI product needs model-level service expectations alongside product-level expectations. Product value does not excuse an unsafe system, and a well-scoring model does not prove product value.
Use the first 90 days to prove the system, not perform a reorganization
Do not redraw the entire org chart because several teams have successful demos. Use a bounded operating-model trial. A practical 90-day starter plan begins with two high-signal use cases where latency, cost, and safety are manageable, supported by the minimum reusable platform capabilities the squads need.
Select the use cases. Choose problems with a clear user, repeated target task, observable outcome, accessible evidence, and a containable failure mode. Avoid starting with a vague mandate such as making the product intelligent.
Charter the pod. Assign product, design, engineering, and a data or evaluation partner. Add a forward deployed engineer when customer environments and integrations are central to the risk. Name the outcome owner and the production escalation owner.
Write the evidence contract. Record the baseline, outcome, leading behavior, target tasks, riskiest assumptions, evaluation rubric, quality threshold, latency and cost budgets, safety boundaries, and decision rule before polishing the experience.
Build a thin vertical slice. Include the real interaction, representative data, model behavior, evaluation harness, telemetry, and fallback. The purpose is to learn whether the complete path works, not to maximize feature coverage.
Release in stages. Start with an internal workflow or another low-risk, bounded setting when appropriate. Expand only as the evidence and operational confidence improve. Staged adoption is especially valuable when the team is still learning how to classify and respond to failures.
Codify what repeats. Move reusable model access, evaluation tooling, observability, prompt or pattern libraries, model cards, and safety controls into the platform or community of practice. Keep problem-specific logic with the outcome squad.
At the end of the trial, judge the operating system, not the volume of AI output. The squad should be able to show whether the outcome changed or the hypothesis was invalidated, rerun the evaluation, identify the versions behind a result, observe production failures, execute the fallback, and explain what became reusable. If all you have is faster drafting and a compelling demo, do not scale the topology yet.
My test is simple: can the team explain the customer change it owns, reproduce the evidence behind its decision, and contain a bad result without waiting for an AI expert to rescue it? If not, the organization has adopted tools, not an AI-native operating model.
Your first move can stay small: choose one team, one consequential outcome, and one disciplined discovery cycle. Write the target task, failure boundary, evidence, and human owner before choosing a model. More tooling will not repair ambiguous accountability; it will only make the ambiguity move faster.
I recently tuned into a powerful conversation where Petra Wille sits down with Teresa Torres to unpack a major shift in product learning: moving from purely instructor-led cohort courses to offering on-demand options. As someone leading product management at HighLevel, I’ve wrestled with the same trade-offs—how to scale product discovery skills without compromising depth, community, or outcomes—and this discussion hit home.
What stood out immediately is how Teresa shares why she resisted on-demand for so long, how deliberate practice has always been at the heart of her teaching, and what finally changed her mind. That framing matters. In my experience, deliberate practice is the backbone of real capability building: clear goals, targeted reps, tight feedback loops, and sustained reflection. It’s how we turn continuous discovery from a concept into a craft product teams can reliably execute.
We also dug into the trade-offs between cohort-based vs. on-demand learning. Cohorts bring structure, accountability, and shared language—critical for team-based behavior change. On-demand learning offers flexibility, reach, and just-in-time reinforcement—key for busy product managers, designers, and engineers balancing roadmaps and research. The challenge is not choosing one over the other, but architecting a blended learning system that preserves the rigor of cohorts while using on-demand to extend practice, sustain momentum, and meet learners where they are.
That’s where technology becomes a force multiplier. From AI-powered interview coaches to microlearning formats, we explored how AI can support behavior change and skill building without losing the human element. I’ve seen the same in my teams: when AI provides structured, rubric-based feedback on interviews, assumptions, or opportunity framing, people get expert-quality guidance at scale. Used well, this shortens the feedback cycle and increases the number of high-quality reps—without displacing peer critique or expert coaching.
Microlearning and problem sets deserve special attention. Short, focused practice—think “Duolingo” for product discovery—helps teams internalize patterns like crafting unbiased interview prompts, distinguishing signals from stories, or iterating on interview flow. Combined with spaced repetition, these formats build muscle memory for critical skills, so discovery doesn’t stall the moment the cohort ends. In other words, on-demand isn’t a downgrade; with the right scaffolding, it can be a durability upgrade.
Equally important, why AI should augment—not replace—human connection in discovery. No model can substitute for the trust you build with customers, the judgment you develop through messy real-world conversations, or the creative tension of team debate. My takeaway: use AI to accelerate preparation, evaluation, and deliberate practice; rely on humans for empathy, ethics, sense-making, and decision quality.
If you’ve ever wondered how to balance flexibility, structure, and deliberate practice in product learning—or you’re just curious how AI might reshape how we build skills—this conversation is for you.
Listen to this episode on: Spotify | Apple Podcasts
Explore the resources and links mentioned: Follow Teresa Torres: https://ProductTalk.org; Follow Petra Wille: https://Petra-Wille.com; Product Talk Academy; Continuous Interviewing course by Teresa Torres; Story-Based Customer Interviews On Demand course by Teresa; Customer Recruiting for Continuous Discovery On Demand course by Teresa; Duolingo; Teresa’s Interview Coach; AI as a Strategic Thought Partner with UX Implications podcast episode; Teresa’s socials: X, LinkedIn, Youtube, Product Talk Blog.
I’d love to hear your perspective. How are you blending cohort-based learning, on-demand practice, and AI coaching on your product teams? Drop your thoughts in the comments—let’s compare notes on what’s working.
I’ve been deep in the work of building practical, agentic capabilities into AI products, so this story about Alyx immediately resonated with me. It’s a rare, clear-eyed look at what it actually takes to ship a useful AI agent inside an AI platform—while using that same platform to build, test, and continuously improve the agent.
What does it really take to build an AI agent inside an AI platform—especially when you’re using that same platform to build the agent?
Listening to SallyAnn DeLucia (Director of Product at Arize) and Jack Zhou (Staff Engineer at Arize) unpack Alyx—the AI agent that helps teams debug, optimize, and evaluate AI applications—I recognized playbooks I trust: start scrappy, dogfood relentlessly, build intuition with real users, and systematize improvement with thoughtful evals.
Their early phase looked exactly like the messy reality many of us try to hide: Jupyter notebooks, hacked-together web apps, and weekly dogfooding sessions with their customer success team. That’s where patterns emerged, confidence was built, and the highest-leverage skills for the agent were prioritized. It’s a reminder that “vibe checks” matter at first—but you must quickly graduate to measurable, repeatable learning loops.
In my experience, the foundation of GenAI product quality is threefold: tracing, observability, and evals. They reached the same conclusion—defining traces across tool calls and sessions, creating observability into model behavior, and layering evals to compare both micro-decisions and system-level outcomes. That discipline converts hunches into evidence and makes agent behavior improvable, not mysterious.
What stood out was how cross-functional, boundary-spanning teams made the difference. Customer success engineers surfaced repeatable workflows. Product framed early skills. Engineering wrapped prototype tools into something coherent. Using their own platform to build Alyx accelerated intuition and de-risked launch. That’s the product loop I aim to cultivate: close to customers, close to data, and fast to learn.
As Alyx matures, the next step is moving from “on rails” workflows to more autonomous, agentic planning loops. That evolution requires stronger tool design, richer feedback signals, and evals that reflect end-to-end user value. It’s exactly the shift I expect across GenAI: from scripted assistants to adaptive systems that reason, plan, and act with guardrails.
Listen to this episode on: Spotify | Apple Podcasts
Guests:
SallyAnn DeLucia, Director of Product, Arize
Jack Zhou, Staff Engineer, Arize
In this episode, we cover:
What tracing, observability, and evals really mean in GenAI applications
How Arize used its own platform to build Alyx, its AI agent
The role of customer success engineers in surfacing repeatable workflows
Why early prototyping looked like messy notebooks and hacked-together local apps
How dogfooding shaped Alyx’s evolution and built confidence for launch
Why evals start messy, and how Arize layered evals across tool calls, sessions, and system-level decisions
The importance of cross-functional, boundary-spanning teams in building AI products
What’s next for Alyx: moving from “on rails” workflows to more autonomous, agentic planning loops
My takeaways for product teams building GenAI agents are simple and hard: design tools with observability in mind; operationalize evals early even if they’re imperfect; embed customer-facing engineers in the loop to capture real workflows; and keep the first skills narrow, high-impact, and testable. If your team can move from demos to disciplined measurement quickly, you’ll accelerate product-market fit.
Resources & Links
Arize AI — Sign up for a free account and try Alex
Arize Blog — Lessons learned from building AI products
Maven AI Evals Course — The course Teresa took to learn about evals (Get 35% off with Teresa’s affiliate link)
Cursor — The AI-powered code editor used by the Arize engineering team
DataDog — For understanding application traces
OpenAI GPT Models — GPT-3.5, GPT-4, and newer models used in early and current versions of Alex
Jupyter Notebooks — A tool for combining code, data, and notes, used in Arise’s prototyping
Axial Coding Method by Hamel Husain — A framework for analyzing data and designing evals
Chapters
00:00 Introduction to Sally Ann and Jack
01:08 Overview of Arize.ai and Its Core Components
01:44 Deep Dive into Tracing, Observability, and Evals
03:56 Introduction to Alyx: Arize's AI Agent
04:15 The Genesis and Evolution of Alyx
08:51 Challenges and Solutions in Building Alyx
24:33 Prototyping and Early Development of Alyx
26:22 Exploring the Power of Coding Notebooks
26:51 Early Experiments with Alyx
27:59 Challenges with Real Data
29:20 Internal Testing and Dogfooding
31:55 The Importance of Evals
35:16 Developing Custom Evals
43:09 Future Plans for Alyx
47:59 How to Get Started with Alyx
Full Transcript
Podcast transcripts are only available to paid subscribers.
If you’re building in GenAI right now, this conversation offers a pragmatic blueprint. Start with high-signal workflows, turn qualitative insights into quantitative evals, and use tracing plus observability to make agents debuggable. That’s how scrappy prototypes become reliable systems. And if you want a tangible example, “47:59 How to Get Started with Alyx” is a helpful on-ramp.
I recently spent time with an episode of All Things Product that hit especially hard as we head into year-end: Petra Wille and Teresa Torres ask, “What do you want to be known for in your work?” As someone leading product management and building high-performing teams, I regularly bring this question into my Q4 conversations. It’s a powerful lens for product management leadership, career transitions, and how we show up for our customers and colleagues.
Listen to this episode on: Spotify | Apple Podcasts
In this conversation, I appreciated how clearly they unpack the nuances of impact, craft, personal brand, and values—and how those ideas shape the footprints we leave in teams, organizations, and the broader product community. Their stories and lessons learned are equal parts relatable and practical, which is exactly what we need when we’re balancing execution with reflection.
Let’s talk about “legacy.” The word can feel loaded—big, vague, and distant. I reframe it with my teams into a question we can act on now: What meaningful change did we enable for customers and our organization this quarter, and what do we want colleagues to remember about how we did it? That framing keeps us grounded in outcomes and behaviors, not just lofty aspirations.
The distinction between impact and craft is central. Impact is the difference our work makes—what changes because of our decisions. Craft is what we hone for intrinsic reward—our product discovery techniques, decision-making frameworks, and communication muscles. Early in my career, I over-indexed on impact metrics and under-invested in craft. I shipped value, but I wasn’t building the repeatable habits that elevate a product creator for the long haul. Over time, I learned that craft compounds—and it pays dividends in both product-market fit lessons and leadership credibility.
Personal brand and values also matter more than many of us admit. When the pressure is on, people remember how we decide, how we communicate trade-offs, and how consistently we anchor on customer value. I want to be known for rigorous product discovery, clarity under uncertainty, and the integrity to say “no” when it protects long-term outcomes. Those cues travel fast across an organization and quietly define our leadership legacy.
Feedback gaps can reveal blind spots—and we all have them. I proactively create multiple feedback loops: structured 1:1s, skip-levels, stakeholder debriefs after key product decisions, and customer touchpoints. I specifically ask for disconfirming evidence—what am I missing, where did my decision-making create friction, and how might I simplify? Weekly customer learning is non-negotiable for me; it keeps the team grounded and accelerates product discovery. If you need a starting point, Teresa’s work on weekly customer interviews is a solid playbook: Customer Interviews: How to Recruit, What to Ask, and How to Synthesize What You Learn.
Here are the prompts I’m using with my team for Q4 reflection. Why “legacy” can feel loaded—and better ways to frame the question. The difference between impact (what changes because of your work) and craft (what you hone for intrinsic reward). How personal brand and values influence what colleagues remember about you. Why feedback gaps can reveal blind spots—and how to proactively seek better input. Reflection prompts to carry into your Q4 (and beyond). I encourage folks to journal on these, then bring two concrete actions into our next planning cycle.
If you’re thinking about your own growth, preparing for career transitions, or simply curious how others reflect on their product practice, this episode offers both inspiration and pragmatic takeaways. I’m weaving these themes into our planning and calibrations because reflection is a force multiplier—it sharpens strategy, strengthens culture, and ultimately improves customer outcomes.
Follow Teresa Torres: https://ProductTalk.org
Follow Petra Wille: https://Petra-Wille.com
Mentioned in the episode: Petra’s Thought-Provoking Questions to Prompt Your End-of-Year Reflection
Mentioned in the episode: Xing
Mentioned in the episode: Teresa’s work on weekly customer interviews: Customer Interviews: How to Recruit, What to Ask, and How to Synthesize What You Learn
Mentioned in the episode: Petra’s guide: The Product Leader’s Guide to Giving Feedback
Join the conversation with me: What do you want to be known for in your product work this coming year? Share your thoughts below and let’s learn from one another.
Full Transcript
Full transcripts are only available for paid subscribers.
What if my next teammate wasn’t a human hire but an AI coworker—one that can answer support tickets, process invoices, or draft emails—and my non-technical colleagues could teach it how to do those tasks themselves? That is the practical promise behind Neople’s “digital coworkers,” and it’s a shift I’ve been anticipating across customer support and operations: AI that blends the reliability of automation with the empathy and flexibility of modern agents.
Listen to this episode on: Spotify | Apple Podcasts
In exploring how Neople builds and deploys these agents, I appreciated the clarity from Seyna Diop (Chief Product Officer), Job Nijenhuis (CTO & Co-founder), and Christos C. (Lead Design Engineer). They walked through the evolution from simple response suggestions to fully autonomous customer service agents, the architecture powering their conversational workflow builder, and the evaluation loops that include customers as part of the quality process. As a product leader, this resonates deeply with how I approach product discovery, product management leadership, and go-to-market enablement for gen AI in customer support.
Moved from “LLMs will solve everything” to finding the right balance between code, agents, and guardrails
Designed evals that run in production to detect hallucinations before an email ever reaches a customer
Helped non-technical users build automations conversationally — and taught them decomposition along the way
Turned customers’ feedback loops into eval pipelines that improve product quality over time
From a customer support AI strategy standpoint, these choices are decisive. I’ve seen teams struggle when they lead with model horsepower rather than a layered system of retrieval, business logic, and guardrails. The Neople approach aligns with what I’ve practiced: set clear task boundaries, ground responses in trustworthy knowledge, and instrument every step so evals reflect real-world behaviors—not just lab benchmarks.
I also love the emphasis on conversational building for non-technical users. Teaching decomposition implicitly—by guiding users to break down tasks into steps—accelerates adoption and reduces support burden. It’s a practical onramp to gen ai for product prototyping: let users design flows in natural language, then progressively reveal structure, data dependencies, and edge cases as they iterate.
Scaling these agents “where you work” requires deep integrations and visibility. We discussed how the team makes agents feel native in existing tools, maintains “Visibility and Transparency in Neople Responses,” and keeps humans in the loop for sensitive workflows. That transparency is non-negotiable: if an AI is going to act on behalf of my team, I want traceable reasoning, source citations, and reversible actions.
Quality, of course, is where most agent initiatives rise or fall. Running evals in production, detecting hallucinations before messages reach customers, and converting feedback loops into continuous improvement pipelines—this is exactly how you earn trust at scale. It mirrors how I deploy forward deployed engineers with customers: ship intentional constraints, watch real usage, and feed structured signals back into the system to compound quality.
The roadmap beyond support is equally compelling. Once agents demonstrate reliability in high-volume, high-variance environments like customer support, adjacent functions—sales ops, finance ops, and onboarding—become reachable. That’s a credible path to product-market fit lessons: start where the pain is sharp and measurable, prove value with operational KPIs, then expand horizontally with guardrails intact.
For those who want to go deeper, the conversation spans the origin story and real-world applications, through “Integrations and Scaling: Making Neople Work Everywhere,” into techniques for “Ensuring Quality in Customer Knowledge Bases,” “Customer Feedback and Error Analysis,” and the “Technical Details of Knowledge Retrieval.” It also touches “Embedding Strategies and Document Types,” “Automation and Actions in Customer Support,” and “Expanding Beyond Customer Support.” It’s a comprehensive, pragmatic tour of what it takes to make AI coworkers production-ready.
Neople.io – Learn more about Neople’s AI coworkers
The Joy Lab – Neople’s community and podcast about AI and work
If you’re piloting agents today, my recommendations are straightforward: choose a single, high-impact use case; define guardrails and “safe failure” modes; stand up production evals that mirror customer outcomes; and make transparency a default. With that foundation, AI coworkers can become dependable teammates—ones your non-technical colleagues can actually work with, trust, and improve.
Product-market fit in the GenAI era is elusive because both the technology surface area and user expectations change weekly. That’s why Braintrust caught my eye: they set a relentless quality bar, delayed go-to-market on purpose, and used real-world evaluation pain to shape an end-to-end platform for building AI apps. In my work leading product management teams, I recognize this pattern as the difference between shipping demos and shipping durable value.
Context matters. Ankur Goyal’s journey runs through MemSQL (now SingleStore), Impira, and Figma. Working with high-bar users at MemSQL forged a bias toward precision, performance, and reliability—traits that translate directly to AI infrastructure where flaky evals and brittle prompts can quietly erode trust. When you build for exacting users early, the feedback loop is unforgiving—and that’s a gift.
The throughline is quality. Great software often comes from a place of “paranoia”—the productive kind that compels us to fail proofs, harden edge cases, and verify outcomes under load. In AI product development, that paranoia shows up as rigorous evals, clear data contracts, reproducibility, and measured rollouts. It’s not glamorous, but it’s how you earn compounding trust with builders and operators.
Recruiting is strategy. The trick to recruiting well is selecting for taste, curiosity, and ownership—people who elevate the craft and sweat the engineering details. In AI-heavy products, I’ve had the most success with forward deployed engineers who live with users long enough to discover the non-obvious constraints that should drive the roadmap. Taste plus proximity beats velocity without context.
Impulse control creates leverage. Braintrust delayed go-to-market, which is counterintuitive when the market is hot. But in a new category, premature scaling yields fake signals. The better move is to tighten the loop: instrument the “prompt playground,” pressure-test evals, validate the inner loop of building AI apps, and only then broaden access. When the core interaction is right, growth compounds; when it’s off, every feature feels like a workaround.
Figma-era frustrations with evals became the opportunity. Anyone who has tried to standardize AI evaluations across prompts, models, and datasets knows how quickly the surface area explodes. Converting that frustration into Braintrust’s product thesis—reliable, end-to-end workflows for AI app development—speaks to a classic product discovery principle: go deep on a painful, persistent job-to-be-done before you go broad.
How to recognize a real market opportunity: look for high-frequency workflows with measurable outcomes, teams who already duct-tape solutions, and buyers who have the budget and urgency to pull the product in. When you see repeatable pull from discerning users—and you can demonstrate quality with transparent evals—you’re approaching true PMF rather than narrative fit.
Inside the first six months, the right posture is deliberate focus. For a platform like Braintrust, that means obsessing over the developer inner loop: data in, prompt iteration, eval rigor, versioning, approvals, and productionization. The “prompt playground” must evolve from experimentation to governance, so teams can move from clever demos to reliable deployments with confidence.
AI continues to reshape the platform’s future. As model ecosystems shift (OpenAI and beyond) and the data plane sprawls (Databricks, Snowflake), developers want a unified surface to build, evaluate, and ship. Integrations with familiar tools like Airtable, Coda, Zapier, and Figma lower adoption friction by meeting teams where they already work, while enterprise-grade controls unlock buyers at the scale of Goldman Sachs.
The cultural choices matter as much as the code. Make big bets with extreme clarity, or don’t make them at all. Stay mission-driven when novelty tempts distraction. Write down the customer promise and keep it tight. Hiring mistakes—especially around quality, curiosity, and ownership—compound quickly in AI product teams, so reset the bar early and protect it.
What PMF really looks like here: customers self-discover core value, usage deepens without hand-holding, and cross-functional teams (engineering, data science, and operations) align around shared definitions of quality. Support volume becomes more about how-to than break-fix. Roadmap prioritization becomes easier because the next best feature reveals itself in the workflow data.
My playbook takeaways for product management leadership in GenAI: prioritize eval rigor before growth, use forward deployed engineers for product discovery, specialize the prompt playground into a governed inner loop, and delay go-to-market until high-bar users pull you in. These are the same principles I apply to gen ai for product prototyping and customer support ai strategy—because durable PMF in AI still comes down to quality, focus, and earned trust.
Referenced:
• Airtable: https://www.airtable.com/
• Adam Prout: https://www.linkedin.com/in/adam-prout-0b347630/
• Braintrust: https://braintrust.dev
• Brian Helmig: https://www.linkedin.com/in/bryanhelmig/
• Coda: https://coda.io/
• Databricks: https://www.databricks.com/
• David Kossnick: https://www.linkedin.com/in/davidkossnick/
I’ve spent the last few years watching AI reshape product roadmaps, developer workflows, and customer expectations. One idea now feels undeniable: the web must evolve to serve a new primary user—AIs. That shift changes how we think about search, reliability, governance, monetization, and ultimately, how we design products that scale with trust.
Parag Agrawal is the co-founder and CEO of Parallel, a startup building search infrastructure for the web’s second user: AIs. Before launching Parallel, Parag spent over a decade at Twitter, where he served as CTO and later CEO during a period of intense transformation, as well as public scrutiny.
I was particularly struck by how crisply this frames the next frontier for product leaders: build systems that machines can consume at massive scale without sacrificing accuracy, provenance, or trust. In particular, I was drawn to the emphasis on “deep research,” where Parallel is tackling “deep research” challenges by prioritizing accuracy over speed, and the design choices that make their APIs uniquely agent-friendly. As someone who has shipped AI features into production, that trade-off resonates—speed gets demos; accuracy earns renewals.
Here’s how I’m synthesizing the most actionable takeaways for product, engineering, and go-to-market leaders. First, design for AI as the primary customer. That means structuring content and APIs so agents can reliably reason, verify, and self-correct. Agent-friendly interfaces need deterministic schemas, explicit provenance, stable latency envelopes, and predictable failure modes. If an agent can’t trust your contract, it won’t chain your service into complex workflows, and you’ll lose the compounding effects that make AI platforms defensible.
Second, bring a systems mindset to accuracy. “Accuracy over speed” isn’t a slogan—it’s an architecture choice. In my experience, that shows up as retrieval strategies tuned for recall and precision trade-offs, multi-pass verification, and human-in-the-loop escalation paths for high-risk queries. For deep research use cases, you need to make the cost of being wrong explicit in your design and your SLAs.
Third, expect your ICP to evolve as AI matures. Early adopters may be research-heavy teams and product creators building agentic workflows. Over time, as reliability improves, your ideal customer shifts toward operational teams that demand measurable outcomes—support deflection, conversion lift, cycle-time reduction. I map these stages explicitly in the roadmap and keep pricing, packaging, and onboarding aligned to each phase.
Fourth, consider business models that keep the web open for AI while aligning incentives. If AIs are the web’s second user, publishers need fair value exchange for structured access, provenance, and usage. In practice, that could look like tiered access, usage-based pricing, attribution requirements, or revenue-sharing tied to agent-driven outcomes. The key is ensuring that openness and sustainability are not at odds.
Fifth, build engineering teams that are both pragmatic and research-aware. On my teams, I look for a balance between high-potential builders who move fast with ambiguous specs and experienced hands who can productionize novel systems. Forward deployed engineers can be a force multiplier here—embedding with customers to surface edge cases, close the verification loop, and turn qualitative insights into productized patterns.
Sixth, recognize how the software engineer’s role is evolving in an AI-assisted world. Engineers are increasingly orchestrators—composing models, retrieval layers, tools, and policies—rather than only writing business logic. That requires better observability for prompts and agents, reproducibility for experiments, and contracts that make emergent behavior inspectable and testable. This is where “uniquely agent-friendly” APIs show their value—clear contracts enable safe autonomy.
Seventh, treat launch timing as a function of trust, not just velocity. Founders often ask when to ship. My rule: launch when you can document bounds, prove repeatability on critical paths, and explain failure semantics. In AI, your narrative is your control surface—fundraising frameworks and customer conversations both benefit when you can quantify reliability, not just showcase capability.
Finally, the long-term vision matters. If agents are finally becoming useful in production, the platforms that win will combine: machine-readable content at scale, accuracy-first retrieval and verification, agent-safe API design, and sustainable economics for an open web. That’s the blueprint I’m applying to my own product strategy: build for agents, measure for trust, and align incentives so the ecosystem compounds rather than fragments.
To product leaders navigating this shift: revisit your ICP, rewrite your API contracts for agents, and make “accuracy over speed” a first-class requirement. To engineering leaders: invest in evaluation harnesses, data quality pipelines, and forward deployed engineers who can turn messy customer workflows into reusable system capabilities. The AI era rewards teams that pair ambition with discipline—and that’s where the next wave of durable advantage will be built.
You have customers, a growing backlog, and pressure to hire. Some accounts love the product. Others need executive attention, custom onboarding, or one more feature before they will commit. The decision in front of you is not simply whether to scale. It is whether the thing you are about to scale is customer pull or organizational effort.
Scaling amplifies the system you already have. Repeatable value becomes efficient growth. Ambiguous positioning becomes a larger pipeline of poor-fit prospects. Manual rescue becomes an expensive services operation. Before you add people, products, or channels, you need to locate the earliest unproven link between customer pain and repeatable economics.
Treat product-market fit as a chain of proof
Product-market fit is not a permanent badge attached to a company. It belongs to a specific combination of customer, job, product promise, and market condition. You can have strong fit with one segment and weak fit everywhere else. You can also have a product customers value without yet having a repeatable way to acquire, onboard, and support them.
That distinction matters because weak fit often looks like progress from inside the company. Sales creates urgency through relationships. Founders rescue implementations. Product accepts unrelated feature requests. Discounts overcome hesitation. Revenue arrives, but each account succeeds for a different reason.
Strong fit produces different behavior. Customers bring the product into their workflow, return to it, involve colleagues, expand its use, and react when it fails. In an early market, you may not have mature renewal data yet. You can still look for dependency: repeated use of the critical workflow, customer-initiated follow-up, willingness to share data or complete integrations, and internal advocacy when procurement becomes difficult.
Gate
Question to answer
Evidence that counts
Common false positive
Problem
Does a defined customer face an urgent job under recognizable conditions?
A recent incident, a costly workaround, an accountable owner, and a reason to act now
General agreement that the problem sounds important
Solution
Can the product complete the outcome that matters?
The user reaches the promised result through the critical path, including necessary trust and support steps
Feature usage without the intended customer outcome
Pull
Does value change customer behavior?
Repeat use, invitations, advocacy, renewal intent, expansion, or meaningful concern when the product is unavailable
Compliments, survey enthusiasm, or a pilot with no operational commitment
Repeatability
Can similar customers succeed through a recognizable motion?
Consistent positioning, buying criteria, onboarding steps, time-to-value pattern, and support needs
Revenue held together by founder access, discounts, or custom work
Expansion
Will the next product or segment inherit an advantage from the wedge?
A large adjacent market that requires a new customer, promise, channel, and operating model
Use the gates in order. Evidence at a later gate cannot repair a missing earlier one. A large pipeline does not prove urgency. High activation does not prove retention. A successful enterprise account does not prove that the implementation can be repeated.
Keep an evidence ledger for recent wins, losses, active customers, and churned accounts. Record the segment, triggering event, previous workaround, promised outcome, time-to-value path, manual interventions, commercial exceptions, and observed post-launch behavior. Separate what the product accomplished from what a founder, salesperson, implementation specialist, or discount accomplished. That separation is often where the real scaling constraint becomes visible.
Build a narrow wedge that still solves the whole critical job
A narrow wedge is not a thin product. It is a complete promise made to a constrained customer. The discipline is to narrow the persona, trigger, and job while preserving everything required for a credible outcome.
Payroll illustrates the distinction. A first product can omit broad people-management capabilities, but it cannot treat accuracy, compliance, and support as optional polish. Financial infrastructure can defer secondary workflows, but resilient integrations, risk controls, and clear operations are part of the product customers are buying. An emergency communications tool may begin with one high-value workflow, but interoperability, reliability, and human control determine whether the product can be trusted at all.
This is where the usual interpretation of an MVP causes trouble. Minimum should describe the surface area, not the integrity of the result. If a missing edge prevents the customer from safely completing the job, it is not an edge. It is part of the core.
Test urgency with behavior, not adjectives
When a prospect calls the idea useful, interesting, or impressive, you have learned very little. Ask about the last time the problem occurred:
What triggered the problem, and what happened next?
Who noticed it first, and who became accountable for resolving it?
What workaround did the customer use?
What did the delay, error, or manual process affect?
What has prevented the customer from fixing it already?
Why would the customer change now rather than in a later planning cycle?
The strongest signals impose a cost on the customer. They share operational data, introduce the real buyer, schedule implementation work, navigate security review, or change an existing process. These actions do not guarantee a sale, but they reveal more than enthusiastic language does.
Rejection is equally useful when you classify it correctly. A prospect may lack the pain, distrust a new vendor, have no current priority, face a switching barrier, involve the wrong buyer, or need a missing capability. Only the last category resembles a feature request, and even then it belongs on the roadmap only when the need repeats inside the chosen customer profile. A forceful no from the wrong segment should sharpen your positioning, not broaden your product.
Write the wedge as an operational contract
Before approving a scaling plan, require a one-page wedge definition that a product, sales, and customer success leader would interpret the same way:
Customer: the specific user, buyer, and organization profile you are serving.
Trigger: the event or condition that makes the job urgent.
Current alternative: the incumbent product, manual process, internal tool, or decision to do nothing.
Promise: the outcome the customer should be able to verify.
Critical path: the shortest end-to-end journey from entry to that outcome.
Trust requirements: the reliability, compliance, security, explainability, support, or human-review conditions that make the outcome usable.
Exclusions: the segments, use cases, and requests you are deliberately not serving yet.
For an AI product, include the human decision boundary in the promise. If the product summarizes events, detects anomalies, translates information, or recommends an action, define what the system may do automatically, what evidence the user can inspect, and where a person remains accountable. A demonstration can prove model capability. It does not prove that the workflow is dependable enough to scale.
Choose a growth engine that matches the market friction
Companies often copy a fashionable go-to-market motion without copying the conditions that made it work. Product-led growth is powerful when users can discover value quickly and carry the product to others. Direct sales is necessary when value depends on organizational change, integration, or risk approval. Community distribution works when participation by one role naturally invites another. None is inherently more advanced.
Market condition
Promising first motion
Product capability the motion requires
An individual can create value quickly, and the output is naturally visible to others
Self-serve adoption with product-led sharing
Fast onboarding, an early success moment, reusable templates, and a reason to share the result
Several connected roles benefit from participation
Community or network-led distribution
Simple invitations, role-specific value, safe defaults, and repeated interactions across the network
A small business has an urgent, high-trust operational job
Focused founder-led selling followed by a standardized assisted motion
A complete workflow, clear pricing, easy migration, credible support, and rapid value realization
A mid-market operator needs change across physical or operational workflows
Direct sales paired with field discovery
Ease of use, reliable implementation, flexible integrations, and evidence that frontline users adopt the system
A technical enterprise buyer needs proof before procurement
Product-led enterprise selling with forward-deployed support
An undeniable demonstration, fast pilot-to-production movement, deep integrations, and referenceable outcomes
A government or safety-critical buyer faces high institutional risk
Trust-first entry through a narrow deployment, partnership, or subsidized wedge
Interoperability, procurement support, security, auditability, and mission-critical reliability
Canva’s early focus on social media managers joined three useful properties: a recurring design job, an immediate visual outcome, and public output that could attract another user. ClassDojo’s classroom-to-family interactions made participation itself a distribution path. Samsara used direct contact with mid-market operators because physical operations required field learning and change management. Applied Intuition could let sophisticated technical value lead an enterprise conversation, then use credibility, references, and deployment speed to move through procurement. Prepared used a trust-building entry strategy in public safety, where adoption could not be separated from integrations and institutional risk.
The lesson is not to reproduce any one motion. It is to map the friction. Ask whether the user is also the buyer, whether value can be experienced before procurement, whether output travels, whether another participant improves the experience, whether data must be integrated, and how much organizational risk the buyer assumes. Your primary growth engine should remove the largest constraint revealed by those answers.
Then measure the engine at its point of truth. A self-serve motion needs activation by persona, repeat use of the core workflow, and invitations or shared output that lead to retained users. An enterprise motion needs qualified opportunities reaching production, a stable time-to-value path, and referenceable outcomes. A network motion needs successful cross-role participation, not just account creation. Aggregate sign-ups or pipeline can rise while the actual engine deteriorates, so preserve segment and acquisition-channel cohorts.
Free entry deserves particular care. ClassDojo delayed monetization for seven years while building trust and reach, and Prepared gave away its first product for years in a procurement-heavy market. Those choices made sense within their specific distribution constraints. Free is not proof of demand, and it is not a substitute for a business model. Treat it as a financing decision: state what adoption, standardization, trust, or network advantage must be created before the paid value can emerge.
Scale repeatability instead of scaling heroics
You are ready to scale a motion when similar customers can move from trigger to value through a recognizable path. The path does not need to be effortless. Enterprise and regulated products will retain human involvement. It does need bounded variation: teams should know which steps are standard, which exceptions are acceptable, who owns them, and what they cost.
Look for the following conditions before adding substantial capacity:
The same customer profile and urgent job explain a meaningful share of wins.
The same positioning attracts the customer and survives the sales conversation.
Implementation follows a common critical path, even when integrations differ.
Customers reach comparable outcomes without routine executive rescue.
Pricing and packaging can be explained without inventing a new deal structure for every account.
Support requests reveal fixable patterns rather than a different product expectation in every segment.
Expansion follows realized value instead of a discount or a contractual bundle customers do not use.
If these conditions are missing, headcount may hide the problem temporarily. More salespeople create more poorly qualified demand. More implementation staff normalize product gaps. More product teams accept more local requests. The company becomes busy faster without becoming more repeatable.
Turn founder knowledge into an operating system
Founder-led discovery and selling generate dense context. Scaling fails when that context remains trapped in memory or gets reduced to a generic sales script. Codify the reasoning, not just the words:
Which triggering events identify a serious prospect?
Which objections reveal poor fit, and which reveal a solvable adoption barrier?
What must be true before a pilot begins?
What customer behavior marks first value?
Which implementation exceptions require product work?
Which promises may sales make without escalation?
Who decides when a request is important enough to change the standard path?
A practical operating rhythm combines a weekly review of customer and delivery evidence with periodic strategy resets. The weekly review should examine wins, losses, activation, value realization, retention signals, implementation exceptions, and support patterns by segment. The strategy reset should decide whether the customer profile, wedge, growth engine, or resource allocation needs to change. Mixing those decisions into every weekly meeting creates thrash; waiting for an annual planning cycle leaves weak assumptions in place too long.
Pre-brief and debrief consequential customer interactions. Before the meeting, record the hypothesis, missing evidence, and decision the conversation may affect. Afterward, separate observations from interpretation and identify what changed. This keeps the loudest anecdote from becoming the roadmap while preserving important qualitative signal.
Protect quality with explicit ownership
Rapid growth exposes the edges customers could previously route around. Reliability, reconciliation, permissions, integrations, incident handling, and support become product surfaces. Assign a clear owner to each critical path, maintain a decision log for high-impact changes, and prepare runbooks before the next crisis. During a serious incident, one source of operational truth and one accountable owner per path reduce contradictory decisions.
Team design should preserve both commercial accountability and journey coherence. Revenue-only squads can accumulate one-off commitments. Experience-only squads can polish surfaces disconnected from adoption or retention. A hybrid scorecard makes the trade-off visible: each team owns a customer or business outcome while remaining accountable for the quality of the shared journey.
Hiring is part of this operating system. Humility and intrinsic motivation matter because scaling creates more ambiguous handoffs, not fewer. Test whether candidates revise a view when evidence changes, surface risks early, and protect the customer promise when short-term pressure rises. Executive alignment on pace, product quality, cost discipline, and decision rights is more valuable than complementary resumes paired with incompatible operating assumptions.
Keep fixed costs tied to proven constraints. If discovery is weak, another delivery team will not fix it. If qualified demand exceeds a stable implementation path, sales capacity may compound the bottleneck. If repeated customer needs are consuming manual effort, productization or operational tooling may be justified. Every hiring request should name the proven constraint it removes and the evidence that the constraint, rather than weak fit, is limiting growth.
Expand only when the wedge creates an inherited advantage
A successful wedge creates pressure to move upmarket, add personas, or launch adjacent products. The market size can make almost any adjacency look reasonable. The better question is whether the new bet inherits an advantage from the core or quietly starts a second company.
Gusto could broaden beyond payroll because the original workflow earned trust around money and people operations. Canva could extend from individual creation toward teams and enterprises, but doing so required identity, permissions, governance, brand controls, and performance work that changed the architecture, not just the packaging. ClassDojo could add services for an existing education community after distribution and trust had compounded. Applied Intuition pursued multiple products early because simulation, tooling, and infrastructure formed a coherent technical system. Samsara combined a broad platform direction with acute operational use cases rather than asking customers to buy an abstract platform first.
These paths expose two valid models. In a wedge-first model, depth creates trust and distribution before adjacent products arrive. In a systems-first model, multiple products may be justified earlier because they share technical primitives, customer data, deployment workflows, and a single buyer problem. The second model demands unusually strong coherence. A collection of features sold to the same logo is not automatically a platform.
Require an expansion memo to answer six practical questions:
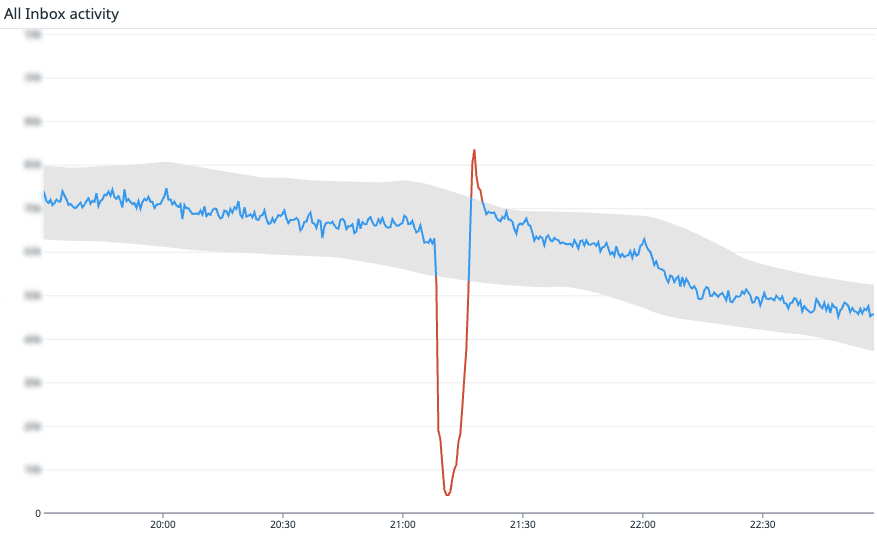
When millions of conversations flow through a platform every day, reliability isn’t just a technical metric—it’s the foundation of customer trust. I’ve learned the hard way that green dashboards can still mask red-hot customer pain. That’s why I push teams to focus on outcomes, not just infrastructure signals.
For me, reliability starts with one essential question: “Can our customers do the job they’ve hired us to do?” That single question cuts through complexity and forces a customer-outcome lens on everything from alerting to SLAs.
That mindset leads naturally to what I call “heartbeat metrics” — vital signs that instantly tell us if systems are truly serving their purpose. Think of them as a pulse check on real customer outcomes. If the pulse weakens, customers feel it instantly. A heartbeat metric is the clearest signal you can get that a product is alive and doing its job.
I’ve seen this put into practice at scale. At Intercom, where the AI Agent Fin resolves millions of customer inquiries autonomously, their fundamental heartbeat metric is the rate of new messages and replies across Intercom. For Fin, it’s successful AI responses. If those dip, it’s hitting the ability to connect. It might be a database failover, a misconfigured fleet, or a bad code change — it doesn’t matter. What matters is that it’s hitting customers’ ability to use Intercom.
Intercom isn’t alone. Amazon tracks order volume as their heartbeat. Affirm watches checkout attempts. If those numbers fall below expected levels, they don’t wait for a support ticket—they investigate immediately, because they know their customers’ success depends on it.
Not every metric qualifies as a heartbeat. The best ones share three traits: they’re directly tied to customer value (the main job your product is hired to do), high-volume and predictable (so anomaly detection can spot small drifts quickly), and binary in spirit (a drop is a clear sign something is broken, not just “a bit slower than usual”).
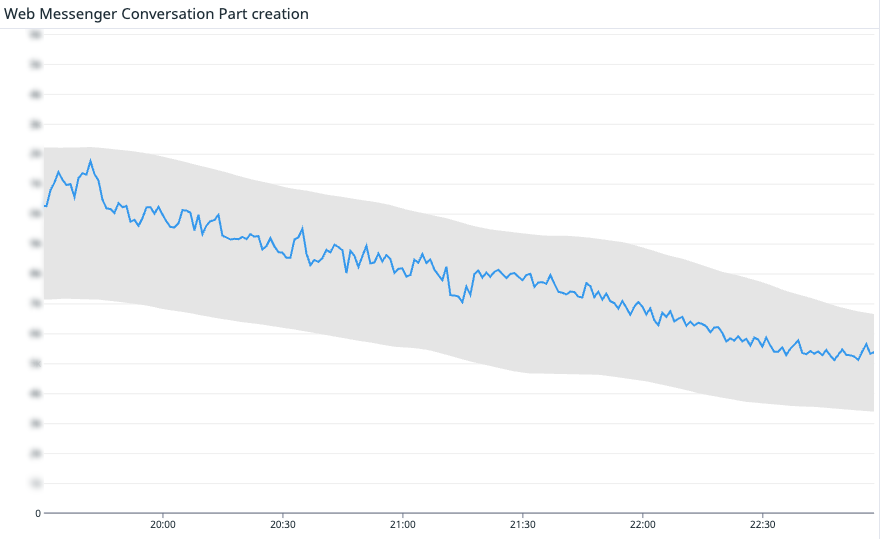
Stop watching servers—start watching customer impact. This chart tracks conversation-part creation over time; the blue line descends within a shaded band, indicating expected behavior and clear SLIs aligned to your SLA.
When we anchor on heartbeat metrics, three benefits show up fast: we detect issues faster than user reports or support tickets, we keep teams focused on what truly matters to customers, and we create a direct tie to our SLA—a system-level answer to, “Is the promise we made being kept?”
To be clear, I still monitor the usual suspects—latency, error rates, and infrastructure health. Heartbeat metrics don’t replace those; they complement them. They’re the fastest shortcut to understanding customer impact.
At scale, one pulse isn’t enough. Complex systems need multiple vital signs that reflect how different user groups succeed. Intercom started simple—are customers creating messages at the expected rate?—and then broke that signal down across core systems. Together, these metrics form a complete picture: Fin replies to your customers. Teammates reply in the Inbox. Teammates interact with the Inbox UI. Users on your website can message with the Web Messenger. Users on your app can message with the Mobile Messenger. If even one of them drops, it’s a major customer-impacting problem.
Speed matters when the heartbeat alarm fires. After months of reliable signal, automation becomes a force multiplier—paired with human oversight. Here’s what happens when a heartbeat metric drops: If we have just deployed new code to production, we automatically roll it back. Rolling back recent changes is a safe, and fast operation. We automatically create an incident in incident.io and page in engineering and an incident commander. If this alarm fires, it’s likely we will need our full incident response including status page updates. The system automatically suggests initial actions to first responders. For example, we use incident.io’s Investigations feature to get a head start on suggesting root causes.
This kind of automation pays off. On April 24th, a server issue slowed the Inbox, impacting teammates’ ability to use the Inbox. Heartbeat metrics caught it fast, and the issue was resolved in 10 minutes. End-user messaging was unaffected. This counted as downtime toward the SLA, with a full root cause analysis shared publicly here. That level of transparency keeps trust intact even when incidents happen.
Outcome-first monitoring in action: a Terraform-managed Datadog heartbeat anomaly alert with Honeycomb double-checks, rollback runbook links, and Slack/webhook routing for SLA-conscious operations.
Where heartbeat metrics truly shine is in how they define and enforce accountability. They don’t just monitor; they inform SLAs in a way customers understand. Two independent SLAs matter most in this model: Core Platform SLA: If your team can’t reply in the Inbox or customers can’t message via the Messenger, that’s downtime. Fin SLA: If Fin cannot generate text answers, we record downtime.
Measurement matters. Many status pages stay green as long as an HTTP probe returns 200 OK, even when users are stuck. Heartbeat metrics close that gap by checking real customer outcomes, not just server responses. I also favor anomaly detection—tracking expected patterns over time and flagging when something looks off—and tooling that lets us drop to a per-customer level when we need to understand individual impact.
If you don’t have a heartbeat metric yet, start simple. Pinpoint your product’s must-do job—the one thing customers must accomplish to succeed. Choose a metric with volume so you can detect drifts quickly, not just total failures. Make it binary in spirit so a drop clearly signals breakage. Hook it to your alerts so it’s loud and reaches the right responders. Use it to align teams on what to do when the heartbeat falters. And stick to it, 24/7—reliability isn’t a 9-to-5 job.
For monitoring, I like practical guardrails. Here’s a Datadog monitor pattern I recommend for an Inbox-style heartbeat (Terraform syntax, simplified for clarity): keep a tight baseline window, alert on negative deviations beyond statistically expected ranges, auto-page responders, and attach standard operating procedures for immediate rollback and incident initiation. It’s simple, auditable, and fast.
Modern systems grow more complex every quarter. The question that matters stays refreshingly simple: “Can our customers do what they came here to do?” Build a reliability heartbeat that answers that question in real time, and you’ll keep your teams honest, aligned, and fast. Define yours—it might become your most valuable signal.
How do you lead a support team in this new world with AI metrics? That question has been front and center for me as we integrate AI-first customer service tools into our daily operations.
The technology is amazing, but our assumptions and processes for understanding and leveraging AI metrics are very different from traditional support metrics. Our new CX Score is the perfect example.
Two months ago, we launched CX Score – a new way to analyze every single conversation and give you a complete view of your support experience. I was genuinely excited as someone who’s battled with CSAT survey mechanics, teammate exclusion processes for CSAT, and the nagging truth that this is only a small portion of our volume. As we’ve navigated CX Score, we’ve learned lessons that apply broadly to AI metrics. Two takeaways stand out for me.
First, lots of data calls for new processes. One of the first things we noticed was the sheer amount of data. For better or worse, CSAT was a small enough sample size to review every comment – particularly unhappy ones. Our QA team would read and categorize each response, and follow up with customers. Managers would read most comments for their team (~15 in total per manager), and discuss in 1:1s.
But what do you do with 1,600+ reviews across the org? This is the reality of AI metrics, and when you have more data than ever before, the old processes don’t scale. We briefly tried reviewing all unhappy CX ratings. We tried taking a sample, but this felt just as limited as CSAT. We exported the trends and conversation data back into an LLM for analysis, but without in-depth prompting the results were only okay.
What worked was reframing how we use the signal. Because CX Score is great for reviewing trends, we use it to measure week-over-week performance for both Fin and as a team wide KPI for human support. We also use CX Score to review specific targeted areas, like a new hire’s conversations on a certain product area. And we use it to review the customer experience for a group of customers, or to analyze a customer’s entire case history so we can lean in at the customer level.
An isometric blueprint reveals how an AI agent powers modern support—from triage to resolution—linking chat, knowledge, and workflows so teams scale service without losing accuracy, context, or the human touch.
Second, the complexities of AI mean we won’t always know the “why” – and that’s ok! People naturally want to know “the why” – especially support folks. When we started using CX Score, one of the biggest challenges was the team wanting to dig deeper into why a specific score was given. While the score provides a great overview, people wanted a detailed, step-by-step explanation. But LLMs are mostly a “black box” – especially to the everyday person. As AI becomes more and more ingrained in our work, we’ll need to accept not always knowing every detail.
This required a mindset shift for both the wider team and leadership as we moved into a world of AI metrics. We focused on the outcome vs. the process, celebrating positives and highlighting insights and actions previously impossible with only CSAT. We refused to compare to humans, reminding ourselves that many of the unknowns of AI are equally true with humans; even with a large survey, we never know for sure how customers feel. And we acknowledged emotions. Our Ops Manager William would poll the leadership team in our weekly ops meeting, asking, “In one word, how did the CX Score make you feel last week?” That simple ritual gave managers space to surface wins and challenges, and it kept us grounded.
What’s next is continuing to revamp how we work and adjusting our collective mindset for AI tools and metrics. The pros highly outweigh the cons, so I encourage you to jump in and start experimenting with AI metrics, especially where they can augment customer experience, operational cadence, and product feedback loops.
Lastly, this technology is improving very quickly. Just yesterday we added deeper AI explanations and additional attributes to explain the CX Score and aggregate summaries across topics. I’m excited to try it out!
Subscribe to The Ticket here – a bi-weekly LinkedIn newsletter delivering key insights for customer service professionals in this time of mind-blowing change.